Bugün, Llama 2 çıkarımı ve ince ayar desteğinin kullanıma sunulduğunu duyurmanın heyecanını yaşıyoruz. AWS Eğitimi ve AWS Çıkarımları örnekler Amazon SageMaker Hızlı Başlangıç. SageMaker aracılığıyla AWS Trainium ve Inferentia tabanlı bulut sunucularının kullanılması, kullanıcıların ince ayar maliyetlerini %50'ye kadar azaltmasına, dağıtım maliyetlerini 4.7 kata kadar düşürmesine ve ayrıca jeton başına gecikmeyi azaltmasına yardımcı olabilir. Llama 2, optimize edilmiş bir transformatör mimarisi kullanan, otomatik gerileyen üretken bir metin dili modelidir. Herkese açık bir model olan Llama 2, metin sınıflandırma, duygu analizi, dil çevirisi, dil modelleme, metin oluşturma ve diyalog sistemleri gibi birçok NLP görevi için tasarlanmıştır. Llama 2 gibi LLM'lerin ince ayarının yapılması ve dağıtılması, iyi bir müşteri deneyimi sunmak için gerçek zamanlı performansa ulaşmak maliyetli veya zorlayıcı olabilir. Trainium ve AWS Inferentia, aşağıdakiler tarafından etkinleştirilir: AWS Nöron yazılım geliştirme kiti (SDK), Llama 2 modellerinin eğitimi ve çıkarımı için yüksek performanslı ve uygun maliyetli bir seçenek sunar.
Bu yazıda, SageMaker JumpStart'ta Trainium ve AWS Inferentia bulut sunucularında Llama 2'nin nasıl dağıtılacağını ve ince ayarlarının nasıl yapılacağını gösteriyoruz.
Çözüme genel bakış
Bu blogda aşağıdaki senaryoları inceleyeceğiz:
- Llama 2'yi her iki platformda da AWS Inferentia bulut sunucularına dağıtın Amazon SageMaker Stüdyosu Tek tıklamayla dağıtım deneyimi ve SageMaker Python SDK'sı ile kullanıcı arayüzü.
- Hem SageMaker Studio kullanıcı arayüzünde hem de SageMaker Python SDK'sında Trainium örneklerinde Llama 2'ye ince ayar yapın.
- İnce ayarın etkinliğini göstermek için, ince ayarı yapılmış Llama 2 modelinin performansını önceden eğitilmiş modelin performansıyla karşılaştırın.
Uygulamayı öğrenmek için bkz. GitHub örnek not defteri.
SageMaker Studio kullanıcı arayüzünü ve Python SDK'yı kullanarak Llama 2'yi AWS Inferentia bulut sunucularına dağıtın
Bu bölümde, tek tıklamayla dağıtım için SageMaker Studio kullanıcı arayüzünü ve Python SDK'yı kullanarak AWS Inferentia bulut sunucularında Llama 2'nin nasıl dağıtılacağını gösteriyoruz.
SageMaker Studio kullanıcı arayüzünde Llama 2 modelini keşfedin
SageMaker JumpStart, hem kamuya açık hem de tescilli olanlara erişim sağlar. temel modelleri. Temel modeller üçüncü taraf ve özel sağlayıcılar tarafından desteklenir ve korunur. Bu nedenle, model kaynağı tarafından belirlenen farklı lisanslar altında yayınlanırlar. Kullandığınız herhangi bir temel modelin lisansını mutlaka inceleyin. İçeriği indirmeden veya kullanmadan önce geçerli lisans koşullarını incelemek ve bunlara uymak ve bunların kullanım durumunuz için kabul edilebilir olduğundan emin olmak sizin sorumluluğunuzdadır.
Llama 2 temel modellerine, SageMaker Studio kullanıcı arayüzündeki ve SageMaker Python SDK'sındaki SageMaker JumpStart aracılığıyla erişebilirsiniz. Bu bölümde SageMaker Studio'daki modelleri nasıl keşfedeceğimizi ele alıyoruz.
SageMaker Studio, veri hazırlamaktan ML'nizi oluşturmaya, eğitmeye ve dağıtmaya kadar tüm makine öğrenimi (ML) geliştirme adımlarını gerçekleştirmek için amaca yönelik olarak oluşturulmuş araçlara erişebileceğiniz tek bir web tabanlı görsel arayüz sağlayan entegre bir geliştirme ortamıdır (IDE). modeller. SageMaker Studio'nun nasıl başlatılacağı ve kurulacağı hakkında daha fazla ayrıntı için bkz. Amazon SageMaker Stüdyosu.
SageMaker Studio'ya girdikten sonra, önceden eğitilmiş modeller, dizüstü bilgisayarlar ve önceden oluşturulmuş çözümler içeren SageMaker JumpStart'a şu adresten erişebilirsiniz: Önceden oluşturulmuş ve otomatikleştirilmiş çözümler. Tescilli modellere nasıl erişileceğine ilişkin daha ayrıntılı bilgi için bkz. Amazon SageMaker Studio'da Amazon SageMaker JumpStart'ın tescilli temel modellerini kullanın.

SageMaker JumpStart açılış sayfasından çözümlere, modellere, not defterlerine ve diğer kaynaklara göz atabilirsiniz.
Llama 2 modellerini görmüyorsanız SageMaker Studio sürümünüzü kapatıp yeniden başlatarak güncelleyin. Sürüm güncellemeleri hakkında daha fazla bilgi için bkz. Studio Klasik Uygulamalarını Kapatın ve Güncelleyin.
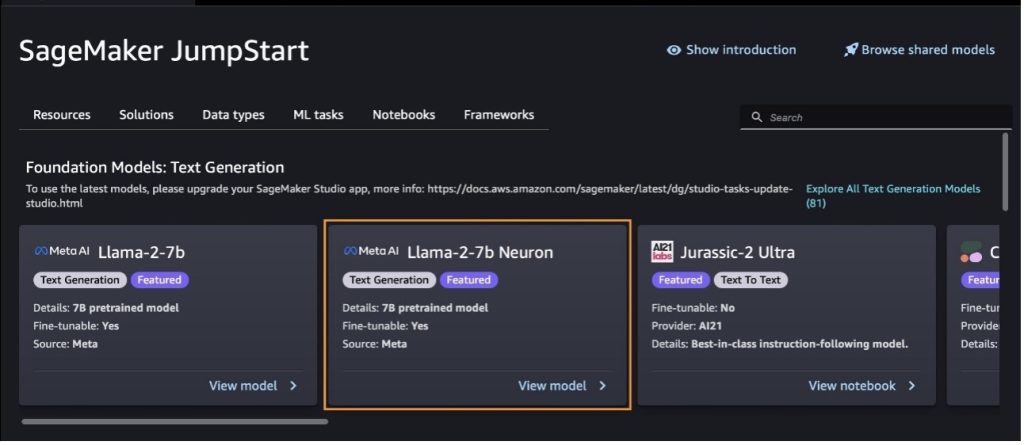
Diğer model çeşitlerini de tercih ederek bulabilirsiniz. Tüm Metin Oluşturma Modellerini Keşfedin veya arıyor llama or neuron arama kutusunda. Llama 2 Neuron modellerini bu sayfada görebileceksiniz.

Llama-2-13b modelini SageMaker Hızlı Başlangıç ile devreye alın
Lisans, eğitim için kullanılan veriler ve nasıl kullanılacağı gibi modelle ilgili ayrıntıları görüntülemek için model kartını seçebilirsiniz. Ayrıca iki düğme de bulabilirsiniz, Sürüş ve Not defterini aç, bu kodsuz örneği kullanarak modeli kullanmanıza yardımcı olur.
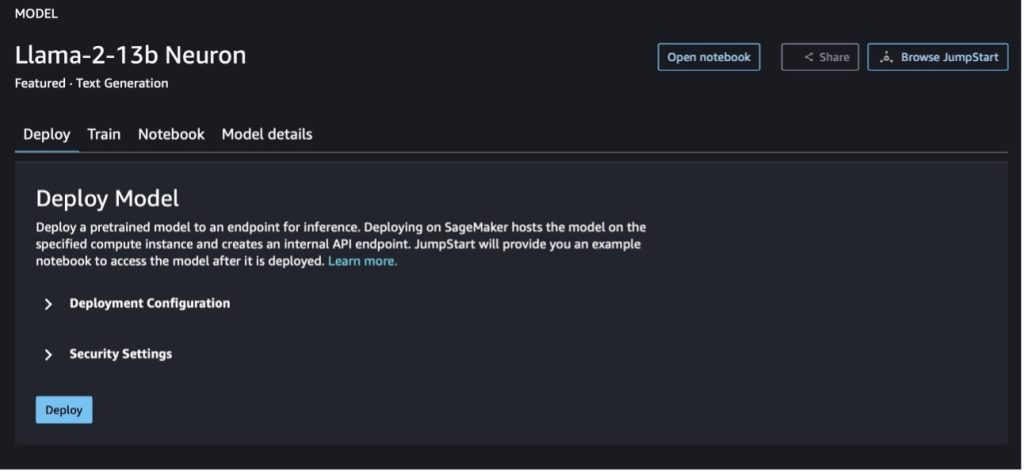
Düğmelerden birini seçtiğinizde, onaylamanız için Son Kullanıcı Lisans Sözleşmesi ve Kabul Edilebilir Kullanım Politikası (AUP) bir açılır pencerede gösterilir.
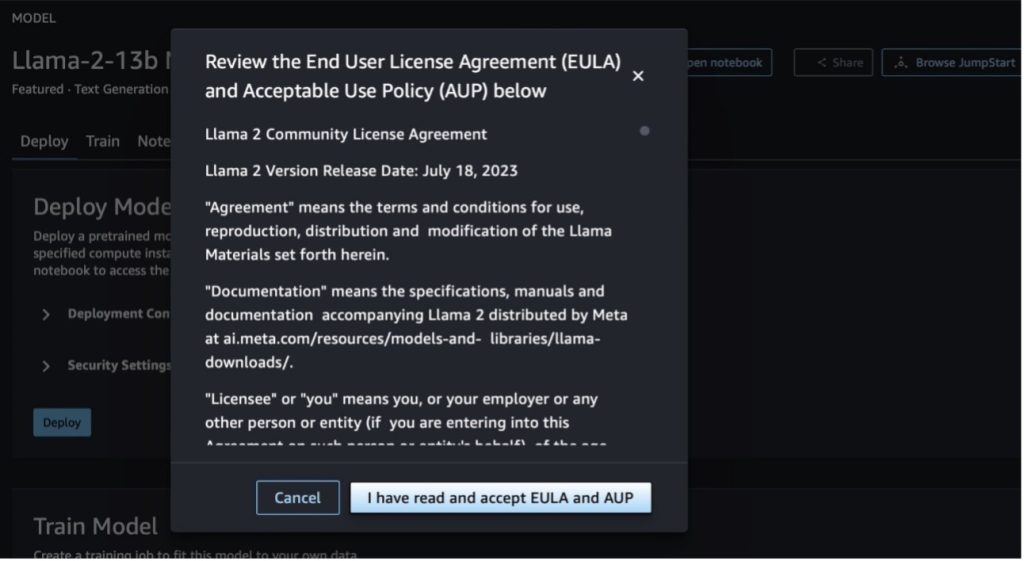
Politikaları kabul ettikten sonra modelin uç noktasını dağıtabilir ve bir sonraki bölümdeki adımlarla kullanabilirsiniz.
Llama 2 Neuron modelini Python SDK aracılığıyla dağıtma
Seçtiğinizde Sürüş ve şartları kabul ettiğinizde model dağıtımı başlayacaktır. Alternatif olarak, aşağıdakileri seçerek örnek not defteri aracılığıyla dağıtım yapabilirsiniz: Not defterini aç. Örnek not defteri, modelin çıkarım için nasıl dağıtılacağı ve kaynakların nasıl temizleneceği konusunda uçtan uca rehberlik sağlar.
Trainium veya AWS Inferentia bulut sunucularında bir modeli dağıtmak veya ince ayar yapmak için öncelikle PyTorch Neuron'u (meşale-nöronx) modeli, Inferentia'nın NeuronCores'ları için optimize edecek olan Neuron'a özgü bir grafik halinde derlemek. Kullanıcılar, uygulamanın hedeflerine bağlı olarak derleyiciye en düşük gecikme veya en yüksek verimi optimize etmesi talimatını verebilir. JumpStart'ta, kullanıcıların derleme adımlarını hızlandırmasına olanak tanıyarak modellerin daha hızlı ince ayarlanmasını ve dağıtılmasını sağlamak için çeşitli konfigürasyonlar için Neuron grafiklerini önceden derledik.
Neuron'un önceden derlenmiş grafiğinin, Neuron Compiler sürümünün belirli bir sürümüne göre oluşturulduğunu unutmayın.
LIama 2'yi AWS Inferentia tabanlı bulut sunucularına dağıtmanın iki yolu vardır. İlk yöntem önceden oluşturulmuş yapılandırmayı kullanır ve modeli yalnızca iki satır kodla dağıtmanıza olanak tanır. İkincisinde, konfigürasyon üzerinde daha fazla kontrole sahip olursunuz. Önceden oluşturulmuş konfigürasyonla ilk yöntemle başlayalım ve örnek olarak önceden eğitilmiş Llama 2 13B Nöron Modelini kullanalım. Aşağıdaki kod, Llama 13B'nin yalnızca iki satırla nasıl dağıtılacağını gösterir:
Bu modellerde çıkarım yapmak için argümanı belirtmeniz gerekir. accept_eula olduğu True bir parçası olarak model.deploy() Arama. Bu argümanın doğru olarak ayarlanması, modelin EULA'sını okuyup kabul ettiğinizi onaylar. EULA'yı model kartı açıklamasında veya Meta web sitesi.
Llama 2 13B için varsayılan bulut sunucusu türü ml.inf2.8xlarge'dir. Ayrıca desteklenen diğer model kimliklerini de deneyebilirsiniz:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(sohbet modeli)meta-textgenerationneuron-llama-2-13b-f(sohbet modeli)
Alternatif olarak, bağlam uzunluğu, tensör paralel derecesi ve maksimum hareketli toplu iş boyutu gibi dağıtım yapılandırmaları üzerinde daha fazla kontrole sahip olmak istiyorsanız, bunları bu bölümde gösterildiği gibi çevresel değişkenler aracılığıyla değiştirebilirsiniz. Dağıtımın temelindeki Derin Öğrenme Konteyneri (DLC) Büyük Model Çıkarımı (LMI) NeuronX DLC. Çevresel değişkenler aşağıdaki gibidir:
- OPTION_N_POSITIONS – Maksimum giriş ve çıkış jeton sayısı. Örneğin, modeli şununla derlerseniz:
OPTION_N_POSITIONS512 olarak, maksimum 128 çıkış jetonuyla (giriş ve çıkış jetonlarının toplamı 384 olmalıdır) 512'lik bir giriş jetonunu (giriş istemi boyutu) kullanabilirsiniz. Maksimum çıkış jetonu için 384'ün altındaki herhangi bir değer uygundur ancak bunun ötesine geçemezsiniz (örneğin, giriş 256 ve çıkış 512). - OPTION_TENSOR_PARALLEL_DEGREE – Modeli AWS Inferentia bulut sunucularına yükleyecek NeuronCores sayısı.
- OPTION_MAX_ROLLING_BATCH_SIZE – Eşzamanlı istekler için maksimum toplu iş boyutu.
- OPTION_DTYPE – Modelin yükleneceği tarih türü.
Nöron grafiğinin derlenmesi bağlam uzunluğuna bağlıdır (OPTION_N_POSITIONS), tensör paralel derecesi (OPTION_TENSOR_PARALLEL_DEGREE), maksimum parti boyutu (OPTION_MAX_ROLLING_BATCH_SIZE) ve veri türü (OPTION_DTYPE) modeli yüklemek için. SageMaker JumpStart, çalışma zamanı derlemesini önlemek amacıyla önceki parametrelere yönelik çeşitli konfigürasyonlar için önceden derlenmiş Neuron grafiklerine sahiptir. Önceden derlenmiş grafiklerin konfigürasyonları aşağıdaki tabloda listelenmiştir. Çevresel değişkenler aşağıdaki kategorilerden birine girdiği sürece Nöron grafiklerinin derlenmesi atlanacaktır.
| LIama-2 7B ve LIama-2 7B Sohbet | ||||
| Örnek türü | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B ve LIama-2 13B Sohbet | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Aşağıda Llama 2 13B'nin dağıtımına ve mevcut tüm yapılandırmaların ayarlanmasına ilişkin bir örnek yer almaktadır.
Artık Llama-2-13b modelini konuşlandırdığımıza göre, uç noktayı çağırarak onunla çıkarım yapabiliriz. Aşağıdaki kod parçacığı, metin oluşturmayı denetlemek için desteklenen çıkarım parametrelerinin kullanımını gösterir:
- maksimum uzunluk – Model, çıktı uzunluğu (giriş içeriği uzunluğunu içerir) ulaşana kadar metin üretir.
max_length. Belirtilmişse, pozitif bir tamsayı olmalıdır. - max_new_tokens – Model, çıktı uzunluğu (giriş bağlamı uzunluğu hariç) şu değere ulaşana kadar metin üretir:
max_new_tokens. Belirtilmişse, pozitif bir tamsayı olmalıdır. - num_beams – Bu açgözlü aramada kullanılan ışın sayısını gösterir. Belirtilmişse, değerinden büyük veya ona eşit bir tamsayı olmalıdır
num_return_sequences. - no_repeat_ngram_size – Model, bir sözcük dizisinin
no_repeat_ngram_sizeçıktı dizisinde tekrarlanmaz. Belirtilmişse, 1'den büyük bir pozitif tamsayı olmalıdır. - sıcaklık – Bu, çıktıdaki rastgeleliği kontrol eder. Daha yüksek bir sıcaklık, düşük olasılıklı sözcükler içeren bir çıktı dizisiyle sonuçlanır; daha düşük bir sıcaklık, yüksek olasılıklı kelimeler içeren bir çıktı dizisiyle sonuçlanır. Eğer
temperature0'a eşittir, açgözlü kod çözme ile sonuçlanır. Belirtilmişse, pozitif bir kayan nokta olmalıdır. - erken_durdurma - Eğer
True, tüm ışın hipotezleri cümle belirtecinin sonuna ulaştığında metin oluşturma tamamlanır. Belirtilmişse Boolean olmalıdır. - örnek yap - Eğer
Truemodel, olasılığa göre bir sonraki kelimeyi örnekler. Belirtilmişse Boolean olmalıdır. - top_k – Metin oluşturmanın her adımında model yalnızca metinden örnekler alır.
top_kbüyük olasılıkla kelimeler. Belirtilmişse, pozitif bir tamsayı olmalıdır. - top_p – Metin oluşturmanın her adımında model, kümülatif olasılığa sahip mümkün olan en küçük kelime kümesinden örnekler alır.
top_p. Belirtilmişse, 0–1 arasında bir değişken olmalıdır. - durdurmak – Belirtilmişse, dizelerin bir listesi olmalıdır. Belirtilen dizelerden herhangi biri oluşturulursa metin oluşturma durdurulur.
Aşağıdaki kod bir örneği gösterir:
Çıktı:
Yükteki parametreler hakkında daha fazla bilgi için bkz. Detaylı parametreler.
Ayrıca parametrelerin uygulanmasını da inceleyebilirsiniz. defter Not defterinin bağlantısı hakkında daha fazla bilgi eklemek için.
SageMaker Studio kullanıcı arayüzünü ve SageMaker Python SDK'sını kullanarak Trainium bulut sunucularında Llama 2 modellerine ince ayar yapın
Üretken yapay zeka temel modelleri, makine öğrenimi ve yapay zekanın birincil odak noktası haline geldi; ancak bunların geniş genelleştirilmesi, benzersiz veri kümelerinin dahil olduğu sağlık hizmetleri veya finansal hizmetler gibi belirli alanlarda yetersiz kalabiliyor. Bu sınırlama, bu üretken yapay zeka modellerinin, bu özel alanlardaki performanslarını artırmak için alana özgü verilerle ince ayar yapılması ihtiyacını vurgulamaktadır.
Artık Llama 2 modelinin önceden eğitilmiş sürümünü konuşlandırdığımıza göre, doğruluğu artırmak, modeli hızlı tamamlama açısından geliştirmek ve modeli ihtiyaca göre uyarlamak için alana özgü verilere nasıl ince ayar yapabileceğimize bakalım. özel iş kullanım durumunuz ve verileriniz. SageMaker Studio kullanıcı arayüzünü veya SageMaker Python SDK'yı kullanarak modellerde ince ayar yapabilirsiniz. Bu bölümde her iki yöntemi de tartışacağız.
SageMaker Studio ile Llama-2-13b Neuron modeline ince ayar yapın
SageMaker Studio'da Llama-2-13b Neuron modeline gidin. Üzerinde Sürüş sekmesini işaret edebilirsiniz. Amazon Basit Depolama Hizmeti İnce ayar için eğitim ve doğrulama veri kümelerini içeren (Amazon S3) paketi. Ayrıca, ince ayar yapmak için dağıtım yapılandırmasını, hiperparametreleri ve güvenlik ayarlarını yapılandırabilirsiniz. O zaman seç Tren SageMaker ML örneğinde eğitim işini başlatmak için.
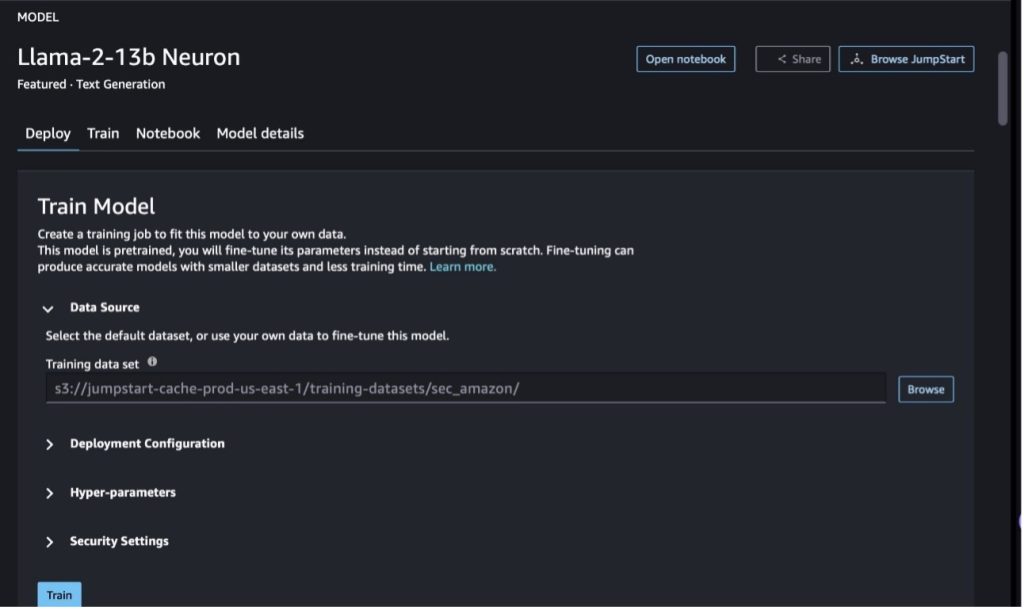
Llama 2 modellerini kullanmak için EULA ve AUP'yi kabul etmeniz gerekir. Seçtiğinizde görünecektir Tren. Seçin EULA ve AUP'yi okudum ve kabul ediyorum ince ayar işine başlamak için.
İnce ayarlı model için eğitim işinizin durumunu SageMaker konsolunda aşağıdaki seçeneği seçerek görüntüleyebilirsiniz: Eğitim işleri Gezinti bölmesinde.
Bu kodsuz örneği kullanarak Llama 2 Neuron modelinize ince ayar yapabilir veya sonraki bölümde gösterildiği gibi Python SDK aracılığıyla ince ayar yapabilirsiniz.
SageMaker Python SDK aracılığıyla Llama-2-13b Neuron modeline ince ayar yapın
Etki alanı uyarlama biçimiyle veya veri kümesinde ince ayar yapabilirsiniz. talimat tabanlı ince ayar biçim. İnce ayara gönderilmeden önce eğitim verilerinin nasıl biçimlendirilmesi gerektiğine ilişkin talimatlar aşağıda verilmiştir:
- Giriş - A
trainJSON satırları (.jsonl) veya metin (.txt) biçimli dosyayı içeren dizin.- JSON satırları (.jsonl) dosyası için her satır ayrı bir JSON nesnesidir. Her JSON nesnesi, anahtarın olması gereken yerde bir anahtar/değer çifti olarak yapılandırılmalıdır.
textve değer bir eğitim örneğinin içeriğidir. - Train dizini altındaki dosya sayısı 1'e eşit olmalıdır.
- JSON satırları (.jsonl) dosyası için her satır ayrı bir JSON nesnesidir. Her JSON nesnesi, anahtarın olması gereken yerde bir anahtar/değer çifti olarak yapılandırılmalıdır.
- Çıktı – Çıkarım için devreye alınabilecek eğitimli bir model.
Bu örnekte, şunun bir alt kümesini kullanıyoruz: Dolly veri kümesi talimat ayarlama formatında. Dolly veri seti, soru cevaplama, özetleme ve bilgi çıkarma gibi çeşitli kategoriler için yaklaşık 15,000 talimat takip kaydı içerir. Apache 2.0 lisansı altında mevcuttur. biz kullanıyoruz information_extraction ince ayar örnekleri.
- Dolly veri kümesini yükleyin ve bölün
train(ince ayar için) vetest(Evrim için):
- Eğitim işine yönelik bir talimat formatındaki verileri ön işlemek için bir bilgi istemi şablonu kullanın:
- Hiperparametreleri inceleyin ve kendi kullanım durumunuz için bunların üzerine yazın:
- Modele ince ayar yapın ve bir SageMaker eğitim işine başlayın. İnce ayar komut dosyaları aşağıdakileri temel alır: nöronx-nemo-megatron paketlerin değiştirilmiş versiyonları olan depo Nemo ve Tepe Neuron ve EC2 Trn1 bulut sunucularıyla kullanım için uyarlanmıştır. nöronx-nemo-megatron depo, LLM'lere ölçekte ince ayar yapmanıza olanak tanıyan 3B (veri, tensör ve boru hattı) paralelliğine sahiptir. Desteklenen Trainium örnekleri ml.trn1.32xlarge ve ml.trn1n.32xlarge'dir.
- Son olarak, ince ayarı yapılmış modeli bir SageMaker uç noktasına dağıtın:
Önceden eğitilmiş ve ince ayarlı Llama 2 Neuron modelleri arasındaki yanıtları karşılaştırın
Artık Llama-2-13b modelinin önceden eğitilmiş sürümünü dağıttığımıza ve ince ayarını yaptığımıza göre, aşağıdaki tabloda gösterildiği gibi her iki modeldeki hızlı tamamlamaların bazı performans karşılaştırmalarını görüntüleyebiliriz. Ayrıca .txt formatındaki bir SEC dosyalama veri kümesinde Llama 2'ye ince ayar yapmak için bir örnek de sunuyoruz. Ayrıntılar için bkz. GitHub örnek not defteri.
| + | Girdiler | Zemin gerçeği | İnce ayarı yapılmamış modelden yanıt | İnce ayarlı modelden yanıt |
| 1 | Aşağıda, daha fazla bağlam sağlayan bir girdiyle eşleştirilmiş, bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.nn### Talimat:nMoret'in okuduğu üniversiteleri ve her biri için mezuniyet yıllarını çıkarın ve bunları madde işaretli listeye koyun.nn### Girdi:nMoret 1953'te Vevey İsviçre'de doğdu Lisans eğitimini École Polytechnique Fédérale de Lausanne'de (EPFL) tamamladı ve 1975'te mezun oldu. Tennessee Üniversitesi'nde yüksek lisans eğitimine devam ederek doktora derecesini aldı. Daha sonra New Mexico Üniversitesi'nin fakültesine katıldı ve 1980 yılında EPFL'ye geçene kadar burada kaldı. Aralık 2006'da EPFL'den emekli oldu. nnMoret, 2016'da ACM Journal of Experimental Algorithmics'i kurdu ve 1996 yılına kadar derginin genel yayın yönetmeni olarak kaldı. 2003'de Moret, Workshop in Algorithms for Bioinformatics'i (WABI) kurdu ve bu dergide çalışmaya devam ediyor. Konferansın Yönlendirme Komitesi.nnMoret, hesaplamalı biyoloji ve biyoinformatik alanlarına yaptığı olağanüstü katkılardan dolayı 2001 yılında Uluslararası Hesaplamalı Biyoloji Derneği Üyesi seçildi.nn### Yanıt:n | * École Polytechnique Fédérale de Lausanne (EPFL) (1975 mezunu)n* Tennessee Üniversitesi (1980 mezunu) | Moret, École Polytechnique Fédérale de Lausanne (EPFL) ve Tennessee Üniversitesi'nde eğitim gördü ve sırasıyla 1975 ve 1980'de mezun oldu.nn### İpucu:nn- Girişi bir cümle listesine bölmek için "bölme" işlevini kullanın.n- Her cümleyi bir kelime listesine bölmek için "bölme" işlevini kullanın. n- Bölmek için "bölme" işlevini kullanın | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- Tennessee Üniversitesi,1980n- New Mexico Üniversitesi- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Aşağıda, bir girdiyle eşleştirilen bir görevi açıklayan bir talimat bulunmaktadır. daha fazla bağlam sağlar. İsteği uygun şekilde tamamlayan bir yanıt yazın.n |
| 2 | Aşağıda, daha fazla bağlam sağlayan bir girdiyle eşleştirilmiş, bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.nn### Talimat:nParçadan Dionysos'un niteliklerini tanımlayın. Sonuçları virgülle ayrılmış biçimde görüntüleyin.nn### Giriş:nDionysos (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnŞarap, bereket, partiler, festivaller, çılgınlık, kaos, sarhoşluk, bitki örtüsü, coşku ve tiyatro. Zeus ve Semele'nin iki kez doğan oğludur, Zeus onu annesinin rahminden alıp Dionysos'u kendi uyluğuna dikmiş ve doğmaya hazır olana kadar onu taşımıştır. Sanatta ya yaşlı sakallı bir tanrı (özellikle MÖ 430'dan önce) ya da kadınsı, uzun saçlı bir genç (özellikle MÖ 430'dan sonra) olarak tasvir edilmiştir. Nitelikleri arasında tirsus, bir bardak, üzüm asması ve sarmaşıktan bir taç yer alır. Sık sık satirlerin, maenadların ve eski öğretmeni Silenus'un da aralarında bulunduğu bir grup hizmetçiden oluşan thiasos'unun yanındadır. Dionysos'un eşi Ariadne'dir. Bir zamanlar Dionysius'un Yunan panteonuna sonradan eklendiği düşünülüyordu, ancak Linear B tabletlerinin keşfi onun erken dönemden itibaren bir tanrı olduğunu doğruluyor. Bacchus onun Yunancadaki diğer adıydı ve Romalılar arasında yaygın olarak kullanılmaya başlandı. Kutsal hayvanları arasında yunuslar, yılanlar, kaplanlar ve eşekler yer alır.nn### Response:n | thyrsus, bir bardak, üzüm asması, sarmaşıktan bir taç | Dionysos (Διόνυσος, Diónusos)nnŞarap, bereket, partiler, festivaller, delilik, kaos, sarhoşluk, bitki örtüsü, coşku ve tiyatro tanrısı. Zeus ve Semele'nin iki doğumlu oğludur; Zeus onu annesinin rahminden alıp Dionysos'u kendi uyluğuna dikmiştir. | thyrsus, bir içki bardağı, üzüm asması, sarmaşıktan bir taç Aşağıda, daha fazla bağlam sağlayan bir girdiyle eşleştirilen, bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.nn### Talimat:nParth ve Arşak İmparatorluğu arasındaki fark nedir?nn### Girdi:nArşak İmparatorluğu olarak da bilinen Part İmparatorluğu, bir |
| 3 | Aşağıda, daha fazla bağlam sağlayan bir girdiyle eşleştirilmiş, bir görevi açıklayan bir talimat bulunmaktadır. İsteği uygun şekilde tamamlayan bir yanıt yazın.nn### Talimat:nÖzbekistan'ın başkenti neden en büyük Yunan topluluğunu içeriyor?nn### Girdi:nÖzbekistan'daki Yunanlıların sayısı yaklaşık 9,000. Topluluk, 1940'larda Özbekistan'a zorla sınır dışı edilen Rusya'dan gelen Rumlardan ve Yunanistan'dan gelen siyasi mültecilerden oluşuyor. İkinci Dünya Savaşı'ndan önce ülkede yaklaşık 30,000 Yunan yaşıyordu ve Yunan İç Savaşı ve Yunanistan Demokratik Ordusu'nun yenilgisinden sonra 11,000 kişi daha geldi. Sayıları 40,000'larda 1960 civarındaydı. Bunun temel nedeni, Soğuk Savaş'ın sona ermesinin ardından Yunanistan İç Savaşı'ndan sonra siyasi nedenlerle sürgüne gönderilen tüm etnik Yunanlıların geri dönmesine kanunların izin vermesiyle Yunanistan'a göçtür. Ülkedeki en büyük Yunan topluluğu, Yunan siyasi mültecilerin çoğunun Sovyet yetkilileri tarafından yeniden yerleştirildiği başkent Taşkent'te bulunuyor. Antik çağda ülkenin güneyi Helenistik Seleukos Krallığı'nın bir parçasıydı ancak oradaki az sayıdaki Yunan topluluğu o zamandan beri asimile olmuştur. Etnik Rumları temsil eden en önemli kuruluş Taşkent Rum Kültür Derneği'dir. Bu organizasyonun faaliyetleri arasında Yunanca dili eğitimi (toplam 19 öğrenciyle 571 sınıf, yetişkinlere yönelik sınıflar) ve Yunan dansları ve müziğinin öğretilmesi yer alıyor.nn### Yanıt:n | Özbekistan'daki Yunan siyasi mültecilerin çoğu Sovyet yetkilileri tarafından başkent Taşkent'e yerleştirildi. | n“`nÖzbekistan'ın başkenti en büyük Rum topluluğunu barındırıyor çünkü Özbekistan'daki Rumların sayısı yaklaşık 9,000. Topluluk, 1940'larda Özbekistan'a zorla sınır dışı edilen Rusya'dan gelen Rumlardan ve Yunanistan'dan gelen siyasi mültecilerden oluşuyor. İkinci Dünya Savaşı'ndan önce ülkede yaklaşık 30,000 Rum yaşıyordu ve ayrıca 11,00 Rum da yaşıyordu. | Özbekistan'ın başkenti en büyük Yunan topluluğunu barındırıyor çünkü burası, Yunan siyasi mültecilerin çoğunun, Yunanistan'dan sınır dışı edildikten sonra Sovyet yetkilileri tarafından yeniden yerleştirildiği yer. nn Aşağıda, bir görevi açıklayan ve aşağıdakileri sağlayan bir girdiyle eşleştirilen bir talimat verilmiştir: daha fazla bağlam. İsteği uygun şekilde tamamlayan bir yanıt yazın.nn### Talimat:nParth ve Arşak İmparatorluğu arasındaki fark nedir?nn### Giriş:n |
İnce ayarlı modelden gelen yanıtların, önceden eğitilmiş modele kıyasla hassasiyet, uygunluk ve netlik açısından önemli bir gelişme gösterdiğini görebiliriz. Bazı durumlarda, kullanım durumunuz için önceden eğitilmiş modeli kullanmak yeterli olmayabilir; bu nedenle, bu tekniği kullanarak modelde ince ayar yapmak, çözümü veri kümeniz için daha kişisel hale getirecektir.
Temizlemek
Eğitim işinizi tamamladıktan ve mevcut kaynakları artık kullanmak istemediğinizde aşağıdaki kodu kullanarak kaynakları silin:
Sonuç
Llama 2 Neuron modellerinin SageMaker'da konuşlandırılması ve ince ayarının yapılması, büyük ölçekli üretken yapay zeka modellerinin yönetilmesinde ve optimize edilmesinde önemli bir ilerleme olduğunu göstermektedir. Llama-2-7b ve Llama-2-13b gibi değişkenler de dahil olmak üzere bu modeller, AWS Inferentia ve Trainium tabanlı bulut sunucuları üzerinde verimli eğitim ve çıkarım için Neuron'u kullanarak performanslarını ve ölçeklenebilirliklerini artırır.
Bu modelleri SageMaker JumpStart Kullanıcı Arayüzü ve Python SDK aracılığıyla dağıtma yeteneği esneklik ve kullanım kolaylığı sunar. Neuron SDK, popüler makine öğrenimi çerçevelerini desteklemesi ve yüksek performanslı yetenekleriyle bu büyük modellerin verimli şekilde işlenmesini sağlar.
Bu modellerin alana özgü veriler üzerinde ince ayarının yapılması, bunların özel alanlardaki geçerliliğini ve doğruluğunu artırmak açısından çok önemlidir. SageMaker Studio Kullanıcı Arayüzü veya Python SDK aracılığıyla gerçekleştirebileceğiniz süreç, belirli ihtiyaçlara göre özelleştirme yapılmasına olanak tanıyarak, hızlı tamamlama ve yanıt kalitesi açısından gelişmiş model performansına yol açar.
Karşılaştırmalı olarak, bu modellerin önceden eğitilmiş versiyonları güçlü olsa da daha genel veya tekrarlayan yanıtlar sağlayabilir. İnce ayar, modeli belirli bağlamlara göre uyarlayarak daha doğru, ilgili ve çeşitli yanıtlar sağlar. Bu özelleştirme, özellikle önceden eğitilmiş ve ince ayarlı modellerden alınan yanıtlar karşılaştırıldığında belirgindir; burada sonuncusu, çıktının kalitesinde ve özgüllüğünde gözle görülür bir iyileşme gösterir. Sonuç olarak, Neuron Llama 2 modellerinin SageMaker'da dağıtımı ve ince ayarı, gelişmiş yapay zeka modellerini yönetmek için sağlam bir çerçeveyi temsil ediyor ve özellikle belirli alanlara veya görevlere göre uyarlandığında performans ve uygulanabilirlikte önemli iyileştirmeler sunuyor.
Örnek SageMaker'a başvurarak bugün başlayın defter.
Önceden eğitilmiş Llama 2 modellerinin GPU tabanlı örneklerde dağıtılması ve ince ayarının yapılması hakkında daha fazla bilgi için bkz. Amazon SageMaker JumpStart'ta metin oluşturmak için Llama 2'ye ince ayar yapın ve Meta'nın Llama 2 temel modelleri artık Amazon SageMaker JumpStart'ta mevcut.
Yazarlar, Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne ve Mike James'e teknik katkılarından dolayı teşekkür etmek ister.
Yazarlar Hakkında
 Xin Huang Amazon SageMaker JumpStart ve Amazon SageMaker yerleşik algoritmaları için Kıdemli Uygulamalı Bilim İnsanıdır. Ölçeklenebilir makine öğrenimi algoritmaları geliştirmeye odaklanıyor. Araştırma ilgi alanları, doğal dil işleme, tablo verileri üzerinde açıklanabilir derin öğrenme ve parametrik olmayan uzay-zaman kümelemenin sağlam analizi alanındadır. ACL, ICDM, KDD konferanslarında ve Royal Statistical Society: Series A'da birçok makale yayınladı.
Xin Huang Amazon SageMaker JumpStart ve Amazon SageMaker yerleşik algoritmaları için Kıdemli Uygulamalı Bilim İnsanıdır. Ölçeklenebilir makine öğrenimi algoritmaları geliştirmeye odaklanıyor. Araştırma ilgi alanları, doğal dil işleme, tablo verileri üzerinde açıklanabilir derin öğrenme ve parametrik olmayan uzay-zaman kümelemenin sağlam analizi alanındadır. ACL, ICDM, KDD konferanslarında ve Royal Statistical Society: Series A'da birçok makale yayınladı.
 Nitin Eusebios AWS'de Kıdemli Kurumsal Çözümler Mimarıdır ve Yazılım Mühendisliği, Kurumsal Mimari ve AI/ML konularında deneyimlidir. Üretken yapay zekanın olanaklarını keşfetme konusunda son derece tutkulu. AWS platformunda iyi tasarlanmış uygulamalar oluşturmalarına yardımcı olmak için müşterilerle işbirliği yapıyor ve kendisini teknolojik zorlukları çözmeye ve bulut yolculuklarına yardımcı olmaya adamıştır.
Nitin Eusebios AWS'de Kıdemli Kurumsal Çözümler Mimarıdır ve Yazılım Mühendisliği, Kurumsal Mimari ve AI/ML konularında deneyimlidir. Üretken yapay zekanın olanaklarını keşfetme konusunda son derece tutkulu. AWS platformunda iyi tasarlanmış uygulamalar oluşturmalarına yardımcı olmak için müşterilerle işbirliği yapıyor ve kendisini teknolojik zorlukları çözmeye ve bulut yolculuklarına yardımcı olmaya adamıştır.
 Madhur Prashant AWS'de üretken yapay zeka alanında çalışıyor. İnsan düşüncesi ile üretken yapay zekanın kesişimi konusunda tutkulu. İlgi alanları üretken yapay zekaya, özellikle de yararlı, zararsız ve en önemlisi müşteriler için ideal çözümler oluşturmaya dayanıyor. İş dışında yoga yapmayı, yürüyüş yapmayı, ikiziyle vakit geçirmeyi ve gitar çalmayı seviyor.
Madhur Prashant AWS'de üretken yapay zeka alanında çalışıyor. İnsan düşüncesi ile üretken yapay zekanın kesişimi konusunda tutkulu. İlgi alanları üretken yapay zekaya, özellikle de yararlı, zararsız ve en önemlisi müşteriler için ideal çözümler oluşturmaya dayanıyor. İş dışında yoga yapmayı, yürüyüş yapmayı, ikiziyle vakit geçirmeyi ve gitar çalmayı seviyor.
 Dewan Choudhury Amazon Web Services'ta Yazılım Geliştirme Mühendisi. Amazon SageMaker'ın algoritmaları ve JumpStart teklifleri üzerinde çalışıyor. AI/ML altyapıları oluşturmanın yanı sıra, ölçeklenebilir dağıtık sistemler oluşturma konusunda da tutkulu.
Dewan Choudhury Amazon Web Services'ta Yazılım Geliştirme Mühendisi. Amazon SageMaker'ın algoritmaları ve JumpStart teklifleri üzerinde çalışıyor. AI/ML altyapıları oluşturmanın yanı sıra, ölçeklenebilir dağıtık sistemler oluşturma konusunda da tutkulu.
 Hao Zhou Amazon SageMaker'da Araştırma Bilimcisidir. Bundan önce Amazon Fraud Detector için dolandırıcılık tespitine yönelik makine öğrenimi yöntemleri geliştirme üzerinde çalışıyordu. Makine öğrenimi, optimizasyon ve üretken yapay zeka tekniklerini gerçek dünyadaki çeşitli sorunlara uygulama konusunda tutkulu. Northwestern Üniversitesi'nden Elektrik Mühendisliği alanında doktora derecesine sahiptir.
Hao Zhou Amazon SageMaker'da Araştırma Bilimcisidir. Bundan önce Amazon Fraud Detector için dolandırıcılık tespitine yönelik makine öğrenimi yöntemleri geliştirme üzerinde çalışıyordu. Makine öğrenimi, optimizasyon ve üretken yapay zeka tekniklerini gerçek dünyadaki çeşitli sorunlara uygulama konusunda tutkulu. Northwestern Üniversitesi'nden Elektrik Mühendisliği alanında doktora derecesine sahiptir.
 Qing Lan AWS'de Yazılım Geliştirme Mühendisidir. Amazon'da yüksek performanslı ML çıkarım çözümleri ve yüksek performanslı günlük kaydı sistemi dahil olmak üzere birçok zorlu ürün üzerinde çalışıyor. Qing'in ekibi, Amazon Advertising'de çok düşük gecikme süresi gerektiren ilk Milyar parametre modelini başarıyla başlattı. Qing, altyapı optimizasyonu ve Derin Öğrenme hızlandırması hakkında derinlemesine bilgi sahibidir.
Qing Lan AWS'de Yazılım Geliştirme Mühendisidir. Amazon'da yüksek performanslı ML çıkarım çözümleri ve yüksek performanslı günlük kaydı sistemi dahil olmak üzere birçok zorlu ürün üzerinde çalışıyor. Qing'in ekibi, Amazon Advertising'de çok düşük gecikme süresi gerektiren ilk Milyar parametre modelini başarıyla başlattı. Qing, altyapı optimizasyonu ve Derin Öğrenme hızlandırması hakkında derinlemesine bilgi sahibidir.
 Ashish Khetan Amazon SageMaker yerleşik algoritmalarına sahip Kıdemli Uygulamalı Bilim Adamıdır ve makine öğrenimi algoritmalarının geliştirilmesine yardımcı olur. Doktora derecesini University of Illinois Urbana-Champaign'den almıştır. Makine öğrenimi ve istatistiksel çıkarım alanlarında aktif bir araştırmacıdır ve NeurIPS, ICML, ICLR, JMLR, ACL ve EMNLP konferanslarında birçok makale yayınlamıştır.
Ashish Khetan Amazon SageMaker yerleşik algoritmalarına sahip Kıdemli Uygulamalı Bilim Adamıdır ve makine öğrenimi algoritmalarının geliştirilmesine yardımcı olur. Doktora derecesini University of Illinois Urbana-Champaign'den almıştır. Makine öğrenimi ve istatistiksel çıkarım alanlarında aktif bir araştırmacıdır ve NeurIPS, ICML, ICLR, JMLR, ACL ve EMNLP konferanslarında birçok makale yayınlamıştır.
 Doktor Li Zhang Amazon SageMaker JumpStart ve Amazon SageMaker yerleşik algoritmaları için Baş Ürün Yöneticisi-Tekniktir; veri bilimcilerin ve makine öğrenimi uygulayıcılarının modellerini eğitmeye ve dağıtmaya başlamalarına yardımcı olan ve Amazon SageMaker ile takviyeli öğrenmeyi kullanan bir hizmettir. IBM Research'te baş araştırma personeli ve usta mucit olarak yaptığı geçmiş çalışmalar, IEEE INFOCOM'da zaman testi makalesi ödülünü kazandı.
Doktor Li Zhang Amazon SageMaker JumpStart ve Amazon SageMaker yerleşik algoritmaları için Baş Ürün Yöneticisi-Tekniktir; veri bilimcilerin ve makine öğrenimi uygulayıcılarının modellerini eğitmeye ve dağıtmaya başlamalarına yardımcı olan ve Amazon SageMaker ile takviyeli öğrenmeyi kullanan bir hizmettir. IBM Research'te baş araştırma personeli ve usta mucit olarak yaptığı geçmiş çalışmalar, IEEE INFOCOM'da zaman testi makalesi ödülünü kazandı.
 Kamran Han, AWS'de AWS Inferentina/Trianium Kıdemli Teknik İş Geliştirme Müdürü. AWS Inferentia ve AWS Trainium'u kullanarak müşterilerin derin öğrenme eğitimi ve çıkarım iş yüklerini dağıtmasına ve optimize etmesine yardımcı olma konusunda on yılı aşkın deneyime sahiptir.
Kamran Han, AWS'de AWS Inferentina/Trianium Kıdemli Teknik İş Geliştirme Müdürü. AWS Inferentia ve AWS Trainium'u kullanarak müşterilerin derin öğrenme eğitimi ve çıkarım iş yüklerini dağıtmasına ve optimize etmesine yardımcı olma konusunda on yılı aşkın deneyime sahiptir.
 Joe Senerchia AWS'de Kıdemli Ürün Yöneticisidir. Derin öğrenme, yapay zeka ve yüksek performanslı bilgi işlem iş yükleri için Amazon EC2 bulut sunucularını tanımlar ve oluşturur.
Joe Senerchia AWS'de Kıdemli Ürün Yöneticisidir. Derin öğrenme, yapay zeka ve yüksek performanslı bilgi işlem iş yükleri için Amazon EC2 bulut sunucularını tanımlar ve oluşturur.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

