Veri entegrasyonu, sağlam veri analitiğinin temelidir. Çeşitli kaynaklardan verilerin keşfini, hazırlanmasını ve kompozisyonunu kapsar. Modern veri ortamında, farklı kaynaklardan gelen verilere erişmek, bunları entegre etmek ve dönüştürmek, veriye dayalı karar verme açısından hayati bir süreçtir. AWS TutkalSunucusuz bir veri entegrasyonu ve ayıklama, dönüştürme ve yükleme (ETL) hizmeti olan , bu süreçte devrim yaratarak süreci daha erişilebilir ve verimli hale getirdi. AWS Glue, karmaşıklıkları ve maliyetleri ortadan kaldırarak kuruluşların veri entegrasyonu görevlerini dakikalar içinde gerçekleştirmesine olanak tanıyarak verimliliği artırır.
Bu blog yazısı şunları araştırıyor: yeni ilan edildi Google BigQuery için yönetilen bağlayıcı ve AWS Glue Studio ile kod yazmadan modern bir ETL işlem hattının nasıl oluşturulacağını gösterir.
AWS Glue'a Genel Bakış
AWS Tutkal analiz, makine öğrenimi (ML) ve uygulama geliştirme için verilerin keşfedilmesini, hazırlanmasını ve birleştirilmesini kolaylaştıran sunucusuz bir veri entegrasyon hizmetidir. AWS Glue, veri entegrasyonu için gereken tüm yetenekleri sağlar; böylece verilerinizi aylar yerine dakikalar içinde analiz etmeye ve kullanmaya başlayabilirsiniz. AWS Glue, veri entegrasyonunu kolaylaştırmak için hem görsel hem de kod tabanlı arayüzler sağlar. Kullanıcılar verileri daha kolay bulabilir ve erişebilirler. AWS Tutkal Veri Kataloğu. Veri mühendisleri ve ETL (çıkarma, dönüştürme ve yükleme) geliştiricileri, ETL iş akışlarını birkaç adımda görsel olarak oluşturabilir, çalıştırabilir ve izleyebilir. AWS Tutkal Stüdyosu. Veri analistleri ve veri bilimcileri kullanabilir AWS Tutkal DataBrew kod yazmadan verileri görsel olarak zenginleştirmek, temizlemek ve normalleştirmek.
Google BigQuery Spark bağlayıcıyla tanışın
AWS Glue, çeşitli veri entegrasyonu kullanım senaryolarının taleplerini karşılamak amacıyla artık Google BigQuery için yerel bir spark bağlayıcısı sunuyor. Müşteriler artık Google BigQuery'deki tabloları okumak ve tablolara yazmak için AWS Glue 4.0 for Spark'ı kullanabilir. Ayrıca, bir tablonun tamamını okuyabilir veya özel bir sorgu çalıştırabilir ve doğrudan ve dolaylı yazma yöntemlerini kullanarak verilerinizi yazabilirsiniz. BigQuery'ye, güvenli bir şekilde saklanan hizmet hesabı kimlik bilgilerini kullanarak bağlanırsınız. AWS Sırları Yöneticisi.
Google BigQuery Spark bağlayıcının avantajları
- Eksiksiz bütünleşme: Yerel bağlayıcı, veri entegrasyonu için sezgisel ve kolaylaştırılmış bir arayüz sunarak öğrenme eğrisini azaltır.
- Maliyet etkinliği: Özel bağlayıcıların oluşturulması ve bakımı pahalı olabilir. AWS Glue tarafından sağlanan yerel bağlayıcı uygun maliyetli bir alternatiftir.
- verim: Daha önce haftalar veya aylar süren veri dönüştürme görevleri artık dakikalar içinde gerçekleştirilerek verimlilik optimize ediliyor.
Çözüme genel bakış
Bu örnekte, yerel Google BigQuery bağlayıcıyla birlikte AWS Glue'yu kullanarak iki ETL işi oluşturacaksınız.
- BigQuery tablosunu sorgulayın ve verileri şuraya kaydedin: Amazon Basit Depolama Hizmeti (Amazon S3) Parke formatında.
- Google BigQuery'de depolanacak toplu bir sonucu dönüştürmek ve oluşturmak için ilk işten çıkarılan verileri kullanın.

Önkoşullar
Bu çözümde kullanılan veri kümesi NCEI/WDS Küresel Önemli Deprem VeritabanıMÖ 5,700'den günümüze kadar 2150'den fazla depremin küresel listesi. Bu herkese açık verileri Google BigQuery projenize kopyalayın veya mevcut veri kümenizi kullanın.
BigQuery bağlantılarını yapılandırma
AWS Glue'dan Google BigQuery'ye bağlanmak için bkz. BigQuery bağlantılarını yapılandırma. Google Cloud Platform kimlik bilgilerinizi bir Secrets Manager sırrında oluşturup saklamanız, ardından bu sırrı bir Google BigQuery AWS Glue bağlantısıyla ilişkilendirmeniz gerekir.
Amazon S3'ü kurun
Amazon S3'teki her nesne bir klasörde depolanır. Verileri Amazon S3'te depolayabilmeniz için önce şunları yapmanız gerekir: S3 paketi oluştur sonuçları saklamak için
Bir S3 paketi oluşturmak için:
- AWS Yönetim Konsolu'nda Amazon S3, seçmek Grup oluştur.
- Global olarak benzersiz bir girin Name kovanız için; Örneğin,
awsglue-demo. - Klinik Kova oluştur.
AWS Glue ETL işi için bir IAM rolü oluşturun
AWS Glue ETL işini oluşturduğunuzda, AWS Kimlik ve Erişim Yönetimi (IAM) işin kullanacağı rol. Rol, Amazon S3 (tüm kaynaklar, hedefler, komut dosyaları, sürücü dosyaları ve geçici dizinler için) ve Secrets Manager dahil olmak üzere iş tarafından kullanılan tüm kaynaklara erişim izni vermelidir.
Talimatlar için bkz. ETL işiniz için bir IAM rolü yapılandırın.
Çözüm yolu
Verileri Google BigQuery'den Amazon S3'e aktarmak için AWS Glue Studio'da görsel bir ETL işi oluşturun
- Açın AWS Tutkal konsol.
- AWS Glue'da şuraya gidin: Görsel ETL altında ETL işleri bölümünü kullanın ve şunu kullanarak yeni bir ETL işi oluşturun: Görsel boş bir tuvalle.
- Bir girin Name örneğin AWS Glue işiniz için,
bq-s3-dataflow. - seç Google BigQuery veri kaynağı olarak.
- Bir girin isim örneğin Google BigQuery kaynak düğümünüz için:
noaa_significant_earthquakes. - Bir seçin Google BigQuery örneğin bağlantı,
bq-connection. - Bir girin Ebeveyn örneğin proje,
bigquery-public-datasources. - seç Tek bir tablo seçin için BigQuery Kaynağı.
- Girin tablo örneğin [veri kümesi].[tablo] biçiminde geçiş yapmak istiyorsunuz,
noaa_significant_earthquakes.earthquakes.
- Bir girin isim örneğin Google BigQuery kaynak düğümünüz için:
- Ardından veri hedefini şu şekilde seçin: Amazon S3.
- Bir girin Name hedef Amazon S3 düğümü için örneğin depremler.
- Çıkış verilerini seçin oluşturulan as Parke.
- seçmek Sıkıştırma tipi as Çabuk.
- Için S3 Hedef Konumu, önkoşullarda oluşturulan paketi girin; örneğin,
s3://<YourBucketName>/noaa_significant_earthquakes/earthquakes/. - değiştirmelisin
<YourBucketName>kovanızın adı ile birlikte.
- Sonra git İş detayları. In IAM Rolü, önkoşullardan IAM rolünü seçin; örneğin,
AWSGlueRole.
- Klinik İndirim.
İşi çalıştırın ve izleyin
- ETL işiniz yapılandırıldıktan sonra işi çalıştırabilirsiniz. AWS Glue, ETL sürecini çalıştırarak Google BigQuery'den veri çıkaracak ve bunu belirttiğiniz S3 konumuna yükleyecektir.
- AWS Glue konsolunda işin ilerleyişini izleyin. Her şeyin sorunsuz çalıştığından emin olmak için günlükleri ve iş çalıştırma geçmişini görebilirsiniz.

Veri doğrulama
- İş başarılı bir şekilde yürütüldükten sonra, S3 klasörünüzdeki verileri beklentilerinize uygun olduğundan emin olmak için doğrulayın. Sonuçları kullanarak görebilirsiniz Amazon S3 Seçimi.

Otomatikleştirin ve planlayın
- Gerekirse ETL sürecini düzenli olarak yürütmek için iş planlamasını ayarlayın. ETL işlerinizi otomatikleştirmek için AWS'yi kullanarak S3 klasörünüzün Google BigQuery'den gelen en son verilerle her zaman güncel olmasını sağlayabilirsiniz.
Verileri Google BigQuery'den Amazon S3'e aktarmak için bir AWS Glue ETL işini başarıyla yapılandırdınız. Daha sonra, bu verileri toplamak ve Google BigQuery'ye aktarmak için ETL işini oluşturursunuz.
AWS Glue Studio Visual ETL ile depremin sıcak noktalarını bulma.
- Açılış AWS Tutkal konsol.
- AWS Glue'da şuraya gidin: Görsel ETL altında ETL işleri bölümünü kullanın ve şunu kullanarak yeni bir ETL işi oluşturun: Görsel boş bir tuvalle.
- AWS Glue işiniz için bir ad girin; örneğin:
s3-bq-dataflow. - Klinik Amazon S3 veri kaynağı olarak.
- Bir girin Name kaynak Amazon S3 düğümü için örneğin depremler.
- seç S3 konumu gibi S3 kaynak türü.
- Önkoşullarda oluşturulan S3 paketini şu şekilde girin: S3 URL'siÖrneğin,
s3://<YourBucketName>/noaa_significant_earthquakes/earthquakes/. - değiştirmelisin
<YourBucketName>kovanızın adı ile birlikte. - seçmek Veri formatı as Parke.
- seç çıkarım şeması.

- Sonra seç Alanları Seç dönüşümü.
- seç
earthquakesas Düğüm ebeveynleri. - Alanları seçin:
id, eq_primary, and country.
- seç
- Sonra seç Toplam dönüşüm.
- Bir girin NameÖrneğin,
Aggregate. - Klinik
Select Fieldsas Düğüm ebeveynleri. - Klinik
eq_primary and countrygibi gruplandırmak sütunlar. - Ekle
idgibi toplam sütun vecountgibi toplama işlevi.
- Bir girin NameÖrneğin,
- Sonra seç Alanı Yeniden Adlandır dönüşümü.
- Kaynak Amazon S3 düğümü için bir ad girin; örneğin,
Rename eq_primary. - Klinik
Aggregateas Düğüm ebeveynleri. - Klinik
eq_primarygibi Geçerli alan adı Ve girinearthquake_magnitudegibi Yeni alan adı.
- Kaynak Amazon S3 düğümü için bir ad girin; örneğin,
- Sonra seç Alanı Yeniden Adlandır dönüşüm
- Kaynak Amazon S3 düğümü için bir ad girin; örneğin,
Rename count(id). - Klinik
Rename eq_primaryas Düğüm ebeveynleri. - Klinik
count(id)gibi Geçerli alan adı Ve girinnumber_of_earthquakesgibi Yeni alan adı.
- Kaynak Amazon S3 düğümü için bir ad girin; örneğin,
- Ardından veri hedefini şu şekilde seçin: Google BigQuery.
- Google BigQuery kaynak düğümünüz için bir ad girin; örneğin:
most_powerful_earthquakes. - Bir seçin Google BigQuery bağlantısıÖrneğin,
bq-connection. - seç üst projeÖrneğin,
bigquery-public-datasources. - adını girin tablo [veri kümesi].[tablo] biçiminde oluşturmak istiyorsunuz, örneğin,
noaa_significant_earthquakes.most_powerful_earthquakes. - Klinik direkt gibi Yazma yöntemi.

- Google BigQuery kaynak düğümünüz için bir ad girin; örneğin:
- Sonra git İş detayları sekmesinde ve içinde IAM Rolü, önkoşullardan IAM rolünü seçin; örneğin,
AWSGlueRole.
- Klinik İndirim.
İşi çalıştırın ve izleyin
- ETL işiniz yapılandırıldıktan sonra işi çalıştırabilirsiniz. AWS Glue, Google BigQuery'den veri çıkarıp belirttiğiniz S3 konumuna yükleyerek ETL sürecini çalıştırır.
- AWS Glue konsolunda işin ilerleyişini izleyin. Her şeyin sorunsuz çalıştığından emin olmak için günlükleri ve iş çalıştırma geçmişini görebilirsiniz.
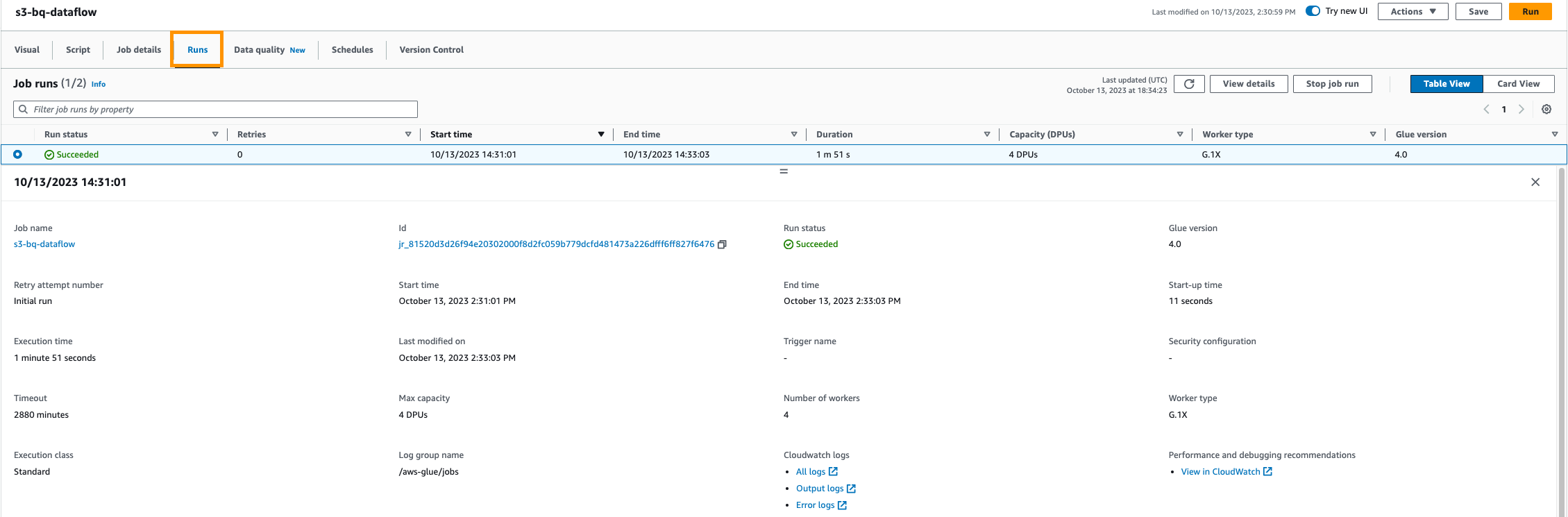
Veri doğrulama
- İş başarıyla çalıştırıldıktan sonra Google BigQuery veri kümenizdeki verileri doğrulayın. Bu ETL işi, en güçlü depremlerin meydana geldiği ülkelerin bir listesini döndürür. Bunları, belirli bir büyüklükteki depremlerin ülkeye göre sayısını sayarak sağlar.

Otomatikleştirin ve planlayın
- ETL sürecini düzenli olarak yürütmek için iş planlamasını ayarlayabilirsiniz. AWS Glue, ETL işlerinizi otomatikleştirmenize olanak tanıyarak S3 klasörünüzün Google BigQuery'den gelen en son verilerle her zaman güncel olmasını sağlar.
Bu kadar! Amazon S3'ten Google BigQuery'ye veri aktarmak için bir AWS Glue ETL işini başarıyla kurdunuz. Bu entegrasyonu, bu iki platform arasında veri çıkarma, dönüştürme ve yükleme sürecini otomatikleştirmek için kullanabilirsiniz; böylece verilerinizi analiz ve diğer uygulamalar için hazır hale getirebilirsiniz.
Temizlemek
Ücretlendirmeyi önlemek için aşağıdaki adımları tamamlayarak bu blog gönderisinde kullanılan kaynakları AWS hesabınızdan temizleyin:
- AWS Glue konsolunda seçin Görsel ETL Gezinti bölmesinde.
- İş listesinden işi seçin
bq-s3-data-flowve sil. - İş listesinden işi seçin
s3-bq-data-flowve sil. - AWS Glue konsolunda seçin Bağlantılar altındaki gezinme bölmesinde Veri Kataloğu.
- Seçin BiqQuery bağlantısı yarattınız ve sildiniz.
- Secrets Manager konsolunda oluşturduğunuz sırrı seçin ve silin.
- IAM konsolunda, Roller Gezinti bölmesinde AWS Glue ETL işi için oluşturduğunuz rolü seçip silin.
- Amazon S3 konsolunda oluşturduğunuz S3 klasörünü arayın, boş nesneleri silmek için, ardından kovayı silin.
- Google BigQuery kaynaklarını içeren projeyi silerek Google hesabınızdaki kaynakları temizleyin. Belgeleri takip ederek Google kaynaklarını temizleyin.
Sonuç
AWS Glue'nun Google BigQuery ile entegrasyonu analiz hattını basitleştirir, analiz süresini kısaltır ve veriye dayalı karar almayı kolaylaştırır. Kuruluşlara veri entegrasyonunu ve analitiğini kolaylaştırma gücü verir. AWS Glue'un sunucusuz yapısı, altyapı yönetimine gerek olmadığı anlamına gelir ve yalnızca işleriniz çalışırken tüketilen kaynaklar için ödeme yaparsınız. Kuruluşlar karar vermede verilere giderek daha fazla güvenirken, bu yerel spark bağlayıcısı, veri analitiği ihtiyaçlarını hızlı bir şekilde karşılamak için verimli, uygun maliyetli ve çevik bir çözüm sağlar.
AWS Glue'da Google BigQuery'deki tablolardan nasıl okunacağını ve tablolara nasıl yazılacağını öğrenmek istiyorsanız adım adım göz atın Video öğretici. Bu eğitimde, bağlantının kurulmasından veri aktarım akışının çalıştırılmasına kadar tüm süreci adım adım anlatacağız. AWS Glue hakkında daha fazla bilgi için şu adresi ziyaret edin: AWS Tutkal.
Ek
Bu örneği AWS Glue konsolu yerine kod kullanarak uygulamak istiyorsanız aşağıdaki kod parçacıklarını kullanın.
Google BigQuery'den veri okuma ve Amazon S3'e veri yazma
Amazon S3'ten veri okuma, toplama ve Google BigQuery'ye yazma
yazarlar hakkında
 Kartikay Khator Amazon Web Services'te (AWS) Küresel Yaşam Bilimleri alanında Çözüm Mimarıdır. AWS Analytics hizmetlerine odaklanarak müşterilerin ihtiyaçlarını karşılamak için yenilikçi ve ölçeklenebilir çözümler oluşturma konusunda tutkuludur. Teknoloji dünyasının ötesinde hevesli bir koşucudur ve yürüyüş yapmaktan hoşlanır.
Kartikay Khator Amazon Web Services'te (AWS) Küresel Yaşam Bilimleri alanında Çözüm Mimarıdır. AWS Analytics hizmetlerine odaklanarak müşterilerin ihtiyaçlarını karşılamak için yenilikçi ve ölçeklenebilir çözümler oluşturma konusunda tutkuludur. Teknoloji dünyasının ötesinde hevesli bir koşucudur ve yürüyüş yapmaktan hoşlanır.
 Kamen Sharlandjiev Kıdemli Büyük Veri ve ETL Çözümleri Mimarı ve Amazon AppFlow uzmanıdır. Karmaşık veri entegrasyonu zorluklarıyla karşı karşıya kalan müşterilerin hayatını kolaylaştırma misyonundadır. Onun gizli silahı mı? İşin minimum çabayla ve kodlama gerektirmeden yapılmasını sağlayan, tam olarak yönetilen, az kodlu AWS hizmetleri.
Kamen Sharlandjiev Kıdemli Büyük Veri ve ETL Çözümleri Mimarı ve Amazon AppFlow uzmanıdır. Karmaşık veri entegrasyonu zorluklarıyla karşı karşıya kalan müşterilerin hayatını kolaylaştırma misyonundadır. Onun gizli silahı mı? İşin minimum çabayla ve kodlama gerektirmeden yapılmasını sağlayan, tam olarak yönetilen, az kodlu AWS hizmetleri.
 Anshul Sharma AWS Glue Team'de Yazılım Geliştirme Mühendisidir. Glue müşterisine herhangi bir Veri kaynağını (Veri ambarı, Veri gölleri, NoSQL vb.) Glue ETL İşlerine bağlamanın yerel yolunu sağlayan bağlantı sözleşmesini yürütüyor. Teknoloji dünyasının ötesinde bir kriket ve futbol aşığıdır.
Anshul Sharma AWS Glue Team'de Yazılım Geliştirme Mühendisidir. Glue müşterisine herhangi bir Veri kaynağını (Veri ambarı, Veri gölleri, NoSQL vb.) Glue ETL İşlerine bağlamanın yerel yolunu sağlayan bağlantı sözleşmesini yürütüyor. Teknoloji dünyasının ötesinde bir kriket ve futbol aşığıdır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/unlock-scalable-analytics-with-aws-glue-and-google-bigquery/

