Büyük dil modelleri (LLM'ler), sürekli olarak yeni kullanım senaryolarının keşfedilmesiyle giderek daha popüler hale geliyor. Genel olarak, hızlı mühendisliği kodunuza dahil ederek LLM'ler tarafından desteklenen uygulamalar oluşturabilirsiniz. Ancak mevcut bir LLM'nin başlatılmasının yetersiz kaldığı durumlar vardır. Modelin ince ayarının yardımcı olabileceği yer burasıdır. İstem mühendisliği, girdi istemleri hazırlayarak modelin çıktısını yönlendirmekle ilgilidir; oysa ince ayar, modeli belirli görevlere veya alanlara daha uygun hale getirmek için özel veri kümeleri üzerinde eğitmekle ilgilidir.
Bir modele ince ayar yapmadan önce göreve özel bir veri kümesi bulmanız gerekir. Yaygın olarak kullanılan bir veri kümesi, Ortak Tarama veri kümesi. Common Crawl külliyatı, 2008'den bu yana düzenli olarak toplanan petabaytlarca veriyi içerir ve ham web sayfası verilerini, meta veri özetlerini ve metin alıntılarını içerir. Hangi veri kümesinin kullanılması gerektiğinin belirlenmesine ek olarak, verilerin ince ayarın özel ihtiyacına göre temizlenmesi ve işlenmesi de gereklidir.
Yakın zamanda, en son Common Crawl veri kümesinin bir alt kümesini önceden işlemek ve ardından LLM'sine temizlenmiş verilerle ince ayar yapmak isteyen bir müşteriyle çalıştık. Müşteri bunu AWS'de en uygun maliyetli şekilde nasıl başarabileceğini arıyordu. Gereksinimleri tartıştıktan sonra şunu kullanmanızı öneririz: Amazon EMR Sunucusuz veri ön işleme platformu olarak. EMR Sunucusuz, büyük ölçekli veri işlemeye çok uygundur ve altyapı bakımı ihtiyacını ortadan kaldırır. Maliyet açısından yalnızca her iş için kullanılan kaynaklara ve süreye göre ücretlendirilir. Müşteri, EMR Serverless'ı kullanarak bir hafta içinde yüzlerce TB veriyi ön işlemeyi başardı. Verileri ön işleme tabi tuttuktan sonra kullandılar. Amazon Adaçayı Yapıcı LLM'ye ince ayar yapmak için.
Bu yazıda size müşterinin kullanım durumu ve kullanılan mimari konusunda yol göstereceğiz.
Aşağıdaki bölümlerde öncelikle Ortak Tarama veri kümesini ve ihtiyaç duyduğumuz verileri nasıl keşfedip filtreleyeceğimizi tanıtıyoruz. Amazon Atina yalnızca taradığı veri boyutuna göre ücret alır ve uygun maliyetli olarak verileri hızlı bir şekilde keşfetmek ve filtrelemek için kullanılır. EMR Sunucusuz, Spark veri işleme için uygun maliyetli ve bakım gerektirmeyen bir seçenek sunar ve filtrelenen verileri işlemek için kullanılır. Daha sonra kullanıyoruz Amazon SageMaker Hızlı Başlangıç ince ayar yapmak için Lama 2 modeli önceden işlenmiş veri kümesiyle. SageMaker JumpStart, en yaygın kullanım durumları için yalnızca birkaç tıklamayla devreye alınabilecek bir dizi çözüm sunar. Llama 2 gibi bir LLM'ye ince ayar yapmak için herhangi bir kod yazmanıza gerek yok. Son olarak, ince ayarlı modeli kullanarak dağıtıyoruz. Amazon Adaçayı Yapıcı ve aynı soru için orijinal ve ince ayarlı Llama 2 modelleri arasındaki metin çıktısı farklılıklarını karşılaştırın.
Aşağıdaki diyagram bu çözümün mimarisini göstermektedir.
Çözüm ayrıntılarına derinlemesine dalmadan önce aşağıdaki önkoşul adımlarını tamamlayın:
Common Crawl, 50 milyardan fazla web sayfasının taranmasıyla elde edilen açık bir veri kümesidir. 2008'den başlayarak petabayt düzeyine ulaşan çok sayıda dilde devasa miktarda yapılandırılmamış veri içeriyor. Sürekli olarak güncellenmektedir.
GPT-3 eğitiminde, aşağıdaki şemada gösterildiği gibi Ortak Tarama veri kümesi, eğitim verilerinin %60'ını oluşturur (kaynak: Dil Modelleri Birkaç Atış Öğrencisidir).
Bahsetmeye değer bir diğer önemli veri seti ise C4 veri kümesi. Colossal Clean Crawled Corpus'un kısaltması olan C4, Common Crawl veri kümesinin sonradan işlenmesinden elde edilen bir veri kümesidir. Meta'nın LLaMA makalesinde, Common Crawl'ın %67'sini (3.3 TB veri kullanarak) ve C4'ün %15'ini (783 GB veri kullanarak) oluşturduğu, kullanılan veri kümelerinin ana hatlarını çizdiler. Makale, model performansını artırmak için farklı şekilde önceden işlenmiş verileri birleştirmenin önemini vurgulamaktadır. Orijinal C4 verilerinin Common Crawl'ın parçası olmasına rağmen Meta, bu verilerin yeniden işlenmiş sürümünü tercih etti.
Bu bölümde Ortak Tarama veri kümesiyle etkileşim kurmanın, filtrelemenin ve işlemenin yaygın yollarını ele alıyoruz.
Common Crawl ham veri kümesi üç tür veri dosyası içerir: ham web sayfası verileri (WARC), meta veriler (WAT) ve metin çıkarma (WET).
2013'ten sonra toplanan veriler WARC formatında depolanır ve ilgili meta verileri (WAT) ve metin çıkarma verilerini (WET) içerir. Veri kümesi Amazon S3'te bulunur, aylık olarak güncellenir ve şu adresten doğrudan erişilebilir: AWS Pazar Yeri.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzOrtak Tarama veri kümesi ayrıca verileri filtrelemek için cc-index-table adı verilen bir dizin tablosu da sağlar.
Cc-index-table, mevcut verilerin bir indeksidir ve WARC dosyalarının tablo tabanlı bir indeksini sağlar. Hangi WARC dosyasının belirli bir URL'ye karşılık geldiği gibi bilgilerin kolayca aranmasına olanak tanır.
Örneğin, cc-index verilerini aşağıdaki kodla eşlemek için bir Athena tablosu oluşturabilirsiniz:
Önceki SQL ifadeleri, bir Athena tablosunun nasıl oluşturulacağını, bölümlerin nasıl ekleneceğini ve bir sorgunun nasıl çalıştırılacağını gösterir.
Ortak Tarama veri kümesindeki verileri filtreleme
Create table SQL deyiminden görebileceğiniz gibi, verileri filtrelemeye yardımcı olabilecek birkaç alan vardır. Örneğin, belirli bir dönemdeki Çince belgelerin sayısını almak istiyorsanız SQL ifadesi aşağıdaki gibi olabilir:
Daha fazla işlem yapmak istiyorsanız sonuçları başka bir S3 klasörüne kaydedebilirsiniz.
Filtrelenen verileri analiz edin
The Ortak Tarama GitHub deposu ham verilerin işlenmesi için çeşitli PySpark örnekleri sağlar.
Koşmanın bir örneğine bakalım server_count.py (Common Crawl GitHub deposu tarafından sağlanan örnek komut dosyası) s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Öncelikle EMR Spark gibi bir Spark ortamına ihtiyacınız var. Örneğin, EC2 kümesinde bir Amazon EMR'yi şurada başlatabilirsiniz: us-east-1 (çünkü veri kümesi us-east-1). EC2 kümesinde EMR kullanmak, işleri üretim ortamına göndermeden önce testler gerçekleştirmenize yardımcı olabilir.
EC2 kümesinde EMR başlattıktan sonra kümenin birincil düğümünde SSH oturumu açmanız gerekir. Ardından Python ortamını paketleyin ve betiği gönderin (bkz. Conda belgeleri Miniconda'yı yüklemek için):
warc.path dosyasındaki tüm referansların işlenmesi zaman alabilir. Demo amacıyla aşağıdaki stratejilerle işlem süresini artırabilirsiniz:
- dosyasını indirin
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzyerel makinenize kopyalayın, sıkıştırın ve ardından HDFS veya Amazon S3'e yükleyin. Bunun nedeni .gzip dosyasının bölünebilir olmamasıdır. Bu dosyayı paralel olarak işlemek için sıkıştırmayı açmanız gerekir. - Değiştirmek
warc.pathDosyanın satırlarının çoğunu silin ve işin çok daha hızlı çalışmasını sağlamak için yalnızca iki satır bırakın.
İş tamamlandıktan sonra sonucu görebilirsiniz. s3://xxxx-common-crawl/output/, Parke formatında.
Özelleştirilmiş sahip olma mantığını uygulayın
Ortak Tarama GitHub deposu, WARC dosyalarını işlemek için ortak bir yaklaşım sağlar. Genel olarak uzatabilirsiniz CCSparkJob tek bir yöntemi geçersiz kılmak için (process_record), ki bu birçok durum için yeterlidir.
Son çıkan filmlerin IMDB incelemelerine ulaşmak için bir örneğe bakalım. Öncelikle IMDB sitesindeki dosyaları filtrelemeniz gerekir:
Daha sonra IMDB inceleme verilerini içeren WARC dosya listelerini alabilir ve WARC dosya adlarını bir metin dosyasına liste olarak kaydedebilirsiniz.
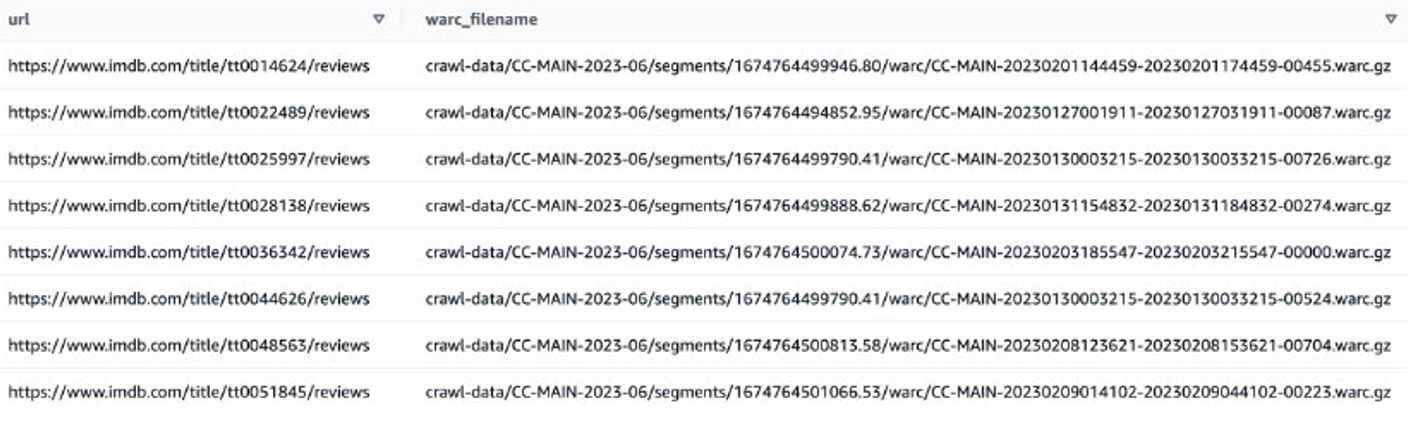
Alternatif olarak EMR Spark'ı kullanarak WARC dosya listesini alabilir ve bunu Amazon S3'te saklayabilirsiniz. Örneğin:
Çıktı dosyası şuna benzer görünmelidir: s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Bir sonraki adım, bu WARC dosyalarından kullanıcı yorumlarını çıkarmaktır. Uzatabilirsiniz CCSparkJob geçersiz kılmak için process_record() yöntem:
Önceki komut dosyasını, sonraki adımlarda kullanacağınız imdb_extractor.py olarak kaydedebilirsiniz. Verileri ve komut dosyalarını hazırladıktan sonra, filtrelenen verileri işlemek için EMR Serverless'ı kullanabilirsiniz.
EMR Sunucusuz
EMR Sunucusuz, kümeleri veya sunucuları yapılandırmaya, yönetmeye ve ölçeklendirmeye gerek kalmadan Apache Spark ve Hive gibi açık kaynaklı çerçeveleri kullanarak büyük veri analizi uygulamalarını çalıştırmaya yönelik sunucusuz bir dağıtım seçeneğidir.
EMR Serverless ile, değişen veri hacimlerini ve işleme gereksinimlerini karşılamak için kaynakları saniyeler içinde yeniden boyutlandıran otomatik ölçeklendirmeyle analiz iş yüklerini istediğiniz ölçekte çalıştırabilirsiniz. EMR Serverless, uygulamanız için doğru miktarda kapasite sağlamak üzere kaynakları otomatik olarak yukarı ve aşağı ölçeklendirir ve siz yalnızca kullandığınız kadar ödersiniz.
Ortak Tarama veri kümesinin işlenmesi genellikle tek seferlik bir işlem görevidir ve bu da onu EMR Sunucusuz iş yükleri için uygun kılar.
EMR Sunucusuz uygulama oluşturma
EMR Studio konsolunda bir EMR Sunucusuz uygulaması oluşturabilirsiniz. Aşağıdaki adımları tamamlayın:
- EMR Studio konsolunda, Uygulamalar altında Serverless Gezinti bölmesinde.
- Klinik Uygulama oluştur.

- Uygulama için bir ad girin ve bir Amazon EMR sürümü seçin.
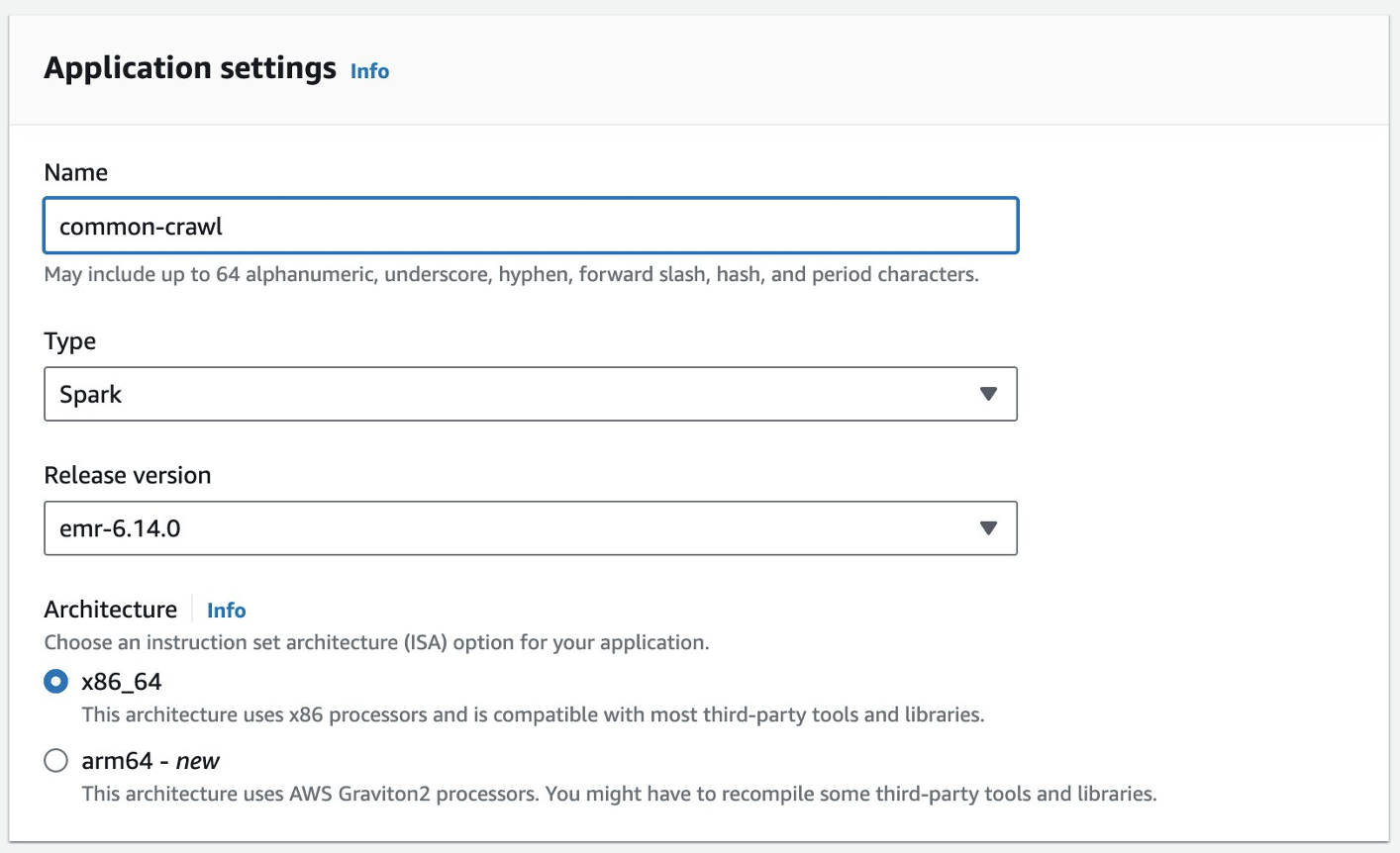
- VPC kaynaklarına erişim gerekiyorsa özelleştirilmiş bir ağ ayarı ekleyin.

- Klinik Uygulama oluştur.
Spark sunucusuz ortamınız daha sonra hazır olacaktır.
EMR Spark Serverless'a bir iş göndermeden önce yine de bir yürütme rolü oluşturmanız gerekir. Bakınız Amazon EMR Sunucusuz kullanmaya başlarken daha fazla ayrıntı için.
Ortak Tarama verilerini EMR Serverless ile işleyin
EMR Spark Serverless uygulamanız hazır olduktan sonra verileri işlemek için aşağıdaki adımları tamamlayın:
- Bir Conda ortamı hazırlayın ve bunu EMR Spark Serverless'ta ortam olarak kullanılacak Amazon S3'e yükleyin.
- Çalıştırılacak komut dosyalarını bir S3 klasörüne yükleyin. Aşağıdaki örnekte iki komut dosyası vardır:
- imbd_extractor.py – Veri kümesinden içerik çıkarmak için özelleştirilmiş mantık. İçeriği bu yazının başlarında bulabilirsiniz.
- cc-pyspark/sparkcc.py – Örnek PySpark çerçevesi Ortak Tarama GitHub deposu, dahil edilmesi gereken bir şey.
- PySpark işini EMR Serverless Spark'a gönderin. Bu örneği ortamınızda çalıştırmak için aşağıdaki parametreleri tanımlayın:
- Uygulama Kimliği – EMR Sunucusuz uygulamanızın uygulama kimliği.
- yürütme rolü-arn – EMR Sunucusuz yürütme rolünüz. Bunu oluşturmak için bkz. İş çalışma zamanı rolü oluşturma.
- WARC dosya konumu – WARC dosyalarınızın konumu.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtBu yazının başlarında edindiğiniz filtrelenmiş WARC dosya listesini içerir. - spark.sql.warehouse.dir – Varsayılan depo konumu (S3 dizininizi kullanın).
- spark.archives – Hazırlanan Conda ortamının S3 konumu.
- spark.submit.pyDosyaları – Hazırlanan PySpark scripti sparkcc.py.
Aşağıdaki koda bakın:
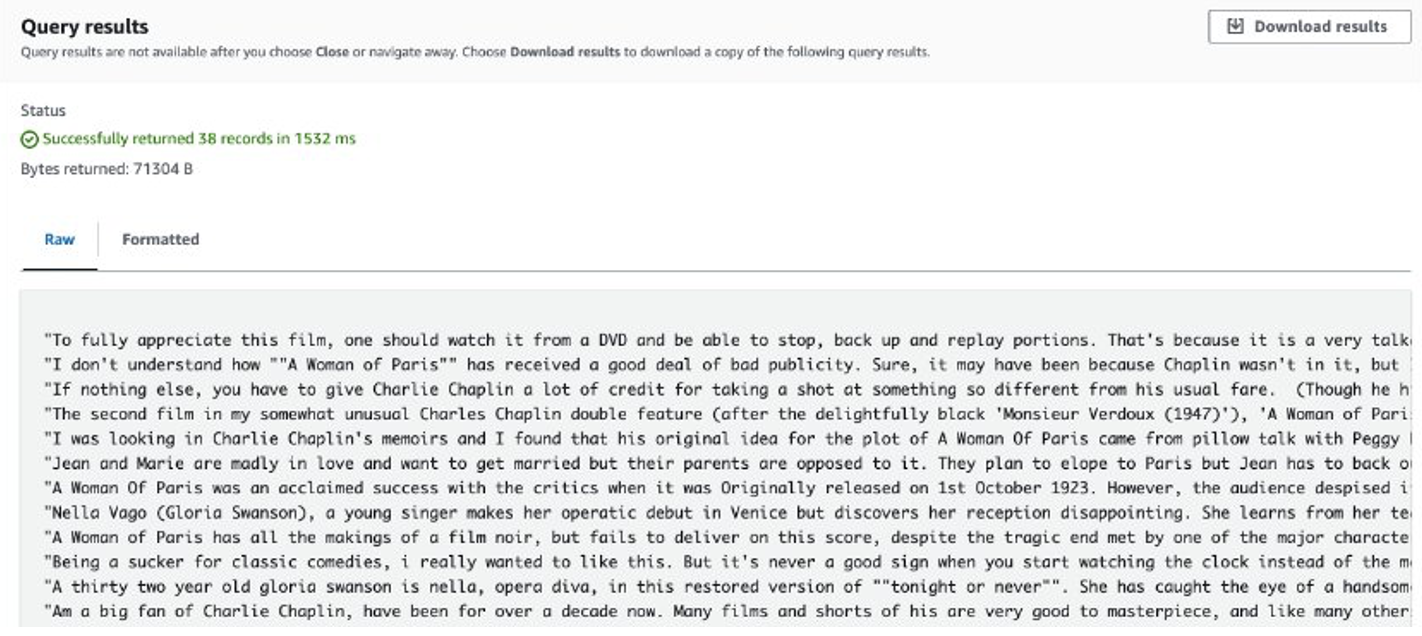
İş tamamlandıktan sonra çıkarılan incelemeler Amazon S3'te depolanır. İçerikleri kontrol etmek için aşağıdaki ekran görüntüsünde gösterildiği gibi Amazon S3 Select'i kullanabilirsiniz.
Hususlar
Özelleştirilmiş kodla büyük miktarda veriyle uğraşırken dikkate alınması gereken noktalar şunlardır:
- Bazı üçüncü taraf Python kitaplıkları Conda'da mevcut olmayabilir. Bu gibi durumlarda PySpark çalışma zamanı ortamını oluşturmak için Python sanal ortamına geçebilirsiniz.
- İşlenecek çok büyük miktarda veri varsa bunu paralelleştirmek için birden fazla EMR Serverless Spark uygulaması oluşturup kullanmayı deneyin. Her uygulama, dosya listelerinin bir alt kümesiyle ilgilenir.
- Ortak Tarama verilerini filtrelerken veya işlerken Amazon S3'te yavaşlama sorunuyla karşılaşabilirsiniz. Bunun nedeni, verileri depolayan S3 kümesinin herkese açık olması ve diğer kullanıcıların da verilere aynı anda erişebilmesidir. Bu sorunu azaltmak için bir yeniden deneme mekanizması ekleyebilir veya Common Crawl S3 klasöründeki belirli verileri kendi grubunuzla senkronize edebilirsiniz.
SageMaker ile Llama 2'ye ince ayar yapın
Veriler hazırlandıktan sonra onunla bir Llama 2 modeline ince ayar yapabilirsiniz. Bunu SageMaker JumpStart'ı kullanarak herhangi bir kod yazmadan yapabilirsiniz. Daha fazla bilgi için bkz. Amazon SageMaker JumpStart'ta metin oluşturmak için Llama 2'ye ince ayar yapın.
Bu senaryoda, etki alanı uyarlama ince ayarı gerçekleştirirsiniz. Bu veri kümesinde girdi CSV, JSON veya TXT dosyasından oluşur. Tüm inceleme verilerini bir TXT dosyasına koymanız gerekir. Bunu yapmak için EMR Spark Serverless'a basit bir Spark işi gönderebilirsiniz. Aşağıdaki örnek kod pasajına bakın:
Eğitim verilerini hazırladıktan sonra veri konumunu girin. Eğitim veri seti, Daha sonra seçmek Tren.
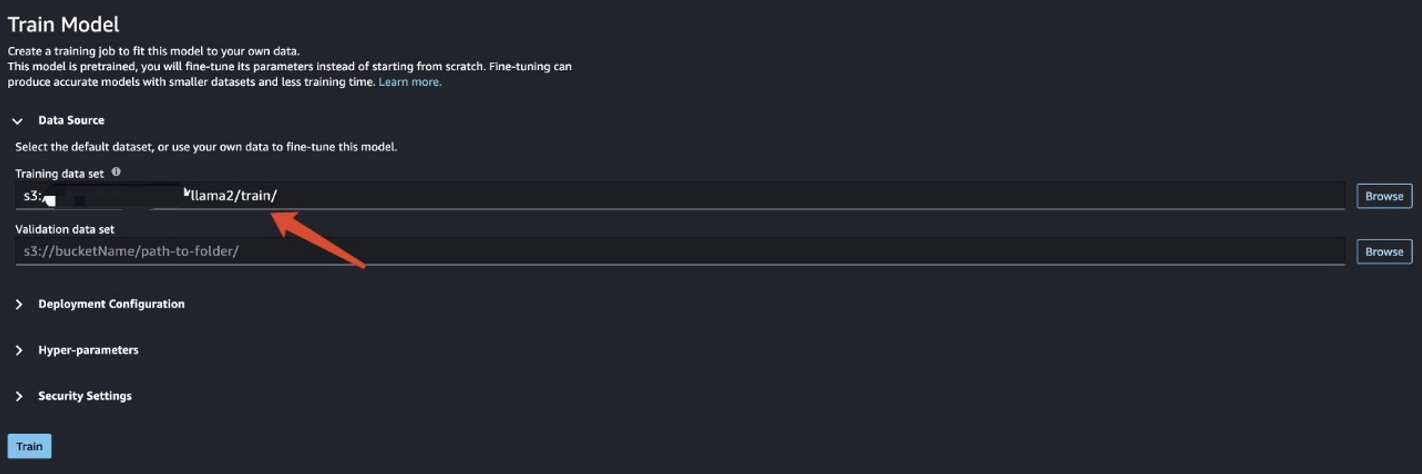
Eğitim işi durumunu takip edebilirsiniz.
İnce ayarlı modeli değerlendirin
Eğitim tamamlandıktan sonra seçin Sürüş İnce ayarlı modelinizi dağıtmak için SageMaker JumpStart'ta.

Model başarıyla dağıtıldıktan sonra şunu seçin: Not Defterini Açsizi Python kodunuzu çalıştırabileceğiniz hazırlanmış bir Jupyter not defterine yönlendirir.

Dizüstü bilgisayar için Image Data Science 2.0 ve Python 3 çekirdeğini kullanabilirsiniz.

Daha sonra bu defterdeki ince ayarlı modeli ve orijinal modeli değerlendirebilirsiniz.
Aşağıda aynı soru için orijinal model ve ince ayarlı model tarafından döndürülen iki yanıt bulunmaktadır.
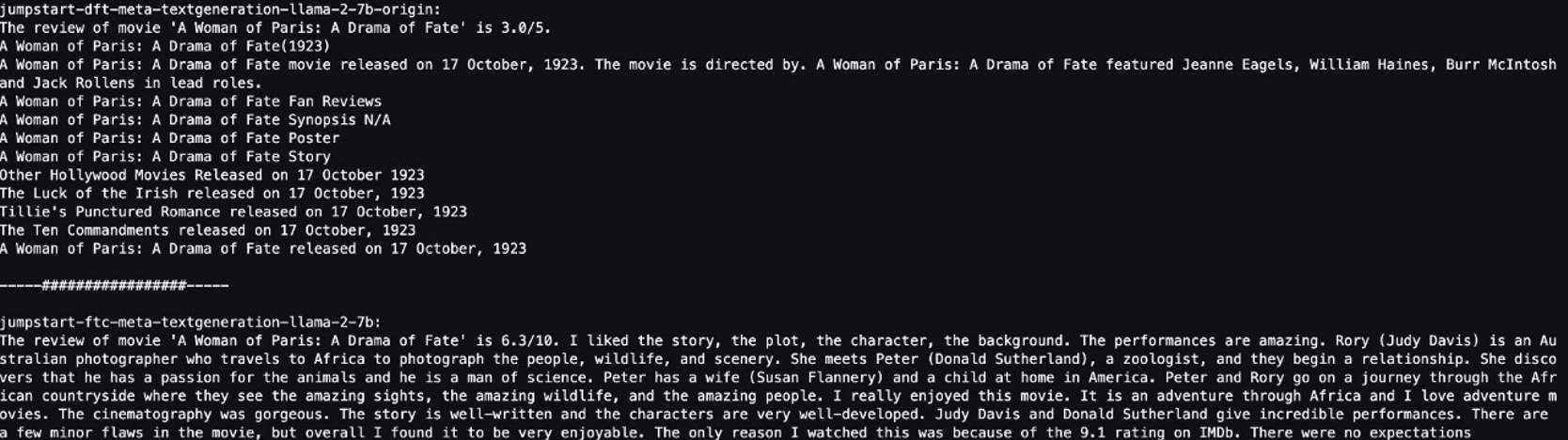
Her iki modele de aynı cümleyi verdik: “'A Woman of Paris: A Drama of Fate' filminin eleştirisi” ve cümleyi tamamlamalarını sağladık.
Orijinal model anlamsız cümleler çıkarır:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Buna karşılık, ince ayarlı modelin çıktıları daha çok bir film incelemesine benzer:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Açıkçası, ince ayarlı model bu özel senaryoda daha iyi performans gösteriyor.
Temizlemek
Bu alıştırmayı tamamladıktan sonra kaynaklarınızı temizlemek için aşağıdaki adımları tamamlayın:
- S3 klasörünü silin temizlenmiş veri kümesini saklayan.
- EMR Sunucusuz ortamını durdurun.
- SageMaker uç noktasını silin LLM modelini barındıran.
- SageMaker alanını silin not defterlerinizi çalıştırır.
Oluşturduğunuz uygulama varsayılan olarak 15 dakika işlem yapılmadığında otomatik olarak durmalıdır.
Genel olarak Athena ortamını temizlemenize gerek yoktur çünkü kullanmadığınız zamanlarda herhangi bir ücret alınmaz.
Sonuç
Bu yazıda Common Crawl veri kümesini ve LLM ince ayarı için verileri işlemek amacıyla EMR Serverless'ın nasıl kullanılacağını tanıttık. Daha sonra LLM'ye ince ayar yapmak ve herhangi bir kod olmadan dağıtmak için SageMaker JumpStart'ın nasıl kullanılacağını gösterdik. EMR Serverless'ın daha fazla kullanım örneği için bkz. Amazon EMR Sunucusuz. Amazon SageMaker JumpStart'ta modelleri barındırma ve ince ayar yapma hakkında daha fazla bilgi için bkz. Sagemaker JumpStart belgeleri.
Yazarlar Hakkında
 Shijian Tang Amazon Web Services'te Analitik Uzmanı Çözüm Mimarıdır.
Shijian Tang Amazon Web Services'te Analitik Uzmanı Çözüm Mimarıdır.
 Matthew Liem Amazon Web Services'te Kıdemli Çözüm Mimarisi Yöneticisidir.
Matthew Liem Amazon Web Services'te Kıdemli Çözüm Mimarisi Yöneticisidir.
 Dalei Xu Amazon Web Services'te Analitik Uzmanı Çözüm Mimarıdır.
Dalei Xu Amazon Web Services'te Analitik Uzmanı Çözüm Mimarıdır.
 Yuanjun Xiao Amazon Web Services'te Kıdemli Çözüm Mimarıdır.
Yuanjun Xiao Amazon Web Services'te Kıdemli Çözüm Mimarıdır.
- SEO Destekli İçerik ve Halkla İlişkiler Dağıtımı. Bugün Gücünüzü Artırın.
- PlatoData.Network Dikey Üretken Yapay Zeka. Kendine güç ver. Buradan Erişin.
- PlatoAiStream. Web3 Zekası. Bilgi Genişletildi. Buradan Erişin.
- PlatoESG. karbon, temiz teknoloji, Enerji, Çevre, Güneş, Atık Yönetimi. Buradan Erişin.
- PlatoSağlık. Biyoteknoloji ve Klinik Araştırmalar Zekası. Buradan Erişin.
- Kaynak: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/

