Idag är vi glada över att kunna tillkännage möjligheten att finjustera Code Llama-modeller av Meta med Amazon SageMaker JumpStart. Code Llama-familjen av stora språkmodeller (LLM) är en samling förtränade och finjusterade kodgenereringsmodeller som sträcker sig i skala från 7 miljarder till 70 miljarder parametrar. Finjusterade Code Llama-modeller ger bättre noggrannhet och förklaringsmöjligheter jämfört med basmodellerna Code Llama, vilket framgår av dess testning mot HumanEval och MBPP-datauppsättningar. Du kan finjustera och distribuera Code Llama-modeller med SageMaker JumpStart med hjälp av Amazon SageMaker Studio UI med några få klick eller med SageMaker Python SDK. Finjustering av Llama-modeller baseras på skripten som tillhandahålls i lama-recept GitHub repo från Meta med PyTorch FSDP, PEFT/LoRA och Int8 kvantiseringstekniker.
I det här inlägget går vi igenom hur man finjusterar Code Llama-förtränade modeller via SageMaker JumpStart genom en gränssnitts- och SDK-upplevelse med ett klick tillgänglig i följande GitHub repository.
Vad är SageMaker JumpStart
Med SageMaker JumpStart kan utövare av maskininlärning (ML) välja från ett brett urval av allmänt tillgängliga grundmodeller. ML-utövare kan distribuera grundmodeller till dedikerade Amazon SageMaker instanser från en nätverksisolerad miljö och anpassa modeller med SageMaker för modellträning och implementering.
Vad är Code Llama
Code Llama är en kodspecialiserad version av Lama 2 som skapades genom att vidareutbilda Llama 2 i dess kodspecifika datauppsättningar och sampla mer data från samma datauppsättning under längre tid. Code Llama har förbättrade kodningsmöjligheter. Den kan generera kod och naturligt språk om kod, från både kod och naturliga språkprompter (till exempel "Skriv en funktion till mig som matar ut Fibonacci-sekvensen"). Du kan också använda den för kodkomplettering och felsökning. Det stöder många av de mest populära programmeringsspråken som används idag, inklusive Python, C++, Java, PHP, Typescript (JavaScript), C#, Bash och mer.
Varför finjustera Code Llama-modeller
Meta publicerade Code Llama prestanda riktmärken på HumanEval och MBPP för vanliga kodningsspråk som Python, Java och JavaScript. Prestandan för Code Llama Python-modeller på HumanEval visade varierande prestanda över olika kodningsspråk och uppgifter, från 38 % på 7B Python-modellen till 57 % på 70B Python-modeller. Dessutom har finjusterade Code Llama-modeller på SQL-programmeringsspråk visat bättre resultat, vilket framgår av riktmärken för SQL-utvärdering. Dessa publicerade riktmärken belyser de potentiella fördelarna med att finjustera Code Llama-modeller, vilket möjliggör bättre prestanda, anpassning och anpassning till specifika kodningsdomäner och uppgifter.
Finjustering utan kod via SageMaker Studio UI
För att börja finjustera dina Llama-modeller med SageMaker Studio, utför följande steg:
- Välj på SageMaker Studio-konsolen Försprång i navigeringsfönstret.
Du hittar listor över över 350 modeller, allt från öppen källkod och proprietära modeller.
- Sök efter Code Llama-modeller.

Om du inte ser Code Llama-modeller kan du uppdatera din SageMaker Studio-version genom att stänga av och starta om. För mer information om versionsuppdateringar, se Stäng av och uppdatera Studio-appar. Du kan även hitta andra modellvarianter genom att välja Utforska alla kodgenereringsmodeller eller söker efter Code Llama i sökrutan.
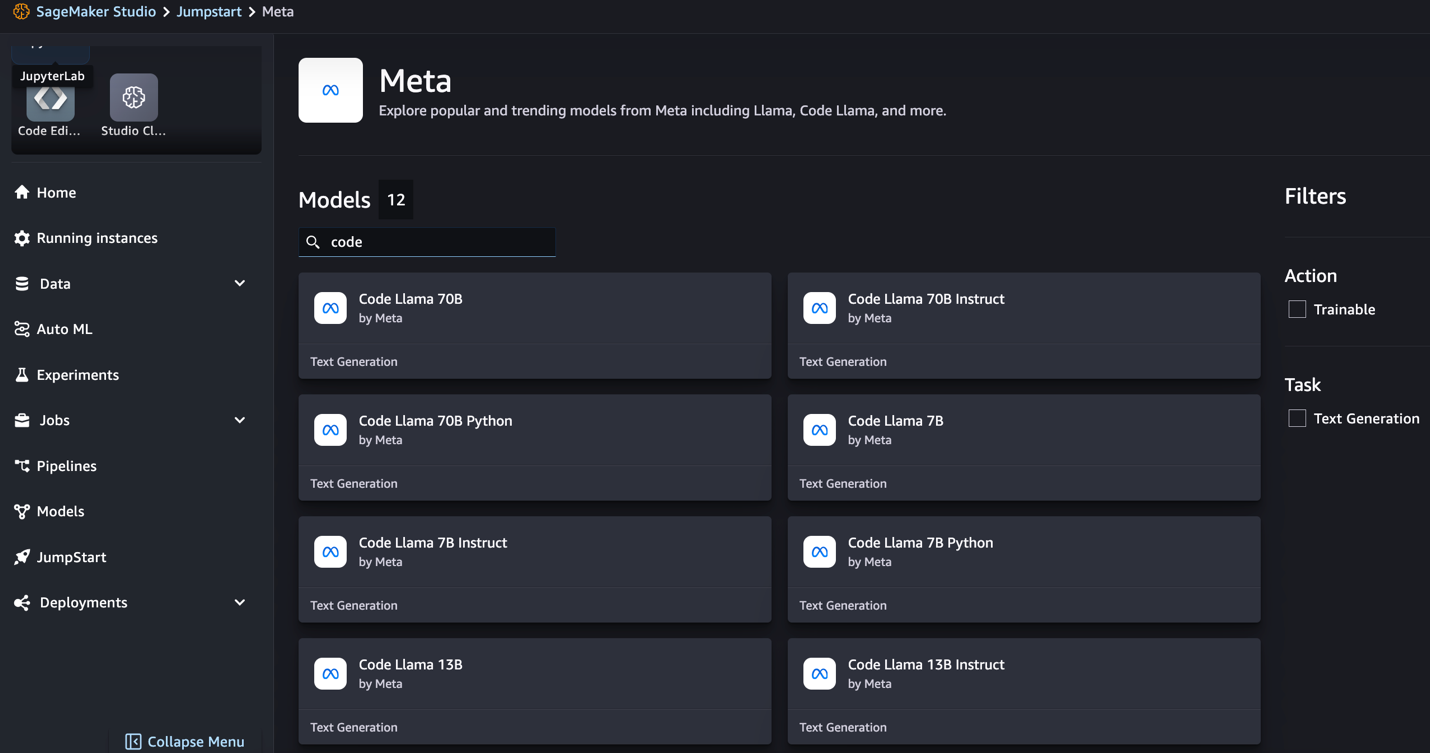
SageMaker JumpStart stöder för närvarande instruktionsfinjustering för Code Llama-modeller. Följande skärmdump visar finjusteringssidan för Code Llama 2 70B-modellen.
- För Utbildningsdataplats, kan du peka på Amazon enkel lagringstjänst (Amazon S3) hink som innehåller tränings- och valideringsdataset för finjustering.
- Ställ in din distributionskonfiguration, hyperparametrar och säkerhetsinställningar för finjustering.
- Välja Tåg för att påbörja finjusteringsjobbet på en SageMaker ML-instans.
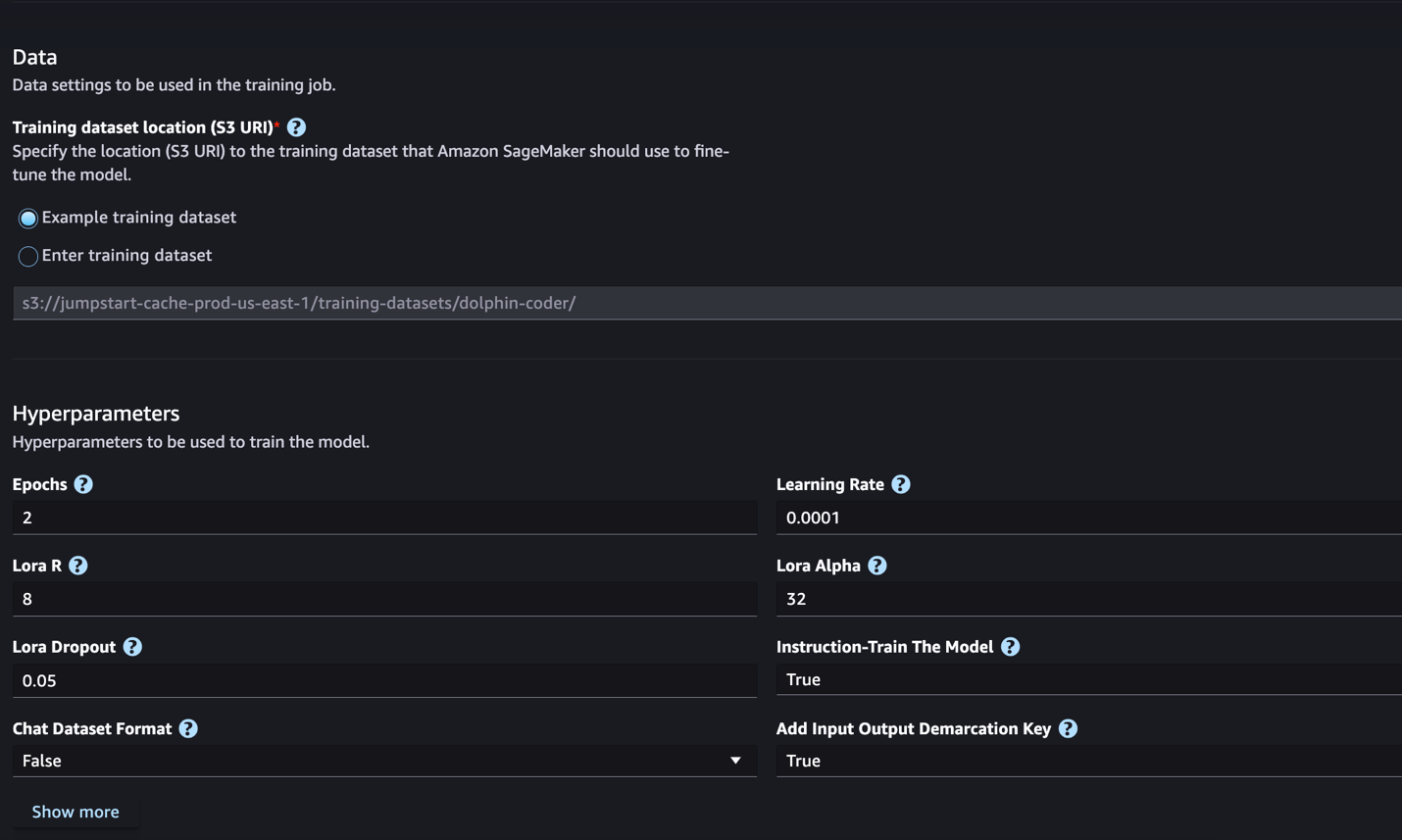
Vi diskuterar datauppsättningsformatet du behöver förbereda för finjustering av instruktioner i nästa avsnitt.
- Efter att modellen har finjusterats kan du distribuera den med hjälp av modellsidan på SageMaker JumpStart.
Alternativet att distribuera den finjusterade modellen visas när finjusteringen är klar, som visas i följande skärmdump.

Finjustera via SageMaker Python SDK
I det här avsnittet visar vi hur man finjusterar Code LIama-modeller med SageMaker Python SDK på en instruktionsformaterad datamängd. Specifikt är modellen finjusterad för en uppsättning NLP-uppgifter (natural language processing) som beskrivs med instruktioner. Detta hjälper till att förbättra modellens prestanda för osynliga uppgifter med noll-shot-uppmaningar.
Slutför följande steg för att slutföra ditt finjusteringsjobb. Du kan få hela finjusteringskoden från GitHub repository.
Låt oss först titta på datauppsättningsformatet som krävs för finjustering av instruktionen. Träningsdata bör formateras i ett JSON-rader (.jsonl)-format, där varje rad är en ordbok som representerar ett dataprov. All träningsdata måste finnas i en enda mapp. Det kan dock sparas i flera .jsonl-filer. Följande är ett exempel i JSON-radformat:
Utbildningsfoldern kan innehålla en template.json fil som beskriver in- och utdataformaten. Följande är en exempelmall:
För att matcha mallen måste varje exempel i JSON-radfilerna innehålla system_prompt, questionoch response fält. I den här demonstrationen använder vi Dolphin Coder dataset från Hugging Face.
När du har förberett datamängden och laddat upp den till S3-skopan kan du börja finjustera med följande kod:
Du kan distribuera den finjusterade modellen direkt från estimatorn, som visas i följande kod. För detaljer, se anteckningsboken i GitHub repository.
Finjusteringstekniker
Språkmodeller som Llama är mer än 10 GB eller till och med 100 GB stora. Att finjustera så stora modeller kräver instanser med avsevärt högt CUDA-minne. Dessutom kan träningen av dessa modeller vara mycket långsam på grund av modellens storlek. Därför använder vi följande optimeringar för effektiv finjustering:
- Lågrankad anpassning (LoRA) – Detta är en typ av parametereffektiv finjustering (PEFT) för effektiv finjustering av stora modeller. Med den här metoden fryser du hela modellen och lägger bara till en liten uppsättning justerbara parametrar eller lager i modellen. Till exempel, istället för att träna alla 7 miljarder parametrar för Llama 2 7B, kan du finjustera mindre än 1 % av parametrarna. Detta bidrar till en betydande minskning av minneskravet eftersom du bara behöver lagra gradienter, optimerartillstånd och annan träningsrelaterad information för endast 1 % av parametrarna. Dessutom hjälper detta till att minska träningstiden såväl som kostnaden. För mer information om denna metod, se LoRA: Lågrankad anpassning av stora språkmodeller.
- Int8 kvantisering – Även med optimeringar som LoRA är modeller som Llama 70B fortfarande för stora för att träna. För att minska minnesavtrycket under träning kan du använda Int8-kvantisering under träning. Kvantisering minskar vanligtvis precisionen för flyttalsdatatyper. Även om detta minskar minnet som krävs för att lagra modellvikter, försämrar det prestandan på grund av förlust av information. Int8-kvantisering använder bara en kvarts precision men medför ingen försämring av prestanda eftersom den inte bara tappar bitarna. Den rundar data från en typ till en annan. För att lära dig om Int8-kvantisering, se LLM.int8(): 8-bitars matrismultiplikation för transformatorer i skala.
- Fullständigt delad data parallell (FSDP) – Det här är en typ av dataparallell träningsalgoritm som skär modellens parametrar över dataparallellarbetare och som valfritt kan överföra en del av träningsberäkningen till CPU:erna. Även om parametrarna är delade över olika GPU:er, är beräkningen av varje mikrobatch lokal för GPU-arbetaren. Det skär parametrar mer enhetligt och uppnår optimerad prestanda via kommunikation och beräkningsöverlappning under träning.
Följande tabell sammanfattar detaljerna för varje modell med olika inställningar.
| Modell | Standardinställning | LORA + FSDP | LORA + Ingen FSDP | Int8 Kvantisering + LORA + Ingen FSDP |
| Kod Llama 2 7B | LORA + FSDP | Ja | Ja | Ja |
| Kod Llama 2 13B | LORA + FSDP | Ja | Ja | Ja |
| Kod Llama 2 34B | INT8 + LORA + INGEN FSDP | Nej | Nej | Ja |
| Kod Llama 2 70B | INT8 + LORA + INGEN FSDP | Nej | Nej | Ja |
Finjustering av Llama-modeller baseras på skript som tillhandahålls av följande GitHub repo.
Hyperparametrar som stöds för träning
Code Llama 2 finjustering stöder ett antal hyperparametrar, som var och en kan påverka minneskravet, träningshastigheten och prestandan för den finjusterade modellen:
- epok – Antalet pass som finjusteringsalgoritmen tar genom träningsdatauppsättningen. Måste vara ett heltal större än 1. Standard är 5.
- learning_rate – Den hastighet med vilken modellvikterna uppdateras efter att man har arbetat igenom varje grupp med träningsexempel. Måste vara en positiv float större än 0. Standard är 1e-4.
- instruktion_avstämd – Om man ska instruera-träna modellen eller inte. Måste vara
TrueorFalse. Standard ärFalse. - per_device_train_batch_size – Batchstorleken per GPU-kärna/CPU för träning. Måste vara ett positivt heltal. Standard är 4.
- per_device_eval_batch_size – Batchstorleken per GPU-kärna/CPU för utvärdering. Måste vara ett positivt heltal. Standard är 1.
- max_train_samples – För felsökningsändamål eller snabbare träning, trunkera antalet träningsexempel till detta värde. Värde -1 betyder att man använder alla träningsprover. Måste vara ett positivt heltal eller -1. Standard är -1.
- max_val_samples – För felsökningsändamål eller snabbare utbildning, trunkera antalet valideringsexempel till detta värde. Värde -1 betyder att alla valideringsprover används. Måste vara ett positivt heltal eller -1. Standard är -1.
- max_input_length – Maximal total ingångssekvenslängd efter tokenisering. Sekvenser längre än detta kommer att trunkeras. Om -1,
max_input_lengthär inställd på minimum 1024 och den maximala modelllängden som definieras av tokenizern. Om inställt på ett positivt värde,max_input_lengthär inställd på minimum av det angivna värdet ochmodel_max_lengthdefinieras av tokenizern. Måste vara ett positivt heltal eller -1. Standard är -1. - validation_split_ratio – Om valideringskanalen är
none, måste förhållandet mellan tågvalideringsdelningen från tågdata vara mellan 0–1. Standard är 0.2. - train_data_split_seed – Om valideringsdata inte finns, fixar detta den slumpmässiga uppdelningen av ingående träningsdata till tränings- och valideringsdata som används av algoritmen. Måste vara ett heltal. Standard är 0.
- förbearbetning_antal_arbetare – Antalet processer som ska användas för förbearbetning. Om
None, används huvudprocessen för förbearbetning. Standard ärNone. - lora_r – Lora R. Måste vara ett positivt heltal. Standard är 8.
- lora_alpha – Lora Alpha. Måste vara ett positivt heltal. Standard är 32
- lora_avhopp – Lora Dropout. måste vara ett positivt flytande mellan 0 och 1. Standard är 0.05.
- int8_kvantisering - Om
True, modellen är laddad med 8-bitars precision för träning. Standard för 7B och 13B ärFalse. Standard för 70B ärTrue. - aktivera_fsdp – Om det är sant, använder utbildning FSDP. Standard för 7B och 13B är True. Standard för 70B är False. Anteckna det
int8_quantizationstöds inte med FSDP.
Tänk på följande när du väljer hyperparametrar:
- Att lägga plattor
int8_quantization=Trueminskar minnesbehovet och leder till snabbare träning. - minskande
per_device_train_batch_sizeochmax_input_lengthminskar minneskravet och kan därför köras på mindre instanser. Att ställa in mycket låga värden kan dock öka träningstiden. - Om du inte använder Int8 kvantisering (
int8_quantization=False), använd FSDP (enable_fsdp=True) för snabbare och effektiv träning.
Stödda instanstyper för utbildning
Följande tabell sammanfattar de instanstyper som stöds för att träna olika modeller.
| Modell | Standardinstanstyp | Stödda instanstyper |
| Kod Llama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Kod Llama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Kod Llama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
Tänk på följande när du väljer instanstyp:
- G5-instanser ger den mest effektiva utbildningen bland de instanstyper som stöds. Därför, om du har tillgängliga G5-instanser, bör du använda dem.
- Träningstiden beror till stor del på mängden av antalet GPU:er och CUDA-minnet som är tillgängligt. Därför är träning på instanser med samma antal GPU:er (till exempel ml.g5.2xlarge och ml.g5.4xlarge) ungefär densamma. Därför kan du använda den billigare instansen för träning (ml.g5.2xlarge).
- När du använder p3-instanser kommer träning att göras med 32-bitars precision eftersom bfloat16 inte stöds på dessa instanser. Därför kommer träningsjobbet att förbruka dubbelt så mycket CUDA-minne när man tränar på p3-instanser jämfört med g5-instanser.
För att lära dig mer om kostnaden för utbildning per instans, se Amazon EC2 G5-instanser.
Utvärdering
Utvärdering är ett viktigt steg för att bedöma prestandan hos finjusterade modeller. Vi presenterar både kvalitativa och kvantitativa utvärderingar för att visa förbättring av finjusterade modeller jämfört med icke finjusterade. I kvalitativ utvärdering visar vi ett exempelsvar från både finjusterade och icke finjusterade modeller. Vid kvantitativ utvärdering använder vi HumanEval, en testsvit utvecklad av OpenAI för att generera Python-kod för att testa förmågan att producera korrekta och korrekta resultat. HumanEval-förvaret är under MIT-licens. Vi finjusterade Python-varianter av alla Code LIama-modeller över olika storlekar (Code LIama Python 7B, 13B, 34B och 70B på Dolphin Coder dataset), och presentera utvärderingsresultaten i följande avsnitt.
Kvalitativ utvärdering
Med din finjusterade modell utplacerad kan du börja använda slutpunkten för att generera kod. I följande exempel presenterar vi svar från både bas- och finjusterade Code LIama 34B Python-varianter på ett testprov i Dolphin Coder dataset:
Den finjusterade Code Llama-modellen genererar, förutom att tillhandahålla koden för den föregående frågan, en detaljerad förklaring av tillvägagångssättet och en pseudokod.
Kod Llama 34b Python icke-finjusterat svar:
Kod Llama 34B Python Finjusterat svar
Mark Sanningen
Intressant nog ger vår finjusterade version av Code Llama 34B Python en dynamisk programmeringsbaserad lösning till den längsta palindromiska delsträngen, som skiljer sig från lösningen som tillhandahålls i grundsanningen från det valda testexemplet. Vår finjusterade modell resonerar och förklarar den dynamiska programmeringsbaserade lösningen i detalj. Å andra sidan hallucinerar den icke finjusterade modellen potentiella utsignaler direkt efter print uttalande (visas i den vänstra cellen) eftersom utgången axyzzyx är inte den längsta palindromen i den givna strängen. När det gäller tidskomplexitet är den dynamiska programmeringslösningen generellt sett bättre än den ursprungliga metoden. Den dynamiska programmeringslösningen har en tidskomplexitet på O(n^2), där n är längden på inmatningssträngen. Detta är effektivare än den initiala lösningen från den icke-finjusterade modellen, som också hade en kvadratisk tidskomplexitet på O(n^2) men med ett mindre optimerat tillvägagångssätt.
Det här ser lovande ut! Kom ihåg att vi bara finjusterade Code LIama Python-varianten med 10 % av Dolphin Coder dataset. Det finns mycket mer att utforska!
Trots noggranna instruktioner i svaret behöver vi fortfarande undersöka riktigheten av Python-koden som tillhandahålls i lösningen. Därefter använder vi ett utvärderingsramverk som heter Människan Eval att köra integrationstester på det genererade svaret från Code LIama för att systematiskt undersöka dess kvalitet.
Kvantitativ utvärdering med HumanEval
HumanEval är en utvärderingssele för att utvärdera en LLM:s problemlösningsförmåga på Python-baserade kodningsproblem, som beskrivs i artikeln Utvärdera stora språkmodeller tränade på kod. Specifikt består den av 164 ursprungliga Python-baserade programmeringsproblem som bedömer en språkmodells förmåga att generera kod baserat på tillhandahållen information som funktionssignatur, docstring, body och enhetstester.
För varje Python-baserad programmeringsfråga skickar vi den till en Code LIama-modell utplacerad på en SageMaker-slutpunkt för att få k-svar. Därefter kör vi vart och ett av k-svaren på integrationstesten i HumanEval-förvaret. Om något svar av de k svaren klarar integrationstesten, räknar vi att testfallet lyckas; annars misslyckades. Sedan upprepar vi processen för att beräkna förhållandet mellan framgångsrika fall som den slutliga utvärderingspoängen pass@k. Enligt standardpraxis sätter vi k som 1 i vår utvärdering, att bara generera ett svar per fråga och testa om det klarar integrationstestet.
Följande är en exempelkod för att använda HumanEval-förrådet. Du kan komma åt datasetet och generera ett enda svar med hjälp av en SageMaker-slutpunkt. För detaljer, se anteckningsboken i GitHub repository.
Följande tabell visar förbättringarna av de finjusterade Code LIama Python-modellerna jämfört med de icke-finjusterade modellerna över olika modellstorlekar. För att säkerställa korrektheten distribuerar vi också de icke finjusterade Code LIama-modellerna i SageMaker-slutpunkter och kör igenom Human Eval-utvärderingar. De pass@1 siffror (första raden i följande tabell) matchar de rapporterade siffrorna i Code Llama forskningsartikel. Inferensparametrarna är konsekvent inställda som "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Som vi kan se från resultaten visar alla de finjusterade Code LIama Python-varianterna betydande förbättringar jämfört med de icke-finjusterade modellerna. Speciellt överträffar Code LIama Python 70B den icke finjusterade modellen med cirka 12 %.
| . | 7B Python | 13B Python | 34B | 34B Python | 70B Python |
| Förtränad modellprestanda (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Finjusterad modellprestanda (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Nu kan du prova att finjustera Code LIama-modeller på din egen datauppsättning.
Städa upp
Om du bestämmer dig för att du inte längre vill ha SageMaker-slutpunkten igång kan du ta bort den med hjälp av AWS SDK för Python (Boto3), AWS-kommandoradsgränssnitt (AWS CLI), eller SageMaker-konsol. För mer information, se Ta bort slutpunkter och resurser. Dessutom kan du stäng av SageMaker Studio-resurserna som inte längre behövs.
Slutsats
I det här inlägget diskuterade vi finjustering av Metas Code Llama 2-modeller med SageMaker JumpStart. Vi visade att du kan använda SageMaker JumpStart-konsolen i SageMaker Studio eller SageMaker Python SDK för att finjustera och distribuera dessa modeller. Vi diskuterade också finjusteringstekniken, instanstyper och stödda hyperparametrar. Dessutom skisserade vi rekommendationer för optimerad träning utifrån olika tester vi genomfört. Som vi kan se från dessa resultat av att finjustera tre modeller över två datauppsättningar, förbättrar finjustering sammanfattningen jämfört med icke-finjusterade modeller. Som ett nästa steg kan du prova att finjustera dessa modeller på din egen datauppsättning med hjälp av koden som tillhandahålls i GitHub-förvaret för att testa och jämföra resultaten för dina användningsfall.
Om författarna
 Dr Xin Huang är en Senior Applied Scientist för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer. Han fokuserar på att utveckla skalbara maskininlärningsalgoritmer. Hans forskningsintressen är inom området naturlig språkbehandling, förklarlig djupinlärning på tabelldata och robust analys av icke-parametrisk rum-tid-klustring. Han har publicerat många artiklar i ACL, ICDM, KDD-konferenser och Royal Statistical Society: Series A.
Dr Xin Huang är en Senior Applied Scientist för Amazon SageMaker JumpStart och Amazon SageMaker inbyggda algoritmer. Han fokuserar på att utveckla skalbara maskininlärningsalgoritmer. Hans forskningsintressen är inom området naturlig språkbehandling, förklarlig djupinlärning på tabelldata och robust analys av icke-parametrisk rum-tid-klustring. Han har publicerat många artiklar i ACL, ICDM, KDD-konferenser och Royal Statistical Society: Series A.
 Vishaal Yalamanchali är en Startup Solutions Architect som arbetar med tidig generativ AI, robotik och autonoma fordonsföretag. Vishaal arbetar med sina kunder för att leverera banbrytande ML-lösningar och är personligen intresserad av förstärkningsinlärning, LLM-utvärdering och kodgenerering. Före AWS var Vishaal en grundutbildning vid UCI, fokuserad på bioinformatik och intelligenta system.
Vishaal Yalamanchali är en Startup Solutions Architect som arbetar med tidig generativ AI, robotik och autonoma fordonsföretag. Vishaal arbetar med sina kunder för att leverera banbrytande ML-lösningar och är personligen intresserad av förstärkningsinlärning, LLM-utvärdering och kodgenerering. Före AWS var Vishaal en grundutbildning vid UCI, fokuserad på bioinformatik och intelligenta system.
 Meenakshisundaram Thandavarayan arbetar för AWS som AI/ML-specialist. Han har en passion för att designa, skapa och främja människocentrerade data- och analysupplevelser. Meena fokuserar på att utveckla hållbara system som levererar mätbara konkurrensfördelar för strategiska kunder till AWS. Meena är en kopplings- och designtänkare och strävar efter att driva företag till nya sätt att arbeta genom innovation, inkubation och demokratisering.
Meenakshisundaram Thandavarayan arbetar för AWS som AI/ML-specialist. Han har en passion för att designa, skapa och främja människocentrerade data- och analysupplevelser. Meena fokuserar på att utveckla hållbara system som levererar mätbara konkurrensfördelar för strategiska kunder till AWS. Meena är en kopplings- och designtänkare och strävar efter att driva företag till nya sätt att arbeta genom innovation, inkubation och demokratisering.
 Dr Ashish Khetan är en Senior Applied Scientist med Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han tog sin doktorsexamen från University of Illinois Urbana-Champaign. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
Dr Ashish Khetan är en Senior Applied Scientist med Amazon SageMaker inbyggda algoritmer och hjälper till att utveckla maskininlärningsalgoritmer. Han tog sin doktorsexamen från University of Illinois Urbana-Champaign. Han är en aktiv forskare inom maskininlärning och statistisk slutledning och har publicerat många artiklar i NeurIPS, ICML, ICLR, JMLR, ACL och EMNLP-konferenser.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

