Grandes Modelos de Linguagem (LLMs) revolucionaram o campo do processamento de linguagem natural (PNL), melhorando tarefas como tradução de idiomas, resumo de texto e análise de sentimentos. No entanto, à medida que estes modelos continuam a crescer em tamanho e complexidade, monitorizar o seu desempenho e comportamento tornou-se cada vez mais desafiante.
Monitorizar o desempenho e o comportamento dos LLMs é uma tarefa crítica para garantir a sua segurança e eficácia. Nossa arquitetura proposta fornece uma solução escalonável e personalizável para monitoramento LLM online, permitindo que as equipes adaptem sua solução de monitoramento aos seus casos de uso e requisitos específicos. Ao usar os serviços da AWS, nossa arquitetura fornece visibilidade em tempo real do comportamento do LLM e permite que as equipes identifiquem e resolvam rapidamente quaisquer problemas ou anomalias.
Nesta postagem, demonstramos algumas métricas para monitoramento LLM online e suas respectivas arquiteturas para escalabilidade usando serviços AWS, como Amazon CloudWatch e AWS Lambda. Isso oferece uma solução personalizável além do que é possível com avaliação do modelo empregos com Rocha Amazônica.
Visão geral da solução
A primeira coisa a considerar é que diferentes métricas requerem diferentes considerações computacionais. É necessária uma arquitetura modular, onde cada módulo possa receber dados de inferência do modelo e produzir suas próprias métricas.
Sugerimos que cada módulo receba solicitações de inferência para o LLM, passando pares de prompt e conclusão (resposta) para módulos de computação métrica. Cada módulo é responsável por calcular suas próprias métricas em relação ao prompt de entrada e à conclusão (resposta). Essas métricas são passadas para o CloudWatch, que pode agregá-las e trabalhar com alarmes do CloudWatch para enviar notificações sobre condições específicas. O diagrama a seguir ilustra essa arquitetura.
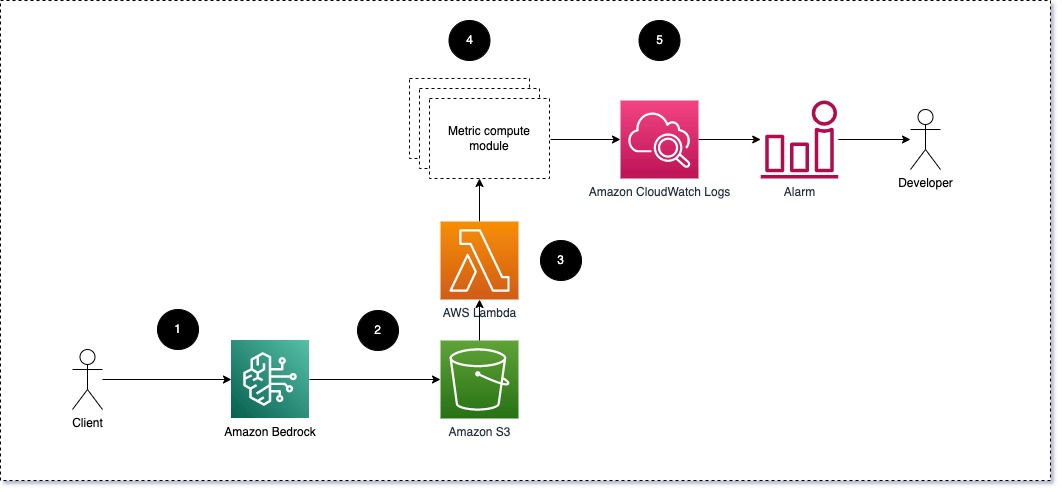
Fig 1: Módulo de computação métrica – visão geral da solução
O fluxo de trabalho inclui as seguintes etapas:
- Um usuário faz uma solicitação ao Amazon Bedrock como parte de um aplicativo ou interface de usuário.
- O Amazon Bedrock salva a solicitação e a conclusão (resposta) em Serviço de armazenamento simples da Amazon (Amazon S3) conforme a configuração de registro de invocação.
- O arquivo salvo no Amazon S3 cria um evento que desencadeia uma função Lambda. A função invoca os módulos.
- Os módulos postam suas respectivas métricas para Métricas do CloudWatch.
- Alarmes pode notificar a equipe de desenvolvimento sobre valores de métricas inesperados.
A segunda coisa a considerar ao implementar o monitoramento LLM é escolher as métricas certas para rastrear. Embora existam muitas métricas potenciais que você pode usar para monitorar o desempenho do LLM, explicamos algumas das mais amplas nesta postagem.
Nas seções a seguir, destacamos algumas das métricas de módulo relevantes e sua respectiva arquitetura de módulo de computação métrica.
Semelhança semântica entre prompt e conclusão (resposta)
Ao executar LLMs, você pode interceptar o prompt e a conclusão (resposta) de cada solicitação e transformá-los em incorporações usando um modelo de incorporação. Embeddings são vetores de alta dimensão que representam o significado semântico do texto. Titã Amazona fornece esses modelos por meio da Titan Embeddings. Calculando uma distância como o cosseno entre esses dois vetores, você pode quantificar o quão semanticamente semelhantes são o prompt e a conclusão (resposta). Você pode usar SciPy or scikit-learn para calcular a distância do cosseno entre vetores. O diagrama a seguir ilustra a arquitetura deste módulo de computação métrica.
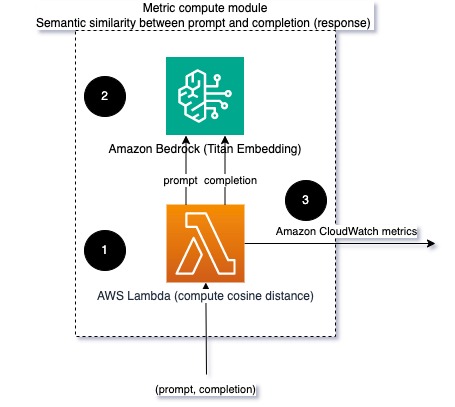
Fig 2: Módulo de computação métrica – similaridade semântica
Este fluxo de trabalho inclui as seguintes etapas principais:
- Uma função Lambda recebe uma mensagem transmitida via Amazon Kinesis contendo um par de prompt e conclusão (resposta).
- A função obtém uma incorporação para o prompt e a conclusão (resposta) e calcula a distância do cosseno entre os dois vetores.
- A função envia essas informações para métricas do CloudWatch.
Sentimento e toxicidade
O monitoramento do sentimento permite avaliar o tom geral e o impacto emocional das respostas, enquanto a análise de toxicidade fornece uma medida importante da presença de linguagem ofensiva, desrespeitosa ou prejudicial nos resultados do LLM. Quaisquer mudanças no sentimento ou toxicidade devem ser monitoradas de perto para garantir que o modelo esteja se comportando conforme o esperado. O diagrama a seguir ilustra o módulo de computação métrica.

Fig 3: Módulo de computação métrica – sentimento e toxicidade
O fluxo de trabalho inclui as seguintes etapas:
- Uma função Lambda recebe um par de prompt e conclusão (resposta) por meio do Amazon Kinesis.
- Por meio da orquestração do AWS Step Functions, a função chama Amazon Comprehend para detectar o sentimento e Toxicidade.
- A função salva as informações nas métricas do CloudWatch.
Para obter mais informações sobre como detectar sentimento e toxicidade com o Amazon Comprehend, consulte Crie um preditor de toxicidade baseado em texto robusto e Sinalize conteúdo prejudicial usando a detecção de toxicidade do Amazon Comprehend.
Proporção de recusas
Um aumento nas recusas, como quando um LLM nega a conclusão devido à falta de informações, pode significar que usuários mal-intencionados estão tentando usar o LLM de forma a fazer o jailbreak ou que as expectativas dos usuários não estão sendo atendidas e eles estão obtendo respostas de baixo valor. Uma forma de avaliar a frequência com que isto acontece é comparar as recusas padrão do modelo LLM utilizado com as respostas reais do LLM. Por exemplo, a seguir estão algumas das frases de recusa comuns do Claude v2 LLM da Anthropic:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Num conjunto fixo de solicitações, um aumento destas recusas pode ser um sinal de que o modelo se tornou excessivamente cauteloso ou sensível. O caso inverso também deve ser avaliado. Poderia ser um sinal de que o modelo está agora mais propenso a se envolver em conversas tóxicas ou prejudiciais.
Para ajudar a modelar a integridade e a taxa de recusa do modelo, podemos comparar a resposta com um conjunto de frases de recusa conhecidas do LLM. Este poderia ser um classificador real que pode explicar por que o modelo recusou a solicitação. Você pode calcular a distância do cosseno entre a resposta e as respostas de recusa conhecidas do modelo que está sendo monitorado. O diagrama a seguir ilustra esse módulo de computação métrica.
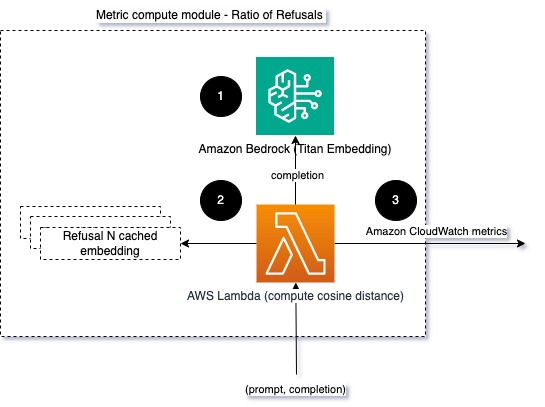
Fig 4: Módulo de cálculo métrico – proporção de recusas
O fluxo de trabalho consiste nas seguintes etapas:
- Uma função Lambda recebe um prompt e uma conclusão (resposta) e obtém uma incorporação da resposta usando o Amazon Titan.
- A função calcula o cosseno ou a distância euclidiana entre a resposta e os prompts de recusa existentes armazenados em cache na memória.
- A função envia essa média para métricas do CloudWatch.
Outra opção é usar correspondência difusa para uma abordagem simples, mas menos poderosa, para comparar as recusas conhecidas aos resultados do LLM. Consulte o Documentação Python Por exemplo.
Resumo
A observabilidade do LLM é uma prática crítica para garantir o uso confiável e confiável dos LLMs. Monitorar, compreender e garantir a precisão e a confiabilidade dos LLMs pode ajudá-lo a mitigar os riscos associados a esses modelos de IA. Ao monitorar alucinações, conclusões incorretas (respostas) e prompts, você pode garantir que seu LLM permaneça no caminho certo e forneça o valor que você e seus usuários procuram. Nesta postagem, discutimos algumas métricas para mostrar exemplos.
Para obter mais informações sobre como avaliar modelos de fundação, consulte Use o SageMaker Clarify para avaliar modelos de basee procure mais cadernos de exemplo disponível em nosso repositório GitHub. Você também pode explorar maneiras de operacionalizar avaliações LLM em escala em Operacionalize a avaliação LLM em escala usando os serviços Amazon SageMaker Clarify e MLOps. Por fim, recomendamos consultar Avalie grandes modelos de linguagem quanto à qualidade e responsabilidade para saber mais sobre como avaliar LLMs.
Sobre os autores
 Bruno Klein é engenheiro sênior de aprendizado de máquina com prática de análise de serviços profissionais da AWS. Ele ajuda os clientes a implementar soluções de big data e análise. Fora do trabalho, ele gosta de passar tempo com a família, viajar e experimentar novas comidas.
Bruno Klein é engenheiro sênior de aprendizado de máquina com prática de análise de serviços profissionais da AWS. Ele ajuda os clientes a implementar soluções de big data e análise. Fora do trabalho, ele gosta de passar tempo com a família, viajar e experimentar novas comidas.
 Rushabh Lokhande é engenheiro sênior de dados e ML com prática de análise de serviços profissionais da AWS. Ele ajuda os clientes a implementar soluções de big data, aprendizado de máquina e análise. Fora do trabalho, ele gosta de passar tempo com a família, ler, correr e jogar golfe.
Rushabh Lokhande é engenheiro sênior de dados e ML com prática de análise de serviços profissionais da AWS. Ele ajuda os clientes a implementar soluções de big data, aprendizado de máquina e análise. Fora do trabalho, ele gosta de passar tempo com a família, ler, correr e jogar golfe.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

