Hoje, clientes de todos os setores – sejam serviços financeiros, saúde e ciências biológicas, viagens e hospitalidade, mídia e entretenimento, telecomunicações, software como serviço (SaaS) e até mesmo provedores de modelos proprietários – estão usando modelos de linguagem grandes (LLMs) para crie aplicativos como chatbots de perguntas e respostas (QnA), mecanismos de pesquisa e bases de conhecimento. Esses IA generativa os aplicativos não são usados apenas para automatizar processos de negócios existentes, mas também têm a capacidade de transformar a experiência dos clientes que usam esses aplicativos. Com os avanços feitos com LLMs como o Instrução Mixtral-8x7B, derivado de arquiteturas como a mistura de especialistas (MoE), os clientes procuram continuamente maneiras de melhorar o desempenho e a precisão dos aplicativos generativos de IA, ao mesmo tempo que lhes permitem usar com eficácia uma gama mais ampla de modelos de código aberto e fechado.
Uma série de técnicas são normalmente usadas para melhorar a precisão e o desempenho da saída de um LLM, como o ajuste fino com ajuste fino eficiente de parâmetros (PEFT), Aprendizagem por reforço a partir do feedback humano (RLHF), e realizando destilação de conhecimento. No entanto, ao construir aplicações generativas de IA, você pode usar uma solução alternativa que permita a incorporação dinâmica de conhecimento externo e controle as informações usadas para geração sem a necessidade de ajustar seu modelo fundamental existente. É aqui que entra a Geração Aumentada de Recuperação (RAG), especificamente para aplicações generativas de IA, em oposição às alternativas de ajuste fino mais caras e robustas que discutimos. Se você estiver implementando aplicativos RAG complexos em suas tarefas diárias, poderá encontrar desafios comuns em seus sistemas RAG, como recuperação imprecisa, aumento do tamanho e da complexidade dos documentos e excesso de contexto, o que pode impactar significativamente a qualidade e a confiabilidade das respostas geradas. .
Esta postagem discute padrões RAG para melhorar a precisão das respostas usando LangChain e ferramentas como o recuperador de documentos pai, além de técnicas como compactação contextual, a fim de permitir que os desenvolvedores melhorem os aplicativos generativos de IA existentes.
Visão geral da solução
Nesta postagem, demonstramos o uso da geração de texto Mixtral-8x7B Instruct combinada com o modelo de incorporação BGE Large En para construir com eficiência um sistema RAG QnA em um notebook Amazon SageMaker usando a ferramenta de recuperação de documento pai e a técnica de compactação contextual. O diagrama a seguir ilustra a arquitetura desta solução.
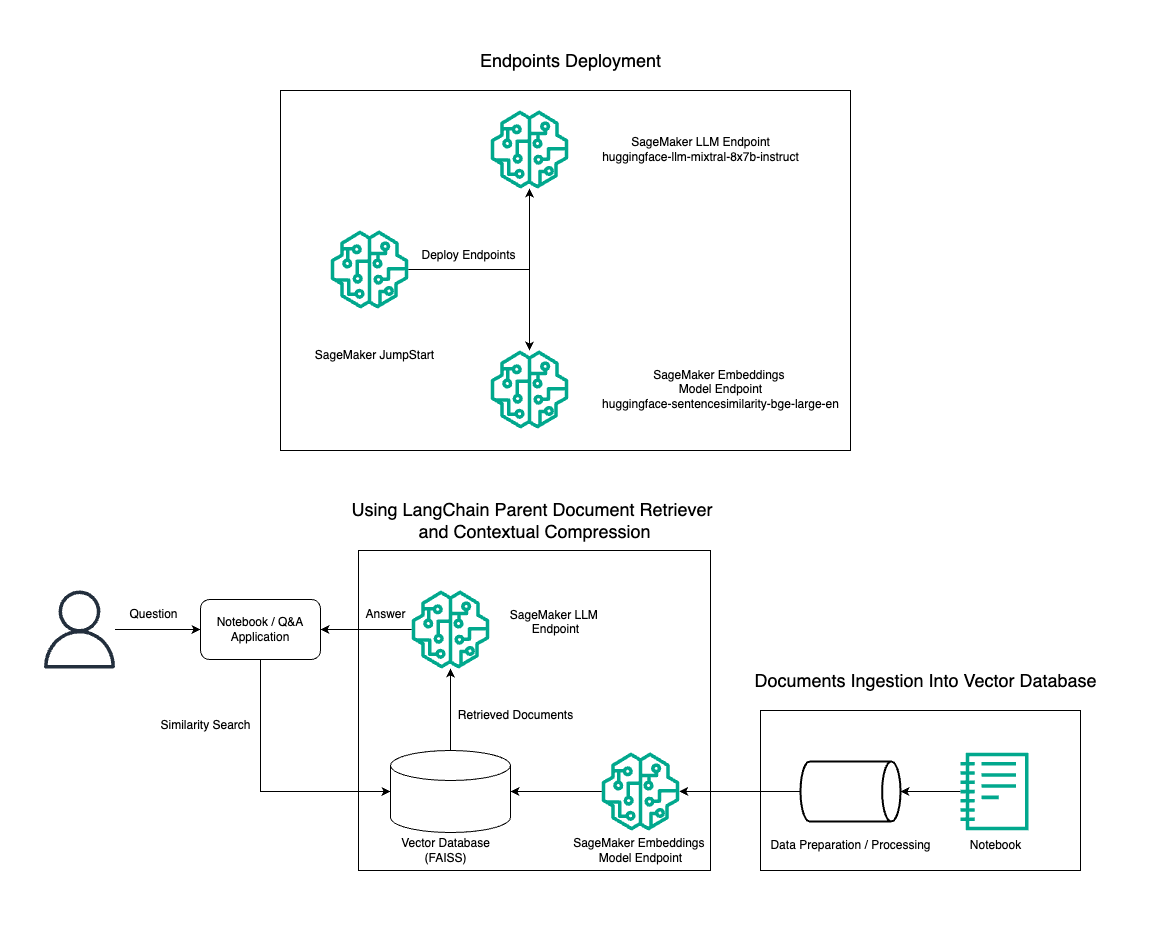
Você pode implantar esta solução com apenas alguns cliques usando JumpStart do Amazon SageMaker, uma plataforma totalmente gerenciada que oferece modelos básicos de última geração para vários casos de uso, como escrita de conteúdo, geração de código, resposta a perguntas, redação, resumo, classificação e recuperação de informações. Ele fornece uma coleção de modelos pré-treinados que você pode implantar com rapidez e facilidade, acelerando o desenvolvimento e a implantação de aplicativos de aprendizado de máquina (ML). Um dos principais componentes do SageMaker JumpStart é o Model Hub, que oferece um vasto catálogo de modelos pré-treinados, como o Mixtral-8x7B, para uma variedade de tarefas.
Mixtral-8x7B usa uma arquitetura MoE. Essa arquitetura permite que diferentes partes de uma rede neural se especializem em diferentes tarefas, dividindo efetivamente a carga de trabalho entre vários especialistas. Esta abordagem permite o treinamento eficiente e a implantação de modelos maiores em comparação com arquiteturas tradicionais.
Uma das principais vantagens da arquitetura MoE é a sua escalabilidade. Ao distribuir a carga de trabalho entre vários especialistas, os modelos do MoE podem ser treinados em conjuntos de dados maiores e obter melhor desempenho do que os modelos tradicionais do mesmo tamanho. Além disso, os modelos MoE podem ser mais eficientes durante a inferência porque apenas um subconjunto de especialistas precisa ser ativado para uma determinada entrada.
Para obter mais informações sobre o Mixtral-8x7B Instruct na AWS, consulte Mixtral-8x7B já está disponível no Amazon SageMaker JumpStart. O modelo Mixtral-8x7B é disponibilizado sob a licença permissiva Apache 2.0, para uso sem restrições.
Nesta postagem, discutimos como você pode usar LangChain para criar aplicações RAG eficazes e mais eficientes. LangChain é uma biblioteca Python de código aberto projetada para construir aplicativos com LLMs. Ele fornece uma estrutura modular e flexível para combinar LLMs com outros componentes, como bases de conhecimento, sistemas de recuperação e outras ferramentas de IA, para criar aplicativos poderosos e personalizáveis.
Caminhamos pela construção de um pipeline RAG no SageMaker com Mixtral-8x7B. Usamos o modelo de geração de texto Mixtral-8x7B Instruct com o modelo de incorporação BGE Large En para criar um sistema QnA eficiente usando RAG em um notebook SageMaker. Usamos uma instância ml.t3.medium para demonstrar a implantação de LLMs por meio do SageMaker JumpStart, que pode ser acessado por meio de um endpoint de API gerado pelo SageMaker. Esta configuração permite a exploração, experimentação e otimização de técnicas avançadas de RAG com LangChain. Também ilustramos a integração da loja FAISS Embedding no fluxo de trabalho RAG, destacando seu papel no armazenamento e recuperação de embeddings para melhorar o desempenho do sistema.
Realizamos um breve passo a passo do notebook SageMaker. Para obter instruções mais detalhadas e passo a passo, consulte o Padrões RAG avançados com Mixtral no repositório SageMaker Jumpstart GitHub.
A necessidade de padrões RAG avançados
Padrões RAG avançados são essenciais para melhorar as capacidades atuais dos LLMs no processamento, compreensão e geração de texto semelhante ao humano. À medida que o tamanho e a complexidade dos documentos aumentam, representar múltiplas facetas do documento numa única incorporação pode levar a uma perda de especificidade. Embora seja essencial capturar a essência geral de um documento, é igualmente crucial reconhecer e representar os diversos subcontextos dentro dele. Este é um desafio que você enfrenta frequentemente ao trabalhar com documentos maiores. Outro desafio do RAG é que, com a recuperação, você não tem conhecimento das consultas específicas que seu sistema de armazenamento de documentos enfrentará durante a ingestão. Isso pode fazer com que as informações mais relevantes para uma consulta sejam ocultadas no texto (estouro de contexto). Para mitigar falhas e melhorar a arquitetura RAG existente, você pode usar padrões RAG avançados (recuperação de documentos pai e compactação contextual) para reduzir erros de recuperação, melhorar a qualidade das respostas e permitir o tratamento de perguntas complexas.
Com as técnicas discutidas nesta postagem, você pode enfrentar os principais desafios associados à recuperação e integração de conhecimento externo, permitindo que seu aplicativo forneça respostas mais precisas e contextualmente conscientes.
Nas seções a seguir, exploramos como recuperadores de documentos pai e compressão contextual pode ajudá-lo a lidar com alguns dos problemas que discutimos.
Recuperador de documentos pai
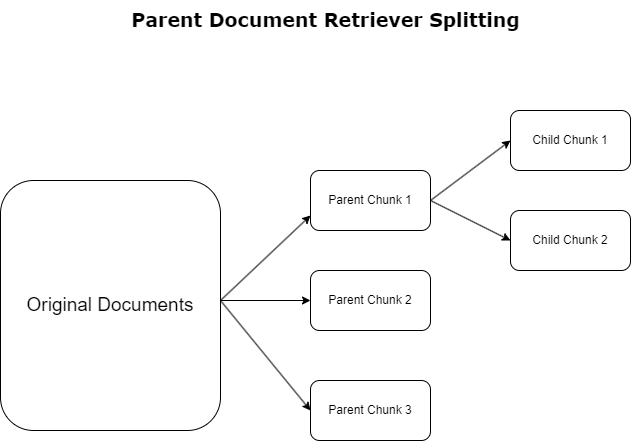
Na seção anterior, destacamos os desafios que as aplicações RAG encontram ao lidar com documentos extensos. Para enfrentar esses desafios, recuperadores de documentos pai categorizar e designar documentos recebidos como documentos parentais. Esses documentos são reconhecidos por sua natureza abrangente, mas não são utilizados diretamente em sua forma original para incorporações. Em vez de compactar um documento inteiro em uma única incorporação, os recuperadores de documentos pais dissecam esses documentos pais em documentos infantis. Cada documento filho captura aspectos ou tópicos distintos do documento pai mais amplo. Após a identificação destes segmentos filhos, são atribuídos embeddings individuais a cada um, captando a sua essência temática específica (ver diagrama seguinte). Durante a recuperação, o documento pai é invocado. Esta técnica fornece recursos de pesquisa direcionados, porém abrangentes, fornecendo ao LLM uma perspectiva mais ampla. Os recuperadores de documentos pais fornecem aos LLMs uma vantagem dupla: a especificidade da incorporação de documentos filhos para recuperação precisa e relevante de informações, juntamente com a invocação de documentos pais para geração de respostas, o que enriquece os resultados do LLM com um contexto completo e em camadas.
Compressão contextual
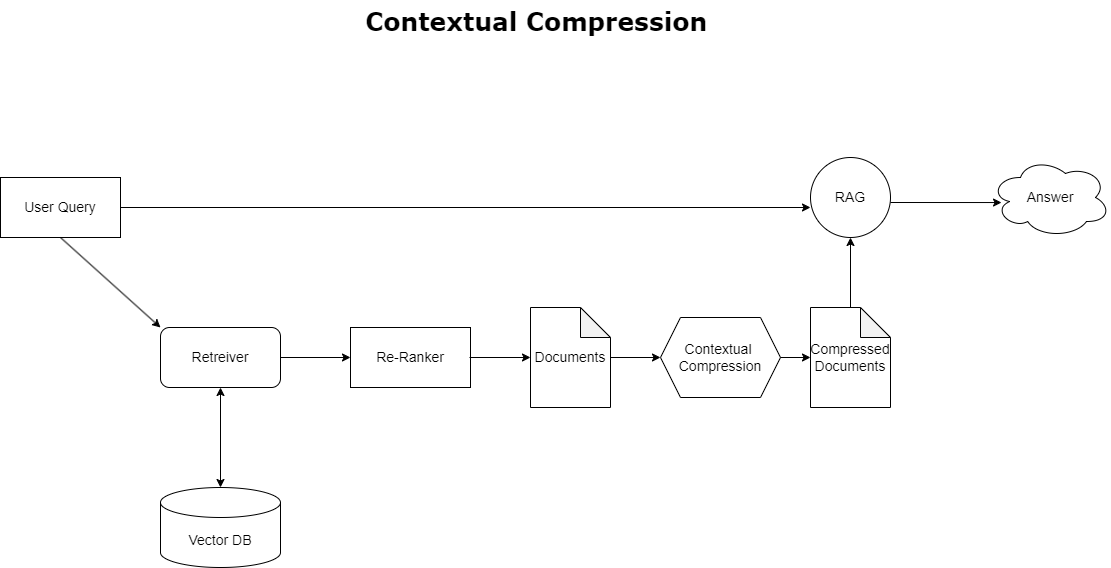
Para resolver o problema de estouro de contexto discutido anteriormente, você pode usar compressão contextual compactar e filtrar os documentos recuperados de acordo com o contexto da consulta, para que apenas as informações pertinentes sejam mantidas e processadas. Isto é conseguido através de uma combinação de um recuperador de base para busca inicial de documentos e um compressor de documentos para refinar esses documentos, reduzindo seu conteúdo ou excluindo-os inteiramente com base na relevância, conforme ilustrado no diagrama a seguir. Essa abordagem simplificada, facilitada pelo recuperador de compactação contextual, aumenta muito a eficiência do aplicativo RAG, fornecendo um método para extrair e utilizar apenas o que é essencial de uma massa de informações. Ele aborda de frente a questão da sobrecarga de informações e do processamento de dados irrelevantes, levando a uma melhor qualidade de resposta, operações de LLM mais econômicas e um processo geral de recuperação mais suave. Essencialmente, é um filtro que adapta as informações à consulta em questão, tornando-se uma ferramenta muito necessária para desenvolvedores que desejam otimizar seus aplicativos RAG para melhor desempenho e satisfação do usuário.
Pré-requisitos
Se você é novo no SageMaker, consulte o Guia de desenvolvimento do Amazon SageMaker.
Antes de começar com a solução, crie uma conta AWS. Ao criar uma conta da AWS, você obtém uma identidade de logon único (SSO) que tem acesso completo a todos os serviços e recursos da AWS na conta. Essa identidade é chamada de conta AWS usuário root.
Fazendo login no Console de gerenciamento da AWS usar o endereço de e-mail e a senha usados para criar a conta fornece acesso completo a todos os recursos da AWS em sua conta. Recomendamos fortemente que você não utilize o usuário root para tarefas cotidianas, mesmo as administrativas.
Em vez disso, siga o melhores práticas de segurança in Gerenciamento de acesso e identidade da AWS (Eu sou e crie um usuário e grupo administrativo. Em seguida, bloqueie com segurança as credenciais do usuário root e use-as para executar apenas algumas tarefas de gerenciamento de contas e serviços.
O modelo Mixtral-8x7b requer uma instância ml.g5.48xlarge. O SageMaker JumpStart fornece uma maneira simplificada de acessar e implantar mais de 100 modelos diferentes de código aberto e de terceiros. A fim de lançar um endpoint para hospedar Mixtral-8x7B do SageMaker JumpStart, talvez seja necessário solicitar um aumento de cota de serviço para acessar uma instância ml.g5.48xlarge para uso de endpoint. Você pode solicitar aumentos de cota de serviço através do console, Interface de linha de comando da AWS (AWS CLI) ou API para permitir acesso a esses recursos adicionais.
Configure uma instância de notebook SageMaker e instale dependências
Para começar, crie uma instância de notebook SageMaker e instale as dependências necessárias. Consulte o GitHub repo para garantir uma configuração bem-sucedida. Depois de configurar a instância do notebook, você poderá implantar o modelo.
Você também pode executar o notebook localmente em seu ambiente de desenvolvimento integrado (IDE) preferido. Certifique-se de ter o laboratório do notebook Jupyter instalado.
Implantar o modelo
Implante o modelo Mixtral-8X7B Instruct LLM no SageMaker JumpStart:
Implante o modelo de incorporação BGE Large En no SageMaker JumpStart:
Configurar LangChain
Depois de importar todas as bibliotecas necessárias e implantar o modelo Mixtral-8x7B e o modelo de embeddings BGE Large En, agora você pode configurar o LangChain. Para obter instruções passo a passo, consulte o GitHub repo.
Preparação de dados
Nesta postagem, usamos vários anos de Cartas aos Acionistas da Amazon como um corpus de texto para realizar perguntas e respostas. Para etapas mais detalhadas para preparar os dados, consulte o GitHub repo.
Resposta de perguntas
Depois que os dados estiverem preparados, você pode usar o wrapper fornecido pelo LangChain, que envolve o armazenamento de vetores e recebe informações para o LLM. Este wrapper executa as seguintes etapas:
- Faça a pergunta de entrada.
- Crie uma incorporação de pergunta.
- Busque documentos relevantes.
- Incorpore os documentos e a pergunta em um prompt.
- Invoque o modelo com o prompt e gere a resposta de maneira legível.
Agora que o armazenamento de vetores está instalado, você pode começar a fazer perguntas:
Cadeia de recuperação regular
No cenário anterior, exploramos a maneira rápida e direta de obter uma resposta contextual à sua pergunta. Agora vamos dar uma olhada em uma opção mais personalizável com a ajuda do RetrievalQA, onde você pode personalizar como os documentos buscados devem ser adicionados ao prompt usando o parâmetro chain_type. Além disso, para controlar quantos documentos relevantes devem ser recuperados, você pode alterar o parâmetro k no código a seguir para ver resultados diferentes. Em muitos cenários, você pode querer saber quais documentos de origem o LLM usou para gerar a resposta. Você pode obter esses documentos na saída usando return_source_documents, que retorna os documentos que são adicionados ao contexto do prompt do LLM. O RetrievalQA também permite fornecer um modelo de prompt personalizado que pode ser específico para o modelo.
Vamos fazer uma pergunta:
Cadeia de recuperação de documentos pai
Vejamos uma opção RAG mais avançada com a ajuda de ParentDocumentRetriever. Ao trabalhar com recuperação de documentos, você pode encontrar uma compensação entre armazenar pequenos pedaços de um documento para incorporações precisas e documentos maiores para preservar mais contexto. O recuperador de documentos pai atinge esse equilíbrio dividindo e armazenando pequenos pedaços de dados.
Usamos um parent_splitter para dividir os documentos originais em pedaços maiores chamados documentos pais e um child_splitter para criar documentos secundários menores a partir dos documentos originais:
Os documentos filhos são então indexados em um armazenamento de vetores usando embeddings. Isto permite a recuperação eficiente de documentos secundários relevantes com base na similaridade. Para recuperar informações relevantes, o recuperador de documentos pai primeiro busca os documentos filhos no armazenamento de vetores. Em seguida, ele procura os IDs pais desses documentos filhos e retorna os documentos pais maiores correspondentes.
Vamos fazer uma pergunta:
Cadeia de compressão contextual
Vejamos outra opção RAG avançada chamada compressão contextual. Um desafio da recuperação é que geralmente não sabemos as consultas específicas que seu sistema de armazenamento de documentos enfrentará quando você ingerir dados no sistema. Isso significa que as informações mais relevantes para uma consulta podem estar ocultas em um documento com muito texto irrelevante. Passar esse documento completo por meio de sua inscrição pode levar a chamadas de LLM mais caras e respostas piores.
O recuperador de compressão contextual aborda o desafio de recuperar informações relevantes de um sistema de armazenamento de documentos, onde os dados pertinentes podem estar enterrados em documentos que contêm muito texto. Ao compactar e filtrar os documentos recuperados com base no contexto de consulta determinado, apenas as informações mais relevantes são retornadas.
Para usar o recuperador de compactação contextual, você precisará de:
- Um recuperador de base – Este é o recuperador inicial que busca documentos do sistema de armazenamento com base na consulta
- Um compressor de documentos – Este componente pega os documentos inicialmente recuperados e os encurta, reduzindo o conteúdo de documentos individuais ou eliminando completamente documentos irrelevantes, usando o contexto da consulta para determinar a relevância
Adicionando compactação contextual com um extrator de cadeia LLM
Primeiro, envolva seu base retriever com um ContextualCompressionRetriever. Você adicionará um LLMChainExtrator, que irá iterar sobre os documentos inicialmente retornados e extrair de cada um apenas o conteúdo que for relevante para a consulta.
Inicialize a cadeia usando o ContextualCompressionRetriever com um LLMChainExtractor e passe o prompt por meio do chain_type_kwargs argumento.
Vamos fazer uma pergunta:
Filtre documentos com um filtro de cadeia LLM
A Filtro LLMChain é um compressor um pouco mais simples, porém mais robusto, que usa uma cadeia LLM para decidir quais dos documentos inicialmente recuperados filtrar e quais retornar, sem manipular o conteúdo do documento:
Inicialize a cadeia usando o ContextualCompressionRetriever com um LLMChainFilter e passe o prompt por meio do chain_type_kwargs argumento.
Vamos fazer uma pergunta:
Compare os resultados
A tabela a seguir compara resultados de diferentes consultas com base na técnica.
| Técnica | Consulta 1 | Consulta 2 | Comparação |
| Como a AWS evoluiu? | Por que a Amazon tem sucesso? | ||
| Saída regular da cadeia do Retriever | A AWS (Amazon Web Services) evoluiu de um investimento inicialmente não lucrativo para um negócio com receita anual de US$ 85 bilhões e forte lucratividade, oferecendo uma ampla gama de serviços e recursos e tornando-se uma parte significativa do portfólio da Amazon. Apesar de enfrentar o ceticismo e os obstáculos de curto prazo, a AWS continuou a inovar, atrair novos clientes e migrar clientes ativos, oferecendo benefícios como agilidade, inovação, economia e segurança. A AWS também expandiu seus investimentos de longo prazo, incluindo o desenvolvimento de chips, para fornecer novos recursos e mudar o que é possível para seus clientes. | A Amazon é bem-sucedida devido à sua contínua inovação e expansão em novas áreas, como serviços de infraestrutura tecnológica, dispositivos de leitura digital, assistentes pessoais acionados por voz e novos modelos de negócios, como o mercado de terceiros. A sua capacidade de escalar operações rapidamente, como visto na rápida expansão das suas redes de atendimento e transporte, também contribui para o seu sucesso. Além disso, o foco da Amazon na otimização e ganhos de eficiência em seus processos resultou em melhorias de produtividade e reduções de custos. O exemplo da Amazon Business destaca a capacidade da empresa de alavancar os seus pontos fortes de comércio eletrónico e logística em diferentes setores. | Com base nas respostas da cadeia de recuperação regular, notamos que embora forneça respostas longas, sofre de estouro de contexto e não menciona quaisquer detalhes significativos do corpus no que diz respeito à resposta à consulta fornecida. A cadeia de recuperação regular não é capaz de capturar as nuances com profundidade ou visão contextual, potencialmente perdendo aspectos críticos do documento. |
| Saída do Recuperador de Documento Pai | A AWS (Amazon Web Services) começou com um lançamento inicial do serviço Elastic Compute Cloud (EC2) com poucos recursos em 2006, fornecendo apenas um tamanho de instância, em um data center, em uma região do mundo, apenas com instâncias do sistema operacional Linux , e sem muitos recursos importantes, como monitoramento, balanceamento de carga, escalonamento automático ou armazenamento persistente. No entanto, o sucesso da AWS permitiu-lhes iterar e adicionar rapidamente os recursos que faltavam, eventualmente expandindo para oferecer vários sabores, tamanhos e otimizações de computação, armazenamento e rede, bem como desenvolver seus próprios chips (Graviton) para aumentar ainda mais o preço e o desempenho. . O processo de inovação iterativo da AWS exigiu investimentos significativos em recursos financeiros e humanos ao longo de 20 anos, muitas vezes bem antes do pagamento, para atender às necessidades dos clientes e melhorar as experiências dos clientes, a fidelidade e os retornos para os acionistas no longo prazo. | A Amazon é bem-sucedida devido à sua capacidade de inovar constantemente, adaptar-se às mudanças nas condições do mercado e atender às necessidades dos clientes em vários segmentos de mercado. Isso é evidente no sucesso da Amazon Business, que cresceu e gerou cerca de US$ 35 bilhões em vendas brutas anualizadas, oferecendo seleção, valor e conveniência aos clientes empresariais. Os investimentos da Amazon em comércio eletrônico e capacidades de logística também permitiram a criação de serviços como o Buy with Prime, que ajuda os comerciantes com sites diretos ao consumidor a impulsionar a conversão de visualizações em compras. | O recuperador de documentos pai se aprofunda nas especificidades da estratégia de crescimento da AWS, incluindo o processo iterativo de adição de novos recursos com base no feedback do cliente e a jornada detalhada desde um lançamento inicial com poucos recursos até uma posição dominante no mercado, ao mesmo tempo em que fornece uma resposta rica em contexto . As respostas abrangem uma ampla gama de aspectos, desde inovações técnicas e estratégia de mercado até eficiência organizacional e foco no cliente, fornecendo uma visão holística dos fatores que contribuem para o sucesso, juntamente com exemplos. Isso pode ser atribuído aos recursos de pesquisa direcionados, porém abrangentes, do recuperador de documentos pai. |
| Extrator de cadeia LLM: saída de compressão contextual | A AWS evoluiu começando como um pequeno projeto dentro da Amazon, exigindo um investimento de capital significativo e enfrentando ceticismo tanto dentro quanto fora da empresa. No entanto, a AWS estava à frente dos concorrentes em potencial e acreditava no valor que poderia trazer aos clientes e à Amazon. A AWS assumiu um compromisso de longo prazo de continuar investindo, resultando em mais de 3,300 novos recursos e serviços lançados em 2022. A AWS transformou a forma como os clientes gerenciam sua infraestrutura de tecnologia e se tornou um negócio com taxa de execução de receita anual de US$ 85 bilhões e forte lucratividade. A AWS também melhorou continuamente suas ofertas, como aprimorar o EC2 com recursos e serviços adicionais após seu lançamento inicial. | Com base no contexto fornecido, o sucesso da Amazon pode ser atribuído à sua expansão estratégica de uma plataforma de venda de livros para um mercado global com um ecossistema vibrante de vendedores terceirizados, investimento inicial na AWS, inovação na introdução do Kindle e Alexa e crescimento substancial na receita anual de 2019 a 2022. Esse crescimento levou à expansão da área do centro de distribuição, à criação de uma rede de transporte de última milha e à construção de uma nova rede de centros de classificação, que foram otimizadas para produtividade e redução de custos. | O extrator de corrente LLM mantém um equilíbrio entre cobrir pontos-chave de forma abrangente e evitar profundidade desnecessária. Ele se ajusta dinamicamente ao contexto da consulta, de forma que a saída seja diretamente relevante e abrangente. |
| Filtro de cadeia LLM: saída de compactação contextual | A AWS (Amazon Web Services) evoluiu lançando inicialmente poucos recursos, mas iterando rapidamente com base no feedback do cliente para adicionar os recursos necessários. Essa abordagem permitiu que a AWS lançasse o EC2 em 2006 com recursos limitados e depois adicionasse continuamente novas funcionalidades, como tamanhos de instância adicionais, data centers, regiões, opções de sistema operacional, ferramentas de monitoramento, balanceamento de carga, escalonamento automático e armazenamento persistente. Com o tempo, a AWS deixou de ser um serviço com poucos recursos para se tornar um negócio multibilionário, concentrando-se nas necessidades do cliente, na agilidade, na inovação, na economia e na segurança. A AWS agora tem uma taxa de receita anual de US$ 85 bilhões e oferece mais de 3,300 novos recursos e serviços a cada ano, atendendo a uma ampla gama de clientes, desde start-ups até empresas multinacionais e organizações do setor público. | A Amazon é bem-sucedida devido aos seus modelos de negócios inovadores, avanços tecnológicos contínuos e mudanças organizacionais estratégicas. A empresa tem revolucionado consistentemente os setores tradicionais ao introduzir novas ideias, como uma plataforma de comércio eletrônico para vários produtos e serviços, um mercado de terceiros, serviços de infraestrutura em nuvem (AWS), o leitor eletrônico Kindle e o assistente pessoal acionado por voz Alexa. . Além disso, a Amazon fez mudanças estruturais para melhorar a sua eficiência, como a reorganização da sua rede de distribuição nos EUA para diminuir custos e prazos de entrega, contribuindo ainda mais para o seu sucesso. | Semelhante ao extrator de cadeia LLM, o filtro de cadeia LLM garante que, embora os pontos-chave sejam cobertos, o resultado seja eficiente para clientes que procuram respostas concisas e contextuais. |
Ao comparar essas diferentes técnicas, podemos ver que em contextos como detalhar a transição da AWS de um serviço simples para uma entidade complexa e multibilionária ou explicar os sucessos estratégicos da Amazon, a cadeia de recuperação regular carece da precisão que as técnicas mais sofisticadas oferecem. levando a informações menos direcionadas. Embora muito poucas diferenças sejam visíveis entre as técnicas avançadas discutidas, elas são de longe mais informativas do que as cadeias de recuperação regulares.
Para clientes em setores como saúde, telecomunicações e serviços financeiros que desejam implementar RAG em suas aplicações, as limitações da cadeia de recuperação regular em fornecer precisão, evitar redundância e compactar informações de maneira eficaz tornam-na menos adequada para atender a essas necessidades em comparação para o recuperador de documentos pai mais avançado e técnicas de compactação contextual. Essas técnicas são capazes de destilar grandes quantidades de informações nos insights concentrados e impactantes de que você precisa, ao mesmo tempo que ajudam a melhorar o desempenho em termos de preço.
limpar
Quando terminar de executar o notebook, exclua os recursos criados para evitar o acúmulo de cobranças pelos recursos em uso:
Conclusão
Nesta postagem, apresentamos uma solução que permite implementar o recuperador de documentos pai e técnicas de cadeia de compactação contextual para aprimorar a capacidade dos LLMs de processar e gerar informações. Testamos essas técnicas RAG avançadas com os modelos Mixtral-8x7B Instruct e BGE Large En disponíveis com SageMaker JumpStart. Também exploramos o uso de armazenamento persistente para incorporações e blocos de documentos e integração com armazenamentos de dados corporativos.
As técnicas que realizamos não apenas refinam a forma como os modelos LLM acessam e incorporam conhecimento externo, mas também melhoram significativamente a qualidade, relevância e eficiência de seus resultados. Ao combinar a recuperação de grandes corpora de texto com capacidades de geração de linguagem, essas técnicas avançadas de RAG permitem que os LLMs produzam respostas mais factuais, coerentes e apropriadas ao contexto, melhorando seu desempenho em várias tarefas de processamento de linguagem natural.
O SageMaker JumpStart está no centro desta solução. Com o SageMaker JumpStart, você obtém acesso a uma ampla variedade de modelos de código aberto e fechado, simplificando o processo de introdução ao ML e permitindo experimentação e implantação rápidas. Para começar a implantar esta solução, navegue até o notebook na seção GitHub repo.
Sobre os autores
 Niithiyn Vijeaswaran é arquiteto de soluções na AWS. Sua área de foco é IA generativa e aceleradores de IA da AWS. Ele possui bacharelado em Ciência da Computação e Bioinformática. Niithiyn trabalha em estreita colaboração com a equipe Generative AI GTM para capacitar os clientes da AWS em diversas frentes e acelerar a adoção da IA generativa. Ele é um grande fã do Dallas Mavericks e gosta de colecionar tênis.
Niithiyn Vijeaswaran é arquiteto de soluções na AWS. Sua área de foco é IA generativa e aceleradores de IA da AWS. Ele possui bacharelado em Ciência da Computação e Bioinformática. Niithiyn trabalha em estreita colaboração com a equipe Generative AI GTM para capacitar os clientes da AWS em diversas frentes e acelerar a adoção da IA generativa. Ele é um grande fã do Dallas Mavericks e gosta de colecionar tênis.
 Sebastião Bustillo é arquiteto de soluções na AWS. Ele se concentra em tecnologias de IA/ML com uma profunda paixão por IA generativa e aceleradores de computação. Na AWS, ele ajuda os clientes a obter valor comercial por meio de IA generativa. Quando não está no trabalho, ele gosta de preparar uma xícara perfeita de café especial e explorar o mundo com sua esposa.
Sebastião Bustillo é arquiteto de soluções na AWS. Ele se concentra em tecnologias de IA/ML com uma profunda paixão por IA generativa e aceleradores de computação. Na AWS, ele ajuda os clientes a obter valor comercial por meio de IA generativa. Quando não está no trabalho, ele gosta de preparar uma xícara perfeita de café especial e explorar o mundo com sua esposa.
 Armando diaz é arquiteto de soluções na AWS. Ele se concentra em IA generativa, IA/ML e análise de dados. Na AWS, Armando ajuda os clientes a integrar recursos de IA generativos de ponta em seus sistemas, promovendo inovação e vantagem competitiva. Quando não está no trabalho, ele gosta de passar tempo com a esposa e a família, fazer caminhadas e viajar pelo mundo.
Armando diaz é arquiteto de soluções na AWS. Ele se concentra em IA generativa, IA/ML e análise de dados. Na AWS, Armando ajuda os clientes a integrar recursos de IA generativos de ponta em seus sistemas, promovendo inovação e vantagem competitiva. Quando não está no trabalho, ele gosta de passar tempo com a esposa e a família, fazer caminhadas e viajar pelo mundo.
 Dr. Farooq Sabir é arquiteto sênior de soluções de inteligência artificial e aprendizado de máquina da AWS. Ele possui doutorado e mestrado em Engenharia Elétrica pela Universidade do Texas em Austin e mestrado em Ciência da Computação pelo Georgia Institute of Technology. Ele tem mais de 15 anos de experiência profissional e também gosta de ensinar e orientar estudantes universitários. Na AWS, ele ajuda os clientes a formular e resolver seus problemas de negócios em ciência de dados, aprendizado de máquina, visão computacional, inteligência artificial, otimização numérica e domínios relacionados. Com sede em Dallas, Texas, ele e sua família adoram viajar e fazer longas viagens.
Dr. Farooq Sabir é arquiteto sênior de soluções de inteligência artificial e aprendizado de máquina da AWS. Ele possui doutorado e mestrado em Engenharia Elétrica pela Universidade do Texas em Austin e mestrado em Ciência da Computação pelo Georgia Institute of Technology. Ele tem mais de 15 anos de experiência profissional e também gosta de ensinar e orientar estudantes universitários. Na AWS, ele ajuda os clientes a formular e resolver seus problemas de negócios em ciência de dados, aprendizado de máquina, visão computacional, inteligência artificial, otimização numérica e domínios relacionados. Com sede em Dallas, Texas, ele e sua família adoram viajar e fazer longas viagens.
 Marco Punio é um arquiteto de soluções focado em estratégia de IA generativa, soluções de IA aplicadas e condução de pesquisas para ajudar os clientes a aumentar a escala na AWS. Marco é um consultor de nuvem digital nativo com experiência nos setores de FinTech, saúde e ciências biológicas, software como serviço e, mais recentemente, nos setores de telecomunicações. Ele é um tecnólogo qualificado e apaixonado por aprendizado de máquina, inteligência artificial e fusões e aquisições. Marco mora em Seattle, WA e gosta de escrever, ler, fazer exercícios e criar aplicativos em seu tempo livre.
Marco Punio é um arquiteto de soluções focado em estratégia de IA generativa, soluções de IA aplicadas e condução de pesquisas para ajudar os clientes a aumentar a escala na AWS. Marco é um consultor de nuvem digital nativo com experiência nos setores de FinTech, saúde e ciências biológicas, software como serviço e, mais recentemente, nos setores de telecomunicações. Ele é um tecnólogo qualificado e apaixonado por aprendizado de máquina, inteligência artificial e fusões e aquisições. Marco mora em Seattle, WA e gosta de escrever, ler, fazer exercícios e criar aplicativos em seu tempo livre.
 AJ Dhimine é arquiteto de soluções na AWS. Ele é especialista em IA generativa, computação sem servidor e análise de dados. Ele é um membro/mentor ativo da Comunidade de Campo Técnico de Aprendizado de Máquina e publicou vários artigos científicos sobre vários tópicos de IA/ML. Ele trabalha com clientes, desde start-ups até empresas, para desenvolver soluções de IA generativas AWSome. Ele é particularmente apaixonado por aproveitar grandes modelos de linguagem para análise avançada de dados e explorar aplicações práticas que abordam desafios do mundo real. Fora do trabalho, AJ gosta de viajar e atualmente está em 53 países com o objetivo de visitar todos os países do mundo.
AJ Dhimine é arquiteto de soluções na AWS. Ele é especialista em IA generativa, computação sem servidor e análise de dados. Ele é um membro/mentor ativo da Comunidade de Campo Técnico de Aprendizado de Máquina e publicou vários artigos científicos sobre vários tópicos de IA/ML. Ele trabalha com clientes, desde start-ups até empresas, para desenvolver soluções de IA generativas AWSome. Ele é particularmente apaixonado por aproveitar grandes modelos de linguagem para análise avançada de dados e explorar aplicações práticas que abordam desafios do mundo real. Fora do trabalho, AJ gosta de viajar e atualmente está em 53 países com o objetivo de visitar todos os países do mundo.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

