Políticas de controlo eficientes permitem às empresas industriais aumentar a sua rentabilidade, maximizando a produtividade e reduzindo ao mesmo tempo o tempo de inatividade não programado e o consumo de energia. Encontrar políticas de controle ideais é uma tarefa complexa porque os sistemas físicos, como reatores químicos e turbinas eólicas, são muitas vezes difíceis de modelar e porque os desvios na dinâmica do processo podem causar a deterioração do desempenho ao longo do tempo. A aprendizagem por reforço offline é uma estratégia de controle que permite às empresas industriais construir políticas de controle inteiramente a partir de dados históricos, sem a necessidade de um modelo de processo explícito. Esta abordagem não requer interação direta com o processo em uma etapa de exploração, o que remove uma das barreiras para a adoção de aprendizagem por reforço em aplicações críticas de segurança. Neste post, construiremos uma solução ponta a ponta para encontrar políticas de controle ideais usando apenas dados históricos sobre Amazon Sage Maker usando Ray RLlib biblioteca. Para saber mais sobre aprendizagem por reforço, consulte Use o aprendizado por reforço com o Amazon SageMaker.
Os casos de uso
O controle industrial envolve o gerenciamento de sistemas complexos, como linhas de fabricação, redes de energia e fábricas de produtos químicos, para garantir uma operação eficiente e confiável. Muitas estratégias de controle tradicionais baseiam-se em regras e modelos predefinidos, que muitas vezes requerem otimização manual. É prática padrão em algumas indústrias monitorar o desempenho e ajustar a política de controle quando, por exemplo, o equipamento começa a degradar ou as condições ambientais mudam. A reajuste pode levar semanas e exigir a injeção de excitações externas no sistema para registrar sua resposta em uma abordagem de tentativa e erro.
A aprendizagem por reforço surgiu como um novo paradigma no controle de processos para aprender políticas de controle ideais por meio da interação com o ambiente. Este processo requer a divisão dos dados em três categorias: 1) medições disponíveis no sistema físico, 2) o conjunto de ações que podem ser tomadas no sistema e 3) uma métrica numérica (recompensa) do desempenho do equipamento. Uma política é treinada para encontrar a ação, numa determinada observação, que provavelmente produzirá as maiores recompensas futuras.
No aprendizado por reforço offline, pode-se treinar uma política em dados históricos antes de implantá-la na produção. O algoritmo treinado nesta postagem do blog é chamado “Aprendizagem Q Conservadora”(CQL). O CQL contém um modelo de “ator” e um modelo de “crítico” e é projetado para prever de forma conservadora seu próprio desempenho após executar uma ação recomendada. Neste post, o processo é demonstrado com um problema ilustrativo de controle de carrinho-pólo. O objetivo é treinar um agente para equilibrar uma vara em um carrinho enquanto simultaneamente move o carrinho em direção a um local de destino designado. O procedimento de treinamento utiliza dados off-line, permitindo que o agente aprenda com informações pré-existentes. Este estudo de caso demonstra o processo de treinamento e sua eficácia em possíveis aplicações do mundo real.
Visão geral da solução
A solução apresentada nesta postagem automatiza a implantação de um fluxo de trabalho ponta a ponta para aprendizado por reforço offline com dados históricos. O diagrama a seguir descreve a arquitetura usada neste fluxo de trabalho. Os dados de medição são produzidos na borda por um equipamento industrial (aqui simulado por um AWS Lambda função). Os dados são colocados em um Amazon Kinesis Data Firehose, que o armazena em Serviço de armazenamento simples da Amazon (Amazon S3). O Amazon S3 é uma solução de armazenamento durável, de alto desempenho e de baixo custo que permite servir grandes volumes de dados para um processo de treinamento de machine learning.
Cola AWS cataloga os dados e os torna consultáveis usando Amazona atena. O Athena transforma os dados de medição em um formato que um algoritmo de aprendizado por reforço pode ingerir e, em seguida, descarrega-os de volta no Amazon S3. O Amazon SageMaker carrega esses dados em um trabalho de treinamento e produz um modelo treinado. O SageMaker então atende esse modelo em um endpoint do SageMaker. O equipamento industrial pode então consultar esse endpoint para receber recomendações de ação.
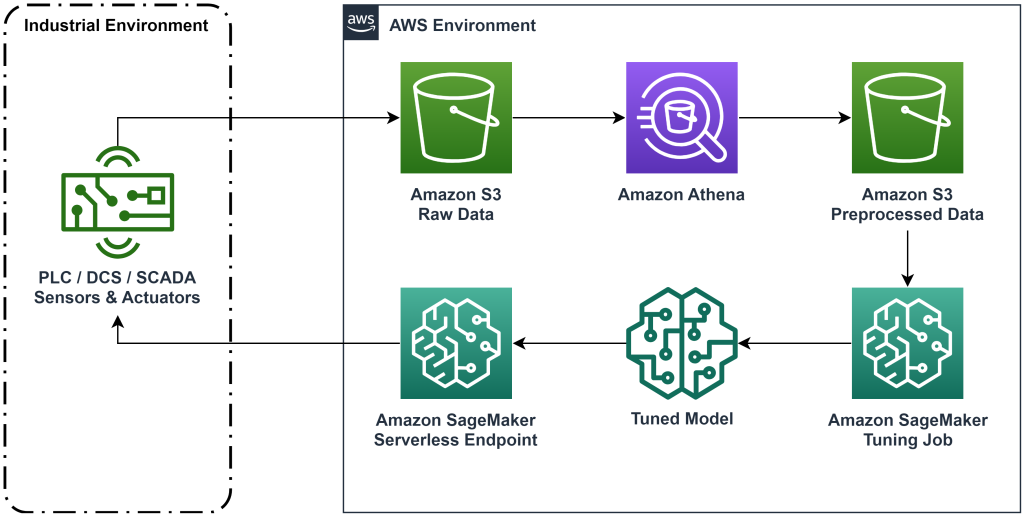
Figura 1: Diagrama de arquitetura mostrando o fluxo de trabalho de aprendizagem por reforço de ponta a ponta.
Nesta postagem, dividiremos o fluxo de trabalho nas seguintes etapas:
- Formule o problema. Decida quais ações podem ser tomadas, em quais medidas fazer recomendações e determine numericamente quão bem cada ação foi executada.
- Prepare os dados. Transforme a tabela de medidas em um formato que o algoritmo de aprendizado de máquina possa consumir.
- Treine o algoritmo nesses dados.
- Selecione a melhor execução de treinamento com base nas métricas de treinamento.
- Implante o modelo em um endpoint do SageMaker.
- Avalie o desempenho do modelo em produção.
Pré-requisitos
Para concluir este passo a passo, você precisa ter um Conta da AWS e uma interface de linha de comando com AWS SAM instalado. Siga estas etapas para implantar o modelo AWS SAM para executar esse fluxo de trabalho e gerar dados de treinamento:
- Baixe o repositório de código com o comando
- Mude o diretório para o repositório:
- Construa o repositório:
- Implantar o repositório
- Use os comandos a seguir para chamar um script bash, que gera dados simulados usando uma função AWS Lambda.
sudo yum install jqcd utilssh generate_mock_data.sh
Passo a passo da solução
Formular problema
Nosso sistema nesta postagem do blog é um carrinho com uma vara equilibrada no topo. O sistema funciona bem quando o mastro está na vertical e a posição do carrinho está próxima da posição do gol. Na etapa de pré-requisito, geramos dados históricos deste sistema.
A tabela a seguir mostra dados históricos coletados do sistema.
| Posição do carrinho | Velocidade do carrinho | Ângulo do pólo | Velocidade angular do pólo | Posição do gol | Força externa | Recompensa | Horário |
| 0.53 | -0.79 | -0.08 | 0.16 | 0.50 | -0.04 | 11.5 | 5: 37: 54 PM |
| 0.51 | -0.82 | -0.07 | 0.17 | 0.50 | -0.04 | 11.9 | 5: 37: 55 PM |
| 0.50 | -0.84 | -0.07 | 0.18 | 0.50 | -0.03 | 12.2 | 5: 37: 56 PM |
| 0.48 | -0.85 | -0.07 | 0.18 | 0.50 | -0.03 | 10.5 | 5: 37: 57 PM |
| 0.46 | -0.87 | -0.06 | 0.19 | 0.50 | -0.03 | 10.3 | 5: 37: 58 PM |
Você pode consultar informações históricas do sistema usando o Amazon Athena com a seguinte consulta:
O estado deste sistema é definido pela posição do carrinho, velocidade do carrinho, ângulo do pólo, velocidade angular do pólo e posição do objetivo. A ação realizada em cada passo de tempo é a força externa aplicada ao carrinho. O ambiente simulado gera um valor de recompensa que é maior quando o carrinho está mais próximo da posição do objetivo e o poste está mais vertical.
Preparar dados
Para apresentar as informações do sistema ao modelo de aprendizagem por reforço, transforme-as em objetos JSON com chaves que categorizam valores nas categorias de estado (também chamadas de observação), ação e recompensa. Armazene esses objetos no Amazon S3. Aqui está um exemplo de objetos JSON produzidos a partir de intervalos de tempo na tabela anterior.
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
A pilha do AWS CloudFormation contém uma saída chamada AthenaQueryToCreateJsonFormatedData. Execute esta consulta no Amazon Athena para realizar a transformação e armazenar os objetos JSON no Amazon S3. O algoritmo de aprendizado por reforço usa a estrutura desses objetos JSON para entender em quais valores basear as recomendações e o resultado da execução de ações nos dados históricos.
Agente de trem
Agora podemos iniciar um trabalho de treinamento para produzir um modelo de recomendação de ação treinado. O Amazon SageMaker permite iniciar rapidamente vários trabalhos de treinamento para ver como diversas configurações afetam o modelo treinado resultante. Chame a função Lambda chamada TuningJobLauncherFunction para iniciar um trabalho de ajuste de hiperparâmetros que experimenta quatro conjuntos diferentes de hiperparâmetros ao treinar o algoritmo.
Selecione a melhor corrida de treinamento
Para descobrir qual dos trabalhos de treinamento produziu o melhor modelo, examine as curvas de perda produzidas durante o treinamento. O modelo crítico do CQL estima o desempenho do ator (chamado de valor Q) após realizar uma ação recomendada. Parte da função de perda do crítico inclui o erro de diferença temporal. Esta métrica mede a precisão do valor Q do crítico. Procure execuções de treinamento com um valor Q médio alto e um erro de diferença temporal baixo. Este papel, Um fluxo de trabalho para aprendizagem de reforço robótico off-line sem modelo, detalha como selecionar a melhor corrida de treinamento. O repositório de código possui um arquivo, /utils/investigate_training.py, que cria uma figura HTML que descreve o trabalho de treinamento mais recente. Execute este arquivo e use a saída para escolher a melhor execução de treinamento.
Podemos usar o valor médio de Q para prever o desempenho do modelo treinado. Os valores Q são treinados para prever de forma conservadora a soma dos valores de recompensas futuras descontadas. Para processos de longa duração, podemos converter esse número em uma média ponderada exponencialmente multiplicando o valor Q por (1- “taxa de desconto”). A melhor execução de treinamento neste conjunto alcançou um valor médio de Q de 539. Nossa taxa de desconto é de 0.99, portanto, o modelo está prevendo pelo menos 5.39 de recompensa média por intervalo de tempo. Você pode comparar esse valor com o desempenho histórico do sistema para obter uma indicação se o novo modelo superará a política de controle histórica. Neste experimento, a recompensa média dos dados históricos por intervalo de tempo foi de 4.3, portanto, o modelo CQL está prevendo um desempenho 25% melhor do que o sistema alcançado historicamente.
Implantar modelo
Os endpoints do Amazon SageMaker permitem servir modelos de machine learning de diversas maneiras para atender a diversos casos de uso. Nesta postagem, usaremos o tipo de endpoint sem servidor para que nosso endpoint seja dimensionado automaticamente de acordo com a demanda e só pagaremos pelo uso da computação quando o endpoint estiver gerando uma inferência. Para implantar um endpoint sem servidor, inclua um ProduçãoVariantServerlessConfig no variante de produção do SageMaker configuração de terminal. O snippet de código a seguir mostra como o endpoint sem servidor neste exemplo é implantado usando o kit de desenvolvimento de software Amazon SageMaker para Python. Encontre o código de amostra usado para implantar o modelo em sagemaker-offline-reforço-aprendizado-ray-cql.
Os arquivos do modelo treinado estão localizados nos artefatos do modelo S3 para cada execução de treinamento. Para implantar o modelo de aprendizado de máquina, localize os arquivos de modelo da melhor execução de treinamento e chame a função Lambda chamada “ModelDeployerFunction” com um evento que contém os dados deste modelo. A função Lambda iniciará um endpoint sem servidor SageMaker para servir o modelo treinado. Exemplo de evento a ser usado ao chamar o “ModelDeployerFunction"
Avalie o desempenho do modelo treinado
É hora de ver como está o desempenho do nosso modelo treinado em produção! Para verificar o desempenho do novo modelo, chame a função Lambda chamada “RunPhysicsSimulationFunction”Com o nome do endpoint SageMaker no evento. Isso executará a simulação usando as ações recomendadas pelo endpoint. Exemplo de evento a ser usado ao chamar o RunPhysicsSimulatorFunction:
Use a consulta do Athena a seguir para comparar o desempenho do modelo treinado com o desempenho histórico do sistema.
| Fonte de ação | Recompensa média por intervalo de tempo |
trained_model |
10.8 |
historic_data |
4.3 |
As animações a seguir mostram a diferença entre um episódio de amostra dos dados de treinamento e um episódio em que o modelo treinado foi usado para escolher qual ação tomar. Nas animações, a caixa azul é o carrinho, a linha azul é o mastro e o retângulo verde é o local do gol. A seta vermelha mostra a força aplicada ao carrinho em cada intervalo de tempo. A seta vermelha nos dados de treinamento salta bastante para frente e para trás porque os dados foram gerados usando 50% de ações especializadas e 50% de ações aleatórias. O modelo treinado aprendeu uma política de controle que move o carrinho rapidamente para a posição de meta, mantendo a estabilidade, inteiramente a partir da observação de demonstrações de não especialistas.
 |
 |
limpar
Para excluir recursos usados neste fluxo de trabalho, navegue até a seção de recursos da pilha do Amazon CloudFormation e exclua os buckets do S3 e as funções do IAM. Em seguida, exclua a própria pilha do CloudFormation.
Conclusão
O aprendizado por reforço off-line pode ajudar as empresas industriais a automatizar a busca por políticas ideais sem comprometer a segurança, usando dados históricos. Para implementar essa abordagem em suas operações, comece identificando as medidas que compõem um sistema determinado pelo estado, as ações que você pode controlar e as métricas que indicam o desempenho desejado. Então, acesse este repositório do GitHub para a implementação de uma solução automática ponta a ponta usando Ray e Amazon SageMaker.
A postagem apenas mostra o que você pode fazer com o Amazon SageMaker RL. Experimente e envie-nos comentários, seja no Fórum de discussão do Amazon SageMaker ou por meio de seus contatos usuais da AWS.
Sobre os autores
 Walt Mayfield é arquiteto de soluções na AWS e ajuda empresas de energia a operar com mais segurança e eficiência. Antes de ingressar na AWS, Walt trabalhou como engenheiro de operações na Hilcorp Energy Company. Ele gosta de jardinagem e pesca voadora nas horas vagas.
Walt Mayfield é arquiteto de soluções na AWS e ajuda empresas de energia a operar com mais segurança e eficiência. Antes de ingressar na AWS, Walt trabalhou como engenheiro de operações na Hilcorp Energy Company. Ele gosta de jardinagem e pesca voadora nas horas vagas.
 Felipe Lopes é arquiteto de soluções sênior na AWS com concentração em operações de produção de petróleo e gás. Antes de ingressar na AWS, Felipe trabalhou na GE Digital e na Schlumberger, onde se concentrou na modelagem e otimização de produtos para aplicações industriais.
Felipe Lopes é arquiteto de soluções sênior na AWS com concentração em operações de produção de petróleo e gás. Antes de ingressar na AWS, Felipe trabalhou na GE Digital e na Schlumberger, onde se concentrou na modelagem e otimização de produtos para aplicações industriais.
 Yingwei Yu é Cientista Aplicado na Generative AI Incubator, AWS. Ele tem experiência trabalhando com diversas organizações de todos os setores em diversas provas de conceito em aprendizado de máquina, incluindo processamento de linguagem natural, análise de séries temporais e manutenção preditiva. Nas horas vagas, gosta de nadar, pintar, fazer caminhadas e passar tempo com a família e amigos.
Yingwei Yu é Cientista Aplicado na Generative AI Incubator, AWS. Ele tem experiência trabalhando com diversas organizações de todos os setores em diversas provas de conceito em aprendizado de máquina, incluindo processamento de linguagem natural, análise de séries temporais e manutenção preditiva. Nas horas vagas, gosta de nadar, pintar, fazer caminhadas e passar tempo com a família e amigos.
 Haozhu Wang é um cientista pesquisador da Amazon Bedrock com foco na construção dos modelos de fundação Titan da Amazon. Anteriormente, ele trabalhou no Amazon ML Solutions Lab como colíder do Reinforcement Learning Vertical e ajudou clientes a criar soluções avançadas de ML com as pesquisas mais recentes sobre aprendizado por reforço, processamento de linguagem natural e aprendizado de gráficos. Haozhu recebeu seu PhD em Engenharia Elétrica e de Computação pela Universidade de Michigan.
Haozhu Wang é um cientista pesquisador da Amazon Bedrock com foco na construção dos modelos de fundação Titan da Amazon. Anteriormente, ele trabalhou no Amazon ML Solutions Lab como colíder do Reinforcement Learning Vertical e ajudou clientes a criar soluções avançadas de ML com as pesquisas mais recentes sobre aprendizado por reforço, processamento de linguagem natural e aprendizado de gráficos. Haozhu recebeu seu PhD em Engenharia Elétrica e de Computação pela Universidade de Michigan.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- ChartPrime. Eleve seu jogo de negociação com ChartPrime. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

