Nos últimos anos, os Grandes Modelos de Linguagem (LLMs) ganharam destaque como ferramentas excepcionais capazes de compreender, gerar e manipular texto com uma proficiência sem precedentes. Suas aplicações potenciais abrangem desde agentes de conversação até geração de conteúdo e recuperação de informações, prometendo revolucionar todos os setores. No entanto, aproveitar este potencial e garantir a utilização responsável e eficaz destes modelos depende do processo crítico de avaliação do LLM. Uma avaliação é uma tarefa usada para medir a qualidade e a responsabilidade do resultado de um LLM ou serviço de IA generativo. A avaliação de LLMs não é motivada apenas pelo desejo de compreender o desempenho de um modelo, mas também pela necessidade de implementar IA responsável e pela necessidade de mitigar o risco de fornecer informações erradas ou conteúdo tendencioso e de minimizar a geração de informações prejudiciais, inseguras, maliciosas e antiéticas. contente. Além disso, a avaliação de LLMs também pode ajudar a mitigar os riscos de segurança, especialmente no contexto de adulteração imediata de dados. Para aplicações baseadas em LLM, é crucial identificar vulnerabilidades e implementar salvaguardas que protejam contra possíveis violações e manipulações não autorizadas de dados.
Ao fornecer ferramentas essenciais para avaliar LLMs com uma configuração simples e abordagem de um clique, Esclarecimento do Amazon SageMaker Os recursos de avaliação LLM concedem aos clientes acesso à maioria dos benefícios mencionados acima. Com essas ferramentas em mãos, o próximo desafio é integrar a avaliação LLM ao ciclo de vida de Machine Learning and Operation (MLOps) para alcançar automação e escalabilidade no processo. Nesta postagem, mostramos como integrar a avaliação do Amazon SageMaker Clarify LLM com o Amazon SageMaker Pipelines para permitir a avaliação do LLM em escala. Além disso, fornecemos um exemplo de código neste GitHub repositório para permitir que os usuários conduzam avaliações paralelas de vários modelos em escala, usando exemplos como Llama2-7b-f, Falcon-7b e modelos Llama2-7b ajustados.
Quem precisa realizar a avaliação LLM?
Qualquer pessoa que treine, ajuste ou simplesmente use um LLM pré-treinado precisa avaliá-lo com precisão para avaliar o comportamento do aplicativo desenvolvido por esse LLM. Com base neste princípio, podemos classificar os usuários de IA generativa que precisam de recursos de avaliação LLM em 3 grupos, conforme mostrado na figura a seguir: fornecedores de modelos, sintonizadores finos e consumidores.

- Provedores de modelo fundamental (FM) treinar modelos de uso geral. Esses modelos podem ser usados para muitas tarefas posteriores, como extração de recursos ou geração de conteúdo. Cada modelo treinado precisa de ser comparado com muitas tarefas, não só para avaliar o seu desempenho, mas também para compará-lo com outros modelos existentes, para identificar áreas que necessitam de melhorias e, finalmente, para acompanhar os avanços no campo. Os fornecedores de modelos também precisam verificar a presença de quaisquer vieses para garantir a qualidade do conjunto de dados inicial e o comportamento correto do seu modelo. A recolha de dados de avaliação é vital para os fornecedores de modelos. Além disso, estes dados e métricas devem ser recolhidos para cumprir as regulamentações futuras. ISO 42001, Ordem Executiva da Administração Biden e Lei de IA da UE desenvolver padrões, ferramentas e testes para ajudar a garantir que os sistemas de IA sejam seguros, protegidos e confiáveis. Por exemplo, a Lei de IA da UE tem a tarefa de fornecer informações sobre quais conjuntos de dados são usados para treinamento, qual poder de computação é necessário para executar o modelo, relatar os resultados do modelo em relação a benchmarks padrão do público/indústria e compartilhar resultados de testes internos e externos.
- Modelo sintonizadores finos desejam resolver tarefas específicas (por exemplo, classificação de sentimentos, resumo, resposta a perguntas), bem como modelos pré-treinados para adotar tarefas específicas de domínio. Eles precisam de métricas de avaliação geradas por fornecedores de modelos para selecionar o modelo pré-treinado correto como ponto de partida.
Eles precisam avaliar seus modelos ajustados em relação ao caso de uso desejado com conjuntos de dados específicos de tarefa ou de domínio. Freqüentemente, eles devem selecionar e criar seus conjuntos de dados privados, uma vez que os conjuntos de dados disponíveis publicamente, mesmo aqueles projetados para uma tarefa específica, podem não capturar adequadamente as nuances necessárias para seu caso de uso específico.
O ajuste fino é mais rápido e barato do que um treinamento completo e requer uma iteração operacional mais rápida para implantação e teste porque geralmente são gerados muitos modelos candidatos. A avaliação desses modelos permite melhoria contínua, calibração e depuração do modelo. Observe que os sintonizadores finos podem se tornar consumidores de seus próprios modelos quando desenvolvem aplicações no mundo real. - Modelo consumidores ou implantadores de modelos atendem e monitoram modelos de uso geral ou ajustados em produção, com o objetivo de aprimorar seus aplicativos ou serviços por meio da adoção de LLMs. O primeiro desafio que eles enfrentam é garantir que o LLM escolhido esteja alinhado com suas necessidades específicas, custos e expectativas de desempenho. Interpretar e compreender os resultados do modelo é uma preocupação persistente, especialmente quando a privacidade e a segurança dos dados estão envolvidas (por exemplo, para auditoria de risco e conformidade em indústrias regulamentadas, como o setor financeiro). A avaliação contínua do modelo é fundamental para evitar a propagação de preconceitos ou conteúdo prejudicial. Ao implementar um quadro robusto de monitorização e avaliação, os consumidores do modelo podem identificar e abordar proativamente a regressão nos LLMs, garantindo que estes modelos mantêm a sua eficácia e fiabilidade ao longo do tempo.
Como realizar a avaliação LLM
A avaliação eficaz do modelo envolve três componentes fundamentais: um ou mais FMs ou modelos ajustados para avaliar os conjuntos de dados de entrada (prompts, conversas ou entradas regulares) e a lógica de avaliação.
Para selecionar os modelos para avaliação, diferentes fatores devem ser considerados, incluindo características dos dados, complexidade do problema, recursos computacionais disponíveis e o resultado desejado. O armazenamento de dados de entrada fornece os dados necessários para treinar, ajustar e testar o modelo selecionado. É vital que esse armazenamento de dados seja bem estruturado, representativo e de alta qualidade, pois o desempenho do modelo depende muito dos dados com os quais ele aprende. Por último, as lógicas de avaliação definem os critérios e métricas utilizados para avaliar o desempenho do modelo.
Juntos, esses três componentes formam uma estrutura coesa que garante a avaliação rigorosa e sistemática dos modelos de aprendizado de máquina, levando, em última análise, a decisões informadas e a melhorias na eficácia do modelo.
As técnicas de avaliação de modelos ainda são um campo ativo de pesquisa. Muitos benchmarks e estruturas públicas foram criados pela comunidade de pesquisadores nos últimos anos para cobrir uma ampla gama de tarefas e cenários, como COLA, SuperCOLA, LEME, MMLU e GRANDE-banco. Esses benchmarks possuem tabelas de classificação que podem ser usadas para comparar e contrastar os modelos avaliados. Os benchmarks, como o HELM, também visam avaliar métricas além das medidas de precisão, como precisão ou pontuação F1. O benchmark HELM inclui métricas de justiça, preconceito e toxicidade que têm uma importância igualmente significativa na pontuação geral de avaliação do modelo.
Todos esses benchmarks incluem um conjunto de métricas que medem o desempenho do modelo em uma determinada tarefa. As métricas mais famosas e comuns são ROUGE (Subestudo Orientado para Recall para Avaliação de Gisting), AZUL (Subestudo de Avaliação Bilíngue), ou METEOR (Métrica para Avaliação de Tradução com Ordenação Explícita). Essas métricas servem como uma ferramenta útil para avaliação automatizada, fornecendo medidas quantitativas de similaridade lexical entre o texto gerado e o texto de referência. No entanto, eles não captam toda a amplitude da geração de linguagem semelhante à humana, que inclui compreensão semântica, contexto ou nuances estilísticas. Por exemplo, o HELM não fornece detalhes de avaliação relevantes para casos de uso específicos, soluções para testar prompts personalizados e resultados facilmente interpretados usados por não especialistas, porque o processo pode ser caro, difícil de escalar e apenas para tarefas específicas.
Além disso, alcançar a geração de uma linguagem semelhante à humana muitas vezes requer a incorporação de humanos no circuito para trazer avaliações qualitativas e julgamento humano para complementar as métricas de precisão automatizadas. A avaliação humana é um método valioso para avaliar os resultados do LLM, mas também pode ser subjetiva e sujeita a preconceitos porque diferentes avaliadores humanos podem ter opiniões e interpretações diversas sobre a qualidade do texto. Além disso, a avaliação humana pode consumir muitos recursos e ser dispendiosa e pode exigir tempo e esforço significativos.
Vamos nos aprofundar em como o Amazon SageMaker Clarify conecta os pontos perfeitamente, ajudando os clientes a realizar avaliação e seleção completas de modelos.
Avaliação LLM com Amazon SageMaker Clarify
O Amazon SageMaker Clarify ajuda os clientes a automatizar as métricas, incluindo, entre outras, precisão, robustez, toxicidade, estereótipos e conhecimento factual para automação, e estilo, coerência, relevância para avaliação baseada em humanos e métodos de avaliação, fornecendo uma estrutura para avaliar LLMs e serviços baseados em LLM, como Amazon Bedrock. Como um serviço totalmente gerenciado, o SageMaker Clarify simplifica o uso de estruturas de avaliação de código aberto no Amazon SageMaker. Os clientes podem selecionar conjuntos de dados e métricas de avaliação relevantes para seus cenários e estendê-los com seus próprios conjuntos de dados imediatos e algoritmos de avaliação. O SageMaker Clarify fornece resultados de avaliação em vários formatos para oferecer suporte a diferentes funções no fluxo de trabalho LLM. Os cientistas de dados podem analisar resultados detalhados com visualizações do SageMaker Clarify em notebooks, cartões de modelo do SageMaker e relatórios em PDF. Enquanto isso, as equipes de operações podem usar o Amazon SageMaker GroundTruth para revisar e anotar itens de alto risco identificados pelo SageMaker Clarify. Por exemplo, por estereotipagem, toxicidade, PII escapado ou baixa precisão.
Anotações e aprendizado por reforço são posteriormente empregados para mitigar riscos potenciais. Explicações amigáveis sobre os riscos identificados agilizam o processo de revisão manual, reduzindo assim os custos. Os relatórios resumidos oferecem aos intervenientes empresariais referências comparativas entre diferentes modelos e versões, facilitando a tomada de decisões informadas.
A figura a seguir mostra a estrutura para avaliar LLMs e serviços baseados em LLM:
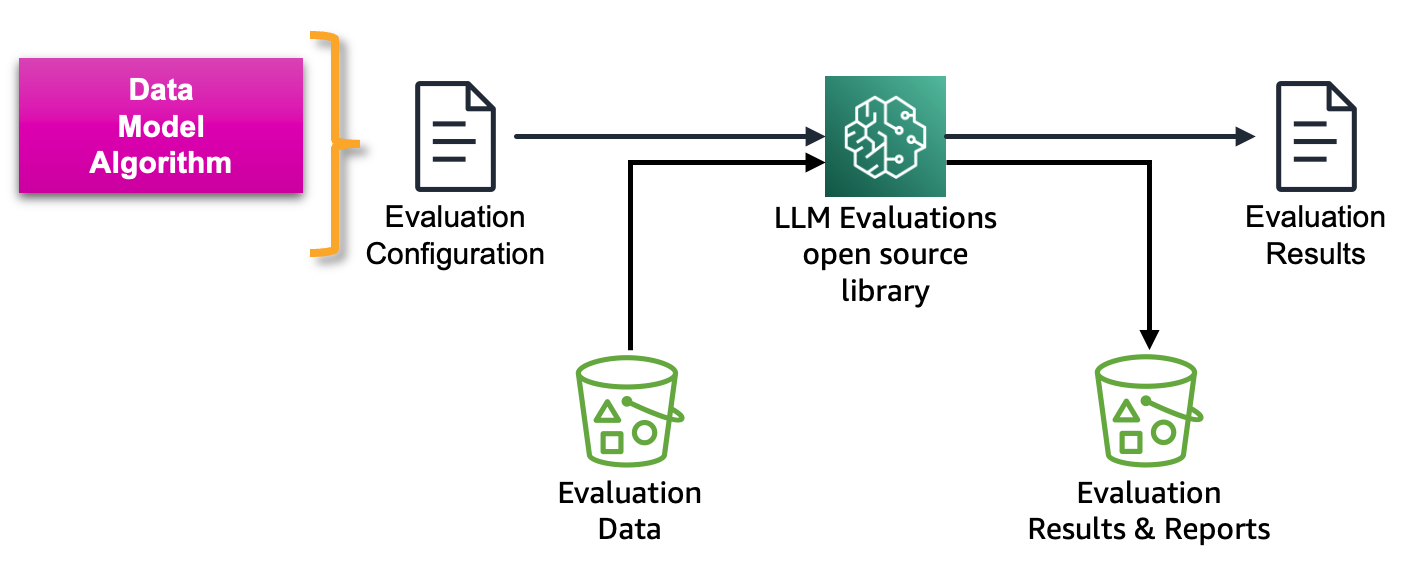
A avaliação Amazon SageMaker Clarify LLM é uma biblioteca Foundation Model Evaluation (FMEval) de código aberto desenvolvida pela AWS para ajudar os clientes a avaliar facilmente LLMs. Todas as funcionalidades também foram incorporadas ao Amazon SageMaker Studio para permitir a avaliação LLM para seus usuários. Nas seções a seguir, apresentamos a integração dos recursos de avaliação do Amazon SageMaker Clarify LLM com o SageMaker Pipelines para permitir a avaliação do LLM em escala usando princípios de MLOps.
Ciclo de vida de MLOps do Amazon SageMaker
Como a postagem “Roteiro básico de MLOps para empresas com o Amazon SageMaker” descreve, MLOps é a combinação de processos, pessoas e tecnologia para produzir casos de uso de ML com eficiência.
A figura a seguir mostra o ciclo de vida completo do MLOps:

Uma jornada típica começa com um cientista de dados criando um notebook de prova de conceito (PoC) para provar que o ML pode resolver um problema de negócios. Ao longo do desenvolvimento da Prova de Conceito (PoC), cabe ao cientista de dados converter os Indicadores Chave de Desempenho (KPIs) de negócios em métricas do modelo de aprendizado de máquina, como precisão ou taxa de falsos positivos, e utilizar um conjunto de dados de teste limitado para avaliar esses Métricas. Os cientistas de dados colaboram com engenheiros de ML para fazer a transição do código de notebooks para repositórios, criando pipelines de ML usando Amazon SageMaker Pipelines, que conectam várias etapas e tarefas de processamento, incluindo pré-processamento, treinamento, avaliação e pós-processamento, ao mesmo tempo em que incorporam continuamente novas produções. dados. A implantação do Amazon SageMaker Pipelines depende de interações de repositório e ativação de pipeline de CI/CD. O pipeline de ML mantém modelos de alto desempenho, imagens de contêiner, resultados de avaliação e informações de status em um registro de modelo, onde as partes interessadas do modelo avaliam o desempenho e decidem sobre a progressão para a produção com base nos resultados de desempenho e benchmarks, seguido pela ativação de outro pipeline de CI/CD para preparação e implantação de produção. Uma vez em produção, os consumidores de ML utilizam o modelo por meio de inferência acionada por aplicativo por meio de invocação direta ou chamadas de API, com ciclos de feedback para proprietários de modelos para avaliação contínua de desempenho.
Integração do Amazon SageMaker Clarify e MLOps
Seguindo o ciclo de vida do MLOps, os sintonizadores ou usuários de modelos de código aberto produzem modelos ajustados ou FM usando Amazon SageMaker Jumpstart e serviços MLOps, conforme descrito em Implementação de práticas de MLOps com modelos pré-treinados do Amazon SageMaker JumpStart. Isso levou a um novo domínio para operações de modelo básico (FMOps) e operações LLM (LLMOps) FMOps/LLMOps: Operacionalize IA generativa e diferenças com MLOps.
A figura a seguir mostra o ciclo de vida completo dos LLMOps:
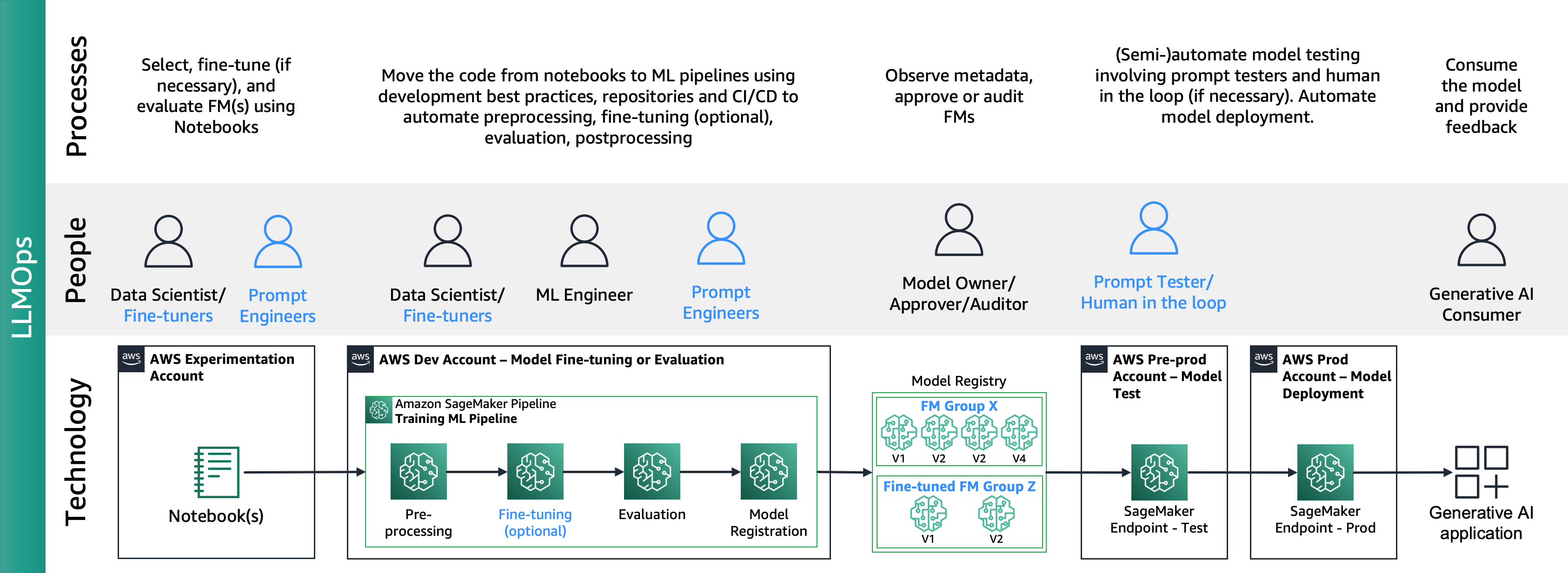
No LLMOps as principais diferenças em relação ao MLOps são a seleção e avaliação do modelo envolvendo diferentes processos e métricas. Na fase inicial de experimentação, os cientistas de dados (ou sintonizadores finos) selecionam o FM que será usado para um caso de uso específico de IA generativa.
Isso geralmente resulta no teste e no ajuste fino de vários FMs, alguns dos quais podem produzir resultados comparáveis. Após a seleção do(s) modelo(s), os engenheiros imediatos são responsáveis por preparar os dados de entrada necessários e os resultados esperados para avaliação (por exemplo, prompts de entrada compreendendo dados de entrada e consulta) e definir métricas como similaridade e toxicidade. Além dessas métricas, os cientistas de dados ou sintonizadores precisos devem validar os resultados e escolher o FM apropriado não apenas em métricas de precisão, mas em outros recursos, como latência e custo. Em seguida, eles podem implantar um modelo em um endpoint SageMaker e testar seu desempenho em pequena escala. Embora a fase de experimentação possa envolver um processo simples, a transição para a produção exige que os clientes automatizem o processo e melhorem a robustez da solução. Portanto, precisamos nos aprofundar em como automatizar a avaliação, permitindo que os testadores realizem avaliações eficientes em escala e implementando o monitoramento em tempo real da entrada e da saída do modelo.
Automatize a avaliação FM
O Amazon SageMaker Pipelines automatiza todas as fases de pré-processamento, ajuste fino de FM (opcional) e avaliação em escala. Dados os modelos selecionados durante a experimentação, os engenheiros de prompt precisam cobrir um conjunto maior de casos, preparando muitos prompts e armazenando-os em um repositório de armazenamento designado chamado catálogo de prompts. Para obter mais informações, consulte FMOps/LLMOps: Operacionalize IA generativa e diferenças com MLOps. Então, o Amazon SageMaker Pipelines pode ser estruturado da seguinte forma:
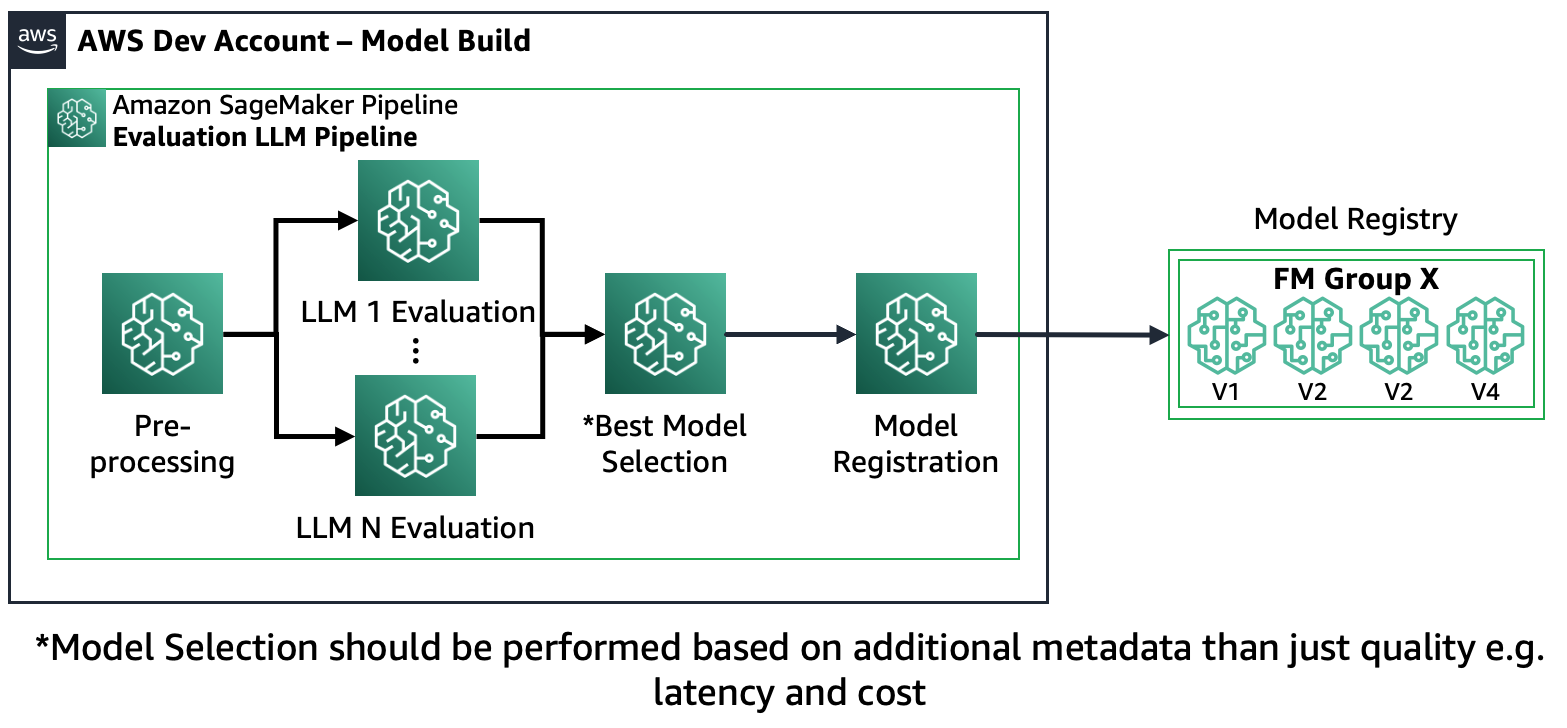
Cenário 1 – Avaliar vários FMs: Neste cenário, os FMs podem cobrir o caso de uso de negócios sem ajustes finos. O pipeline do Amazon SageMaker consiste nas seguintes etapas: pré-processamento de dados, avaliação paralela de vários FMs, comparação de modelos e seleção com base na precisão e outras propriedades, como custo ou latência, registro de artefatos de modelo selecionados e metadados.
O diagrama a seguir ilustra essa arquitetura.
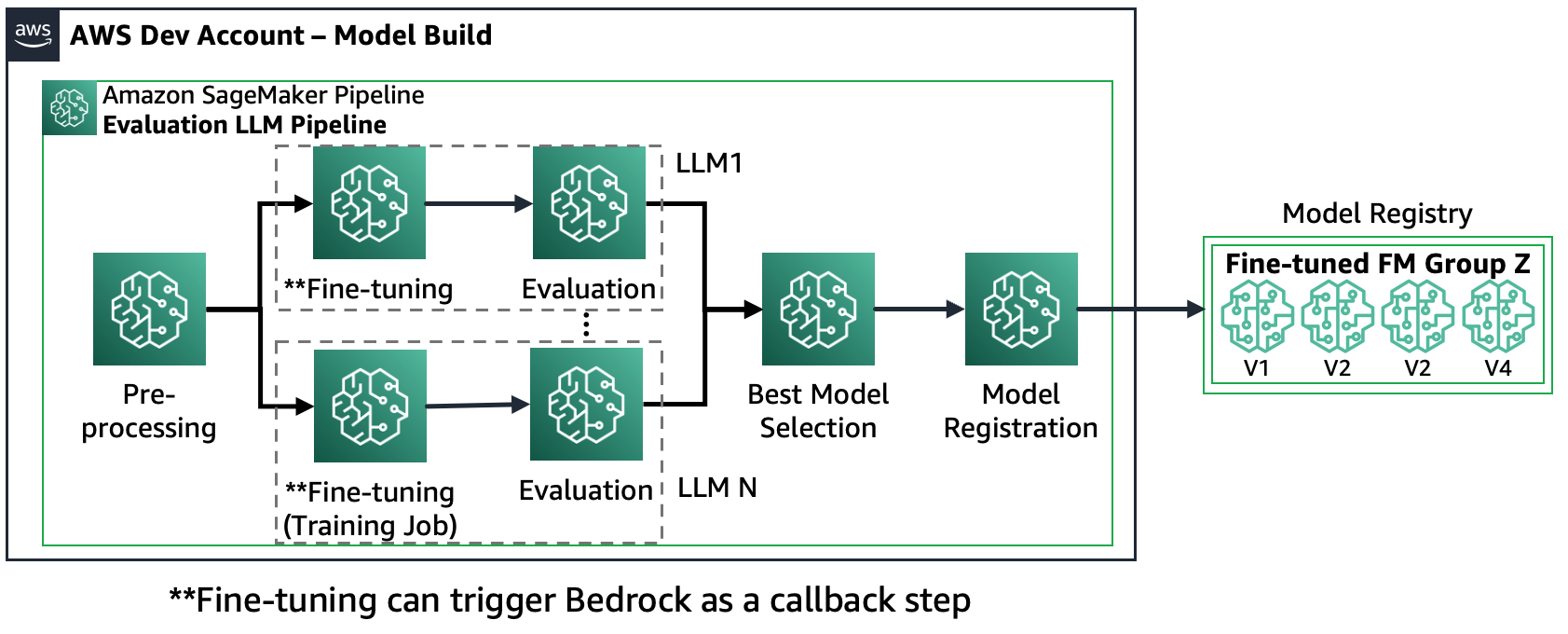
Cenário 2 – Ajustar e avaliar vários FMs: neste cenário, o Amazon SageMaker Pipeline é estruturado de forma semelhante ao Cenário 1, mas executa em paralelo as etapas de ajuste fino e avaliação para cada FM. O modelo melhor ajustado será registrado no Registro de Modelos.
O diagrama a seguir ilustra essa arquitetura.
Cenário 3 – Avaliar vários FMs e FMs ajustados: Este cenário é uma combinação de avaliação de FMs de uso geral e FMs ajustados. Neste caso, os clientes querem verificar se um modelo ajustado pode ter um desempenho melhor do que um FM de uso geral.
A figura a seguir mostra as etapas resultantes do SageMaker Pipeline.
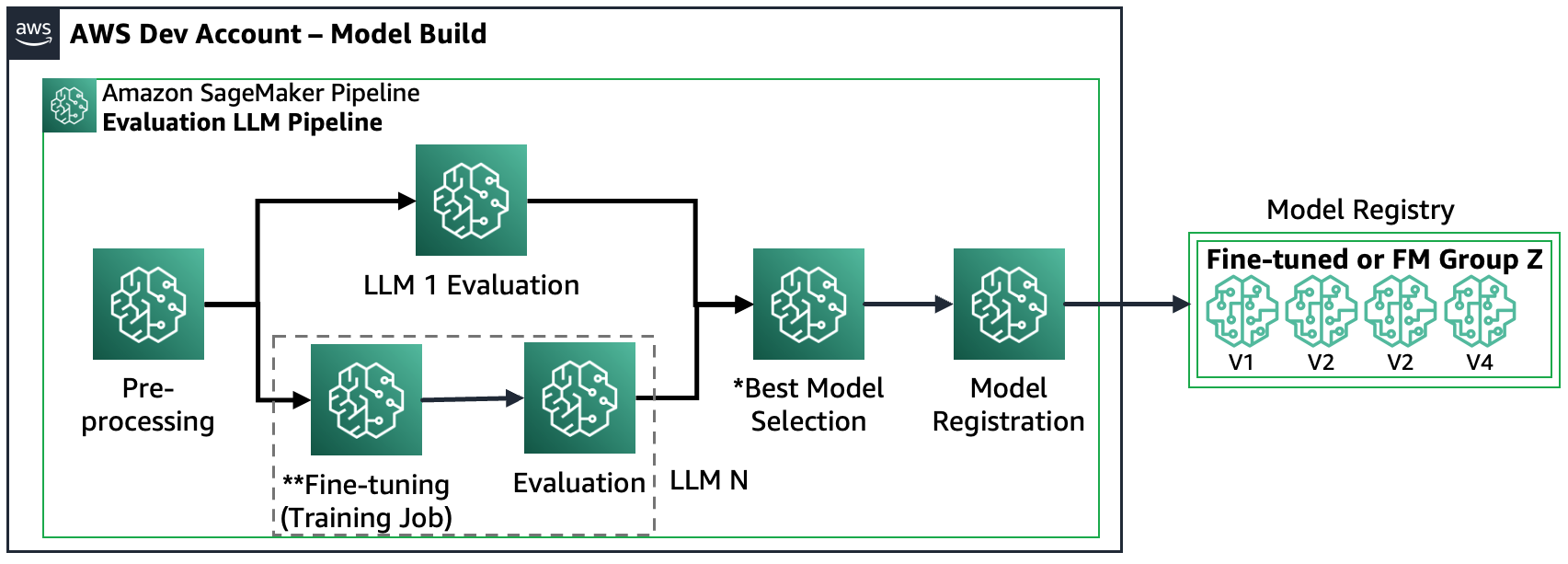
Observe que o registro do modelo segue dois padrões: (a) armazenar um modelo de código aberto e artefatos ou (b) armazenar uma referência a um FM proprietário. Para obter mais informações, consulte FMOps/LLMOps: Operacionalize IA generativa e diferenças com MLOps.
Visão geral da solução
Para acelerar sua jornada rumo à avaliação LLM em escala, criamos uma solução que implementa os cenários usando o Amazon SageMaker Clarify e o novo Amazon SageMaker Pipelines SDK. O exemplo de código, incluindo conjuntos de dados, notebooks de origem e pipelines do SageMaker (etapas e pipeline de ML), está disponível em GitHub. Para desenvolver esta solução de exemplo, usamos dois FMs: Llama2 e Falcon-7B. Nesta postagem, nosso foco principal está nos elementos-chave da solução SageMaker Pipeline que pertencem ao processo de avaliação.
Configuração de avaliação: Com o propósito de padronizar o procedimento de avaliação, criamos um arquivo de configuração YAML, (evaluation_config.yaml), que contém os detalhes necessários para o processo de avaliação incluindo o conjunto de dados, o(s) modelo(s) e os algoritmos a serem executados durante o processo de avaliação. etapa de avaliação do SageMaker Pipeline. O exemplo a seguir ilustra o arquivo de configuração:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Etapa de avaliação: O novo SageMaker Pipeline SDK oferece aos usuários a flexibilidade de definir etapas personalizadas no fluxo de trabalho de ML usando o decorador Python '@step'. Portanto, os usuários precisam criar um script Python básico que conduza a avaliação, conforme segue:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultPipeline do SageMaker: Depois de criar as etapas necessárias, como pré-processamento de dados, implantação de modelo e avaliação de modelo, o usuário precisa vincular as etapas usando o SageMaker Pipeline SDK. O novo SDK gera automaticamente o fluxo de trabalho interpretando as dependências entre diferentes etapas quando uma API de criação do SageMaker Pipeline é invocada, conforme mostrado no exemplo a seguir:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()O exemplo implementa a avaliação de um único FM pré-processando o conjunto de dados inicial, implantando o modelo e executando a avaliação. O gráfico acíclico direcionado ao pipeline (DAG) gerado é mostrado na figura a seguir.
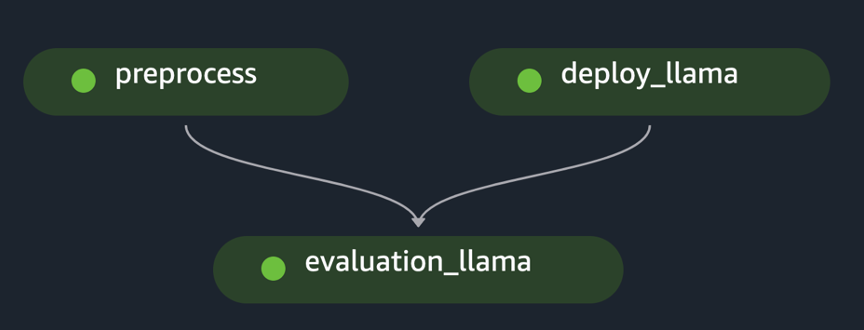
Seguindo uma abordagem semelhante e usando e adaptando o exemplo em Ajuste modelos LLaMA 2 no SageMaker JumpStart, criamos o pipeline para avaliar um modelo ajustado, conforme mostrado na figura a seguir.

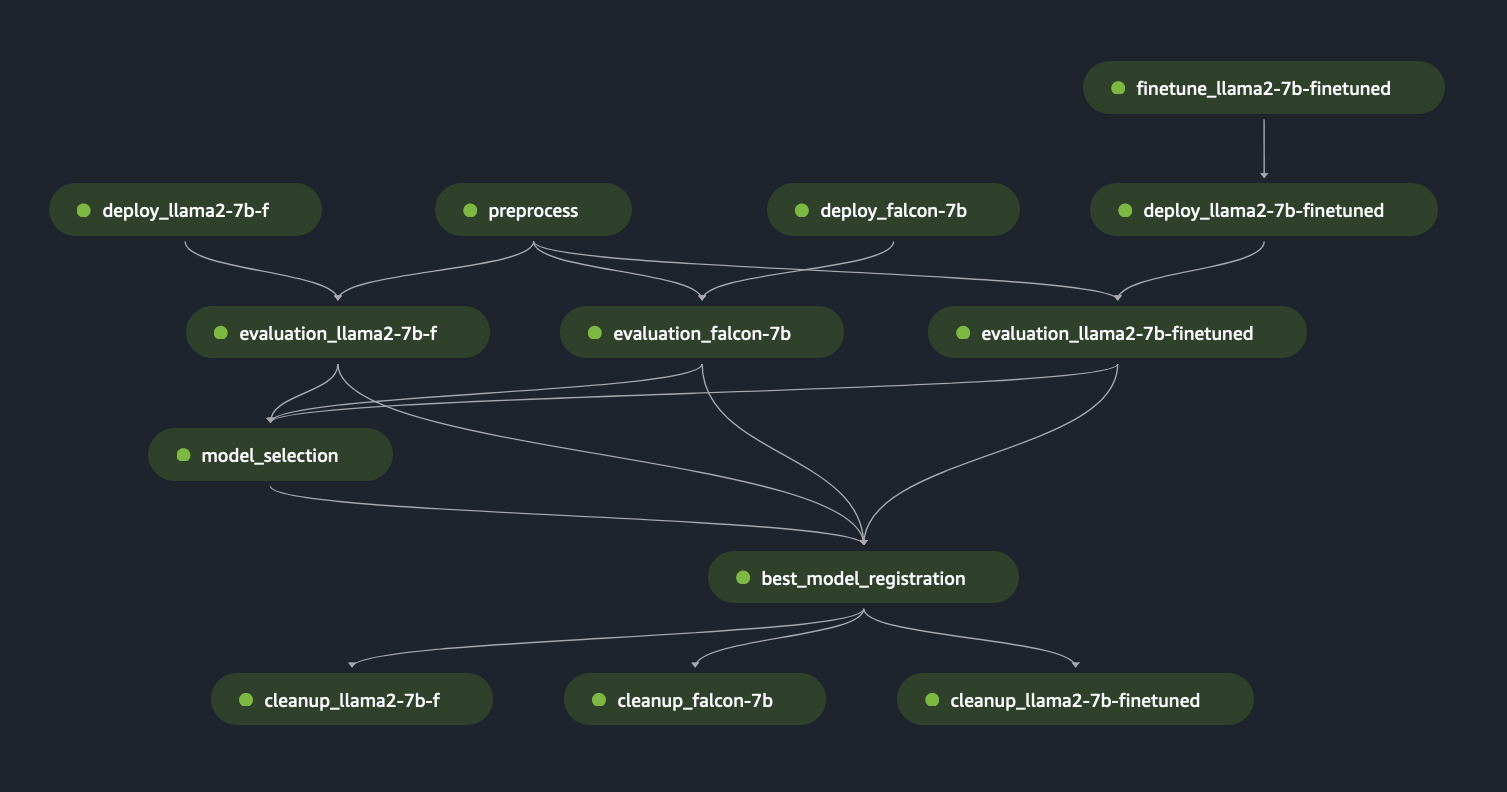
Usando as etapas anteriores do SageMaker Pipeline como blocos “Lego”, desenvolvemos a solução para o Cenário 1 e o Cenário 3, conforme mostrado nas figuras a seguir. Especificamente, o GitHub O repositório permite ao usuário avaliar vários FMs em paralelo ou realizar avaliações mais complexas, combinando a avaliação de modelos básicos e ajustados.


As funcionalidades adicionais disponíveis no repositório incluem o seguinte:
- Geração de etapa de avaliação dinâmica: Nossa solução gera todas as etapas de avaliação necessárias dinamicamente com base no arquivo de configuração para permitir que os usuários avaliem qualquer número de modelos. Ampliamos a solução para suportar uma fácil integração de novos tipos de modelos, como Hugging Face ou Amazon Bedrock.
- Impedir a reimplantação do endpoint: se um endpoint já estiver instalado, ignoramos o processo de implantação. Isso permite que o usuário reutilize endpoints com FMs para avaliação, resultando em economia de custos e redução do tempo de implantação.
- Limpeza de ponto final: Após a conclusão da avaliação, o SageMaker Pipeline desativa os endpoints implantados. Essa funcionalidade pode ser estendida para manter ativo o melhor endpoint do modelo.
- Etapa de seleção do modelo: Adicionamos um espaço reservado para etapa de seleção de modelo que requer a lógica de negócios da seleção final do modelo, incluindo critérios como custo ou latência.
- Etapa de registro do modelo: o melhor modelo pode ser registrado no Amazon SageMaker Model Registry como uma nova versão de um grupo de modelos específico.
- Piscina quente: Os pools quentes gerenciados pelo SageMaker permitem reter e reutilizar a infraestrutura provisionada após a conclusão de um trabalho para reduzir a latência para cargas de trabalho repetitivas
A figura a seguir ilustra esses recursos e um exemplo de avaliação multimodelo que os usuários podem criar de forma fácil e dinâmica usando nossa solução neste GitHub repositório.
Mantivemos intencionalmente a preparação de dados fora do escopo, pois ela será descrita em profundidade em uma postagem diferente, incluindo designs de catálogo de prompt, modelos de prompt e otimização de prompt. Para obter mais informações e definições de componentes relacionados, consulte FMOps/LLMOps: Operacionalize IA generativa e diferenças com MLOps.
Conclusão
Nesta postagem, nos concentramos em como automatizar e operacionalizar a avaliação de LLMs em escala usando recursos de avaliação de LLM do Amazon SageMaker Clarify e Amazon SageMaker Pipelines. Além dos projetos de arquitetura teórica, temos exemplos de código neste GitHub repositório (apresentando FMs Llama2 e Falcon-7B) para permitir que os clientes desenvolvam seus próprios mecanismos de avaliação escalonáveis.
A ilustração a seguir mostra a arquitetura de avaliação do modelo.

Nesta postagem, focamos na operacionalização da avaliação LLM em escala, conforme mostrado no lado esquerdo da ilustração. No futuro, nos concentraremos no desenvolvimento de exemplos que cumpram o ciclo de vida de ponta a ponta dos FMs até a produção, seguindo a diretriz descrita em FMOps/LLMOps: Operacionalize IA generativa e diferenças com MLOps. Isso inclui o serviço LLM, o monitoramento, o armazenamento da classificação de saída que eventualmente desencadeará a reavaliação automática e o ajuste fino e, por último, o uso de humanos no circuito para trabalhar em dados rotulados ou catálogo de prompts.
Sobre os autores
 Dr. é arquiteto principal de soluções especializadas em aprendizado de máquina e operações da Amazon Web Services. Sokratis se concentra em permitir que clientes corporativos industrializem suas soluções de aprendizado de máquina (ML) e IA generativa, explorando os serviços da AWS e moldando seu modelo operacional, ou seja, bases de MLOps/FMOps/LLMOps e roteiro de transformação aproveitando as melhores práticas de desenvolvimento. Ele passou mais de 15 anos inventando, projetando, liderando e implementando soluções inovadoras de ML e IA de nível de produção ponta a ponta nas áreas de energia, varejo, saúde, finanças, esportes motorizados, etc.
Dr. é arquiteto principal de soluções especializadas em aprendizado de máquina e operações da Amazon Web Services. Sokratis se concentra em permitir que clientes corporativos industrializem suas soluções de aprendizado de máquina (ML) e IA generativa, explorando os serviços da AWS e moldando seu modelo operacional, ou seja, bases de MLOps/FMOps/LLMOps e roteiro de transformação aproveitando as melhores práticas de desenvolvimento. Ele passou mais de 15 anos inventando, projetando, liderando e implementando soluções inovadoras de ML e IA de nível de produção ponta a ponta nas áreas de energia, varejo, saúde, finanças, esportes motorizados, etc.
 Jagdeep Singh Soni é arquiteto de soluções parceiro sênior da AWS com sede na Holanda. Ele usa sua paixão por DevOps, GenAI e ferramentas de construção para ajudar integradores de sistemas e parceiros de tecnologia. Jagdeep aplica sua experiência em desenvolvimento de aplicativos e arquitetura para impulsionar a inovação em sua equipe e promover novas tecnologias.
Jagdeep Singh Soni é arquiteto de soluções parceiro sênior da AWS com sede na Holanda. Ele usa sua paixão por DevOps, GenAI e ferramentas de construção para ajudar integradores de sistemas e parceiros de tecnologia. Jagdeep aplica sua experiência em desenvolvimento de aplicativos e arquitetura para impulsionar a inovação em sua equipe e promover novas tecnologias.
 Dr. Ricardo Gatti é um arquiteto sênior de soluções para startups baseado na Itália. Ele é um consultor técnico de clientes, ajudando-os a expandir seus negócios selecionando as ferramentas e tecnologias certas para inovar, escalar rapidamente e se tornarem globais em minutos. Ele sempre foi apaixonado por aprendizado de máquina e IA generativa, tendo estudado e aplicado essas tecnologias em diferentes domínios ao longo de sua carreira profissional. Ele é apresentador e editor do podcast italiano da AWS “Casa Startup”, dedicado a histórias de fundadores de startups e novas tendências tecnológicas.
Dr. Ricardo Gatti é um arquiteto sênior de soluções para startups baseado na Itália. Ele é um consultor técnico de clientes, ajudando-os a expandir seus negócios selecionando as ferramentas e tecnologias certas para inovar, escalar rapidamente e se tornarem globais em minutos. Ele sempre foi apaixonado por aprendizado de máquina e IA generativa, tendo estudado e aplicado essas tecnologias em diferentes domínios ao longo de sua carreira profissional. Ele é apresentador e editor do podcast italiano da AWS “Casa Startup”, dedicado a histórias de fundadores de startups e novas tendências tecnológicas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/

