Os modelos de linguagem generativa provaram ser extremamente hábeis na resolução de tarefas lógicas e analíticas de processamento de linguagem natural (PNL). Além disso, o uso de engenharia imediata podem melhorar notavelmente o seu desempenho. Por exemplo, cadeia de pensamento (CoT) é conhecido por melhorar a capacidade de um modelo para problemas complexos de várias etapas. Para aumentar ainda mais a precisão em tarefas que envolvem raciocínio, um autoconsistência foi sugerida uma abordagem de prompting, que substitui a decodificação gananciosa pela estocástica durante a geração da linguagem.
Rocha Amazônica é um serviço totalmente gerenciado que oferece uma escolha de modelos básicos de alto desempenho das principais empresas de IA e da Amazon por meio de uma única API, juntamente com um amplo conjunto de recursos para construir IA generativa aplicativos com segurança, privacidade e IA responsável. Com o inferência em lote API, você pode usar o Amazon Bedrock para executar inferência com modelos básicos em lotes e obter respostas com mais eficiência. Esta postagem mostra como implementar solicitações de autoconsistência por meio de inferência em lote no Amazon Bedrock para melhorar o desempenho do modelo em tarefas de raciocínio aritmético e de múltipla escolha.
Visão geral da solução
A solicitação de autoconsistência de modelos de linguagem depende da geração de múltiplas respostas que são agregadas em uma resposta final. Em contraste com abordagens de geração única como CoT, o procedimento de amostragem e marginalização de autoconsistência cria uma gama de conclusões de modelo que levam a uma solução mais consistente. A geração de diferentes respostas para um determinado prompt é possível devido ao uso de uma estratégia de decodificação estocástica, em vez de gananciosa.
A figura a seguir mostra como a autoconsistência difere do CoT ganancioso, pois gera um conjunto diversificado de caminhos de raciocínio e os agrega para produzir a resposta final.

Estratégias de decodificação para geração de texto
O texto gerado por modelos de linguagem somente decodificadores se desdobra palavra por palavra, com o token subsequente sendo previsto com base no contexto anterior. Para um determinado prompt, o modelo calcula uma distribuição de probabilidade indicando a probabilidade de cada token aparecer em seguida na sequência. A decodificação envolve a tradução dessas distribuições de probabilidade em texto real. A geração de texto é mediada por um conjunto de parâmetros de inferência que geralmente são hiperparâmetros do próprio método de decodificação. Um exemplo é o temperatura, que modula a distribuição de probabilidade do próximo token e influencia a aleatoriedade da saída do modelo.
Decodificação gananciosa é uma estratégia de decodificação determinística que a cada etapa seleciona o token com maior probabilidade. Embora simples e eficiente, a abordagem corre o risco de cair em padrões repetitivos, porque desconsidera o espaço de probabilidade mais amplo. Definir o parâmetro de temperatura como 0 no momento da inferência equivale essencialmente à implementação de uma decodificação gananciosa.
Amostragem introduz estocasticidade no processo de decodificação selecionando aleatoriamente cada token subsequente com base na distribuição de probabilidade prevista. Essa aleatoriedade resulta em maior variabilidade de saída. A decodificação estocástica mostra-se mais adequada para capturar a diversidade de resultados potenciais e muitas vezes produz respostas mais imaginativas. Valores de temperatura mais elevados introduzem mais flutuações e aumentam a criatividade da resposta do modelo.
Técnicas de estímulo: CoT e autoconsistência
A capacidade de raciocínio dos modelos de linguagem pode ser aumentada por meio de engenharia imediata. Em particular, o CoT demonstrou provocar raciocínio em tarefas complexas de PNL. Uma maneira de implementar um tiro zero CoT é via aumento imediato com a instrução para “pensar passo a passo”. Outra é expor o modelo a exemplos de etapas intermediárias de raciocínio em solicitação de poucos tiros moda. Ambos os cenários normalmente usam decodificação gananciosa. CoT leva a ganhos significativos de desempenho em comparação com instruções simples em tarefas de aritmética, bom senso e raciocínio simbólico.
Solicitação de autoconsistência baseia-se no pressuposto de que a introdução da diversidade no processo de raciocínio pode ser benéfica para ajudar os modelos a convergirem para a resposta correta. A técnica utiliza decodificação estocástica para atingir esse objetivo em três etapas:
- Solicite o modelo de linguagem com exemplares CoT para suscitar o raciocínio.
- Substitua a decodificação gananciosa por uma estratégia de amostragem para gerar um conjunto diversificado de caminhos de raciocínio.
- Agregue os resultados para encontrar a resposta mais consistente no conjunto de respostas.
É demonstrado que a autoconsistência supera o prompt CoT em benchmarks populares de aritmética e raciocínio de bom senso. Uma limitação da abordagem é seu maior custo computacional.
Esta postagem mostra como a solicitação de autoconsistência melhora o desempenho de modelos de linguagem generativa em duas tarefas de raciocínio da PNL: resolução de problemas aritméticos e resposta a perguntas específicas de domínio de múltipla escolha. Demonstramos a abordagem usando inferência em lote no Amazon Bedrock:
- Acessamos o Amazon Bedrock Python SDK no JupyterLab em um Amazon Sage Maker instância do notebook.
- Para raciocínio aritmético, solicitamos Comando Cohere no conjunto de dados GSM8K de problemas de matemática do ensino fundamental.
- Para raciocínio de múltipla escolha, solicitamos AI21 Labs Jurássico-2 Médio em uma pequena amostra de perguntas do exame AWS Certified Solutions Architect – Associate.
Pré-requisitos
Este passo a passo pressupõe os seguintes pré-requisitos:

O custo estimado para executar o código mostrado nesta postagem é de US$ 100, assumindo que você execute o prompt de autoconsistência uma vez com 30 caminhos de raciocínio usando um valor para a amostragem baseada em temperatura.
Conjunto de dados para testar capacidades de raciocínio aritmético
GSM8K é um conjunto de dados de problemas de matemática escolares montados por humanos, apresentando uma alta diversidade linguística. Cada problema leva de 2 a 8 etapas para ser resolvido e requer a execução de uma sequência de cálculos elementares com operações aritméticas básicas. Esses dados são comumente usados para avaliar as capacidades de raciocínio aritmético em várias etapas dos modelos de linguagem generativa. O Conjunto de trem GSM8K compreende 7,473 registros. O seguinte é um exemplo:
{"question": "Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?", "answer": "Natalia sold 48/2 = <<48/2=24>>24 clips in May.nNatalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May.n#### 72"}
Configure para executar inferência em lote com Amazon Bedrock
A inferência em lote permite executar várias chamadas de inferência para o Amazon Bedrock de forma assíncrona e melhorar o desempenho da inferência de modelo em grandes conjuntos de dados. O serviço está em versão prévia no momento desta redação e está disponível apenas por meio da API. Referir-se Executar inferência em lote para acessar APIs de inferência em lote por meio de SDKs personalizados.
Depois de baixar e descompactar o SDK do Python em uma instância de notebook SageMaker, você pode instalá-lo executando o seguinte código em uma célula de notebook Jupyter:
Formate e faça upload de dados de entrada para o Amazon S3
Os dados de entrada para inferência em lote precisam ser preparados no formato JSONL com recordId e modelInput chaves. Este último deve corresponder ao campo corporal do modelo a ser invocado no Amazon Bedrock. Em particular, alguns parâmetros de inferência suportados para o comando Cohere e guarante que os mesmos estão temperature por aleatoriedade, max_tokens para comprimento de saída, e num_generations para gerar múltiplas respostas, todas as quais são passadas junto com o prompt as modelInput:
See Parâmetros de inferência para modelos de fundação para obter mais detalhes, incluindo outros fornecedores de modelos.
Nossos experimentos sobre raciocínio aritmético são realizados na configuração de poucas tomadas, sem personalização ou ajuste fino do Cohere Command. Usamos o mesmo conjunto de oito exemplares de poucas tomadas da cadeia de pensamento (tabela 20) e autoconsistência (tabela 17) papéis. Os prompts são criados concatenando os exemplares com cada pergunta do conjunto de trens GSM8K.
Montamos max_tokens para 512 e num_generations para 5, o máximo permitido pelo Comando Cohere. Para decodificação gananciosa, definimos temperature para 0 e para autoconsistência, realizamos três experimentos nas temperaturas 0.5, 0.7 e 1. Cada configuração produz dados de entrada diferentes de acordo com os respectivos valores de temperatura. Os dados são formatados como JSONL e armazenados no Amazon S3.
Crie e execute trabalhos de inferência em lote no Amazon Bedrock
A criação de trabalhos de inferência em lote requer um cliente Amazon Bedrock. Especificamos os caminhos de entrada e saída do S3 e damos a cada trabalho de invocação um nome exclusivo:
Os empregos são criado passando a função do IAM, o ID do modelo, o nome do trabalho e a configuração de entrada/saída como parâmetros para a API do Amazon Bedrock:
listagem, monitoração e paragem trabalhos de inferência em lote são suportados por suas respectivas chamadas de API. Na criação, os empregos aparecem primeiro como Submitted, então como InProgress, e finalmente como Stopped, Failedou Completed.
Se os trabalhos forem concluídos com êxito, o conteúdo gerado poderá ser recuperado do Amazon S3 usando seu local de saída exclusivo.
[Out]: 'Natalia sold 48 * 1/2 = 24 clips less in May. This means she sold 48 + 24 = 72 clips in April and May. The answer is 72.'
A autoconsistência aumenta a precisão do modelo em tarefas aritméticas
A solicitação de autoconsistência do Comando Cohere supera uma linha de base CoT gananciosa em termos de precisão no conjunto de dados GSM8K. Para autoconsistência, amostramos 30 caminhos de raciocínio independentes em três temperaturas diferentes, com topP e topK definido para seu valores padrão. As soluções finais são agregadas escolhendo a ocorrência mais consistente por votação majoritária. Em caso de empate, escolhemos aleatoriamente uma das respostas majoritárias. Calculamos valores de precisão e desvio padrão calculados em média em 100 execuções.
A figura a seguir mostra a precisão do conjunto de dados GSM8K do Cohere Command solicitado com CoT ganancioso (azul) e autoconsistência nos valores de temperatura 0.5 (amarelo), 0.7 (verde) e 1.0 (laranja) em função do número de amostras amostradas. caminhos de raciocínio.
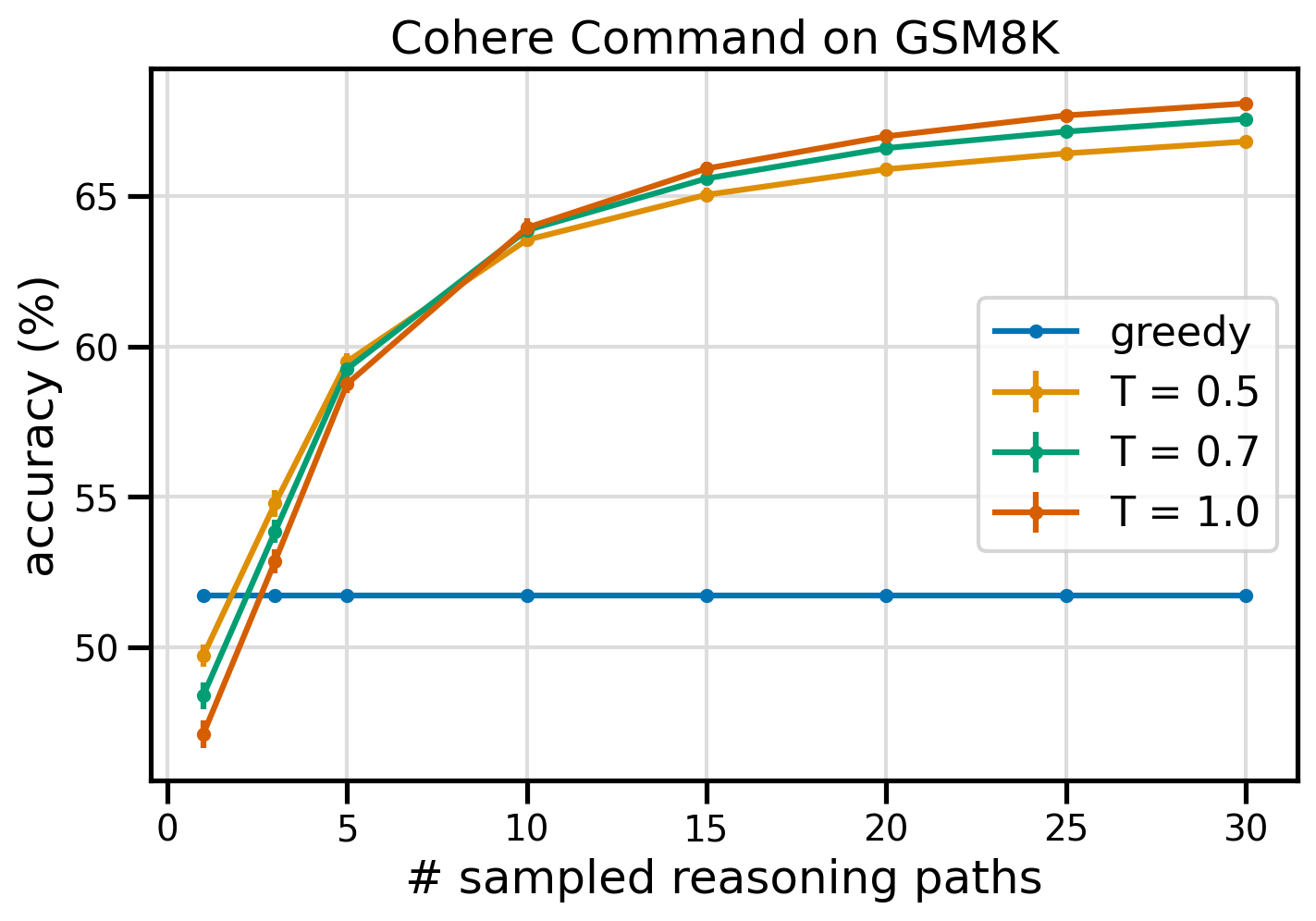
A figura anterior mostra que a autoconsistência aumenta a precisão aritmética em relação ao CoT ganancioso quando o número de caminhos amostrados é tão baixo quanto três. O desempenho aumenta consistentemente com novos caminhos de raciocínio, confirmando a importância de introduzir diversidade na geração de pensamento. O Cohere Command resolve o conjunto de questões GSM8K com 51.7% de precisão quando solicitado com CoT vs. 68% com 30 caminhos de raciocínio autoconsistentes em T = 1.0. Todos os três valores de temperatura pesquisados produzem resultados semelhantes, com temperaturas mais baixas tendo comparativamente melhor desempenho em caminhos menos amostrados.
Considerações práticas sobre eficiência e custo
A autoconsistência é limitada pelo aumento do tempo de resposta e dos custos incorridos ao gerar múltiplas saídas por prompt. Como ilustração prática, a inferência em lote para geração gananciosa com o Cohere Command em 7,473 registros GSM8K foi concluída em menos de 20 minutos. O trabalho utilizou 5.5 milhões de tokens como entrada e gerou 630,000 tokens de saída. No momento Preços de inferência do Amazon Bedrock, o custo total incorrido foi de cerca de US$ 9.50.
Para autoconsistência com o Comando Cohere, usamos o parâmetro de inferência num_generations para criar várias conclusões por prompt. No momento em que este livro foi escrito, o Amazon Bedrock permitia no máximo cinco gerações e três Submitted trabalhos de inferência em lote. Os trabalhos seguem para o InProgress status sequencialmente, portanto, a amostragem de mais de cinco caminhos requer múltiplas invocações.
A figura a seguir mostra os tempos de execução do Cohere Command no conjunto de dados GSM8K. O tempo de execução total é mostrado no eixo x e o tempo de execução por caminho de raciocínio amostrado no eixo y. A geração gananciosa é executada no menor tempo, mas incorre em um custo de tempo maior por caminho amostrado.

A geração gananciosa é concluída em menos de 20 minutos para o conjunto GSM8K completo e mostra um caminho de raciocínio exclusivo. A autoconsistência com cinco amostras requer cerca de 50% mais tempo para ser concluída e custa cerca de US$ 14.50, mas produz cinco caminhos (mais de 500%) nesse tempo. O tempo total de execução e o custo aumentam gradativamente a cada cinco caminhos extras amostrados. Uma análise de custo-benefício sugere que 1–2 trabalhos de inferência em lote com 5–10 caminhos amostrados é a configuração recomendada para implementação prática de autoconsistência. Isso alcança um desempenho aprimorado do modelo, mantendo o custo e a latência sob controle.
A autoconsistência melhora o desempenho do modelo além do raciocínio aritmético
Uma questão crucial para provar a adequação da solicitação de autoconsistência é se o método tem sucesso em outras tarefas e modelos de linguagem de PNL. Como uma extensão de um caso de uso relacionado à Amazon, realizamos uma pequena análise em exemplos de perguntas do Certificação AWS Solutions Architect Associate. Este é um exame de múltipla escolha sobre tecnologia e serviços AWS que requer conhecimento de domínio e capacidade de raciocinar e decidir entre diversas opções.
Preparamos um conjunto de dados de SAA-C01 e SAA-C03 exemplos de perguntas do exame. Das 20 questões disponíveis, usamos as 4 primeiras como exemplos de poucas tentativas e solicitamos que o modelo responda às 16 restantes. Desta vez, executamos inferência com o modelo AI21 Labs Jurassic-2 Mid e geramos no máximo 10 caminhos de raciocínio em temperatura 0.7. Os resultados mostram que a autoconsistência melhora o desempenho: embora o CoT ganancioso produza 11 respostas corretas, a autoconsistência tem sucesso em mais 2.
A tabela a seguir mostra os resultados de precisão para 5 e 10 caminhos amostrados com média de 100 execuções.
| . | Decodificação gananciosa | T = 0.7 |
| # caminhos amostrados: 5 | 68.6 | 74.1 ± 0.7 |
| # caminhos amostrados: 10 | 68.6 | 78.9 ± 0.3 |
Na tabela a seguir, apresentamos duas questões do exame que são respondidas incorretamente pelo CoT ganancioso enquanto a autoconsistência é bem-sucedida, destacando em cada caso os traços de raciocínio corretos (verde) ou incorretos (vermelho) que levaram o modelo a produzir respostas corretas ou incorretas. Embora nem todos os caminhos amostrados gerados pela autoconsistência estejam corretos, a maioria converge para a resposta verdadeira à medida que o número de caminhos amostrados aumenta. Observamos que 5 a 10 caminhos são normalmente suficientes para melhorar os resultados gananciosos, com retornos decrescentes em termos de eficiência além desses valores.
| Questão |
Um aplicativo da web permite que os clientes carreguem pedidos em um bucket S3. Os eventos resultantes do Amazon S3 acionam uma função Lambda que insere uma mensagem em uma fila SQS. Uma única instância do EC2 lê mensagens da fila, processa-as e armazena-as em uma tabela DynamoDB particionada por ID de pedido exclusivo. Espera-se que o tráfego no próximo mês aumente por um fator de 10 e um arquiteto de soluções está revisando a arquitetura em busca de possíveis problemas de dimensionamento. Qual componente tem MAIS probabilidade de precisar de re-arquitetura para poder ser dimensionado para acomodar o novo tráfego? A. Função Lambda |
Um aplicativo em execução na AWS usa uma implantação de cluster de banco de dados Amazon Aurora Multi-AZ para seu banco de dados. Ao avaliar as métricas de desempenho, um arquiteto de soluções descobriu que as leituras do banco de dados estão causando alta E/S e adicionando latência às solicitações de gravação no banco de dados. O que o arquiteto de soluções deve fazer para separar as solicitações de leitura das solicitações de gravação? A. Habilite o cache de leitura no banco de dados Aurora. |
| Resposta correta | C – Uma única instância do EC2 não será escalonável e é um ponto único de falha na arquitetura. Uma solução muito melhor seria fazer com que as instâncias do EC2 em um grupo de Auto Scaling em 2 zonas de disponibilidade lessem mensagens da fila. As outras respostas são todos serviços gerenciados que podem ser configurados para escalar ou serão escalados automaticamente. | C – As réplicas do Aurora fornecem uma maneira de descarregar o tráfego de leitura. As réplicas do Aurora compartilham o mesmo armazenamento subjacente do banco de dados principal, portanto, o tempo de atraso geralmente é muito baixo. As réplicas do Aurora têm seus próprios endpoints, portanto, o aplicativo precisará ser configurado para direcionar o tráfego de leitura para os novos endpoints. |
| Decodificação gananciosa | Pode não ser possível dimensionar diretamente a instância do EC2, pois pode não ser possível redimensionar a instância. Dimensionar a função Lambda pode não ser suficiente, já que as funções Lambda têm um limite de alocação de memória de 6 GB. Dimensionar a fila SQS pode não ser suficiente, já que o SQS tem um limite de 10,000 mensagens. As tabelas do DynamoDB podem ser dimensionadas provisionando mais unidades de capacidade. A resposta correta é d. | Modificando o aplicativo para ler a instância em espera do Multi-AZ (opção B) é a melhor abordagem. A instância em espera é replicada de forma assíncrona a partir da instância primária, portanto, as operações de leitura não interferirão nas operações de gravação. Habilitando o cache de leitura (opção A) ou criar uma réplica do Aurora (opção C) não resolverá o problema de contenção de E/S. Criar um segundo banco de dados Aurora e vinculá-lo como uma réplica de leitura (opção D) também não resolverá o problema de contenção de E/S. A resposta correta é b. |
| Caminho amostrado nº 1 | Dimensionar a instância EC2 para 10 vezes o seu tamanho atual pode não ser viável, seja do ponto de vista de custo ou de desempenho. Seria necessária uma instância maior, o que pode ser caro. Uma abordagem mais econômica poderia ser usar um enxame de instâncias menores (por exemplo, Grupo de Auto Scaling) para compartilhar a carga. Nesse caso, a instância EC2 provavelmente precisaria ser reprojetada. A resposta correta é C. | Modificar o aplicativo para usar os terminais apropriados não é uma solução prática, pois exigiria alterações no código do aplicativo. A resposta correta é C: Crie uma réplica do Aurora e modifique o aplicativo para usar os endpoints apropriados. |
| Caminho amostrado nº 2 | Escalar uma única instância do EC2 é mais difícil e problemático do que escalar outros componentes de serviço. Amazon SQS, Lambda e DynamoDB podem ser dimensionados automaticamente para lidar com o aumento da carga. A resposta correta é C. |
(C) Crie uma réplica do Aurora e modifique o aplicativo para usar os endpoints apropriados. Ao configurar uma réplica do Aurora, você pode separar o tráfego de leitura do tráfego de gravação. As réplicas do Aurora usam URLs de endpoint diferentes, permitindo direcionar o tráfego de leitura para a réplica em vez do banco de dados primário. A réplica pode processar solicitações de leitura em paralelo com solicitações de gravação no banco de dados primário, reduzindo E/S e latência. |
limpar
A execução de inferência em lote no Amazon Bedrock está sujeita a cobranças de acordo com os preços do Amazon Bedrock. Ao concluir o passo a passo, exclua a instância do notebook SageMaker e remova todos os dados dos buckets S3 para evitar cobranças futuras.
Considerações
Embora a solução demonstrada mostre um melhor desempenho dos modelos de linguagem quando solicitada com autoconsistência, é importante observar que o passo a passo não está pronto para produção. Antes de implantar em produção, você deve adaptar esta prova de conceito à sua própria implementação, tendo em mente os seguintes requisitos:
- Restrição de acesso a APIs e bancos de dados para evitar uso não autorizado.
- Aderência às práticas recomendadas de segurança da AWS em relação ao acesso a funções do IAM e grupos de segurança.
- Validação e higienização da entrada do usuário para evitar ataques de injeção imediata.
- Monitoramento e registro de processos acionados para permitir testes e auditoria.
Conclusão
Esta postagem mostra que a solicitação de autoconsistência melhora o desempenho de modelos de linguagem generativos em tarefas complexas de PNL que exigem habilidades lógicas aritméticas e de múltipla escolha. A autoconsistência usa decodificação estocástica baseada em temperatura para gerar vários caminhos de raciocínio. Isso aumenta a capacidade do modelo de suscitar pensamentos diversos e úteis para chegar a respostas corretas.
Com a inferência em lote do Amazon Bedrock, o modelo de linguagem Cohere Command é solicitado a gerar respostas autoconsistentes para um conjunto de problemas aritméticos. A precisão melhora de 51.7% com decodificação gananciosa para 68% com amostragem autoconsistente de 30 caminhos de raciocínio em T = 1.0. A amostragem de cinco caminhos já aumenta a precisão em 7.5 pontos percentuais. A abordagem é transferível para outros modelos de linguagem e tarefas de raciocínio, conforme demonstrado pelos resultados do modelo AI21 Labs Jurassic-2 Mid em um exame de Certificação AWS. Em um conjunto de perguntas de tamanho pequeno, a autoconsistência com cinco caminhos amostrados aumenta a precisão em 5 pontos percentuais em relação ao CoT ganancioso.
Incentivamos você a implementar solicitações de autoconsistência para melhorar o desempenho em seus próprios aplicativos com modelos de linguagem generativos. Aprender mais sobre Comando Cohere e AI21 Laboratórios Jurássico modelos disponíveis no Amazon Bedrock. Para obter mais informações sobre inferência em lote, consulte Executar inferência em lote.
Agradecimentos
O autor agradece aos revisores técnicos Amin Tajgardoon e Patrick McSweeney pelos comentários úteis.
Sobre o autor

Lúcia Santamaria é cientista aplicada sênior na Universidade de ML da Amazon, onde se concentra em aumentar o nível de competência em ML em toda a empresa por meio de educação prática. Lucía é doutorada em astrofísica e é apaixonada por democratizar o acesso ao conhecimento e às ferramentas tecnológicas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/enhance-performance-of-generative-language-models-with-self-consistency-prompting-on-amazon-bedrock/

