Estúdio Amazon SageMaker fornece uma solução totalmente gerenciada para que cientistas de dados construam, treinem e implantem modelos de aprendizado de máquina (ML) de forma interativa. No processo de trabalho em suas tarefas de ML, os cientistas de dados normalmente iniciam seu fluxo de trabalho descobrindo fontes de dados relevantes e conectando-se a elas. Em seguida, eles usam SQL para explorar, analisar, visualizar e integrar dados de várias fontes antes de usá-los em seu treinamento e inferência de ML. Anteriormente, os cientistas de dados muitas vezes se viam fazendo malabarismos com diversas ferramentas para dar suporte ao SQL em seu fluxo de trabalho, o que prejudicava a produtividade.
Temos o prazer de anunciar que os notebooks JupyterLab no SageMaker Studio agora vêm com suporte integrado para SQL. Os cientistas de dados agora podem:
- Conecte-se a serviços de dados populares, incluindo Amazona atena, Amazon RedShift, Zona de dados da Amazone Snowflake diretamente nos notebooks
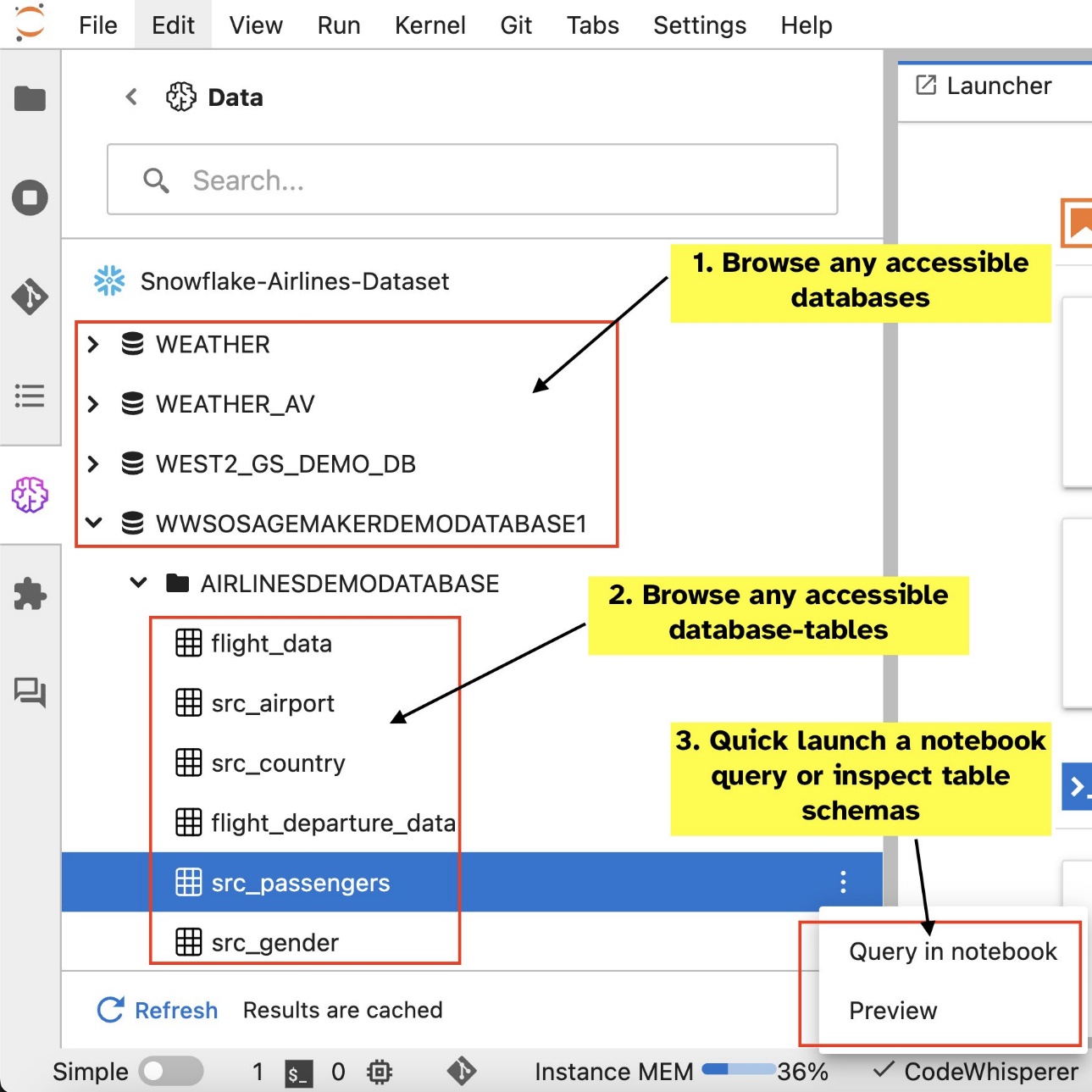
- Navegue e pesquise bancos de dados, esquemas, tabelas e visualizações e visualize dados na interface do notebook
- Misture código SQL e Python no mesmo notebook para exploração e transformação eficiente de dados para uso em projetos de ML
- Use recursos de produtividade do desenvolvedor, como conclusão de comandos SQL, assistência à formatação de código e realce de sintaxe para ajudar a acelerar o desenvolvimento de código e melhorar a produtividade geral do desenvolvedor
Além disso, os administradores podem gerenciar com segurança as conexões com esses serviços de dados, permitindo que os cientistas de dados acessem dados autorizados sem a necessidade de gerenciar credenciais manualmente.
Nesta postagem, orientamos você na configuração desse recurso no SageMaker Studio e nos vários recursos desse recurso. Em seguida, mostramos como você pode aprimorar a experiência SQL no notebook usando recursos de Text-to-SQL fornecidos por modelos avançados de linguagem grande (LLMs) para escrever consultas SQL complexas usando texto em linguagem natural como entrada. Finalmente, para permitir que um público mais amplo de usuários gere consultas SQL a partir de entrada de linguagem natural em seus notebooks, mostramos como implantar esses modelos Text-to-SQL usando Amazon Sage Maker pontos finais.
Visão geral da solução
Com a integração SQL do notebook SageMaker Studio JupyterLab, agora você pode se conectar a fontes de dados populares como Snowflake, Athena, Amazon Redshift e Amazon DataZone. Este novo recurso permite executar diversas funções.
Por exemplo, você pode explorar visualmente fontes de dados como bancos de dados, tabelas e esquemas diretamente de seu ecossistema JupyterLab. Se os ambientes do seu notebook estiverem executando o SageMaker Distribution 1.6 ou superior, procure um novo widget no lado esquerdo da interface do JupyterLab. Essa adição aprimora a acessibilidade e o gerenciamento de dados em seu ambiente de desenvolvimento.
Se você não estiver usando a distribuição sugerida do SageMaker (1.5 ou inferior) ou em um ambiente personalizado, consulte o apêndice para obter mais informações.
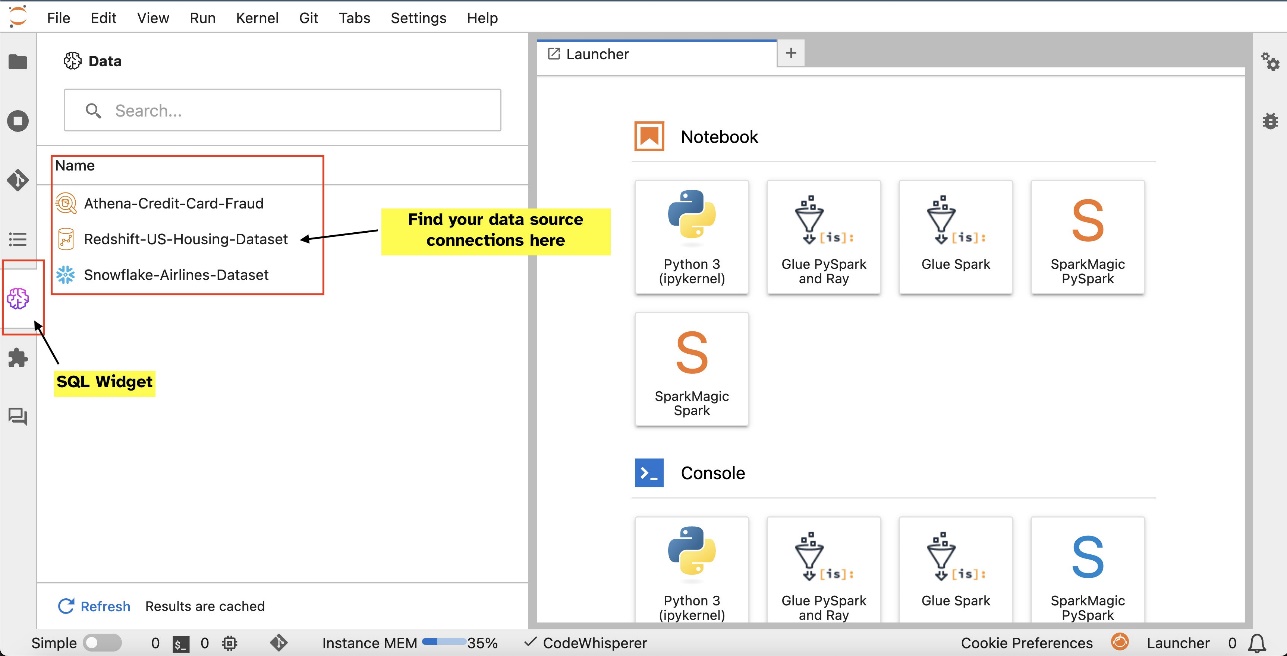
Depois de configurar as conexões (ilustradas na próxima seção), você poderá listar conexões de dados, navegar em bancos de dados e tabelas e inspecionar esquemas.
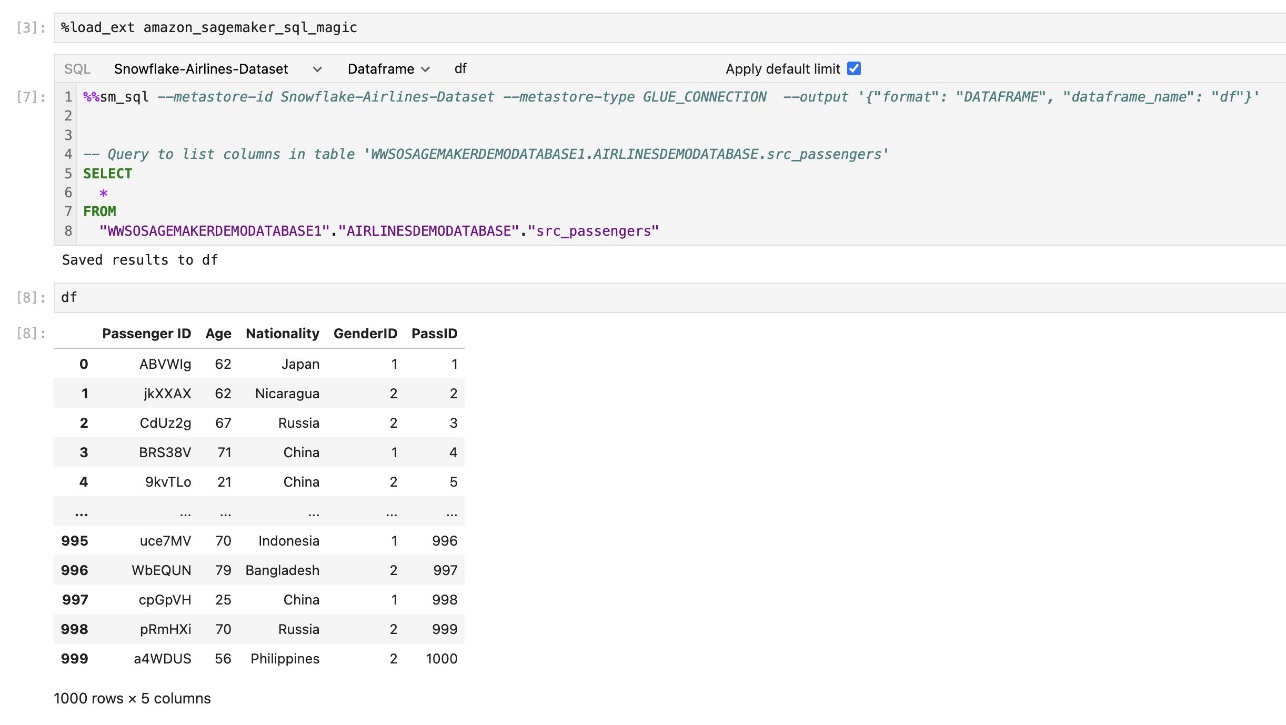
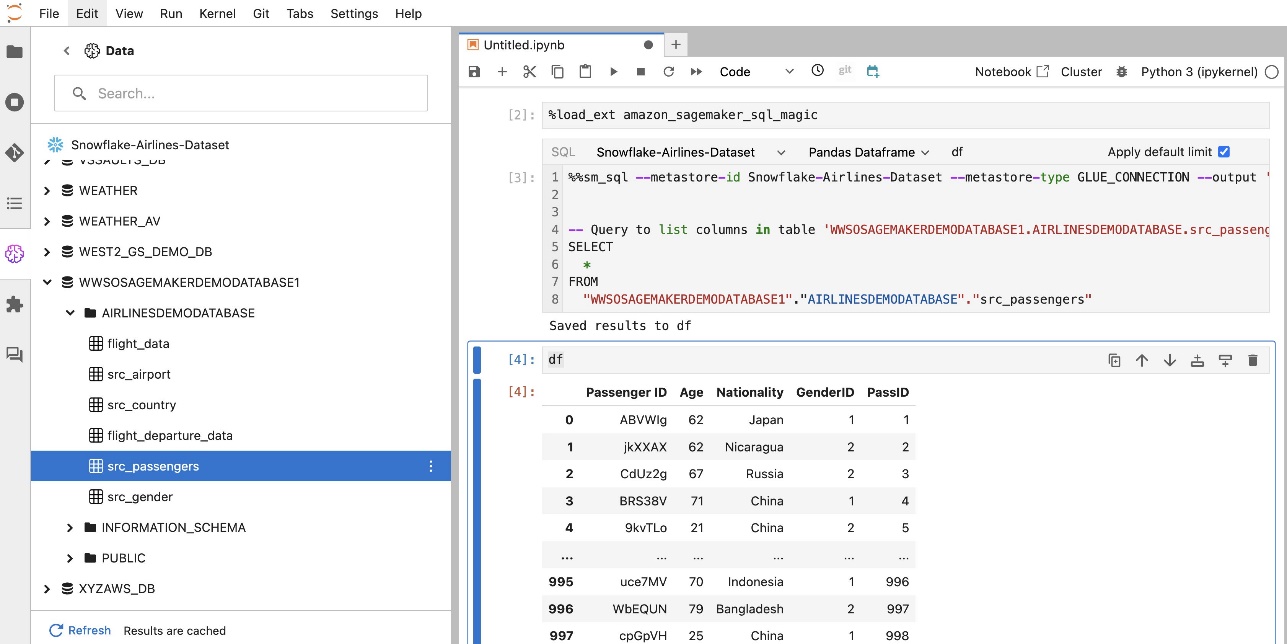
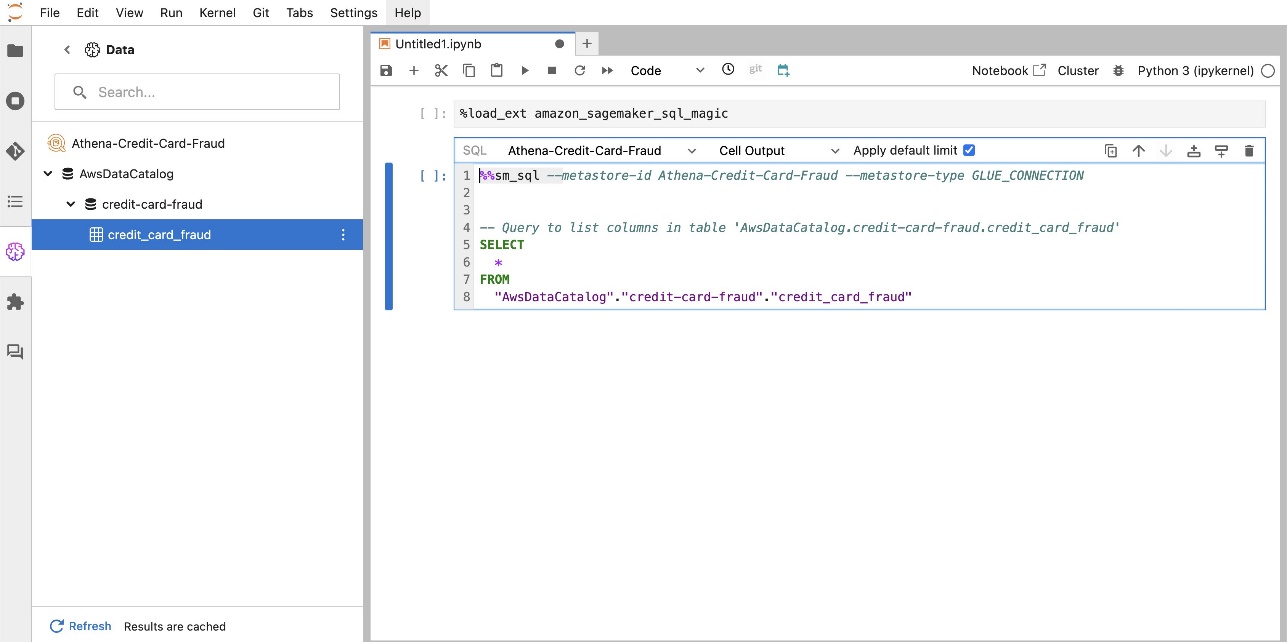
A extensão SQL integrada do SageMaker Studio JupyterLab também permite executar consultas SQL diretamente de um notebook. Os notebooks Jupyter podem diferenciar entre código SQL e Python usando o %%sm_sql comando mágico, que deve ser colocado no topo de qualquer célula que contenha código SQL. Este comando sinaliza ao JupyterLab que as instruções a seguir são comandos SQL em vez de código Python. A saída de uma consulta pode ser exibida diretamente no notebook, facilitando a integração perfeita de fluxos de trabalho SQL e Python em sua análise de dados.
A saída de uma consulta pode ser exibida visualmente como tabelas HTML, conforme mostrado na captura de tela a seguir.

Eles também podem ser escritos em um DataFrame do pandas.
Pré-requisitos
Certifique-se de atender aos seguintes pré-requisitos para usar a experiência SQL do notebook SageMaker Studio:
- SageMaker Estúdio V2 – Certifique-se de estar executando a versão mais atualizada do seu Domínio e perfis de usuário do SageMaker Studio. Se você estiver atualmente no SageMaker Studio Classic, consulte Migração do Amazon SageMaker Studio Classic.
- Papel do IAM – SageMaker requer um Gerenciamento de acesso e identidade da AWS (IAM) a ser atribuída a um domínio ou perfil de usuário do SageMaker Studio para gerenciar permissões de maneira eficaz. Pode ser necessária uma atualização da função de execução para trazer a navegação de dados e o recurso de execução SQL. O exemplo de política a seguir permite que os usuários concedam, listem e executem Cola AWS, Atena, Serviço de armazenamento simples da Amazon (Amazon S3), Gerenciador de segredos da AWSe recursos do Amazon Redshift:
- Espaço JupyterLab – Você precisa de acesso ao SageMaker Studio atualizado e ao JupyterLab Space com Distribuição do SageMaker v1.6 ou versões de imagem posteriores. Se você estiver usando imagens personalizadas para JupyterLab Spaces ou versões mais antigas do SageMaker Distribution (v1.5 ou inferior), consulte o apêndice para obter instruções sobre como instalar os pacotes e módulos necessários para habilitar esse recurso em seus ambientes. Para saber mais sobre o SageMaker Studio JupyterLab Spaces, consulte Aumente a produtividade no Amazon SageMaker Studio: apresentando JupyterLab Spaces e ferramentas generativas de IA.
- Credenciais de acesso à fonte de dados – Este recurso de notebook do SageMaker Studio requer nome de usuário e senha de acesso a fontes de dados como Snowflake e Amazon Redshift. Crie acesso baseado em nome de usuário e senha a essas fontes de dados, caso ainda não tenha uma. O acesso baseado em OAuth ao Snowflake não é um recurso compatível no momento em que este livro foi escrito.
- Carregar magia SQL – Antes de executar consultas SQL a partir de uma célula do notebook Jupyter, é essencial carregar a extensão SQL magics. Use o comando
%load_ext amazon_sagemaker_sql_magicpara ativar esse recurso. Além disso, você pode executar o%sm_sql?comando para visualizar uma lista abrangente de opções suportadas para consulta de uma célula SQL. Essas opções incluem definir um limite de consulta padrão de 1,000, executar uma extração completa e injetar parâmetros de consulta, entre outras. Essa configuração permite a manipulação flexível e eficiente de dados SQL diretamente no ambiente do seu notebook.
Criar conexões de banco de dados
Os recursos integrados de navegação e execução de SQL do SageMaker Studio são aprimorados pelas conexões do AWS Glue. Uma conexão do AWS Glue é um objeto do AWS Glue Data Catalog que armazena dados essenciais, como credenciais de login, strings de URI e informações de nuvem privada virtual (VPC) para armazenamentos de dados específicos. Essas conexões são usadas por rastreadores, trabalhos e endpoints de desenvolvimento do AWS Glue para acessar vários tipos de armazenamentos de dados. Você pode usar essas conexões para dados de origem e de destino e até mesmo reutilizar a mesma conexão em vários rastreadores ou trabalhos de extração, transformação e carregamento (ETL).
Para explorar fontes de dados SQL no painel esquerdo do SageMaker Studio, primeiro você precisa criar objetos de conexão do AWS Glue. Essas conexões facilitam o acesso a diferentes fontes de dados e permitem explorar seus elementos de dados esquemáticos.
Nas seções a seguir, percorremos o processo de criação de conectores AWS Glue específicos para SQL. Isso permitirá que você acesse, visualize e explore conjuntos de dados em uma variedade de armazenamentos de dados. Para obter informações mais detalhadas sobre conexões do AWS Glue, consulte Conectando-se aos dados.
Criar uma conexão do AWS Glue
A única maneira de trazer fontes de dados para o SageMaker Studio é com conexões AWS Glue. Você precisa criar conexões do AWS Glue com tipos de conexão específicos. No momento em que este livro foi escrito, o único mecanismo suportado para criar essas conexões era usar o Interface de linha de comando da AWS (AWSCL).
Arquivo JSON de definição de conexão
Ao se conectar a diferentes fontes de dados no AWS Glue, você deve primeiro criar um arquivo JSON que defina as propriedades da conexão, conhecido como arquivo de definição de conexão. Este arquivo é crucial para estabelecer uma conexão AWS Glue e deve detalhar todas as configurações necessárias para acessar a fonte de dados. Para práticas recomendadas de segurança, é recomendado usar o Secrets Manager para armazenar com segurança informações confidenciais, como senhas. Enquanto isso, outras propriedades de conexão podem ser gerenciadas diretamente por meio de conexões AWS Glue. Essa abordagem garante que as credenciais confidenciais sejam protegidas, ao mesmo tempo que torna a configuração da conexão acessível e gerenciável.
A seguir está um exemplo de uma definição de conexão JSON:
Ao configurar conexões do AWS Glue para suas fontes de dados, há algumas diretrizes importantes a serem seguidas para fornecer funcionalidade e segurança:
- Stringificação de propriedades - Dentro do
PythonPropertieschave, certifique-se de que todas as propriedades estejam pares de valores-chave stringificados. É crucial escapar corretamente das aspas duplas usando o caractere de barra invertida () quando necessário. Isso ajuda a manter o formato correto e evita erros de sintaxe em seu JSON. - Tratamento de informações confidenciais – Embora seja possível incluir todas as propriedades da conexão dentro
PythonProperties, é aconselhável não incluir detalhes confidenciais, como senhas, diretamente nessas propriedades. Em vez disso, use o Secrets Manager para lidar com informações confidenciais. Essa abordagem protege seus dados confidenciais, armazenando-os em um ambiente controlado e criptografado, longe dos principais arquivos de configuração.
Crie uma conexão do AWS Glue usando a AWS CLI
Depois de incluir todos os campos necessários no arquivo JSON de definição de conexão, você estará pronto para estabelecer uma conexão do AWS Glue para sua fonte de dados usando a AWS CLI e o seguinte comando:
Este comando inicia uma nova conexão do AWS Glue com base nas especificações detalhadas no seu arquivo JSON. A seguir está uma análise rápida dos componentes do comando:
- -região – Especifica a região da AWS onde sua conexão do AWS Glue será criada. É crucial selecionar a região onde as fontes de dados e outros serviços estão localizados para minimizar a latência e cumprir os requisitos de residência de dados.
- –cli-input-json arquivo:///caminho/para/arquivo/conexão/definição/arquivo.json – Este parâmetro direciona a AWS CLI para ler a configuração de entrada de um arquivo local que contém sua definição de conexão no formato JSON.
Você deve ser capaz de criar conexões do AWS Glue com o comando anterior da AWS CLI no terminal do Studio JupyterLab. No Envie o menu, escolha Novo e terminal.

Se o create-connection for executado com êxito, você deverá ver sua fonte de dados listada no painel do navegador SQL. Se você não vir sua fonte de dados listada, escolha revisar para atualizar o cache.

Criar uma conexão Snowflake
Nesta seção, nos concentramos na integração de uma fonte de dados Snowflake com o SageMaker Studio. A criação de contas, bancos de dados e armazéns do Snowflake está fora do escopo desta postagem. Para começar com o Snowflake, consulte o Guia do usuário do floco de neve. Nesta postagem, nos concentramos na criação de um arquivo JSON de definição do Snowflake e no estabelecimento de uma conexão de fonte de dados do Snowflake usando AWS Glue.
Criar um segredo do Secrets Manager
Você pode se conectar à sua conta Snowflake usando um ID de usuário e senha ou chaves privadas. Para se conectar com um ID de usuário e senha, você precisa armazenar suas credenciais com segurança no Secrets Manager. Conforme mencionado anteriormente, embora seja possível incorporar essas informações em PythonProperties, não é recomendado armazenar informações confidenciais em formato de texto simples. Certifique-se sempre de que os dados confidenciais sejam tratados com segurança para evitar possíveis riscos de segurança.
Para armazenar informações no Secrets Manager, conclua as etapas a seguir:
- No console do Secrets Manager, escolha Guarde um novo segredo.
- Escolha Tipo de segredo, escolha Outro tipo de segredo.
- Para o par chave-valor, escolha Texto simples e insira o seguinte:
- Insira um nome para o seu segredo, como
sm-sql-snowflake-secret. - Deixe as outras configurações como padrão ou personalize, se necessário.
- Crie o segredo.
Crie uma conexão AWS Glue para Snowflake
Conforme discutido anteriormente, as conexões do AWS Glue são essenciais para acessar qualquer conexão do SageMaker Studio. Você pode encontrar uma lista de todas as propriedades de conexão suportadas para Snowflake. A seguir está um exemplo de definição de conexão JSON para Snowflake. Substitua os valores do espaço reservado pelos valores apropriados antes de salvá-lo no disco:
Para criar um objeto de conexão do AWS Glue para a fonte de dados Snowflake, use o seguinte comando:
Este comando cria uma nova conexão de fonte de dados Snowflake no painel do navegador SQL que pode ser navegada e você pode executar consultas SQL nela a partir da célula do notebook JupyterLab.
Criar uma conexão do Amazon Redshift
O Amazon Redshift é um serviço de data warehouse totalmente gerenciado em escala de petabytes que simplifica e reduz o custo de análise de todos os seus dados usando SQL padrão. O procedimento para criar uma conexão do Amazon Redshift é semelhante ao de uma conexão Snowflake.
Criar um segredo do Secrets Manager
Semelhante à configuração do Snowflake, para se conectar ao Amazon Redshift usando um ID de usuário e uma senha, você precisa armazenar com segurança as informações secretas no Secrets Manager. Conclua as seguintes etapas:
- No console do Secrets Manager, escolha Guarde um novo segredo.
- Escolha Tipo de segredo, escolha Credenciais para cluster do Amazon Redshift.
- Insira as credenciais usadas para fazer login para acessar o Amazon Redshift como fonte de dados.
- Escolha o cluster Redshift associado aos segredos.
- Insira um nome para o segredo, como
sm-sql-redshift-secret. - Deixe as outras configurações como padrão ou personalize, se necessário.
- Crie o segredo.
Seguindo essas etapas, você garante que suas credenciais de conexão sejam tratadas com segurança, usando os recursos robustos de segurança da AWS para gerenciar dados confidenciais de maneira eficaz.
Crie uma conexão AWS Glue para Amazon Redshift
Para configurar uma conexão com o Amazon Redshift usando uma definição JSON, preencha os campos necessários e salve a seguinte configuração JSON em disco:
Para criar um objeto de conexão do AWS Glue para a fonte de dados do Redshift, use o seguinte comando da AWS CLI:
Este comando cria uma conexão no AWS Glue vinculada à sua fonte de dados do Redshift. Se o comando for executado com êxito, você poderá ver sua fonte de dados Redshift no notebook SageMaker Studio JupyterLab, pronta para executar consultas SQL e realizar análises de dados.

Crie uma conexão do Athena
Athena é um serviço de consulta SQL totalmente gerenciado da AWS que permite a análise de dados armazenados no Amazon S3 usando SQL padrão. Para configurar uma conexão do Athena como fonte de dados no navegador SQL do notebook JupyterLab, você precisa criar um JSON de definição de conexão de amostra do Athena. A estrutura JSON a seguir configura os detalhes necessários para se conectar ao Athena, especificando o catálogo de dados, o diretório de preparação do S3 e a região:
Para criar um objeto de conexão do AWS Glue para a fonte de dados do Athena, use o seguinte comando da AWS CLI:
Se o comando for bem-sucedido, você poderá acessar o catálogo de dados e as tabelas do Athena diretamente do navegador SQL em seu notebook SageMaker Studio JupyterLab.
Consultar dados de múltiplas fontes
Se você tiver várias fontes de dados integradas ao SageMaker Studio por meio do navegador SQL integrado e do recurso SQL do notebook, poderá executar consultas rapidamente e alternar sem esforço entre back-ends de fontes de dados em células subsequentes em um notebook. Esse recurso permite transições perfeitas entre diferentes bancos de dados ou fontes de dados durante o fluxo de trabalho de análise.
Você pode executar consultas em uma coleção diversificada de back-ends de fontes de dados e trazer os resultados diretamente para o espaço Python para análise ou visualização adicional. Isto é facilitado pela %%sm_sql comando mágico disponível em notebooks SageMaker Studio. Para gerar os resultados da sua consulta SQL em um DataFrame do pandas, existem duas opções:
- Na barra de ferramentas da célula do seu notebook, escolha o tipo de saída Quadro de dados e nomeie sua variável DataFrame
- Anexe o seguinte parâmetro ao seu
%%sm_sqlcomando:
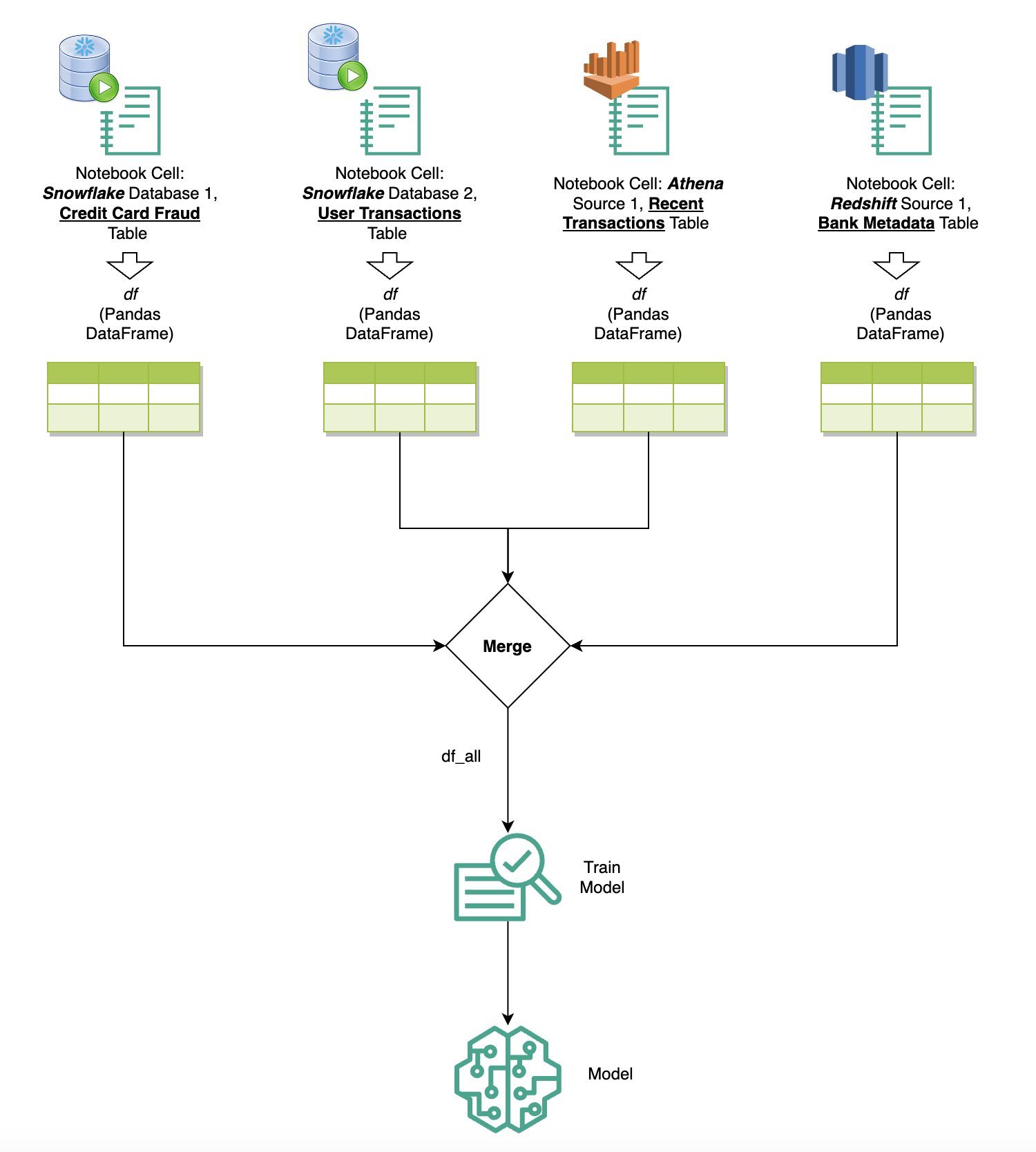
O diagrama a seguir ilustra esse fluxo de trabalho e mostra como você pode executar consultas sem esforço em várias fontes em células subsequentes do notebook, bem como treinar um modelo SageMaker usando trabalhos de treinamento ou diretamente no notebook usando computação local. Além disso, o diagrama destaca como a integração SQL integrada do SageMaker Studio simplifica os processos de extração e construção diretamente no ambiente familiar de uma célula de notebook JupyterLab.
Texto para SQL: usando linguagem natural para aprimorar a criação de consultas
SQL é uma linguagem complexa que requer compreensão de bancos de dados, tabelas, sintaxes e metadados. Hoje, a inteligência artificial (IA) generativa pode permitir que você escreva consultas SQL complexas sem exigir experiência profunda em SQL. O avanço dos LLMs impactou significativamente a geração de SQL baseada no processamento de linguagem natural (PNL), permitindo a criação de consultas SQL precisas a partir de descrições em linguagem natural – uma técnica conhecida como Text-to-SQL. No entanto, é essencial reconhecer as diferenças inerentes entre a linguagem humana e o SQL. A linguagem humana às vezes pode ser ambígua ou imprecisa, enquanto o SQL é estruturado, explícito e inequívoco. Preencher essa lacuna e converter com precisão a linguagem natural em consultas SQL pode representar um desafio formidável. Quando fornecidos com prompts apropriados, os LLMs podem ajudar a preencher essa lacuna, compreendendo a intenção por trás da linguagem humana e gerando consultas SQL precisas de acordo.
Com o lançamento do recurso de consulta SQL no notebook do SageMaker Studio, o SageMaker Studio simplifica a inspeção de bancos de dados e esquemas, além de criar, executar e depurar consultas SQL sem nunca sair do IDE do notebook Jupyter. Esta seção explora como os recursos de texto para SQL de LLMs avançados podem facilitar a geração de consultas SQL usando linguagem natural em notebooks Jupyter. Empregamos o modelo Text-to-SQL de última geração defog/sqlcoder-7b-2 em conjunto com o Jupyter AI, um assistente generativo de IA projetado especificamente para notebooks Jupyter, para criar consultas SQL complexas a partir de linguagem natural. Ao usar esse modelo avançado, podemos criar consultas SQL complexas de maneira fácil e eficiente usando linguagem natural, aprimorando assim nossa experiência SQL em notebooks.
Prototipagem de notebook usando o Hugging Face Hub
Para começar a prototipagem, você precisa do seguinte:
- Código GitHub – O código apresentado nesta seção está disponível no seguinte GitHub repo e fazendo referência ao caderno de exemplo.
- Espaço JupyterLab – O acesso a um SageMaker Studio JupyterLab Space apoiado por instâncias baseadas em GPU é essencial. Para o
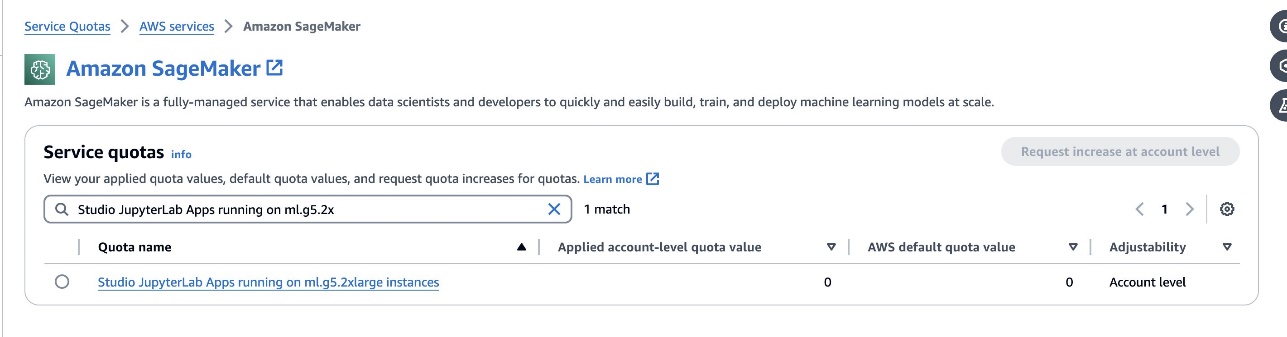
defog/sqlcoder-7b-2modelo, é recomendado um modelo de parâmetro 7B, usando uma instância ml.g5.2xlarge. Alternativas comodefog/sqlcoder-70b-alphum oudefog/sqlcoder-34b-alphatambém são viáveis para conversão de linguagem natural em SQL, mas tipos de instância maiores podem ser necessários para a prototipagem. Certifique-se de ter a cota para iniciar uma instância apoiada por GPU navegando até o console Service Quotas, pesquisando por SageMaker e pesquisando porStudio JupyterLab Apps running on <instance type>.
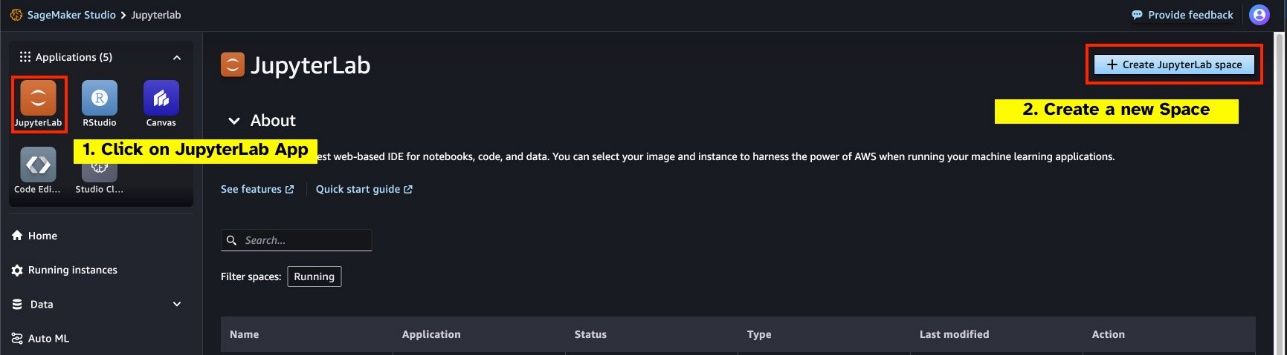
Inicie um novo JupyterLab Space apoiado por GPU em seu SageMaker Studio. Recomenda-se criar um novo JupyterLab Space com pelo menos 75 GB de Loja de blocos elásticos da Amazon (Amazon EBS) para um modelo de parâmetros 7B.

- Abraçando o Face Hub – Se o seu domínio do SageMaker Studio tiver acesso para baixar modelos do Abraçando o Face Hub, você pode usar o
AutoModelForCausalLMclasse de abraço/transformadores para baixar modelos automaticamente e fixá-los em suas GPUs locais. Os pesos do modelo serão armazenados no cache da sua máquina local. Veja o seguinte código:
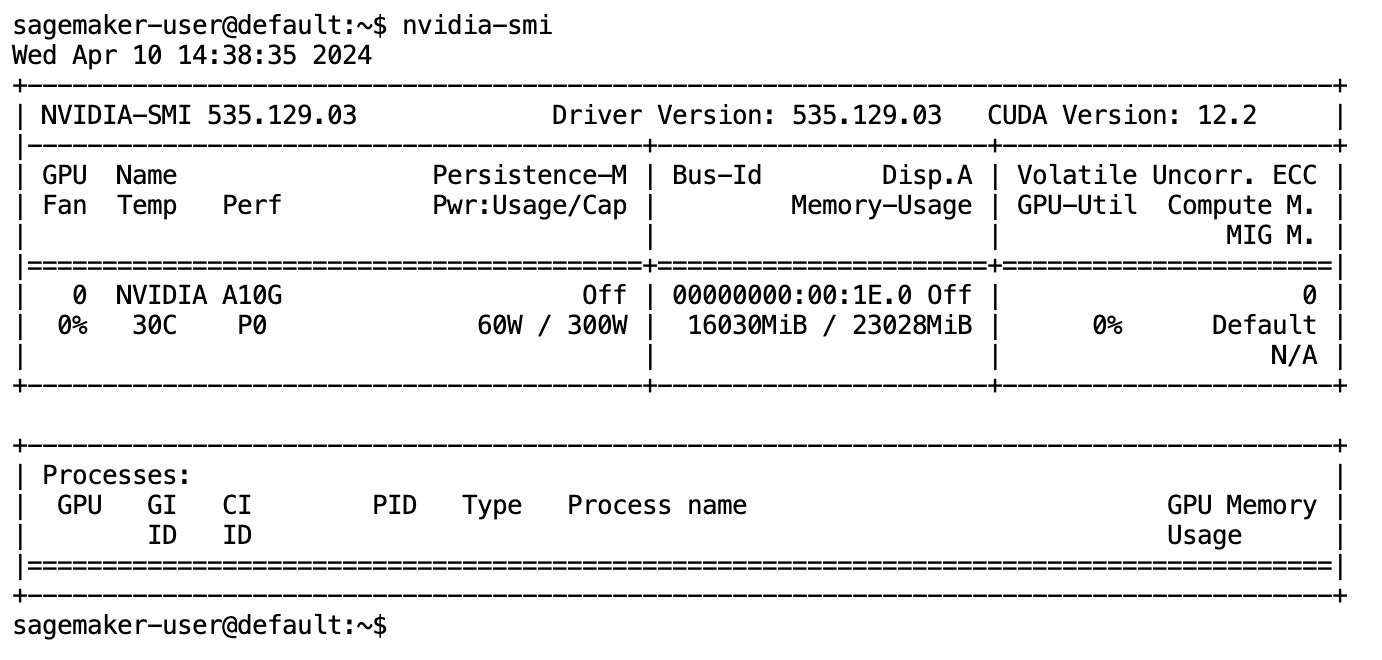
Depois que o modelo for totalmente baixado e carregado na memória, você deverá observar um aumento na utilização da GPU em sua máquina local. Isso indica que o modelo está usando ativamente os recursos da GPU para tarefas computacionais. Você pode verificar isso em seu próprio espaço JupyterLab executando nvidia-smi (para uma exibição única) ou nvidia-smi —loop=1 (para repetir a cada segundo) do seu terminal JupyterLab.
Os modelos de texto para SQL são excelentes para compreender a intenção e o contexto da solicitação de um usuário, mesmo quando a linguagem usada é coloquial ou ambígua. O processo envolve a tradução de entradas de linguagem natural nos elementos corretos do esquema do banco de dados, como nomes de tabelas, nomes de colunas e condições. No entanto, um modelo Text-to-SQL pronto para uso não conhecerá inerentemente a estrutura do seu data warehouse, os esquemas de banco de dados específicos ou será capaz de interpretar com precisão o conteúdo de uma tabela com base apenas nos nomes das colunas. Para usar efetivamente esses modelos para gerar consultas SQL práticas e eficientes a partir de linguagem natural, é necessário adaptar o modelo de geração de texto SQL ao esquema específico do banco de dados do warehouse. Essa adaptação é facilitada pelo uso de Solicitações de LLM. A seguir está um modelo de prompt recomendado para o modelo texto para SQL defog/sqlcoder-7b-2, dividido em quatro partes:
- Tarefa – Esta seção deve especificar uma tarefa de alto nível a ser realizada pelo modelo. Ele deve incluir o tipo de back-end do banco de dados (como Amazon RDS, PostgreSQL ou Amazon Redshift) para alertar o modelo sobre quaisquer diferenças sintáticas sutis que possam afetar a geração da consulta SQL final.
- Instruções – Esta seção deve definir limites de tarefas e reconhecimento de domínio para o modelo e pode incluir alguns exemplos para orientar o modelo na geração de consultas SQL ajustadas.
- Esquema de banco de dados – Esta seção deve detalhar os esquemas do banco de dados do warehouse, descrevendo os relacionamentos entre tabelas e colunas para ajudar o modelo a compreender a estrutura do banco de dados.
- Resposta – Esta seção é reservada para o modelo gerar a resposta da consulta SQL para a entrada de linguagem natural.
Um exemplo do esquema e prompt do banco de dados usado nesta seção está disponível no arquivo Repositório do GitHub.
A engenharia imediata não envolve apenas formular perguntas ou afirmações; é uma arte e uma ciência diferenciadas que impactam significativamente a qualidade das interações com um modelo de IA. A maneira como você elabora um prompt pode influenciar profundamente a natureza e a utilidade da resposta da IA. Esta habilidade é fundamental para maximizar o potencial das interações de IA, especialmente em tarefas complexas que exigem compreensão especializada e respostas detalhadas.
É importante ter a opção de criar e testar rapidamente a resposta de um modelo para um determinado prompt e otimizar o prompt com base na resposta. Os notebooks JupyterLab fornecem a capacidade de receber feedback instantâneo do modelo em execução na computação local e otimizar o prompt e ajustar ainda mais a resposta de um modelo ou alterar totalmente um modelo. Nesta postagem, usamos um notebook SageMaker Studio JupyterLab apoiado pela GPU NVIDIA A5.2G de 10 GB do ml.g24xlarge para executar inferência de modelo Text-to-SQL no notebook e construir interativamente nosso prompt de modelo até que a resposta do modelo esteja suficientemente ajustada para fornecer respostas que são diretamente executáveis nas células SQL do JupyterLab. Para executar a inferência do modelo e transmitir simultaneamente as respostas do modelo, usamos uma combinação de model.generate e TextIteratorStreamer conforme definido no código a seguir:
A saída do modelo pode ser decorada com a magia SQL do SageMaker %%sm_sql ..., que permite que o notebook JupyterLab identifique a célula como uma célula SQL.
Hospedar modelos Text-to-SQL como endpoints do SageMaker
No final do estágio de prototipagem, selecionamos nosso LLM Text-to-SQL preferido, um formato de prompt eficaz e um tipo de instância apropriado para hospedar o modelo (GPU único ou multi-GPU). O SageMaker facilita a hospedagem escalonável de modelos personalizados por meio do uso de endpoints SageMaker. Esses endpoints podem ser definidos de acordo com critérios específicos, permitindo a implantação de LLMs como endpoints. Esse recurso permite dimensionar a solução para um público mais amplo, permitindo que os usuários gerem consultas SQL a partir de entradas de linguagem natural usando LLMs hospedados personalizados. O diagrama a seguir ilustra essa arquitetura.

Para hospedar seu LLM como um endpoint do SageMaker, você gera vários artefatos.
O primeiro artefato são os pesos do modelo. Servindo a biblioteca SageMaker Deep Java (DJL) contêineres permitem que você defina configurações por meio de um meta servindo.propriedades arquivo, que permite direcionar como os modelos são originados — diretamente do Hugging Face Hub ou baixando artefatos de modelo do Amazon S3. Se você especificar model_id=defog/sqlcoder-7b-2, DJL Serving tentará baixar este modelo diretamente do Hugging Face Hub. No entanto, você poderá incorrer em cobranças de entrada/saída de rede sempre que o endpoint for implantado ou dimensionado elasticamente. Para evitar essas cobranças e potencialmente acelerar o download de artefatos do modelo, é recomendável ignorar o uso model_id in serving.properties e salve os pesos do modelo como artefatos S3 e especifique-os apenas com s3url=s3://path/to/model/bin.
Salvar um modelo (com seu tokenizer) em disco e carregá-lo no Amazon S3 pode ser feito com apenas algumas linhas de código:
Você também usa um arquivo de prompt de banco de dados. Nesta configuração, o prompt do banco de dados é composto por Task, Instructions, Database Schema e Answer sections. Para a arquitetura atual, alocamos um arquivo de prompt separado para cada esquema de banco de dados. No entanto, há flexibilidade para expandir essa configuração para incluir vários bancos de dados por arquivo de prompt, permitindo que o modelo execute junções compostas em bancos de dados no mesmo servidor. Durante nosso estágio de prototipagem, salvamos o prompt do banco de dados como um arquivo de texto chamado <Database-Glue-Connection-Name>.prompt, Onde Database-Glue-Connection-Name corresponde ao nome da conexão visível em seu ambiente JupyterLab. Por exemplo, esta postagem se refere a uma conexão Snowflake chamada Airlines_Dataset, então o arquivo de prompt do banco de dados é nomeado Airlines_Dataset.prompt. Esse arquivo é então armazenado no Amazon S3 e posteriormente lido e armazenado em cache pela nossa lógica de serviço de modelo.
Além disso, esta arquitetura permite que qualquer usuário autorizado deste endpoint defina, armazene e gere linguagem natural para consultas SQL sem a necessidade de múltiplas reimplantações do modelo. Usamos o seguinte exemplo de prompt de banco de dados para demonstrar a funcionalidade Text-to-SQL.
Em seguida, você gera uma lógica de serviço de modelo customizado. Nesta seção, você descreve uma lógica de inferência personalizada chamada modelo.py. Este script foi projetado para otimizar o desempenho e a integração de nossos serviços Text-to-SQL:
- Definir a lógica de cache do arquivo de prompt do banco de dados – Para minimizar a latência, implementamos uma lógica personalizada para baixar e armazenar em cache os arquivos de prompt do banco de dados. Esse mecanismo garante que os prompts estejam prontamente disponíveis, reduzindo a sobrecarga associada a downloads frequentes.
- Definir lógica de inferência de modelo personalizado – Para aumentar a velocidade de inferência, nosso modelo texto para SQL é carregado no formato de precisão float16 e depois convertido em um modelo DeepSpeed. Esta etapa permite um cálculo mais eficiente. Além disso, dentro dessa lógica, você especifica quais parâmetros os usuários podem ajustar durante as chamadas de inferência para adaptar a funcionalidade de acordo com suas necessidades.
- Definir lógica personalizada de entrada e saída – Estabelecer formatos de entrada/saída claros e personalizados é essencial para uma integração suave com aplicações downstream. Um desses aplicativos é o JupyterAI, que discutiremos na seção subsequente.
Além disso, incluímos um serving.properties arquivo, que atua como um arquivo de configuração global para modelos hospedados usando serviço DJL. Para obter mais informações, consulte Configurações e configurações.
Por último, você também pode incluir um requirements.txt arquivo para definir módulos adicionais necessários para inferência e empacotar tudo em um tarball para implantação.
Veja o seguinte código:
Integre seu endpoint com o assistente SageMaker Studio Jupyter AI
IA de Júpiter é uma ferramenta de código aberto que traz IA generativa para notebooks Jupyter, oferecendo uma plataforma robusta e fácil de usar para explorar modelos de IA generativa. Ele aumenta a produtividade em notebooks JupyterLab e Jupyter, fornecendo recursos como a magia %%ai para criar um playground de IA generativo dentro de notebooks, uma interface de bate-papo nativa no JupyterLab para interagir com IA como um assistente de conversação e suporte para uma ampla variedade de LLMs de provedores como Titã Amazona, AI21, Anthropic, Cohere e Hugging Face ou serviços gerenciados como Rocha Amazônica e terminais SageMaker. Para esta postagem, usamos a integração pronta para uso do Jupyter AI com endpoints SageMaker para trazer o recurso Text-to-SQL para notebooks JupyterLab. A ferramenta Jupyter AI vem pré-instalada em todos os SageMaker Studio JupyterLab Spaces apoiados por Imagens de distribuição do SageMaker; os usuários finais não são obrigados a fazer nenhuma configuração adicional para começar a usar a extensão Jupyter AI para integração com um endpoint hospedado pelo SageMaker. Nesta seção, discutimos as duas maneiras de usar a ferramenta integrada Jupyter AI.
Jupyter AI dentro de um notebook usando magia
IA de Jupyter %%ai O comando mágico permite que você transforme seus notebooks SageMaker Studio JupyterLab em um ambiente de IA generativo reproduzível. Para começar a usar magias de IA, certifique-se de ter carregado a extensão jupyter_ai_magics para usar %%ai magia e, adicionalmente, carregar amazon_sagemaker_sql_magic usar %%sm_sql Magia:
Para executar uma chamada para seu endpoint SageMaker a partir de seu notebook usando o %%ai comando mágico, forneça os seguintes parâmetros e estruture o comando da seguinte forma:
- –nome da região – Especifique a região onde seu endpoint está implementado. Isso garante que a solicitação seja roteada para a localização geográfica correta.
- –esquema de solicitação – Incluir o esquema dos dados de entrada. Este esquema descreve o formato esperado e os tipos de dados de entrada que seu modelo precisa para processar a solicitação.
- –caminho de resposta – Defina o caminho dentro do objeto de resposta onde a saída do seu modelo está localizada. Este caminho é usado para extrair os dados relevantes da resposta retornada pelo seu modelo.
- -f (opcional) - Isto é um formatador de saída sinalizador que indica o tipo de saída retornada pelo modelo. No contexto de um notebook Jupyter, se a saída for código, esse sinalizador deverá ser definido adequadamente para formatar a saída como código executável na parte superior de uma célula do notebook Jupyter, seguido por uma área de entrada de texto livre para interação do usuário.
Por exemplo, o comando em uma célula do notebook Jupyter pode ser semelhante ao seguinte código:
Janela de bate-papo do Jupyter AI
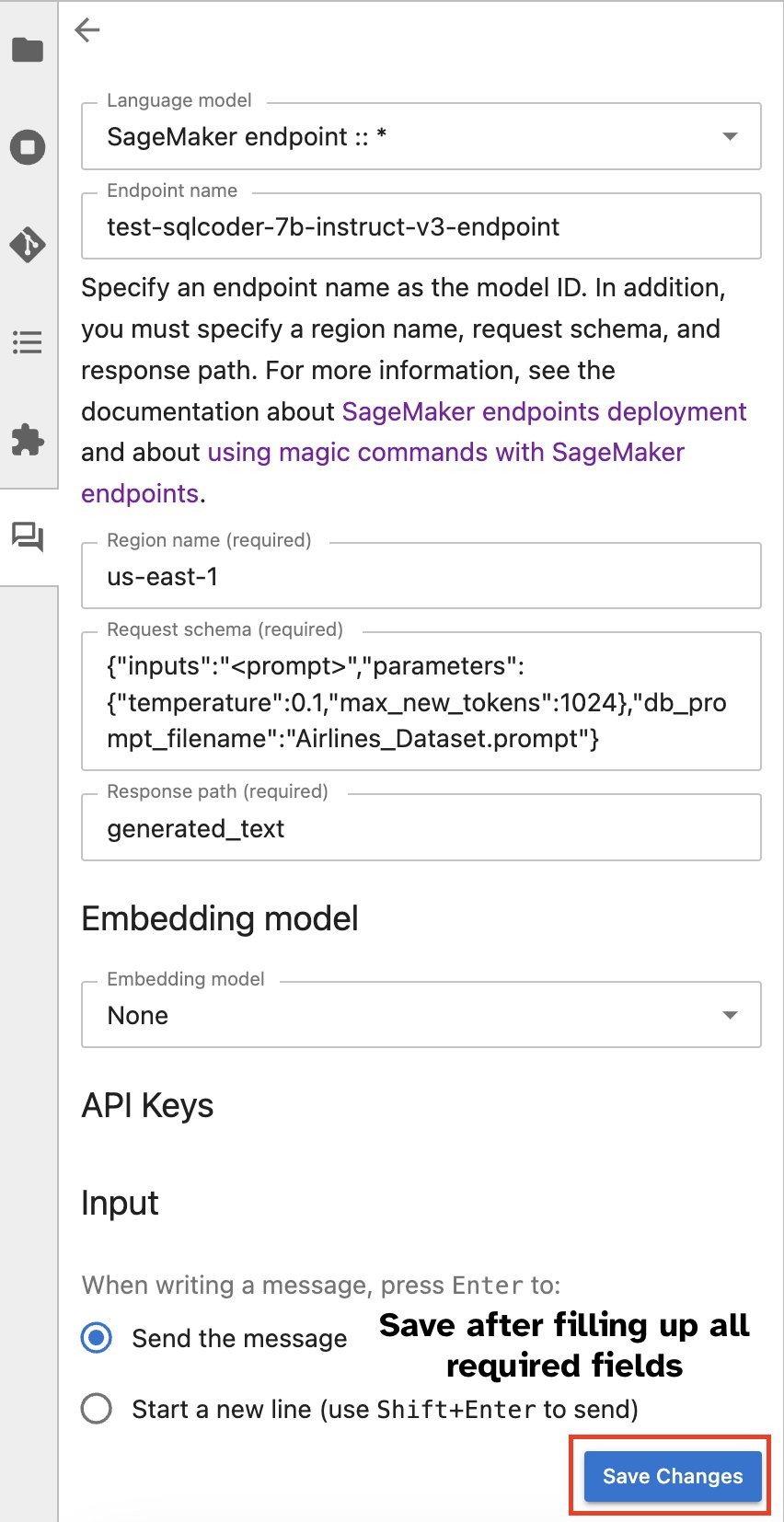
Alternativamente, você pode interagir com endpoints SageMaker por meio de uma interface de usuário integrada, simplificando o processo de geração de consultas ou diálogo. Antes de começar a conversar com seu endpoint SageMaker, defina as configurações relevantes no Jupyter AI para o endpoint SageMaker, conforme mostrado na captura de tela a seguir.
 |
 |
Conclusão
O SageMaker Studio agora simplifica e agiliza o fluxo de trabalho do cientista de dados integrando suporte SQL aos notebooks JupyterLab. Isso permite que os cientistas de dados se concentrem em suas tarefas sem a necessidade de gerenciar diversas ferramentas. Além disso, a nova integração SQL integrada no SageMaker Studio permite que as pessoas de dados gerem consultas SQL sem esforço usando texto em linguagem natural como entrada, acelerando assim seu fluxo de trabalho.
Incentivamos você a explorar esses recursos no SageMaker Studio. Para obter mais informações, consulte Prepare dados com SQL no Studio.
Apêndice
Habilitar o navegador SQL e a célula SQL do notebook em ambientes personalizados
Se você não estiver usando uma imagem de distribuição do SageMaker ou imagens de distribuição 1.5 ou inferior, execute os seguintes comandos para ativar o recurso de navegação SQL dentro de seu ambiente JupyterLab:
Realoque o widget do navegador SQL
Os widgets JupyterLab permitem a realocação. Dependendo de sua preferência, você pode mover widgets para qualquer lado do painel de widgets do JupyterLab. Se preferir, você pode mover a direção do widget SQL para o lado oposto (da direita para a esquerda) da barra lateral com um simples clique com o botão direito no ícone do widget e escolhendo Alternar lado da barra lateral.
 |
 |
Sobre os autores
 Pranav Murthy é arquiteto de soluções especialista em IA/ML na AWS. Ele se concentra em ajudar os clientes a criar, treinar, implantar e migrar cargas de trabalho de aprendizado de máquina (ML) para o SageMaker. Anteriormente, ele trabalhou na indústria de semicondutores desenvolvendo grandes modelos de visão computacional (CV) e processamento de linguagem natural (PNL) para melhorar processos de semicondutores usando técnicas de ML de última geração. Nas horas vagas, gosta de jogar xadrez e viajar. Você pode encontrar Pranav em LinkedIn.
Pranav Murthy é arquiteto de soluções especialista em IA/ML na AWS. Ele se concentra em ajudar os clientes a criar, treinar, implantar e migrar cargas de trabalho de aprendizado de máquina (ML) para o SageMaker. Anteriormente, ele trabalhou na indústria de semicondutores desenvolvendo grandes modelos de visão computacional (CV) e processamento de linguagem natural (PNL) para melhorar processos de semicondutores usando técnicas de ML de última geração. Nas horas vagas, gosta de jogar xadrez e viajar. Você pode encontrar Pranav em LinkedIn.
 Varun Xá é engenheiro de software e trabalha no Amazon SageMaker Studio na Amazon Web Services. Ele está focado na construção de soluções interativas de ML que simplificam as jornadas de processamento e preparação de dados. Em seu tempo livre, Varun gosta de atividades ao ar livre, incluindo caminhadas e esqui, e está sempre pronto para descobrir lugares novos e emocionantes.
Varun Xá é engenheiro de software e trabalha no Amazon SageMaker Studio na Amazon Web Services. Ele está focado na construção de soluções interativas de ML que simplificam as jornadas de processamento e preparação de dados. Em seu tempo livre, Varun gosta de atividades ao ar livre, incluindo caminhadas e esqui, e está sempre pronto para descobrir lugares novos e emocionantes.
 Sumedha Swami é gerente de produto principal da Amazon Web Services, onde lidera a equipe do SageMaker Studio em sua missão de desenvolver o IDE preferido para ciência de dados e aprendizado de máquina. Ele dedicou os últimos 15 anos construindo produtos empresariais e de consumo baseados em aprendizado de máquina.
Sumedha Swami é gerente de produto principal da Amazon Web Services, onde lidera a equipe do SageMaker Studio em sua missão de desenvolver o IDE preferido para ciência de dados e aprendizado de máquina. Ele dedicou os últimos 15 anos construindo produtos empresariais e de consumo baseados em aprendizado de máquina.
 bosco albuquerque é arquiteto de soluções de parceiros sênior na AWS e tem mais de 20 anos de experiência trabalhando com produtos de banco de dados e análises de fornecedores de banco de dados corporativos e provedores de nuvem. Ele ajudou empresas de tecnologia a projetar e implementar soluções e produtos de análise de dados.
bosco albuquerque é arquiteto de soluções de parceiros sênior na AWS e tem mais de 20 anos de experiência trabalhando com produtos de banco de dados e análises de fornecedores de banco de dados corporativos e provedores de nuvem. Ele ajudou empresas de tecnologia a projetar e implementar soluções e produtos de análise de dados.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

