Amazon Sage Maker endpoints multimodelos (MMEs) são um recurso totalmente gerenciado de inferência do SageMaker que permite implantar milhares de modelos em um único endpoint. Anteriormente, os MMEs alocavam de forma pré-determinada o poder de computação da CPU aos modelos, independentemente da carga de tráfego do modelo, usando Servidor Multimodelo (MMS) como seu servidor modelo. Neste post, discutimos uma solução na qual um MME pode ajustar dinamicamente o poder computacional atribuído a cada modelo com base no padrão de tráfego do modelo. Esta solução permite que você use a computação subjacente dos MMEs com mais eficiência e economize custos.
Os MMEs carregam e descarregam modelos dinamicamente com base no tráfego de entrada para o terminal. Ao utilizar o MMS como servidor modelo, os MMEs alocam um número fixo de trabalhadores modelo para cada modelo. Para obter mais informações, consulte Modelar padrões de hospedagem no Amazon SageMaker, Parte 3: executar e otimizar a inferência de vários modelos com endpoints de vários modelos do Amazon SageMaker.
No entanto, isso pode levar a alguns problemas quando o padrão de tráfego é variável. Digamos que você tenha um ou poucos modelos recebendo uma grande quantidade de tráfego. Você pode configurar o MMS para alocar um grande número de trabalhadores para esses modelos, mas isso é atribuído a todos os modelos por trás do MME porque é uma configuração estática. Isso faz com que um grande número de trabalhadores utilizem computação de hardware, até mesmo os modelos ociosos. O problema oposto pode acontecer se você definir um valor pequeno para o número de trabalhadores. Os modelos populares não terão trabalhadores suficientes no nível do servidor de modelo para alocar adequadamente hardware suficiente atrás do endpoint para esses modelos. O principal problema é que é difícil permanecer independente do padrão de tráfego se você não puder dimensionar dinamicamente seus trabalhadores no nível do servidor modelo para alocar a quantidade necessária de computação.
A solução que discutimos nesta postagem usa DJLServindo como o servidor modelo, o que pode ajudar a mitigar alguns dos problemas que discutimos e permitir o escalonamento por modelo e permitir que os MMEs sejam independentes dos padrões de tráfego.
Arquitetura MME
Os MMEs SageMaker permitem implantar vários modelos atrás de um único endpoint de inferência que pode conter uma ou mais instâncias. Cada instância é projetada para carregar e servir vários modelos até sua capacidade de memória e CPU/GPU. Com essa arquitetura, um negócio de software como serviço (SaaS) pode quebrar o custo linearmente crescente de hospedagem de vários modelos e alcançar a reutilização da infraestrutura consistente com o modelo de multilocação aplicado em outras partes da pilha de aplicativos. O diagrama a seguir ilustra essa arquitetura.
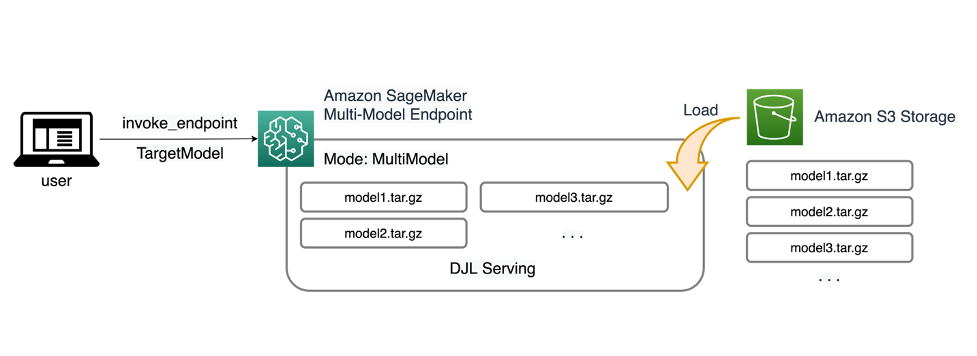
Um SageMaker MME carrega modelos dinamicamente de Serviço de armazenamento simples da Amazon (Amazon S3) quando invocado, em vez de fazer download de todos os modelos quando o endpoint é criado pela primeira vez. Como resultado, uma invocação inicial de um modelo pode apresentar uma latência de inferência mais alta do que as inferências subsequentes, que são concluídas com latência baixa. Se o modelo já estiver carregado no contêiner quando invocado, a etapa de download será ignorada e o modelo retornará as inferências com baixa latência. Por exemplo, suponha que você tenha um modelo que seja usado apenas algumas vezes por dia. Ele é carregado automaticamente sob demanda, enquanto os modelos acessados com frequência são retidos na memória e invocados com latência consistentemente baixa.
Atrás de cada MME estão instâncias de hospedagem de modelo, conforme ilustrado no diagrama a seguir. Essas instâncias carregam e despejam vários modelos de e para a memória com base nos padrões de tráfego para os modelos.
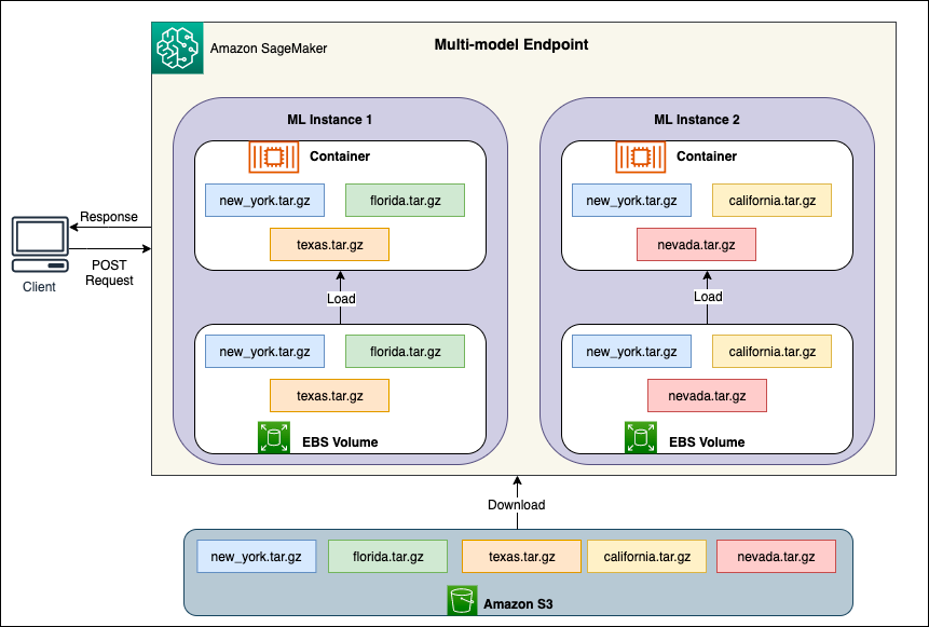
O SageMaker continua a rotear solicitações de inferência para um modelo para a instância onde o modelo já está carregado, de modo que as solicitações sejam atendidas a partir de uma cópia do modelo em cache (consulte o diagrama a seguir, que mostra o caminho da primeira solicitação de previsão versus a previsão em cache caminho da solicitação). No entanto, se o modelo receber muitas solicitações de invocação e houver instâncias adicionais para o MME, o SageMaker roteará algumas solicitações para outra instância para acomodar o aumento. Para aproveitar as vantagens do dimensionamento automatizado do modelo no SageMaker, certifique-se de ter configuração do escalonamento automático da instância para provisionar capacidade de instância adicional. Configure sua política de escalabilidade em nível de endpoint com parâmetros personalizados ou invocações por minuto (recomendado) para adicionar mais instâncias à frota de endpoints.

Visão geral do servidor modelo
Um servidor modelo é um componente de software que fornece um ambiente de tempo de execução para implantar e servir modelos de aprendizado de máquina (ML). Ele atua como uma interface entre os modelos treinados e os aplicativos clientes que desejam fazer previsões usando esses modelos.
O objetivo principal de um servidor de modelo é permitir a integração sem esforço e a implantação eficiente de modelos de ML em sistemas de produção. Em vez de incorporar o modelo diretamente em um aplicativo ou estrutura específica, o servidor de modelo fornece uma plataforma centralizada onde vários modelos podem ser implantados, gerenciados e servidos.
Os servidores modelo normalmente oferecem as seguintes funcionalidades:
- Carregamento do modelo – O servidor carrega os modelos de ML treinados na memória, deixando-os prontos para servir previsões.
- API de inferência – O servidor expõe uma API que permite que aplicativos clientes enviem dados de entrada e recebam previsões dos modelos implementados.
- Escala – Os servidores modelo são projetados para lidar com solicitações simultâneas de vários clientes. Eles fornecem mecanismos para processamento paralelo e gerenciamento eficiente de recursos para garantir alto rendimento e baixa latência.
- Integração com mecanismos de back-end – Os servidores de modelo têm integrações com estruturas de backend como DeepSpeed e FasterTransformer para particionar modelos grandes e executar inferência altamente otimizada.
Arquitetura DJL
Serviço DJL é um servidor de modelo universal de código aberto e alto desempenho. DJL Serving é construído sobre DJL, uma biblioteca de aprendizagem profunda escrita na linguagem de programação Java. Pode pegar um modelo de aprendizado profundo, vários modelos ou fluxos de trabalho e disponibilizá-los por meio de um endpoint HTTP. DJL Serving suporta a implantação de modelos de várias estruturas como PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer e muito mais.
DJL Serving oferece muitos recursos que permitem implantar seus modelos com alto desempenho:
- FÁCIL DE USAR – DJL Serving pode atender a maioria dos modelos prontos para uso. Basta trazer os artefatos do modelo e o DJL Serving pode hospedá-los.
- Suporte a vários dispositivos e aceleradores – DJL Serving suporta a implantação de modelos em CPU, GPU e Inferência da AWS.
- Performance – DJL Serving executa inferência multithread em uma única JVM para aumentar o rendimento.
- Lote dinâmico – DJL Serving oferece suporte a lotes dinâmicos para aumentar o rendimento.
- Escala automática – O DJL Serving aumentará ou diminuirá automaticamente os trabalhadores com base na carga de tráfego.
- Suporte multimotor – DJL Serving pode hospedar modelos simultaneamente usando diferentes estruturas (como PyTorch e TensorFlow).
- Modelos de conjunto e fluxo de trabalho – DJL Serving suporta a implantação de fluxos de trabalho complexos compostos de vários modelos e executa partes do fluxo de trabalho na CPU e partes na GPU. Os modelos dentro de um fluxo de trabalho podem usar estruturas diferentes.
Em particular, o recurso de escalonamento automático do DJL Serving facilita a garantia de que os modelos sejam dimensionados adequadamente para o tráfego de entrada. Por padrão, DJL Serving determina o número máximo de trabalhadores para um modelo que pode ser suportado com base no hardware disponível (núcleos de CPU, dispositivos GPU). Você pode definir limites inferiores e superiores para cada modelo para garantir que um nível mínimo de tráfego sempre possa ser atendido e que um único modelo não consuma todos os recursos disponíveis.
DJL Serving usa um Netty front-end sobre pools de threads de trabalho de back-end. O frontend usa uma única configuração do Netty com vários HttpRequestHandlers. Diferentes manipuladores de solicitações fornecerão suporte para o API de inferência, API de gerenciamentoou outras APIs disponíveis em vários plug-ins.
O back-end é baseado no WorkLoadManager (WLM). O WLM cuida de vários threads de trabalho para cada modelo, juntamente com o processamento em lote e o roteamento de solicitações para eles. Quando vários modelos são atendidos, o WLM verifica primeiro o tamanho da fila de solicitação de inferência de cada modelo. Se o tamanho da fila for maior que duas vezes o tamanho do lote de um modelo, o WLM aumentará o número de trabalhadores atribuídos a esse modelo.
Visão geral da solução
A implementação do DJL com um MME difere da configuração padrão do MMS. Para DJL Serving com um MME, compactamos os seguintes arquivos no formato model.tar.gz que o SageMaker Inference espera:
- modelo.joblib – Para esta implementação, enviamos diretamente os metadados do modelo para o tarball. Neste caso, estamos trabalhando com um
.joblibarquivo, então fornecemos esse arquivo em nosso tarball para nosso script de inferência ler. Se o artefato for muito grande, você também poderá enviá-lo para o Amazon S3 e apontar para isso na configuração de serviço definida para DJL. - servindo.propriedades – Aqui você pode configurar qualquer modelo relacionado ao servidor variáveis ambientais. O poder do DJL aqui é que você pode configurar
minWorkersemaxWorkerspara cada tarball de modelo. Isso permite que cada modelo seja ampliado ou reduzido no nível do servidor de modelo. Por exemplo, se um modelo singular estiver recebendo a maior parte do tráfego para um MME, o servidor do modelo aumentará a escala dos trabalhadores dinamicamente. Neste exemplo, não configuramos essas variáveis e deixamos o DJL determinar o número necessário de trabalhadores dependendo do nosso padrão de tráfego. - modelo.py – Este é o script de inferência para qualquer pré-processamento ou pós-processamento personalizado que você gostaria de implementar. O model.py espera que sua lógica seja encapsulada em um método handle por padrão.
- requisitos.txt (opcional) – Por padrão, DJL vem instalado com PyTorch, mas quaisquer dependências adicionais necessárias podem ser enviadas aqui.
Neste exemplo, mostramos o poder do DJL com um MME usando um modelo SKLearn de amostra. Executamos um trabalho de treinamento com esse modelo e, em seguida, criamos 1,000 cópias desse artefato de modelo para apoiar nosso MME. Em seguida, mostramos como o DJL pode escalar dinamicamente para lidar com qualquer tipo de padrão de tráfego que seu MME possa receber. Isso pode incluir uma distribuição uniforme do tráfego entre todos os modelos ou até mesmo alguns modelos populares que recebem a maior parte do tráfego. Você pode encontrar todo o código a seguir GitHub repo.
Pré-requisitos
Para este exemplo, usamos uma instância de notebook SageMaker com um kernel conda_python3 e uma instância ml.c5.xlarge. Para realizar os testes de carga, você pode usar um Amazon Elastic Compute Nuvem (Amazon EC2) ou uma instância maior de notebook SageMaker. Neste exemplo, escalamos para mais de mil transações por segundo (TPS), portanto, sugerimos testar em uma instância EC2 mais pesada, como ml.c5.18xlarge, para que você tenha mais computação para trabalhar.
Criar um artefato de modelo
Primeiro precisamos criar nosso artefato de modelo e os dados que usamos neste exemplo. Para este caso, geramos alguns dados artificiais com NumPy e treinamos usando um modelo de regressão linear SKLearn com o seguinte trecho de código:
Depois de executar o código anterior, você deverá ter um model.joblib arquivo criado em seu ambiente local.
Extraia a imagem DJL Docker
A imagem Docker djl-inference:0.23.0-cpu-full-v1.0 é nosso contêiner de serviço DJL usado neste exemplo. Você pode ajustar o seguinte URL dependendo da sua região:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
Opcionalmente, você também pode usar esta imagem como imagem base e estendê-la para construir sua própria imagem Docker. Registro do Amazon Elastic Container (Amazon ECR) com quaisquer outras dependências necessárias.
Crie o arquivo de modelo
Primeiro, criamos um arquivo chamado serving.properties. Isso instrui DJLServing a usar o mecanismo Python. Também definimos o max_idle_time de um trabalhador é de 600 segundos. Isso garante que demoremos mais para reduzir o número de trabalhadores que temos por modelo. Nós não nos ajustamos minWorkers e maxWorkers que podemos definir e deixamos o DJL calcular dinamicamente o número de trabalhadores necessários dependendo do tráfego que cada modelo está recebendo. O servindo.properties é mostrado a seguir. Para ver a lista completa de opções de configuração, consulte Configuração do mecanismo.
A seguir, criamos nosso arquivo model.py, que define o carregamento do modelo e a lógica de inferência. Para MMEs, cada arquivo model.py é específico para um modelo. Os modelos são armazenados em seus próprios caminhos no armazenamento de modelos (geralmente /opt/ml/model/). Ao carregar modelos, eles serão carregados no caminho do armazenamento de modelos em seu próprio diretório. O exemplo model.py completo nesta demonstração pode ser visto no GitHub repo.
Nós criamos um model.tar.gz arquivo que inclui nosso modelo (model.joblib), model.py e serving.properties:
Para fins de demonstração, fazemos 1,000 cópias do mesmo model.tar.gz arquivo para representar o grande número de modelos a serem hospedados. Na produção, você precisa criar um model.tar.gz arquivo para cada um de seus modelos.
Por fim, carregamos esses modelos no Amazon S3.
Criar um modelo do SageMaker
Agora criamos um Modelo do SageMaker. Usamos a imagem ECR definida anteriormente e o artefato do modelo da etapa anterior para criar o modelo SageMaker. Na configuração do modelo, configuramos o Modo como MultiModel. Isso informa ao DJLServing que estamos criando um MME.
Crie um endpoint SageMaker
Nesta demonstração, usamos 20 instâncias ml.c5d.18xlarge para escalar para um TPS na faixa dos milhares. Certifique-se de obter um aumento de limite no seu tipo de instância, se necessário, para atingir o TPS que você está almejando.
Teste de carga
No momento em que este artigo foi escrito, a ferramenta interna de teste de carga SageMaker Recomendador de inferência do Amazon SageMaker não oferece suporte nativo a testes para MMEs. Portanto, usamos a ferramenta Python de código aberto Gafanhoto. O Locust é simples de configurar e pode rastrear métricas como TPS e latência ponta a ponta. Para uma compreensão completa de como configurá-lo com o SageMaker, consulte Práticas recomendadas para teste de carga endpoints de inferência em tempo real do Amazon SageMaker.
Neste caso de uso, temos três padrões de tráfego diferentes que queremos simular com MMEs, portanto temos os três scripts Python a seguir que se alinham com cada padrão. Nosso objetivo aqui é provar que, independentemente de qual seja o nosso padrão de tráfego, podemos atingir o mesmo TPS alvo e escalar adequadamente.
Podemos especificar um peso em nosso script Locust para atribuir tráfego em diferentes partes de nossos modelos. Por exemplo, com nosso modelo único quente, implementamos dois métodos como segue:
Podemos então atribuir um determinado peso a cada método, que é quando um determinado método recebe uma porcentagem específica do tráfego:
Para 20 instâncias ml.c5d.18xlarge, vemos as seguintes métricas de invocação no Amazon CloudWatch console. Estes valores permanecem bastante consistentes em todos os três padrões de tráfego. Para entender melhor as métricas do CloudWatch para inferência em tempo real e MMEs do SageMaker, consulte Métricas de invocação de endpoint do SageMaker.
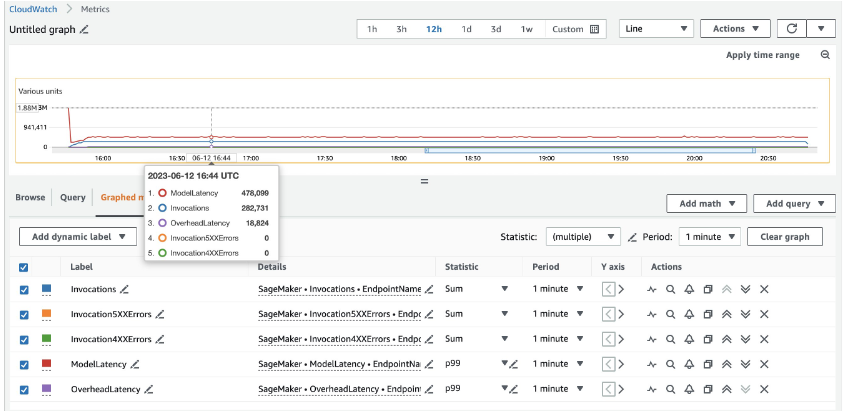
Você pode encontrar o restante dos scripts do Locust no diretório locust-utils no repositório GitHub.
Resumo
Nesta postagem, discutimos como um MME pode ajustar dinamicamente o poder de computação atribuído a cada modelo com base no padrão de tráfego do modelo. Este recurso recém-lançado está disponível em todas as regiões da AWS onde o SageMaker está disponível. Observe que no momento do anúncio, apenas instâncias de CPU são suportadas. Para saber mais, consulte Algoritmos, estruturas e instâncias compatíveis.
Sobre os autores
 Ram Vegiraju é um arquiteto de ML da equipe SageMaker Service. Ele se concentra em ajudar os clientes a criar e otimizar suas soluções de IA/ML no Amazon SageMaker. Nas horas vagas, adora viajar e escrever.
Ram Vegiraju é um arquiteto de ML da equipe SageMaker Service. Ele se concentra em ajudar os clientes a criar e otimizar suas soluções de IA/ML no Amazon SageMaker. Nas horas vagas, adora viajar e escrever.
 Qingwei Li é especialista em aprendizado de máquina na Amazon Web Services. Ele recebeu seu Ph.D. em Pesquisa Operacional depois que ele quebrou a conta de bolsa de pesquisa de seu orientador e não entregou o Prêmio Nobel que prometeu. Atualmente, ele ajuda os clientes do setor de seguros e serviços financeiros a criar soluções de aprendizado de máquina na AWS. Nas horas vagas, gosta de ler e ensinar.
Qingwei Li é especialista em aprendizado de máquina na Amazon Web Services. Ele recebeu seu Ph.D. em Pesquisa Operacional depois que ele quebrou a conta de bolsa de pesquisa de seu orientador e não entregou o Prêmio Nobel que prometeu. Atualmente, ele ajuda os clientes do setor de seguros e serviços financeiros a criar soluções de aprendizado de máquina na AWS. Nas horas vagas, gosta de ler e ensinar.
 James Wu é arquiteto de soluções especialista em IA/ML sênior na AWS. ajudando os clientes a projetar e criar soluções de IA/ML. O trabalho de James abrange uma ampla variedade de casos de uso de ML, com interesse principal em visão computacional, aprendizado profundo e dimensionamento de ML em toda a empresa. Antes de ingressar na AWS, James foi arquiteto, desenvolvedor e líder de tecnologia por mais de 10 anos, incluindo 6 anos em engenharia e 4 anos nos setores de marketing e publicidade.
James Wu é arquiteto de soluções especialista em IA/ML sênior na AWS. ajudando os clientes a projetar e criar soluções de IA/ML. O trabalho de James abrange uma ampla variedade de casos de uso de ML, com interesse principal em visão computacional, aprendizado profundo e dimensionamento de ML em toda a empresa. Antes de ingressar na AWS, James foi arquiteto, desenvolvedor e líder de tecnologia por mais de 10 anos, incluindo 6 anos em engenharia e 4 anos nos setores de marketing e publicidade.
 Saurabh Trikande é gerente de produto sênior da Amazon SageMaker Inference. Ele é apaixonado por trabalhar com clientes e motivado pelo objetivo de democratizar o aprendizado de máquina. Ele se concentra nos principais desafios relacionados à implantação de aplicativos de ML complexos, modelos de ML multilocatários, otimizações de custos e à implantação de modelos de aprendizado profundo mais acessíveis. Em seu tempo livre, Saurabh gosta de caminhar, aprender sobre tecnologias inovadoras, seguir o TechCrunch e passar tempo com sua família.
Saurabh Trikande é gerente de produto sênior da Amazon SageMaker Inference. Ele é apaixonado por trabalhar com clientes e motivado pelo objetivo de democratizar o aprendizado de máquina. Ele se concentra nos principais desafios relacionados à implantação de aplicativos de ML complexos, modelos de ML multilocatários, otimizações de custos e à implantação de modelos de aprendizado profundo mais acessíveis. Em seu tempo livre, Saurabh gosta de caminhar, aprender sobre tecnologias inovadoras, seguir o TechCrunch e passar tempo com sua família.
 Xu Deng é gerente de engenharia de software da equipe SageMaker. Ele se concentra em ajudar os clientes a criar e otimizar sua experiência de inferência de IA/ML no Amazon SageMaker. Nas horas vagas adora viajar e praticar snowboard.
Xu Deng é gerente de engenharia de software da equipe SageMaker. Ele se concentra em ajudar os clientes a criar e otimizar sua experiência de inferência de IA/ML no Amazon SageMaker. Nas horas vagas adora viajar e praticar snowboard.
 Siddharth Venkatesan é engenheiro de software em AWS Deep Learning. Atualmente ele se concentra na construção de soluções para inferência de grandes modelos. Antes da AWS, ele trabalhou na organização Amazon Grocery, criando novos recursos de pagamento para clientes em todo o mundo. Fora do trabalho, ele gosta de esquiar, praticar atividades ao ar livre e assistir esportes.
Siddharth Venkatesan é engenheiro de software em AWS Deep Learning. Atualmente ele se concentra na construção de soluções para inferência de grandes modelos. Antes da AWS, ele trabalhou na organização Amazon Grocery, criando novos recursos de pagamento para clientes em todo o mundo. Fora do trabalho, ele gosta de esquiar, praticar atividades ao ar livre e assistir esportes.
 Rohith Nallamaddi é um engenheiro de desenvolvimento de software na AWS. Ele trabalha na otimização de cargas de trabalho de aprendizado profundo em GPUs, criando inferência de ML de alto desempenho e servindo soluções. Antes disso, ele trabalhou na construção de microsserviços baseados na AWS para negócios Amazon F3. Fora do trabalho, ele gosta de jogar e assistir esportes.
Rohith Nallamaddi é um engenheiro de desenvolvimento de software na AWS. Ele trabalha na otimização de cargas de trabalho de aprendizado profundo em GPUs, criando inferência de ML de alto desempenho e servindo soluções. Antes disso, ele trabalhou na construção de microsserviços baseados na AWS para negócios Amazon F3. Fora do trabalho, ele gosta de jogar e assistir esportes.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

