Mergulhe no Deep Learning (D2L.ai) é um livro de código aberto que torna o aprendizado profundo acessível a todos. Ele apresenta notebooks Jupyter interativos com código independente em PyTorch, JAX, TensorFlow e MXNet, bem como exemplos do mundo real, figuras de exposição e matemática. Até agora, o D2L foi adotado por mais de 400 universidades em todo o mundo, como a Universidade de Cambridge, a Universidade de Stanford, o Instituto de Tecnologia de Massachusetts, a Universidade Carnegie Mellon e a Universidade Tsinghua. Esta obra também está disponível em chinês, japonês, coreano, português, turco e vietnamita, com planos de lançamento em espanhol e outros idiomas.
É um esforço desafiador ter um livro on-line continuamente atualizado, escrito por vários autores e disponível em vários idiomas. Nesta postagem, apresentamos uma solução que a D2L.ai usou para enfrentar esse desafio usando o Recurso de tradução personalizada ativa (ACT) of Amazon Tradutor e construir um pipeline de tradução automática multilíngue.
Demonstramos como usar o Console de gerenciamento da AWS e API pública do Amazon Translate para fornecer tradução automática em lote de máquina e analisar as traduções entre dois pares de idiomas: inglês e chinês e inglês e espanhol. Também recomendamos as práticas recomendadas ao usar o Amazon Translate nesse pipeline de tradução automática para garantir a qualidade e a eficiência da tradução.
Visão geral da solução
Criamos pipelines de tradução automática para vários idiomas usando o recurso ACT no Amazon Translate. O ACT permite que você personalize a saída da tradução em tempo real, fornecendo exemplos de tradução sob medida na forma de dados paralelos. Os dados paralelos consistem em uma coleção de exemplos textuais em um idioma de origem e as traduções desejadas em um ou mais idiomas de destino. Durante a tradução, o ACT seleciona automaticamente os segmentos mais relevantes dos dados paralelos e atualiza o modelo de tradução em tempo real com base nesses pares de segmentos. Isso resulta em traduções que correspondem melhor ao estilo e ao conteúdo dos dados paralelos.
A arquitetura contém vários subpipelines; cada subpipeline lida com a tradução de um idioma, como inglês para chinês, inglês para espanhol e assim por diante. Múltiplos subpipelines de tradução podem ser processados em paralelo. Em cada subpipeline, primeiro criamos os dados paralelos no Amazon Translate usando o conjunto de dados de alta qualidade de exemplos de tradução final dos livros D2L traduzidos por humanos. Em seguida, geramos a saída de tradução automática personalizada em tempo real, o que alcança melhor qualidade e precisão.
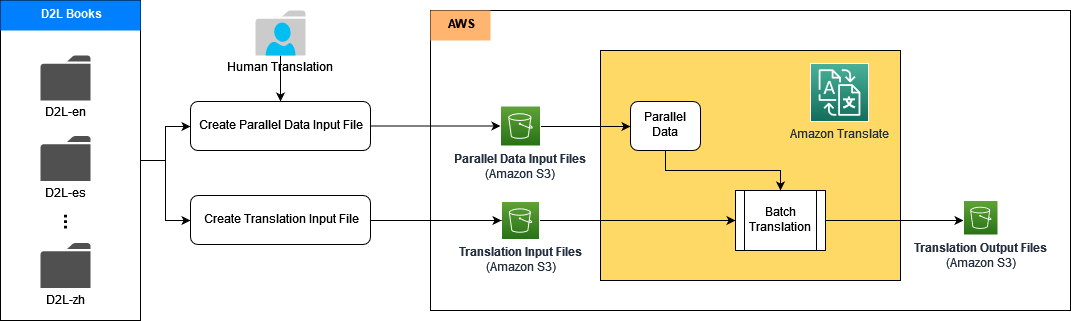
Nas seções a seguir, demonstramos como criar cada pipeline de tradução usando o Amazon Translate com ACT, juntamente com Amazon Sage Maker e Serviço de armazenamento simples da Amazon (Amazônia S3).
Primeiro, colocamos os documentos de origem, os documentos de referência e o conjunto de treinamento de dados paralelos em um bucket do S3. Em seguida, construímos notebooks Jupyter no SageMaker para executar o processo de tradução usando as APIs públicas do Amazon Translate.
Pré-requisitos
Para seguir as etapas desta postagem, certifique-se de ter uma conta da AWS com o seguinte:
- O acesso aos Gerenciamento de acesso e identidade da AWS (IAM) para configuração de função e política
- Acesso ao Amazon Translate, SageMaker e Amazon S3
- Um bucket S3 para armazenar os documentos de origem, documentos de referência, conjunto de dados de dados paralelos e saída da tradução
Crie uma função e políticas do IAM para o Amazon Translate com o ACT
Nossa função IAM precisa conter uma política de confiança personalizada para o Amazon Translate:
Essa função também deve ter uma política de permissões que conceda ao Amazon Translate acesso de leitura à pasta de entrada e às subpastas no Amazon S3 que contêm os documentos de origem e acesso de leitura/gravação ao bucket e à pasta do S3 de saída que contém os documentos traduzidos:
Para executar os notebooks Jupyter no SageMaker para os trabalhos de tradução, precisamos conceder uma política de permissão em linha à função de execução do SageMaker. Essa função passa a função do serviço Amazon Translate para o SageMaker, que permite que os notebooks do SageMaker tenham acesso à origem e aos documentos traduzidos nos buckets S3 designados:
Preparar amostras de treinamento de dados paralelos
Os dados paralelos no ACT precisam ser treinados por um arquivo de entrada que consiste em uma lista de pares de exemplos textuais, por exemplo, um par de idioma de origem (inglês) e idioma de destino (chinês). O arquivo de entrada pode estar no formato TMX, CSV ou TSV. A captura de tela a seguir mostra um exemplo de arquivo de entrada CSV. A primeira coluna contém os dados do idioma de origem (em inglês) e a segunda coluna contém os dados do idioma de destino (em chinês). O exemplo a seguir foi extraído do livro D2L-en e do livro D2L-zh.

Realize treinamento de dados paralelos personalizados no Amazon Translate
Primeiro, configuramos o bucket S3 e as pastas conforme mostrado na captura de tela a seguir. O source_data pasta contém os documentos de origem antes da tradução; os documentos gerados após a tradução em lote são colocados na pasta de saída. O ParallelData A pasta contém o arquivo de entrada de dados paralelos preparado na etapa anterior.
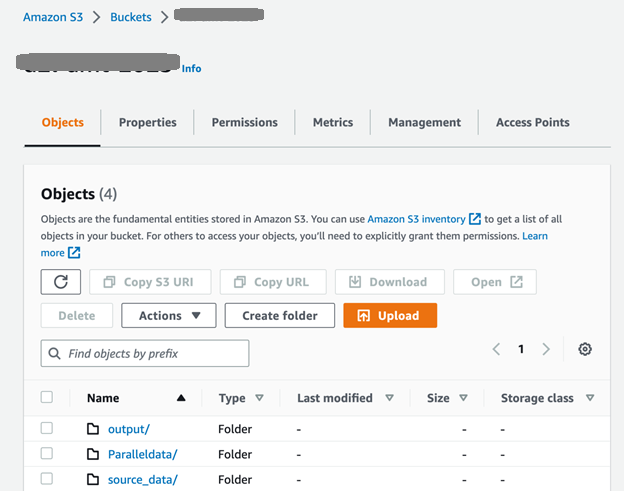
Depois de carregar os arquivos de entrada para o source_data pasta, podemos usar o API CreateParallelData para executar um trabalho paralelo de criação de dados no Amazon Translate:
Para atualizar os dados paralelos existentes com novos conjuntos de dados de treinamento, podemos usar o API UpdateParallelData:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data( Name=pd_name, # pd_name is the parallel data name Description=pd_description, # pd_description is the parallel data description ParallelDataConfig={ 'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step 'Format': 'CSV' },
)
print(pd_name, ": ", response_t['Status'], " updated.")
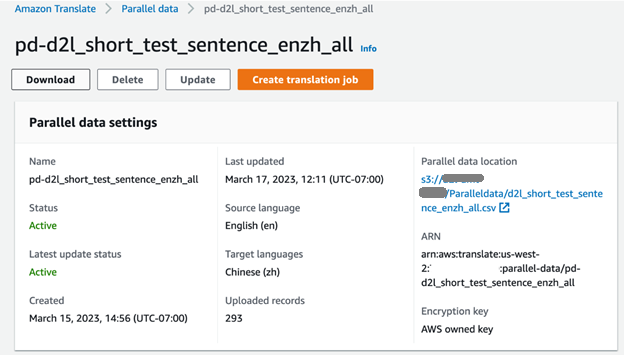
Podemos verificar o progresso do trabalho de treinamento no console do Amazon Translate. Quando a tarefa estiver concluída, o status dos dados paralelos será exibido como Ativo e está pronto para usar.
Execute a tradução em lote assincronizada usando dados paralelos
A tradução em lote pode ser realizada em um processo em que vários documentos de origem são traduzidos automaticamente em documentos nos idiomas de destino. O processo envolve o upload dos documentos de origem para a pasta de entrada do bucket S3 e, em seguida, a aplicação do API StartTextTranslationJob do Amazon Translate para iniciar um trabalho de tradução assíncrona:
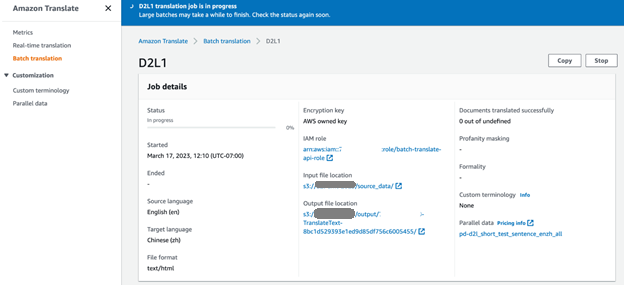
Selecionamos cinco documentos originais em inglês do livro D2L (D2L-en) para a tradução em massa. No console do Amazon Translate, podemos monitorar o andamento do trabalho de tradução. Quando o status do trabalho muda para Efetuado, podemos encontrar os documentos traduzidos em chinês (D2L-zh) na pasta de saída do bucket S3.
Avalie a qualidade da tradução
Para demonstrar a eficácia do recurso ACT no Amazon Translate, também aplicamos o método tradicional de tradução em tempo real do Amazon Translate sem dados paralelos para processar os mesmos documentos e comparamos a saída com a saída de tradução em lote com ACT. Usamos a pontuação BLEU (BiLingual Evaluation Understudy) para avaliar a qualidade da tradução entre os dois métodos. A única maneira de medir com precisão a qualidade da tradução automática é ter uma revisão especializada e classificar a qualidade. No entanto, BLEU fornece uma estimativa de melhoria de qualidade relativa entre duas saídas. Uma pontuação BLEU é tipicamente um número entre 0–1; calcula a semelhança da tradução automática com a tradução humana de referência. A pontuação mais alta representa melhor qualidade na compreensão da linguagem natural (NLU).
Testamos um conjunto de documentos em quatro canais: inglês para chinês (en para zh), chinês para inglês (zh para en), inglês para espanhol (en para es) e espanhol para inglês (es para en). A figura a seguir mostra que a tradução com ACT produziu uma pontuação BLEU média mais alta em todos os pipelines de tradução.
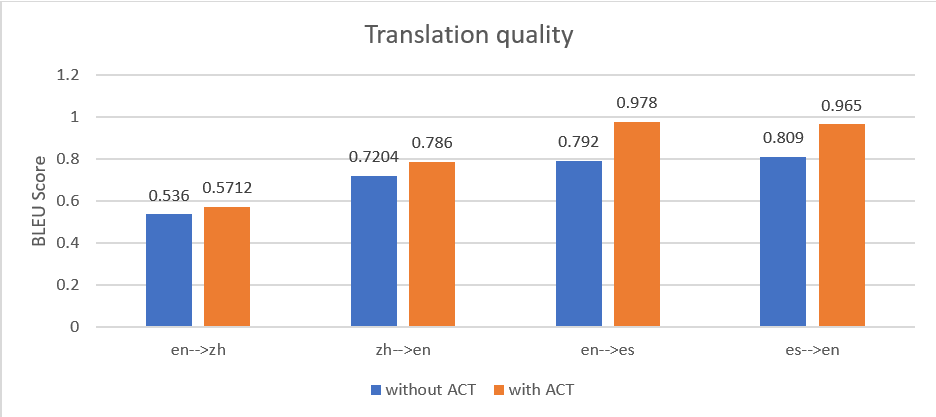
Também observamos que, quanto mais granulares forem os pares de dados paralelos, melhor será o desempenho da tradução. Por exemplo, usamos o seguinte arquivo de entrada de dados paralelos com pares de parágrafos, que contém 10 entradas.

Para o mesmo conteúdo, usamos o seguinte arquivo paralelo de entrada de dados com pares de sentenças e 16 entradas.

Usamos os dois arquivos de entrada de dados paralelos para construir duas entidades de dados paralelas no Amazon Translate e, em seguida, criamos dois trabalhos de tradução em lote com o mesmo documento de origem. A figura a seguir compara as traduções de saída. Isso mostra que a saída usando dados paralelos com pares de sentenças superou aquela usando dados paralelos com pares de parágrafos, tanto para tradução de inglês para chinês quanto para tradução de chinês para inglês.
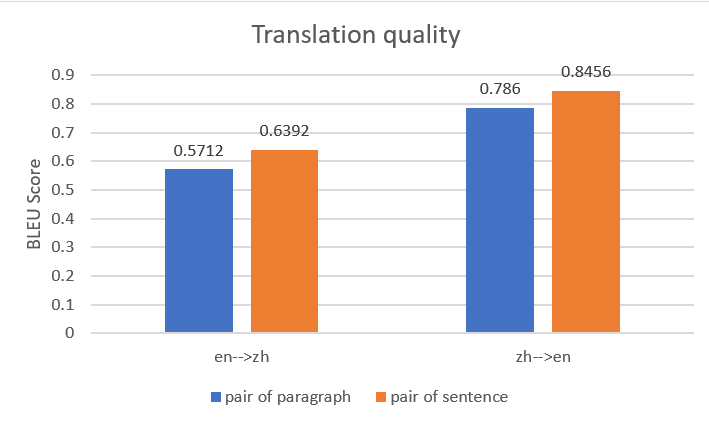
Se você estiver interessado em aprender mais sobre essas análises de benchmark, consulte Tradução Automática e Sincronização para “Dive into Deep Learning”.
limpar
Para evitar custos recorrentes no futuro, recomendamos que você limpe os recursos que criou:
- No console do Amazon Translate, selecione os dados paralelos que você criou e escolha Apagar. Alternativamente, você pode usar o API DeleteParallelData ou de Interface de linha de comando da AWS (AWS CLI) excluir dados paralelos comando para excluir os dados paralelos.
- Excluir o balde S3 usado para hospedar os documentos de origem e referência, documentos traduzidos e arquivos paralelos de entrada de dados.
- Exclua a função e a política do IAM. Para obter instruções, consulte Excluindo funções ou perfis de instância e Excluindo políticas de IAM.
Conclusão
Com esta solução, pretendemos reduzir a carga de trabalho dos tradutores humanos em 80%, mantendo a qualidade da tradução e suportando vários idiomas. Você pode usar esta solução para melhorar a qualidade e eficiência de sua tradução. Estamos trabalhando para melhorar ainda mais a arquitetura da solução e a qualidade da tradução para outros idiomas.
Seus comentários são sempre bem-vindos; por favor, deixe seus pensamentos e perguntas na seção de comentários.
Sobre os autores
 Yun Fei Bai é Arquiteto de Soluções Sênior na AWS. Com experiência em IA/ML, ciência de dados e análise, Yunfei ajuda os clientes a adotar os serviços da AWS para fornecer resultados de negócios. Ele projeta soluções de AI/ML e análise de dados que superam desafios técnicos complexos e impulsionam objetivos estratégicos. Yunfei é PhD em Engenharia Elétrica e Eletrônica. Fora do trabalho, Yunfei gosta de ler e ouvir música.
Yun Fei Bai é Arquiteto de Soluções Sênior na AWS. Com experiência em IA/ML, ciência de dados e análise, Yunfei ajuda os clientes a adotar os serviços da AWS para fornecer resultados de negócios. Ele projeta soluções de AI/ML e análise de dados que superam desafios técnicos complexos e impulsionam objetivos estratégicos. Yunfei é PhD em Engenharia Elétrica e Eletrônica. Fora do trabalho, Yunfei gosta de ler e ouvir música.
 Raquel Hu é um cientista aplicado na AWS Machine Learning University (MLU). Ela tem liderado alguns projetos de curso, incluindo ML Operations (MLOps) e Accelerator Computer Vision. Rachel é palestrante sênior da AWS e falou nas principais conferências, incluindo AWS re:Invent, NVIDIA GTC, KDD e MLOps Summit. Antes de ingressar na AWS, Rachel trabalhou como engenheira de aprendizado de máquina criando modelos de processamento de linguagem natural. Fora do trabalho, ela gosta de ioga, frisbee, leitura e viagens.
Raquel Hu é um cientista aplicado na AWS Machine Learning University (MLU). Ela tem liderado alguns projetos de curso, incluindo ML Operations (MLOps) e Accelerator Computer Vision. Rachel é palestrante sênior da AWS e falou nas principais conferências, incluindo AWS re:Invent, NVIDIA GTC, KDD e MLOps Summit. Antes de ingressar na AWS, Rachel trabalhou como engenheira de aprendizado de máquina criando modelos de processamento de linguagem natural. Fora do trabalho, ela gosta de ioga, frisbee, leitura e viagens.
 Watson Srivathsan é o principal gerente de produto do Amazon Translate, o serviço de processamento de linguagem natural da AWS. Nos fins de semana, você o encontrará explorando o ar livre no noroeste do Pacífico.
Watson Srivathsan é o principal gerente de produto do Amazon Translate, o serviço de processamento de linguagem natural da AWS. Nos fins de semana, você o encontrará explorando o ar livre no noroeste do Pacífico.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- EVM Finanças. Interface unificada para finanças descentralizadas. Acesse aqui.
- Grupo de Mídia Quântica. IR/PR Amplificado. Acesse aqui.
- PlatoAiStream. Inteligência de Dados Web3. Conhecimento Amplificado. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-a-multilingual-automatic-translation-pipeline-with-amazon-translate-active-custom-translation/

