A ascensão da pesquisa contextual e semântica tornou a pesquisa das empresas de comércio eletrônico e varejo mais simples para seus consumidores. Os mecanismos de pesquisa e os sistemas de recomendação alimentados por IA generativa podem melhorar exponencialmente a experiência de pesquisa de produtos, compreendendo as consultas em linguagem natural e retornando resultados mais precisos. Isso melhora a experiência geral do usuário, ajudando os clientes a encontrar exatamente o que procuram.
Serviço Amazon OpenSearch agora suporta o similaridade de cosseno métrica para índices k-NN. A similaridade de cosseno mede o cosseno do ângulo entre dois vetores, onde um ângulo de cosseno menor denota uma maior similaridade entre os vetores. Com similaridade de cosseno, você pode medir a orientação entre dois vetores, o que o torna uma boa escolha para alguns aplicativos de pesquisa semântica específicos.
Nesta postagem, mostramos como construir um mecanismo de pesquisa contextual de texto e imagens para recomendações de produtos usando o Modelo de incorporações multimodais Amazon Titan, Disponível em Rocha Amazônica, com Amazon OpenSearch sem servidor.
Um modelo de incorporação multimodal é projetado para aprender representações conjuntas de diferentes modalidades, como texto, imagens e áudio. Ao treinar em conjuntos de dados em grande escala contendo imagens e suas legendas correspondentes, um modelo de incorporação multimodal aprende a incorporar imagens e textos em um espaço latente compartilhado. A seguir está uma visão geral de alto nível de como funciona conceitualmente:
- Codificadores separados – Esses modelos têm codificadores separados para cada modalidade – um codificador de texto para texto (por exemplo, BERT ou RoBERTa), codificador de imagem para imagens (por exemplo, CNN para imagens) e codificadores de áudio para áudio (por exemplo, modelos como Wav2Vec) . Cada codificador gera embeddings capturando características semânticas de suas respectivas modalidades
- Fusão de modalidades – As incorporações dos codificadores unimodais são combinadas usando camadas adicionais de rede neural. O objetivo é aprender interações e correlações entre as modalidades. As abordagens comuns de fusão incluem concatenação, operações elemento a elemento, agrupamento e mecanismos de atenção.
- Espaço de representação compartilhado – As camadas de fusão ajudam a projetar as modalidades individuais em um espaço de representação compartilhado. Ao treinar em conjuntos de dados multimodais, o modelo aprende um espaço de incorporação comum onde os embeddings de cada modalidade que representam o mesmo conteúdo semântico subjacente estão mais próximos.
- Tarefas posteriores – Os embeddings multimodais conjuntos gerados podem então ser usados para várias tarefas posteriores, como recuperação, classificação ou tradução multimodal. O modelo usa correlações entre modalidades para melhorar o desempenho nessas tarefas em comparação com incorporações modais individuais. A principal vantagem é a capacidade de compreender as interações e a semântica entre modalidades como texto, imagens e áudio por meio de modelagem conjunta.
Visão geral da solução
A solução fornece uma implementação para a construção de um protótipo de mecanismo de pesquisa baseado em modelo de linguagem grande (LLM) para recuperar e recomendar produtos com base em consultas de texto ou imagem. Detalhamos as etapas para usar um Incorporações multimodais do Amazon Titan modelo para codificar imagens e texto em embeddings, ingerir embeddings em um índice do OpenSearch Service e consultar o índice usando o OpenSearch Service Funcionalidade de k-vizinhos mais próximos (k-NN).
Esta solução inclui os seguintes componentes:
- Modelo de incorporações multimodais Amazon Titan – Este modelo de base (FM) gera embeddings das imagens dos produtos utilizados neste post. Com o Amazon Titan Multimodal Embeddings, você pode gerar embeddings para seu conteúdo e armazená-los em um banco de dados vetorial. Quando um usuário final envia qualquer combinação de texto e imagem como uma consulta de pesquisa, o modelo gera embeddings para a consulta de pesquisa e os combina com os embeddings armazenados para fornecer resultados de pesquisa e recomendações relevantes aos usuários finais. Você pode personalizar ainda mais o modelo para aprimorar a compreensão de seu conteúdo exclusivo e fornecer resultados mais significativos usando pares imagem-texto para ajuste fino. Por padrão, o modelo gera vetores (incorporação) de 1,024 dimensões e é acessado via Amazon Bedrock. Você também pode gerar dimensões menores para otimizar a velocidade e o desempenho
- Amazon OpenSearch sem servidor – É uma configuração sem servidor sob demanda para OpenSearch Service. Usamos o Amazon OpenSearch Serverless como banco de dados vetorial para armazenar embeddings gerados pelo modelo Amazon Titan Multimodal Embeddings. Um índice criado na coleção Amazon OpenSearch Serverless serve como armazenamento de vetores para nossa solução Retrieval Augmented Generation (RAG).
- Estúdio Amazon SageMaker – É um ambiente de desenvolvimento integrado (IDE) para aprendizado de máquina (ML). Os profissionais de ML podem executar todas as etapas de desenvolvimento de ML, desde a preparação de seus dados até a construção, o treinamento e a implantação de modelos de ML.
O design da solução consiste em duas partes: indexação de dados e pesquisa contextual. Durante a indexação de dados, você processa as imagens do produto para gerar incorporações para essas imagens e, em seguida, preenche o armazenamento de dados vetoriais. Essas etapas são concluídas antes das etapas de interação do usuário.
Na fase de pesquisa contextual, uma consulta de pesquisa (texto ou imagem) do usuário é convertida em embeddings e uma pesquisa por similaridade é executada no banco de dados vetorial para encontrar imagens de produtos semelhantes com base na pesquisa por similaridade. Em seguida, você exibe os principais resultados semelhantes. Todo o código deste post está disponível no GitHub repo.
O diagrama a seguir ilustra a arquitetura da solução.
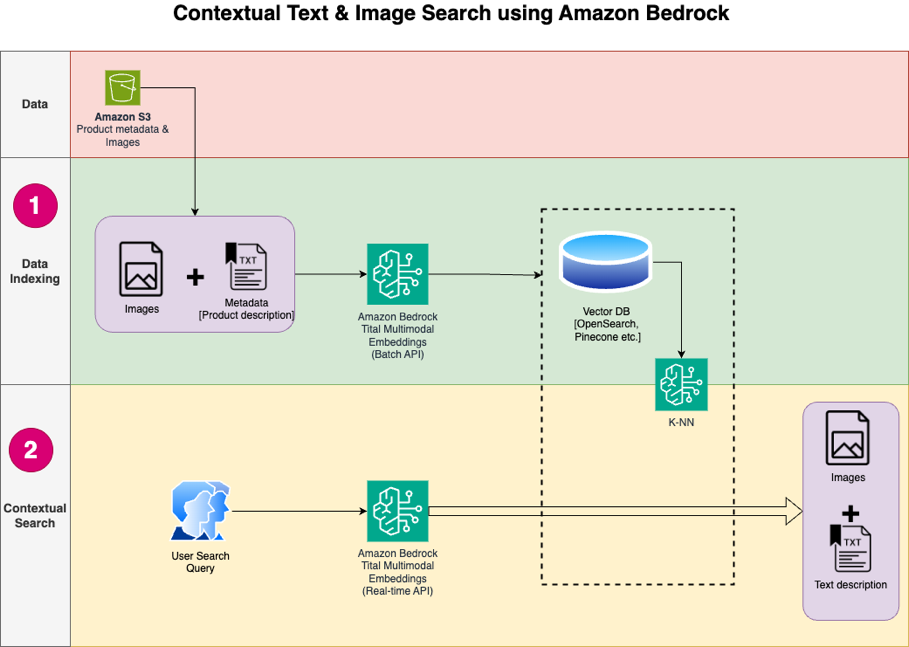
A seguir estão as etapas do fluxo de trabalho da solução:
- Baixe o texto e as imagens da descrição do produto do público Serviço de armazenamento simples da Amazon (Amazon S3).
- Revise e prepare o conjunto de dados.
- Gere embeddings para as imagens do produto usando o modelo Amazon Titan Multimodal Embeddings (amazon.titan-embed-image-v1). Se você tiver um grande número de imagens e descrições, poderá opcionalmente usar o Inferência em lote para Amazon Bedrock.
- Armazene incorporações no Amazon OpenSearch sem servidor como o motor de busca.
- Por fim, busque a consulta do usuário em linguagem natural, converta-a em embeddings usando o modelo Amazon Titan Multimodal Embeddings e execute uma pesquisa k-NN para obter os resultados de pesquisa relevantes.
Usamos o SageMaker Studio (não mostrado no diagrama) como IDE para desenvolver a solução.
Essas etapas são discutidas em detalhes nas seções a seguir. Também incluímos capturas de tela e detalhes do resultado.
Pré-requisitos
Para implementar a solução fornecida nesta postagem, você deve ter o seguinte:
- An Conta da AWS e familiaridade com FMs, Amazon Bedrock, Amazon Sage Makere serviço OpenSearch.
- O modelo Amazon Titan Multimodal Embeddings habilitado no Amazon Bedrock. Você pode confirmar que está ativado no Acesso ao modelo página do console Amazon Bedrock. Se o Amazon Titan Multimodal Embeddings estiver habilitado, o status de acesso será exibido como Acesso concedido, como mostrado na captura de tela a seguir.

Se o modelo não estiver disponível, habilite o acesso ao modelo escolhendo Gerenciar o acesso ao modelo, selecionando Embeddings multimodais Amazon Titan G1e escolhendo Solicitar acesso ao modelo. O modelo é habilitado para uso imediatamente.

Configure a solução
Quando as etapas de pré-requisito forem concluídas, você estará pronto para configurar a solução:
- Na sua conta AWS, abra o console do SageMaker e escolha Studio no painel de navegação.
- Escolha seu domínio e perfil de usuário e escolha Estúdio Aberto.
Seu domínio e nome de perfil de usuário podem ser diferentes.

- Escolha Terminal do sistema para Utilitários e arquivos.
- Execute o seguinte comando para clonar o GitHub repo para a instância do SageMaker Studio:
- Navegue até a
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2epasta. - Abra o
titan_mm_embed_search_blog.ipynbnotebook.
Execute a solução
Abra o arquivo titan_mm_embed_search_blog.ipynb e use o kernel Data Science Python 3. No Execute menu, escolha Executar todas as células para executar o código neste notebook.
Este notebook executa as seguintes etapas:
- Instale os pacotes e bibliotecas necessários para esta solução.
- Carregue o disponível publicamente Conjunto de dados de objetos da Amazon Berkeley e metadados em um quadro de dados do pandas.
O conjunto de dados é uma coleção de 147,702 listagens de produtos com metadados multilíngues e 398,212 imagens de catálogo exclusivas. Para esta postagem, você usa apenas as imagens e nomes dos itens em inglês dos EUA. Você usa aproximadamente 1,600 produtos.

- Gere embeddings para as imagens de itens usando o modelo Amazon Titan Multimodal Embeddings usando o
get_titan_multomodal_embedding()função. Por uma questão de abstração, definimos todas as funções importantes usadas neste caderno noutils.pyarquivo.

Em seguida, você cria e configura um armazenamento de vetores sem servidor do Amazon OpenSearch (coleção e índice).
- Antes de criar a nova coleção e índice de procura de vetores, primeiro você deve criar três políticas associadas do OpenSearch Service: a política de segurança de criptografia, a política de segurança de rede e a política de acesso a dados.

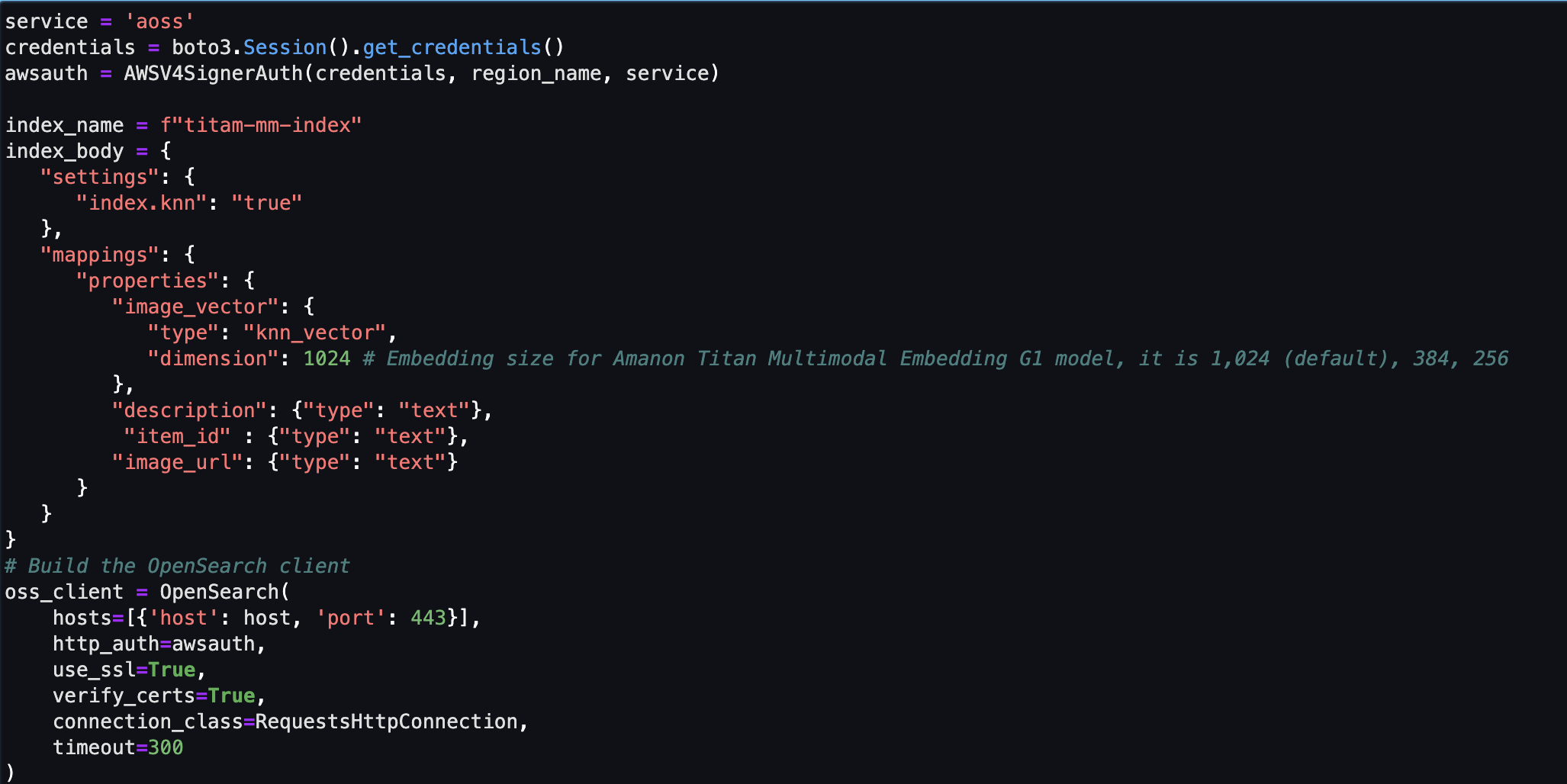
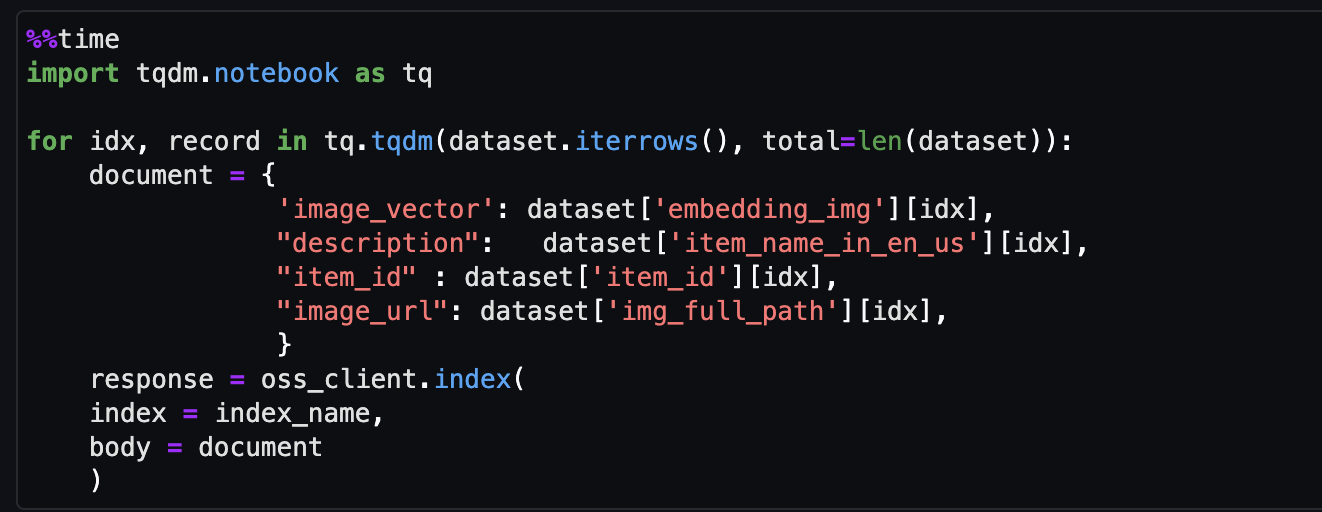
- Por fim, ingira a incorporação da imagem no índice vetorial.
Agora você pode realizar uma pesquisa multimodal em tempo real.
Execute uma pesquisa contextual
Nesta seção, mostramos os resultados da pesquisa contextual com base em uma consulta de texto ou imagem.
Primeiro, vamos realizar uma pesquisa de imagens com base na entrada de texto. No exemplo a seguir, usamos a entrada de texto “copo para bebidas” e enviamos ao mecanismo de busca para encontrar itens semelhantes.
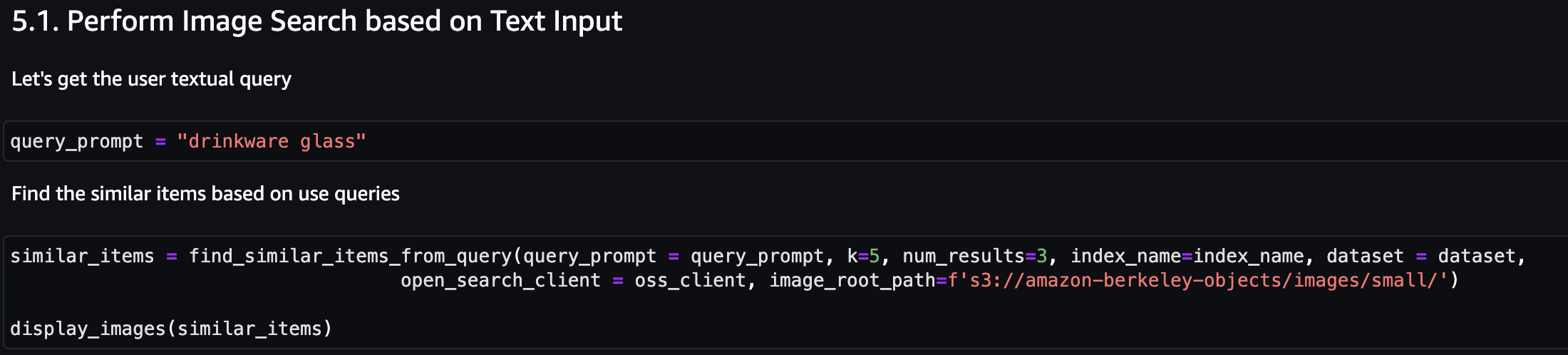
A imagem a seguir mostra os resultados.

Agora vamos ver os resultados com base em uma imagem simples. A imagem de entrada é convertida em embeddings vetoriais e, com base na busca por similaridade, o modelo retorna o resultado.
Você pode usar qualquer imagem, mas para o exemplo a seguir, usamos uma imagem aleatória do conjunto de dados com base no ID do item (por exemplo, item_id = “B07JCDQWM6”) e, em seguida, envie esta imagem ao mecanismo de busca para encontrar itens semelhantes.

A imagem a seguir mostra os resultados.

limpar
Para evitar cobranças futuras, exclua os recursos usados nesta solução. Você pode fazer isso executando a seção de limpeza do notebook.

Conclusão
Esta postagem apresentou um passo a passo do uso do modelo Amazon Titan Multimodal Embeddings no Amazon Bedrock para criar aplicativos de pesquisa contextual poderosos. Em particular, demonstramos um exemplo de aplicativo de pesquisa de lista de produtos. Vimos como o modelo de embeddings permite a descoberta eficiente e precisa de informações a partir de imagens e dados textuais, melhorando assim a experiência do usuário durante a busca pelos itens relevantes.
O Amazon Titan Multimodal Embeddings ajuda você a potencializar experiências de pesquisa, recomendação e personalização multimodais mais precisas e contextualmente relevantes para os usuários finais. Por exemplo, uma empresa de banco de imagens com centenas de milhões de imagens pode usar o modelo para potencializar sua funcionalidade de pesquisa, para que os usuários possam pesquisar imagens usando uma frase, imagem ou uma combinação de imagem e texto.
O modelo Amazon Titan Multimodal Embeddings no Amazon Bedrock já está disponível nas regiões da AWS Leste dos EUA (Norte da Virgínia) e Oeste dos EUA (Oregon). Para saber mais, consulte Amazon Titan Image Generator, Multimodal Embeddings e modelos de texto já estão disponíveis no Amazon Bedrock, Página do produto Amazon Titan, e as Guia do usuário do Amazon Bedrock. Para começar a usar o Amazon Titan Multimodal Embeddings no Amazon Bedrock, visite o Console Amazon Bedrock.
Comece a construir com o modelo Amazon Titan Multimodal Embeddings em Rocha Amazônica hoje mesmo.
Sobre os autores
 Sandeep Singh é cientista sênior de dados de IA generativa na Amazon Web Services, ajudando empresas a inovar com IA generativa. Ele é especialista em IA generativa, inteligência artificial, aprendizado de máquina e design de sistemas. Ele é apaixonado por desenvolver soluções de última geração baseadas em IA/ML para resolver problemas de negócios complexos para diversos setores, otimizando a eficiência e a escalabilidade.
Sandeep Singh é cientista sênior de dados de IA generativa na Amazon Web Services, ajudando empresas a inovar com IA generativa. Ele é especialista em IA generativa, inteligência artificial, aprendizado de máquina e design de sistemas. Ele é apaixonado por desenvolver soluções de última geração baseadas em IA/ML para resolver problemas de negócios complexos para diversos setores, otimizando a eficiência e a escalabilidade.
 Mani Khanuja é líder de tecnologia - especialistas em IA generativa, autora do livro Applied Machine Learning and High Performance Computing on AWS e membro do Conselho de Administração da Women in Manufacturing Education Foundation Board. Ela lidera projetos de aprendizado de máquina em vários domínios, como visão computacional, processamento de linguagem natural e IA generativa. Ela fala em conferências internas e externas, como AWS re:Invent, Women in Manufacturing West, webinars no YouTube e GHC 23. Em seu tempo livre, ela gosta de fazer longas corridas na praia.
Mani Khanuja é líder de tecnologia - especialistas em IA generativa, autora do livro Applied Machine Learning and High Performance Computing on AWS e membro do Conselho de Administração da Women in Manufacturing Education Foundation Board. Ela lidera projetos de aprendizado de máquina em vários domínios, como visão computacional, processamento de linguagem natural e IA generativa. Ela fala em conferências internas e externas, como AWS re:Invent, Women in Manufacturing West, webinars no YouTube e GHC 23. Em seu tempo livre, ela gosta de fazer longas corridas na praia.
 Rupinder Grewal é arquiteto de soluções especialista sênior em IA/ML da AWS. Atualmente, ele se concentra no fornecimento de modelos e MLOps no Amazon SageMaker. Antes dessa função, ele trabalhou como engenheiro de aprendizado de máquina construindo e hospedando modelos. Fora do trabalho, ele gosta de jogar tênis e andar de bicicleta em trilhas de montanha.
Rupinder Grewal é arquiteto de soluções especialista sênior em IA/ML da AWS. Atualmente, ele se concentra no fornecimento de modelos e MLOps no Amazon SageMaker. Antes dessa função, ele trabalhou como engenheiro de aprendizado de máquina construindo e hospedando modelos. Fora do trabalho, ele gosta de jogar tênis e andar de bicicleta em trilhas de montanha.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

