Customer 360 (C360) gir en komplett og enhetlig oversikt over en kundes interaksjoner og atferd på tvers av alle kontaktpunkter og kanaler. Denne visningen brukes til å identifisere mønstre og trender i kundeadferd, som kan informere datadrevne beslutninger for å forbedre forretningsresultater. Du kan for eksempel bruke C360 til å segmentere og lage markedsføringskampanjer som er mer sannsynlig å få resonans hos spesifikke kundegrupper.
I 2022 bestilte AWS en studie utført av American Productivity and Quality Center (APQC) for å kvantifisere Forretningsverdien til Customer 360. Følgende figur viser noen av beregningene som er hentet fra studien. Organisasjoner som bruker C360 oppnådde 43.9 % reduksjon i salgssyklusvarighet, 22.8 % økning i kundelevetidsverdi, 25.3 % raskere time to market og 19.1 % forbedring i nett promoterscore (NPS).

Uten C360, møter bedrifter tapte muligheter, unøyaktige rapporter og usammenhengende kundeopplevelser, noe som fører til kundefragang. Å bygge en C360-løsning kan imidlertid være komplisert. EN Gartner markedsføringsundersøkelse fant at bare 14 % av organisasjonene har implementert en C360-løsning, på grunn av manglende konsensus om hva et 360-graders syn betyr, utfordringer med datakvalitet og mangel på tverrfunksjonell styringsstruktur for kundedata.
I dette innlegget diskuterer vi hvordan du kan bruke spesialbygde AWS-tjenester for å lage en ende-til-ende datastrategi for C360 for å forene og styre kundedata som adresserer disse utfordringene. Vi strukturerer den i fem pilarer som driver C360: datainnsamling, forening, analyse, aktivering og datastyring, sammen med en løsningsarkitektur som du kan bruke for implementeringen din.
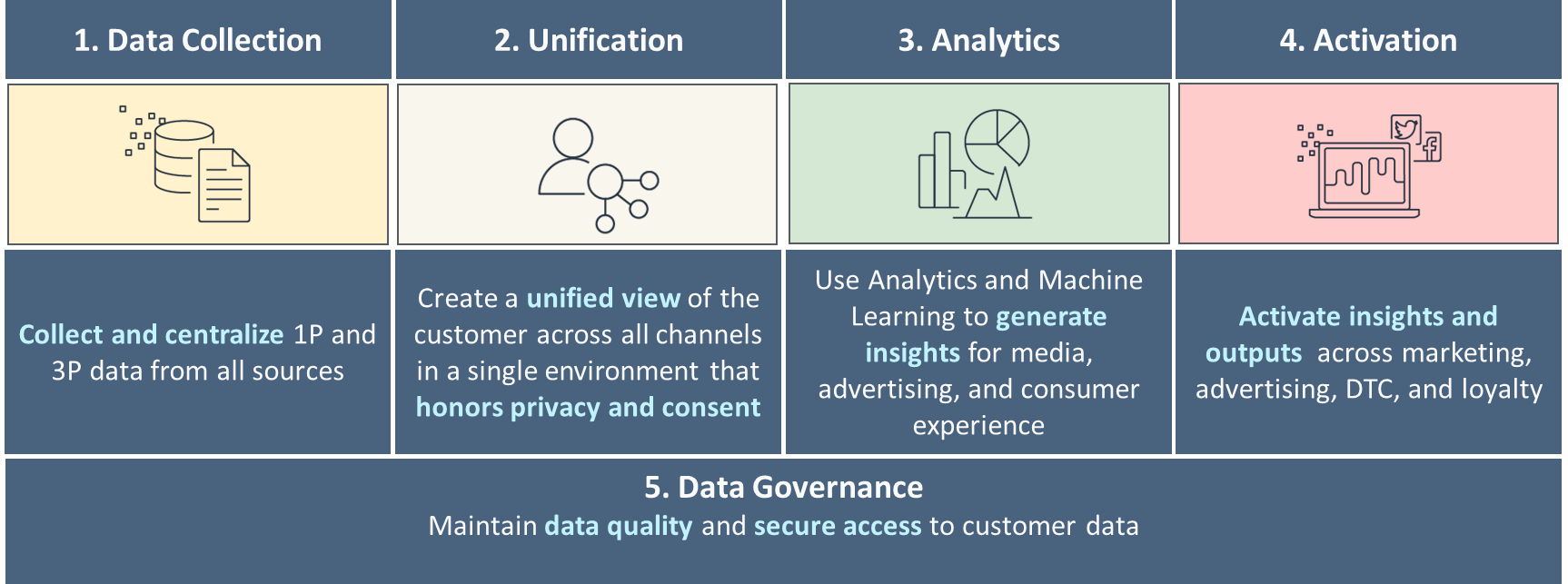
De fem søylene til en moden C360
Når du går i gang med å lage en C360, jobber du med flere brukstilfeller, typer kundedata og brukere og applikasjoner som krever forskjellige verktøy. Å bygge en C360 på de riktige datasettene, legge til nye datasett over tid samtidig som kvaliteten på dataene opprettholdes, og holde den sikker, trenger en ende-til-ende-datastrategi for kundedataene dine. Du må også tilby verktøy som gjør det enkelt for teamene dine å bygge produkter som modner din C360.
Vi anbefaler å bygge din datastrategi rundt fem pilarer i C360, som vist i følgende figur. Dette starter med grunnleggende datainnsamling, forening og kobling av data fra ulike kanaler relatert til unike kunder, og går videre mot grunnleggende til avansert analyse for beslutningstaking, og personlig engasjement gjennom ulike kanaler. Etter hvert som du modnes i hver av disse pilarene, går du videre mot å svare på sanntids kundesignaler.
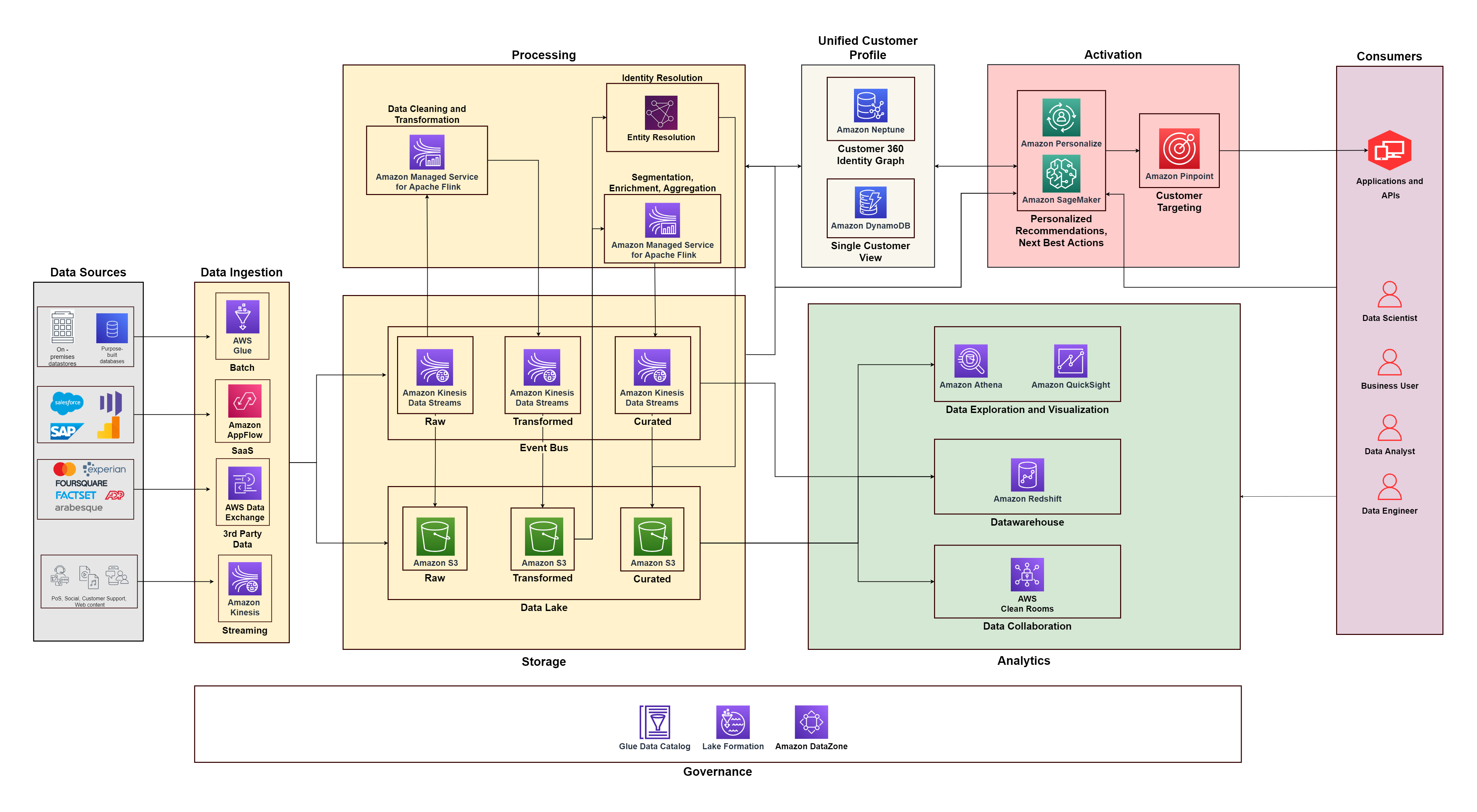
Følgende diagram illustrerer den funksjonelle arkitekturen som kombinerer byggesteinene til en Kundedataplattform på AWS med tilleggskomponenter som brukes til å designe en ende-til-ende C360-løsning. Dette er på linje med de fem pilarene vi diskuterer i dette innlegget.
Pilar 1: Datainnsamling
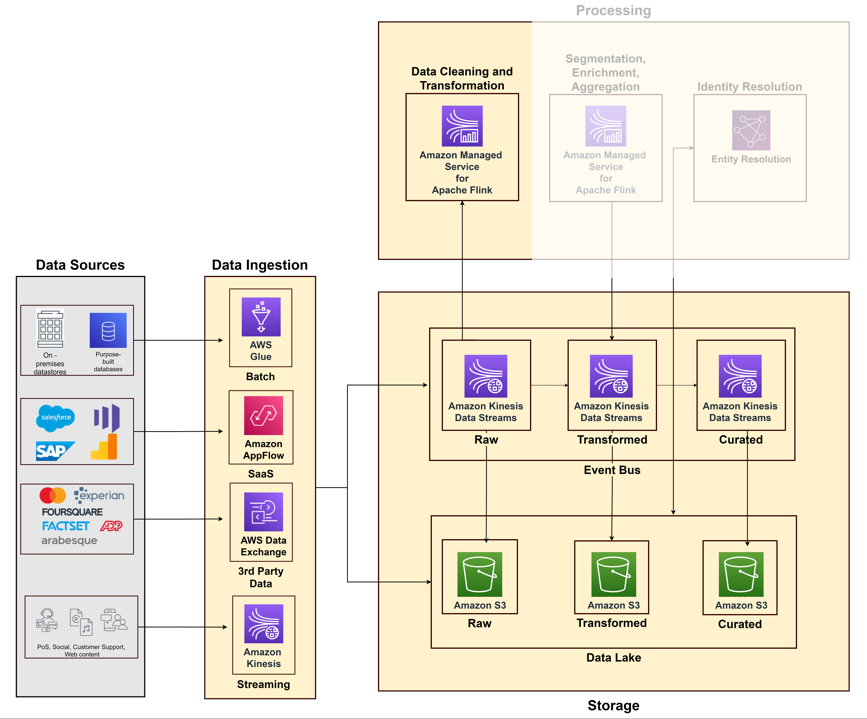
Når du begynner å bygge din kundedataplattform, må du samle inn data fra ulike systemer og berøringspunkter, slik som salgssystemer, kundestøtte, web og sosiale medier og datamarkedsplasser. Tenk på datainnsamlingspilaren som en kombinasjon av inntaks-, lagrings- og prosesseringsevner.
Inntak av data
Du må bygge inntakspipelines basert på faktorer som typer datakilder (lokale datalagre, filer, SaaS-applikasjoner, tredjepartsdata) og dataflyt (ubegrensede strømmer eller batchdata). AWS tilbyr forskjellige tjenester for å bygge rørledninger for datainntak:
- AWS Lim er en serverløs dataintegrasjonstjeneste som tar inn data i batcher fra lokale databaser og datalagre i skyen. Den kobles til mer enn 70 datakilder og hjelper deg med å bygge ut, transformere og laste (ETL) rørledninger uten å måtte administrere rørledningsinfrastruktur. AWS limdatakvalitet sjekker etter og varsler om dårlige data, noe som gjør det enkelt å oppdage og fikse problemer før de skader virksomheten din.
- Amazon App Flow inntar data fra SaaS-applikasjoner (Software as a Service) som Google Analytics, Salesforce, SAP og Marketo, noe som gir deg fleksibiliteten til å innta data fra mer enn 50 SaaS-applikasjoner.
- AWS datautveksling gjør det enkelt å finne, abonnere på og bruke tredjepartsdata for analyser. Du kan abonnere på dataprodukter som bidrar til å berike kundeprofiler, for eksempel demografiske data, annonsedata og finansmarkedsdata.
- Amazon Kinesis inntar strømmehendelser i sanntid fra salgssteder, klikkstrømdata fra mobilapper og nettsteder og sosiale medier. Du kan også vurdere å bruke Amazon administrerte strømming for Apache Kafka (Amazon MSK) for streaming av hendelser i sanntid.
Følgende diagram illustrerer de forskjellige rørledningene for å innta data fra forskjellige kildesystemer ved bruk av AWS-tjenester.
Datalagring
Strukturerte, semistrukturerte eller ustrukturerte batchdata lagres i et objektlager fordi disse er kostnadseffektive og holdbare. Amazon enkel lagringstjeneste (Amazon S3) er en administrert lagringstjeneste med arkiveringsfunksjoner som kan lagre petabyte med data med elleve 9-ere med holdbarhet. Streaming av data med lav latensbehov lagres i Amazon Kinesis datastrømmer for sanntidsforbruk. Dette tillater umiddelbare analyser og handlinger for ulike nedstrømsforbrukere – som sett med Riot Games sentral Riot Event Bus.
Databehandling
Rådata er ofte rotete med duplikater og uregelmessige formater. Du må behandle dette for å gjøre det klart for analyse. Hvis du bruker batchdata og strømming av data, bør du vurdere å bruke et rammeverk som kan håndtere begge deler. Et mønster som Kappa arkitektur ser på alt som en strøm, noe som forenkler prosesseringsrørledningene. Vurder å bruke Amazon Managed Service for Apache Flink å håndtere bearbeidingsarbeidet. Med Managed Service for Apache Flink kan du rense og transformere strømmedataene og dirigere dem til riktig destinasjon basert på latenskrav. Du kan også implementere batchdatabehandling ved hjelp av Amazon EMR på åpen kildekode-rammeverk som Apache Spark med 3.5 ganger bedre ytelse enn den selvstyrte versjonen. Arkitekturbeslutningen om å bruke et batch- eller streamingbehandlingssystem vil avhenge av ulike faktorer; Hvis du imidlertid ønsker å aktivere sanntidsanalyse av kundedataene dine, anbefaler vi å bruke et Kappa-arkitekturmønster.
Pilar 2: Ensretting
For å koble de mangfoldige dataene som kommer fra ulike kontaktpunkter til en unik kunde, må du bygge en identitetsbehandlingsløsning som identifiserer anonyme pålogginger, lagrer nyttig kundeinformasjon, kobler dem til eksterne data for bedre innsikt og grupperer kunder i interessedomener. Selv om identitetsbehandlingsløsningen bidrar til å bygge den enhetlige kundeprofilen, anbefaler vi å vurdere dette som en del av databehandlingsmulighetene dine. Følgende diagram illustrerer komponentene i en slik løsning.
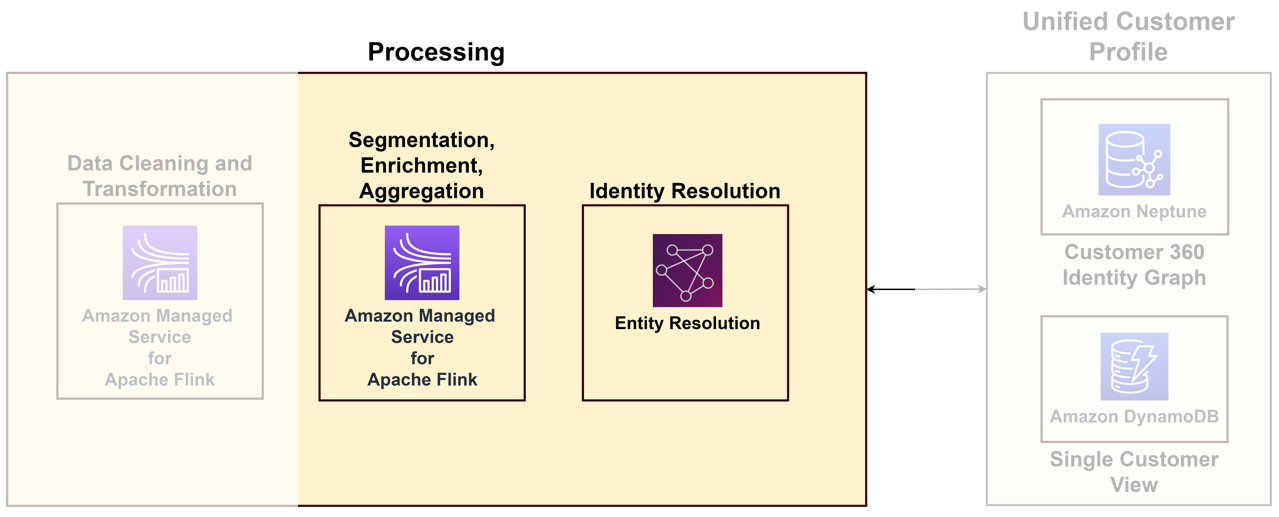
Nøkkelkomponentene er som følger:
- Identitetsoppløsning – Identitetsoppløsning er en dedupliseringsløsning, der poster matches for å identifisere en unik kunde og potensielle kunder ved å koble flere identifikatorer som informasjonskapsler, enhetsidentifikatorer, IP-adresser, e-post-IDer og interne bedrifts-IDer til en kjent person eller anonym profil ved bruk av personvern- kompatible metoder. Dette kan oppnås ved hjelp av AWS-enhetsoppløsning, som gjør det mulig å bruke regler og maskinlæringsteknikker (ML). matche poster og løse identiteter. Alternativt kan du lage identitetsgrafer ved hjelp av Amazon Neptun for én samlet oversikt over kundene dine.
- Profilaggregering – Når du har identifisert en kunde unikt, kan du bygge applikasjoner i Managed Service for Apache Flink å konsolidere alle deres metadata, fra navn til interaksjonshistorikk. Deretter transformerer du disse dataene til et kortfattet format. I stedet for å vise hver transaksjonsdetalj, kan du tilby en samlet forbruksverdi og en kobling til deres Customer Relationship Management (CRM)-post. For kundeserviceinteraksjoner, oppgi en gjennomsnittlig CSAT-poengsum og en kobling til kundesentersystemet for et dypere dykk inn i kommunikasjonshistorikken deres.
- Profilberikelse – Etter at du har løst en kunde til en enkelt identitet, forbedre profilen ved hjelp av ulike datakilder. Berikelse innebærer vanligvis å legge til demografiske, atferdsmessige og geolokaliseringsdata. Du kan bruke tredjeparts dataprodukter fra AWS Marketplace levert gjennom AWS Data Exchange for å få innsikt i inntekt, forbruksmønstre, kredittrisikoscore og mange flere dimensjoner for å avgrense kundeopplevelsen ytterligere.
- Kundesegmentering – Etter å ha identifisert og beriket en kundes profil unikt, kan du segmentere dem basert på demografi som alder, forbruk, inntekt og plassering ved å bruke applikasjoner i Managed Service for Apache Flink. Etter hvert som du avanserer, kan du innlemme AI-tjenester for mer presise målrettingsteknikker.
Etter at du har utført identitetsbehandlingen og segmenteringen, trenger du en lagringskapasitet for å lagre den unike kundeprofilen og tilby søke- og spørringsmuligheter på toppen av den slik at nedstrømsforbrukere kan bruke de berikede kundedataene.
Følgende diagram illustrerer enhetssøylen for en enhetlig kundeprofil og enkeltvisning av kunden for nedstrømsapplikasjoner.
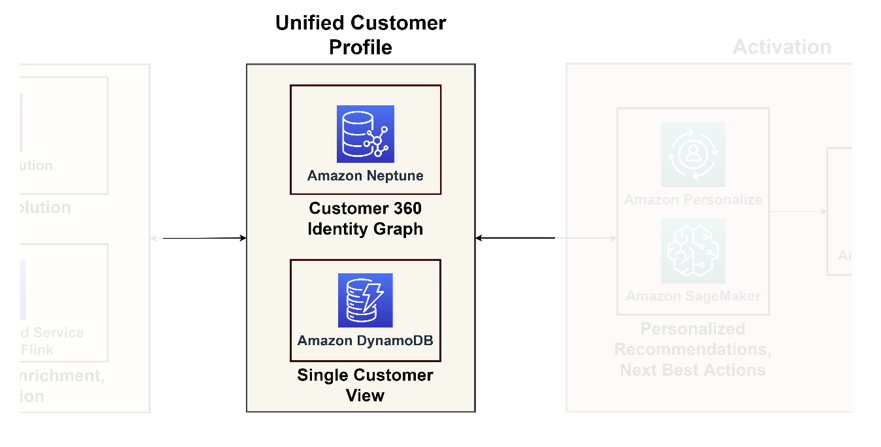
Samlet kundeprofil
Grafdatabaser utmerker seg når det gjelder å modellere kundeinteraksjoner og relasjoner, og tilbyr en omfattende oversikt over kundereisen. Hvis du har å gjøre med milliarder av profiler og interaksjoner, kan du vurdere å bruke Neptune, en administrert grafdatabasetjeneste på AWS. Organisasjoner som f.eks Zeta og Activision har med hell brukt Neptun til å lagre og spørre etter milliarder av unike identifikatorer per måned og millioner av spørringer per sekund på millisekunders responstid.
Enkel kundevisning
Selv om grafdatabaser gir dyptgående innsikt, kan de likevel være komplekse for vanlige applikasjoner. Det er klokt å konsolidere disse dataene i en enkelt kundevisning, som fungerer som en primær referanse for nedstrømsapplikasjoner, alt fra e-handelsplattformer til CRM-systemer. Dette konsoliderte synet fungerer som et bindeledd mellom dataplattformen og kundesentriske applikasjoner. For slike formål anbefaler vi å bruke Amazon DynamoDB for sin tilpasningsevne, skalerbarhet og ytelse, noe som resulterer i en oppdatert og effektiv kundedatabase. Denne databasen vil akseptere mange skrivespørsmål tilbake fra aktiveringssystemene som lærer ny informasjon om kundene og gir dem tilbake.
Pilar 3: Analytics
Analysesøylen definerer funksjoner som hjelper deg med å generere innsikt på toppen av kundedataene dine. Din analysestrategi gjelder de bredere organisasjonsbehovene, ikke bare C360. Du kan bruke de samme egenskapene til å betjene finansiell rapportering, måle operasjonell ytelse eller til og med tjene penger på dataressurser. Strategier basert på hvordan teamene dine utforsker data, kjører analyser, krangle data for nedstrømskrav og visualiser data på forskjellige nivåer. Planlegg hvordan du kan gjøre det mulig for teamene dine å bruke ML for å gå fra beskrivende til foreskrivende analyser.
De AWS moderne dataarkitektur viser en måte å bygge en spesialbygd, sikker og skalerbar dataplattform i skyen. Lær av dette for å bygge spørringsmuligheter på tvers av datainnsjøen og datavarehuset.
Følgende diagram bryter ned analysefunksjonen i datautforskning, visualisering, datavarehus og datasamarbeid. La oss finne ut hvilken rolle hver av disse komponentene spiller i forbindelse med C360.

Data leting
Datautforskning hjelper til med å avdekke inkonsekvenser, avvik eller feil. Ved å oppdage disse tidlig, kan teamene dine få renere dataintegrasjon for C360, som igjen fører til mer nøyaktige analyser og spådommer. Vurder personene som utforsker dataene, deres tekniske ferdigheter og tiden til innsikt. For eksempel kan dataanalytikere som vet å skrive SQL direkte spørre dataene som ligger i Amazon S3 ved å bruke Amazonas Athena. Brukere som er interessert i visuell utforskning kan gjøre det ved å bruke AWS Lim DataBrew. Dataforskere eller ingeniører kan bruke Amazon EMR Studio or Amazon SageMaker Studio for å utforske data fra den bærbare datamaskinen, og for en lavkodeopplevelse kan du bruke Amazon SageMaker Data Wrangler. Fordi disse tjenestene spør direkte etter S3-bøtter, kan du utforske dataene når de lander i datasjøen, noe som reduserer tiden til innsikt.
Visualisering
Å gjøre om komplekse datasett til intuitive bilder avdekker skjulte mønstre i dataene, og er avgjørende for C360-bruk. Med denne funksjonen kan du designe rapporter for ulike nivåer som imøtekommer ulike behov: lederrapporter som tilbyr strategiske oversikter, ledelsesrapporter som fremhever operasjonelle beregninger, og detaljerte rapporter som dykker ned i detaljene. Slik visuell klarhet hjelper organisasjonen din med å ta informerte beslutninger på tvers av alle nivåer, og sentraliserer kundens perspektiv.
Følgende diagram viser et eksempel på C360-dashbord bygget på Amazon QuickSight. QuickSight tilbyr skalerbare, serverløse visualiseringsmuligheter. Du kan dra nytte av ML-integrasjonene for automatisert innsikt som prognoser og oppdagelse av anomalier eller spørringer med naturlig språk med Amazon Q i QuickSight, direkte datatilkobling fra ulike kilder, og betal-per-økt-priser. Med QuickSight kan du legge inn dashboards til eksterne nettsteder og applikasjoner, og KRYDDER motoren muliggjør rask, interaktiv datavisualisering i stor skala. Følgende skjermbilde viser et eksempel på et C360-dashbord bygget på QuickSight.
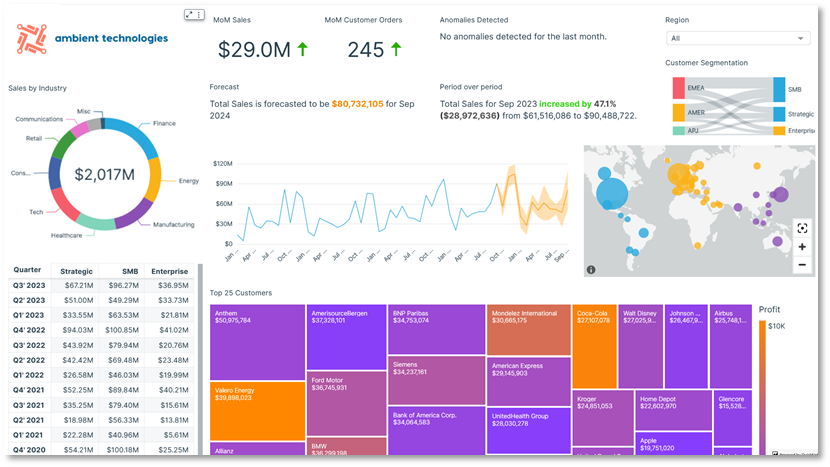
Datavarehus
Datavarehus er effektive når det gjelder å konsolidere strukturerte data fra mange forskjellige kilder og betjene analyseforespørsler fra et stort antall samtidige brukere. Datavarehus kan gi en enhetlig, konsistent oversikt over en stor mengde kundedata for C360-brukstilfeller. Amazon RedShift dekker dette behovet ved å håndtere store datamengder og ulike arbeidsmengder på en dyktig måte. Det gir sterk konsistens på tvers av datasett, slik at organisasjoner kan utlede pålitelig, omfattende innsikt om kundene sine, noe som er avgjørende for informert beslutningstaking. Amazon Redshift tilbyr sanntidsinnsikt og prediktive analysefunksjoner for å analysere data fra terabyte til petabyte. Med Amazon Redshift ML, kan du bygge inn ML på toppen av dataene som er lagret i datavarehuset med minimale utviklingskostnader. Amazon Redshift Serverløs forenkler applikasjonsbygging og gjør det enkelt for bedrifter å bygge inn rike dataanalysefunksjoner.
Datasamarbeid
Du kan trygt samarbeide og analysere kollektive datasett fra partnerne dine uten å dele eller kopiere hverandres underliggende data ved å bruke AWS rene rom. Du kan samle ulike data fra tvers av engasjementskanaler og partnerdatasett for å danne en 360-graders oversikt over kundene dine. AWS Clean Rooms kan forbedre C360 ved å muliggjøre brukstilfeller som markedsføringsoptimalisering på tvers av kanaler, avansert kundesegmentering og personvernkompatibel personalisering. Ved å slå sammen datasett på en sikker måte, gir den rikere innsikt og robust datapersonvern, som oppfyller forretningsbehov og regulatoriske standarder.
Pilar 4: Aktivering
Verdien av data avtar jo eldre den blir, noe som fører til høyere alternativkostnader over tid. I en undersøkelse utført av Intersystems, 75 % av de spurte organisasjonene mener at utidige data hindret forretningsmuligheter. I en annen undersøkelse, 58% av organisasjonene (av 560 respondenter fra HBR Advisory Council og lesere) uttalte at de så en økning i kundebevaring og lojalitet ved å bruke sanntids kundeanalyse.
Du kan oppnå en modenhet i C360 når du bygger evnen til å handle på all innsikten som er oppnådd fra de forrige pilarene vi diskuterte i sanntid. For eksempel, på dette modenhetsnivået, kan du handle på kundesentiment basert på konteksten du automatisk utledet med en beriket kundeprofil og integrerte kanaler. For dette må du implementere preskriptive beslutninger om hvordan du skal adressere kundens følelser. For å gjøre dette i stor skala, må du bruke AI/ML-tjenester for beslutningstaking. Følgende diagram illustrerer arkitekturen for å aktivere innsikt ved bruk av ML for foreskrivende analyse og AI-tjenester for målretting og segmentering.
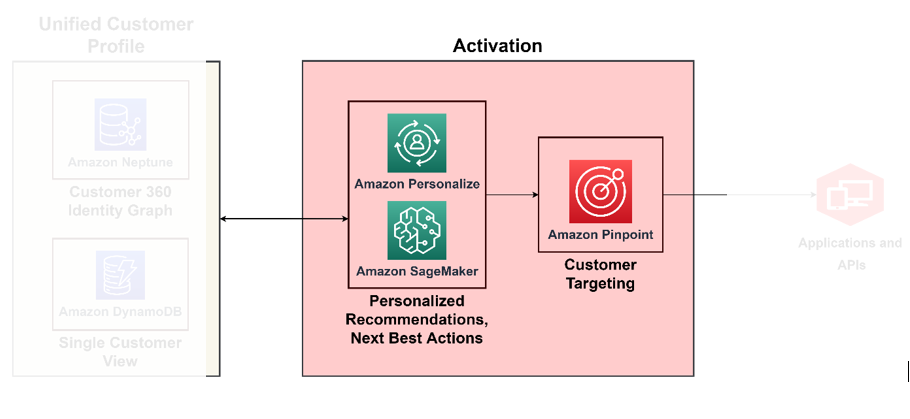
Bruk ML for beslutningsmotoren
Med ML kan du forbedre den generelle kundeopplevelsen – du kan lage prediktive kundeatferdsmodeller, utforme hyper-personlige tilbud og målrette den rette kunden med riktig insentiv. Du kan bygge dem ved hjelp av Amazon SageMaker, som inneholder en pakke med administrerte tjenester kartlagt til datavitenskapens livssyklus, inkludert datakrangel, modellopplæring, modellvert, modellslutning, deteksjon av modelldrift og funksjonslagring. SageMaker lar deg bygge og operasjonalisere ML-modellene dine, ved å sette dem tilbake i applikasjonene dine for å gi rett innsikt til rett person til rett tid.
Amazon Tilpasse støtter kontekstuelle anbefalinger, der du kan forbedre relevansen til anbefalinger ved å generere dem innenfor en kontekst – for eksempel enhetstype, plassering eller tid på dagen. Teamet ditt kan komme i gang uten tidligere ML-erfaring ved å bruke APIer for å bygge sofistikerte personaliseringsmuligheter med noen få klikk. For mer informasjon, se Tilpass anbefalingene dine ved å markedsføre spesifikke varer ved å bruke forretningsregler med Amazon Personalize.
Aktiver kanaler på tvers av markedsføring, annonsering, direkte til forbruker og lojalitet
Nå som du vet hvem kundene dine er og hvem du skal nå ut til, kan du bygge løsninger for å kjøre målrettingskampanjer i stor skala. Med Amazon nøyaktig, kan du tilpasse og segmentere kommunikasjon for å engasjere kunder på tvers av flere kanaler. Du kan for eksempel bruke Amazon Pinpoint til bygge engasjerende kundeopplevelser gjennom ulike kommunikasjonskanaler som e-post, SMS, push-varslinger og in-app-varslinger.
Pilar 5: Datastyring
Etablering av riktig styring som balanserer kontroll og tilgang gir brukere tillit og tillit til data. Tenk deg å tilby kampanjer på produkter som en kunde ikke trenger, eller bombardere feil kunder med varsler. Dårlig datakvalitet kan føre til slike situasjoner, og resulterer til slutt i kundefragang. Du må bygge prosesser som validerer datakvaliteten og ta korrigerende tiltak. AWS limdatakvalitet kan hjelpe deg med å bygge løsninger som validerer kvaliteten på data i hvile og under transport, basert på forhåndsdefinerte regler.
For å sette opp en tverrfunksjonell styringsstruktur for kundedata, trenger du en evne til å styre og dele data på tvers av organisasjonen. Med Amazon DataZone, kan administratorer og dataforvaltere administrere og styre tilgang til data, og forbrukere som dataingeniører, dataforskere, produktsjefer, analytikere og andre forretningsbrukere kan oppdage, bruke og samarbeide med disse dataene for å få innsikt. Det strømlinjeformer datatilgang, lar deg finne og bruke kundedata, fremmer teamsamarbeid med delte dataressurser, og gir personlig tilpassede analyser enten via en nettapp eller API på en portal. AWS Lake formasjon sørger for sikker tilgang til data, og garanterer at de rette personene ser de riktige dataene av de riktige grunnene, noe som er avgjørende for effektiv tverrfunksjonell styring i enhver organisasjon. Bedriftsmetadata lagres og administreres av Amazon DataZone, som er underbygget av tekniske metadata og skjemainformasjon, som er registrert i AWS Lim Data Catalog. Disse tekniske metadataene brukes også både av andre styringstjenester som Lake Formation og Amazon DataZone, og analysetjenester som Amazon Redshift, Athena og AWS Glue.

Å bringe det hele sammen
Ved å bruke følgende diagram som referanse, kan du opprette prosjekter og team for å bygge og drive forskjellige kapasiteter. For eksempel kan du ha et dataintegreringsteam som fokuserer på datainnsamlingspilaren – du kan deretter justere funksjonelle roller, som dataarkitekter og dataingeniører. Du kan bygge analyse- og datavitenskapspraksisen din for å fokusere på henholdsvis analyse- og aktiveringspilarene. Deretter kan du opprette et spesialisert team for behandling av kundeidentitet og for å bygge det enhetlige synet på kunden. Du kan etablere et datastyringsteam med dataansvarlige fra forskjellige funksjoner, sikkerhetsadministratorer og beslutningstakere for datastyring for å designe og automatisere policyer.
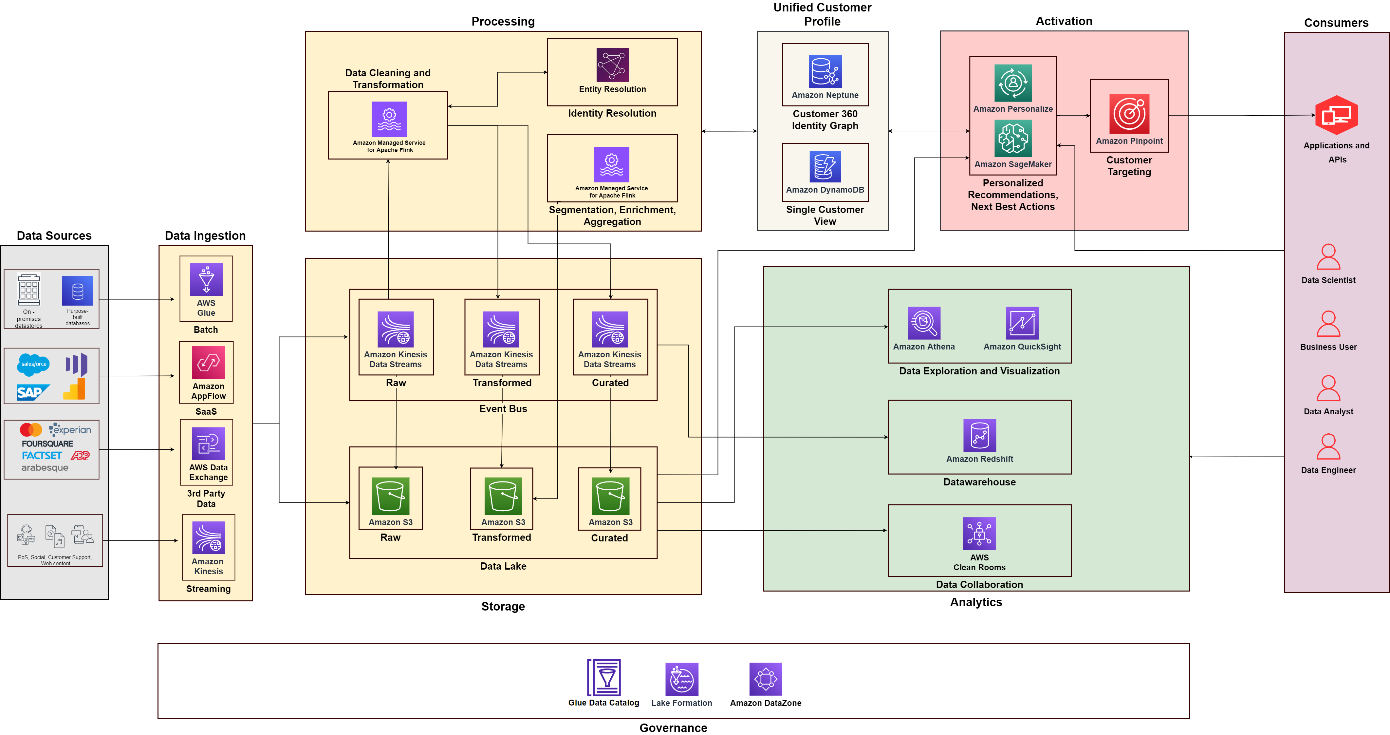
konklusjonen
Å bygge en robust C360-kapasitet er grunnleggende for organisasjonen din for å få innsikt i kundebasen din. AWS-databaser, analyse og AI/ML-tjenester kan bidra til å strømlinjeforme denne prosessen, noe som gir skalerbarhet og effektivitet. Ved å følge de fem pilarene for å veilede tankegangen din, kan du bygge en ende-til-ende datastrategi som definerer C360-visningen på tvers av organisasjonen, sørger for at data er nøyaktige og etablerer tverrfunksjonell styring for kundedata. Du kan kategorisere og prioritere produktene og funksjonene du må bygge innenfor hver pilar, velge riktig verktøy for jobben og bygge ferdighetene du trenger i teamene dine.
Besøk AWS for datakundehistorier for å lære hvordan AWS forvandler kundereiser, fra verdens største bedrifter til voksende startups.
Om forfatterne
 Ismail Makhlouf er Senior Specialist Solutions Architect for Data Analytics hos AWS. Ismail fokuserer på arkitekturløsninger for organisasjoner på tvers av deres ende-til-ende dataanalyseområde, inkludert batch- og sanntidsstrømming, big data, datavarehus og datainnsjø-arbeidsbelastninger. Han jobber primært med organisasjoner innen detaljhandel, e-handel, FinTech, HealthTech og reise for å nå forretningsmålene deres med godt utformede dataplattformer.
Ismail Makhlouf er Senior Specialist Solutions Architect for Data Analytics hos AWS. Ismail fokuserer på arkitekturløsninger for organisasjoner på tvers av deres ende-til-ende dataanalyseområde, inkludert batch- og sanntidsstrømming, big data, datavarehus og datainnsjø-arbeidsbelastninger. Han jobber primært med organisasjoner innen detaljhandel, e-handel, FinTech, HealthTech og reise for å nå forretningsmålene deres med godt utformede dataplattformer.
 Sandipan Bhaumik (Sandi) er Senior Analytics Specialist Solutions Architect hos AWS. Han hjelper kunder med å modernisere dataplattformene sine i skyen for å utføre analyser sikkert i stor skala, redusere driftskostnader og optimalisere bruken for kostnadseffektivitet og bærekraft.
Sandipan Bhaumik (Sandi) er Senior Analytics Specialist Solutions Architect hos AWS. Han hjelper kunder med å modernisere dataplattformene sine i skyen for å utføre analyser sikkert i stor skala, redusere driftskostnader og optimalisere bruken for kostnadseffektivitet og bærekraft.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

