Dette innlegget er skrevet sammen med Aruna Abeyakoon og Denisse Colin fra Light and Wonder (L&W).
Hovedkontor i Las Vegas, Light & Wonder, Inc. er det ledende globale spillselskapet på tvers av plattformer som tilbyr gamblingprodukter og -tjenester. I samarbeid med AWS utviklet Light & Wonder nylig en bransjeførste sikker løsning, Light & Wonder Connect (LnW Connect), for å streame telemetri- og maskinhelsedata fra omtrent en halv million elektroniske spilleautomater fordelt på kasinokundebasen globalt da LnW Connect når sitt fulle potensial. Over 500 maskinhendelser overvåkes i nesten sanntid for å gi et fullstendig bilde av maskinforholdene og deres driftsmiljøer. Ved å bruke data strømmet gjennom LnW Connect, har L&W som mål å skape bedre spillopplevelse for sluttbrukerne deres, samt gi mer verdi til kasinokundene deres.
Light & Wonder slo seg sammen med Amazon ML Solutions Lab å bruke hendelsesdata strømmet fra LnW Connect for å muliggjøre maskinlæring (ML)-drevet prediktivt vedlikehold for spilleautomater. Prediktivt vedlikehold er en vanlig ML-brukstilfelle for virksomheter med fysisk utstyr eller maskineri. Med prediktivt vedlikehold kan L&W få avansert advarsel om maskinhavari og proaktivt sende ut et serviceteam for å inspisere problemet. Dette vil redusere maskinens nedetid og unngå betydelig inntektstap for kasinoer. Uten noe fjerndiagnosesystem på plass, kan problemløsning av Light & Wonder-serviceteamet på kasinogulvet være kostbart og ineffektivt, samtidig som det forringer kundens spillopplevelse.
Prosjektets natur er svært utforskende - dette er det første forsøket på prediktivt vedlikehold i spillindustrien. Amazon ML Solutions Lab og L&W-teamet la ut på en ende-til-ende-reise fra å formulere ML-problemet og definere evalueringsverdiene, til å levere en løsning av høy kvalitet. Den endelige ML-modellen kombinerer CNN og Transformer, som er de toppmoderne nevrale nettverksarkitekturene for modellering av sekvensielle maskinloggdata. Innlegget presenterer en detaljert beskrivelse av denne reisen, og vi håper du vil like den like mye som vi gjør!
I dette innlegget diskuterer vi følgende:
- Hvordan vi formulerte det prediktive vedlikeholdsproblemet som et ML-problem med et sett med passende beregninger for evaluering
- Hvordan vi forberedte data for trening og testing
- Dataforbehandling og funksjonsteknikker vi brukte for å oppnå effektive modeller
- Utføre et hyperparameterjusteringstrinn med Amazon SageMaker Automatisk modellinnstilling
- Sammenligninger mellom grunnlinjemodellen og den endelige CNN+Transformer-modellen
- Ytterligere teknikker vi brukte for å forbedre modellytelsen, for eksempel ensembling
Bakgrunn
I denne delen diskuterer vi problemene som nødvendiggjorde denne løsningen.
datasett
Spilleautomatmiljøer er svært regulerte og er utplassert i et luftgapet miljø. I LnW Connect ble en krypteringsprosess designet for å gi en sikker og pålitelig mekanisme for dataene som skal bringes inn i en AWS-datainnsjø for prediktiv modellering. De aggregerte filene er kryptert og dekrypteringsnøkkelen er kun tilgjengelig i AWS Key Management Service (AWS KMS). Et mobilbasert privat nettverk til AWS er satt opp som filene ble lastet opp til Amazon Simple Storage Service (Amazon S3).
LnW Connect streamer et bredt spekter av maskinbegivenheter, for eksempel spillstart, spillslutt og mer. Systemet samler over 500 ulike typer arrangementer. Som vist i det følgende
, hver hendelse registreres sammen med et tidsstempel for når det skjedde og ID-en til maskinen som registrerer hendelsen. LnW Connect registrerer også når en maskin går inn i en ikke-spillbar tilstand, og den vil bli merket som en maskinfeil eller sammenbrudd hvis den ikke gjenopprettes til en spillbar tilstand innen tilstrekkelig kort tidsrom.
| Maskin ID | Hendelsestype-ID | Tidsstempel |
|---|---|---|
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
I tillegg til dynamiske maskinhendelser, er statiske metadata om hver maskin også tilgjengelig. Dette inkluderer informasjon som maskinunikk identifikator, kabinetttype, plassering, operativsystem, programvareversjon, spilltema og mer, som vist i følgende tabell. (Alle navnene i tabellen er anonymisert for å beskytte kundeinformasjon.)
| Maskin ID | Skapstype | OS | Sted | Spilltema |
|---|---|---|---|---|
| 276 | A | OS_Ver0 | AA Resort & Casino | StormMaiden |
| 167 | B | OS_Ver1 | BB Casino, Resort & Spa | UHMLIndia |
| 13 | C | OS_Ver0 | CC Casino & Hotel | Fantastisk Tiger |
| 307 | D | OS_Ver0 | DD Casino Resort | NeptunesRealm |
| 70 | E | OS_Ver0 | EE Resort & Casino | RLMealTicket |
Problemdefinisjon
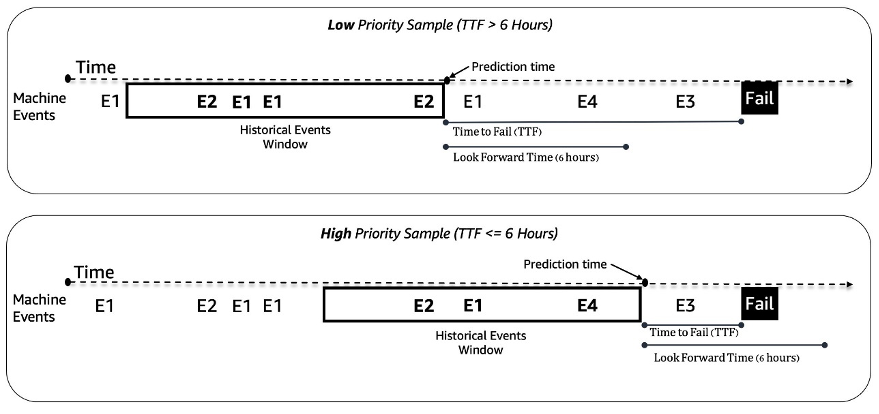
Vi behandler det prediktive vedlikeholdsproblemet for spilleautomater som et binært klassifiseringsproblem. ML-modellen tar inn den historiske sekvensen av maskinhendelser og andre metadata og forutsier om en maskin vil støte på en feil i et 6-timers fremtidig tidsvindu. Hvis en maskin går i stykker innen 6 timer, anses den som en høyprioritert maskin for vedlikehold. Ellers er det lavt prioritert. Følgende figur gir eksempler på prøver med lav prioritet (øverst) og høy prioritet (nederst). Vi bruker et tilbakeblikktidsvindu med fast lengde for å samle inn historiske maskinhendelsesdata for prediksjon. Eksperimenter viser at lengre tilbakeblikkstidsvinduer forbedrer modellens ytelse betydelig (mer detaljer senere i dette innlegget).
Modelleringsutfordringer
Vi møtte et par utfordringer med å løse dette problemet:
- Vi har en enorm mengde hendelseslogger som inneholder rundt 50 millioner hendelser i måneden (fra omtrent 1,000 spillprøver). Nøye optimalisering er nødvendig i datautvinnings- og forbehandlingsstadiet.
- Modellering av hendelsessekvenser var utfordrende på grunn av den ekstremt ujevne fordelingen av hendelser over tid. Et 3-timers vindu kan inneholde alt fra titalls til tusenvis av hendelser.
- Maskiner er i god stand mesteparten av tiden, og det høyprioriterte vedlikeholdet er en sjelden klasse, som introduserte et problem med klasseubalanse.
- Nye maskiner legges fortløpende til systemet, så vi måtte sørge for at modellen vår kan håndtere prediksjon på nye maskiner som aldri har vært sett i trening.
Dataforbehandling og funksjonsutvikling
I denne delen diskuterer vi våre metoder for dataforberedelse og funksjonsutvikling.
Funksjonsteknikk
Spilleautomatfeeder er strømmer av ulikt fordelte tidsseriehendelser; for eksempel kan antall hendelser i et 3-timers vindu variere fra titalls til tusenvis. For å håndtere denne ubalansen brukte vi hendelsesfrekvenser i stedet for de rå sekvensdataene. En enkel tilnærming er å samle hendelsesfrekvensen for hele tilbakeblikkvinduet og mate den inn i modellen. Men når du bruker denne representasjonen, går tidsinformasjonen tapt, og rekkefølgen på hendelsene blir ikke bevart. Vi brukte i stedet temporal binning ved å dele tidsvinduet inn i N like undervinduer og beregne hendelsesfrekvensene i hvert. De siste funksjonene i et tidsvindu er sammenkoblingen av alle dets undervindusfunksjoner. Ved å øke antallet søppelkasser bevares mer tidsmessig informasjon. Følgende figur illustrerer temporal binning på et eksempelvindu.
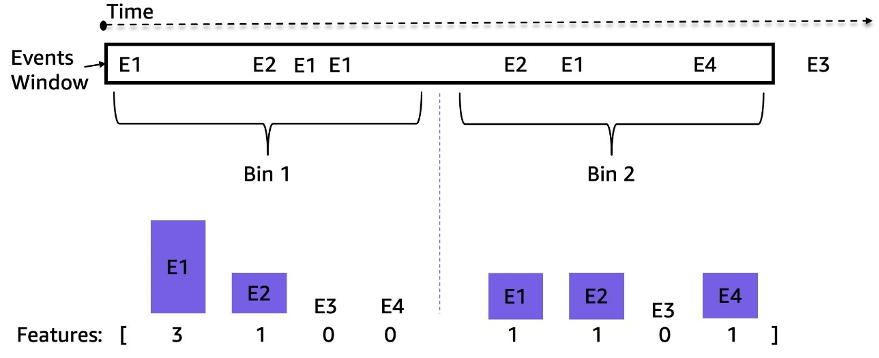
Først deles prøvetidsvinduet inn i to like undervinduer (binger); vi brukte bare to søppelkasser her for enkelhets skyld for illustrasjon. Deretter blir tellingene av hendelsene E1, E2, E3 og E4 beregnet i hver binge. Til slutt er de sammenkoblet og brukt som funksjoner.
Sammen med de hendelsesfrekvensbaserte funksjonene brukte vi maskinspesifikke funksjoner som programvareversjon, kabinetttype, spilltema og spillversjon. I tillegg la vi til funksjoner relatert til tidsstemplene for å fange sesongvariasjonene, for eksempel time på dagen og ukedag.
Dataforberedelse
For å trekke ut data effektivt for trening og testing, bruker vi Amazon Athena og AWS Glue Data Catalog. Hendelsesdataene lagres i Amazon S3 i Parkett-format og partisjoneres i henhold til dag/måned/time. Dette muliggjør effektiv utvinning av dataprøver innenfor et spesifisert tidsvindu. Vi bruker data fra alle maskiner den siste måneden til testing og resten av dataene til trening, noe som bidrar til å unngå potensiell datalekkasje.
ML metodikk og modelltrening
I denne delen diskuterer vi grunnmodellen vår med AutoGluon og hvordan vi bygde et tilpasset nevralt nettverk med SageMaker automatisk modellinnstilling.
Bygge en grunnlinjemodell med AutoGluon
Med alle ML-brukstilfeller er det viktig å etablere en grunnlinjemodell som skal brukes til sammenligning og iterasjon. Vi brukte AutoGluon å utforske flere klassiske ML-algoritmer. AutoGluon er et brukervennlig AutoML-verktøy som bruker automatisk databehandling, hyperparameterinnstilling og modellensemble. Den beste grunnlinjen ble oppnådd med et vektet ensemble av gradientforsterkede beslutningstremodeller. Brukervennligheten til AutoGluon hjalp oss i oppdagelsesstadiet med å navigere raskt og effektivt gjennom et bredt spekter av mulige data- og ML-modelleringsretninger.
Bygge og justere en tilpasset nevrale nettverksmodell med SageMaker automatisk modellinnstilling
Etter å ha eksperimentert med forskjellige nevrale nettverksarkitekturer, bygde vi en tilpasset dyplæringsmodell for prediktivt vedlikehold. Vår modell overgikk AutoGluon grunnlinjemodellen med 121 % i tilbakekalling med 80 % presisjon. Den endelige modellen tar inn historiske maskinhendelsessekvensdata, tidsfunksjoner som time på dagen og statiske maskinmetadata. vi utnytter SageMaker automatisk modellinnstilling jobber for å søke etter de beste hyperparametrene og modellarkitekturene.
Følgende figur viser modellarkitekturen. Vi normaliserer først de innlagte hendelsessekvensdataene etter gjennomsnittlige frekvenser for hver hendelse i treningssettet for å fjerne den overveldende effekten av høyfrekvente hendelser (start av spillet, slutt på spillet, og så videre). Innebyggingene for individuelle hendelser kan læres, mens de tidsmessige funksjonene (dag i uken, time på dagen) trekkes ut ved hjelp av pakken GluonTS. Deretter kobler vi hendelsessekvensdataene sammen med de tidsmessige funksjonene som input til modellen. Modellen består av følgende lag:
- Convolutional layers (CNN) – Hvert CNN-lag består av to 1-dimensjonale konvolusjonsoperasjoner med gjenværende forbindelser. Utgangen til hvert CNN-lag har samme sekvenslengde som inngangen for å tillate enkel stabling med andre moduler. Det totale antallet CNN-lag er en justerbar hyperparameter.
- Transformatorkoderlag (TRANS) – Utgangen fra CNN-lagene mates sammen med posisjonskodingen til en flerhodes selvoppmerksomhetsstruktur. Vi bruker TRANS for å direkte fange opp tidsmessige avhengigheter i stedet for å bruke tilbakevendende nevrale nettverk. Her hjelper binning av de rå sekvensdataene (reduserer lengden fra tusenvis til hundrevis) å lindre flaskehalsene i GPU-minnet, samtidig som den kronologiske informasjonen holdes i en justerbar grad (antall hyllene er en justerbar hyperparameter).
- Aggregasjonslag (AGG) – Det siste laget kombinerer metadatainformasjonen (spilltematype, kabinetttype, plasseringer) for å produsere sannsynlighetsprediksjonen på prioritert nivå. Den består av flere lag og fullt sammenkoblede lag for inkrementell dimensjonsreduksjon. Multi-hot-innbyggingen av metadata kan også læres, og går ikke gjennom CNN- og TRANS-lag fordi de ikke inneholder sekvensiell informasjon.
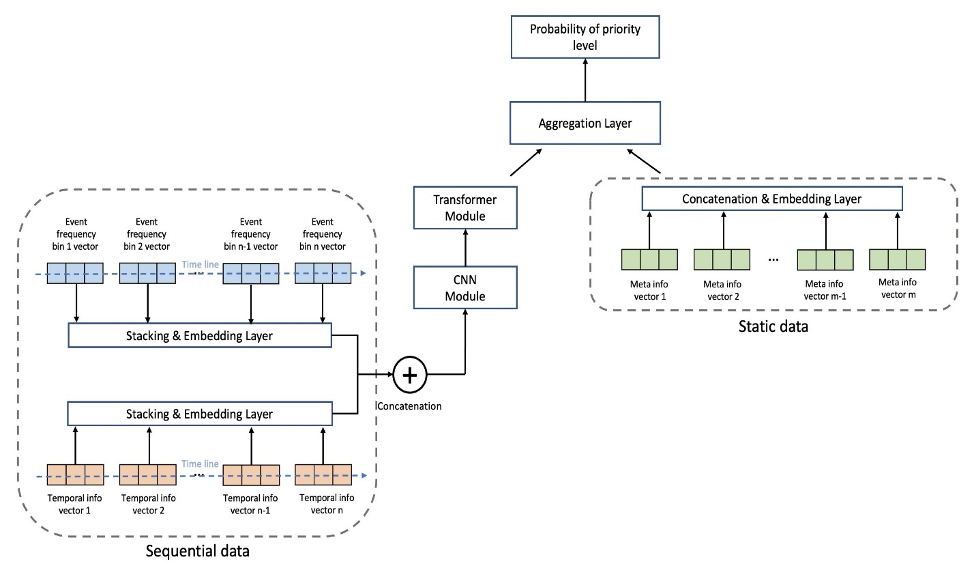
Vi bruker kryssentropi-tapet med klassevekter som justerbare hyperparametre for å justere for klasseubalanseproblemet. I tillegg er antallet CNN- og TRANS-lag avgjørende hyperparametre med mulige verdier på 0, noe som betyr at spesifikke lag kanskje ikke alltid eksisterer i modellarkitekturen. På denne måten har vi et enhetlig rammeverk der modellarkitekturene søkes sammen med andre vanlige hyperparametre.
Vi bruker SageMaker automatisk modellinnstilling, også kjent som hyperparameteroptimalisering (HPO), for å effektivt utforske modellvariasjoner og det store søkerommet til alle hyperparametre. Automatisk modellinnstilling mottar den tilpassede algoritmen, treningsdata og hyperparametersøkeplasskonfigurasjoner, og søker etter de beste hyperparametrene ved å bruke forskjellige strategier som Bayesian, Hyperband og mer med flere GPU-forekomster parallelt. Etter å ha evaluert på et hold-out-valideringssett, fikk vi den beste modellarkitekturen med to lag med CNN, ett lag med TRANS med fire hoder og et AGG-lag.
Vi brukte følgende hyperparameterområder for å søke etter den beste modellarkitekturen:
For ytterligere å forbedre modellnøyaktigheten og redusere modellvariansen, trente vi modellen med flere uavhengige tilfeldige vektinitialiseringer, og aggregerte resultatet med gjennomsnittsverdier som den endelige sannsynlighetsprediksjonen. Det er en avveining mellom flere dataressurser og bedre modellytelse, og vi observerte at 5–10 burde være et rimelig tall i den gjeldende brukssaken (resultater vist senere i dette innlegget).
Modellytelsesresultater
I denne delen presenterer vi modellens ytelsesevalueringsberegninger og resultater.
Evalueringsberegninger
Presisjon er svært viktig for denne prediktive vedlikeholdsbruken. Lav presisjon betyr rapportering av flere falske vedlikeholdsanrop, noe som øker kostnadene gjennom unødvendig vedlikehold. Fordi gjennomsnittlig presisjon (AP) ikke stemmer helt overens med høypresisjonsmålet, introduserte vi en ny beregning kalt gjennomsnittlig gjenkalling med høy presisjon (ARHP). ARHP er lik gjennomsnittet av tilbakekallinger ved 60 %, 70 % og 80 % presisjonspoeng. Vi brukte også presisjon på topp K% (K=1, 10), AUPR og AUROC som ekstra beregninger.
Resultater
Følgende tabell oppsummerer resultatene ved å bruke grunnlinjen og de tilpassede nevrale nettverksmodellene, med 7/1/2022 som tog-/testdelingspunkt. Eksperimenter viser at å øke vinduslengden og prøvedatastørrelsen både forbedrer modellytelsen, fordi de inneholder mer historisk informasjon for å hjelpe med prediksjonen. Uavhengig av datainnstillingene, overgår den nevrale nettverksmodellen AutoGluon i alle beregninger. For eksempel økes tilbakekallingen med den faste presisjonen på 80 % med 121 %, noe som gjør at du raskt kan identifisere flere feilfungerende maskiner hvis du bruker den nevrale nettverksmodellen.
| Modell | Vinduslengde/Datastørrelse | AUROC | AUPR | ARHP | Recall@Prec0.6 | Recall@Prec0.7 | Recall@Prec0.8 | Prec@top1% | Prec@top10% |
|---|---|---|---|---|---|---|---|---|---|
| AutoGluon grunnlinje | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| Nevrale nettverket | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| AutoGluon grunnlinje | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| Nevrale nettverket | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
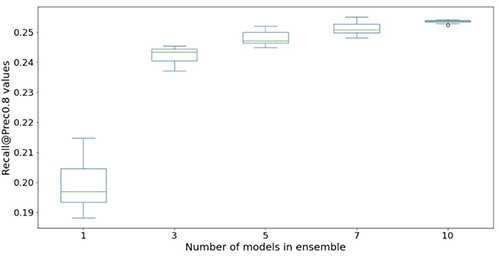
De følgende figurene illustrerer effekten av å bruke ensembler for å øke ytelsen til nevrale nettverksmodeller. Alle evalueringsverdiene vist på x-aksen er forbedret, med høyere gjennomsnitt (mer nøyaktig) og lavere varians (mer stabil). Hvert boksplott er fra 12 gjentatte eksperimenter, fra ingen ensembler til 10 modeller i ensembler (x-aksen). Lignende trender vedvarer i alle beregninger bortsett fra Prec@top1% og Recall@Prec80% vist.
Etter å ha tatt med beregningskostnadene, observerer vi at bruk av 5–10 modeller i ensembler er egnet for Light & Wonder-datasett.

konklusjonen
Samarbeidet vårt har resultert i etableringen av en banebrytende løsning for prediktivt vedlikehold for spillindustrien, samt et gjenbrukbart rammeverk som kan brukes i en rekke prediktivt vedlikeholdsscenarier. Bruken av AWS-teknologier som SageMaker automatisk modellinnstilling gjør det lettere for Light & Wonder å navigere i nye muligheter ved å bruke datastrømmer i nær sanntid. Light & Wonder starter distribusjonen på AWS.
Hvis du vil ha hjelp til å fremskynde bruken av ML i produktene og tjenestene dine, vennligst kontakt Amazon ML Solutions Lab program.
Om forfatterne
 Aruna Abeyakoon er Senior Director for Data Science & Analytics ved Light & Wonder Land-based Gaming Division. Aruna leder bransjens første Light & Wonder Connect-initiativ og støtter både kasinopartnere og interne interessenter med forbrukeratferd og produktinnsikt for å lage bedre spill, optimalisere produkttilbud, administrere eiendeler og helseovervåking og prediktivt vedlikehold.
Aruna Abeyakoon er Senior Director for Data Science & Analytics ved Light & Wonder Land-based Gaming Division. Aruna leder bransjens første Light & Wonder Connect-initiativ og støtter både kasinopartnere og interne interessenter med forbrukeratferd og produktinnsikt for å lage bedre spill, optimalisere produkttilbud, administrere eiendeler og helseovervåking og prediktivt vedlikehold.
 Denisse Colin er Senior Data Science Manager hos Light & Wonder, et ledende globalt spillselskap på tvers av plattformer. Hun er medlem av Gaming Data & Analytics-teamet som hjelper til med å utvikle innovative løsninger for å forbedre produktytelsen og kundenes opplevelser gjennom Light & Wonder Connect.
Denisse Colin er Senior Data Science Manager hos Light & Wonder, et ledende globalt spillselskap på tvers av plattformer. Hun er medlem av Gaming Data & Analytics-teamet som hjelper til med å utvikle innovative løsninger for å forbedre produktytelsen og kundenes opplevelser gjennom Light & Wonder Connect.
 Tesfagabir Meharizghi er en dataforsker ved Amazon ML Solutions Lab hvor han hjelper AWS-kunder på tvers av ulike bransjer som spill, helsevesen og biovitenskap, produksjon, bilindustri og sport og media, akselerere bruken av maskinlæring og AWS skytjenester for å løse virksomheten deres utfordringer.
Tesfagabir Meharizghi er en dataforsker ved Amazon ML Solutions Lab hvor han hjelper AWS-kunder på tvers av ulike bransjer som spill, helsevesen og biovitenskap, produksjon, bilindustri og sport og media, akselerere bruken av maskinlæring og AWS skytjenester for å løse virksomheten deres utfordringer.
 Mohamad Aljazaery er en anvendt vitenskapsmann ved Amazon ML Solutions Lab. Han hjelper AWS-kunder med å identifisere og bygge ML-løsninger for å møte deres forretningsutfordringer innen områder som logistikk, personalisering og anbefalinger, datasyn, svindelforebygging, prognoser og forsyningskjedeoptimalisering.
Mohamad Aljazaery er en anvendt vitenskapsmann ved Amazon ML Solutions Lab. Han hjelper AWS-kunder med å identifisere og bygge ML-løsninger for å møte deres forretningsutfordringer innen områder som logistikk, personalisering og anbefalinger, datasyn, svindelforebygging, prognoser og forsyningskjedeoptimalisering.
 Yawei Wang er en Applied Scientist ved Amazon ML Solution Lab. Han hjelper AWS forretningspartnere med å identifisere og bygge ML-løsninger for å møte organisasjonens forretningsutfordringer i et virkelighetsscenario.
Yawei Wang er en Applied Scientist ved Amazon ML Solution Lab. Han hjelper AWS forretningspartnere med å identifisere og bygge ML-løsninger for å møte organisasjonens forretningsutfordringer i et virkelighetsscenario.
 Yun Zhou er en Applied Scientist ved Amazon ML Solutions Lab, hvor han hjelper til med forskning og utvikling for å sikre suksess for AWS-kunder. Han jobber med banebrytende løsninger for ulike bransjer ved hjelp av statistisk modellering og maskinlæringsteknikker. Hans interesse inkluderer generative modeller og sekvensiell datamodellering.
Yun Zhou er en Applied Scientist ved Amazon ML Solutions Lab, hvor han hjelper til med forskning og utvikling for å sikre suksess for AWS-kunder. Han jobber med banebrytende løsninger for ulike bransjer ved hjelp av statistisk modellering og maskinlæringsteknikker. Hans interesse inkluderer generative modeller og sekvensiell datamodellering.
 Panpan Xu er en Applied Science Manager med Amazon ML Solutions Lab ved AWS. Hun jobber med forskning og utvikling av Machine Learning-algoritmer for effektfulle kundeapplikasjoner i en rekke industrielle vertikaler for å akselerere deres AI og skyadopsjon. Hennes forskningsinteresse inkluderer modelltolkbarhet, årsaksanalyse, human-in-the-loop AI og interaktiv datavisualisering.
Panpan Xu er en Applied Science Manager med Amazon ML Solutions Lab ved AWS. Hun jobber med forskning og utvikling av Machine Learning-algoritmer for effektfulle kundeapplikasjoner i en rekke industrielle vertikaler for å akselerere deres AI og skyadopsjon. Hennes forskningsinteresse inkluderer modelltolkbarhet, årsaksanalyse, human-in-the-loop AI og interaktiv datavisualisering.
 Raj Salvaji leder Solutions Architecture i Hospitality-segmentet hos AWS. Han jobber med gjestfrihetskunder ved å gi strategisk veiledning, teknisk ekspertise for å skape løsninger på komplekse forretningsutfordringer. Han trekker på 25 års erfaring i flere ingeniørroller på tvers av gjestfrihet, finans og bilindustri.
Raj Salvaji leder Solutions Architecture i Hospitality-segmentet hos AWS. Han jobber med gjestfrihetskunder ved å gi strategisk veiledning, teknisk ekspertise for å skape løsninger på komplekse forretningsutfordringer. Han trekker på 25 års erfaring i flere ingeniørroller på tvers av gjestfrihet, finans og bilindustri.
 Shane Rai er en rektor ML-strateg ved Amazon ML Solutions Lab ved AWS. Han jobber med kunder på tvers av et mangfold av bransjer for å løse deres mest presserende og innovative forretningsbehov ved å bruke AWSs bredde av skybaserte AI/ML-tjenester.
Shane Rai er en rektor ML-strateg ved Amazon ML Solutions Lab ved AWS. Han jobber med kunder på tvers av et mangfold av bransjer for å løse deres mest presserende og innovative forretningsbehov ved å bruke AWSs bredde av skybaserte AI/ML-tjenester.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- EVM Finans. Unified Interface for desentralisert økonomi. Tilgang her.
- Quantum Media Group. IR/PR forsterket. Tilgang her.
- PlatoAiStream. Web3 Data Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/how-light-wonder-built-a-predictive-maintenance-solution-for-gaming-machines-on-aws/

