
“Een greintje preventie is een pond genezing waard”, luidt het oude gezegde, dat ons eraan herinnert dat het gemakkelijker is om iets te voorkomen dan om de schade te herstellen nadat het is gebeurd.
In het tijdperk van kunstmatige intelligentie (AI) onderstreept dit spreekwoord het belang van het vermijden van potentiële valkuilen, zoals overfitting, door middel van technieken als regularisatie.
In dit artikel zullen we regularisatie ontdekken door te beginnen met de fundamentele principes van de toepassing ervan met behulp van Sci-kit Learn (Machine Learning) en Tensorflow (Deep Learning) en getuige zijn van de transformerende kracht ervan met datasets uit de echte wereld door deze resultaten te vergelijken. Laten we beginnen!
Regularisatie is een cruciaal concept in machine learning en deep learning dat tot doel heeft te voorkomen dat modellen overfitting krijgen.
Overfitting vindt plaats wanneer een model de trainingsgegevens te goed leert. De situatie laat zien dat uw model te mooi is om waar te zijn.
Laten we eens kijken hoe overfitting eruit ziet.
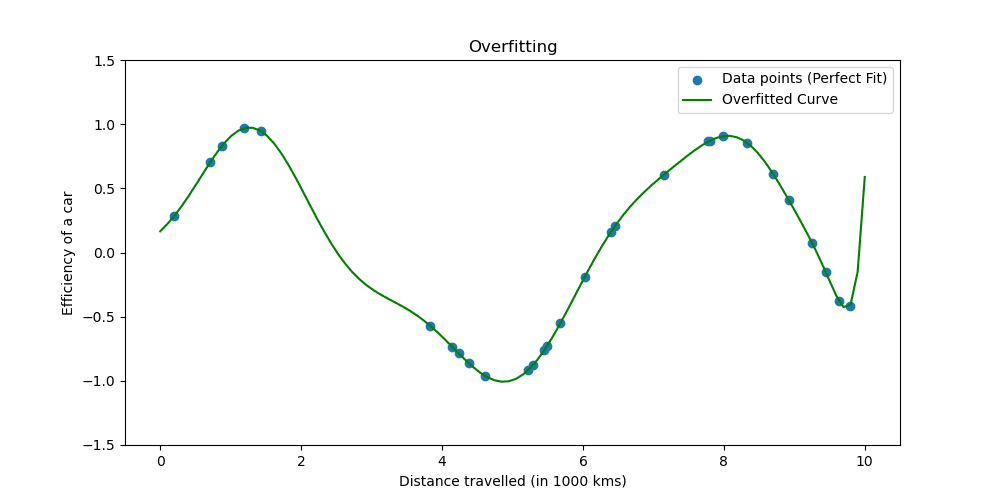
Regularisatietechnieken passen het leerproces aan om het model te vereenvoudigen, waardoor het goed presteert op trainingsgegevens en goed generaliseert naar nieuwe gegevens. We zullen twee bekende manieren verkennen om dit te doen.
Bij machinaal leren wordt regularisatie vaak toegepast op lineaire modellen, zoals lineaire en logistische regressie. In deze context zijn de meest voorkomende vormen van regularisatie:
- L1-regularisatie (Lasso-regressie)
- L2-regularisatie (Ridge-regressie)
Lasso-regularisatie moedigt het model aan om alleen de meest essentiële kenmerken te gebruiken door toe te staan dat sommige coëfficiëntwaarden exact nul zijn, wat bijzonder nuttig kan zijn bij de selectie van kenmerken.


Daarnaast is Ridge-regularisatie ontmoedigt significante coëfficiënten door het kwadraat van hun waarden te bestraffen.

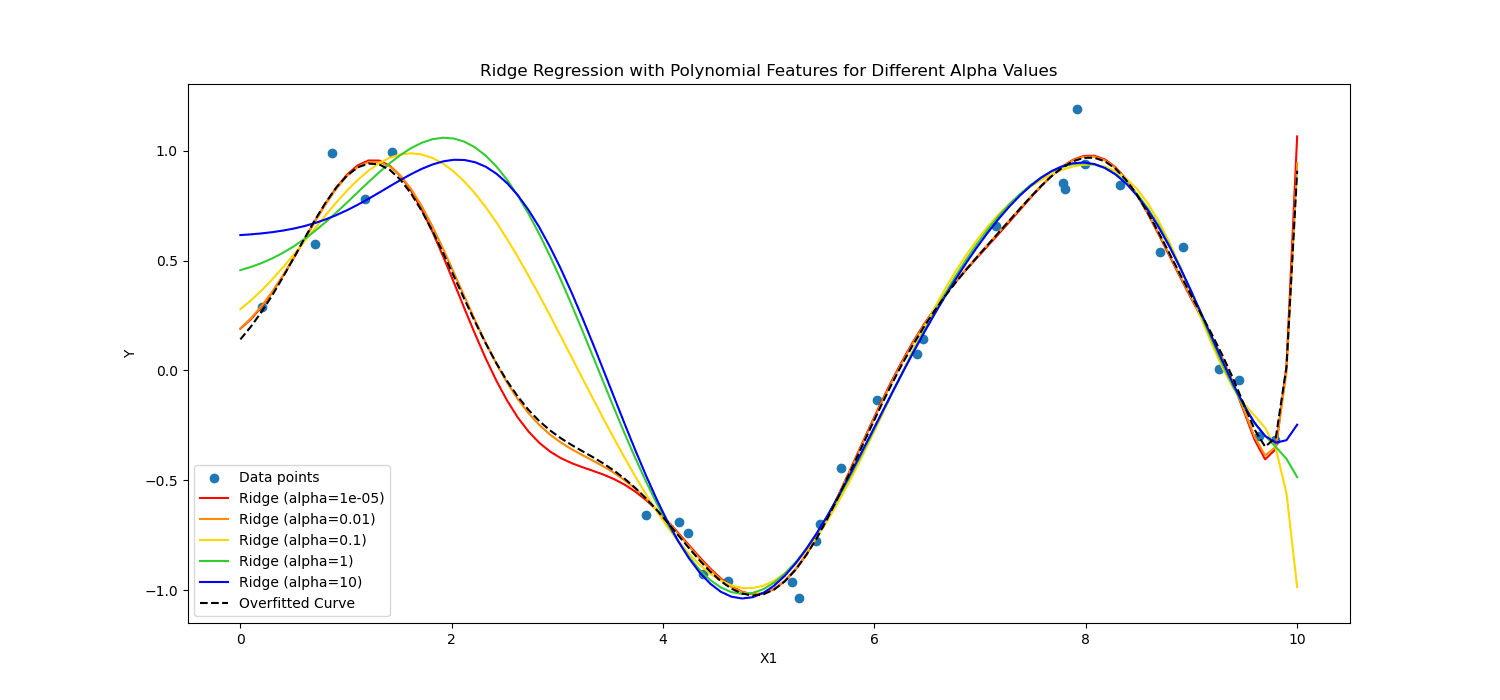
Kortom, ze rekenden anders.
Laten we deze toepassen op de gegevens van hartpatiënten om de kracht ervan in deep learning en machinaal leren te zien.
Nu zullen we regularisatie toepassen om gegevens van hartpatiënten te analyseren om de kracht van regularisatie te zien. U kunt de gegevensset bereiken vanaf hier.
Om machine learning toe te passen, zullen we Scikit-learn gebruiken; om deep learning toe te passen, zullen we TensorFlow gebruiken. Laten we beginnen!
Regularisatie in Machine Learning
Scikit-learn is een van de meest populaire Python-bibliotheken voor machinaal leren dat eenvoudige en efficiënte tools voor gegevensanalyse en modellering biedt.
Het omvat implementaties van verschillende regularisatietechnieken, vooral voor lineaire modellen.
Hier zullen we onderzoeken hoe u L1 (Lasso) en L2 (Ridge) regularisatie kunt toepassen.
In de volgende code zullen we logistieke regressie trainen met behulp van Ridge(L2) en Lasso-regularisatietechnieken (L1). Aan het einde zullen we het gedetailleerde rapport zien. Laten we de code eens bekijken.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
Hier is de uitvoer.
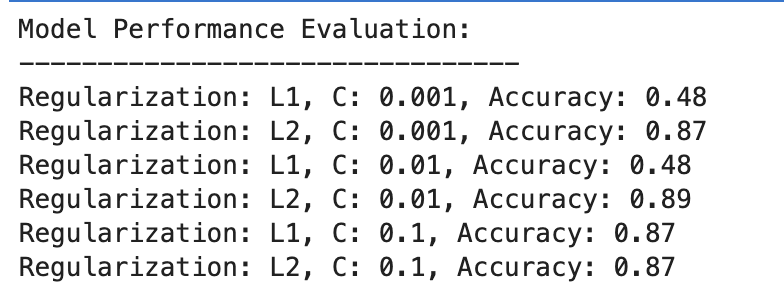
Laten we het resultaat evalueren.
L1 Regularisatie
- Bij C=0.001 is de nauwkeurigheid opmerkelijk laag (48%). Hieruit blijkt dat het model ondermaats is. Het getuigt van te veel regularisatie.
- Naarmate C toeneemt tot 0.01, blijft de nauwkeurigheid voor L1 ongewijzigd, wat erop wijst dat het model nog steeds last heeft van onderaanpassing of dat de regularisatie te sterk is.
- Bij C=0.1 verbetert de nauwkeurigheid aanzienlijk tot 87%, wat aantoont dat het verminderen van de regularisatiekracht het model in staat stelt beter van de gegevens te leren.
L2 Regularisatie
Over de hele linie presteert de L2-regularisatie consistent goed, met een nauwkeurigheid van 87% voor C=0.001 en iets hoger, namelijk 89% voor C=0.01, en stabiliseert zich vervolgens op 87% voor C=0.1.
Dit suggereert dat T2-regularisatie over het algemeen vergevingsgezinder en effectiever is voor deze dataset in logistische regressiemodellen, mogelijk vanwege de aard ervan.
Regularisatie in diep leren
Bij deep learning worden verschillende regularisatietechnieken gebruikt, waaronder L1 (Lasso) en L2 (Ridge) regularisatie, uitval en vroegtijdig stoppen.
In deze zullen we, om te herhalen wat we eerder in het machine learning-voorbeeld hebben gedaan, L1- en L2-regularisatie toepassen. Laten we deze keer een lijst met L1- en L2-regularisatiewaarden definiëren.
Vervolgens zullen we voor al deze waarden ons deep learning-model trainen en evalueren, en aan het einde zullen we de resultaten beoordelen.
Laten we de code bekijken.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
Hier is de uitvoer.
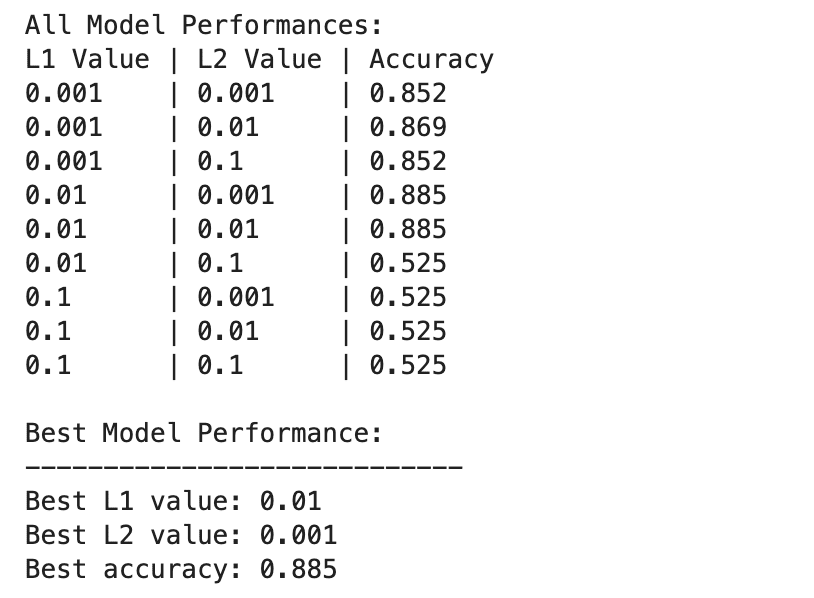
De prestaties van het deep learning-model variëren sterker tussen verschillende combinaties van L1- en L2-regularisatiewaarden.
De beste prestaties worden waargenomen bij L1=0.01 en L2=0.001, met een nauwkeurigheid van 88.5%, wat duidt op een evenwichtige regularisatie die overfitting voorkomt, terwijl het model de onderliggende patronen in de gegevens kan vastleggen.
Hogere regularisatiewaarden, vooral bij L1=0.1 of L2=0.1, verminderen de nauwkeurigheid van het model drastisch tot 52.5%, wat erop wijst dat te veel regularisatie het leervermogen van het model ernstig beperkt.
Machine learning en deep learning bij regularisatie
Laten we de resultaten tussen Machine Learning en Deep Learning vergelijken.
Effectiviteit van regularisatie: Zowel in machine learning als in deep learning-contexten helpt passende regularisatie overfitting te verminderen, maar overmatige regularisatie leidt tot onderfitting. De optimale regularisatiesterkte varieert, waarbij deep learning-modellen mogelijk een genuanceerder evenwicht vereisen vanwege hun hogere complexiteit.
prestaties: Het best presterende machine learning-model (L2 met C=0.01, 89% nauwkeurigheid) en het best presterende deep learning-model (L1=0.01, L2=0.001, 88.5% nauwkeurigheid) bereiken vergelijkbare nauwkeurigheid, wat aantoont dat beide benaderingen effectief kunnen zijn geregulariseerd om hoge prestaties op deze dataset te bereiken.
Regularisatiestrategie: T2-regularisatie lijkt effectiever en minder gevoelig voor de keuze van C in logistische regressiemodellen, terwijl een combinatie van L1- en L2-regularisatie het beste resultaat oplevert bij diepgaand leren, waarbij een evenwicht wordt geboden tussen kenmerkselectie en gewichtsstrafbaarheid.
De keuze en kracht van regularisatie moeten zorgvuldig worden afgestemd om de complexiteit van het leren in evenwicht te brengen met het risico van over- of onderaanpassing.
Tijdens dit onderzoek hebben we regularisatie gedemystificeerd, waarbij we de rol ervan hebben aangetoond bij het voorkomen van overfitting en ervoor hebben gezorgd dat onze modellen goed generaliseren naar onzichtbare gegevens.
Door regularisatietechnieken toe te passen, komt u dichter bij uw vaardigheid in machine learning en deep learning, waardoor uw toolset voor datawetenschappers wordt versterkt.
Ga naar de dataprojecten en probeer uw gegevens te regulariseren in verschillende scenario's, zoals Voorspelling van de bezorgduur. In dit dataproject hebben we zowel Machine Learning- als Deep Learning-modellen gebruikt. Uiteindelijk hebben we echter ook aangegeven dat er wellicht ruimte voor verbetering is. Waarom probeer je daar geen regularisatie en kijk of het helpt?
Nate Rosidi is een datawetenschapper en in productstrategie. Hij is ook een adjunct-professor onderwijsanalyse en is de oprichter van StrataScratch, een platform dat datawetenschappers helpt bij het voorbereiden van hun interviews met echte interviewvragen van topbedrijven. Maak contact met hem op Twitter: StrataScratch or LinkedIn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

