Wist je dat hoewel de Ahrefs Blog wordt aangedreven door WordPress, een groot deel van de rest van de site wordt aangedreven door JavaScript, zoals React?
De realiteit van het huidige internet is dat JavaScript overal is. De meeste websites gebruiken een soort JavaScript om interactiviteit toe te voegen en de gebruikerservaring te verbeteren.
Toch heeft het meeste JavaScript dat op zoveel websites wordt gebruikt helemaal geen invloed op SEO. Als je een normale WordPress-installatie hebt zonder veel aanpassingen, dan zal waarschijnlijk geen van de problemen op jou van toepassing zijn.
Waar u problemen zult tegenkomen, is wanneer JavaScript wordt gebruikt om een hele pagina op te bouwen, elementen toe te voegen of weg te halen, of te wijzigen wat al op de pagina stond. Sommige sites gebruiken het voor menu's, het binnenhalen van producten of prijzen, het ophalen van inhoud uit meerdere bronnen of, in sommige gevallen, voor alles op de site. Als dit klinkt als uw site, lees dan verder.
We zien hele systemen en apps gebouwd met JavaScript-frameworks en zelfs enkele traditionele CMS'en met een JavaScript-flair waarbij ze headless of ontkoppeld zijn. Het CMS wordt gebruikt als de backend-gegevensbron, maar de frontend-presentatie wordt afgehandeld door JavaScript.
Ik zeg niet dat SEO's eropuit moeten gaan om JavaScript te leren programmeren. Ik raad het eigenlijk niet aan, omdat het niet waarschijnlijk is dat je ooit de code zult aanraken. Wat SEO's moeten weten, is hoe Google omgaat met JavaScript en hoe ze problemen kunnen oplossen.
JavaScript SEO is een onderdeel van technische SEO (zoekmachineoptimalisatie) waardoor websites die veel JavaScript gebruiken, gemakkelijk kunnen worden gecrawld en geïndexeerd, en ook zoekvriendelijk zijn. Het doel is dat deze websites gevonden worden en hoger scoren in zoekmachines.
JavaScript is niet slecht voor SEO, en het is niet slecht. Het is gewoon anders dan veel SEO's gewend zijn, en er is een beetje een leercurve.
Veel van de processen lijken op de dingen die SEO's al gewend zijn, maar er kunnen kleine verschillen zijn. Je kijkt nog steeds voornamelijk naar HTML-code, en niet echt naar JavaScript.
Alle normale best practices voor SEO op de pagina zijn nog steeds van toepassing. Zien onze gids over on-page SEO.
Je zult zelfs bekende opties van het plug-intype vinden om veel van de basis-SEO-elementen te verwerken, als dit nog niet is ingebouwd in het raamwerk dat je gebruikt. Voor JavaScript-frameworks worden dit modules genoemd, en u zult veel pakketopties vinden om ze te installeren.
Er zijn versies voor veel van de populaire frameworks, zoals Reageren, Vue, Angular en Svelte die u kunt vinden door te zoeken naar de naam van het framework + de module, zoals 'React Helmet'. Metatags, Helmet en Head zijn allemaal populaire modules met vergelijkbare functionaliteit en zorgen ervoor dat veel van de populaire tags die nodig zijn voor SEO kunnen worden ingesteld.
In sommige opzichten is JavaScript beter dan traditionele HTML, wat betreft het bouwgemak en de prestaties. In sommige opzichten is JavaScript slechter, omdat het bijvoorbeeld niet progressief kan worden geparseerd (zoals HTML en CSS wel kunnen), en het de paginabelasting en prestaties zwaar kan beïnvloeden. Vaak ruilt u prestaties in voor functionaliteit.
JavaScript is niet perfect, en het is niet altijd de juiste tool voor de klus. Ontwikkelaars maken er te veel gebruik van voor dingen waarvoor waarschijnlijk een betere oplossing bestaat. Maar soms moet je werken met wat je krijgt.
Dit zijn veel van de veelvoorkomende SEO-problemen die u kunt tegenkomen bij het werken met JavaScript-sites.
Zorg voor unieke title-tags en metabeschrijvingen
Je wilt nog steeds uniek zijn title-tags en metabeschrijvingen op al uw pagina's. Omdat veel JavaScript-frameworks in sjablonen zijn gemaakt, kun je gemakkelijk in een situatie terechtkomen waarin dezelfde titel of metabeschrijving wordt gebruikt voor alle pagina's of een groep pagina's.
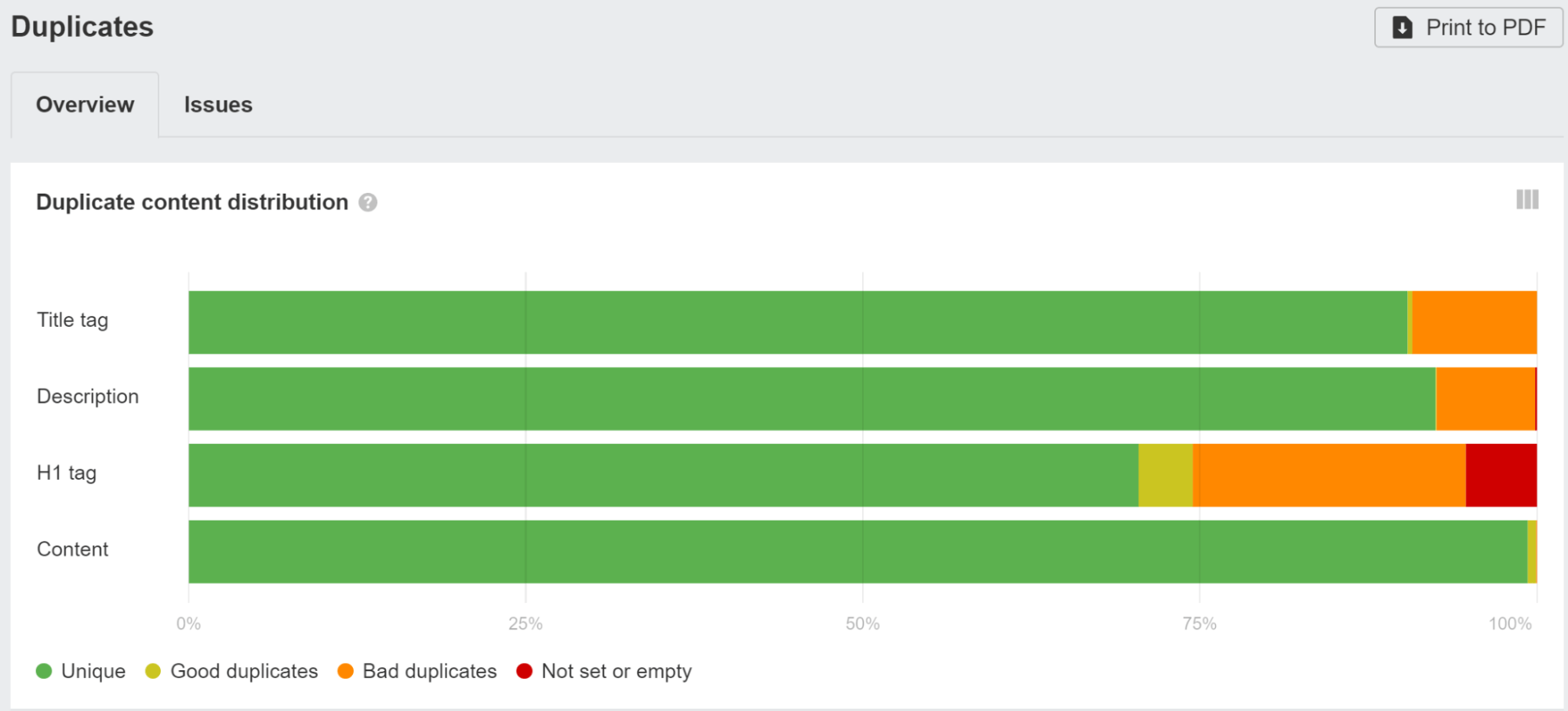
Controleer de duplicaten verslag in Ahrefs' Site Audit en klik op een van de groeperingen om meer gegevens te bekijken over de problemen die we hebben gevonden.
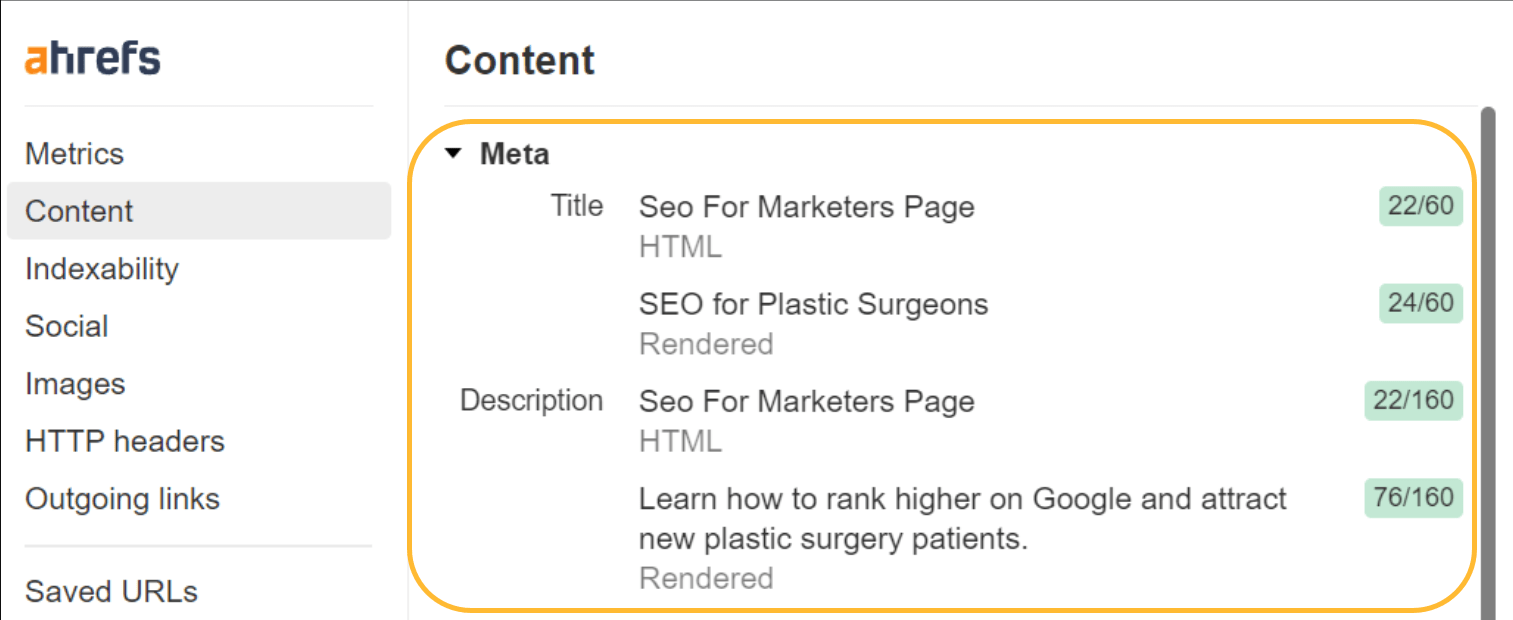
U kunt een van de SEO-modules zoals Helmet gebruiken om aangepaste tags voor elke pagina in te stellen.
JavaScript kan ook worden gebruikt om standaardwaarden die u mogelijk heeft ingesteld, te overschrijven. Google zal dit verwerken en de overschreven titel of beschrijving gebruiken. Voor gebruikers kunnen titels echter problematisch zijn, omdat een titel in de browser kan verschijnen en ze een flits zullen opmerken wanneer deze wordt overschreven.
Als je de titel ziet knipperen, kun je Ahrefs' SEO-werkbalk om zowel de onbewerkte HTML- als de gerenderde versies te zien.
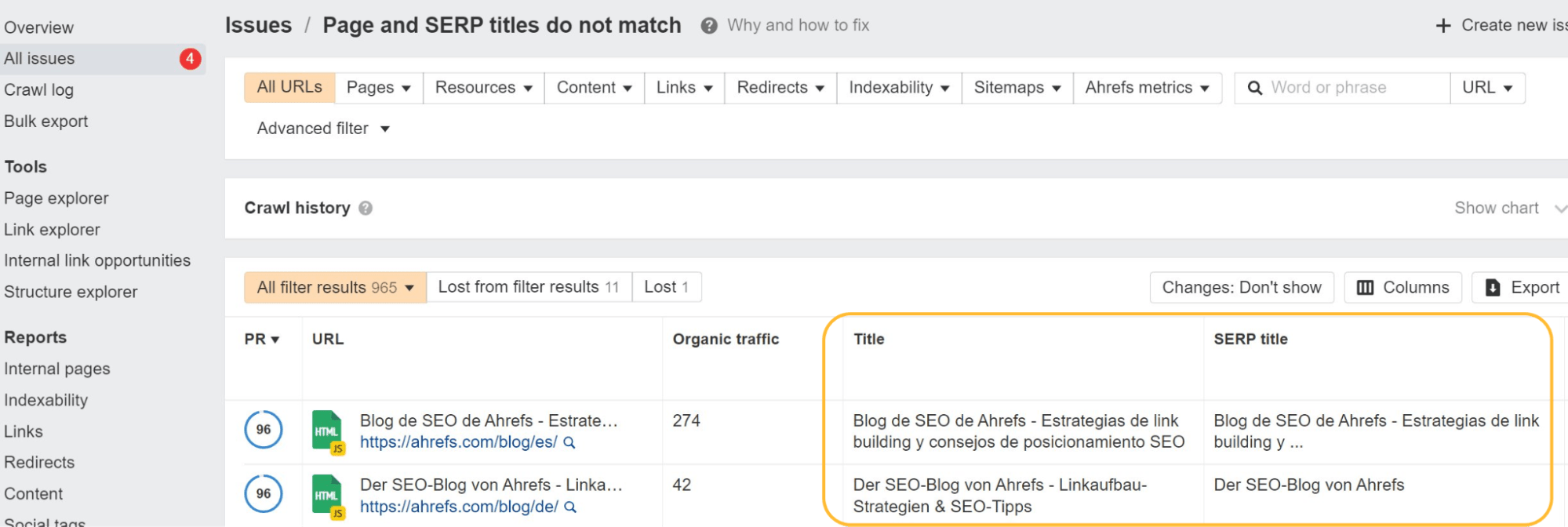
Google mag uw titels of metabeschrijvingen sowieso niet gebruiken. Zoals ik al zei, zijn de titels de moeite waard om op te ruimen voor gebruikers. Het oplossen hiervan voor metabeschrijvingen zal echter niet echt een verschil maken.
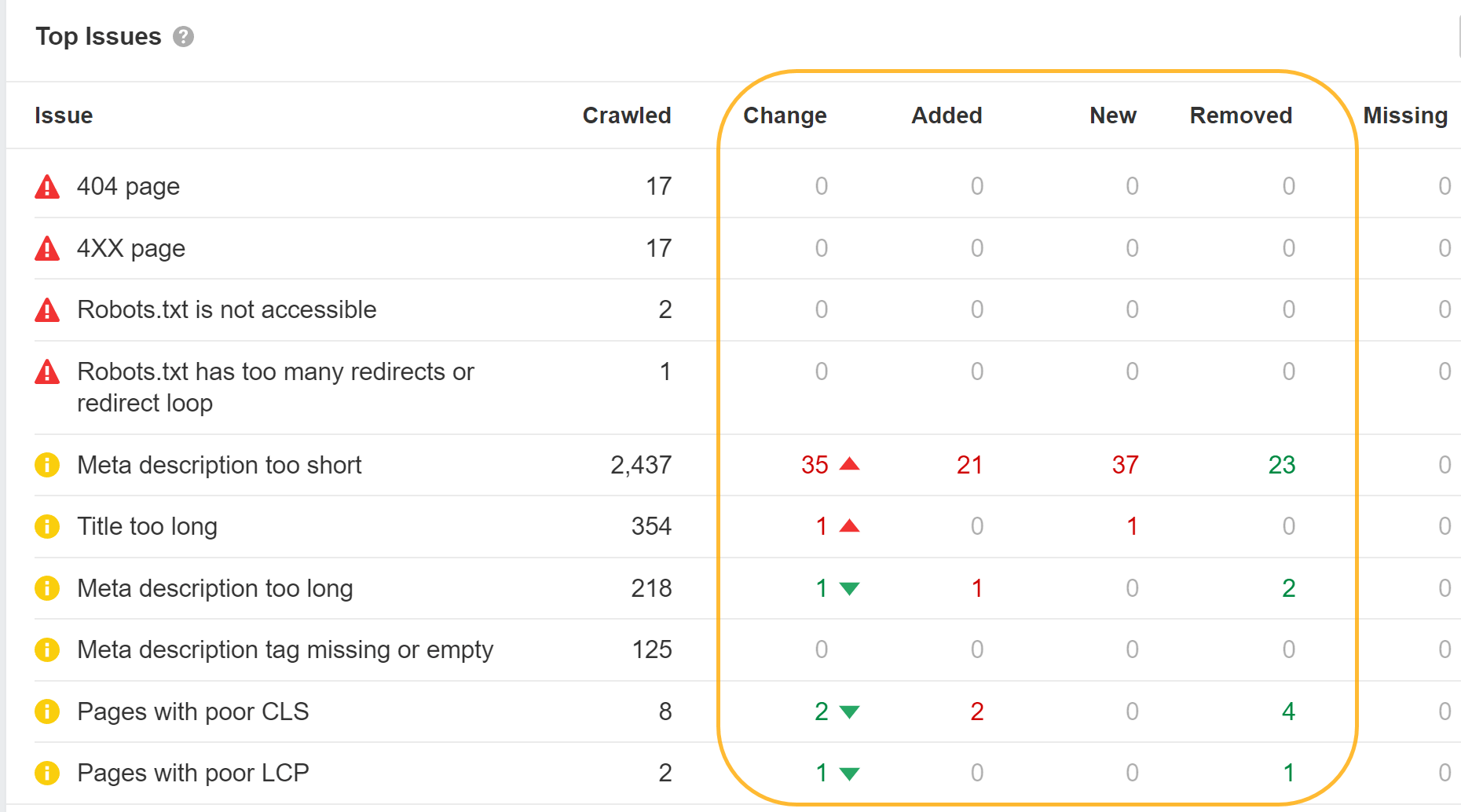
Toen we de herschrijving van Google bestudeerden, ontdekten we dat Google overschrijft titels 33.4% van de tijd en metabeschrijvingen 62.78% van de tijd. In Site Audit laten we u zelfs zien welke van uw title-tags Google heeft gewijzigd.
Canonieke tagproblemen
Jarenlang zei Google dat het geen respect had canonieke tags ingevoegd met JavaScript. Eindelijk werd er een uitzondering toegevoegd aan de documentatie voor gevallen waarin er nog geen tag was. Ik heb die verandering veroorzaakt. Ik heb tests uitgevoerd om aan te tonen dat dit werkte, terwijl Google iedereen vertelde dat dit niet het geval was.
Als er al een canonieke tag aanwezig was en je voegt er nog een toe of overschrijft de bestaande met JavaScript, dan geef je ze twee canonieke tags. In dit geval moet Google uitzoeken welke de canonieke tags moet gebruiken of negeren ten gunste van andere canonicaliseringssignalen.
Het standaard SEO-advies ‘elke pagina moet een naar zichzelf verwijzende canonieke tag hebben’ brengt veel SEO’s in de problemen. Een ontwikkelaar neemt die vereiste over en maakt pagina's met en zonder een afsluitende schuine streep zelf-canoniek.
example.com/page met een canoniek van example.com/page en example.com/page/ met een canoniek van example.com/page/. Oeps, dat is verkeerd! Waarschijnlijk wilt u een van deze versies omleiden naar de andere.
Hetzelfde kan gebeuren met geparametriseerde versies die u misschien wilt combineren, maar elk verwijst naar zichzelf.
Google gebruikt de meest restrictieve meta-robottag
met meta-robots-tags, zal Google altijd de meest beperkende optie kiezen die het ziet, ongeacht de locatie.
Als u een indextag in de onbewerkte HTML en een noindex-tag in de weergegeven HTML heeft, behandelt Google deze als noindex. Als je een noindex-tag in de onbewerkte HTML hebt, maar deze overschrijft met een index-tag met JavaScript, wordt die pagina nog steeds als noindex behandeld.
Het werkt hetzelfde voor nofollow-tags. Google gaat de meest restrictieve optie kiezen.
Stel alt-attributen in voor afbeeldingen
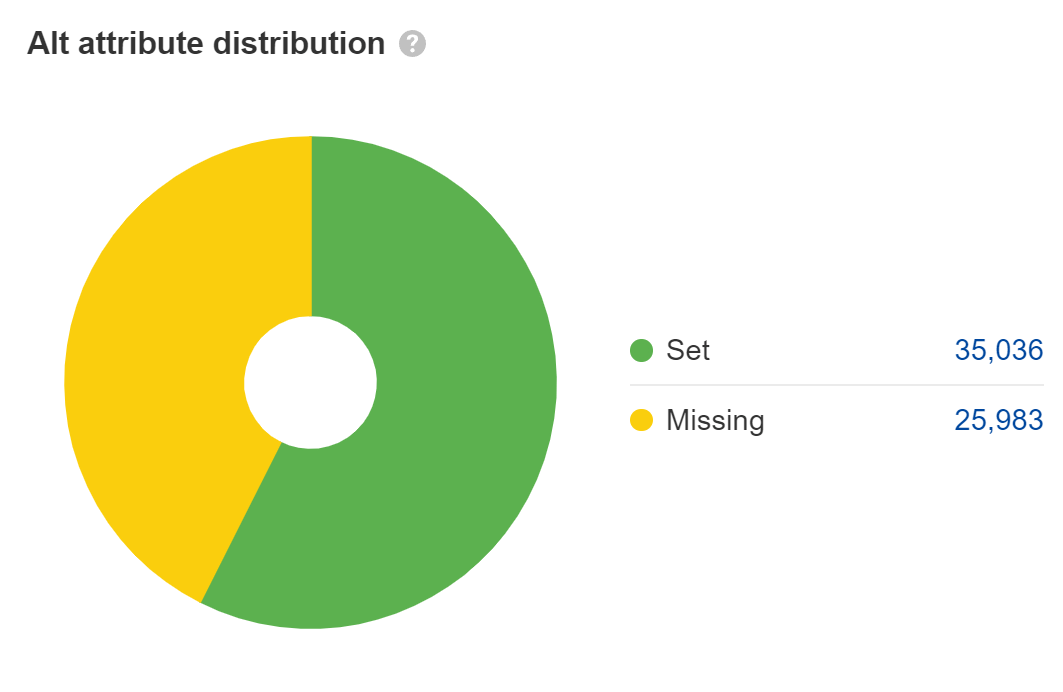
Vermist alt-attributen zijn een toegankelijkheidsprobleem, dat kan uitmonden in een juridisch probleem. De meeste grote bedrijven zijn aangeklaagd wegens ADA-complianceproblemen op hun websites, en sommige worden meerdere keren per jaar aangeklaagd. Ik zou dit oplossen voor de afbeeldingen met de hoofdinhoud, maar niet voor zaken als tijdelijke aanduidingen of decoratieve afbeeldingen waarbij je de alt-attributen leeg kunt laten.
Bij zoeken op internet telt de tekst in alt-attributen als tekst op de pagina, maar dat is eigenlijk de enige rol die deze speelt. Het belang ervan wordt naar mijn mening vaak overschat voor SEO. Het helpt echter wel bij het zoeken naar afbeeldingen en het rangschikken van afbeeldingen.
Veel JavaScript-ontwikkelaars laten alt-attributen leeg, dus controleer nogmaals of de jouwe aanwezig zijn. Kijk naar de Afbeeldingen rapport in Site Audit om deze te vinden.
Sta het crawlen van JavaScript-bestanden toe
Blokkeer de toegang tot bronnen niet als deze nodig zijn om een deel van de pagina op te bouwen of iets aan de inhoud toe te voegen. Google heeft toegang tot bronnen nodig en moet deze downloaden, zodat de pagina's correct kunnen worden weergegeven. In uw robots.txt, de eenvoudigste manier om de benodigde bronnen te laten crawlen, is door het volgende toe te voegen:
User-Agent: GooglebotAllow: .jsAllow: .css
Controleer ook de robots.txt-bestanden op eventuele subdomeinen of aanvullende domeinen waarvan u mogelijk verzoeken indient, zoals die voor uw API-aanroepen.
Als u bronnen heeft geblokkeerd met robots.txt, kunt u controleren of dit invloed heeft op de pagina-inhoud met behulp van de blokkeeropties op het tabblad 'Netwerk' in Chrome Dev Tools. Selecteer het bestand en blokkeer het. Laad de pagina vervolgens opnieuw om te zien of er wijzigingen zijn aangebracht.
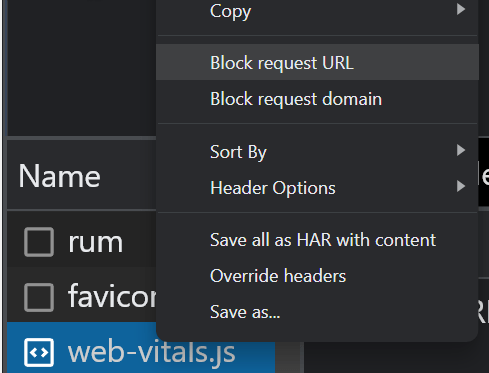
Controleer of Google uw inhoud ziet
Veel pagina's met JavaScript-functionaliteit tonen mogelijk niet standaard alle inhoud aan Google. Als u met uw ontwikkelaars praat, kunnen zij zeggen dat dit niet het Document Object Model (DOM) is geladen. Dit betekent dat de inhoud niet standaard is geladen en later mogelijk wordt geladen met een actie zoals een klik.
Een snelle controle die u kunt doen, is door eenvoudigweg tussen aanhalingstekens naar een fragment van uw inhoud in Google te zoeken. Zoek naar 'een zin uit uw inhoud' en kijk of de pagina wordt weergegeven in de zoekresultaten. Als dat zo is, is uw inhoud waarschijnlijk gezien.
Kanttekening.
Inhoud die standaard verborgen is, wordt mogelijk niet weergegeven in uw fragment op de SERPs. Het is vooral belangrijk om uw mobiele versie te controleren, omdat deze vaak wordt uitgekleed vanwege de gebruikerservaring.
U kunt ook met de rechtermuisknop klikken en de optie "Inspecteren" gebruiken. Zoek naar de tekst op het tabblad "Elementen".
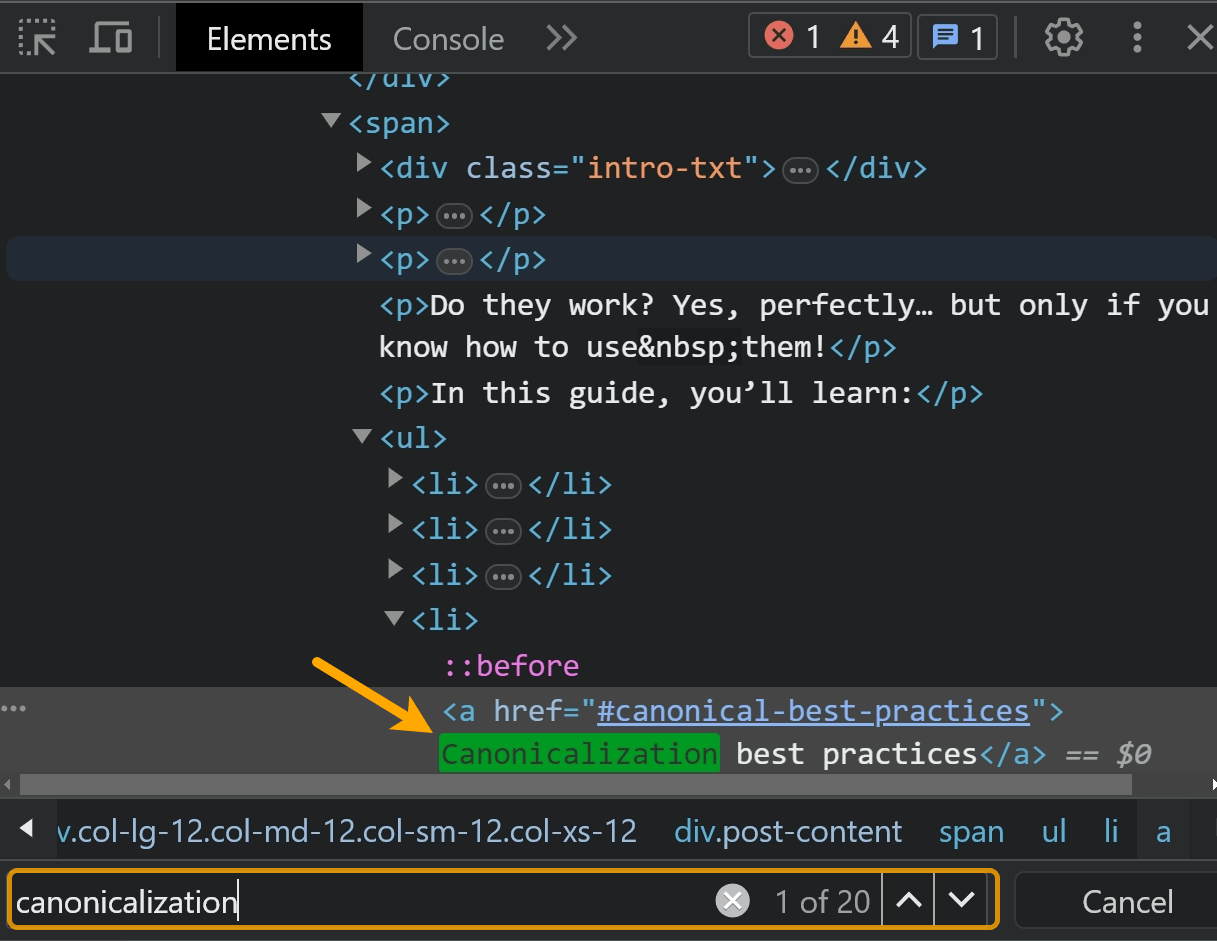
De beste controle is het zoeken in de inhoud van een van de testtools van Google, zoals de URL-inspectietool in Google Search Console. Ik zal hier later meer over praten.
Ik zou zeker alles achter een accordeon of een dropdown controleren. Vaak doen deze elementen verzoeken die inhoud in de pagina laden wanneer erop wordt geklikt. Google klikt niet en ziet de inhoud dus niet.
Als u de inspectiemethode gebruikt om inhoud te doorzoeken, zorg er dan voor dat u de inhoud kopieert en de pagina vervolgens opnieuw laadt of opent in een incognitovenster voordat u gaat zoeken.
Als u op het element hebt geklikt en de inhoud is geladen toen die actie werd ondernomen, vindt u de inhoud. Mogelijk ziet u niet hetzelfde resultaat als u de pagina opnieuw laadt.
Problemen met dubbele inhoud
Met JavaScript kunnen er meerdere URL's zijn voor dezelfde inhoud, wat leidt tot dubbele inhoud problemen. Dit kan worden veroorzaakt door hoofdlettergebruik, schuine strepen, ID's, parameters met ID's, enz. Deze kunnen dus allemaal voorkomen:
domain.com/Abcdomain.com/abcdomain.com/123domain.com/?id=123
Als u slechts één versie geïndexeerd wilt hebben, moet u een naar zichzelf verwijzende canonieke en canonieke tags van andere versies instellen die naar de hoofdversie verwijzen, of idealiter de andere versies omleiden naar de hoofdversie.
Controleer de duplicaten rapport in Site Audit. We geven aan voor welke dubbele clusters canonieke tags zijn ingesteld en voor welke problemen er problemen zijn.
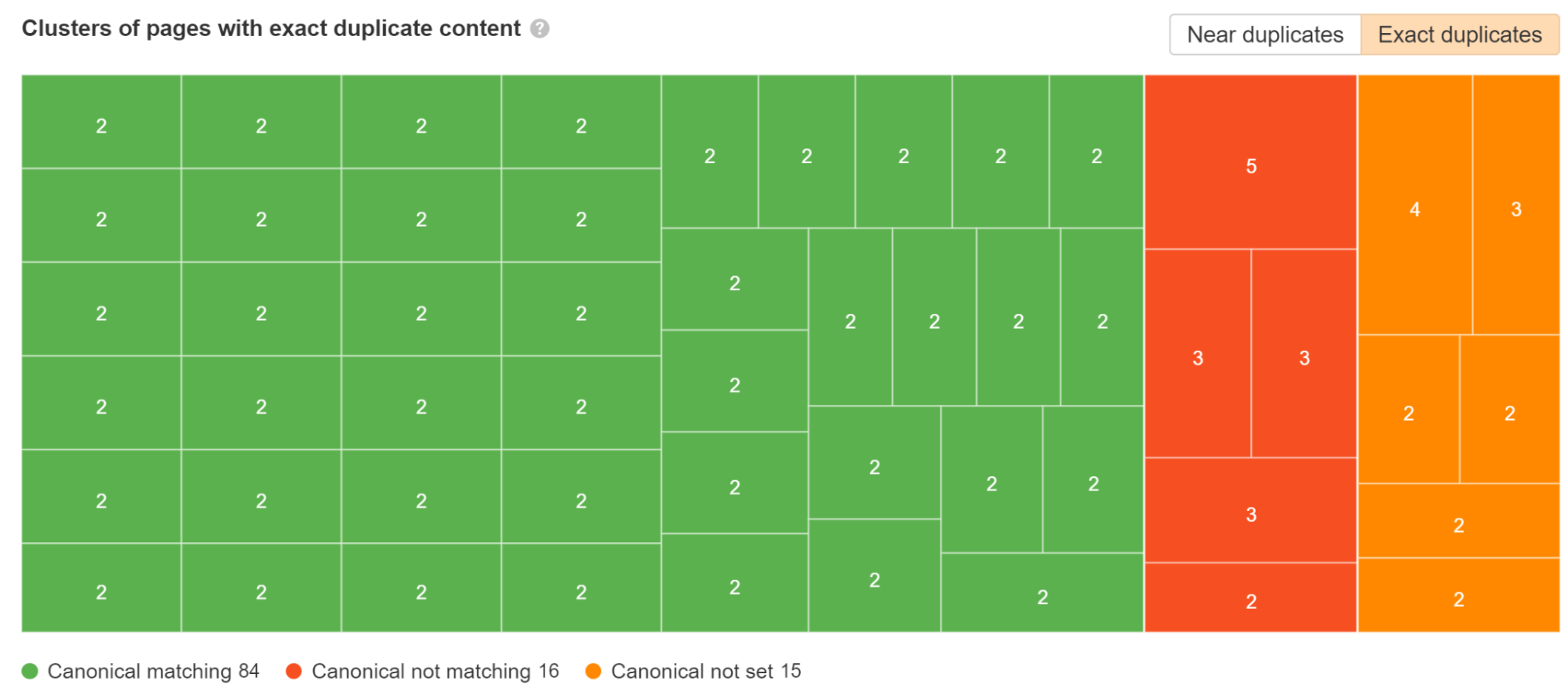
Een veelvoorkomend probleem met JavaScript-frameworks is dat pagina's met en zonder de afsluitende schuine streep kunnen bestaan. In het ideale geval kiest u de versie die u verkiest en zorgt u ervoor dat die versie een naar zichzelf verwijzende canonieke tag heeft, waarna u de andere versie omleidt naar de versie van uw voorkeur.
Bij app-shell-modellen wordt mogelijk heel weinig inhoud en code weergegeven in de initiële HTML-reactie. In feite kan elke pagina op de site dezelfde code weergeven, en deze code kan exact hetzelfde zijn als de code op sommige andere websites.
Als u in Site Audit veel URL's met weinig woorden ziet, kan dit erop duiden dat u dit probleem ondervindt.
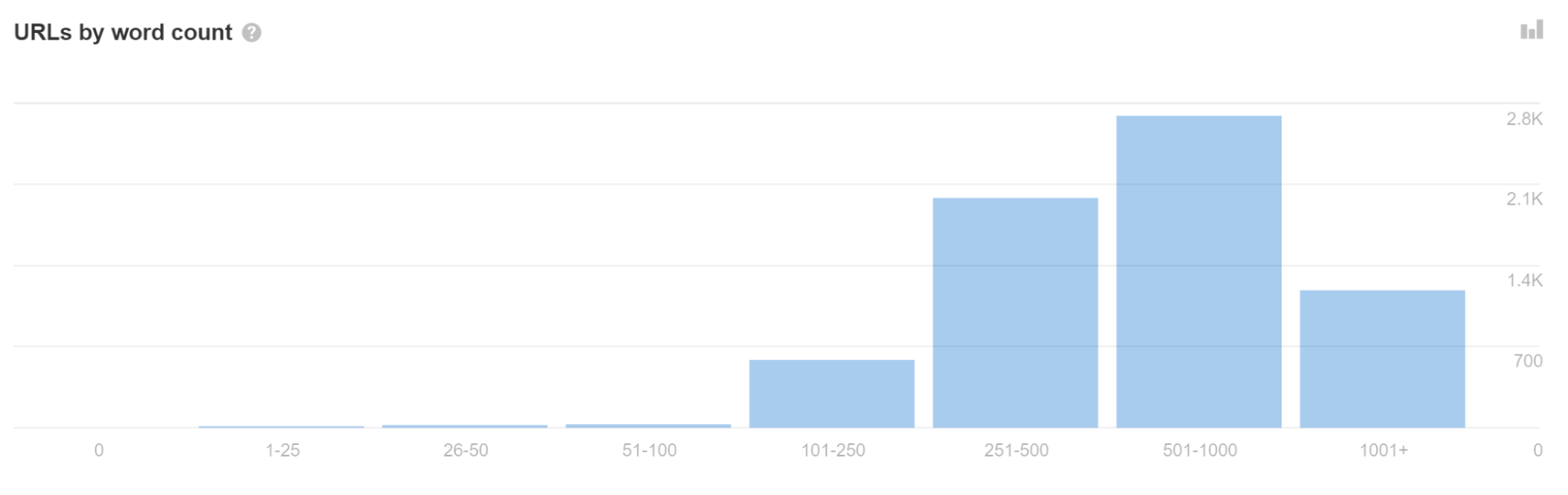
Dit kan er soms toe leiden dat pagina's als duplicaten worden behandeld en niet onmiddellijk worden weergegeven. Erger nog, de verkeerde pagina of zelfs de verkeerde site kan in de zoekresultaten worden weergegeven. Dit zou zichzelf na verloop van tijd moeten oplossen, maar kan problematisch zijn, vooral bij nieuwere websites.
Gebruik geen fragmenten (#) in URL's
# heeft al een gedefinieerde functionaliteit voor browsers. Wanneer erop wordt geklikt, linkt het naar een ander deel van een pagina, zoals onze 'inhoudsopgave'-functie op de blog. Servers verwerken over het algemeen niets na een #. Dus voor een URL zoals abc.com/#something, alles na een # wordt doorgaans genegeerd.
JavaScript-ontwikkelaars hebben besloten dat ze # als trigger voor verschillende doeleinden willen gebruiken, en dat veroorzaakt verwarring. De meest voorkomende manieren waarop ze worden misbruikt zijn voor routering en voor URL-parameters. Ja, ze werken. Nee, je moet het niet doen.
JavaScript-frameworks hebben doorgaans routers die in kaart brengen wat zij routes (paden) noemen schone URL's. Veel JavaScript-ontwikkelaars gebruiken hashes (#) voor routing. Dit is vooral een probleem voor Vue en enkele eerdere versies van Angular.
Om dit voor Vue op te lossen, kunt u samen met uw ontwikkelaar het volgende wijzigen:
Vue router: Use ‘History’ Mode instead of the traditional ‘Hash’ Mode.
const router = new VueRouter ({mode: ‘history’,router: [] //the array of router links)}
Er is een groeiende trend waarbij mensen # gebruiken in plaats van ? als fragment-ID, vooral voor passieve URL-parameters zoals die worden gebruikt voor tracking. Ik heb de neiging om het af te raden vanwege alle verwarring en problemen. Situationeel gezien zou ik het misschien goed vinden als er veel onnodige parameters worden verwijderd.
Maak een sitemap
De routeropties die schone URL's mogelijk maken, hebben meestal een extra module die ook sitemaps kan maken. U kunt ze vinden door te zoeken naar de sitemap van uw systeem en router, zoals 'Vue router sitemap'.
Veel van de weergaveoplossingen kunnen ook sitemapopties hebben. Nogmaals, zoek gewoon het systeem dat u gebruikt en Google het systeem + de sitemap zoals 'Gatsby sitemap', en u zult zeker een oplossing vinden die al bestaat.
Statuscodes en zachte 404's
Omdat JavaScript-frameworks niet server-side zijn, kunnen ze niet echt een serverfout zoals een 404 genereren. Je hebt een aantal verschillende opties voor foutpagina's, zoals:
- Met behulp van een JavaScript-omleiding naar een pagina die wel reageert met een 404-statuscode.
- Een noindex-tag toevoegen aan de pagina die niet werkt, samen met een foutmelding zoals '404-pagina niet gevonden'. Dit wordt behandeld als een zachte 404, aangezien de daadwerkelijk geretourneerde statuscode een 200 oke zal zijn.
JavaScript-omleidingen zijn OK, maar hebben niet de voorkeur
SEO’s zijn eraan gewend 301/302-omleidingen, die server-side zijn. JavaScript wordt doorgaans aan de clientzijde uitgevoerd. Omleidingen aan de serverzijde en zelfs omleidingen voor meta-vernieuwing kunnen door Google gemakkelijker worden verwerkt dan omleidingen via JavaScript, omdat Google de pagina niet hoeft weer te geven om ze te kunnen zien.
JavaScript-omleidingen worden nog steeds gezien en verwerkt tijdens het renderen en zouden in de meeste gevallen in orde moeten zijn. Ze zijn gewoon niet zo ideaal als andere omleidingstypen. Ze worden behandeld als permanente omleidingen en geven nog steeds alle signalen door PageRank.
Je kunt deze omleidingen vaak in de code vinden door te zoeken naar “window.location.href”. De omleidingen kunnen mogelijk ook in het configuratiebestand staan. In de Next.js-configuratie is er een omleidingsfunctie die u kunt gebruiken om omleidingen in te stellen. In andere systemen vindt u ze mogelijk in de router.
Internationaliseringsvraagstukken
Er zijn meestal een paar module-opties voor verschillende raamwerken die bepaalde functies ondersteunen die nodig zijn voor internationalisering, zoals hreflang. Ze zijn gewoonlijk overgezet naar de verschillende systemen en bevatten i18n, intl of, vaak, dezelfde modules die worden gebruikt voor header-tags, zoals Helmet, kunnen worden gebruikt om de benodigde tags toe te voegen.
We signaleren hreflang-problemen in de Lokalisatie rapport in Site Audit. We hebben ook een onderzoek uitgevoerd en dat gevonden 67% van de domeinen die hreflang gebruiken, ondervindt problemen.
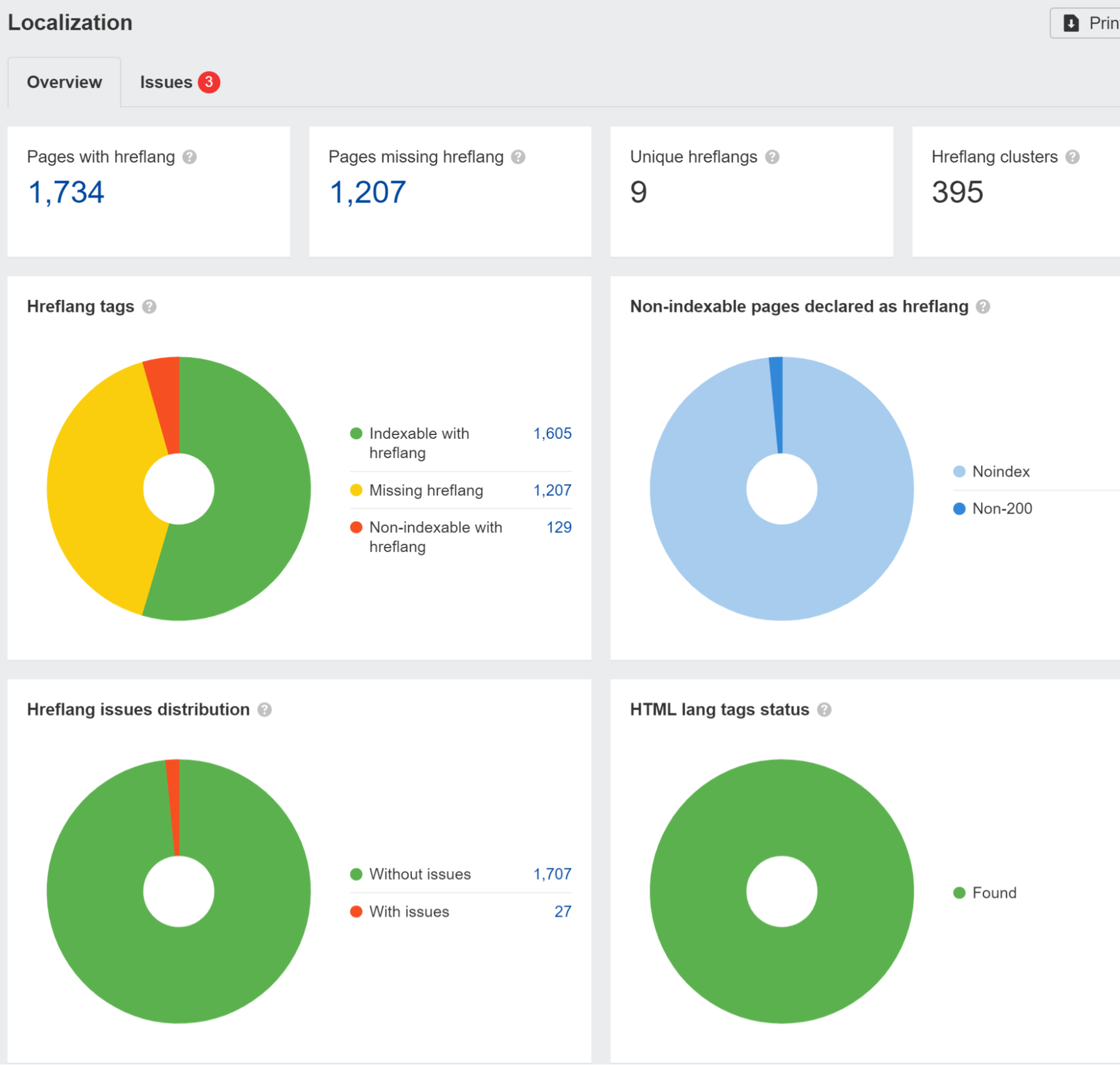
U moet ook op uw hoede zijn als uw site bezoekers uit een specifiek land blokkeert of behandelt of een bepaald IP-adres op verschillende manieren gebruikt. Dit kan ertoe leiden dat uw inhoud niet wordt gezien door Googlebot. Als u logica heeft die gebruikers omleidt, wilt u wellicht bots van deze logica uitsluiten.
Als dit gebeurt, laten we u weten wanneer u een project in Site Audit instelt.

Gebruik gestructureerde gegevens
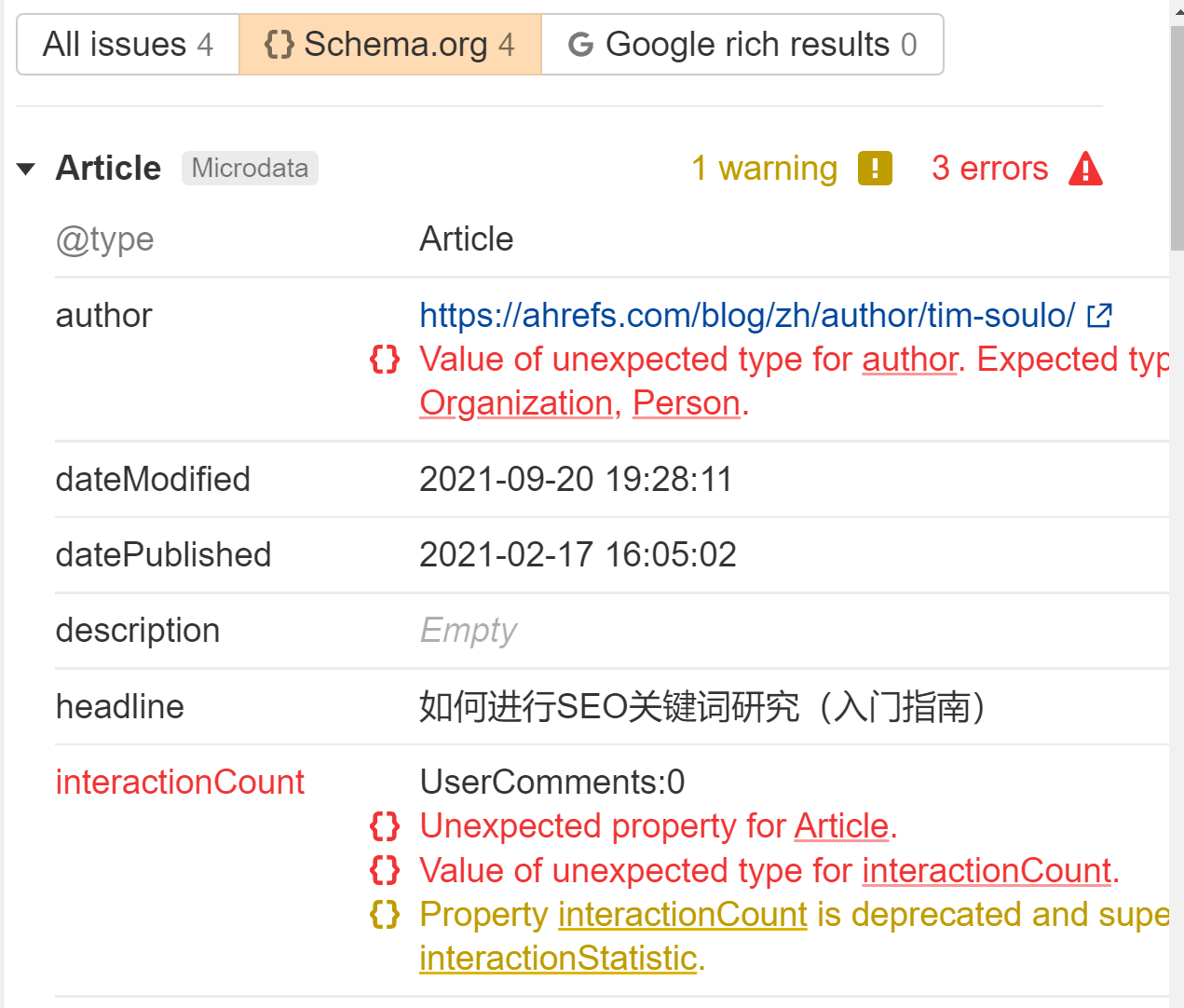
JavaScript kan worden gebruikt om gestructureerde gegevens op uw pagina's te genereren of te injecteren. Het is vrij gebruikelijk om dit met JSON-LD te doen en het zal waarschijnlijk geen problemen veroorzaken, maar voer een aantal tests uit om er zeker van te zijn dat alles eruit komt zoals je verwacht.
We markeren alle gestructureerde gegevens die we tegenkomen in de Problemen rapport in Site Audit. Zoek naar de fout 'Gestructureerde gegevens hebben schema.org-validatie'. Per pagina vertellen wij u precies wat er mis is.
Gebruik links in standaardformaat
Links naar andere pagina's moeten de webstandaardindeling hebben. Interne en externe links moeten een <a> tag met een href attribuut. Er zijn veel manieren waarop u links kunt laten werken voor gebruikers met JavaScript die niet zoekvriendelijk zijn.
Goed:
<a href=”/page”>simple is good</a>
<a href=”/page” onclick=”goTo(‘page’)”>still okay</a>
Bad:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>
<a href=”javascript:void(0)”>nope, missing link</a>
<span onclick=”goTo(‘page’)”>not the right HTML element</span>
<option value="page">nope, wrong HTML element</option>
<a href=”#”>no link</a>
Knop, ng-klik, er zijn nog veel meer manieren waarop dit verkeerd kan worden gedaan.
In mijn ervaring verwerkt Google nog steeds veel van de slechte links en crawlt deze, maar ik weet niet zeker hoe Google deze behandelt als signalen zoals PageRank. Het internet is een rommelige plek en de parsers van Google zijn vaak redelijk vergevingsgezind.
Het is ook de moeite waard om dat op te merken interne links toegevoegd met JavaScript, wordt pas na het renderen opgepikt. Dat zou relatief snel moeten zijn en in de meeste gevallen geen reden tot bezorgdheid zijn.
Gebruik bestandsversiebeheer om onmogelijke statussen op te lossen die worden geïndexeerd
Google slaat alle bronnen zwaar op in de cache. Ik zal hier later wat meer over praten, maar je moet weten dat het systeem ervan ertoe kan leiden dat een aantal onmogelijke toestanden worden geïndexeerd. Dit is een eigenaardigheid van zijn systemen. In deze gevallen worden eerdere bestandsversies gebruikt bij het weergaveproces en kan de geïndexeerde versie van een pagina delen van oudere bestanden bevatten.
U kunt bestandsversiebeheer of vingerafdrukken (file.12345.js) gebruiken om nieuwe bestandsnamen te genereren wanneer er belangrijke wijzigingen worden aangebracht, zodat Google de bijgewerkte versie van de bron moet downloaden voor weergave.
Mogelijk ziet u niet wat er aan Googlebot wordt getoond
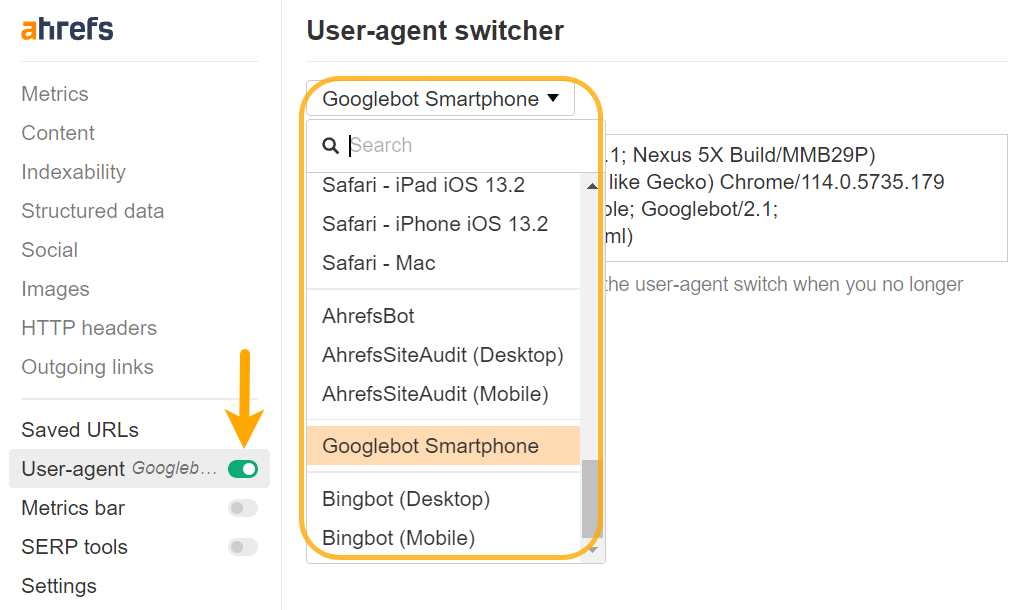
Mogelijk moet u uw user-agent wijzigen om bepaalde problemen goed te kunnen diagnosticeren. Inhoud kan verschillend worden weergegeven voor verschillende user-agents of zelfs IP's. Je zou eens moeten kijken wat Google daadwerkelijk ziet met zijn testtools, en daar zal ik later op ingaan.
U kunt een aangepaste user-agent instellen met Chrome DevTools om problemen op te lossen met sites die vooraf worden weergegeven op basis van specifieke user-agents, of u kunt dit eenvoudig doen met onze werkbalk ook.
Gebruik polyfills voor niet-ondersteunde objecten
Er kunnen functies zijn die door ontwikkelaars worden gebruikt en die Googlebot niet ondersteunt. Uw ontwikkelaars kunnen gebruiken functie detectie. En als er een functie ontbreekt, kunnen ze ervoor kiezen om die functionaliteit over te slaan of een fallback-methode te gebruiken met een polyvulling om te zien of ze het kunnen laten werken.
Dit is meestal een FYI voor SEO’s. Als u iets ziet waarvan u denkt dat Google het zou moeten zien, maar het bedrijf ziet het niet, dan kan dit aan de implementatie liggen.
Gebruik lui laden
Sinds ik dit oorspronkelijk schreef, is lazyloading grotendeels verschoven van JavaScript-gestuurd naar browserbeheer.
Het kan zijn dat je nog steeds een aantal JavaScript-gestuurde lazy load-instellingen tegenkomt. Voor het grootste deel zijn ze waarschijnlijk prima als het luie laden voor afbeeldingen is. Het belangrijkste dat ik zou controleren, is om te zien of de inhoud lui wordt geladen. Raadpleeg het gedeelte 'Controleren of Google uw inhoud ziet' hierboven. Dit soort opstellingen hebben problemen veroorzaakt bij het correct oppikken van de inhoud.
Oneindige scrollproblemen
Als je een oneindige scroll-instelling hebt, raad ik toch een gepagineerde paginaversie aan, zodat Google nog steeds goed kan crawlen.
Een ander probleem dat ik met deze opzet heb gezien, is dat twee pagina's af en toe als één pagina worden geïndexeerd. Ik heb dit een paar keer gezien toen mensen zeiden dat ze hun pagina niet geïndexeerd konden krijgen. Maar ik heb ontdekt dat hun inhoud is geïndexeerd als onderdeel van een andere pagina, meestal het vorige bericht van hen.
Mijn theorie is dat toen Google de viewport groter maakte (hierover later meer), dit de oneindige scroll activeerde en een ander artikel laadde toen het werd weergegeven. In dit geval raad ik aan om het JavaScript-bestand dat het oneindige scrollen afhandelt te blokkeren, zodat de functionaliteit niet kan worden geactiveerd.
Prestatieproblemen
Veel JavaScript-frameworks zorgen voor een hoop moderne prestatie-optimalisatie voor u.
Alle traditionele best practices op het gebied van prestaties zijn nog steeds van toepassing, maar u krijgt een aantal mooie nieuwe opties. Code splitst de bestanden op in kleinere bestanden. Door het schudden van bomen worden de benodigde onderdelen uitgedeeld, zodat je niet alles voor elke pagina laadt, zoals je zou zien in traditionele monolithische opstellingen.
Goed uitgevoerde JavaScript-instellingen zijn iets moois. JavaScript-instellingen die niet goed zijn uitgevoerd, kunnen opgeblazen zijn en lange laadtijden veroorzaken.
Bekijk onze Core Web Vitals-gids voor meer informatie over websiteprestaties.
JavaScript-sites gebruiken meer crawlbudget
JavaScript XHR-verzoeken eten crawlbudget, en ik bedoel dat ze het opslokken. In tegenstelling tot de meeste andere bronnen die in de cache worden opgeslagen, worden deze live opgehaald tijdens het weergaveproces.
Een ander interessant detail is dat de weergaveservice probeert geen bronnen op te halen die niet bijdragen aan de inhoud van de pagina. Als dit verkeerd gaat, mist u mogelijk bepaalde inhoud.
Werknemers worden niet ondersteund, of toch wel?
Hoewel Google historisch gezien zegt dat het servicemedewerkers afwijst en dat servicemedewerkers de DOM niet kunnen bewerken, gaf Google's eigen Martin Splitt aan dat je soms weg kunt komen met het gebruik van webwerkers.
Gebruik HTTP-verbindingen
Googlebot ondersteunt HTTP-verzoeken, maar geen andere verbindingstypen, zoals WebSockets or WebRTC. Als u deze gebruikt, zorg dan voor een fallback die gebruikmaakt van HTTP-verbindingen.
Een probleem met JavaScript-sites is dat ze gedeeltelijke updates van de DOM kunnen uitvoeren. Als u als gebruiker naar een andere pagina bladert, worden bepaalde aspecten, zoals title-tags of canonieke tags in de DOM, mogelijk niet bijgewerkt, maar dit is mogelijk geen probleem voor zoekmachines.
Google laadt elke pagina staatloos alsof het een nieuwe lading is. Het slaat geen eerdere informatie op en navigeert niet tussen pagina's.
Ik heb SEO's zien struikelen omdat ze dachten dat er een probleem was vanwege wat ze te zien kregen na het navigeren van de ene pagina naar de andere, zoals een canonieke tag die niet werd bijgewerkt. Maar Google zal deze toestand misschien nooit zien.
Ontwikkelaars kunnen dit oplossen door de status bij te werken met behulp van de zogenaamde Geschiedenis API. Maar nogmaals, het kan geen probleem zijn. Vaak zijn het gewoon SEO's die problemen veroorzaken voor de ontwikkelaars, omdat het er raar uitziet. Vernieuw de pagina en kijk wat je ziet. Of beter nog, voer het door een van de testtools van Google om te zien wat het ziet.
Over de testtools gesproken, laten we het daar eens over hebben.
Google-testtools
Google heeft verschillende testtools die handig zijn voor JavaScript.
URL-inspectietool in Google Search Console
Dit zou jouw bron van waarheid moeten zijn. Wanneer u een URL inspecteert, krijgt u veel informatie over wat Google heeft gezien en de daadwerkelijk weergegeven HTML van het systeem.
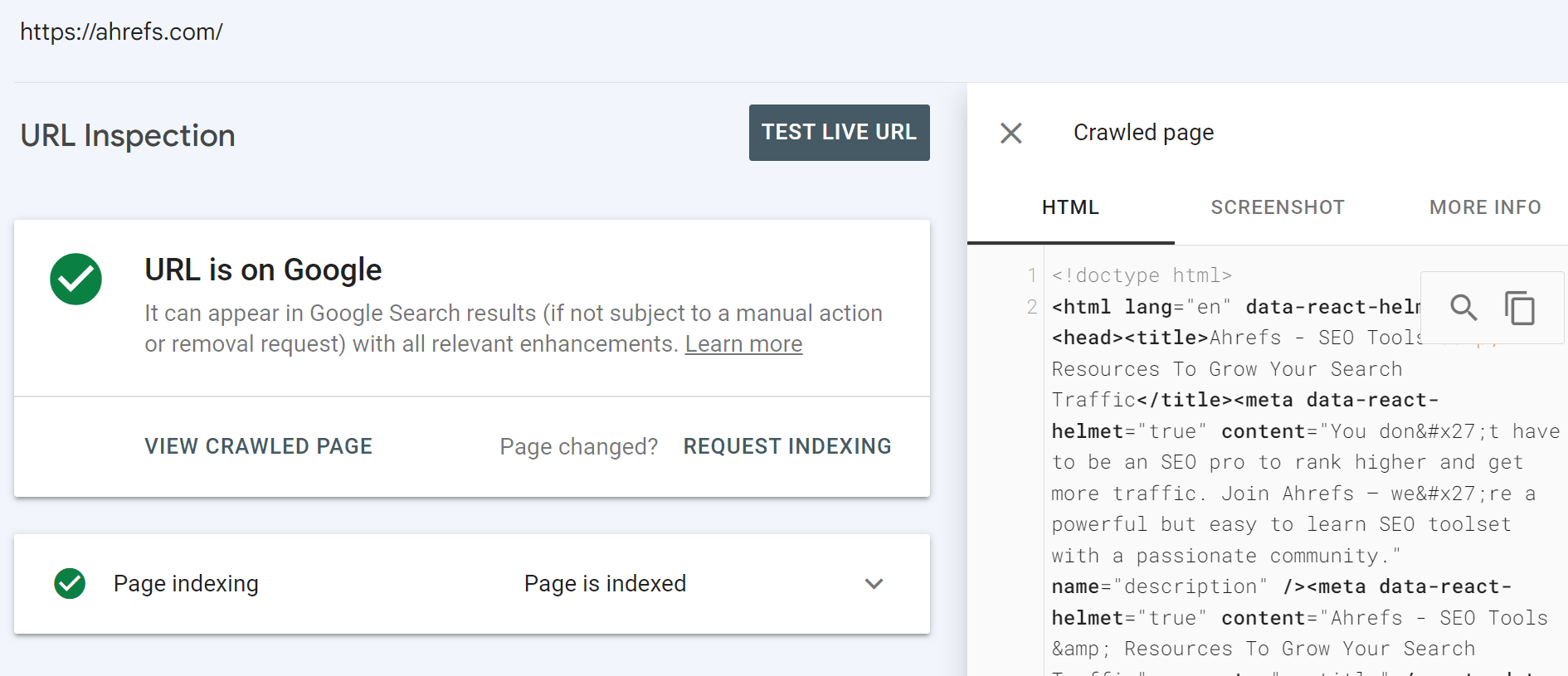
Je hebt ook de mogelijkheid om een live test uit te voeren.

Er zijn enkele verschillen tussen de hoofdrenderer en de live test. De renderer gebruikt bronnen in de cache en is redelijk geduldig. De live test en andere testtools maken gebruik van live bronnen, en ze onderbreken de weergave vroegtijdig omdat u op een resultaat wacht. Ik zal hier later dieper op ingaan in het rendergedeelte.
De schermafbeeldingen in deze tools tonen ook pagina's met geschilderde pixels, wat Google in werkelijkheid niet doet bij het weergeven van een pagina.
De tools zijn handig om te zien of inhoud DOM-geladen is. De HTML die in deze tools wordt weergegeven, is de weergegeven DOM. U kunt naar een tekstfragment zoeken om te zien of dit standaard is geladen.
De tools tonen ook bronnen die mogelijk zijn geblokkeerd en consolefoutmeldingen, die handig zijn bij het opsporen van fouten.
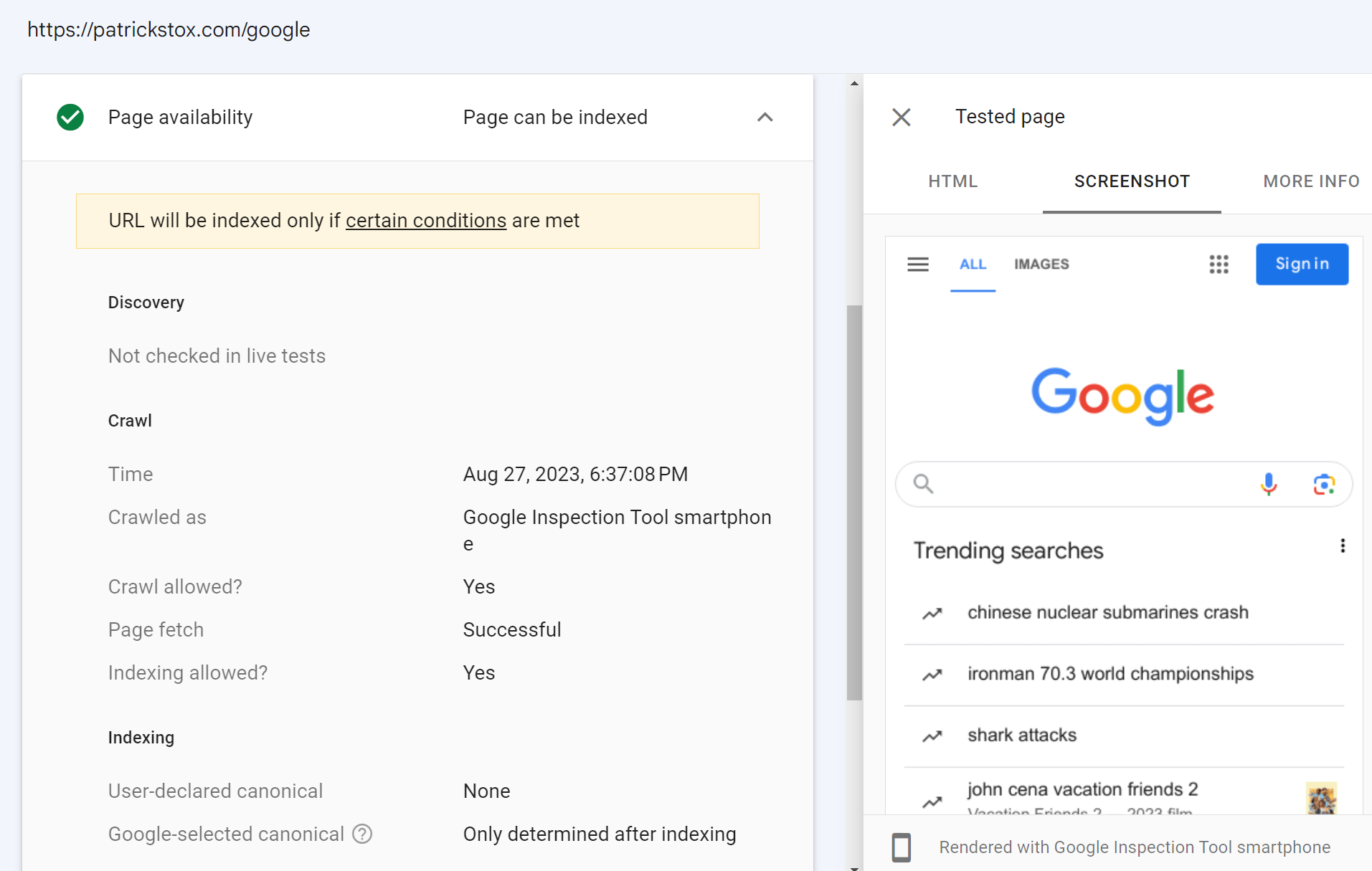
Als u geen toegang heeft tot de Google Search Console-property voor een website, kunt u er nog steeds een live test op uitvoeren. Als u een omleiding toevoegt op uw eigen website op een property waar u toegang heeft tot Google Search Console, kunt u die URL inspecteren. De inspectietool volgt de omleiding en toont u het live testresultaat voor de pagina op het andere domein.
In de onderstaande schermafbeelding heb ik een omleiding van mijn site naar de startpagina van Google toegevoegd. De live test hiervoor volgt de omleiding en toont mij de startpagina van Google. Ik heb eigenlijk geen toegang tot het Google Search Console-account van Google, hoewel ik dat graag zou willen.
Testtool voor rijke resultaten
De Testtool voor rijke resultaten Hiermee kunt u uw weergegeven pagina controleren zoals Googlebot deze zou zien voor mobiel of desktop.
Mobielvriendelijke testtool
U kunt nog steeds gebruik maken van de Mobielvriendelijke testtool voorlopig, maar Google heeft aangekondigd dat het in december 2023 stopt.
Het heeft dezelfde eigenaardigheden als de andere testtools van Google.
Ahrefs
Ahrefs is de enige grote SEO-tool die dat doet geeft webpagina's weer tijdens het crawlen van internet, dus we hebben gegevens van JavaScript-sites die geen enkele andere tool heeft. We renderen ~200 miljoen pagina's per dag, maar dat is een fractie van wat we crawlen.
Hiermee kunnen we controleren op JavaScript-omleidingen. We kunnen ook links tonen die we hebben gevonden ingevoegd met JavaScript, die we tonen met een JS-tag in de linkrapporten:

In het vervolgkeuzemenu voor pagina's in Site Explorer, hebben we ook een inspectieoptie waarmee u de geschiedenis van een pagina kunt bekijken en deze kunt vergelijken met andere crawls. We hebben daar een JS-markering voor pagina's die zijn weergegeven met JavaScript ingeschakeld.

U kunt JavaScript inschakelen Site Audit crawlt om meer gegevens in uw audits te ontsluiten.
Als u JavaScript-weergave hebt ingeschakeld, leveren wij de onbewerkte en gerenderde HTML voor elke pagina. Gebruik de optie ‘vergrootglas’ naast een pagina in Page Explorer en ga in het menu naar ‘Bron bekijken’. U kunt ook vergelijken met eerdere crawls en zoeken in de onbewerkte of weergegeven HTML op alle pagina's van de site.
Als u een crawl zonder JavaScript uitvoert en vervolgens een andere met JavaScript, kunt u onze crawlvergelijkingsfuncties gebruiken om de verschillen tussen de versies te zien.
Ahrefs' SEO-werkbalk ondersteunt ook JavaScript en stelt u in staat HTML te vergelijken met weergegeven versies van tags.
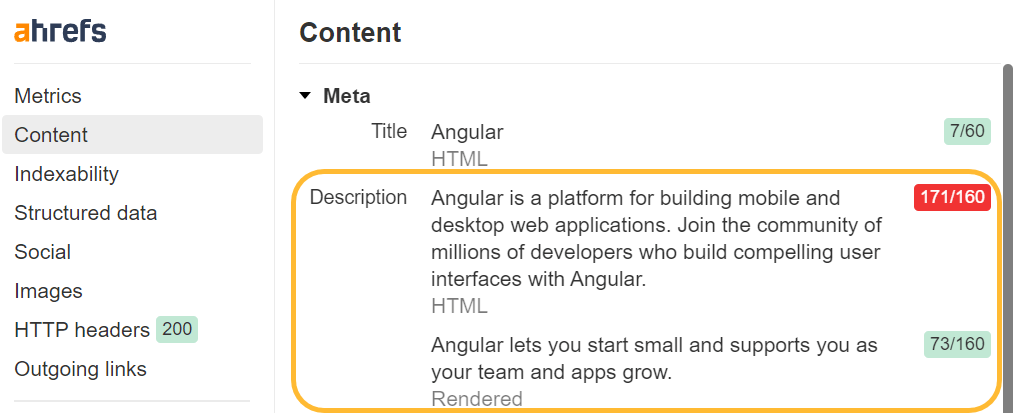
Bron bekijken versus inspecteren
Wanneer u met de rechtermuisknop in een browservenster klikt, ziet u een aantal opties voor het bekijken van de broncode van de pagina en voor het inspecteren van de pagina. Bron bekijken laat je hetzelfde zien als een GET-verzoek. Dit is de onbewerkte HTML van de pagina.

Inspect toont u de verwerkte DOM nadat er wijzigingen zijn aangebracht en komt dichter in de buurt van de inhoud die Googlebot ziet. Het is de pagina nadat JavaScript is uitgevoerd en wijzigingen heeft aangebracht.
Wanneer u met JavaScript werkt, moet u meestal inspectie boven weergavebron gebruiken.
Soms moet u de weergavebron controleren
Omdat Google voor sommige problemen naar zowel onbewerkte als gerenderde HTML kijkt, moet u mogelijk nog steeds de weergavebron controleren. Als de tools van Google u bijvoorbeeld vertellen dat de pagina als noindex is gemarkeerd, maar u geen noindex-tag ziet in de weergegeven HTML, is het mogelijk dat deze aanwezig was in de onbewerkte HTML en werd overschreven.
Voor zaken als noindex, nofollow en canonieke tags moet u mogelijk de onbewerkte HTML controleren, omdat problemen kunnen worden overgedragen. Houd er rekening mee dat Google de meest beperkende uitspraken zal doen die het heeft gezien voor de meta-robottags, en canonieke tags zal negeren wanneer u meerdere canonieke tags laat zien.
Browse niet terwijl JavaScript is uitgeschakeld
Ik heb deze aanbevolen veel te vaak gezien. Google geeft JavaScript weer, dus wat u ziet zonder JavaScript lijkt helemaal niet op wat Google ziet. Dit is gewoon dom.
Gebruik Google Cache niet
De cache van Google is geen betrouwbare manier om te controleren wat Googlebot ziet. Wat u doorgaans in de cache ziet, is de onbewerkte HTML-momentopname. Uw browser activeert vervolgens het JavaScript waarnaar in de HTML wordt verwezen. Het is niet wat Google zag toen het de pagina weergaf.
Om dit nog ingewikkelder te maken, kunnen websites hun eigen Cross-Origin Resource Sharing (CORS) beleid zo ingesteld dat de vereiste bronnen niet vanuit een ander domein kunnen worden geladen.
De cache wordt gehost op webcache.googleusercontent.com. Wanneer dat domein de bronnen van het daadwerkelijke domein probeert op te vragen, zegt het CORS-beleid: "Nee, u heeft geen toegang tot mijn bestanden." Vervolgens worden de bestanden niet geladen en ziet de pagina er in de cache kapot uit.
Het cachesysteem is gemaakt om de inhoud te zien wanneer een website niet beschikbaar is. Het is niet bijzonder nuttig als debug-tool.
In de begindagen van zoekmachines was een gedownload HTML-antwoord voldoende om de inhoud van de meeste pagina's te zien. Dankzij de opkomst van JavaScript moeten zoekmachines nu veel pagina's weergeven zoals een browser dat zou doen, zodat ze de inhoud kunnen zien zoals een gebruiker deze ziet.
Het systeem dat het weergaveproces bij Google afhandelt, heet de Web Rendering Service (WRS). Google heeft een simplistisch diagram gegeven om te laten zien hoe dit proces werkt.
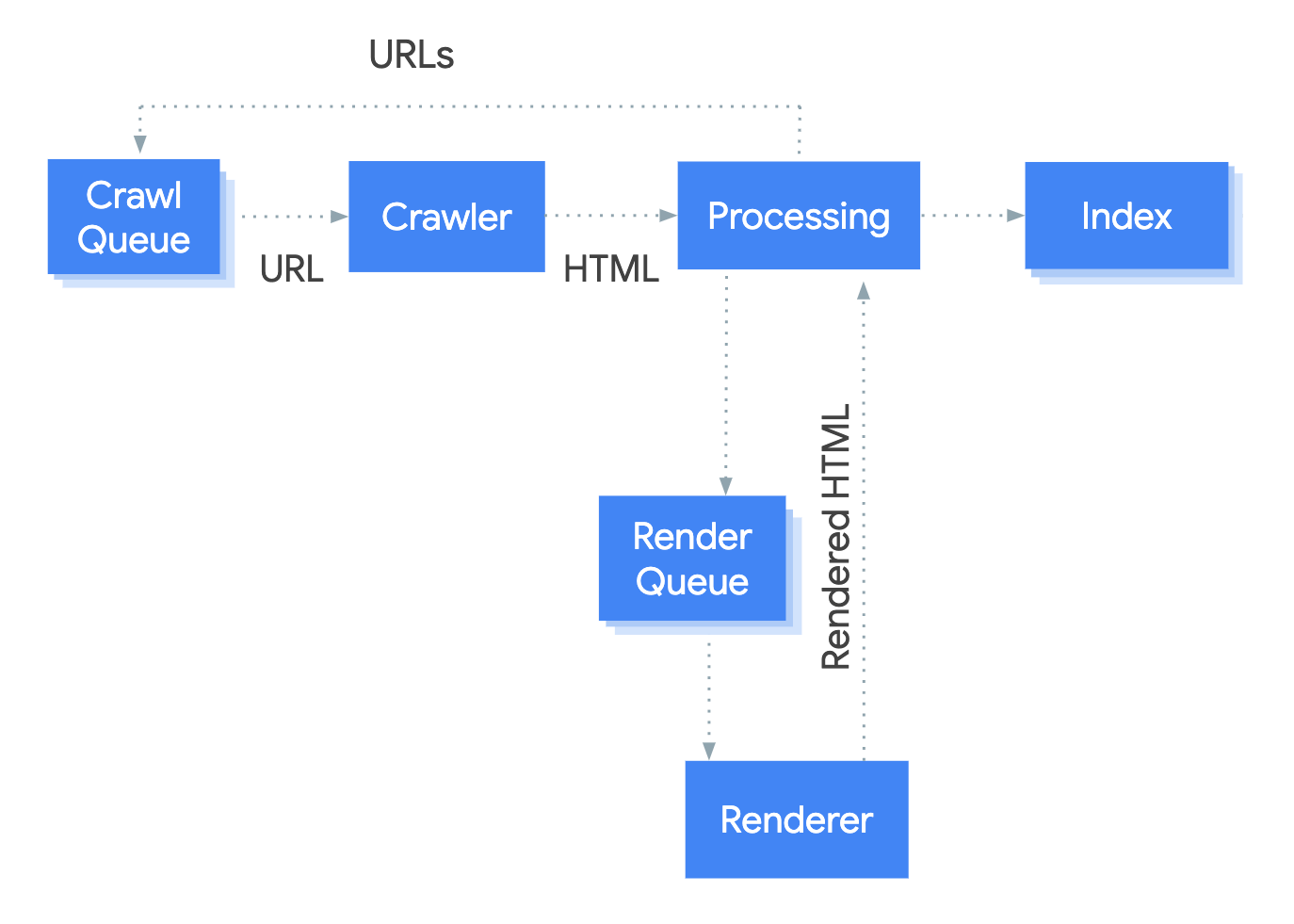
Laten we zeggen dat we het proces starten op URL.
1. kruiper
De crawler stuurt GET-verzoeken naar de server. De server antwoordt met headers en de inhoud van het bestand, dat vervolgens wordt opgeslagen. De headers en de inhoud komen doorgaans in hetzelfde verzoek.
Het verzoek is waarschijnlijk afkomstig van een mobiele user-agent sinds Google bestaat mobiel-eerste indexering nu, maar het kruipt ook nog steeds met de desktop user-agent.
De verzoeken komen vooral uit Mountain View (CA, VS), maar dat gebeurt ook wat crawlen voor locale-adaptieve pagina's buiten de VS Zoals ik eerder al zei, kan dit problemen veroorzaken als sites bezoekers in een specifiek land op verschillende manieren blokkeren of behandelen.
Het is ook belangrijk op te merken dat hoewel Google de uitvoer van het crawlproces op de afbeelding hierboven als 'HTML' vermeldt, het in werkelijkheid de bronnen crawlt en opslaat die nodig zijn om de pagina te bouwen, zoals de HTML-, JavaScript- en CSS-bestanden. Er geldt ook een maximale grootte van 15 MB voor HTML-bestanden.
2. Verwerken
Er zijn veel systemen die in de afbeelding worden verdoezeld door de term 'Verwerking'. Ik ga er een paar bespreken die relevant zijn voor JavaScript.
Bronnen en links
Google navigeert niet van pagina naar pagina zoals een gebruiker dat zou doen. Onderdeel van “Verwerken” is het controleren van de pagina op links naar andere pagina's en bestanden die nodig zijn om de pagina op te bouwen. Deze links worden eruit gehaald en toegevoegd aan de crawlwachtrij, wat Google gebruikt om het crawlen te prioriteren en te plannen.

Google haalt bronlinks (CSS, JS, enz.) op die nodig zijn om een pagina op te bouwen uit zaken als <link> labels.
Zoals ik eerder zei, interne links toegevoegd met JavaScript, wordt pas na het renderen opgepikt. Dat zou relatief snel moeten zijn en in de meeste gevallen geen reden tot bezorgdheid zijn. Dingen als nieuwssites kunnen de uitzondering zijn waar elke seconde telt.
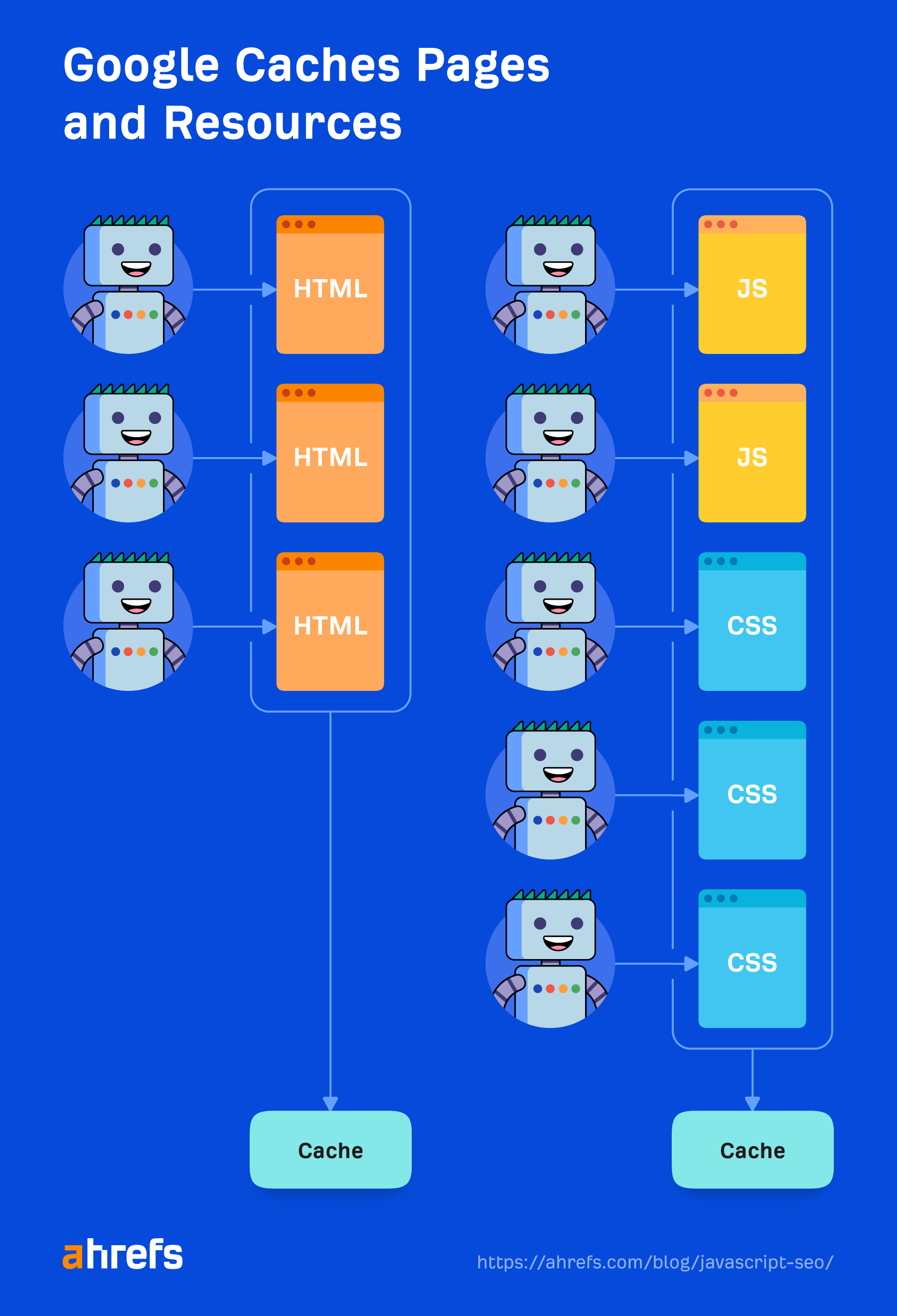
Caching
Elk bestand dat Google downloadt, inclusief HTML-pagina's, JavaScript-bestanden, CSS-bestanden, enz., wordt agressief in de cache opgeslagen. Google negeert uw cachetijden en haalt een nieuwe kopie op wanneer hij dat wil. Ik zal hier wat meer over vertellen en waarom het belangrijk is in de sectie “Renderer”.
Dubbele eliminatie
Dubbele inhoud kan uit de gedownloade HTML worden verwijderd of er geen prioriteit meer aan worden gegeven voordat deze wordt verzonden naar weergave. Ik heb hier al over gesproken in het gedeelte 'Dubbele inhoud' hierboven.
Meest restrictieve richtlijnen
Zoals ik eerder al zei, zal Google de meest restrictieve kiezen verklaringen tussen HTML en de weergegeven versie van een pagina. Als JavaScript een verklaring wijzigt en die in strijd is met de verklaring van HTML, zal Google eenvoudigweg gehoorzamen aan de meest beperkende verklaring. Noindex zal de index overschrijven, en noindex in HTML zal het renderen helemaal overslaan.
3. Renderwachtrij
Een van de grootste zorgen van veel SEO's met JavaScript en tweestapsindexering (HTML en vervolgens weergegeven pagina) is dat pagina's dagen of zelfs weken niet worden weergegeven. Toen Google dit onderzocht, werd het gevonden pagina's gingen met een gemiddelde tijd van vijf seconden naar de rendereren het 90e percentiel was minuten. Dus de hoeveelheid tijd tussen het ophalen van de HTML en het weergeven van de pagina's zou in de meeste gevallen geen probleem moeten zijn.
Google geeft echter niet alle pagina's weer. Zoals ik eerder al zei, wordt een pagina met een robots-metatag of header met een noindex-tag niet naar de renderer verzonden. Er worden geen bronnen verspild door een pagina weer te geven die deze toch niet kan indexeren.
Het heeft ook kwaliteitscontroles in dit proces. Als het naar de HTML kijkt of redelijkerwijs uit andere signalen of patronen kan opmaken dat een pagina niet goed genoeg is om te indexeren, dan zal het niet de moeite nemen om dat naar de renderer te sturen.
Er is ook een eigenaardigheid met nieuwssites. Google wil pagina's op nieuwssites snel indexeren, zodat het de pagina's eerst kan indexeren op basis van de HTML-inhoud en later terug kan komen om deze pagina's weer te geven.
4. Renderer
De renderer is waar Google een pagina weergeeft om te zien wat een gebruiker ziet. Dit is waar het JavaScript en eventuele wijzigingen die door JavaScript in het ARREST.
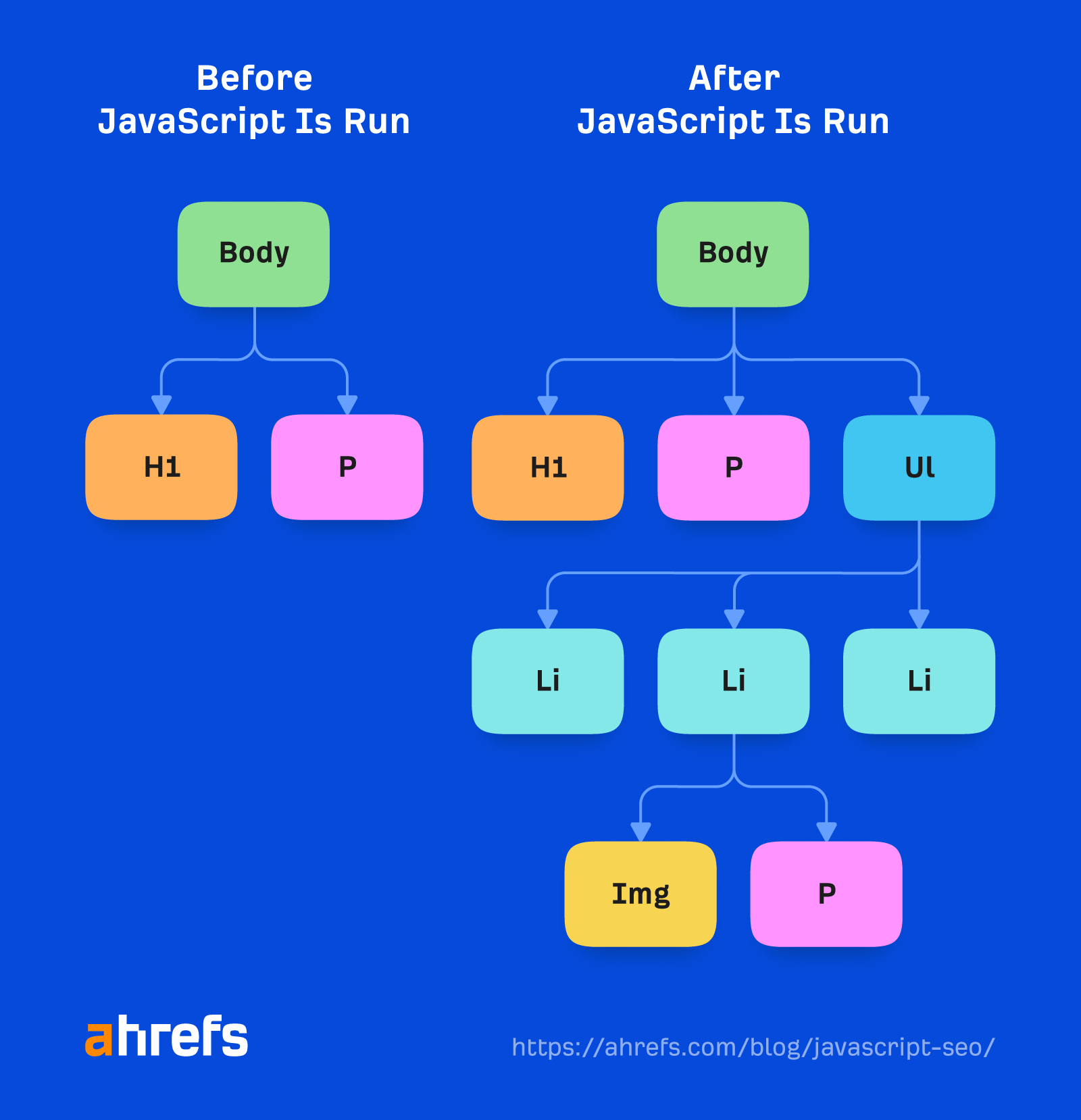
Hiervoor gebruikt Google een headless Chrome-browser die nu ‘evergreen’ is, wat betekent dat deze de nieuwste Chrome-versie moet gebruiken en de nieuwste functies moet ondersteunen. Jaren geleden renderde Google met Chrome 41, en veel functies werden toen nog niet ondersteund.
Google heeft meer informatie over de WRS, waaronder zaken als het weigeren van machtigingen, staatloos zijn, het afvlakken van lichte DOM en schaduw-DOM, en meer dat de moeite van het lezen waard is.
Renderen op webschaal is misschien wel het achtste wereldwonder. Het is een serieuze onderneming en vergt een enorme hoeveelheid middelen. Vanwege de schaal gebruikt Google veel kortere wegen bij het weergaveproces om de zaken te versnellen.
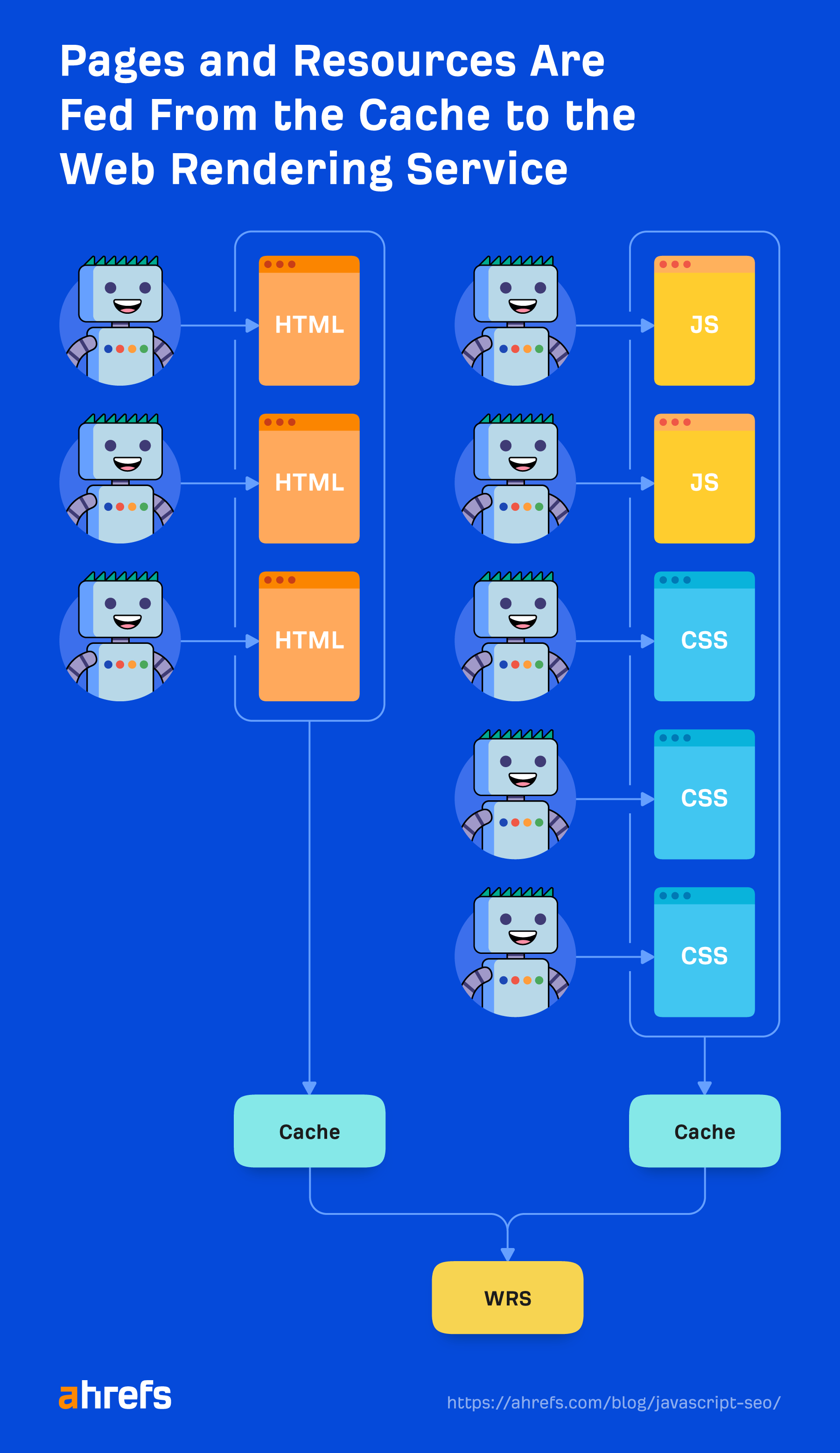
In cache opgeslagen bronnen
Google is sterk afhankelijk van cachingbronnen. Pagina's worden in de cache opgeslagen. Bestanden worden in de cache opgeslagen. Bijna alles wordt in de cache opgeslagen voordat het naar de renderer wordt verzonden. Het gaat niet de deur uit en downloadt elke bron voor elke pagina die wordt geladen, omdat dat duur zou zijn voor zowel de site als de website-eigenaren. In plaats daarvan gebruikt het deze in de cache opgeslagen bronnen om efficiënter te zijn.
De uitzondering hierop zijn XHR-verzoeken, die de renderer in realtime zal doen.
Er is geen time-out van vijf seconden
Een veel voorkomende SEO-mythe is dat Google slechts vijf seconden wacht om uw pagina te laden. Hoewel het altijd een goed idee is om uw site sneller te maken, klopt deze mythe niet echt met de manier waarop Google de hierboven genoemde bestanden in de cache opslaat. Het laadt al een pagina met alles wat in de cache is opgeslagen in zijn systemen, en doet geen verzoeken om nieuwe bronnen.
Als het maar vijf seconden zou wachten, zou het veel inhoud missen.
De mythe komt waarschijnlijk voort uit de testtools zoals de URL Inspection-tool, waarbij bronnen live worden opgehaald in plaats van in de cache, en ze binnen een redelijke tijd een resultaat aan gebruikers moeten retourneren. Het kan ook komen doordat pagina's geen prioriteit hebben bij het crawlen, waardoor mensen denken dat ze lang moeten wachten met het weergeven en indexeren ervan.
Er is geen vaste time-out voor de renderer. Het werkt met een versnelde timer om te zien of er op een later tijdstip iets wordt toegevoegd. Er wordt ook naar de gebeurtenislus in de browser gekeken om te zien wanneer alle acties zijn ondernomen. Het is erg geduldig en u hoeft zich geen zorgen te maken over een specifieke tijdslimiet.
Het is geduldig, maar heeft ook voorzorgsmaatregelen voor het geval er iets vastloopt of iemand Bitcoin op zijn pagina's probeert te minen. Ja, het is een ding. We moesten ook waarborgen toevoegen voor Bitcoin-mining publiceerde een studie over het.
Wat Googlebot ziet
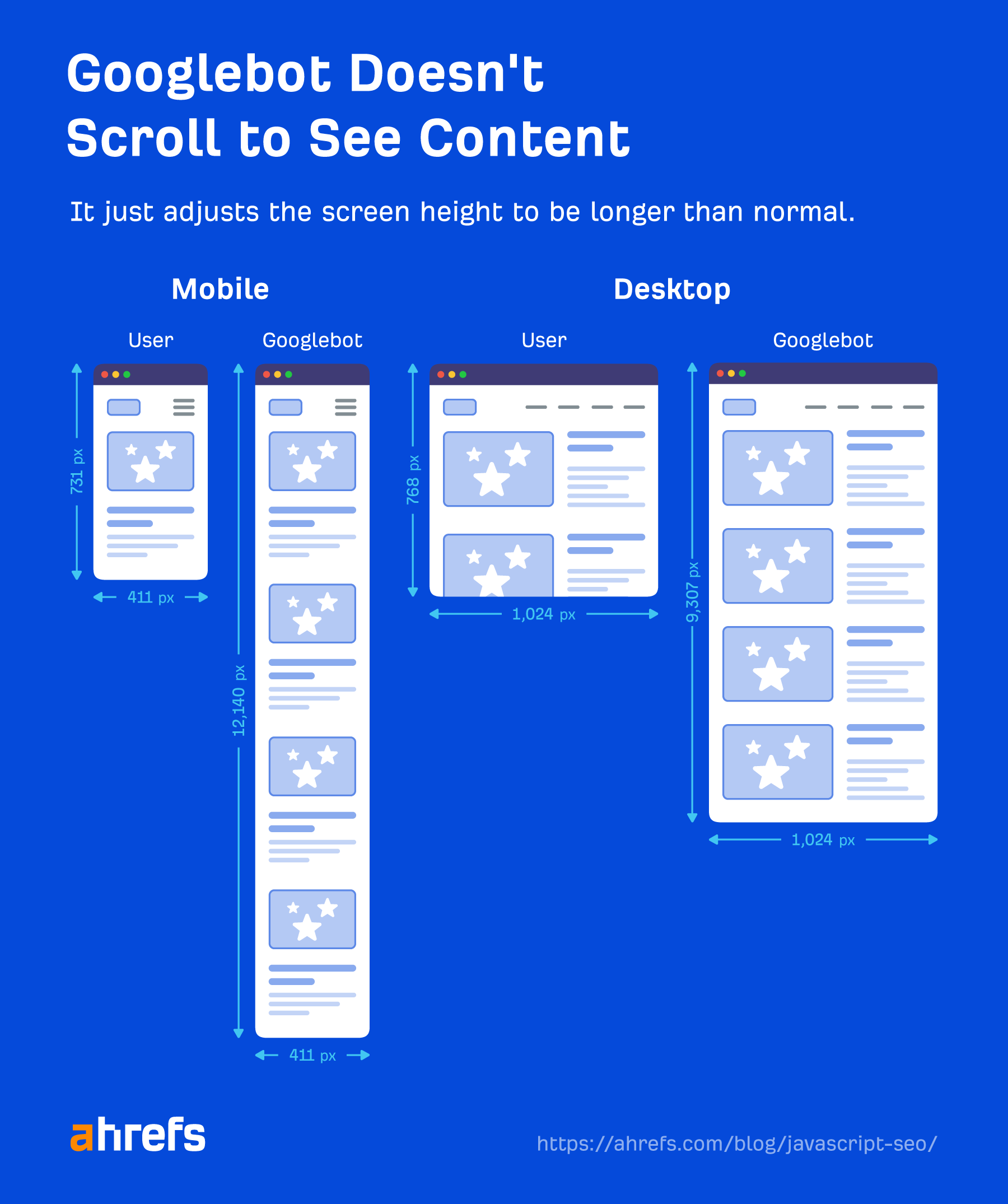
Googlebot onderneemt geen actie op webpagina's. Er wordt niet op dingen geklikt of gescrolld, maar dat betekent niet dat er geen oplossingen zijn. Zolang inhoud in de DOM wordt geladen zonder dat er actie nodig is, zal Google deze zien. Als het pas na een klik in het DOM wordt geladen, wordt de inhoud niet gevonden.
Google hoeft ook niet te scrollen om uw inhoud te zien, omdat het een slimme oplossing heeft om de inhoud te zien. Voor mobiel laadt het de pagina met een schermgrootte van 411×731 pixels en wijzigt de lengte naar 12,140 pixels.
In wezen wordt het een hele lange telefoon met een schermgrootte van 411×12140 pixels. Voor desktop doet het hetzelfde en gaat van 1024×768 pixels naar 1024×9307 pixels. Ik heb geen recente tests voor deze cijfers gezien en deze kunnen veranderen afhankelijk van hoe lang de pagina's zijn.
Een andere interessante kortere weg is dat Google de pixels niet schildert tijdens het weergaveproces. Het kost tijd en extra middelen om het laden van een pagina te voltooien, en het is niet echt nodig om de uiteindelijke staat te zien met de geschilderde pixels. Bovendien zijn grafische kaarten duur tussen gaming, cryptomining en AI.
Google hoeft alleen maar de structuur en de lay-out te kennen, en dat gebeurt zonder de pixels daadwerkelijk te hoeven schilderen. Als Martin plaatst het:
Bij Google Zoeken geven we niet echt om de pixels, omdat we deze niet echt aan iemand willen laten zien. We willen de informatie en de semantische informatie verwerken, dus we hebben iets in de tussenfase nodig. We hoeven de pixels niet daadwerkelijk te schilderen.
Een visueel beeld kan helpen om wat beter uit te leggen wat er is uitgesneden. Als u in Chrome Dev Tools een test uitvoert op het tabblad 'Prestaties', krijgt u een laaddiagram. Het effen groene gedeelte vertegenwoordigt hier de schilderfase. Voor Googlebot gebeurt dat nooit, dus het bespaart middelen.

Gray =Downloaden
Blauw =HTML
Geel = JavaScript
Paars = Indeling
Groen = Schilderen
5. Crawlwachtrij
Google heeft een bron die iets vertelt over het crawlbudget. Maar u moet weten dat elke site zijn eigen crawlbudget heeft en dat aan elk verzoek prioriteit moet worden gegeven. Google moet ook een evenwicht vinden tussen het crawlen van uw pagina's en elke andere pagina op internet.
Nieuwere sites in het algemeen of sites met veel dynamische pagina's worden waarschijnlijk langzamer gecrawld. Sommige pagina's zullen minder vaak worden bijgewerkt dan andere, en sommige bronnen kunnen ook minder vaak worden opgevraagd.
Er zijn veel opties als het gaat om het renderen van JavaScript. Google heeft een solide grafiek die ik zojuist ga laten zien. Elke vorm van SSR, statische weergave en pre-rendering-instellingen zijn prima voor zoekmachines. Gatsby, Next, Nuxt, etc. zijn allemaal geweldig.

De meest problematische is de volledige weergave aan de clientzijde, waarbij alle weergave in de browser plaatsvindt. Hoewel Google waarschijnlijk wel akkoord gaat met weergave aan de clientzijde, kunt u het beste een andere weergaveoptie kiezen om andere te ondersteunen zoekmachines.
Bing heeft dat ook gedaan ondersteuning voor JavaScript-weergave, maar de omvang is onbekend. Yandex en Baidu hebben, voor zover ik heb gezien, beperkte ondersteuning, en veel andere zoekmachines hebben weinig tot geen ondersteuning voor JavaScript. Onze eigen zoekmachine, ja, heeft ondersteuning en we renderen ~200 miljoen pagina's per dag. Maar we geven niet elke pagina weer die we crawlen.
Er is ook de mogelijkheid van dynamische weergave, dat wordt weergegeven voor bepaalde user-agents. Dit is een oplossing en om eerlijk te zijn heb ik het nooit aanbevolen en ik ben blij dat Google dit nu ook afraadt.
In bepaalde situaties wilt u het misschien gebruiken om te renderen voor bepaalde bots, zoals zoekmachines of zelfs bots voor sociale media. Bots voor sociale media gebruiken geen JavaScript, dus dingen zoals OG-tags worden niet gezien tenzij u de inhoud weergeeft voordat u deze aan hen aanbiedt.
In de praktijk maakt het de instellingen complexer en moeilijker voor SEO's om problemen op te lossen. Het is zeker cloaking, ook al zegt Google van niet en vindt het prima.
Note
Als je de oude gebruikte AJAX-crawlschema met hashbangs (#!), weet dat dit verouderd is en niet langer wordt ondersteund.
Laatste gedachten
JavaScript is niet iets waar SEO's bang voor hoeven te zijn. Hopelijk heeft dit artikel je geholpen beter te begrijpen hoe je ermee kunt werken.
Wees niet bang om contact op te nemen met uw ontwikkelaars, met hen samen te werken en hen vragen te stellen. Zij zullen uw grootste bondgenoten zijn bij het verbeteren van uw JavaScript-site voor zoekmachines.
Vragen hebben? Laat het me weten op Twitter.
Verdere lezing
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://ahrefs.com/blog/javascript-seo/

