Generatieve AI heeft veel potentieel op het gebied van AI geopend. We zien talloze toepassingen, waaronder het genereren van tekst, het genereren van code, samenvattingen, vertalingen, chatbots en meer. Een voorbeeld van zo'n gebied dat zich ontwikkelt, is het gebruik van natuurlijke taalverwerking (NLP) om nieuwe mogelijkheden te ontsluiten voor toegang tot gegevens via intuïtieve SQL-query's. In plaats van zich met complexe technische code bezig te houden, kunnen zakelijke gebruikers en data-analisten in gewone taal vragen stellen over data en inzichten. Het primaire doel is om automatisch SQL-query's te genereren op basis van tekst in natuurlijke taal. Om dit te doen, wordt de tekstinvoer omgezet in een gestructureerde weergave en op basis van deze weergave wordt een SQL-query gemaakt die kan worden gebruikt om toegang te krijgen tot een database.
In dit bericht bieden we een inleiding tot tekst in SQL (Text2SQL) en verkennen we gebruiksscenario's, uitdagingen, ontwerppatronen en best practices. Concreet bespreken we het volgende:
- Waarom hebben we Text2SQL nodig?
- Belangrijke componenten voor tekst naar SQL
- Snelle technische overwegingen voor natuurlijke taal of tekst naar SQL
- Optimalisaties en best practices
- Architectuur patronen
Waarom hebben we Text2SQL nodig?
Tegenwoordig is er een grote hoeveelheid gegevens beschikbaar in traditionele data-analyse, datawarehousing en databases, die voor de meerderheid van de organisatieleden misschien niet gemakkelijk te doorzoeken of te begrijpen zijn. Het primaire doel van Text2SQL is om databases met query's toegankelijker te maken voor niet-technische gebruikers, die hun query's in natuurlijke taal kunnen verstrekken.
Met NLP SQL kunnen zakelijke gebruikers gegevens analyseren en antwoorden krijgen door vragen in natuurlijke taal te typen of uit te spreken, zoals de volgende:
- 'Toon de totale omzet voor elk product afgelopen maand'
- “Welke producten genereerden meer omzet?”
- “Hoeveel procent van de klanten komt uit elke regio?”
Amazonebodem is een volledig beheerde service die een keuze biedt uit goed presterende funderingsmodellen (FM's) via één enkele API, waardoor Gen AI-applicaties eenvoudig kunnen worden gebouwd en geschaald. Het kan worden gebruikt om SQL-query's te genereren op basis van vragen die vergelijkbaar zijn met de hierboven genoemde, en om gestructureerde gegevens van de organisatie te bevragen en antwoorden in natuurlijke taal te genereren op basis van de vraagantwoordgegevens.
Belangrijkste componenten voor tekst naar SQL
Tekst-naar-SQL-systemen omvatten verschillende fasen om zoekopdrachten in natuurlijke taal om te zetten in uitvoerbare SQL:
- Natuurlijke taalverwerking:
- Analyseer de invoervraag van de gebruiker
- Haal de belangrijkste elementen en intentie eruit
- Converteren naar een gestructureerd formaat
- SQL-generatie:
- Wijs geëxtraheerde details toe aan de SQL-syntaxis
- Genereer een geldige SQL-query
- Database-query:
- Voer de door AI gegenereerde SQL-query uit op de database
- Resultaten ophalen
- Resultaten terugsturen naar de gebruiker
Een opmerkelijke mogelijkheid van Large Language Models (LLM's) is het genereren van code, inclusief Structured Query Language (SQL) voor databases. Deze LLM's kunnen worden gebruikt om de natuurlijke taalvraag te begrijpen en een overeenkomstige SQL-query als uitvoer te genereren. De LLM's zullen profiteren van het adopteren van in-context leren en het verfijnen van instellingen naarmate er meer gegevens worden verstrekt.
Het volgende diagram illustreert een eenvoudige Text2SQL-stroom.

Snelle technische overwegingen voor natuurlijke taal naar SQL
De prompt is van cruciaal belang bij het gebruik van LLM's om natuurlijke taal in SQL-query's te vertalen, en er zijn verschillende belangrijke overwegingen bij prompt-engineering.
effectief snelle techniek is de sleutel tot het ontwikkelen van natuurlijke taal voor SQL-systemen. Duidelijke, duidelijke aanwijzingen bieden betere instructies voor het taalmodel. Door de context te bieden waarin de gebruiker een SQL-query aanvraagt, samen met relevante details van het databaseschema, kan het model de bedoeling nauwkeurig vertalen. Het opnemen van enkele geannoteerde voorbeelden van aanwijzingen in natuurlijke taal en bijbehorende SQL-query's helpt het model bij het produceren van syntaxis-compatibele uitvoer. Bovendien verbetert de integratie van Retrieval Augmented Generation (RAG), waarbij het model tijdens de verwerking soortgelijke voorbeelden ophaalt, de nauwkeurigheid van de kaarten verder. Goed ontworpen aanwijzingen die het model voldoende instructie, context, voorbeelden en ophaalmogelijkheden geven, zijn cruciaal voor het betrouwbaar vertalen van natuurlijke taal in SQL-query's.
Het volgende is een voorbeeld van een basislijnprompt met codeweergave van de database uit de whitepaper Verbetering van de weinig tekst-naar-SQL-mogelijkheden van grote taalmodellen: een onderzoek naar snelle ontwerpstrategieën.
Zoals in dit voorbeeld wordt geïllustreerd, voorziet het op prompts gebaseerde, paar-shot-leren het model van een handvol geannoteerde voorbeelden in de prompt zelf. Dit demonstreert de doeltoewijzing tussen natuurlijke taal en SQL voor het model. Normaal gesproken bevat de prompt ongeveer 2 à 3 paren die een query in natuurlijke taal en de equivalente SQL-instructie weergeven. Deze paar voorbeelden begeleiden het model bij het genereren van syntaxis-compatibele SQL-query's uit natuurlijke taal zonder dat hiervoor uitgebreide trainingsgegevens nodig zijn.
Verfijning vs. snelle engineering
Bij het bouwen van natuurlijke taal voor SQL-systemen raken we vaak verwikkeld in de discussie of het verfijnen van het model de juiste techniek is of dat effectieve snelle engineering de beste keuze is. Beide benaderingen kunnen worden overwogen en geselecteerd op basis van de juiste reeks vereisten:
-
- Scherpstellen – Het basismodel is vooraf getraind op een groot algemeen tekstcorpus en kan het vervolgens gebruiken instructiegebaseerde verfijning, dat gelabelde voorbeelden gebruikt om de prestaties van een vooraf getraind basismodel op tekst-SQL te verbeteren. Hierdoor wordt het model aangepast aan de doeltaak. Bij fijnafstemming wordt het model rechtstreeks getraind op de eindtaak, maar zijn veel tekst-SQL-voorbeelden vereist. U kunt gecontroleerde afstemming gebruiken op basis van uw LLM om de effectiviteit van tekst-naar-SQL te verbeteren. Hiervoor kunt u verschillende datasets gebruiken, zoals Spin, WikiSQL, JACHT, BIRD-SQLof CoSQL.
- Snelle techniek – Het model is getraind om aanwijzingen te voltooien die zijn ontworpen om de doel-SQL-syntaxis te vragen. Bij het genereren van SQL uit natuurlijke taal met behulp van LLM's is het geven van duidelijke instructies in de prompt belangrijk voor het controleren van de uitvoer van het model. In de prompt kunt u verschillende componenten annoteren, zoals het verwijzen naar kolommen, een schema maken en vervolgens instrueren welk type SQL u moet maken. Deze fungeren als instructies die het model vertellen hoe de SQL-uitvoer moet worden opgemaakt. De volgende prompt toont een voorbeeld waarin u tabelkolommen aanwijst en instructies geeft om een MySQL-query te maken:
Een effectieve aanpak voor tekst-naar-SQL-modellen is om eerst te beginnen met een basis-LLM zonder enige taakspecifieke verfijning. Goed opgestelde aanwijzingen kunnen vervolgens worden gebruikt om het basismodel aan te passen en aan te sturen om de tekst-naar-SQL-toewijzing af te handelen. Dankzij deze snelle engineering kunt u de mogelijkheden ontwikkelen zonder dat u fijnafstemming hoeft uit te voeren. Als prompt-engineering op het basismodel niet voldoende nauwkeurigheid oplevert, kan verfijning van een kleine set tekst-SQL-voorbeelden worden onderzocht, samen met verdere prompt-engineering.
De combinatie van fine-tuning en snelle engineering kan nodig zijn als snelle engineering op basis van het onbewerkte, vooraf getrainde model alleen niet aan de eisen voldoet. Het is echter het beste om in eerste instantie te proberen snelle engineering uit te voeren zonder afstemming, omdat dit snelle iteratie mogelijk maakt zonder gegevensverzameling. Als dit niet voldoende prestaties oplevert, is finetuning naast snelle engineering een haalbare volgende stap. Deze algemene aanpak maximaliseert de efficiëntie, terwijl maatwerk nog steeds mogelijk is als puur op prompt gebaseerde methoden onvoldoende zijn.
Optimalisatie en best practices
Optimalisatie en best practices zijn essentieel om de effectiviteit te vergroten en ervoor te zorgen dat middelen optimaal worden ingezet en de juiste resultaten op de best mogelijke manier worden bereikt. De technieken helpen bij het verbeteren van de prestaties, het beheersen van de kosten en het bereiken van een resultaat van betere kwaliteit.
Bij het ontwikkelen van tekst-naar-SQL-systemen met behulp van LLM's kunnen optimalisatietechnieken de prestaties en efficiëntie verbeteren. Hier volgen enkele belangrijke gebieden waarmee u rekening moet houden:
- Caching – Om de latentie, kostenbeheersing en standaardisatie te verbeteren, kunt u de geparseerde SQL en herkende queryprompts van de tekst-naar-SQL LLM in de cache opslaan. Dit voorkomt het opnieuw verwerken van herhaalde zoekopdrachten.
- Monitoren – Logboeken en statistieken rond het parseren van query's, promptherkenning, het genereren van SQL en SQL-resultaten moeten worden verzameld om het tekst-naar-SQL LLM-systeem te monitoren. Dit biedt zichtbaarheid voor het optimalisatievoorbeeld waarbij de prompt wordt bijgewerkt of de afstemming opnieuw wordt uitgevoerd met een bijgewerkte gegevensset.
- Gematerialiseerde weergaven versus tabellen – Gematerialiseerde weergaven kunnen het genereren van SQL vereenvoudigen en de prestaties voor algemene tekst-naar-SQL-query’s verbeteren. Het rechtstreeks opvragen van tabellen kan resulteren in complexe SQL en ook resulteren in prestatieproblemen, waaronder het voortdurend creëren van prestatietechnieken zoals indexen. Bovendien kunt u prestatieproblemen voorkomen wanneer dezelfde tabel tegelijkertijd voor andere toepassingsgebieden wordt gebruikt.
- Gegevens vernieuwen – Gematerialiseerde weergaven moeten volgens een schema worden vernieuwd om gegevens actueel te houden voor tekst-naar-SQL-query's. U kunt batch- of incrementele vernieuwingsbenaderingen gebruiken om de overhead in evenwicht te brengen.
- Centrale datacatalogus – Het creëren van een gecentraliseerde datacatalogus biedt één overzicht van de databronnen van een organisatie en zal LLM’s helpen de juiste tabellen en schema’s te selecteren om nauwkeurigere antwoorden te geven. Vector inbedding gemaakt op basis van een centrale gegevenscatalogus, kan aan een LLM worden geleverd, samen met de gevraagde informatie om relevante en nauwkeurige SQL-antwoorden te genereren.
Door best practices voor optimalisatie toe te passen, zoals caching, monitoring, gematerialiseerde weergaven, gepland vernieuwen en een centrale catalogus, kunt u de prestaties en efficiëntie van tekst-naar-SQL-systemen met behulp van LLM's aanzienlijk verbeteren.
Architectuur patronen
Laten we eens kijken naar enkele architectuurpatronen die kunnen worden geïmplementeerd voor een tekst-naar-SQL-workflow.
Snelle techniek
Het volgende diagram illustreert de architectuur voor het genereren van query's met een LLM met behulp van prompt-engineering.
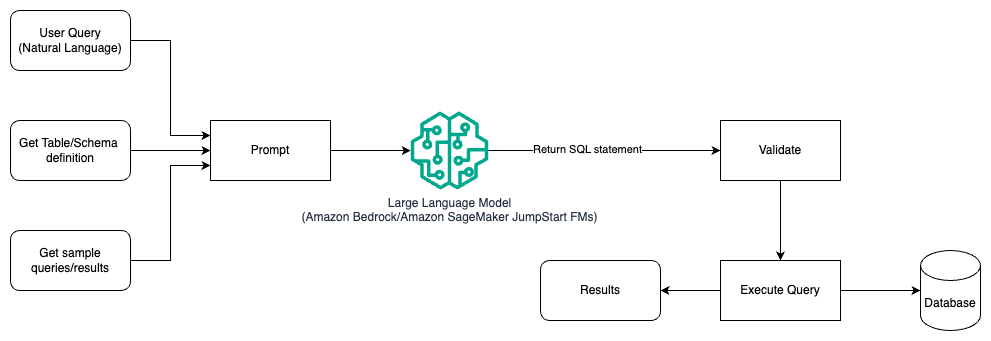
In dit patroon creëert de gebruiker op prompts gebaseerd, enkele shots-leren die het model voorzien van geannoteerde voorbeelden in de prompt zelf, die de tabel- en schemadetails en enkele voorbeeldquery's met de resultaten ervan bevatten. De LLM gebruikt de opgegeven prompt om de door AI gegenereerde SQL terug te sturen, die wordt gevalideerd en vervolgens op de database wordt uitgevoerd om de resultaten te verkrijgen. Dit is het meest eenvoudige patroon om aan de slag te gaan met behulp van snelle engineering. Hiervoor kunt u gebruiken Amazonebodem or funderingsmodellen in Amazon SageMaker JumpStart.
In dit patroon maakt de gebruiker een op prompts gebaseerd, paar-shot-leerproces dat het model voorziet van geannoteerde voorbeelden in de prompt zelf, die de tabel- en schemadetails en enkele voorbeeldquery's met de resultaten ervan bevat. De LLM gebruikt de opgegeven prompt om de door AI gegenereerde SQL terug te sturen, die wordt gevalideerd en tegen de database wordt uitgevoerd om de resultaten te verkrijgen. Dit is het meest eenvoudige patroon om aan de slag te gaan met behulp van snelle engineering. Hiervoor kunt u gebruiken Amazonebodem Dit is een volledig beheerde service die via één API een keuze biedt uit goed presterende basismodellen (FM's) van toonaangevende AI-bedrijven, samen met een breed scala aan mogelijkheden die u nodig hebt om generatieve AI-toepassingen te bouwen met beveiliging, privacy en verantwoorde AI of JumpStart Foundation-modellen dat state-of-the-art basismodellen biedt voor gebruiksscenario's zoals het schrijven van inhoud, het genereren van code, het beantwoorden van vragen, copywriting, samenvatting, classificatie, het ophalen van informatie en meer
Snelle engineering en fine-tuning
Het volgende diagram illustreert de architectuur voor het genereren van query's met een LLM met behulp van prompt-engineering en verfijning.
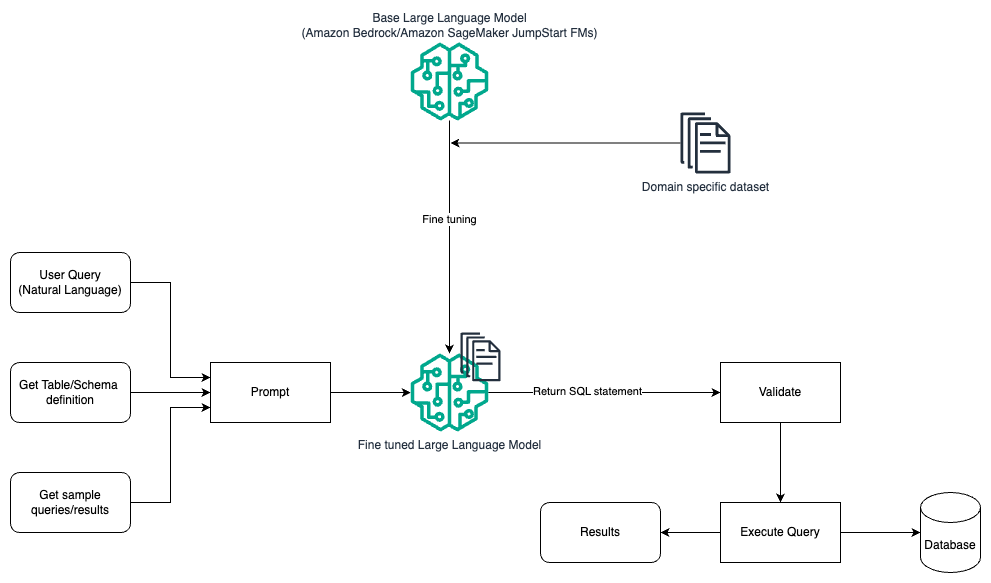
Deze stroom is vergelijkbaar met het vorige patroon, dat grotendeels afhankelijk is van snelle engineering, maar met een extra stroom van verfijning van de domeinspecifieke gegevensset. De verfijnde LLM wordt gebruikt om de SQL-query's te genereren met minimale contextwaarde voor de prompt. Hiervoor kunt u SageMaker JumpStart gebruiken om een LLM op een domeinspecifieke dataset te verfijnen, op dezelfde manier waarop u elk model zou trainen en implementeren. Amazon Sage Maker.
Snelle engineering en RAG
Het volgende diagram illustreert de architectuur voor het genereren van query's met een LLM met behulp van prompt engineering en RAG.
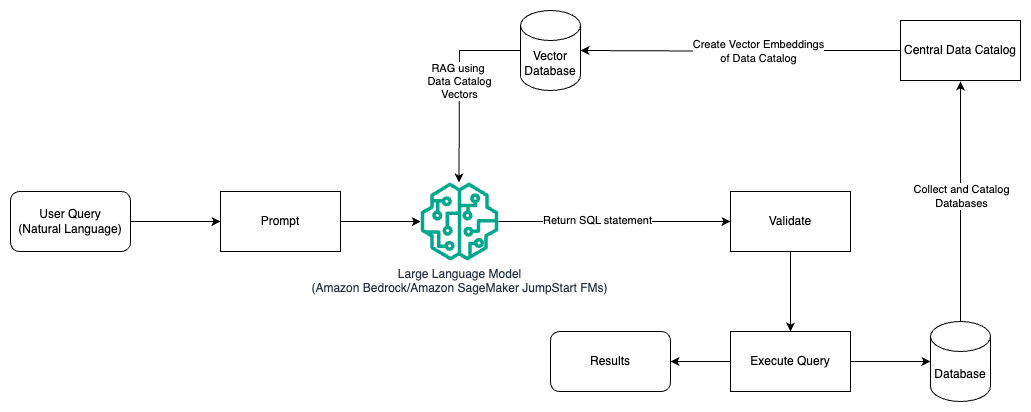
In dit patroon gebruiken we Ophalen Augmented Generation met behulp van vector-inbeddingswinkels, zoals Amazon Titan-inbedding or Cohere insluiten, On Amazonebodem vanuit een centrale datacatalogus, zoals AWS lijm Gegevenscatalogus, van databases binnen een organisatie. De vectorinsluitingen worden opgeslagen in vectordatabases zoals Vector-engine voor Amazon OpenSearch serverloos, Amazon Relational Database Service (Amazon RDS) voor PostgreSQL met de vector verlenging, of Amazon Kendra. LLM's gebruiken de vectorinbedding om sneller de juiste database, tabellen en kolommen uit tabellen te selecteren bij het maken van SQL-query's. Het gebruik van RAG is handig wanneer gegevens en relevante informatie die door LLM's moeten worden opgehaald, in meerdere afzonderlijke databasesystemen zijn opgeslagen en de LLM gegevens uit al deze verschillende systemen moet kunnen doorzoeken of opvragen. Dit is waar het aanbieden van vectorinbedding van een gecentraliseerde of uniforme datacatalogus aan de LLM's resulteert in nauwkeurigere en uitgebreidere informatie die door de LLM's wordt geretourneerd.
Conclusie
In dit bericht hebben we besproken hoe we waarde kunnen genereren uit bedrijfsgegevens met behulp van natuurlijke taal en het genereren van SQL. We hebben gekeken naar de belangrijkste componenten, optimalisatie en best practices. We leerden ook architectuurpatronen, van eenvoudige snelle engineering tot verfijning en RAG. Raadpleeg voor meer informatie Amazonebodem om eenvoudig generatieve AI-applicaties te bouwen en te schalen met basismodellen
Over de auteurs
 Randy DeFauw is Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE van de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft verschillende functies bekleed in de technologiesector, variërend van software-engineering tot productbeheer. In betrad de Big Data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten in de ML-ruimte en heeft op tal van conferenties gepresenteerd, waaronder Strata en GlueCon.
Randy DeFauw is Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE van de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft verschillende functies bekleed in de technologiesector, variërend van software-engineering tot productbeheer. In betrad de Big Data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten in de ML-ruimte en heeft op tal van conferenties gepresenteerd, waaronder Strata en GlueCon.
 Nitin Eusebius is een Sr. Enterprise Solutions Architect bij AWS, met ervaring in Software Engineering, Enterprise Architecture en AI/ML. Hij is zeer gepassioneerd over het verkennen van de mogelijkheden van generatieve AI. Hij werkt samen met klanten om hen te helpen goed ontworpen applicaties op het AWS-platform te bouwen, en is toegewijd aan het oplossen van technologische uitdagingen en het assisteren bij hun cloudreis.
Nitin Eusebius is een Sr. Enterprise Solutions Architect bij AWS, met ervaring in Software Engineering, Enterprise Architecture en AI/ML. Hij is zeer gepassioneerd over het verkennen van de mogelijkheden van generatieve AI. Hij werkt samen met klanten om hen te helpen goed ontworpen applicaties op het AWS-platform te bouwen, en is toegewijd aan het oplossen van technologische uitdagingen en het assisteren bij hun cloudreis.
 Arghya Banerjee is een Sr. Solutions Architect bij AWS in de San Francisco Bay Area, gericht op het helpen van klanten bij het adopteren en gebruiken van AWS Cloud. Arghya richt zich op Big Data, Data Lakes, Streaming, Batch Analytics en AI/ML-diensten en -technologieën.
Arghya Banerjee is een Sr. Solutions Architect bij AWS in de San Francisco Bay Area, gericht op het helpen van klanten bij het adopteren en gebruiken van AWS Cloud. Arghya richt zich op Big Data, Data Lakes, Streaming, Batch Analytics en AI/ML-diensten en -technologieën.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

