Wat is RAG?
Hier is de eenvoudige definitie van 30 seconden. Een diepere duik zal volgen.
RAG (Retrieval Augmented Generation) is momenteel het meest gebruikte woord op de GenAI, meer jargon om niet-ingewijden te verwarren.
RAG staat voor Retrieval Augmented Generation. Het betekent simpelweg dat u kennis kunt toepassen en OPHALEN ten overstaan van de LLM, om uw LLM-prompt en de reactie daarop te VERGROTEN. Op deze manier kunt u vangrails (meer jargon) helpen bieden tegen verouderde antwoorden en uw zakelijke (private) kennisarchief veilig inzetten.
Wat is het probleem dat RAG oplost?
De grote taalmodellen – of basismodellen (ja, er is een verschil. Basismodellen omvatten taalmodellen maar ook andere soorten modellen, bijvoorbeeld beeldspraak) zijn ‘vooraf getraind’, wat sommigen prachtig omschrijven als stochastische papegaaien. Denk ‘vooraf getraind’ in GPT, het model dat ChatGPT aandrijft – GPT staat voor “Generative Pre-trained Transformer. Voorgetraind betekent statische, moment-in-time training. Dat is de reden dat als je het model vraagt: “tegen welke prijs wordt aandelen X verhandeld?”, het het niet zal weten, omdat de informatie te nieuw is, en erger nog, het model misschien niet weet wat het niet weet, zodat het in het ergste geval zal hallucineren. Nu ga ik een punt uitwerken – ChatGPT zal u vertellen dat het de laatste prijs niet kent – het is getraind om te weten dat de gevraagde informatie te direct is en het zal u vertellen een andere manier te vinden. Het punt is echter dat filosofisch gesproken LLM's geen epistemologische grenzen kennen. Er zijn veel gevallen waarin ze niet weten wat ze niet weten. Met RAG kunt u uw grenzen om de ontbrekende LLM-grenzen heen leggen.
Wat betreft jargon rond mens/tech-interfaces en bewustzijn, vind ik ‘kennisopslag’ een bijzonder interessante term die steeds vaker wordt gebruikt in GenAI-gesprekken. Het betekent feitelijk een technische database of een vectoropslag, hoogstwaarschijnlijk een ‘vectordatabase’, maar let op hoe de term de mensheid – kennis, kennis in een winkel, zoals de winkels waarover je leest in de horrorromans van Stephen King – probeert te brengen naar een geautomatiseerde technische constructie. Marketing en subjectieve semantiek in een notendop.
Waar is die diepere duik die je beloofde?
Hier is een diagram van RAG.
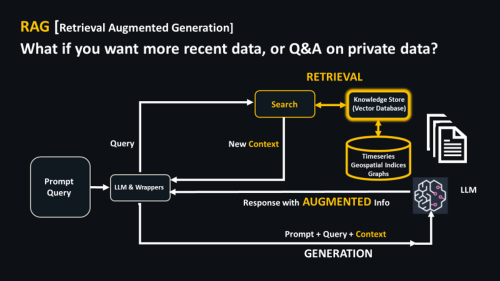
Let op het opeenvolgende proces, van boven naar beneden, in het diagram. Er zijn twee belangrijke onderdelen.
- OPHALEN: Zet een kenniswinkel met zoekfunctie (een soort vectordatabase of winkel) voor de LLM. Wanneer u een vraag stelt, helpt de vectordatabase vast te stellen of deze relevante informatie bevat, bijvoorbeeld actuele financiële informatie die de LLM waarschijnlijk niet zal hebben.
- Dit informeert een prompt die VERGROOT aanvullende VectorDB/Knowledge Store-informatie, dat stukje van uw onderneming of het nieuwe stukje informatie dat de LLM niet kent. In combinatie met de “kennis” van de LLM, uitgebreide inhoud
GENERATION wordt teruggegeven.
Waarom nu?
En die volgorde verklaart een beetje waarom het zo druk is. De term RAG is ontstaan rond 2020, denk ik
dit artikel van Lewis et al. Tot ongeveer drie maanden geleden maakte het echter geen deel uit van het lexicon, zeker niet zoals dat nu het geval is. Mijn Google AdWords-dashboard laat een stijging van 900% zien over de afgelopen 3 maanden en 9900% over 3 jaar. Wat waarschijnlijk de aanstichter is, zijn een paar belangrijke tools in de kringen van GenAI-ontwikkelaars, namelijk de zeer populaire LangChain en de opkomst LamaIndex. Voor degenen onder u met een softwareachtergrond: beschouw deze als VS Code voor GenAI. Met name bij LangChain verklaart de productnaam het “waarom nu”, specifiek de “Chain” van LangChain (terwijl Lang = Taal). Gezien het eerder beschreven sequentiële ketenachtige karakter van RAG, past RAG prachtig in de ontwikkelaarstools.
Waar wordt RAG ingezet en hoe wordt het ingezet?
Zoals beschreven overwint het een aantal behoorlijk fundamentele beperkingen van LLM's en basismodellen, waardoor het vrij alomtegenwoordig toepasbaar is. Het heeft echter al impact in sectoren:
- gedreven door tijd en realtime – denk aan de kapitaalmarkten
- gereguleerd, omdat ze niet fout kunnen gaan en controles op de respons nodig hebben, zal ik het woord 'vangrails' gebruiken voor bedrijfsprocessen die grotendeels publiekelijk zijn en risico's met zich meebrengen. Denk aan juridische diensten, overheidsaanvragen (het Amerikaanse Ministerie van Defensie heeft al documenten en presentaties geproduceerd), mogelijk gezondheidszorg.
- waarvoor (actuele) bedrijfskennis nodig is – dat is in werkelijkheid vrijwel alles, maar denk bijvoorbeeld aan retail en e-commerce.
Overal waar alle drie de vereisten samenkomen, denk aan de juridische dienstverlening die up-to-date contracten beheert in een gereguleerde financiële dienstverleningssector, en dat is jouw goede plek.
Dit is ook waar, zo vertellen gerenommeerde bronnen mij, al implementaties van RAG-infrastructuren, samenvattingen van contracten, samenvattingen van rapporten en gerelateerde chatbot-activiteiten plaatsvinden. Ik heb ergens anders voor gepleit
“gouden” gebruiksscenario’s
hier en hoe u deze krachtig en vasthoudend kunt inzetten hier. Deze gouden gebruiksscenario's combineren doorgaans generatieve AI en discriminerende AI, waarbij 'discriminerend' in de laatste zin de AI betekent die al jaren wordt gebruikt, bijvoorbeeld de machine learning die uw creditcardbeoordeling bepaalt en die identificeert wanneer uw kredietverstrekker u belt met een vermoeden rond frauduleus gebruik van uw kaart. Mijn ervaring is dat deze fraudetelefoontjes meestal de telefoontjes zijn die je op zaterdag- of zondagochtend krijgt als je naar een nieuwe bestemming in het buitenland reist. Er wordt aan dergelijke gouden gebruiksscenario's gewerkt en deze zullen binnenkort ergens bij u in de buurt terechtkomen, de eerste eenvoudigweg met chatinterfaces rond traditionele problemen, en op meer geavanceerde wijze met incrementele analyses die worden ingezet via beide soorten AI.
Welke hulpmiddelen heb ik nodig voor RAG?
RAG is de nieuwe voornaamste reden voor het inzetten van een vectordatabase, een opslagplaats van doorzoekbare kennis in vectorvorm. Vectoren bestaan al jaren, zowel wiskundige vectoren (afstandsmetingen) als vectoren-als-arrays-van-getallen (denk aan een dagelijkse tijdreeks van een voorraad). Denk bij zoeken aan die brute force zoekmethoden die je al jaren gebruikt, als je bijvoorbeeld in Google zoekt. Zoekalgoritmen werden gepopulariseerd door de
Apache Lucene-bibliotheek, vaak geïmplementeerd in tools als Elasticsearch en Solr, en ze vinden
een nieuw leven ingeblazen in combinatie met de vectordatabases of vectorwinkels.
Ik gebruik de term vectorwinkels omdat het in sommige gevallen geen vectordatabase hoeft te zijn. Vectoren kunnen worden opgeslagen in elke toepasselijke wiskundige programmeertaal op hoog niveau die met geheugen omgaat en relatief goed zoeken kan inzetten (beter, zouden sommigen zeggen). Dat omvat bijvoorbeeld Python/NumPy/Pandas, Julia, MATLAB, q of R. Ik was vorige week aan het bellen en iemand zinspeelde op hun zelfgemaakte Pandas-vectorwinkel, geen applicatie op industriële schaal, maar iets om een project op gang te brengen voordat je naar een vectordatabase migreert.
Ik wacht al een tijdje op het Python-gedoe, en om er zeker van te zijn dat GenAI Pythonic is (zie bijvoorbeeld de LangChain-link hierboven). De leveranciers en voorstanders van numerieke programmering zijn beleefd stil geweest, terwijl elke dataleverancier van de daken heeft geschreeuwd: “we zijn een vectordatabase”. Rockset kondigde vorige week op hun Indexconferentie aan dat ze nu een vectordatabase zijn en naast Rockset begint de schare multimodale databases – Datastax (Cassandra), KDB.AI, de grafische databases, Redis Labs – nu het aantal gespecialiseerde nieuwe vectordatabases te overtreffen kinderen – Qdrant, Pinecone, Weaviate. Voor mij zou de manier waarop MathWorks, JuliaHub en Anaconda deze markt benaderen de volgende generatie van deze industrie kunnen bepalen. Het is veel gemakkelijker om op zijn minst aan de slag te gaan met een standaard, multifunctioneel vectorvriendelijk wiskundig hulpmiddel dat elke datawetenschapper kent, en vervolgens te migreren naar een volwaardige krachtpatser voor vectordatabases.
Verdient RAG de hype?
De meeste mensen die ik spreek, zelfs degenen die doorgaans sceptisch staan tegenover jargon, krijgen RAG. Het is een eenvoudige, standaardmanier om ondernemings- en up-to-date controle te krijgen over funderingsmodelprompts. Ik vermoed dat het niet snel zal verdwijnen.
Ik begin echter gevallen te zien waarin bedrijven uit Silicon Valley de uitdrukking ‘reduceren tot RAG’ gebruikten, of ‘machine learning-problemen reduceren tot een zoekprobleem’. Het is bijna te verleidelijk om van alles en nog wat in een GenAI-zoekproces van het RAG/foundation-model te gooien, maar er zijn gevallen waarin traditionele AI het beter doet. De blogosfeer praat hier niet over, maar ik zag leiders van drie hightech leiders in Silicon Valley dit de afgelopen week bespreken. Waar Silicon Valley op het circuit discussieert, discussiëren de bankleiders privé, weg van nieuwsgierige ogen en oren zoals de mijne. Het is een van de redenen waarom onderscheidende AI, waar ik eerder op doelde, van belang is. Infrastructuren die beide toepassen, zullen meer gebruiksscenario's dienen dan infrastructuren die brute force RAG inzetten. Het traditionele machine learning is nog lang niet klaar.
Ik heb ook gehoord dat de allergrootste bedrijven hun eigen LLM's en basismodellen zullen behouden om het ondernemings-, tijd- en privacyprobleem te omzeilen. dus modelleren en trainen is ook nog niet klaar. Dit is de reden waarom Databricks Mozaïek heeft gekocht, zo blijkt. Het AWS-werk met Bedrock en open source foundation-modellen is ook interessant. Het lijkt erop dat datawetenschappers een deel van het werk dat hen bezig hield voordat BigCorp de grootste modellen voor ons trainde, zullen kunnen overnemen. Met andere woorden: sommige delen van de RAG-inspanningen kunnen worden overtroffen door de modelontwikkeling bij de grootste bedrijven, maar ik vermoed dat dit slechts een gedeeltelijke tegenslag zal zijn.
Ten slotte kent ook RAG grenzen. Veel voorkomende uitdagingen zijn onder meer:
- met een performante gelijkeniszoekfunctie,
- de mogelijkheid om documenten toe te voegen/verwijderen
- het garanderen van de waarheidsgetrouwheid en actualiteit – of nieuwheid – van gegevens
- het op een optimale manier integreren van belangrijke gegevenstypen, bijvoorbeeld tijdreeksen, (relationeel) gerichte grafiekinformatie (degenen onder ons in gevectoriseerde tijdreeksen en grafiekecosystemen zijn positief; het is een kans)
Maar er ontstaan ook nieuwe uitdagingen, vooral op het gebied van prestaties en rekenkracht. Bijvoorbeeld:
- documenten opsplitsen voordat ze worden ingevoerd in vectordatabases (waar documenten nodig zijn)
- het retourneren van geschikte “diverse” brokken (het verlichten van het stochastische papegaaienprobleem)
- opeenvolgende query's uitvoeren, ketenen
- inbeddingsfuncties kunnen veranderen; hoe beheer je veranderingen zonder alle input opnieuw in te sluiten.
- De
ecologische (en geopolitieke) gevolgen over, nou ja, alles wat te maken heeft met verbluffend grote computervereisten.
In Conclusie
RAG is, net als veel van het GenAI-technobabbel, jargon. Het laat echter op een verstandige en duidelijke manier zien hoe je een niveau van controle kunt toevoegen, oftewel
terugvinden nuttige informatie, naar vergroten en
voortbrengen LLM/Foundation-modelprompts en uitvoer. Ecosystemen en gereedschappen ontwikkelen en evolueren snel rond de nomenclatuur.
Het is echter nog vroeg. Wat zal over drie maanden de buzzterm zijn?
Ik vermoed dat we een stroom van milieubewustzijn in de sector zullen zien verschijnen naarmate de gevolgen van grote reken- en consumptiemodellen, en mogelijk een paar internationale conflicten, werkelijkheid worden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.finextra.com/blogposting/25150/from-rag-to-riches-in-a-genai-world-some-jargon-explainers-amp-current-trends?utm_medium=rssfinextra&utm_source=finextrablogs

