Grote Taalmodellen (LLM's) hebben een revolutie teweeggebracht op het gebied van natuurlijke taalverwerking (NLP), waardoor taken als taalvertaling, tekstsamenvatting en sentimentanalyse zijn verbeterd. Naarmate deze modellen echter in omvang en complexiteit blijven groeien, is het monitoren van hun prestaties en gedrag steeds uitdagender geworden.
Het monitoren van de prestaties en het gedrag van LLM's is een cruciale taak om hun veiligheid en effectiviteit te garanderen. Onze voorgestelde architectuur biedt een schaalbare en aanpasbare oplossing voor online LLM-monitoring, waardoor teams uw monitoringoplossing kunnen afstemmen op uw specifieke gebruiksscenario's en vereisten. Door gebruik te maken van AWS-services biedt onze architectuur realtime inzicht in het LLM-gedrag en stelt teams in staat eventuele problemen of afwijkingen snel te identificeren en aan te pakken.
In dit bericht demonstreren we enkele statistieken voor online LLM-monitoring en hun respectieve architectuur voor schaal met behulp van AWS-services zoals Amazon Cloud Watch en AWS Lambda. Dit biedt een aanpasbare oplossing die verder gaat dan mogelijk is model evaluatie banen mee Amazonebodem.
Overzicht van de oplossing
Het eerste dat u moet overwegen, is dat verschillende metrieken verschillende berekeningsoverwegingen vereisen. Een modulaire architectuur, waarbij elke module modelinferentiegegevens kan opnemen en zijn eigen metrieken kan produceren, is noodzakelijk.
We stellen voor dat elke module binnenkomende inferentieverzoeken doorgeeft aan de LLM, waarbij prompt- en voltooiingsparen (antwoord) worden doorgegeven aan metrische rekenmodules. Elke module is verantwoordelijk voor het berekenen van zijn eigen statistieken met betrekking tot de invoerprompt en voltooiing (reactie). Deze statistieken worden doorgegeven aan CloudWatch, die ze kan samenvoegen en kan samenwerken met CloudWatch-alarmen om meldingen over specifieke omstandigheden te verzenden. Het volgende diagram illustreert deze architectuur.
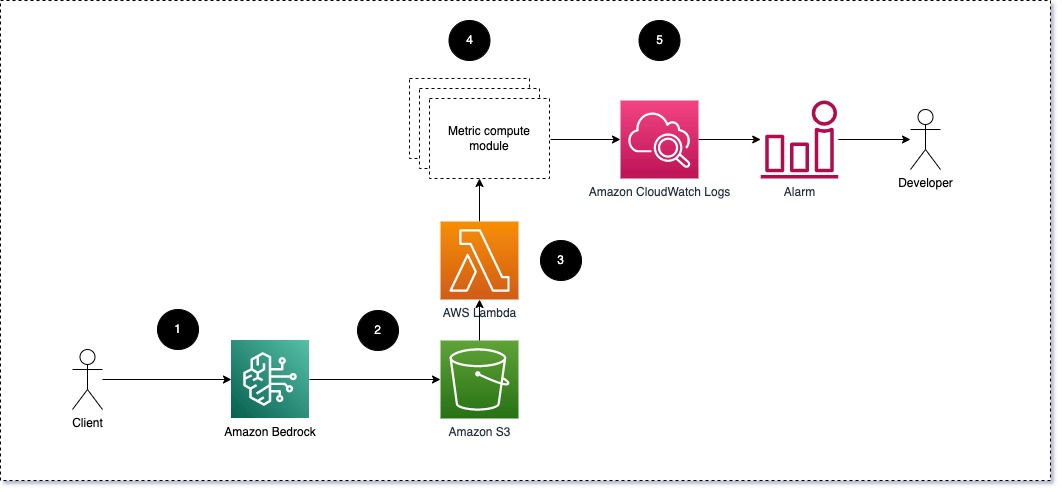
Fig. 1: Metrische rekenmodule – oplossingsoverzicht
De workflow omvat de volgende stappen:
- Een gebruiker dient een verzoek in bij Amazon Bedrock als onderdeel van een applicatie of gebruikersinterface.
- Amazon Bedrock slaat het verzoek en de voltooiing (antwoord) op in Amazon eenvoudige opslagservice (Amazon S3) volgens de configuratie van loggen van aanroepen.
- Het bestand dat is opgeslagen op Amazon S3 creëert een gebeurtenis die triggers een Lambda-functie. De functie roept de modules aan.
- De modules posten hun respectievelijke statistieken CloudWatch-statistieken.
- Alarm kan het ontwikkelteam op de hoogte stellen van onverwachte metrische waarden.
Het tweede waar u rekening mee moet houden bij het implementeren van LLM-monitoring is het kiezen van de juiste statistieken om bij te houden. Hoewel er veel potentiële statistieken zijn die u kunt gebruiken om de LLM-prestaties te monitoren, leggen we in dit bericht enkele van de breedste uit.
In de volgende secties belichten we enkele van de relevante modulestatistieken en hun respectieve metrische rekenmodulearchitectuur.
Semantische gelijkenis tussen prompt en voltooiing (antwoord)
Wanneer u LLM's uitvoert, kunt u de prompt en de voltooiing (reactie) voor elk verzoek onderscheppen en deze omzetten in insluitingen met behulp van een insluitingsmodel. Inbeddingen zijn hoogdimensionale vectoren die de semantische betekenis van de tekst weergeven. Amazone Titan levert dergelijke modellen via Titan Embeddings. Door een afstand zoals de cosinus tussen deze twee vectoren te nemen, kunt u kwantificeren hoe semantisch vergelijkbaar de prompt en de voltooiing (reactie) zijn. Je kunt gebruiken scipy or scikit-leren om de cosinusafstand tussen vectoren te berekenen. Het volgende diagram illustreert de architectuur van deze metrische rekenmodule.
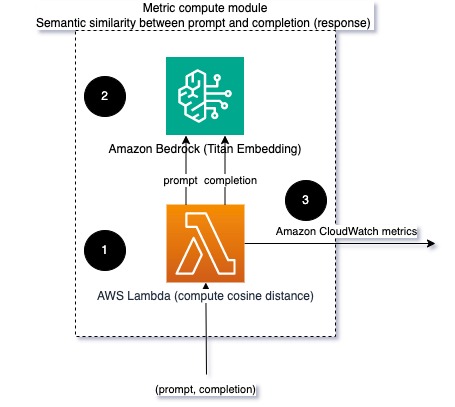
Figuur 2: Metrische rekenmodule – semantische gelijkenis
Deze workflow omvat de volgende belangrijke stappen:
- Een Lambda-functie ontvangt een gestreamd bericht via Amazon Kinesis met een prompt- en voltooiingspaar (antwoord).
- De functie krijgt een inbedding voor zowel de prompt als de voltooiing (reactie) en berekent de cosinusafstand tussen de twee vectoren.
- De functie verzendt die informatie naar CloudWatch-statistieken.
Sentiment en toxiciteit
Door het sentiment te monitoren, kunt u de algehele toon en emotionele impact van de reacties meten, terwijl toxiciteitsanalyse een belangrijke maatstaf is voor de aanwezigheid van aanstootgevend, respectloos of schadelijk taalgebruik in LLM-uitvoer. Eventuele verschuivingen in het sentiment of de toxiciteit moeten nauwlettend in de gaten worden gehouden om er zeker van te zijn dat het model zich gedraagt zoals verwacht. Het volgende diagram illustreert de metrische rekenmodule.

Figuur 3: Metrische rekenmodule – sentiment en toxiciteit
De workflow omvat de volgende stappen:
- Een Lambda-functie ontvangt een prompt- en voltooiingspaar (antwoord) via Amazon Kinesis.
- Via AWS Step Functions-orkestratie roept de functie aan Amazon begrijpt het om het te detecteren sentiment en toxiciteit.
- De functie slaat de informatie op in CloudWatch-statistieken.
Voor meer informatie over het detecteren van sentiment en toxiciteit met Amazon Comprehend raadpleegt u Bouw een robuuste op tekst gebaseerde toxiciteitsvoorspeller en Markeer schadelijke inhoud met behulp van Amazon Comprehend-toxiciteitsdetectie.
Verhouding van weigeringen
Een toename van het aantal weigeringen, bijvoorbeeld wanneer een LLM de voltooiing ontkent vanwege een gebrek aan informatie, zou kunnen betekenen dat kwaadwillende gebruikers de LLM proberen te gebruiken op een manier die bedoeld is om deze te jailbreaken, of dat niet aan de verwachtingen van gebruikers wordt voldaan en zij krijgen reacties van lage waarde. Eén manier om te peilen hoe vaak dit gebeurt, is door standaardweigeringen van het gebruikte LLM-model te vergelijken met de daadwerkelijke antwoorden van de LLM. Hieronder volgen bijvoorbeeld enkele veel voorkomende weigeringszinnen van Claude v2 LLM van Anthropic:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Bij een vaste reeks aanwijzingen kan een toename van deze weigeringen een signaal zijn dat het model te voorzichtig of gevoelig is geworden. Het omgekeerde geval moet ook worden geëvalueerd. Het zou een signaal kunnen zijn dat het model nu meer geneigd is om giftige of schadelijke gesprekken aan te gaan.
Om de integriteit en de modelweigeringsratio te helpen modelleren, kunnen we het antwoord vergelijken met een reeks bekende weigeringszinnen uit de LLM. Dit zou een feitelijke classificatie kunnen zijn die kan verklaren waarom het model het verzoek heeft afgewezen. U kunt de cosinusafstand nemen tussen het antwoord en bekende weigeringsreacties van het model dat wordt bewaakt. Het volgende diagram illustreert deze metrische rekenmodule.
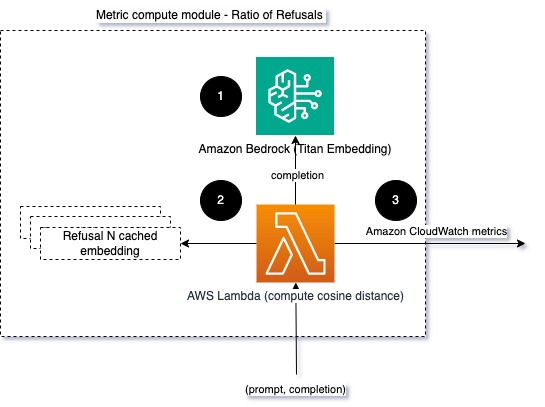
Figuur 4: Metrische rekenmodule – verhouding van weigeringen
De workflow bestaat uit de volgende stappen:
- Een Lambda-functie ontvangt een prompt en voltooiing (antwoord) en krijgt een insluiting van het antwoord met behulp van Amazon Titan.
- De functie berekent de cosinus- of euclidische afstand tussen het antwoord en bestaande weigeringsprompts die in het geheugen zijn opgeslagen.
- De functie verzendt dat gemiddelde naar CloudWatch-statistieken.
Een andere optie is om te gebruiken vage matching voor een eenvoudige maar minder krachtige aanpak om de bekende weigeringen te vergelijken met de LLM-output. Verwijs naar de Python-documentatie bijvoorbeeld.
Samengevat
Waarneembaarheid van LLM's is een cruciale praktijk om het betrouwbare en betrouwbare gebruik van LLM's te garanderen. Het monitoren, begrijpen en garanderen van de nauwkeurigheid en betrouwbaarheid van LLM's kan u helpen de risico's die aan deze AI-modellen zijn verbonden te beperken. Door hallucinaties, slechte voltooiingen (reacties) en aanwijzingen in de gaten te houden, kunt u ervoor zorgen dat uw LLM op koers blijft en de waarde levert waarnaar u en uw gebruikers op zoek zijn. In dit bericht hebben we een aantal statistieken besproken om voorbeelden te laten zien.
Voor meer informatie over het evalueren van funderingsmodellen, zie Gebruik SageMaker Clarify om funderingsmodellen te evaluerenen blader door extra voorbeeld notitieboekjes beschikbaar in onze GitHub-repository. U kunt ook manieren verkennen om LLM-evaluaties op schaal te implementeren Operationaliseer LLM-evaluatie op schaal met behulp van Amazon SageMaker Clarify- en MLOps-services. Tenslotte adviseren wij u te verwijzen naar Evalueer grote taalmodellen op kwaliteit en verantwoordelijkheid voor meer informatie over het evalueren van LLM's.
Over de auteurs
 Bruno Klein is een Senior Machine Learning Engineer met AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van big data- en analytics-oplossingen. Buiten zijn werk brengt hij graag tijd door met zijn gezin, reist hij graag en probeert hij graag nieuwe gerechten.
Bruno Klein is een Senior Machine Learning Engineer met AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van big data- en analytics-oplossingen. Buiten zijn werk brengt hij graag tijd door met zijn gezin, reist hij graag en probeert hij graag nieuwe gerechten.
 Rushab Lokhande is een Senior Data & ML Engineer met AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van big data-, machine learning- en analytics-oplossingen. Buiten zijn werk brengt hij graag tijd door met zijn gezin, lezen, hardlopen en golfen.
Rushab Lokhande is een Senior Data & ML Engineer met AWS Professional Services Analytics Practice. Hij helpt klanten bij het implementeren van big data-, machine learning- en analytics-oplossingen. Buiten zijn werk brengt hij graag tijd door met zijn gezin, lezen, hardlopen en golfen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

