Afbeelding door auteur
Het gebruik van Scikit-learn-pijplijnen kan uw voorverwerkings- en modelleringsstappen vereenvoudigen, de complexiteit van de code verminderen, consistentie in de voorverwerking van gegevens garanderen, helpen bij het afstemmen van hyperparameters en uw workflow overzichtelijker en gemakkelijker te onderhouden maken. Door meerdere transformaties en het uiteindelijke model in één entiteit te integreren, verbeteren Pipelines de reproduceerbaarheid en maken ze alles efficiënter.
In deze tutorial gaan we werken met de Bankverloop dataset van Kaggle om een Random Forest Classifier te trainen. We zullen de conventionele aanpak van datavoorverwerking en modeltraining vergelijken met een efficiëntere methode met behulp van Scikit-learn-pijplijnen en ColumnTransformers.
In de pijplijn voor gegevensverwerking zullen we leren hoe we zowel categorische als numerieke kolommen afzonderlijk kunnen transformeren. We beginnen met een traditionele codestijl en laten vervolgens een betere manier zien om soortgelijke verwerking uit te voeren.
Na het extraheren van de gegevens uit het zipbestand laadt u het `train.csv` bestand met “id” als indexkolom. Verwijder overbodige kolommen en schud de dataset.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
bank_df.head()
We hebben categorische, integer- en float-kolommen. De dataset ziet er redelijk schoon uit.

Eenvoudige Scikit-leercode
Als datawetenschapper heb ik deze code meerdere keren geschreven. Ons doel is om de ontbrekende waarden voor zowel categorische als numerieke kenmerken in te vullen. Om dit te bereiken zullen we een `SimpleImputer` gebruiken met verschillende strategieën voor elk type feature.
Nadat de ontbrekende waarden zijn ingevuld, zullen we categorische kenmerken converteren naar gehele getallen en min-max-schaling toepassen op numerieke kenmerken.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
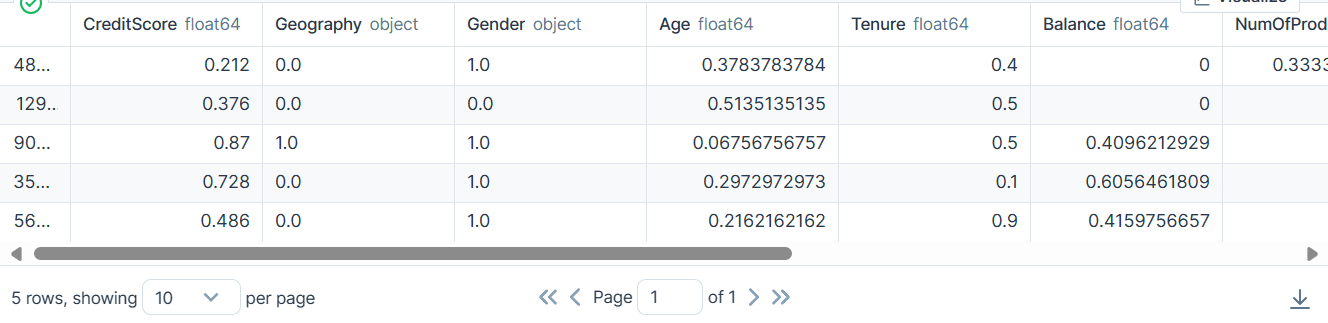
bank_df.head()
Als resultaat hebben we een dataset gekregen die schoon is en getransformeerd met alleen integer- of float-waarden.
Scikit-learn Pipelines-code
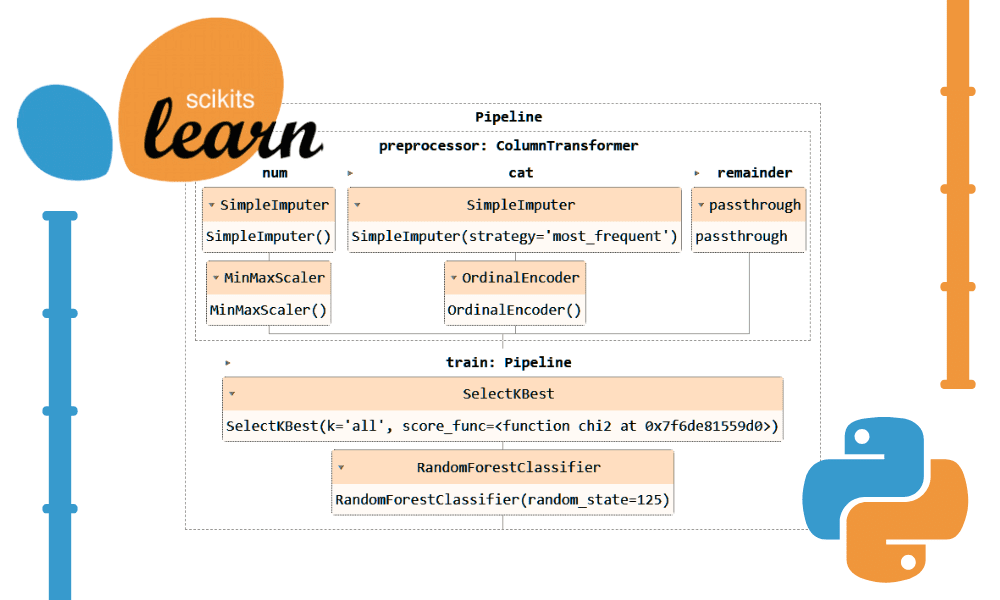
Laten we de bovenstaande code converteren met behulp van de `Pipeline` en `ColumnTransformer`. In plaats van de voorbewerkingstechniek toe te passen, zullen we twee pijpleidingen creëren. Eén is voor numerieke kolommen en één is voor categorische kolommen.
- In de numerieke pijplijn hebben we een eenvoudige impute met een ‘gemiddelde’ strategie gebruikt en een min-max scaler toegepast voor normalisatie.
- In de categorische pijplijn hebben we de eenvoudige imputer met de ‘most_frequent’-strategie en de oorspronkelijke encoder gebruikt om de categorieën om te zetten in numerieke waarden.
We hebben de twee pijplijnen gecombineerd met behulp van de ColumnTransformer en elk voorzien van de kolommenindex. Het zal u helpen deze pijpleidingen op bepaalde kolommen toe te passen. Een categorische transformatorpijplijn wordt bijvoorbeeld alleen op de kolommen 1 en 2 toegepast.
Opmerking: de rest=”passthrough” betekent dat de kolommen die nog niet zijn verwerkt uiteindelijk worden toegevoegd. In ons geval is dit de doelkolom.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Na de transformatie bevat de resulterende array een numerieke transformatiewaarde aan het begin en een categorische transformatiewaarde aan het einde, gebaseerd op de volgorde van de pijpleidingen in de kolomtransformator.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
U kunt het pijplijnobject uitvoeren in het Jupyter Notebook om de pijplijn te visualiseren. Zorg ervoor dat je de nieuwste versie van Scikit-learn hebt.
preproc_pipe

Om ons model te trainen en te evalueren, moeten we onze dataset in twee subsets opsplitsen: training en testen.
Om dit te doen, zullen we eerst afhankelijke en onafhankelijke variabelen creëren en deze omzetten in NumPy-arrays. Vervolgens zullen we de functie `train_test_split` gebruiken om de dataset in twee subsets te splitsen.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Eenvoudige Scikit-leercode
De conventionele manier om trainingscode te schrijven is om eerst een functieselectie uit te voeren met behulp van 'SelectKBest' en vervolgens de nieuwe functie aan ons Random Forest Classifier-model toe te voegen.
We zullen eerst het model trainen met behulp van de trainingsset en de resultaten evalueren met behulp van de testdataset.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
We behaalden een redelijk goede nauwkeurigheidsscore.
0.8613035487063481Scikit-learn Pipelines-code
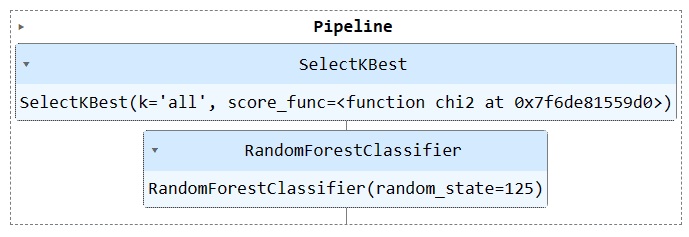
Laten we de functie `Pipeline` gebruiken om beide trainingsstappen in een pijplijn te combineren. Vervolgens passen we het model op de trainingsset en evalueren we het op de testset.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
We hebben vergelijkbare resultaten bereikt, maar de code lijkt efficiënter en eenvoudiger te zijn. Het is vrij eenvoudig om nieuwe stappen toe te voegen aan of te verwijderen uit de trainingspijplijn.
0.8613035487063481
Voer het pijplijnobject uit om de pijplijn te visualiseren.
train_pipe
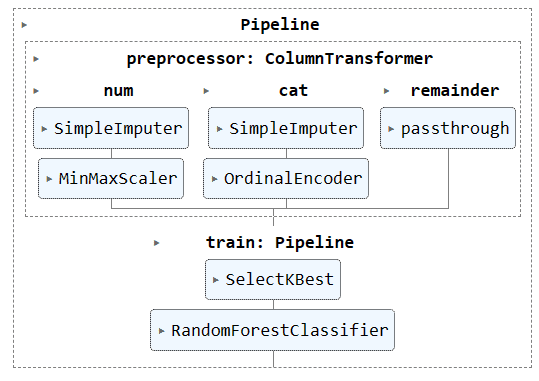
Nu gaan we zowel de voorbewerkings- als de trainingspijplijn combineren door een nieuwe pijplijn te maken en beide pijplijnen toe te voegen.
Hier is de volledige code:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Output:
0.8592837955201874
Visualisatie van de volledige pijplijn.
complete_pipe

Een van de grote voordelen van het gebruik van pijplijnen is dat u de pijplijn met het model kunt opslaan. Tijdens de inferentie hoeft u alleen het pijplijnobject te laden, dat klaar is om de onbewerkte gegevens te verwerken en u nauwkeurige voorspellingen te geven. U hoeft de verwerkings- en transformatiefuncties in het app-bestand niet opnieuw te schrijven, omdat dit kant-en-klaar werkt. Dit maakt de machine learning-workflow efficiënter en bespaart tijd.
Laten we eerst de pijplijn opslaan met behulp van de skops-dev/skops bibliotheek.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Laad vervolgens de opgeslagen pijplijn en geef de pijplijn weer.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Zoals we kunnen zien, hebben we de pijpleiding met succes geladen.
Om onze geladen pijplijn te evalueren, zullen we voorspellingen doen op de testset en vervolgens de nauwkeurigheid en F1-scores berekenen.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
Het blijkt dat we ons moeten concentreren op minderheidsklassen om onze F1-score te verbeteren.
Accuracy: 86.0% F1: 0.76
De projectbestanden en code zijn beschikbaar op Deepnote-werkruimte. De werkruimte heeft twee notebooks: één met de Scikit-learn-pijplijn en één zonder.
In deze zelfstudie hebben we geleerd hoe Scikit-learn-pijplijnen kunnen helpen bij het stroomlijnen van machine learning-workflows door reeksen gegevenstransformaties en modellen aan elkaar te koppelen. Door voorverwerking en modeltraining te combineren in één Pipeline-object kunnen we code vereenvoudigen, consistente datatransformaties garanderen en onze workflows beter georganiseerd en reproduceerbaar maken.
Abid Ali Awan (@1abidaliawan) is een gecertificeerde datawetenschapper-professional die dol is op het bouwen van machine learning-modellen. Momenteel richt hij zich op het creëren van content en het schrijven van technische blogs over machine learning en data science-technologieën. Abid heeft een Master in Technologie Management en een Bachelor in Telecommunicatie Engineering. Zijn visie is om een AI-product te bouwen met behulp van een grafisch neuraal netwerk voor studenten die worstelen met een psychische aandoening.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

