ZOO Digital biedt end-to-end lokalisatie- en mediadiensten om originele tv- en filminhoud aan te passen aan verschillende talen, regio's en culturen. Het maakt de mondialisering gemakkelijker voor de beste makers van inhoud ter wereld. ZOO Digital wordt vertrouwd door de grootste namen op het gebied van entertainment en levert lokalisatie- en mediadiensten van hoge kwaliteit op grote schaal, inclusief nasynchronisatie, ondertiteling, scripting en compliance.
Typische lokalisatieworkflows vereisen handmatige sprekerdiarisatie, waarbij een audiostream wordt gesegmenteerd op basis van de identiteit van de spreker. Dit tijdrovende proces moet worden voltooid voordat de inhoud in een andere taal kan worden nagesynchroniseerd. Met handmatige methoden kan het lokaliseren van een episode van 30 minuten tussen de 1 en 3 uur duren. Door middel van automatisering streeft ZOO Digital ernaar om lokalisatie in minder dan 30 minuten te realiseren.
In dit bericht bespreken we de implementatie van schaalbare machine learning-modellen (ML) voor het bijhouden van media-inhoud met behulp van Amazon Sage Maker, met een focus op de FluisterX model.
Achtergrond
De visie van ZOO Digital is om een snellere doorlooptijd van gelokaliseerde inhoud te bieden. Dit doel wordt belemmerd door het handmatig intensieve karakter van de oefening, aangevuld met het kleine personeelsbestand van geschoolde mensen die de inhoud handmatig kunnen lokaliseren. ZOO Digital werkt met meer dan 11,000 freelancers en heeft alleen al in 600 meer dan 2022 miljoen woorden gelokaliseerd. Het aanbod aan geschoolde mensen wordt echter overtroffen door de toenemende vraag naar inhoud, waardoor automatisering nodig is om te helpen bij lokalisatieworkflows.
Met als doel de lokalisatie van contentworkflows te versnellen door middel van machinaal leren, schakelde ZOO Digital AWS Prototyping in, een investeringsprogramma van AWS om samen met klanten workloads op te bouwen. De opdracht was gericht op het leveren van een functionele oplossing voor het lokalisatieproces en het bieden van praktische training aan ZOO Digital-ontwikkelaars over SageMaker, Amazon Transcribe en Amazon Vertalen.
Klant uitdaging
Nadat een titel (een film of een aflevering van een tv-serie) is getranscribeerd, moeten sprekers aan elk spraaksegment worden toegewezen, zodat ze correct kunnen worden toegewezen aan de stemartiesten die worden gecast om de personages te spelen. Dit proces wordt sprekerdiarisatie genoemd. ZOO Digital staat voor de uitdaging om inhoud op grote schaal te archiveren en tegelijkertijd economisch levensvatbaar te zijn.
Overzicht oplossingen
In dit prototype hebben we de originele mediabestanden opgeslagen in een gespecificeerde Amazon eenvoudige opslagservice (Amazon S3) bak. Deze S3-bucket is geconfigureerd om een gebeurtenis uit te zenden wanneer er nieuwe bestanden in worden gedetecteerd, waardoor een AWS Lambda functie. Raadpleeg de tutorial voor instructies over het configureren van deze trigger Een Amazon S3-trigger gebruiken om een Lambda-functie op te roepen. Vervolgens riep de Lambda-functie het SageMaker-eindpunt aan voor gevolgtrekking met behulp van de Boto3 SageMaker Runtime-client.
De FluisterX model, gebaseerd op Het gefluister van OpenAI, voert transcripties en dagboekregistratie uit voor media-items. Het is gebouwd op de Sneller gefluister herimplementatie, die tot vier keer snellere transcriptie biedt met verbeterde tijdstempeluitlijning op woordniveau in vergelijking met Whisper. Bovendien introduceert het sprekerdiarisering, die niet aanwezig was in het originele Whisper-model. WhisperX gebruikt het Whisper-model voor transcripties, de Wav2Vec2 model om de uitlijning van tijdstempels te verbeteren (zorgen voor synchronisatie van getranscribeerde tekst met audio-tijdstempels), en de pyannoot model voor dagboekschrijven. FFmpeg wordt gebruikt voor het laden van audio van bronmedia en ondersteunt verschillende mediaformaten. De transparante en modulaire modelarchitectuur maakt flexibiliteit mogelijk, omdat elk onderdeel van het model in de toekomst naar behoefte kan worden uitgewisseld. Het is echter essentieel op te merken dat WhisperX geen volledige beheerfuncties heeft en geen product op ondernemingsniveau is. Zonder onderhoud en ondersteuning is het mogelijk niet geschikt voor productie-implementatie.
In deze samenwerking hebben we WhisperX op SageMaker geïmplementeerd en geëvalueerd met behulp van een asynchrone inferentie-eindpunt om het model te hosten. De asynchrone eindpunten van SageMaker ondersteunen uploadgroottes tot 1 GB en bevatten automatische schalingsfuncties die verkeerspieken efficiënt beperken en kosten besparen tijdens daluren. Asynchrone eindpunten zijn bijzonder geschikt voor het verwerken van grote bestanden, zoals films en tv-series in ons gebruiksscenario.
Het volgende diagram illustreert de kernelementen van de experimenten die we in deze samenwerking hebben uitgevoerd.

In de volgende secties gaan we dieper in op de details van de implementatie van het WhisperX-model op SageMaker en evalueren we de prestaties van het bijhouden van dagboeken.
Download het model en zijn componenten
WhisperX is een systeem dat meerdere modellen bevat voor transcriptie, gedwongen uitlijning en dagboekregistratie. Voor een soepele werking van SageMaker zonder de noodzaak om modelartefacten op te halen tijdens de inferentie, is het essentieel om alle modelartefacten vooraf te downloaden. Deze artefacten worden vervolgens tijdens de initiatie in de SageMaker-serveercontainer geladen. Omdat deze modellen niet direct toegankelijk zijn, bieden we beschrijvingen en voorbeeldcode van de WhisperX-bron, met instructies voor het downloaden van het model en de componenten ervan.
WhisperX gebruikt zes modellen:
De meeste van deze modellen zijn verkrijgbaar bij Gezicht knuffelen met behulp van de Huggingface_hub-bibliotheek. Wij gebruiken het volgende download_hf_model() functie om deze modelartefacten op te halen. Een toegangstoken van Hugging Face, gegenereerd na het accepteren van de gebruikersovereenkomsten voor de volgende pyannote-modellen, is vereist:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
Het VAD-model wordt opgehaald uit Amazon S3 en het Wav2Vec2-model wordt opgehaald uit de torchaudio.pipelines-module. Op basis van de volgende code kunnen we alle artefacten van de modellen ophalen, inclusief die van Hugging Face, en deze opslaan in de opgegeven lokale modelmap:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Selecteer de juiste AWS Deep Learning Container om het model te bedienen
Nadat de modelartefacten zijn opgeslagen met behulp van de voorgaande voorbeeldcode, kunt u vooraf gebouwd kiezen AWS diepe leercontainers (DLC's) uit het volgende GitHub repo. Houd bij het selecteren van de Docker-image rekening met de volgende instellingen: framework (Hugging Face), taak (gevolgtrekking), Python-versie en hardware (bijvoorbeeld GPU). Wij raden u aan de volgende afbeelding te gebruiken: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Op deze image zijn alle benodigde systeempakketten vooraf geïnstalleerd, zoals ffmpeg. Vergeet niet om [REGION] te vervangen door de AWS-regio die u gebruikt.
Voor andere vereiste Python-pakketten maakt u een requirements.txt bestand met een lijst met pakketten en hun versies. Deze pakketten worden geïnstalleerd wanneer de AWS DLC wordt gebouwd. Hieronder volgen de aanvullende pakketten die nodig zijn om het WhisperX-model op SageMaker te hosten:
Maak een inferentiescript om de modellen te laden en de inferentie uit te voeren
Vervolgens maken we een maatwerk inference.py script om aan te geven hoe het WhisperX-model en zijn componenten in de container worden geladen en hoe het inferentieproces moet worden uitgevoerd. Het script bevat twee functies: model_fn en transform_fn. De model_fn functie wordt aangeroepen om de modellen vanaf hun respectievelijke locaties te laden. Vervolgens worden deze modellen doorgegeven aan de transform_fn functioneren tijdens inferentie, waarbij transcriptie-, uitlijnings- en dagboekvormingsprocessen worden uitgevoerd. Het volgende is een codevoorbeeld voor inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
In de map van het model, naast de requirements.txt bestand, zorg voor de aanwezigheid van inference.py in een codesubmap. De models map moet er als volgt uitzien:
Maak een tarball van de modellen
Nadat u de modellen en codemappen hebt gemaakt, kunt u de volgende opdrachtregels gebruiken om het model in een tarball (.tar.gz-bestand) te comprimeren en naar Amazon S3 te uploaden. Op het moment van schrijven is, met behulp van het sneller gefluisterde Large V2-model, de resulterende tarball die het SageMaker-model vertegenwoordigt, 3 GB groot. Voor meer informatie, zie Model hostingpatronen in Amazon SageMaker, deel 2: Aan de slag met het implementeren van real-time modellen op SageMaker.
Maak een SageMaker-model en implementeer een eindpunt met een asynchrone voorspeller
Nu kunt u het SageMaker-model, de eindpuntconfiguratie en het asynchrone eindpunt maken AsynchronePredictor met behulp van het model-tarball dat in de vorige stap is gemaakt. Voor instructies, zie Een asynchroon inferentie-eindpunt maken.
Evalueer de prestaties van het dagboekschrijven
Om de dagboekprestaties van het WhisperX-model in verschillende scenario's te beoordelen, hebben we elk drie afleveringen geselecteerd uit twee Engelse titels: één dramatitel bestaande uit afleveringen van 30 minuten, en één documentairetitel bestaande uit afleveringen van 45 minuten. We hebben de metrische toolkit van pyannote gebruikt, pyannote.metrics, om te berekenen foutenpercentage bij dagboekanalyse (DER). Bij de evaluatie dienden handmatig getranscribeerde en in dagboekvorm opgenomen transcripties van ZOO als basiswaarheid.
We hebben de DER als volgt gedefinieerd:
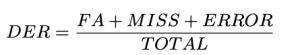
Totaal is de lengte van de grondwaarheidsvideo. FA (Vals alarm) is de lengte van segmenten die in voorspellingen als spraak worden beschouwd, maar niet in de grondwaarheid. Mejuffrouw is de lengte van segmenten die in grondwaarheid als spraak worden beschouwd, maar niet in voorspelling. Fout, Ook wel Verwarring, is de lengte van segmenten die zijn toegewezen aan verschillende sprekers in voorspellingen en grondwaarheden. Alle eenheden worden gemeten in seconden. De typische waarden voor DER kunnen variëren afhankelijk van de specifieke toepassing, dataset en de kwaliteit van het dagboekregistratiesysteem. Houd er rekening mee dat DER groter kan zijn dan 1.0. Een lagere DER is beter.
Om de DER voor een stukje media te kunnen berekenen, is een dagboekanalyse van de grondwaarheid vereist, evenals de door WhisperX getranscribeerde en dagboekgegevens. Deze moeten worden geparseerd en resulteren in lijsten met tupels die een sprekerlabel, de starttijd van het spraaksegment en de eindtijd van het spraaksegment bevatten voor elk spraaksegment in de media. De sprekerlabels hoeven niet overeen te komen tussen de WhisperX- en de grondwaarheidsdiariseringen. De resultaten zijn voornamelijk gebaseerd op de tijd van de segmenten. pyannote.metrics neemt deze tupels van basiswaarheidsdiarisaties en output-diarisaties (waarnaar in de pyannote.metrics-documentatie wordt verwezen als referentie en hypothese) om de DER te berekenen. De volgende tabel vat onze resultaten samen.
| Type video | DER | Correct | Mejuffrouw | Fout | Vals alarm |
| Drama | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Documentaire | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Gemiddelde | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Deze resultaten laten een aanzienlijk prestatieverschil zien tussen de drama- en documentairetitels, waarbij het model aanzienlijk betere resultaten behaalt (met DER als geaggregeerde maatstaf) voor de drama-afleveringen vergeleken met de documentairetitel. Een nadere analyse van de titels geeft inzicht in potentiële factoren die bijdragen aan deze prestatiekloof. Een belangrijke factor zou de frequente aanwezigheid van achtergrondmuziek kunnen zijn die overlapt met spraak in de titel van de documentaire. Hoewel het voorbewerken van media om de nauwkeurigheid van dagboekregistratie te verbeteren, zoals het verwijderen van achtergrondgeluid om spraak te isoleren, buiten de reikwijdte van dit prototype viel, opent het mogelijkheden voor toekomstig werk dat mogelijk de prestaties van WhisperX zou kunnen verbeteren.
Conclusie
In dit bericht hebben we de samenwerking tussen AWS en ZOO Digital onderzocht, waarbij we gebruik maakten van machine learning-technieken met SageMaker en het WhisperX-model om de workflow voor het bijhouden van dagboeken te verbeteren. Het AWS-team speelde een cruciale rol bij het assisteren van ZOO bij het maken van prototypen, het evalueren en begrijpen van de effectieve inzet van aangepaste ML-modellen, specifiek ontworpen voor dagboekregistratie. Dit omvatte onder meer de integratie van automatisch schalen voor schaalbaarheid met behulp van SageMaker.
Het inzetten van AI voor het bijhouden van dagboeken zal leiden tot aanzienlijke besparingen in zowel kosten als tijd bij het genereren van gelokaliseerde inhoud voor ZOO. Door transcribenten te helpen bij het snel en nauwkeurig creëren en identificeren van sprekers, pakt deze technologie de traditioneel tijdrovende en foutgevoelige aard van de taak aan. Het conventionele proces omvat vaak meerdere passages door de video en aanvullende kwaliteitscontrolestappen om fouten te minimaliseren. De adoptie van AI voor het bijhouden van dagboeken maakt een meer gerichte en efficiënte aanpak mogelijk, waardoor de productiviteit binnen een korter tijdsbestek wordt verhoogd.
We hebben de belangrijkste stappen uiteengezet om het WhisperX-model op het asynchrone eindpunt van SageMaker te implementeren, en moedigen u aan om het zelf te proberen met behulp van de meegeleverde code. Voor meer inzicht in de diensten en technologie van ZOO Digital, bezoek De officiële site van ZOO Digital. Voor meer informatie over het implementeren van het OpenAI Whisper-model op SageMaker en verschillende gevolgtrekkingsopties raadpleegt u Host het Whisper Model op Amazon SageMaker: verken de gevolgtrekkingsopties. Deel gerust uw mening in de reacties.
Over de auteurs
 Ying Hou, PhD, is een Machine Learning Prototyping Architect bij AWS. Haar voornaamste interessegebieden omvatten Deep Learning, met een focus op GenAI, Computer Vision, NLP en tijdreeksgegevensvoorspelling. In haar vrije tijd brengt ze graag kwaliteitsmomenten door met haar familie, verdiept ze zich in romans en wandelt ze in de nationale parken van Groot-Brittannië.
Ying Hou, PhD, is een Machine Learning Prototyping Architect bij AWS. Haar voornaamste interessegebieden omvatten Deep Learning, met een focus op GenAI, Computer Vision, NLP en tijdreeksgegevensvoorspelling. In haar vrije tijd brengt ze graag kwaliteitsmomenten door met haar familie, verdiept ze zich in romans en wandelt ze in de nationale parken van Groot-Brittannië.
 Ethan Cumberland is een AI Research Engineer bij ZOO Digital, waar hij werkt aan het gebruik van AI en Machine Learning als ondersteunende technologieën om de workflows op het gebied van spraak, taal en lokalisatie te verbeteren. Hij heeft een achtergrond in software-engineering en onderzoek op het gebied van beveiliging en politie, waarbij hij zich richt op het extraheren van gestructureerde informatie van het internet en het benutten van open-source ML-modellen voor het analyseren en verrijken van verzamelde gegevens.
Ethan Cumberland is een AI Research Engineer bij ZOO Digital, waar hij werkt aan het gebruik van AI en Machine Learning als ondersteunende technologieën om de workflows op het gebied van spraak, taal en lokalisatie te verbeteren. Hij heeft een achtergrond in software-engineering en onderzoek op het gebied van beveiliging en politie, waarbij hij zich richt op het extraheren van gestructureerde informatie van het internet en het benutten van open-source ML-modellen voor het analyseren en verrijken van verzamelde gegevens.
 Gaurav Kaila leidt het AWS Prototyping-team voor Groot-Brittannië en Ierland. Zijn team werkt samen met klanten in diverse sectoren om bedrijfskritische workloads te bedenken en mede te ontwikkelen met een mandaat om de adoptie van AWS-services te versnellen.
Gaurav Kaila leidt het AWS Prototyping-team voor Groot-Brittannië en Ierland. Zijn team werkt samen met klanten in diverse sectoren om bedrijfskritische workloads te bedenken en mede te ontwikkelen met een mandaat om de adoptie van AWS-services te versnellen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

