Dit is een gastpost die samen met Meta's PyTorch-team is geschreven en een voortzetting is van Deel 1 van deze serie, waarin we de prestaties en het gemak demonstreren van het uitvoeren van PyTorch 2.0 op AWS.
Onderzoek naar machinaal leren (ML) heeft bewezen dat grote taalmodellen (LLM's) die zijn getraind met aanzienlijk grote datasets, resulteren in een betere modelkwaliteit. De afgelopen jaren is de omvang van de modellen van de huidige generatie aanzienlijk toegenomen en vereisen ze dat moderne tools en infrastructuur efficiënt en op grote schaal worden getraind. PyTorch Distributed Data Parallelism (DDP) helpt gegevens op een eenvoudige en robuuste manier op schaal te verwerken, maar vereist dat het model op één GPU past. De PyTorch Fully Sharded Data Parallel (FSDP)-bibliotheek doorbreekt deze barrière door model sharding mogelijk te maken om grote modellen te trainen voor parallelle datawerkers.
Voor gedistribueerde modeltraining is een cluster van werkknooppunten vereist die kunnen worden geschaald. Amazon Elastic Kubernetes-service (Amazon EKS) is een populaire Kubernetes-conforme service die het proces van het uitvoeren van AI/ML-workloads aanzienlijk vereenvoudigt, waardoor het beter beheersbaar en minder tijdrovend wordt.
In deze blogpost werkt AWS samen met Meta's PyTorch-team om te bespreken hoe de PyTorch FSDP-bibliotheek kan worden gebruikt om lineaire schaling van deep learning-modellen op AWS naadloos te bereiken met behulp van Amazon EKS en AWS diepe leercontainers (DLC's). We demonstreren dit door een stapsgewijze implementatie van het trainen van 7B-, 13B- en 70B Llama2-modellen met behulp van Amazon EKS met 16 Amazon Elastic Compute-cloud (Amazone EC2) p4de.24xgroot instances (elk met 8 NVIDIA A100 Tensor Core GPU's en elke GPU met 80 GB HBM2e-geheugen) of 16 EC2 p5.48xgroot instances (elk met 8 NVIDIA H100 Tensor Core GPU's en elke GPU met 80 GB HBM3-geheugen), waardoor een vrijwel lineaire schaalvergroting in de doorvoer wordt bereikt en uiteindelijk een snellere trainingstijd mogelijk wordt.
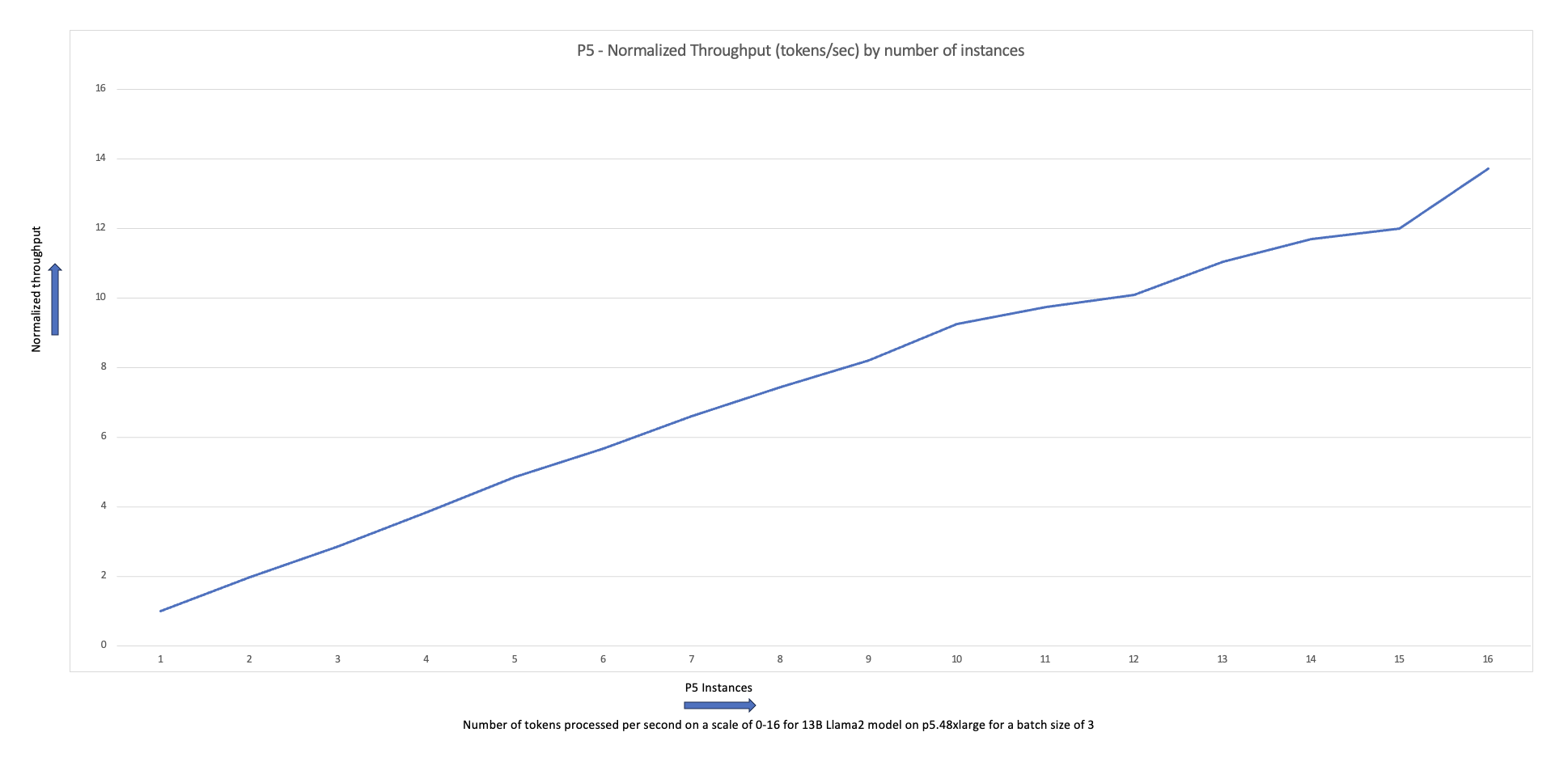
Het volgende schaaldiagram laat zien dat de p5.48xlarge-instanties een schaalefficiëntie van 87% bieden met FSDP Llama2-verfijning in een clusterconfiguratie met 16 knooppunten.
Uitdagingen bij het trainen van LLM's
Bedrijven adopteren steeds vaker LLM's voor een reeks taken, waaronder virtuele assistenten, vertalingen, het maken van inhoud en computervisie, om de efficiëntie en nauwkeurigheid in een verscheidenheid aan toepassingen te verbeteren.
Het trainen of verfijnen van deze grote modellen voor een aangepaste gebruikssituatie vereist echter een grote hoeveelheid gegevens en rekenkracht, wat bijdraagt aan de algehele technische complexiteit van de ML-stack. Dit komt ook door het beperkte geheugen dat beschikbaar is op een enkele GPU, waardoor de grootte van het model dat kan worden getraind wordt beperkt, en ook de batchgrootte per GPU die tijdens de training wordt gebruikt.
Om deze uitdaging aan te pakken, zijn er verschillende technieken voor modelparallellisme, zoals DeepSpeed ZeRO en PyTorch FSDP zijn gemaakt om u in staat te stellen deze barrière van beperkt GPU-geheugen te overwinnen. Dit wordt gedaan door gebruik te maken van een parallelle techniek met sharded data, waarbij elke accelerator slechts een segment (a scherf) van een modelreplica in plaats van de volledige modelreplica, waardoor de geheugenvoetafdruk van de trainingstaak aanzienlijk wordt verkleind.
Dit bericht laat zien hoe je PyTorch FSDP kunt gebruiken om het Llama2-model te verfijnen met Amazon EKS. We bereiken dit door de reken- en GPU-capaciteit uit te schalen om aan de modelvereisten te voldoen.
FSDP-overzicht
In PyTorch DDP-training wordt elke GPU (ook wel a werker in de context van PyTorch) bevat een volledige kopie van het model, inclusief de modelgewichten, gradiënten en optimalisatiestatussen. Elke werknemer verwerkt een batch gegevens en gebruikt aan het einde van de achterwaartse doorgang een alles verminderen operatie om gradiënten tussen verschillende werknemers te synchroniseren.
Het hebben van een replica van het model op elke GPU beperkt de grootte van het model dat kan worden ondergebracht in een DDP-workflow. FSDP helpt deze beperking te overwinnen door modelparameters, optimalisatiestatussen en gradiënten over gegevensparallelle werkers te verdelen, terwijl de eenvoud van gegevensparallellisme nog steeds behouden blijft.
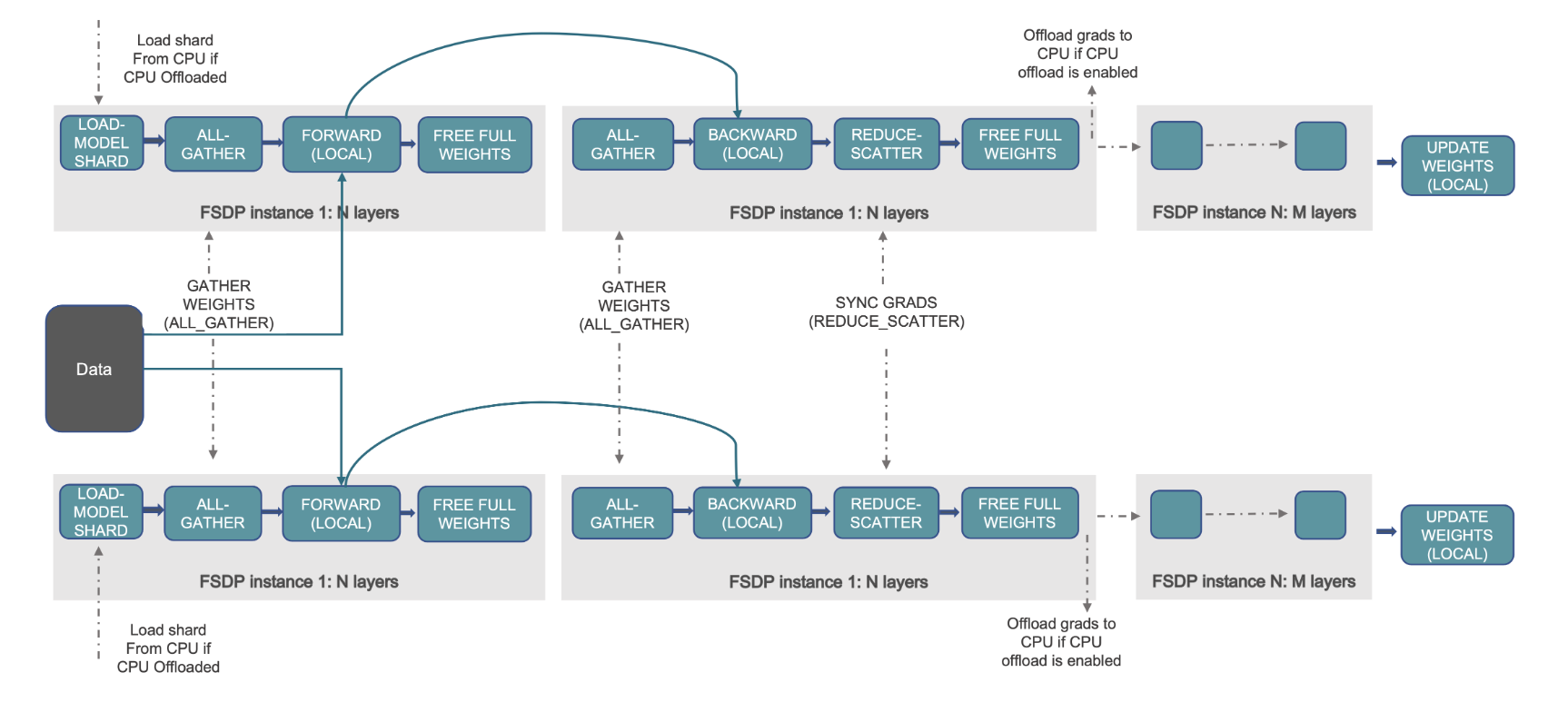
Dit wordt gedemonstreerd in het volgende diagram, waarbij in het geval van DDP elke GPU een volledige kopie van de modelstatus bevat, inclusief de optimalisatiestatus (OS), gradiënten (G) en parameters (P): M(OS + G + P). In FSDP bevat elke GPU slechts een deel van de modelstatus, inclusief de optimalisatiestatus (OS), gradiënten (G) en parameters (P): M (OS + G + P). Het gebruik van FSDP resulteert in een aanzienlijk kleinere GPU-geheugenvoetafdruk in vergelijking met DDP voor alle werknemers, waardoor de training van zeer grote modellen of het gebruik van grotere batchgroottes voor trainingstaken mogelijk wordt.

Dit gaat echter ten koste van een grotere communicatieoverhead, die wordt beperkt door FSDP-optimalisaties zoals overlappende communicatie- en rekenprocessen met functies als vooraf ophalen. Voor meer gedetailleerde informatie, zie Aan de slag met Fully Sharded Data Parallel (FSDP).
FSDP biedt verschillende parameters waarmee u de prestaties en efficiëntie van uw trainingstaken kunt afstemmen. Enkele van de belangrijkste kenmerken en mogelijkheden van FSDP zijn onder meer:
- Transformator-inpakbeleid
- Flexibele gemengde precisie
- Activering checkpointing
- Verschillende shardingstrategieën voor verschillende netwerksnelheden en clustertopologieën:
- FULL_SHARD – Shard-modelparameters, verlopen en optimalisatiestatussen
- HYBRIDE_SHARD – Volledige Shard binnen een knooppunt DDP tussen knooppunten; ondersteunt een flexibele shardinggroep voor een volledige replica van het model (HSDP)
- SHARD_GRAD_OP – Alleen Shard-gradiënten en optimalisatiestatussen
- GEEN_SCHERM – Vergelijkbaar met DDP
Voor meer informatie over FSDP, zie Efficiënte grootschalige training met Pytorch FSDP en AWS.
De volgende afbeelding laat zien hoe FSDP werkt voor twee parallelle gegevensprocessen.
Overzicht oplossingen
In dit bericht hebben we een rekencluster opgezet met behulp van Amazon EKS, een beheerde service om Kubernetes uit te voeren in de AWS Cloud en on-premises datacenters. Veel klanten omarmen Amazon EKS om op Kubernetes gebaseerde AI/ML-workloads uit te voeren, waarbij ze profiteren van de prestaties, schaalbaarheid, betrouwbaarheid en beschikbaarheid, evenals de integraties met AWS-netwerken, beveiliging en andere diensten.
Voor ons FSDP-gebruiksscenario gebruiken we de Kubeflow-trainingsoperator op Amazon EKS, een Kubernetes-native project dat het afstemmen en schaalbare gedistribueerde training voor ML-modellen mogelijk maakt. Het ondersteunt verschillende ML-frameworks, waaronder PyTorch, die u kunt gebruiken om PyTorch-trainingstaken op schaal in te zetten en te beheren.
Met behulp van de aangepaste PyTorchJob-bron van Kubeflow Training Operator voeren we trainingstaken uit op Kubernetes met een configureerbaar aantal werkreplica's waarmee we het gebruik van bronnen kunnen optimaliseren.
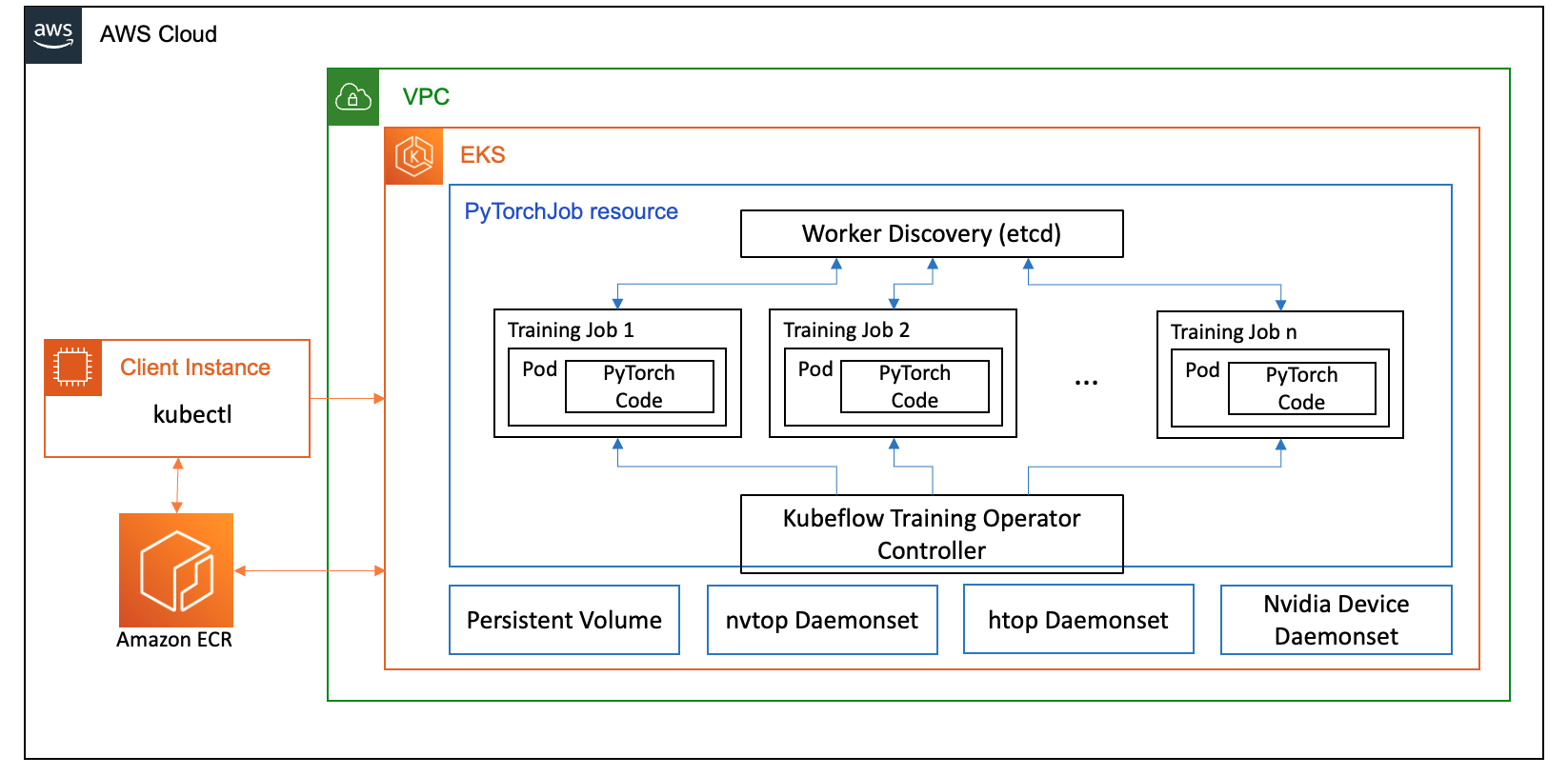
Hieronder volgen enkele componenten van de trainingsoperator die een rol spelen in onze Llama2-gebruikscasus voor het verfijnen van:
- Een gecentraliseerde Kubernetes-controller die gedistribueerde trainingstaken voor PyTorch orkestreert.
- PyTorchJob, een aangepaste Kubernetes-bron voor PyTorch, geleverd door de Kubeflow Training Operator, om Llama2-trainingstaken op Kubernetes te definiëren en te implementeren.
- etcd, dat gerelateerd is aan de implementatie van het rendez-vousmechanisme voor het coördineren van de gedistribueerde training van PyTorch-modellen. Dit
etcdserver vergemakkelijkt, als onderdeel van het rendez-vousproces, de coördinatie en synchronisatie van de deelnemende werknemers tijdens gedistribueerde training.
Het volgende diagram illustreert de oplossingsarchitectuur.
De meeste details zullen worden geabstraheerd door de automatiseringsscripts die we gebruiken om het Llama2-voorbeeld uit te voeren.
In dit gebruiksscenario gebruiken we de volgende codereferenties:
Wat is Lama2?
Llama2 is een LLM die vooraf is getraind in 2 biljoen tokens aan tekst en code. Het is een van de grootste en krachtigste LLM's die momenteel beschikbaar zijn. U kunt Llama2 gebruiken voor een verscheidenheid aan taken, waaronder natuurlijke taalverwerking (NLP), het genereren van tekst en vertaling. Voor meer informatie, zie Aan de slag met Lama.
Llama2 is verkrijgbaar in drie verschillende modelgroottes:
- Lama2-70b – Dit is het grootste Llama2-model, met 70 miljard parameters. Het is het krachtigste Llama2-model en kan worden gebruikt voor de meest veeleisende taken.
- Lama2-13b – Dit is een middelgroot Llama2-model, met 13 miljard parameters. Het biedt een goede balans tussen prestaties en efficiëntie en kan voor verschillende taken worden gebruikt.
- Lama2-7b – Dit is het kleinste Llama2-model, met 7 miljard parameters. Het is het meest efficiënte Llama2-model en kan worden gebruikt voor taken waarvoor niet het hoogste prestatieniveau vereist is.
Met dit bericht kun je al deze modellen op Amazon EKS verfijnen. Om een eenvoudige en reproduceerbare ervaring te bieden bij het maken van een EKS-cluster en het uitvoeren van FSDP-taken daarop, gebruiken we de aws-do-eks project. Het voorbeeld werkt ook met een reeds bestaand EKS-cluster.
Een scripted walkthrough is beschikbaar op GitHub voor een out-of-the-box-ervaring. In de volgende secties leggen we het end-to-end-proces in meer detail uit.
Richt de oplossingsinfrastructuur in
Voor de experimenten die in dit bericht worden beschreven, gebruiken we clusters met p4de (A100 GPU) en p5 (H100 GPU) knooppunten.
Cluster met p4de.24xlarge-knooppunten
Voor ons cluster met p4de-nodes gebruiken we het volgende eks-gpu-p4de-odcr.yaml script:
gebruik exctl en het voorgaande clustermanifest maken we een cluster met p4de-knooppunten:
Cluster met p5.48xgrote knooppunten
Hieronder vindt u een terraform-sjabloon voor een EKS-cluster met P5-knooppunten GitHub repo.
U kunt het cluster aanpassen via het variabelen.tf bestand en maak het vervolgens via de Terraform CLI:
U kunt de beschikbaarheid van het cluster verifiëren door een eenvoudige kubectl-opdracht uit te voeren:
Het cluster is in orde als de uitvoer van deze opdracht het verwachte aantal knooppunten in de status Gereed weergeeft.
Vereisten implementeren
Om FSDP op Amazon EKS uit te voeren, gebruiken we de PyTorchJob aangepaste bron. Het heeft nodig enz en Kubeflow-trainingsoperator als randvoorwaarden.
Implementeer etcd met de volgende code:
Implementeer Kubeflow Training Operator met de volgende code:
Bouw en push een FSDP-containerimage naar Amazon ECR
Gebruik de volgende code om een FSDP-containerimage te bouwen en deze naar te pushen Amazon Elastic Container-register (Amazone ECR):
Maak het FSDP PyTorchJob-manifest
Plaats uw Knuffelen Gezichtsfiche in het volgende fragment voordat u het uitvoert:
Configureer uw PyTorchJob met .env bestand of rechtstreeks in uw omgevingsvariabelen, zoals hieronder:
Genereer het PyTorchJob-manifest met behulp van de fsdp-sjabloon en genereren.sh script of maak het rechtstreeks met behulp van het onderstaande script:
Voer de PyTorchJob uit
Voer de PyTorchJob uit met de volgende code:
U ziet dat het opgegeven aantal FDSP-werkpods is gemaakt en nadat de afbeelding is opgehaald, gaan deze over naar de status Actief.
Gebruik de volgende code om de status van de PyTorchJob te zien:
Gebruik de volgende code om de PyTorchJob te stoppen:
Nadat een taak is voltooid, moet deze worden verwijderd voordat een nieuwe run wordt gestart. We hebben ook vastgesteld dat het verwijderen van deetcdpod en deze opnieuw opstarten voordat u een nieuwe taak start, helpt bij het voorkomen van een RendezvousClosedError.
Schaal het cluster
U kunt de voorgaande stappen voor het maken en uitvoeren van taken herhalen, terwijl u het aantal en het exemplaartype van werkknooppunten in het cluster varieert. Hierdoor kunt u schaaldiagrammen maken zoals eerder weergegeven. Over het algemeen zou u een vermindering van de GPU-geheugenvoetafdruk, een vermindering van de epoch-tijd en een verhoging van de doorvoer moeten zien wanneer er meer knooppunten aan het cluster worden toegevoegd. De vorige grafiek werd geproduceerd door verschillende experimenten uit te voeren met een p5-knooppuntgroep variërend van 1 tot 16 knooppunten in grootte.
Observeer de FSDP-trainingswerklast
Waarneembaarheid van generatieve kunstmatige intelligentie-workloads is belangrijk om inzicht te krijgen in uw lopende taken en om het gebruik van uw computerbronnen te maximaliseren. In dit bericht gebruiken we hiervoor een aantal Kubernetes-native en open source observatietools. Met deze tools kunt u fouten, statistieken en modelgedrag bijhouden, waardoor de waarneembaarheid van AI een cruciaal onderdeel wordt van elk zakelijk gebruik. In deze sectie laten we verschillende benaderingen zien voor het observeren van FSDP-trainingstaken.
Logboeken van werknemerspods
Op het meest basale niveau moet u de logboeken van uw trainingspods kunnen zien. Dit kan eenvoudig worden gedaan door Kubernetes-native opdrachten te gebruiken.
Haal eerst een lijst met pods op en zoek de naam van degene waarvoor u logboeken wilt zien:
Bekijk vervolgens de logs voor de geselecteerde pod:

Slechts één werknemer (gekozen leider) podlogboek zal de algemene functiestatistieken vermelden. De naam van de gekozen leiderspod is beschikbaar aan het begin van elk werkerpodlogboek, geïdentificeerd door de sleutel master_addr=.
CPU-gebruik
Gedistribueerde trainingswerklasten vereisen zowel CPU- als GPU-bronnen. Om deze werklasten te optimaliseren, is het belangrijk om te begrijpen hoe deze bronnen worden gebruikt. Gelukkig zijn er enkele geweldige open source-hulpprogramma's beschikbaar die het CPU- en GPU-gebruik helpen visualiseren. Voor het bekijken van het CPU-gebruik kunt u gebruikenhtop. Als uw werkpods dit hulpprogramma bevatten, kunt u de onderstaande opdracht gebruiken om een shell in een pod te openen en deze vervolgens uit te voerenhtop.
Als alternatief kunt u een htop implementerendaemonsetzoals hieronder vermeld GitHub repo.
Dedaemonsetzal op elk knooppunt een lichtgewicht htop-pod uitvoeren. U kunt elk van deze pods uitvoeren en dehtopopdracht:
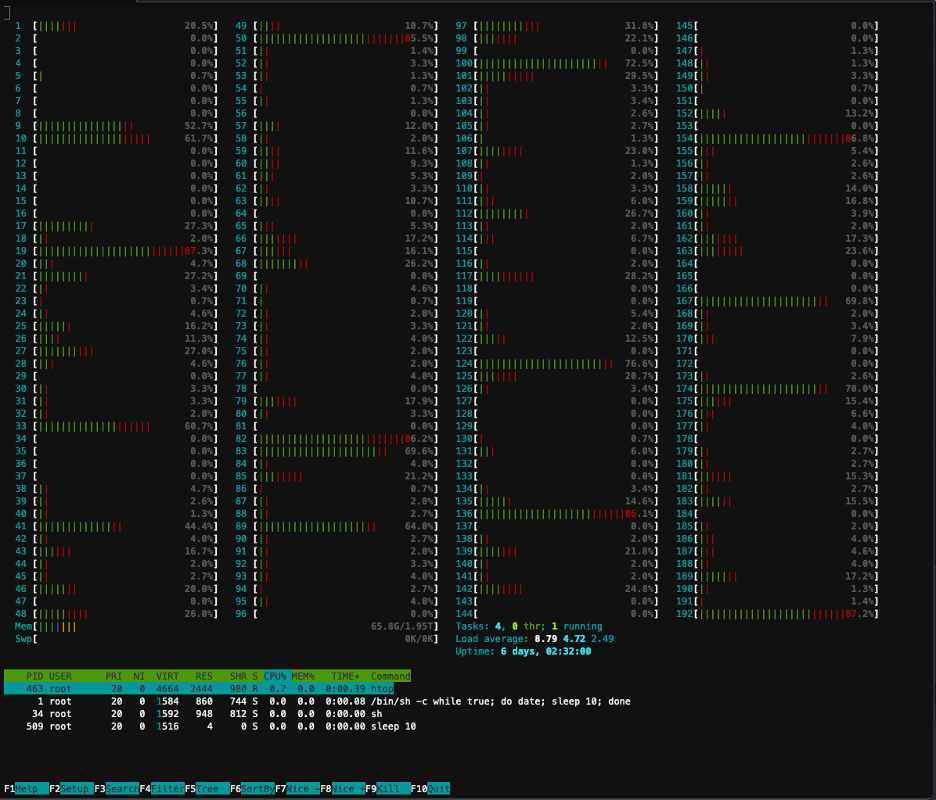
De volgende schermafbeelding toont het CPU-gebruik op een van de knooppunten in het cluster. In dit geval kijken we naar een P5.48xlarge-instantie, die 192 vCPU's heeft. De processorkernen zijn inactief terwijl de modelgewichten worden gedownload, en we zien een toenemend gebruik terwijl de modelgewichten in het GPU-geheugen worden geladen.
GPU-gebruik
Indien denvtophulpprogramma beschikbaar is in uw pod, kunt u het hieronder uitvoeren en vervolgens uitvoerennvtop.
Als alternatief kunt u een nvtop inzettendaemonsetzoals hieronder vermeld GitHub repo.
Deze loopt eennvtoppod op elk knooppunt. Je kunt een van die pods binnengaan en rennennvtop:
De volgende schermafbeelding toont het GPU-gebruik op een van de knooppunten in het trainingscluster. In dit geval kijken we naar een P5.48xlarge-instantie, die 8 NVIDIA H100 GPU's heeft. De GPU's zijn inactief terwijl de modelgewichten worden gedownload, waarna het GPU-geheugengebruik toeneemt naarmate de modelgewichten op de GPU worden geladen, en het GPU-gebruik piekt naar 100% terwijl de trainingsiteraties aan de gang zijn.

Grafana-dashboard
Nu u begrijpt hoe uw systeem werkt op pod- en knooppuntniveau, is het ook belangrijk om naar de statistieken op clusterniveau te kijken. Geaggregeerde gebruiksstatistieken kunnen worden verzameld door NVIDIA DCGM Exporter en Prometheus en gevisualiseerd in Grafana.
Hieronder vindt u een voorbeeld van een Prometheus-Grafana-implementatie GitHub repo.
Hieronder vindt u een voorbeeld van een DCGM-exporteurimplementatie GitHub repo.
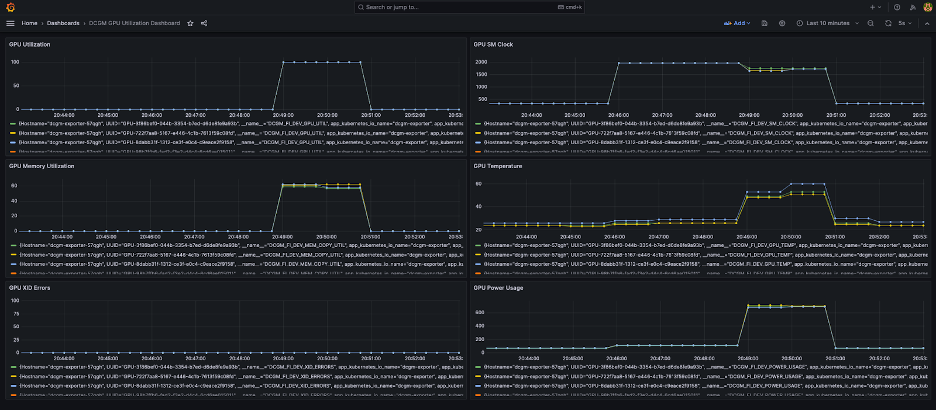
Een eenvoudig Grafana-dashboard wordt weergegeven in de volgende schermafbeelding. Het is gebouwd door de volgende DCGM-statistieken te selecteren: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMP en DCGM_FI_DEV_POWER_USAGE. Het dashboard kan vanuit Prometheus worden geïmporteerd GitHub.
Het volgende dashboard toont één uitvoering van een Llama2 7b-trainingstaak met één tijdperk. De grafieken laten zien dat naarmate de streaming multiprocessor (SM) klok toeneemt, het stroomverbruik en de temperatuur van de GPU's ook toenemen, samen met het GPU- en geheugengebruik. Je kunt ook zien dat er tijdens deze run geen XID-fouten waren en dat de GPU's in orde waren.
Sinds maart 2024 wordt GPU-observatie voor EKS native ondersteund in CloudWatch-containerinzichten. Om deze functionaliteit in te schakelen, hoeft u alleen maar de CloudWatch Observability Add-on in uw EKS-cluster te implementeren. Vervolgens kunt u door statistieken op pod-, knooppunt- en clusterniveau bladeren via vooraf geconfigureerde en aanpasbare dashboards in Container Insights.
Opruimen
Als u uw cluster hebt gemaakt met behulp van de voorbeelden in deze blog, kunt u de volgende code uitvoeren om het cluster en alle daaraan gekoppelde bronnen, inclusief de VPC, te verwijderen:
Voor eksctl:
Voor terraform:
Aankomende functies
Er wordt verwacht dat FSDP een sharding-functie per parameter zal bevatten, met als doel de geheugenvoetafdruk per GPU verder te verbeteren. Bovendien is de voortdurende ontwikkeling van FP8-ondersteuning bedoeld om de FSDP-prestaties op H100 GPU's te verbeteren. Eindelijk, wanneer FSDP is geïntegreerd mettorch.compile, hopen we aanvullende prestatieverbeteringen te zien en functies zoals selectieve activeringscontrolepunten in te schakelen.
Conclusie
In dit bericht hebben we besproken hoe FSDP de geheugenvoetafdruk op elke GPU verkleint, waardoor de training van grotere modellen efficiënter wordt en een bijna lineaire schaalvergroting in de doorvoer wordt bereikt. We hebben dit gedemonstreerd door een stapsgewijze implementatie van het trainen van een Llama2-model met behulp van Amazon EKS op P4de- en P5-instanties en gebruikten observatietools zoals kubectl, htop, nvtop en dcgm om logbestanden te monitoren, evenals het CPU- en GPU-gebruik.
We moedigen u aan om te profiteren van PyTorch FSDP voor uw eigen LLM-trainingsbanen. Ga aan de slag om aws-do-fsdp.
Over de auteurs
 Kanwaljit Khurmi is een Principal AI/ML Solutions Architect bij Amazon Web Services. Hij werkt samen met AWS-klanten om begeleiding en technische assistentie te bieden en hen te helpen de waarde van hun machine learning-oplossingen op AWS te verbeteren. Kanwaljit is gespecialiseerd in het helpen van klanten met gecontaineriseerde, gedistribueerde computer- en deep learning-applicaties.
Kanwaljit Khurmi is een Principal AI/ML Solutions Architect bij Amazon Web Services. Hij werkt samen met AWS-klanten om begeleiding en technische assistentie te bieden en hen te helpen de waarde van hun machine learning-oplossingen op AWS te verbeteren. Kanwaljit is gespecialiseerd in het helpen van klanten met gecontaineriseerde, gedistribueerde computer- en deep learning-applicaties.
 Alex Iankouski is een Principal Solutions Architect, zelfbeheerde Machine Learning bij AWS. Hij is een full-stack software- en infrastructuuringenieur die graag diepgaand, praktijkgericht werk doet. In zijn rol richt hij zich op het helpen van klanten met containerisatie en orkestratie van ML- en AI-workloads op containergebaseerde AWS-services. Hij is ook de auteur van de open source raamwerk doen en een Docker-kapitein die ervan houdt containertechnologieën toe te passen om het innovatietempo te versnellen en tegelijkertijd de grootste uitdagingen ter wereld op te lossen.
Alex Iankouski is een Principal Solutions Architect, zelfbeheerde Machine Learning bij AWS. Hij is een full-stack software- en infrastructuuringenieur die graag diepgaand, praktijkgericht werk doet. In zijn rol richt hij zich op het helpen van klanten met containerisatie en orkestratie van ML- en AI-workloads op containergebaseerde AWS-services. Hij is ook de auteur van de open source raamwerk doen en een Docker-kapitein die ervan houdt containertechnologieën toe te passen om het innovatietempo te versnellen en tegelijkertijd de grootste uitdagingen ter wereld op te lossen.
 Ana Simoes is een Principal Machine Learning Specialist, ML Frameworks bij AWS. Ze ondersteunt klanten die AI, ML en generatieve AI op grote schaal inzetten op de HPC-infrastructuur in de cloud. Ana richt zich op het ondersteunen van klanten bij het realiseren van prijs-prestatieverhoudingen voor nieuwe workloads en gebruiksscenario's voor generatieve AI en machine learning.
Ana Simoes is een Principal Machine Learning Specialist, ML Frameworks bij AWS. Ze ondersteunt klanten die AI, ML en generatieve AI op grote schaal inzetten op de HPC-infrastructuur in de cloud. Ana richt zich op het ondersteunen van klanten bij het realiseren van prijs-prestatieverhoudingen voor nieuwe workloads en gebruiksscenario's voor generatieve AI en machine learning.
 Hamid Shojanazeri is een Partner Engineer bij PyTorch en werkt aan open source, krachtige modeloptimalisatie en gedistribueerde training (FSDP), en gevolgtrekking. Hij is de mede-maker van lama-recept en bijdrage aan FakkelServe. Zijn voornaamste interesse is het verbeteren van de kostenefficiëntie, waardoor AI toegankelijker wordt voor de bredere gemeenschap.
Hamid Shojanazeri is een Partner Engineer bij PyTorch en werkt aan open source, krachtige modeloptimalisatie en gedistribueerde training (FSDP), en gevolgtrekking. Hij is de mede-maker van lama-recept en bijdrage aan FakkelServe. Zijn voornaamste interesse is het verbeteren van de kostenefficiëntie, waardoor AI toegankelijker wordt voor de bredere gemeenschap.
 Minder Wright is een AI/partneringenieur bij PyTorch. Hij werkt aan Triton/CUDA-kernels (Dequant versnellen met SplitK-werkontbinding); paged, streaming en gekwantiseerde optimizers; en PyTorch gedistribueerd (PyTorch FSDP).
Minder Wright is een AI/partneringenieur bij PyTorch. Hij werkt aan Triton/CUDA-kernels (Dequant versnellen met SplitK-werkontbinding); paged, streaming en gekwantiseerde optimizers; en PyTorch gedistribueerd (PyTorch FSDP).
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

