Introductie
In de datagestuurde wereld van vandaag hebben organisaties in verschillende sectoren te maken met enorme hoeveelheden data, complexe pijplijnen en de behoefte aan efficiënte gegevensverwerking. Traditionele data-engineeringoplossingen, zoals Apache Airflow, hebben een belangrijke rol gespeeld bij het orkestreren en controleren van dataoperaties om deze problemen aan te pakken. Met de snelle evolutie van technologie is er echter een nieuwe mededinger op het toneel verschenen, Mage, om het landschap van data-engineering.
leerdoelen
- Om gegevens van derden naadloos te integreren en te synchroniseren
- Realtime en batchpijplijnen bouwen in Python, SQL en R voor transformatie
- Een modulaire code die herbruikbaar en testbaar is met gegevensvalidaties
- Om verschillende pijplijnen uit te voeren, te bewaken en te orkestreren terwijl u slaapt
- Werk samen aan de cloud, versiebeheer met Git en test pijplijnen zonder te wachten op een beschikbare gedeelde staging-omgeving
- Snelle implementaties op cloudproviders zoals AWS, GCP en Azure via terraform-sjablonen
- Transformeer zeer grote datasets rechtstreeks in uw datawarehouse of via native integratie met Spark
- Met ingebouwde monitoring, waarschuwingen en waarneembaarheid via een intuïtieve gebruikersinterface
Zou het niet zo eenvoudig zijn als van een boomstam vallen? Dan moet je Mage zeker proberen!
In dit artikel zal ik het hebben over de kenmerken en functionaliteiten van Mage, met de nadruk op wat ik tot nu toe heb geleerd en de eerste pijplijn die ik ermee heb gebouwd.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat is Mage?
Mage is een moderne tool voor gegevensorkestratie, mogelijk gemaakt door AI en op gebouwd Machine leren modellen en heeft tot doel data-engineeringprocessen als nooit tevoren te stroomlijnen en te optimaliseren. Het is een moeiteloze maar effectieve open-source datapijplijntool voor datatransformatie en -integratie en kan een aantrekkelijk alternatief zijn voor gevestigde tools zoals Airflow. Door de kracht van automatisering en intelligentie te combineren, brengt Mage een revolutie teweeg in de workflow voor gegevensverwerking en transformeert het de manier waarop gegevens worden behandeld en verwerkt. Mage streeft ernaar om het data-engineeringproces te vereenvoudigen en te optimaliseren, in tegenstelling tot alles wat eerder is verschenen met zijn ongeëvenaarde mogelijkheden en gebruiksvriendelijke interface.
Stap 1: snelle installatie
De mage kan worden geïnstalleerd met behulp van Docker-, pip- en conda-opdrachten, of kan worden gehost op cloudservices als een virtuele machine.
Docker gebruiken
#Command line for installing Mage using Docker
>docker run -it -p 6789:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name] #Command line for installing Mage locally at on a different port
>docker run -it -p 6790:6789 -v %cd%:/home/src mageai/mageai /app/run_app.sh mage start [project_name]Pip gebruiken
#installing using pip command
>pip install mage-ai
>mage start [project_name] #installing using conda
>conda install -c conda-forge mage-ai
Er zijn ook aanvullende pakketten voor het installeren van Mage met behulp van Spark, Postgres en nog veel meer. In dit voorbeeld heb ik Google Cloud Compute Engine gebruikt om toegang te krijgen tot Mage (als VM) via SSH. Ik heb de volgende opdrachten uitgevoerd na het installeren van de benodigde Python-pakketten.
#Command for installing Mage
~$ mage sudo pip3 install mage-ai
#Command for starting the project
~$ mage start nyc_trides_project Checking port 6789...
Mage is running at http://localhost:6789 and serving project /home/srinikitha_sri789/nyc_trides_proj
INFO:mage_ai.server.scheduler_manager:Scheduler status: running.Stap 2: Bouwen
Mage biedt verschillende blokken met ingebouwde code met testcases, die kunnen worden aangepast aan uw projectvereisten.

Ik heb Data Loader-, Data Transformer- en Data Exporter-blokken (ETL) gebruikt om de gegevens uit de API te laden, de gegevens te transformeren en naar Google Big Query te exporteren voor verdere analyse.
Laten we leren hoe elk blok werkt.
I) Gegevenslader
Het "Data Loader" -blok dient als een brug tussen de gegevensbron en de opeenvolgende stadia van gegevensverwerking binnen de pijplijn. De datalader neemt gegevens op uit bronnen en zet deze om in een geschikt formaat om deze beschikbaar te maken voor verdere verwerking.
Belangrijkste functionaliteiten
- Connectiviteit met gegevensbronnen: Het data Loader-blok maakt connectiviteit mogelijk met een breed scala aan databases, API's, cloudopslagsystemen (Azure Blob Storage, GBQ, GCS, MySQL, S3, Redshift, Snowflake, Delta Lake, enz.) en andere streamingplatforms.
- Gegevenskwaliteitscontroles en foutafhandeling: Tijdens het laden van gegevens voert het gegevenskwaliteitscontroles uit om ervoor te zorgen dat de gegevens nauwkeurig en consistent zijn en voldoen aan vastgestelde validatienormen. De verstrekte logica voor de gegevenspijplijn kan worden gebruikt om fouten of afwijkingen die worden ontdekt, vast te leggen, te markeren of aan te pakken.
- Metadatabeheer: De metagegevens met betrekking tot de opgenomen gegevens worden beheerd en vastgelegd door het gegevensladerblok. De gegevensbron, het tijdstempel van de extractie, het gegevensschema en andere feiten zijn allemaal opgenomen in deze metadata. Gegevensafstamming, auditing en tracking van gegevenstransformaties in de pijplijn worden eenvoudiger gemaakt door effectief metadatabeheer.
De onderstaande schermafbeelding toont het laden van onbewerkte gegevens van de API in Mage met behulp van de gegevenslader. Na het uitvoeren van de dataloader-code en het succesvol doorlopen van de testcases, wordt de uitvoer gepresenteerd in een boomstructuur binnen de terminal.
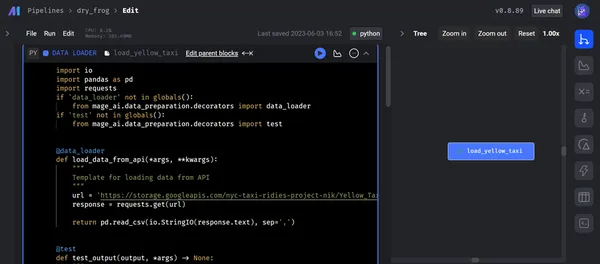
II) Gegevenstransformatie
Het blok "Gegevenstransformatie" voert manipulaties uit op de inkomende gegevens en leidt tot zinvolle inzichten en bereidt deze voor op stroomafwaartse processen. Het heeft een generieke codeoptie en een op zichzelf staand bestand met modulaire code die herbruikbaar en testbaar is met gegevensvalidaties in Python-sjablonen voor gegevensverkenning, herschaling en noodzakelijke kolomacties, SQL en R.
Belangrijkste functionaliteiten
- Combineren van gegevens: Het datatransformatieblok maakt het eenvoudiger om data uit verschillende bronnen of verschillende datasets te combineren en samen te voegen. Data-engineers kunnen gegevens combineren op basis van vergelijkbare sleutelkwaliteiten omdat het een verscheidenheid aan joins mogelijk maakt, waaronder inner joins, outside joins en cross joins. Bij het verrijken van gegevens of het samenvoegen van gegevens uit verschillende bronnen, is deze mogelijkheid erg handig.
- Aangepaste functies: Hiermee kunnen aangepaste functies en uitdrukkingen worden gedefinieerd en toegepast om de gegevens te manipuleren. U kunt gebruikmaken van ingebouwde functies of door de gebruiker gedefinieerde functies schrijven voor geavanceerde gegevenstransformaties.
Na het laden van de gegevens voert de transformatiecode alle noodzakelijke bewerkingen uit (in dit voorbeeld - het converteren van een plat bestand naar feiten- en dimensietabellen) en transformeert de code naar de gegevensexporteur. Na het uitvoeren van het datatransformatieblok wordt hieronder het boomdiagram weergegeven
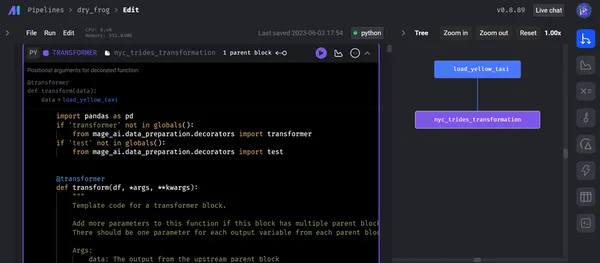
III) Gegevensexporteur
De "Data Exporter" blok exporteert en levert verwerkte gegevens naar verschillende bestemmingen of systemen voor verder gebruik, analyse of opslag. Het zorgt voor een naadloze gegevensoverdracht en integratie met externe systemen. We kunnen de gegevens naar elke opslag exporteren met behulp van standaardsjablonen voor Python (API, Azure Blob Storage, GBQ, GCS, MySQL, S3, Redshift, Snowflake, Delta Lake, enz.), SQL en R.
Belangrijkste functionaliteiten
- Schema-aanpassing: Hiermee kunnen technici het formaat en schema van de geëxporteerde gegevens aanpassen aan de vereisten van het bestemmingssysteem.
- Batchverwerking en streaming: Data Exporter-blok werkt in zowel batch- als streamingmodus. Het vergemakkelijkt batchverwerking door gegevens te exporteren met vooraf gedefinieerde intervallen of op basis van specifieke triggers. Bovendien ondersteunt het real-time datastreaming, waardoor continue en vrijwel onmiddellijke gegevensoverdracht naar downstream-systemen mogelijk is.
- Conformiteit: Het heeft functies zoals codering, toegangscontrole en gegevensmaskering om gevoelige informatie te beschermen tijdens het exporteren van de gegevens.
Na de gegevenstransformatie exporteren we de getransformeerde/verwerkte gegevens naar Google BigQuery met behulp van Data Exporter voor geavanceerde analyses. Zodra het data-exporterblok is uitgevoerd, illustreert het onderstaande boomdiagram de volgende stappen.
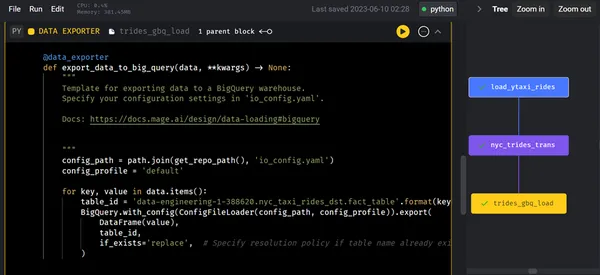

Stap 3: Voorbeeld/analyse
De "Preview"-fase stelt data-engineers in staat om verwerkte of tussentijdse gegevens op een bepaald punt in de pijplijn te inspecteren en te bekijken. Het biedt een gunstige kans om de nauwkeurigheid van de gegevenstransformaties te controleren, de kwaliteit van de gegevens te beoordelen en meer over de gegevens te leren.
Tijdens deze fase ontvangen we elke keer dat we de code uitvoeren feedback in de vorm van grafieken, tabellen en grafieken. Deze feedback stelt ons in staat om waardevolle inzichten en informatie te verzamelen. We kunnen onmiddellijk resultaten zien van de uitvoer van uw code met een interactieve notebook-UI. In de pijplijn genereert elk codeblok gegevens die we kunnen versieren, partitioneren en catalogiseren voor toekomstig gebruik.
Belangrijkste functionaliteiten
- Data visualisatie
- Gegevensbemonstering
- Beoordeling van gegevenskwaliteit
- Validatie van tussentijdse resultaten
- iteratieve ontwikkeling
- Foutopsporing en probleemoplossing
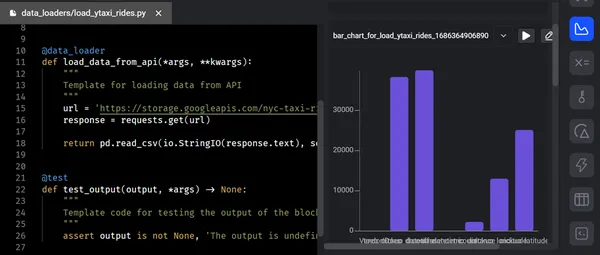

Stap 4: Lancering
In de datapijplijn vertegenwoordigt de "Launch"-fase de laatste stap waarin we de verwerkte data inzetten in productie- of downstreamsystemen voor verdere analyse. Deze fase zorgt ervoor dat de gegevens naar de juiste bestemming worden geleid en toegankelijk worden gemaakt voor de beoogde use cases.
Belangrijkste functionaliteiten
- Gegevensimplementatie
- Automatisering en planning
- Monitoring en waarschuwingen
- Versiebeheer en terugdraaien
- Prestaties Optimalisatie
- foutafhandeling
U kunt Mage implementeren in AWS, GCP of Azure met slechts 2 commando's met behulp van onderhouden Terraform-sjablonen, en u kunt zeer grote datasets rechtstreeks in uw datawarehouse of via native integratie met Spark transformeren en uw pijplijnen operationeel maken met ingebouwde monitoring, waarschuwingen en waarneembaarheid.
De onderstaande schermafbeeldingen tonen het totale aantal runs van pijplijnen en hun status, zoals geslaagd of mislukt, logboeken van elk blok en het niveau ervan.
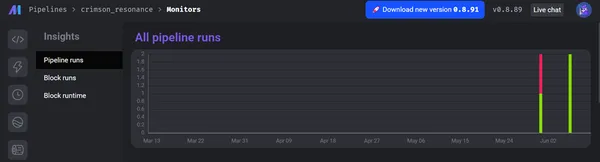
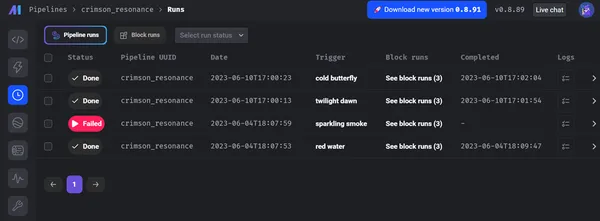
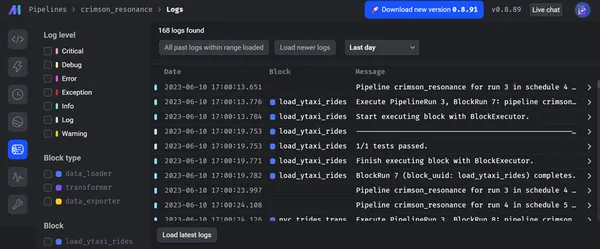
Bovendien geeft Mage prioriteit aan gegevensbeheer en beveiliging. Het biedt een veilige omgeving voor data-engineeringactiviteiten. Dankzij geavanceerde ingebouwde beveiligingsmechanismen zoals end-to-end encryptie, toegangslimieten en auditmogelijkheden. De architectuur van Mage is gebaseerd op strikte regels voor gegevensbescherming en best practices, waarbij de integriteit en vertrouwelijkheid van gegevens worden beschermd. Bovendien kunt u praktijkvoorbeelden en succesverhalen toepassen die het potentieel van Mage in verschillende sectoren benadrukken, waaronder financiën, e-commerce, gezondheidszorg en andere.
Diverse verschillen
| MAAG | ANDERE SOFTWARES |
| Mage is een motor voor het uitvoeren van gegevenspijplijnen die gegevens kunnen verplaatsen en transformeren. Die gegevens kunnen vervolgens overal worden opgeslagen (bijv. S3) en worden gebruikt om modellen in Sagemaker te trainen. | Saliemaker: Sagemaker is een volledig beheerde ML-service die wordt gebruikt om machine learning-modellen te trainen. |
| Mage is een open-source datapijplijntool voor integratie en transformatie van data (ETL). | vijftran: Fivetran is een closed-source Saas-bedrijf (software-as-a-service) dat een beheerde ETL-service levert. |
| Mage is een open-source datapijplijntool voor integratie en transformatie van data. De focus van Mage is om een gemakkelijke ontwikkelaarservaring te bieden. | LuchtByte: AirByte is een van de toonaangevende open-source ELT-platforms die de gegevens van API's, applicaties en databases repliceert naar datalakes, datawarehouses en andere bestemmingen. |
Conclusie
Concluderend kunnen data-engineers en analytische experts gegevens efficiënt laden, transformeren, exporteren, bekijken en implementeren door gebruik te maken van de functies en functionaliteiten van elke fase in de Mage-tool en het efficiënte raamwerk voor het beheren en verwerken van gegevens. Deze mogelijkheid maakt datagestuurde besluitvorming mogelijk, extractie van waardevolle inzichten en zorgt voor paraatheid met productie- of downstreamsystemen. Het wordt algemeen erkend vanwege zijn geavanceerde mogelijkheden, schaalbaarheid en sterke focus op databeheer, waardoor het een game-changer is voor data-engineering.
Key Takeaways
- Mage biedt een pijplijn voor uitgebreide data-engineering, inclusief gegevensopname, transformatie, preview en implementatie. Dit end-to-end-platform zorgt voor snelle gegevensverwerking, effectieve gegevensverspreiding en naadloze connectiviteit.
- De data-engineers van Mage hebben de mogelijkheid om verschillende bewerkingen uit te voeren tijdens de datatransformatiefase, om ervoor te zorgen dat de data wordt opgeschoond, verrijkt en voorbereid voor latere verwerking. De preview-fase maakt validatie en kwaliteitsbeoordeling van de verwerkte gegevens mogelijk, waardoor de nauwkeurigheid en betrouwbaarheid ervan worden gegarandeerd.
- Mage geeft gedurende de hele pijplijn voor data-engineering doeltreffendheid en schaalbaarheid top prioriteit. Om de prestaties te verbeteren, maakt het gebruik van optimalisatietechnieken zoals parallelle verwerking, gegevenspartitionering en caching.
- Mage's lanceringsfase maakt de moeiteloze overdracht van verwerkte gegevens naar stroomafwaartse of productiesystemen. Het heeft tools voor automatisering, versiebeheer, het oplossen van fouten en prestatie-optimalisatie, waardoor betrouwbare en tijdige gegevensoverdracht mogelijk is.
Veelgestelde Vragen / FAQ
A. Functies waarmee Mage zich onderscheidt (sommige van de anderen kunnen uiteindelijk deze functies hebben):
1. Eenvoudige gebruikersinterface/IDE voor het bouwen en beheren van datapijplijnen. Wanneer u uw datapijplijn bouwt, loopt deze tijdens de ontwikkeling precies hetzelfde als tijdens de productie. Het implementeren van de tool en het beheren van de infrastructuur in productie is heel gemakkelijk en eenvoudig, in tegenstelling tot Airflow.
2. Uitrekbaar: We hebben de tool ontworpen en gebouwd met ontwikkelaars in gedachten, zodat het heel gemakkelijk is om nieuwe functionaliteit toe te voegen aan de broncode of via plug-ins.
3. modulair: Elk blok/elke cel die u schrijft is een op zichzelf staand bestand dat interoperabel is; wat betekent dat het kan worden gebruikt in andere pijplijnen of in andere codebases.
A.Mage ondersteunt momenteel Python, SQL, R, PySpark en Spark SQL (in de toekomst).
A. Databricks biedt een infrastructuur om Spark uit te voeren. Ze bieden ook notebooks die uw code ook in Spark kunnen uitvoeren. De mage kan uw code uitvoeren in een Spark-cluster, beheerd door AWS, GCP of zelfs Databricks.
A. Ja, Mage integreert naadloos met bestaande data-infrastructuur en tools als onderdeel van het ontwerp. Het ondersteunt verschillende platforms voor gegevensopslag, databases en API's, waardoor een soepele integratie met uw voorkeurssystemen mogelijk is.
A. Ja, Mage kan het aan. Het is geschikt voor fluctuerende datavolumes en verwerkingsbehoeften vanwege de schaalbaarheid en prestatie-optimalisatiemogelijkheden, waardoor het geschikt is voor organisaties van verschillende groottes en complexiteitsniveaus voor gegevensverwerking.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/06/modern-data-engineering-with-mage-empowering-efficient-data-processing/

