
Afbeelding door auteur
Mistral AI, een van 's werelds toonaangevende AI-onderzoeksbedrijven, heeft onlangs het basismodel vrijgegeven voor Mistral 7B v0.2.
Dit open-source taalmodel werd onthuld tijdens het hackathon-evenement van het bedrijf op 23 maart 2024.
De Mistral 7B-modellen beschikken over 7.3 miljard parameters, waardoor ze extreem krachtig zijn. Ze presteren beter dan Llama 2 13B en Llama 1 34B op bijna alle benchmarks. Het nieuwste V0.2-model introduceert naast andere verbeteringen een 32k-contextvenster, waardoor de mogelijkheid om tekst te verwerken en te genereren wordt vergroot.
Bovendien is de onlangs aangekondigde versie het basismodel van de op instructies afgestemde variant, “Mistral-7B-Instruct-V0.2”, die eerder vorig jaar werd uitgebracht.
In deze tutorial laat ik je zien hoe je dit taalmodel op Hugging Face kunt openen en verfijnen.
We zullen het Mistral 7B-v0.2-basismodel verfijnen met behulp van de AutoTrain-functionaliteit van Hugging Face.
Gezicht knuffelen staat bekend om het democratiseren van de toegang tot machine learning-modellen, waardoor gewone gebruikers geavanceerde AI-oplossingen kunnen ontwikkelen.
AutoTrain, een functie van Hugging Face, automatiseert het proces van modeltraining, waardoor het toegankelijk en efficiënt wordt.
Het helpt gebruikers de beste parameters en trainingstechnieken te selecteren bij het verfijnen van modellen, een taak die anders lastig en tijdrovend kan zijn.
Hier zijn 5 stappen om uw Mistral-7B-model te verfijnen:
1. Inrichting van de omgeving
U moet eerst een account aanmaken bij Hugging Face en vervolgens een modelrepository aanmaken.
Om dit te bereiken, volgt u eenvoudigweg de stappen die hierin worden beschreven link en kom terug naar deze tutorial.
We gaan het model trainen in Python. Als het gaat om het selecteren van een notebookomgeving voor training, kunt u deze gebruiken Kaggle-notitieboekjes or Google Colab, die beide gratis toegang bieden tot GPU's.
Als het trainingsproces te lang duurt, kun je wellicht overstappen naar een cloudplatform zoals AWS Sagemaker of Azure ML.
Voer ten slotte de volgende pip-installaties uit voordat u begint met het coderen van deze tutorial:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Uw dataset voorbereiden
In deze zelfstudie gebruiken we de Alpaca-gegevensset op Hugging Face, dat er als volgt uitziet:
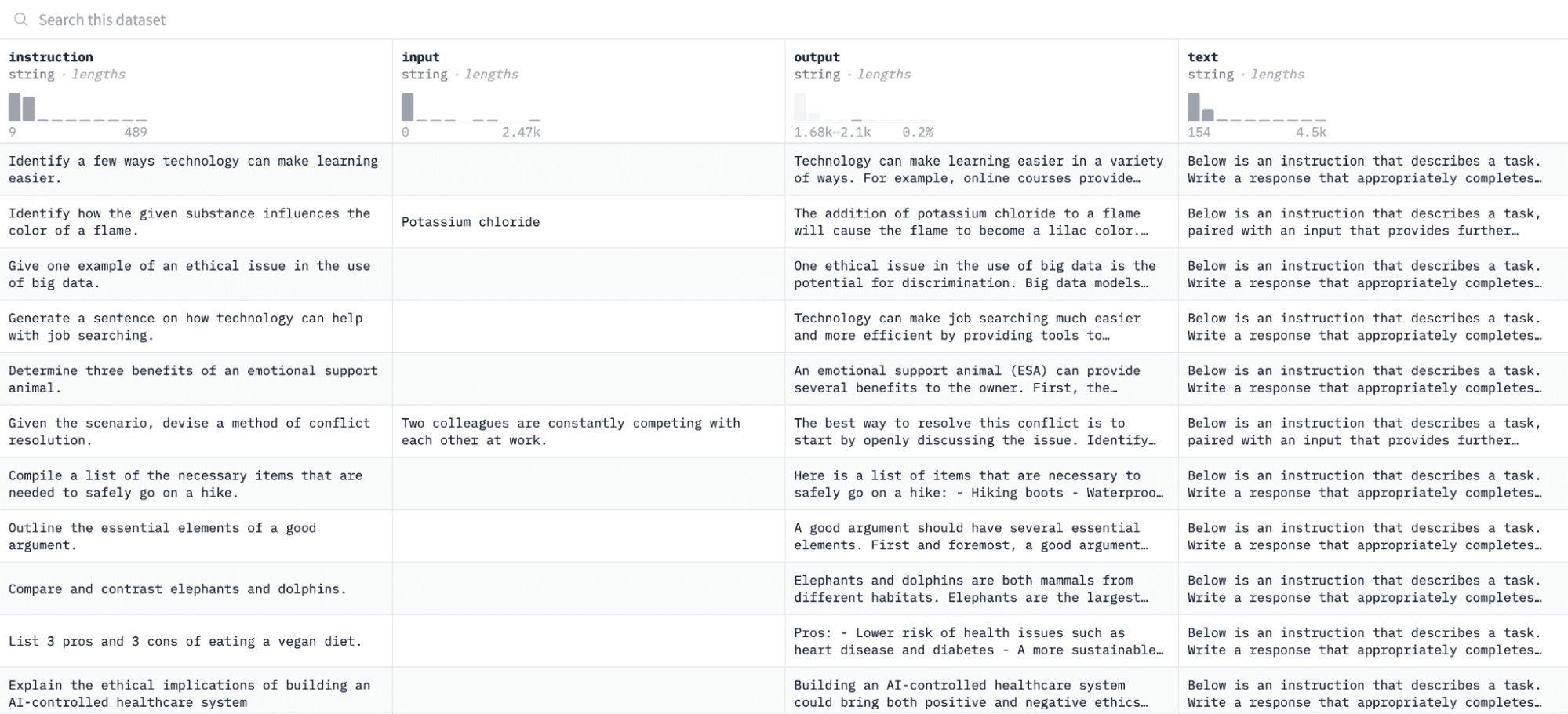
We zullen het model verfijnen op basis van instructies en outputs en beoordelen of het in staat is om te reageren op de gegeven instructie in het evaluatieproces.
Voer de volgende coderegels uit om toegang te krijgen tot deze gegevensset en deze voor te bereiden:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")De eerste functie laadt de Alpaca-dataset met behulp van de “datasets”-bibliotheek en ruimt deze op om ervoor te zorgen dat we geen lege instructies opnemen. De tweede functie structureert uw gegevens in een formaat dat AutoTrain kan begrijpen.
Nadat de bovenstaande code is uitgevoerd, wordt de dataset geladen, geformatteerd en opgeslagen in het opgegeven pad. Wanneer u uw opgemaakte dataset opent, ziet u een enkele kolom met de naam 'formatted_text'.
3. Inrichten van uw trainingsomgeving
Nu u de gegevensset met succes hebt voorbereid, gaan we verder met het instellen van uw modeltrainingsomgeving.
Om dit te doen, moet u de volgende parameters definiëren:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Hier is een overzicht van de bovenstaande specificaties:
- U kunt deze opgeven Naam van het project. Hier worden al uw project- en trainingsbestanden opgeslagen.
- De modelnaam parameter is het model dat u wilt verfijnen. In dit geval heb ik een pad opgegeven naar de Mistral-7B v0.2 basismodel op knuffelend gezicht.
- De hf_token variabele moet worden ingesteld op uw Knuffelgezicht-token, dat u kunt verkrijgen door naar te navigeren deze link.
- Your repo_id moet worden ingesteld op de Hugging Face-modelrepository die u in de eerste stap van deze zelfstudie hebt gemaakt. Mijn repository-ID is bijvoorbeeld NatasshaS/Model2.
4. Modelparameters configureren
Voordat we ons model verfijnen, moeten we de trainingsparameters definiëren, die aspecten van het modelgedrag controleren, zoals trainingsduur en regularisatie.
Deze parameters beïnvloeden belangrijke aspecten, zoals hoe lang het model traint, hoe het van de gegevens leert en hoe het overfitting voorkomt.
U kunt de volgende parameters voor uw model instellen:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Omgevingsvariabelen instellen
Laten we nu onze trainingsomgeving voorbereiden door enkele omgevingsvariabelen in te stellen.
Deze stap zorgt ervoor dat de AutoTrain-functie de gewenste instellingen gebruikt om het model te verfijnen, zoals onze projectnaam en trainingsvoorkeuren:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Start een modeltraining
Laten we ten slotte beginnen met het trainen van het model met behulp van de autotrein commando. Deze stap omvat het specificeren van uw model-, dataset- en trainingsconfiguraties, zoals hieronder weergegeven:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Zorg ervoor dat u de data-pad naar waar uw trainingsgegevensset zich bevindt.
7. Evaluatie van het model
Zodra uw model de training heeft voltooid, zou u een map in uw map moeten zien verschijnen met dezelfde titel als uw projectnaam.
In mijn geval heeft deze map de titel “mistralai,” zoals te zien in de onderstaande afbeelding:
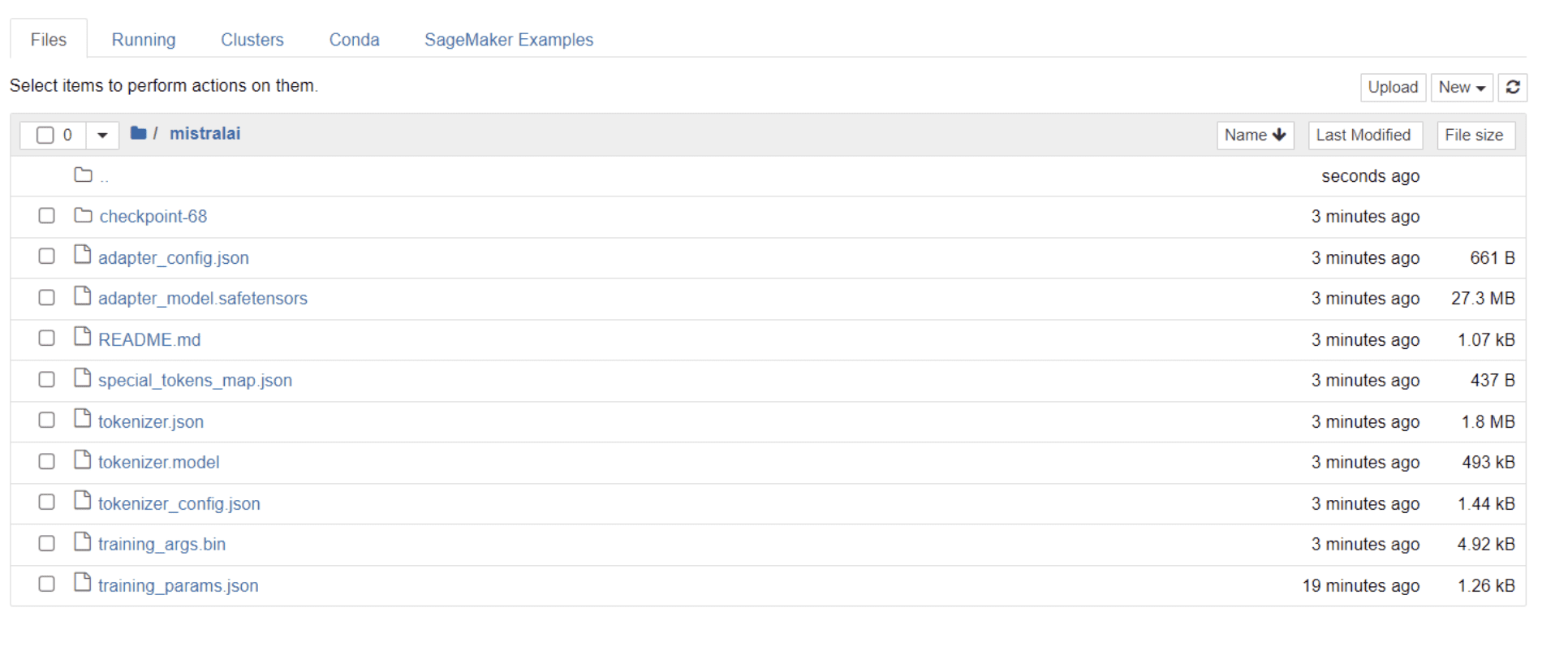
In deze map vindt u bestanden die uw modelgewichten, hyperparameters en architectuurdetails omvatten.
Laten we nu eens kijken of dit verfijnde model nauwkeurig kan reageren op een vraag in onze dataset. Om dit te bereiken, moeten we eerst de volgende coderegels uitvoeren om vijf voorbeeldinvoer en -uitvoer uit onze dataset te genereren:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")U zou een antwoord moeten zien dat er als volgt uitziet, met vijf voorbeeldgegevenspunten:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.We gaan een van de bovenstaande instructies in het model typen en controleren of deze nauwkeurige uitvoer genereert. Hier is een functie om een instructie aan het model te geven en er een antwoord van te krijgen:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerVoer ten slotte een vraag in deze functie in, zoals hieronder weergegeven:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Uw model moet een antwoord genereren dat identiek is aan de overeenkomstige uitvoer in de trainingsgegevensset, zoals hieronder weergegeven:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andHoud er rekening mee dat het antwoord onvolledig of afgekapt lijkt vanwege het aantal tokens dat we hebben opgegeven. Voel je vrij om de waarde “max_length” aan te passen om een uitgebreidere reactie mogelijk te maken.
Als je zo ver bent gekomen: gefeliciteerd!
U hebt met succes een geavanceerd taalmodel verfijnd, waarbij u gebruik maakt van de kracht van Mistral 7B v-0.2 naast de mogelijkheden van Hugging Face.
Maar de reis eindigt hier niet.
Als volgende stap raad ik aan om met verschillende datasets te experimenteren of bepaalde trainingsparameters aan te passen om de modelprestaties te optimaliseren. Het verfijnen van modellen op grotere schaal zal hun bruikbaarheid vergroten, dus probeer te experimenteren met grotere datasets of verschillende formaten, zoals pdf's en tekstbestanden.
Dergelijke ervaring wordt van onschatbare waarde bij het werken met gegevens uit de echte wereld in organisaties, die vaak rommelig en ongestructureerd zijn.
Natasha Selvaraj is een autodidactische datawetenschapper met een passie voor schrijven. Natassha schrijft over alles wat met data science te maken heeft, een echte meester in alle dataonderwerpen. Je kunt contact met haar opnemen via LinkedIn of bekijk haar Youtube kanaal.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

