Partnerschap bericht
Als u in python werkt met grote datasets, misschien enkele gigabytes groot, kunt u waarschijnlijk te maken hebben met de frustratie van uren wachten voordat uw vragen zijn voltooid, terwijl uw CPU-gebaseerde panda's DataFrame moeite heeft om bewerkingen uit te voeren. Deze exacte situatie is waar a panda's gebruiker zou moeten overwegen om de kracht van GPU's voor gegevensverwerking te benutten RAPIDS cuDF.
RAPIDS cuDF, met zijn panda-achtige API, stelt datawetenschappers en ingenieurs in staat om snel gebruik te maken van het enorme potentieel van parallel computing op GPU's - met slechts een paar wijzigingen in de coderegel.
Als u niet bekend bent met GPU-versnelling, is dit bericht een eenvoudige introductie tot het RAPIDS-ecosysteem en toont het de meest voorkomende functionaliteit van cuDF, de GPU-gebaseerde panda's DataFrame-tegenhanger.
Wil je een handige samenvatting van deze tips? Volg samen met de downloadbare cuDF-spiekbriefje.
Gebruikmaken van GPU's met cuDF DataFrame
cuDF is een data science-bouwsteen voor de VERSNELLINGEN reeks GPU-versnelde bibliotheken. Het is een EDA-werkpaard dat u kunt gebruiken om gegevenspijplijnen toe te staan om gegevens te verwerken en nieuwe functies af te leiden. Als een fundamentele component binnen de RAPIDS-suite ondersteunt cuDF de andere bibliotheken, waardoor zijn rol als gemeenschappelijke bouwsteen wordt verstevigd. Zoals alle componenten in de RAPIDS-suite, maakt cuDF gebruik van de CUDA-backend om GPU-berekeningen aan te sturen.
Met een gemakkelijke en vertrouwde Python-interface hoeven cuDF-gebruikers echter niet rechtstreeks met die laag te communiceren.
Hoe cuDF uw datawetenschap sneller kan laten werken
Ben je het beu om naar de klok te kijken terwijl je script wordt uitgevoerd? Of u nu met tekenreeksgegevens werkt of met tijdreeksen werkt, er zijn veel manieren waarop u cuDF kunt gebruiken om uw gegevenswerk vooruit te helpen.
- Tijdreeksanalyse: Of u nu gegevens opnieuw bemonstert, functies extraheert of complexe berekeningen uitvoert, cuDF biedt een aanzienlijke versnelling, mogelijk tot 880x sneller dan panda's voor tijdreeksanalyse.
- Real-time verkennende data-analyse (EDA): Bladeren door grote datasets kan een hele klus zijn met traditionele tools, maar cuDF's GPU-versnelde verwerkingskracht maakt real-time verkenning van zelfs de grootste datasets mogelijk
- Machine learning (ML) gegevensvoorbereiding: Versnel datatransformatietaken en bereid uw data voor op veelgebruikte ML-algoritmen, zoals regressie, classificatie en clustering, met de versnellingsmogelijkheden van cuDF. Efficiënte verwerking betekent snellere modelontwikkeling en stelt u in staat sneller naar de implementatie te gaan.
- Grootschalige datavisualisatie: Of u nu heatmaps maakt voor geografische data of complexe financiële trends visualiseert, ontwikkelaars kunnen datavisualisatiebibliotheken implementeren met krachtige en high-FPS datavisualisatie door gebruik te maken van cuDF en cuxfilter. Door deze integratie wordt real-time interactiviteit een essentieel onderdeel van uw analysecyclus.
- Grootschalige gegevensfiltering en -transformatie: Voor grote datasets van meer dan enkele gigabytes kunt u filter- en transformatietaken uitvoeren met behulp van cuDF in een fractie van de tijd die panda's nodig hebben.
- Tekenreeks gegevensverwerking: Traditioneel was de verwerking van stringgegevens een uitdagende en langzame taak vanwege de complexe aard van tekstuele gegevens. Deze bewerkingen worden moeiteloos gemaakt met GPU-versnelling
- GroupBy-bewerkingen: GroupBy-bewerkingen zijn een hoofdbestanddeel van gegevensanalyse, maar kunnen veel middelen vergen. cuDF versnelt deze taken aanzienlijk, waardoor u sneller inzichten krijgt bij het splitsen en aggregeren van uw gegevens

Vertrouwde interface voor GPU-verwerking
Het uitgangspunt van RAPIDS is om een vertrouwde gebruikerservaring te bieden aan populaire datawetenschapstools, zodat de kracht van NVIDIA GPU's gemakkelijk toegankelijk is voor alle beoefenaars. Of je nu ETL uitvoert, ML-modellen bouwt of grafieken verwerkt, als je panda's kent, NumPy, scikit-leren or NetwerkX, zult u zich thuis voelen bij het gebruik van RAPIDS.
Overschakelen van CPU naar GPU Data Science-stack is nog nooit zo eenvoudig geweest: met zo weinig verandering als het importeren van cuDF in plaats van panda's, kunt u de enorme kracht van NVIDIA GPU's benutten, de werkbelasting 10-100x versnellen (aan de lage kant) en genieten meer productiviteit - en dat terwijl u uw favoriete tools gebruikt.
Controleer de voorbeeldcode hieronder die laat zien hoe vertrouwd cuDF API is voor iedereen die panda's gebruikt.
import pandas as pd
import cudf
df_cpu = pd.read_csv('/data/sample.csv')
df_gpu = cudf.read_csv('/data/sample.csv')Gegevens laden uit uw favoriete gegevensbronnen
De lees- en schrijfmogelijkheden van cuDF zijn aanzienlijk gegroeid sinds de eerste release van RAPIDS in oktober 2018. De gegevens kunnen lokaal op een machine staan, worden opgeslagen in een lokaal cluster of in de cloud. cuDF gebruikt fsspec bibliotheek om de meeste bestandssysteemgerelateerde taken te abstraheren, zodat u zich kunt concentreren op wat het belangrijkst is: functies maken en uw model bouwen.
Dankzij fsspec vereist het lezen van gegevens van een lokaal of cloudbestandssysteem alleen het verstrekken van inloggegevens aan de laatste. Het onderstaande voorbeeld leest hetzelfde bestand vanaf twee verschillende locaties,
import cudf
df_local = cudf.read_csv('/data/sample.csv')
df_remote = cudf.read_csv(
's3://<bucket>/sample.csv'
, storage_options = {'anon': True})cuDF ondersteunt meerdere bestandsindelingen: op tekst gebaseerde indelingen zoals CSV/TSV of JSON, kolomgeoriënteerde indelingen zoals Parket or ORC, of rij-georiënteerde formaten zoals euro. Wat de ondersteuning van het bestandssysteem betreft, kan cuDF bestanden lezen van een lokaal bestandssysteem, cloudproviders zoals AWS S3, Google GS of Azure Blob/Data Lake, on- of off-prem Hadoop Files Systems, en ook rechtstreeks van HTTP of (S )FTP-webservers, Dropbox of Google Drive, of Jupyter File System.
Eenvoudig dataframes maken en opslaan
Het lezen van bestanden is niet de enige manier om cuDF-dataframes te maken. In feite zijn er minstens 4 manieren om dit te doen:
Vanuit een lijst met waarden kunt u DataFrame maken met één kolom,
cudf.DataFrame([1,2,3,4], columns=['foo'])
Een woordenboek doorgeven als u een DataFrame met meerdere kolommen wilt maken,
cudf.DataFrame({
'foo': [1,2,3,4]
, 'bar': ['a','b','c',None]
})Een leeg DataFrame maken en toewijzen aan kolommen,
df_sample = cudf.DataFrame()
df_sample['foo'] = [1,2,3,4]
df_sample['bar'] = ['a','b','c',None]Een lijst met tupels doorgeven,
cudf.DataFrame([
(1, 'a')
, (2, 'b')
, (3, 'c')
, (4, None)
], columns=['ints', 'strings'])U kunt ook van en naar andere geheugenrepresentaties converteren:
- Van een interne GPU-matrix weergegeven als een DeviceNDArray,
- Via DLPack-geheugenobjecten die worden gebruikt om tensoren tussen te delen diepgaand leren frameworks en Apache Arrow-indeling die een veel gemakkelijkere manier mogelijk maakt om geheugenobjecten uit verschillende programmeertalen te manipuleren,
- Voor het converteren van en naar panda's DataFrames en Series.
Bovendien ondersteunt cuDF het opslaan van de gegevens die zijn opgeslagen in een DataFrame in meerdere indelingen en bestandssystemen. In feite kan cuDF gegevens opslaan in alle formaten die het kan lezen.
Al deze mogelijkheden maken het mogelijk om snel aan de slag te gaan, ongeacht wat uw taak is of waar uw gegevens zich bevinden.
Gegevens extraheren, transformeren en samenvatten
De fundamentele datawetenschapstaak, en die waar alle datawetenschappers over klagen, is opschonen, kenmerkend en vertrouwd raken met de dataset. Daar besteden we 80% van onze tijd aan. Waarom kost het zoveel tijd?
Een van de redenen is dat de vragen die we stellen vragen de dataset duurt te lang om te beantwoorden. Iedereen die heeft geprobeerd een dataset van 2 GB op een CPU te lezen en te verwerken, weet waar we het over hebben.
Bovendien, aangezien we mensen zijn en fouten maken, kan het opnieuw uitvoeren van een pijplijn al snel een hele dag worden. Dit resulteert in productiviteitsverlies en waarschijnlijk een koffieverslaving als we naar de onderstaande grafiek kijken.
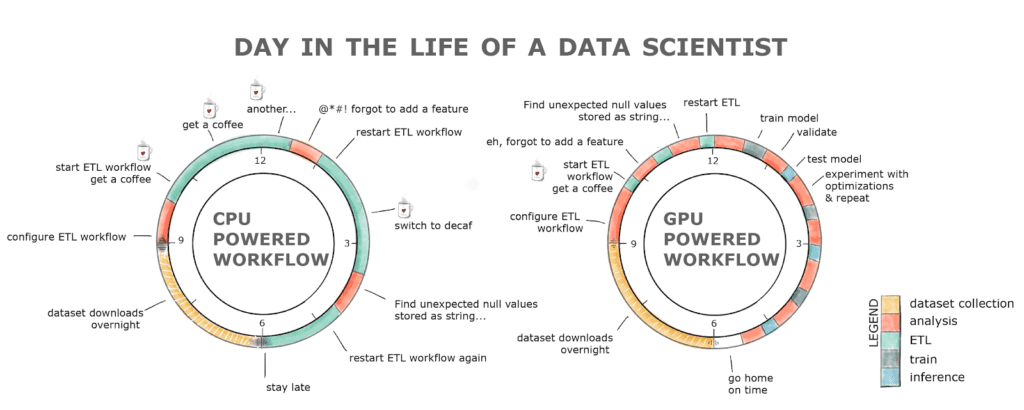
Afbeelding 1. Typische werkdag voor een ontwikkelaar die een GPU- versus CPU-aangedreven workflow gebruikt
RAPIDS met de door GPU aangedreven workflow verlicht al deze hindernissen. De ETL-fase is normaal gesproken ergens tussen de 8-20x sneller, dus het laden van die dataset van 2 GB duurt seconden in vergelijking met minuten op een CPU, het opschonen en transformeren van de gegevens gaat ook veel sneller! Dit alles met een vertrouwde interface en minimale codewijzigingen.
Werken met tekenreeksen en datums op GPU's
Niet meer dan 5 jaar geleden werd het werken met strings en datums op GPU's als bijna onmogelijk beschouwd en buiten het bereik van low-level programmeertalen zoals CUDA. GPU's zijn tenslotte ontworpen om grafische afbeeldingen te verwerken, dat wil zeggen om grote arrays en matrices van ints en floats te manipuleren, geen strings of datums.
Met RAPIDS kunt u niet alleen strings in het GPU-geheugen lezen, maar ook functies extraheren, verwerken en manipuleren. Als u bekend bent met Regex, is het extraheren van nuttige informatie uit een document op een GPU nu een triviale taak dankzij cuDF. Als u bijvoorbeeld alle woorden in uw document wilt vinden en extraheren die overeenkomen met het [az]*stroompatroon (zoals datastroom, werkstroomof stroom) alles wat je hoeft te doen is,
df['string'].str.findall('([a-z]*flow)')
Ook het extraheren van handige functies uit datums of het opvragen van gegevens voor een bepaalde periode is dankzij RAPIDS eenvoudiger en sneller geworden.
dt_to = dt.datetime.strptime("2020-10-03", "%Y-%m-%d")
df.query('dttm <= @dt_to')Panda's-gebruikers empoweren met GPU-versnelling
De overgang van een CPU- naar een GPU-datawetenschapstack is eenvoudig met RAPIDS. Het importeren van cuDF in plaats van panda's is een kleine verandering die enorme voordelen kan opleveren. Of u nu aan een lokale GPU-box werkt of opschaalt naar volwaardige datacenters, de GPU-versnelde kracht van RAPIDS biedt 10-100x snelheidsverbeteringen (aan de lage kant). Dit leidt niet alleen tot een hogere productiviteit, maar maakt ook een efficiënt gebruik van uw favoriete tools mogelijk, zelfs in de meest veeleisende, grootschalige scenario's.
RAPIDS heeft een ware revolutie teweeggebracht in het landschap van gegevensverwerking, waardoor gegevenswetenschappers taken kunnen voltooien in minuten die voorheen uren of zelfs dagen in beslag namen, wat leidde tot hogere productiviteit en lagere totale kosten.
Om aan de slag te gaan met het toepassen van deze technieken op uw dataset, leest u de versnelde data-analyseserie op NVIDIA Technical Blog.
Noot van de redactie: dit post is met toestemming bijgewerkt en oorspronkelijk overgenomen van de NVIDIA Technical Blog.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/07/mastering-gpus-beginners-guide-gpu-accelerated-dataframes-python.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-gpus-a-beginners-guide-to-gpu-accelerated-dataframes-in-python

