Introductie
Stress is een natuurlijke reactie van lichaam en geest op een veeleisende of uitdagende situatie. Het is de manier waarop het lichaam reageert op externe druk of interne gedachten en gevoelens. Stress kan worden veroorzaakt door verschillende factoren, zoals werkdruk, financiële problemen, relatieproblemen, gezondheidsproblemen of belangrijke levensgebeurtenissen. Inzichten in stressdetectie, aangedreven door datawetenschap en machine learning, hebben tot doel stressniveaus bij individuen of populaties te voorspellen. Door verschillende gegevensbronnen te analyseren, zoals fysiologische metingen, gedragsgegevens en omgevingsfactoren, kunnen voorspellende modellen patronen en risicofactoren identificeren die verband houden met stress.

Deze proactieve aanpak maakt tijdig ingrijpen en ondersteuning op maat mogelijk. Stressvoorspelling heeft potentieel in de gezondheidszorg voor vroege detectie en gepersonaliseerde interventie, evenals in beroepsomgevingen om werkomgevingen te optimaliseren. Het kan ook informatie geven over volksgezondheidsinitiatieven en beleidsbeslissingen. Met het vermogen om stress te voorspellen, bieden deze modellen waardevolle inzichten voor het verbeteren van het welzijn en het vergroten van de veerkracht van individuen en gemeenschappen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Overzicht van stressdetectie met behulp van machine learning
Stressdetectie met behulp van machine learning omvat het verzamelen, opschonen en voorbewerken van gegevens. Feature engineering-technieken worden toegepast om zinvolle informatie te extraheren of nieuwe functies te creëren die patronen met betrekking tot stress kunnen vastleggen. Dit kan het extraheren van statistische metingen, frequentiedomeinanalyse of tijdreeksanalyse inhouden om fysiologische of gedragsindicatoren van stress vast te leggen. Relevante functies worden geëxtraheerd of ontwikkeld om de prestaties te verbeteren.

Onderzoekers trainen machine learning-modellen zoals logistische regressie, SVM, beslissingsbomen, willekeurige bossen of neurale netwerken door gelabelde gegevens te gebruiken om stressniveaus te classificeren. Ze evalueren de prestaties van de modellen met behulp van statistieken zoals nauwkeurigheid, precisie, recall en F1-score. Integratie van het getrainde model in real-world toepassingen maakt real-time stressmonitoring mogelijk. Voortdurende monitoring, updates en gebruikersfeedback zijn cruciaal voor het verbeteren van de nauwkeurigheid.
Het is van cruciaal belang om rekening te houden met ethische kwesties en privacykwesties bij het omgaan met gevoelige persoonlijke gegevens die verband houden met stress. De juiste geïnformeerde toestemming, gegevensanonimisering en procedures voor veilige gegevensopslag moeten worden gevolgd om de privacy en rechten van individuen te beschermen. Ethische overwegingen, privacy en gegevensbeveiliging zijn belangrijk tijdens het hele proces. Op machine learning gebaseerde stressdetectie maakt vroegtijdige interventie, gepersonaliseerd stressmanagement en verbeterd welzijn mogelijk.
Gegevensbeschrijving
De dataset "stress" bevat informatie met betrekking tot stressniveaus. Zonder de specifieke structuur en kolommen van de dataset kan ik een algemeen overzicht geven van hoe een databeschrijving voor een percentiel eruit zou kunnen zien.
De gegevensset kan numerieke variabelen bevatten die kwantitatieve metingen vertegenwoordigen, zoals leeftijd, bloeddruk, hartslag of stressniveaus gemeten op een schaal. Het kan ook categorische variabelen bevatten die kwalitatieve kenmerken vertegenwoordigen, zoals geslacht, beroepscategorieën of stressniveaus die in verschillende categorieën zijn ingedeeld (laag, gemiddeld, hoog).
# Array
import numpy as np # Dataframe
import pandas as pd #Visualization
import matplotlib.pyplot as plt
import seaborn as sns # warnings
import warnings
warnings.filterwarnings('ignore') #Data Reading
stress_c= pd.read_csv('/human-stress-prediction/Stress.csv') # Copy
stress=stress_c.copy() # Data
stress.head()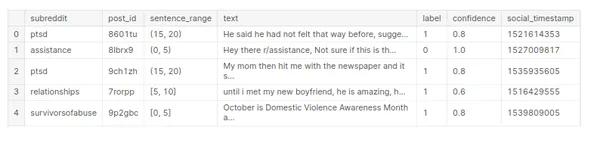
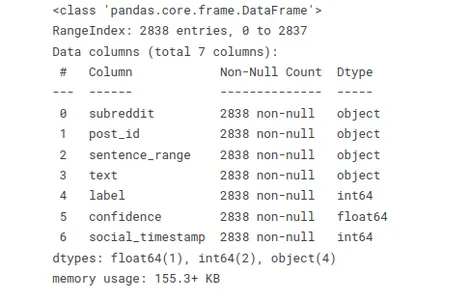
onderstaande functie stelt u in staat om snel de gegevenstypen te beoordelen en ontbrekende of null-waarden te ontdekken. Deze samenvatting is handig bij het werken met grote datasets of bij het opschonen en voorbewerken van data.
# Info
stress.info()
Gebruik de code stress.isnull().sum() om te controleren op null-waarden in de "stress"-dataset en bereken de som van null-waarden in elke kolom.
# Checking null values
stress.isnull().sum()

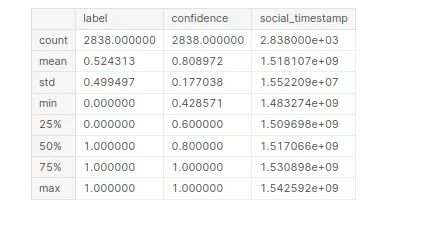
Om statistische informatie te genereren over de dataset "stress". Door deze code samen te stellen, krijgt u een samenvatting van beschrijvende statistieken voor elke numerieke kolom in de dataset.
# Statistical Information
stress.describe()
Verkennende gegevensanalyse (EDA)
Exploratory Data Analysis (EDA) is een cruciale stap in het begrijpen en analyseren van een dataset. Het omvat het visueel verkennen en samenvatten van de belangrijkste kenmerken, patronen en relaties binnen de gegevens
lst=['subreddit','label']
plt.figure(figsize=(15,12))
for i in range(len(lst)): plt.subplot(1,2,i+1) a=stress[lst[i]].value_counts() lbl=a.index plt.title(lst[i]+'_Distribution') plt.pie(x=a,labels=lbl,autopct="%.1f %%") plt.show()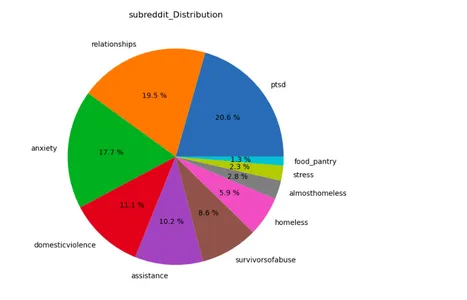
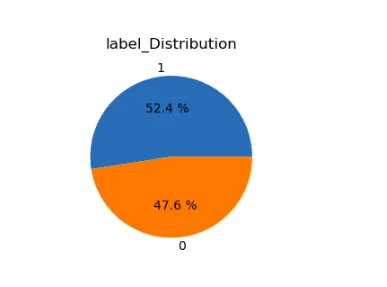
De Matplotlib- en Seaborn-bibliotheken maken een telplot voor de dataset "stress". Het visualiseert het aantal stressgevallen in verschillende subreddits, waarbij de stresslabels worden onderscheiden door verschillende kleuren.
plt.figure(figsize=(20,12))
plt.title('Subreddit wise stress count')
plt.xlabel('Subreddit')
sns.countplot(data=stress,x='subreddit',hue='label',palette='gist_heat')
plt.show()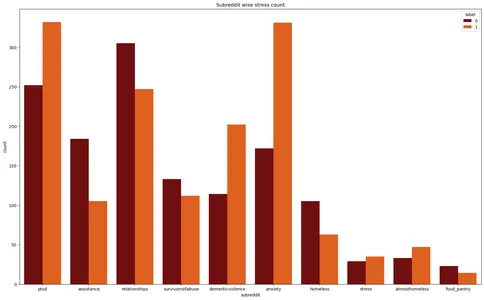
Voorverwerking van tekst
Tekstvoorverwerking verwijst naar het proces waarbij onbewerkte tekstgegevens worden omgezet in een schoner en gestructureerd formaat dat geschikt is voor analyse- of modelleringstaken. Het omvat met name een reeks stappen om ruis te verwijderen, tekst te normaliseren en relevante functies te extraheren. Hier heb ik alle bibliotheken toegevoegd die betrekking hebben op deze tekstverwerking.
# Regular Expression
import re # Handling string
import string # NLP tool
import spacy nlp=spacy.load('en_core_web_sm')
from spacy.lang.en.stop_words import STOP_WORDS # Importing Natural Language Tool Kit for NLP operations
import nltk
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('punkt')
nltk.download('omw-1.4') from nltk.stem import WordNetLemmatizer from wordcloud import WordCloud, STOPWORDS
from nltk.corpus import stopwords
from collections import Counter
Enkele veelgebruikte technieken bij het voorbewerken van tekst zijn:
Tekst opschonen
- Speciale tekens verwijderen: verwijder interpunctie, symbolen of niet-alfanumerieke tekens die niet bijdragen aan de betekenis van de tekst.
- Nummers verwijderen: verwijder numerieke cijfers als ze niet relevant zijn voor de analyse.
- Kleine letters: converteer alle tekst naar kleine letters om consistentie in tekstovereenkomst en analyse te garanderen.
- Stopwoorden verwijderen: verwijder veelgebruikte woorden die niet veel informatie bevatten, zoals 'een', 'de', 'is', enz.
tokenization
- Tekst opsplitsen in woorden of tokens: Splits de tekst op in afzonderlijke woorden of tokens ter voorbereiding op verdere analyse. Onderzoekers kunnen dit bereiken door gebruik te maken van witruimte of meer geavanceerde tokenisatietechnieken, zoals het gebruik van bibliotheken zoals NLTK of spaCy.
Normalisatie
- Lemmatisering: herleid woorden tot hun basis- of woordenboekvorm (lemma's). Bijvoorbeeld het omzetten van "rennen" en "lopen" naar "rennen".
- Stammen: herleid woorden tot hun basisvorm door voorvoegsels of achtervoegsels te verwijderen. Bijvoorbeeld het omzetten van "rennen" en "lopen" naar "rennen".
- Diakritische tekens verwijderen: verwijder accenten of andere diakritische tekens uit tekens.
#defining function for preprocessing
def preprocess(text,remove_digits=True): text = re.sub('W+',' ', text) text = re.sub('s+',' ', text) text = re.sub("(?<!w)d+", "", text) text = re.sub("-(?!w)|(?<!w)-", "", text) text=text.lower() nopunc=[char for char in text if char not in string.punctuation] nopunc=''.join(nopunc) nopunc=' '.join([word for word in nopunc.split() if word.lower() not in stopwords.words('english')]) return nopunc
# Defining a function for lemitization
def lemmatize(words): words=nlp(words) lemmas = [] for word in words: lemmas.append(word.lemma_) return lemmas #converting them into string
def listtostring(s): str1=' ' return (str1.join(s)) def clean_text(input): word=preprocess(input) lemmas=lemmatize(word) return listtostring(lemmas)# Creating a feature to store clean texts
stress['clean_text']=stress['text'].apply(clean_text)
stress.head()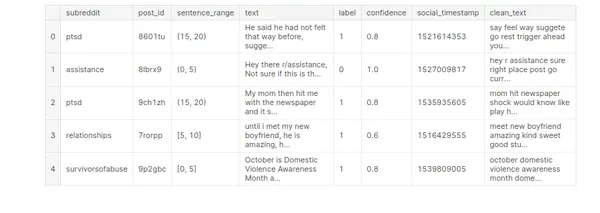
Machine Learning-modelbouw
Machine learning modelbouw is het proces van het creëren van een wiskundige representatie of model dat patronen kan leren en voorspellingen of beslissingen kan maken op basis van gegevens. Het omvat het trainen van een model met behulp van een gelabelde dataset en vervolgens dat model gebruiken om voorspellingen te doen over nieuwe, ongeziene gegevens.
Het selecteren of creëren van relevante kenmerken uit de beschikbare gegevens. Feature engineering heeft tot doel zinvolle informatie uit de onbewerkte gegevens te halen die het model kan helpen om patronen effectief te leren.
# Vectorization
from sklearn.feature_extraction.text import TfidfVectorizer # Model Building
from sklearn.model_selection import GridSearchCV,StratifiedKFold, KFold,train_test_split,cross_val_score,cross_val_predict
from sklearn.linear_model import LogisticRegression,SGDClassifier
from sklearn import preprocessing
from sklearn.naive_bayes import MultinomialNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import StackingClassifier,RandomForestClassifier, AdaBoostClassifier
from sklearn.neighbors import KNeighborsClassifier #Model Evaluation
from sklearn.metrics import confusion_matrix,classification_report, accuracy_score,f1_score,precision_score
from sklearn.pipeline import Pipeline # Time
from time import time# Defining target & feature for ML model building
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1)Het kiezen van een geschikt algoritme voor machine learning of modelarchitectuur op basis van de aard van het probleem en de kenmerken van de gegevens. Verschillende modellen, zoals beslissingsbomen, ondersteunende vectormachines of neurale netwerken, hebben verschillende sterke en zwakke punten.
Het geselecteerde model trainen met behulp van de gelabelde gegevens. Deze stap omvat het invoeren van de trainingsgegevens in het model en het model de patronen en relaties tussen de kenmerken en de doelvariabele laten leren.
# Self-defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Logistic regression def model_lr_tf(x_train, x_test, y_train, y_test): global acc_lr_tf,f1_lr_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = LogisticRegression() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_lr_tf=accuracy_score(y_test,y_pred) f1_lr_tf=f1_score(y_test,y_pred,average='weighted') print('Time :',time()-t0) print('Accuracy: ',acc_lr_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_lr_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by MultinomialNB def model_nb_tf(x_train, x_test, y_train, y_test): global acc_nb_tf,f1_nb_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = MultinomialNB() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_nb_tf=accuracy_score(y_test,y_pred) f1_nb_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_nb_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_nb_tf # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Decision Tree
def model_dt_tf(x_train, x_test, y_train, y_test): global acc_dt_tf,f1_dt_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = DecisionTreeClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_dt_tf=accuracy_score(y_test,y_pred) f1_dt_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_dt_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) return y_test,y_pred,acc_dt_tf # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by KNN def model_knn_tf(x_train, x_test, y_train, y_test): global acc_knn_tf,f1_knn_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = KNeighborsClassifier() #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_knn_tf=accuracy_score(y_test,y_pred) f1_knn_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_knn_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf #vectorizer and classify and create model by Random Forest def model_rf_tf(x_train, x_test, y_train, y_test): global acc_rf_tf,f1_rf_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = RandomForestClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_rf_tf=accuracy_score(y_test,y_pred) f1_rf_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_rf_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) # Self defining function to convert the data into vector form by tf idf
# vectorizer and classify and create model by Adaptive Boosting def model_ab_tf(x_train, x_test, y_train, y_test): global acc_ab_tf,f1_ab_tf # Text to vector transformation vector = TfidfVectorizer() x_train = vector.fit_transform(x_train) x_test = vector.transform(x_test) ovr = AdaBoostClassifier(random_state=1) #fitting training data into the model & predicting t0 = time() ovr.fit(x_train, y_train) y_pred = ovr.predict(x_test) # Model Evaluation conf=confusion_matrix(y_test,y_pred) acc_ab_tf=accuracy_score(y_test,y_pred) f1_ab_tf=f1_score(y_test,y_pred,average='weighted') print('Time : ',time()-t0) print('Accuracy: ',acc_ab_tf) print(10*'===========') print('Confusion Matrix: n',conf) print(10*'===========') print('Classification Report: n',classification_report(y_test,y_pred)) Modelevaluatie
Modelevaluatie is een cruciale stap in machine learning om de prestaties en effectiviteit van een getraind model te beoordelen. Het gaat erom te meten hoe goed de meerdere modellen generaliseren naar ongeziene gegevens en of het aan de gewenste doelstellingen voldoet. Evalueer de prestaties van het getrainde model op basis van de testgegevens. Bereken evaluatiestatistieken zoals nauwkeurigheid, precisie, herinnering en F1-score om de effectiviteit van het model bij stressdetectie te beoordelen. Modelevaluatie geeft inzicht in de sterke en zwakke punten van het model en de geschiktheid ervan voor de beoogde taak.
# Evaluating Models print('********************Logistic Regression*********************')
print('n')
model_lr_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
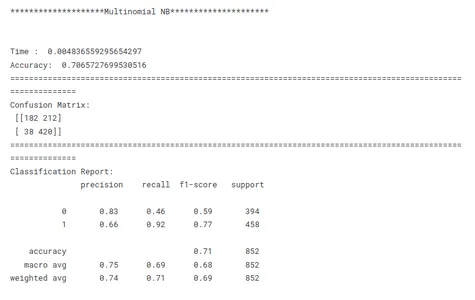
print('********************Multinomial NB*********************')
print('n')
model_nb_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
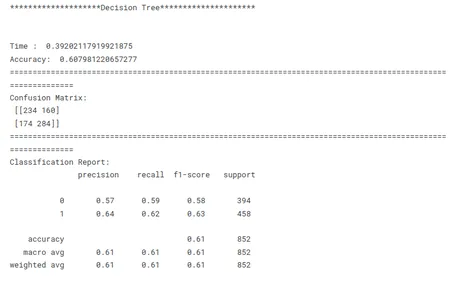
print('********************Decision Tree*********************')
print('n')
model_dt_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
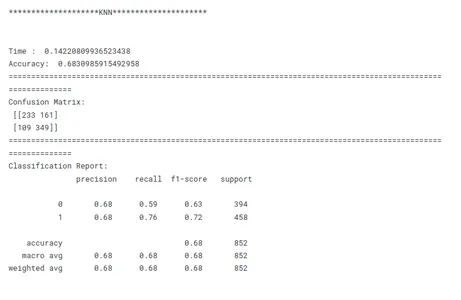
print('********************KNN*********************')
print('n')
model_knn_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
print('********************Random Forest Bagging*********************')
print('n')
model_rf_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')
print('********************Adaptive Boosting*********************')
print('n')
model_ab_tf(x_train, x_test, y_train, y_test)
print('n')
print(30*'==========')
print('n')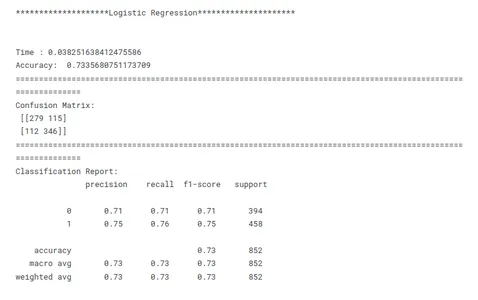
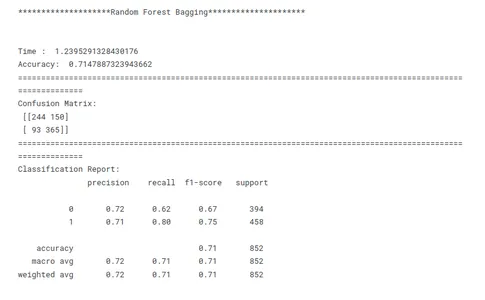
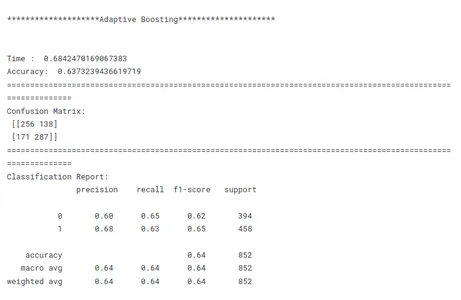
Vergelijking van modelprestaties
Dit is een cruciale stap in machine learning om het best presterende model voor een bepaalde taak te identificeren. Bij het vergelijken van modellen is het belangrijk om een duidelijk doel voor ogen te hebben. Of het nu gaat om het maximaliseren van de nauwkeurigheid, het optimaliseren voor snelheid of het prioriteren van interpreteerbaarheid, de evaluatiestatistieken en -technieken moeten aansluiten bij het specifieke doel.
Consistentie is de sleutel bij het vergelijken van modelprestaties. Het gebruik van consistente evaluatiestatistieken in alle modellen zorgt voor een eerlijke en zinvolle vergelijking. Het is ook belangrijk om de gegevens consistent op te splitsen in trainings-, validatie- en testsets voor alle modellen. Door ervoor te zorgen dat de modellen op dezelfde gegevenssubsets evalueren, maken onderzoekers een eerlijke vergelijking van hun prestaties mogelijk.
Rekening houdend met deze bovenstaande factoren, kunnen onderzoekers een uitgebreide en eerlijke vergelijking van modelprestaties uitvoeren, wat zal leiden tot weloverwogen beslissingen met betrekking tot modelselectie voor het specifieke probleem dat voorhanden is.
# Creating tabular format for better comparison
tbl=pd.DataFrame()
tbl['Model']=pd.Series(['Logistic Regreesion','Multinomial NB', 'Decision Tree','KNN','Random Forest','Adaptive Boosting'])
tbl['Accuracy']=pd.Series([acc_lr_tf,acc_nb_tf,acc_dt_tf,acc_knn_tf, acc_rf_tf,acc_ab_tf])
tbl['F1_Score']=pd.Series([f1_lr_tf,f1_nb_tf,f1_dt_tf,f1_knn_tf, f1_rf_tf,f1_ab_tf])
tbl.set_index('Model')
# Best model on the basis of F1 Score
tbl.sort_values('F1_Score',ascending=False)
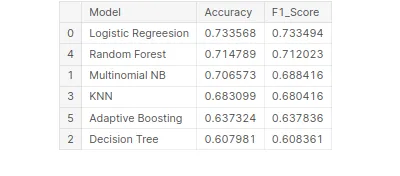
Kruisvalidatie om overfitting te voorkomen
Kruisvalidatie is inderdaad een waardevolle techniek om overfitting te voorkomen bij het trainen van machine learning-modellen. Het biedt een robuuste evaluatie van de prestaties van het model door meerdere subsets van de gegevens te gebruiken voor training en testen. Het helpt bij het beoordelen van het generalisatievermogen van het model door de prestaties op ongeziene gegevens te schatten.
# Using cross validation method to avoid overfitting
import statistics as st
vector = TfidfVectorizer() x_train_v = vector.fit_transform(x_train)
x_test_v = vector.transform(x_test) # Model building
lr =LogisticRegression()
mnb=MultinomialNB()
dct=DecisionTreeClassifier(random_state=1)
knn=KNeighborsClassifier()
rf=RandomForestClassifier(random_state=1)
ab=AdaBoostClassifier(random_state=1)
m =[lr,mnb,dct,knn,rf,ab]
model_name=['Logistic R','MultiNB','DecTRee','KNN','R forest','Ada Boost'] results, mean_results, p, f1_test=list(),list(),list(),list() #Model fitting,cross-validating and evaluating performance def algor(model): print('n',i) pipe=Pipeline([('model',model)]) pipe.fit(x_train_v,y_train) cv=StratifiedKFold(n_splits=5) n_scores=cross_val_score(pipe,x_train_v,y_train,scoring='f1_weighted', cv=cv,n_jobs=-1,error_score='raise') results.append(n_scores) mean_results.append(st.mean(n_scores)) print('f1-Score(train): mean= (%.3f), min=(%.3f)) ,max= (%.3f), stdev= (%.3f)'%(st.mean(n_scores), min(n_scores), max(n_scores),np.std(n_scores))) y_pred=cross_val_predict(model,x_train_v,y_train,cv=cv) p.append(y_pred) f1=f1_score(y_train,y_pred, average = 'weighted') f1_test.append(f1) print('f1-Score(test): %.4f'%(f1)) for i in m: algor(i) # Model comparison By Visualizing fig=plt.subplots(figsize=(20,15))
plt.title('MODEL EVALUATION BY CROSS VALIDATION METHOD')
plt.xlabel('MODELS')
plt.ylabel('F1 Score')
plt.boxplot(results,labels=model_name,showmeans=True)
plt.show() 
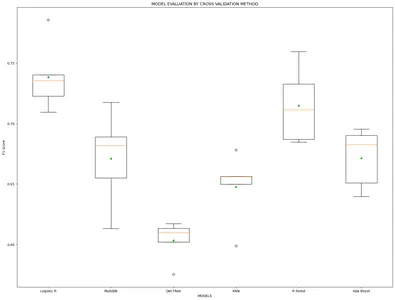
Aangezien de F1-scores van de modellen in beide methoden vrij gelijkaardig zijn. Dus nu passen we de Leave One Out-methode toe om het best presterende model te bouwen.
x=stress['clean_text']
y=stress['label']
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3,random_state=1) vector = TfidfVectorizer()
x_train = vector.fit_transform(x_train)
x_test = vector.transform(x_test)
model_lr_tf=LogisticRegression() model_lr_tf.fit(x_train,y_train)
y_pred=model_lr_tf.predict(x_test)
# Model Evaluation conf=confusion_matrix(y_test,y_pred)
acc_lr=accuracy_score(y_test,y_pred)
f1_lr=f1_score(y_test,y_pred,average='weighted') print('Accuracy: ',acc_lr)
print('F1 Score: ',f1_lr)
print(10*'===========')
print('Confusion Matrix: n',conf)
print(10*'===========')
print('Classification Report: n',classification_report(y_test,y_pred))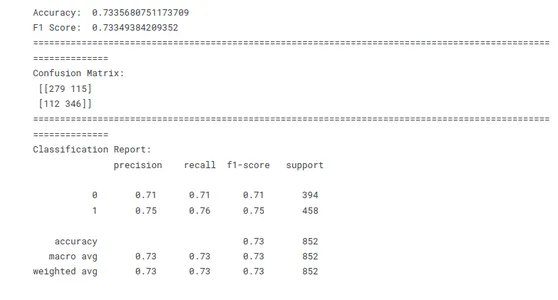
Woordwolken van beklemtoonde en niet-beklemtoonde woorden
De dataset bevat tekstberichten of documenten die zijn gelabeld als gestresst of niet-gestresst. De code doorloopt de twee labels om voor elk label een woordwolk te maken met behulp van de WordCloud-bibliotheek en geeft de woordwolkvisualisatie weer. Elke woordwolk vertegenwoordigt de meest gebruikte woorden in de betreffende categorie, waarbij grotere woorden een hogere frequentie aangeven. De keuze van de kleurenkaart ('winter', 'herfst', 'magma', 'Viridis', 'plasma') bepaalt de kleurstelling van de woordwolken. De resulterende visualisaties bieden een beknopte weergave van de meest voorkomende woorden in verband met beklemtoonde en niet-beklemtoonde berichten of documenten.
Hier zijn woordwolken die beklemtoonde en niet-beklemtoonde woorden vertegenwoordigen die gewoonlijk worden geassocieerd met klemtoondetectie:
for label, cmap in zip([0,1], ['winter', 'autumn', 'magma', 'viridis', 'plasma']): text = stress.query('label == @label')['text'].str.cat(sep=' ') plt.figure(figsize=(12, 9)) wc = WordCloud(width=1000, height=600, background_color="#f8f8f8", colormap=cmap) wc.generate_from_text(text) plt.imshow(wc) plt.axis("off") plt.title(f"Words Commonly Used in ${label}$ Messages", size=20) plt.show()

Voorspelling
De nieuwe invoergegevens worden voorverwerkt en functies worden geëxtraheerd om aan de verwachtingen van het model te voldoen. De voorspellingsfunctie wordt vervolgens gebruikt om voorspellingen te genereren op basis van de geëxtraheerde kenmerken. Ten slotte worden de voorspellingen afgedrukt of gebruikt voor verdere analyse of besluitvorming.
data=["""I don't have the ability to cope with it anymore. I'm trying, but a lot of things are triggering me, and I'm shutting down at work, just finding the place I feel safest, and staying there for an hour or two until I feel like I can do something again. I'm tired of watching my back, tired of traveling to places I don't feel safe, tired of reliving that moment, tired of being triggered, tired of the stress, tired of anxiety and knots in my stomach, tired of irrational thought when triggered, tired of irrational paranoia. I'm exhausted and need a break, but know it won't be enough until I journey the long road through therapy. I'm not suicidal at all, just wishing this pain and misery would end, to have my life back again."""] data=vector.transform(data)
model_lr_tf.predict(data)
data=["""In case this is the first time you're reading this post... We are looking for people who are willing to complete some online questionnaires about employment and well-being which we hope will help us to improve services for assisting people with mental health difficulties to obtain and retain employment. We are developing an employment questionnaire for people with personality disorders; however we are looking for people from all backgrounds to complete it. That means you do not need to have a diagnosis of personality disorder – you just need to have an interest in completing the online questionnaires. The questionnaires will only take about 10 minutes to complete online. For your participation, we’ll donate £1 on your behalf to a mental health charity (Young Minds: Child & Adolescent Mental Health, Mental Health Foundation, or Rethink)"""] data=vector.transform(data)
model_lr_tf.predict(data)
Conclusie
De toepassing van machine learning-technieken bij het voorspellen van stressniveaus biedt gepersonaliseerde inzichten voor mentaal welzijn. Door verschillende factoren te analyseren, zoals numerieke metingen (bloeddruk, hartslag) en categorische kenmerken (bijv. geslacht, beroep), kunnen machine learning-modellen patronen leren en voorspellingen doen over een individueel stressniveau. Met de mogelijkheid om stressniveaus nauwkeurig te detecteren en te monitoren, draagt machine learning bij aan de ontwikkeling van proactieve strategieën en interventies om het mentale welzijn te beheersen en te verbeteren.
We onderzochten de inzichten van het gebruik van machine learning bij stressvoorspelling en het potentieel ervan om onze benadering van het aanpakken van dit kritieke probleem radicaal te veranderen.
- Nauwkeurige voorspellingen: Machine learning-algoritmen analyseren enorme hoeveelheden historische gegevens om stresssituaties nauwkeurig te voorspellen en waardevolle inzichten en voorspellingen te bieden.
- Vroegtijdige opsporing: Machine learning kan waarschuwingssignalen vroegtijdig detecteren, waardoor proactieve maatregelen en tijdige ondersteuning in kwetsbare gebieden mogelijk zijn.
- Verbeterde planning en toewijzing van middelen: Machine learning maakt prognoses van straathotspots en -intensiteiten mogelijk, waardoor de toewijzing van middelen zoals hulpdiensten en medische voorzieningen wordt geoptimaliseerd.
- Verbeterde openbare veiligheid: Tijdige waarschuwingen en waarschuwingen via machine learning-voorspellingen stellen individuen in staat om de nodige voorzorgsmaatregelen te nemen, de impact van straat te verminderen en de openbare veiligheid te verbeteren.
Concluderend biedt deze stressvoorspellingsanalyse waardevolle inzichten in stressniveaus en hun voorspelling met behulp van machine learning. Gebruik de bevindingen om tools en interventies te ontwikkelen voor stressmanagement, het bevorderen van algeheel welzijn en een verbeterde kwaliteit van leven.
Veelgestelde Vragen / FAQ
een: 1. Objectieve beoordeling: Het biedt een objectieve en gegevensgestuurde benadering om stressniveaus te beoordelen, waardoor mogelijke vooroordelen die kunnen ontstaan bij subjectieve beoordelingen worden geëlimineerd.
2. Schaalbaarheid: Machine learning-algoritmen kunnen grote hoeveelheden tekstgegevens efficiënt verwerken, waardoor het schaalbaar is voor het analyseren van een breed scala aan tekstuele uitdrukkingen.
3. Realtime monitoring: Door stressdetectie te automatiseren, maakt het real-time monitoring van stressniveaus mogelijk, waardoor tijdige interventies en ondersteuning mogelijk zijn.
4. Inzichten en onderzoek: Het kan inzichten en trends met betrekking tot stress blootleggen, wat bijdraagt aan het begrip van stresstriggers, -effecten en mogelijke interventies.
een: 1. Posts op sociale media: tekstuele inhoud van platforms zoals Twitter, Facebook of online forums waar individuen hun gedachten en emoties uiten.
2. Chatlogboeken: Gespreksgegevens van berichten-apps, online ondersteuningssystemen of chatbots voor geestelijke gezondheid.
3. Online enquêtes of vragenlijsten: Tekstuele antwoorden op vragen over stress of mentaal welzijn.
4. Elektronische gezondheidsdossiers: Klinische aantekeningen of patiëntverhalen die relevante informatie bevatten over stressgerelateerde ervaringen.
A: 1. Tekstuele uitingen van stress kunnen sterk verschillen tussen individuen, waardoor het een uitdaging is om alle relevante indicatoren en patronen vast te leggen.
2. Contextueel begrip is cruciaal bij stressdetectie, aangezien dezelfde tekst verschillend kan worden gelezen, afhankelijk van de context en het individu.
3. Het verkrijgen van gelabelde gegevens voor het trainen van modellen voor machinaal leren kan tijdrovend en arbeidsintensief zijn, waarbij deskundige input of subjectieve beoordelingen nodig zijn.
4. Het waarborgen van gegevensprivacy, vertrouwelijkheid en ethische omgang met gevoelige informatie over geestelijke gezondheid is van het grootste belang bij het werken met tekstgegevens met betrekking tot stress.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/06/machine-learning-unlocks-insights-for-stress-detection/

