Introductie
Met de toenemende digitalisering zijn gegevens de levensader van de meeste organisaties. Naarmate het bestaan van datagedreven bedrijven groeit, neemt ook de hoeveelheid data die door deze bedrijven wordt gegenereerd en verzameld exponentieel toe. Organisaties passen zich aan aan de nieuw opkomende subset van kunstmatige intelligentie, machinaal leren genaamd, om deze gegevens bij te houden en door te gaan met het nemen van gegevensgestuurde beslissingen. Dit opkomende subveld kan het onontdekte potentieel van organisaties en hun bedrijfsgegevens ontsluiten, waardoor zakelijke beslissingen worden verbeterd. In dit artikel maakt u kennis met verschillende machine learning-bibliotheken die u kunt gebruiken en waarmee u uw werk kunt optimaliseren.
Inhoudsopgave
Wat is machinaal leren?
Machine learning (ML) is een gebied van informatica en kunstmatige intelligentie dat zich richt op het ontwikkelen van algoritmen en statistische modellen waarmee computers kunnen leren van en voorspellingen kunnen doen of beslissingen kunnen nemen op basis van gegevens. Het primaire doel van machine learning is om computers in staat te stellen automatisch de prestaties van een specifieke taak te verbeteren naarmate er meer gegevens in het systeem worden ingevoerd.
Frameworks voor machinaal leren maken gebruik van talloze ML-algoritmen om taken uit te voeren die zijn onderverdeeld in drie hoofdcategorieën: leertaken onder toezicht, zonder toezicht en leertaken. De classificatie is gebaseerd op hoeveel de gegevens zijn gelabeld/gecategoriseerd. Bij begeleid leren worden algoritmen getraind op gelabelde gegevens; niet-gelabelde gegevens worden gebruikt bij leren zonder toezicht.
Top 3 talen die worden gebruikt bij machinaal leren
Bij machine learning kunnen veel programmeertalen worden gebruikt. Van sommige is echter bekend dat ze een betere efficiëntie bieden en handiger zijn om mee te werken: -
Python
Python is een programmeertaal op hoog niveau voor alle doeleinden. Met een omvangrijke ontwikkelingsgemeenschap en een breed scala aan toepassingen is het voor beginners een van de meest geliefde talen ter wereld geworden. Vanwege zijn uitgebreide bibliotheek- en framework-ecosysteem maakt Python het eenvoudig om snel geavanceerde applicaties te maken. NumPy, Pandas, matplotlib, Django, Flask, TensorFlow en PyTorch zijn bekende bibliotheken en frameworks. Webontwikkeling, datamining, machine learning, wetenschappelijk computergebruik, scripting, tijdreeksanalyse en gegevensvoorbehandeling en -analyse.
R Programmeertaal
Een andere programmeertaal die veel wordt gebruikt voor statistische berekeningen en machine learning is de R-programmeertaal. De programmeertaal is ontwikkeld in de jaren negentig en wordt voornamelijk gebruikt bij gegevensanalyse, visualisatie en manipulatie. Het heeft ook een grote en actieve gemeenschap van gebruikers en ontwikkelaars die bijdragen aan de ontwikkeling ervan en hun werk delen via pakketten, dit zijn verzamelingen van functies en datasets die zijn ontworpen voor specifieke taken. Met een grote en actieve gemeenschap van ontwikkelaars en gebruikers is de broncode vrij beschikbaar voor iedereen als open-sourcetaal.
MATLAB-programmeertaal
MATLAB is een bekwame programmeertaal en een computeromgeving voor numerieke, wetenschappelijke, technische en machine-learningprojecten. Het werd ontwikkeld in 1970 en wordt veel gebruikt bij het modelleren, analyseren en simuleren van gegevens. Het heeft een uitgebreide bibliotheek met wiskundige functies voor lineaire algebra, numerieke analyse, matrixbewerkingen en datavisualisatie. Het heeft een gebruiksvriendelijke interface en een reeks tools die ontwikkelaars helpen bij signaal- en beeldverwerking, controlesystemen en financiële modellering. Het is een uitstekende taal met eigendomsrechten, wat impliceert dat de broncode niet vrij toegankelijk is.
Top Python-bibliotheken voor ML en DL die u in 2023 moet kennen
Hoewel veel programmeertalen nuttig zijn bij machine learning, wordt de programmeertaal Python het meest gebruikt omdat deze vele frameworks, modules, neurale netwerken en multidimensionale arrays ondersteunt.
Enkele van de beste Python-bibliotheken staan hieronder vermeld:
Bekijk deze Machine Learning-bibliotheken en kijk waar u ze kunt gebruiken.
Snel
Fastai is een op PyTorch gebaseerd open-source machine learning-framework dat abstracties op hoog niveau biedt voor deep learning-modeltraining. Verschillende functies, waaronder gegevensvoorverwerking, gegevensvergroting, gegevensmanipulatie, training en inferentie met behulp van geavanceerde deep learning-modellen, zijn beschikbaar via de bibliotheek.
Het is een echte aanrader omdat
- Robuuste gegevensvergroting: De bibliotheek genereert uitgebreid meer trainingsgegevens, waardoor de modelprestaties worden verbeterd.
- Gebruiksvriendelijke interface: Fastai presenteert een intuïtieve API om ervoor te zorgen dat gebruikers snel complexe ML-modellen kunnen bouwen en trainen.
- integratie: Het is zeer goed te integreren met andere bibliotheken zoals PyTorch (de basis) om het bouwen en trainen van deep learning-modellen te vergemakkelijken.
Hoewel de FastAI-bibliotheek veel voordelen heeft, zijn er ook enkele mogelijke nadelen.
- Het is een uitdaging voor beginners vanwege een abstractielaag op hoog niveau.
- Biedt beperkt maatwerk.
- Het heeft veel afhankelijkheden.
Machine Learning-bibliotheken in 2023
Bron: Fast.ai-forums
OpenCV
OpenCV (Open Source Computer Vision) is een uitbreidbare, open-source bibliotheek voor computervisie en machine learning die verschillende tools en technieken biedt voor beeld- en video-analyse. Het is een fantastische optie voor zowel beginnende als ervaren machine learning-ontwikkelaars vanwege de platformonafhankelijke compatibiliteit, omvangrijke community en gebruiksvriendelijke gebruikersinterface.
Andere voordelen die OpenCV biedt:
-
- Een reeks tools en technieken: Het biedt verschillende hulpmiddelen en technieken voor beeld- en video-analyse, waaronder beeldverwerking, objectdetectie, gezichtsherkenning en optische tekenherkenning (OCR).
- Gratis en open source: OpenCV is een gratis en open-sourcebibliotheek, wat betekent dat het door iedereen zonder licentiekosten kan worden gebruikt en gewijzigd.
- Integreerbaar: OpenCV is eenvoudig te integreren met andere Python-bibliotheken zoals TensorFlow en PyTorch.
Enkele nadelen van het werken met OpenCV:
- Beperkte ondersteuning voor diep leren vanwege traditionele algoritmen.
- Alleen geschikt voor het verwerken van afbeeldingen en video's, waardoor de effectiviteit bij andere gegevenstypen wordt beperkt.
- Steile leercurve voor beginners.
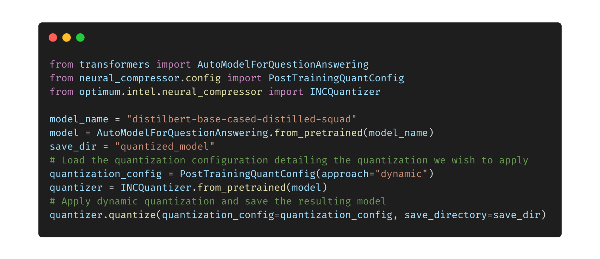
transformers
Hugging Face creëerde de open-source Transformers-bibliotheek voor machine learning. Er worden moderne NLP-modellen (natural language processing) geleverd die eenvoudig te trainen en te verfijnen zijn voor verschillende NLP-taken, waaronder tekstclassificatie, het beantwoorden van vragen en machinevertaling.
Transformers bibliotheekaanbiedingen
- Kolossale gemeenschap: De Transformers-bibliotheek heeft een omvangrijke en levendige ontwikkelaarscommunity die actief bijdraagt aan de ontwikkeling ervan en gebruikers tools en ondersteuning biedt.
- Zeer integreerbaar: De Transformers-bibliotheek kan eenvoudig worden geïntegreerd met populaire machine learning-bibliotheken zoals PyTorch en TensorFlow.
- Voorgetrainde modellen: Veel vooraf getrainde modellen in de Transformers-bibliotheek kunnen worden aangepast voor verschillende NLP-behoeften. Dit bespaart veel tijd en geld in vergelijking met het vanaf nul bouwen van modellen.
Hoewel de Transformers-bibliotheek veel voordelen heeft, zijn er ook enkele mogelijke nadelen waarmee u rekening moet houden:
- Hoewel de Transformers-bibliotheek solide tools biedt voor natuurlijke taalverwerking, is deze misschien niet zo geschikt voor andere soorten gegevens.
- Beperkte ondersteuning voor leren zonder toezicht.
- Uitgebreide rekenvereisten.
Bron: Knuffelend gezicht
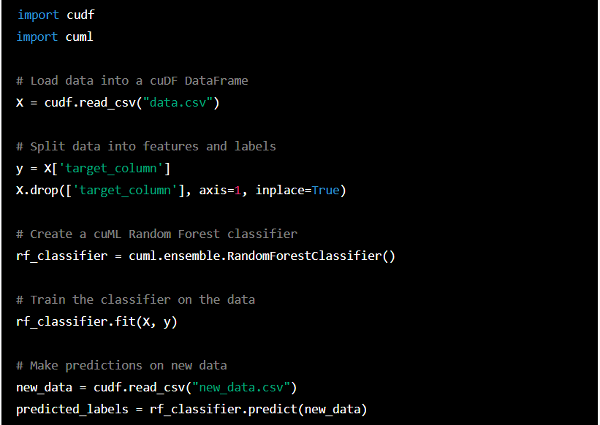
cuML
NVIDIA creëerde de open-source cuML-bibliotheek voor machine learning. Het biedt GPU-versnelde technieken voor verschillende machine-learningtaken zoals classificatie, regressie, clustering en dimensionaliteitsreductie. Enkele van de belangrijkste voordelen van het gebruik van de cuML-bibliotheek zijn:
- Verwerken van aanzienlijke hoeveelheden gegevens: De cuML-bibliotheek biedt mogelijkheden voor het verwerken van enorme hoeveelheden gegevens die moeilijk te verwerken zouden zijn op CPU-gebaseerde computers.
- GPU-versnelling: De cuML-bibliotheek is ontworpen om te draaien op NVIDIA GPU's, wat aanzienlijke versnellingen oplevert in vergelijking met CPU-gebaseerde machine learning-bibliotheken.
- Integratie met andere bibliotheken: De belangrijkste machine learning-bibliotheken Scikit-learn, PyTorch en TensorFlow kunnen allemaal snel worden verbonden met de cuML-bibliotheek.
Enkele nadelen:
- Geoptimaliseerd voor NVIDIA GPU's, kan het minder efficiënt zijn op niet-NVIDIA-hardware.
- Beperkte steun van de gemeenschap.
- Beperkte schaalbaarheid.
Scikit-Leren
Scikit leren is een van de meest populaire machine learning-bibliotheken. Het biedt tools voor het bouwen van voorspellende modellen en het uitvoeren van data-analyse.
Hier zijn enkele van de kritieke kenmerken van scikit-learn en de toepassing ervan in machine learning:
- Voorverwerking en functie-extractie: Scikit-learn biedt veel tools voor het voorbewerken van gegevens en het extraheren van functies uit datasets.
- Modelevaluatie: Scikit-learn biedt een reeks statistieken voor prestatie-evaluatie of verschillende ML-modellen, zoals voorspellende modellen, waaronder nauwkeurigheid, precisie en F1-score.
- Leren onder toezicht: Scikit-learn biedt verschillende algoritmen voor het bouwen van voorspellende modellen op basis van gelabelde gegevens, waaronder lineaire regressie, logistische regressie, beslissingsbomen, willekeurige bossen, ondersteunende vectormachines (SVM's) en neurale netwerken.
Hoewel scikit-learn een krachtige en veelgebruikte machine learning-bibliotheek is, zijn er ook enkele mogelijke nadelen:
- Beperkte ondersteuning voor big data: Scikit-learn is ontworpen om te werken met gegevens die in het geheugen passen, die mogelijk moeten worden herzien voor uitgebreide datasets.
- Beperkte ondersteuning voor diep leren: Scikit-learn heeft beperkte ondersteuning voor deep learning-algoritmen in vergelijking met andere bibliotheken zoals TensorFlow of PyTorch.
PyTorch
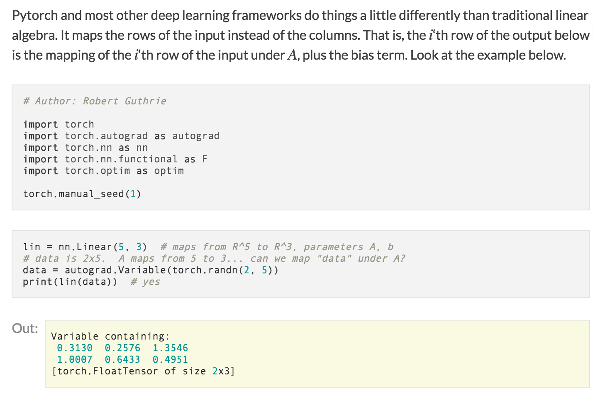
Torch is de basis van het open-source, op Python gebaseerde machine learning-pakket dat bekend staat als PyTorch. In het onderwerp van diepgaand leren, wordt het vaak gebruikt. Met behulp van een eenvoudige en begrijpelijke API stelt de dynamische computationele grafiek van PyTorch ontwikkelaars in staat neurale netwerken te creëren en te trainen.
Het is gunstig voor het produceren van:
- Dynamische rekengrafieken: PyTorch gebruikt een dynamische berekeningsgrafiek waarmee programmeurs de grafiek in realtime kunnen wijzigen terwijl het programma wordt uitgevoerd.
- GPU-versnelling wordt ondersteund door PyTorch en kan de trainingstijden voor complexe modellen drastisch verkorten.
- PyTorch biedt automatische differentiatie, vereenvoudigt de berekening van hellingen en optimaliseert modelparameters tijdens de training.
Er zijn echter ook enkele mogelijke nadelen waarmee rekening moet worden gehouden:
- PyTorch heeft een steile leercurve, vooral voor gebruikers die nog niet bekend zijn met deep learning of neurale netwerken.
- Het is mogelijk niet zo effectief schaalbaar als andere deep learning-bibliotheken voor grote datasets.
- Beperkte modelportabiliteit.
TensorFlow

Bron: tensorflow.org
Een van de meest bekende open-source machine learning-bibliotheken die door Google is gemaakt, heet TensorFlow. Het TensorFlow-pakket biedt het volgende:
- GPU-versnelling.
- Automatische differentiatie voor het berekenen van hellingen.
- Een hub voor herbruikbare machine learning-modellen.
Het is nuttig in deep learning-modellen, omdat het ontwikkelaars in staat stelt diepe neurale netwerken te bouwen en te trainen voor tal van toepassingen.
Tensoren hebben brede toepassingen:
- Natuurlijke taalverwerking (NLP): TensorFlow kan worden gebruikt voor NLP-taken zoals sentimentanalyse en taalvertaling.
- TensorFlow kan generatieve modellen maken, zoals generatieve vijandige netwerken en variatie-auto-encoders.
- Computer visie kunnen ook profiteren van deze Python-bibliotheek.
Hoewel TensorFlow een solide en populaire bibliotheek voor diep leren is, zijn er enkele mogelijke nadelen waarmee rekening moet worden gehouden:
- Beperkte ondersteuning voor traditionele algoritmen voor machine learning.
- Het moet beter schaalbaar zijn voor gedistribueerde systemen.
- Beperkte flexibiliteit.
Keras
Keras is een populaire open-source deep learning-bibliotheek die een hoogwaardige API biedt voor het bouwen en trainen van diepe neurale netwerken. Het werd gemaakt met de nadruk op rapid prototyping en experimenten. Het was bedoeld om gebruiksvriendelijk en eenvoudig te gebruiken te zijn.
De volgende zijn enkele voordelen van het gebruik van Keras:
- Makkelijk te gebruiken: Ontwikkelaars kunnen snel en eenvoudig diepe neurale netwerken ontwerpen en trainen met behulp van Keras dankzij de gebruiksvriendelijke API, waardoor een diepgaand begrip van de onderliggende wiskunde overbodig wordt.
- Flexibiliteit: Keras ondersteunt vele netwerktopologieën, waaronder auto-encoders, terugkerende neurale netwerken en convolutionele neurale netwerken.
- Draagbaarheid: TensorFlow, Microsoft Cognitive Toolkit en Theano zijn slechts enkele van de backends waarmee Keras compatibel is. Als gevolg hiervan is schakelen tussen backends eenvoudig op basis van uw unieke use case.
Hoewel Keras een gebruiksvriendelijke deep learning-bibliotheek is, zijn er ook enkele mogelijke nadelen.
- Het biedt mogelijk minder ondersteuning dan andere bibliotheken voor specifieke gespecialiseerde modellen, zoals neurale grafennetwerken.
- Biedt minder geavanceerde aanpassingen in vergelijking met PyTorch of TensorFlow.
- Beperkte onderzoeksondersteuning.
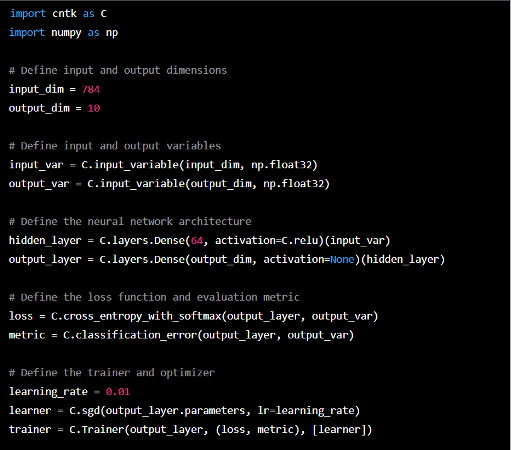
Microsoft ontwikkelde de bekende open-source Microsoft Cognitive Toolkit voor deep learning (CNTK). Het is ontworpen om zowel CPU- als GPU-verwerking aan te kunnen. Diepe neurale netwerktraining wordt geleverd met uitzonderlijke prestaties en schaalbaarheid.
Hier volgen enkele van de belangrijkste voordelen van CNTK bij machine learning:
- Hoge performantie: Door gebruik te maken van parallelle computerarchitecturen is het prestatiegeoptimaliseerd en kan het effectief omgaan met enorme datasets en ingewikkelde, diepe neurale netwerken.
- Flexibiliteit: Deep learning-modellen worden ondersteund voor verschillende toepassingen, waaronder objectidentificatie, beeldclassificatie en natuurlijke taalverwerking.
- Het ondersteunt gedistribueerde training, waarbij het trainingsproces over verschillende machines wordt verdeeld.
Hoewel het verschillende voordelen heeft, zijn er ook enkele nadelen waarmee rekening moet worden gehouden:
- CNTK is sterk geoptimaliseerd voor specifieke gebruikssituaties, zoals beeldherkenning, maar moet mogelijk flexibeler zijn.
- Microsoft heeft verklaard dat het na 2020 geen CNTK meer zal ontwikkelen; daarom krijgt het mogelijk geen updates of nieuwe functies.
PyCaret
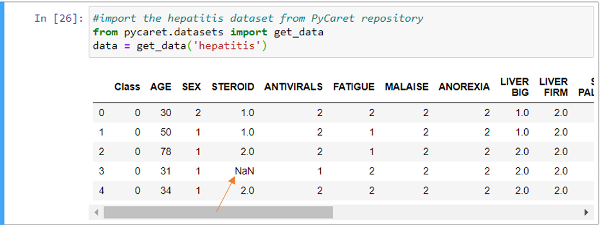
PyCaret is een open-source, low-code machine learning-bibliotheek in Python waarmee gebruikers snel machine learning-modellen kunnen prototypen, experimenteren en implementeren.
Hier zijn enkele belangrijke kenmerken en voordelen van PyCaret:
- Gestroomlijnde machine learning-workflow: Het biedt een gestroomlijnde workflow voor het bouwen, trainen, evalueren en implementeren van machine learning-modellen.
- Low-code-interface: Het biedt een low-code interface voor machine learning, waardoor het toegankelijk is voor gebruikers met weinig of geen programmeerervaring.
- Uitgebreide modelbibliotheek: PyCaret biedt een uitgebreide bibliotheek met machine learning-modellen, waaronder regressie, classificatie, clustering en anomaliedetectie.
Er zijn echter enkele nadelen waarmee rekening moet worden gehouden:
- Beperkingen gegevenstype: PyCaret is ontworpen om gedeelde gegevenstypen en -indelingen te verwerken, maar biedt mogelijk geen complexere gegevenstypen.
- Biedt weinig hyperparameterafstemming.
- PyCaret automatiseert veel aspecten van de machine learning-processen. Het kan het ook uitdagender maken om de onderliggende modellen en algoritmen te interpreteren.
Conclusie
Concluderend kunnen verschillende solide machine-learning-bibliotheken voor Python het maken en implementeren van machine-learning-modellen veel eenvoudiger maken. Deze machine learning-bibliotheken bevatten veel functies, waaronder modelselectie, hyperparameterafstemming, gegevensvisualisatie en gegevensvoorverwerking. Door deze bibliotheken te gebruiken, kunnen ontwikkelaars het machine learning-proces versnellen, tijd en moeite besparen en betere resultaten behalen.
Voor iedereen die geïnteresseerd is in het bestuderen, delen en samenwerken aan een reeks aan datawetenschap en analyse gerelateerde onderwerpen, is Analytics Vidhya (AV) een platform bij uitstek. Nu je de beste machine learning-bibliotheken in Python kent en er praktisch meer over wilt leren, kun je de vele tutorials en cursussen bekijken die beschikbaar zijn op Analytics Vidhya. Je kunt daar een verscheidenheid aan materialen vinden die je kunnen instrueren over het omkeren van een string in Python, inclusief artikelen, tutorials, cursussen en wedstrijden. Over het algemeen kan Analytics Vidhya een waardevol hulpmiddel zijn voor iedereen die Python, Machine Learning en Data Science wil leren, of je nu een beginner bent of een ervaren professional.
Veelgestelde Vragen / FAQ
<h4 id="Q1._Welke_bibliotheek_wordt_gebruikt_voor_machine_learning?“>Q1. Welke bibliotheek wordt gebruikt voor machine learning?
A. Er worden veel bibliotheken gebruikt bij machine learning, en elk daarvan biedt een unieke set functies en mogelijkheden. Enkele van de meest populaire machine learning-bibliotheken zijn Keras, Scikit-Learn, PyTorch, TensorFlow, Matpotlib, NumPy, enz.
<h4 id="V2._Is_Panda's_een_machine_learning_library?“>K2. Is Pandas een machine learning-bibliotheek?
A. Pandas is een prominente open-sourcebibliotheek die veel wordt gebruikt voor datawetenschap en machine learning-taken waarbij datamanipulatie en -analyse betrokken zijn. Het is een flexibel en veelzijdig Python-pakket dat verschillende datastructuren en wiskundige bewerkingen ondersteunt.
<h4 id="Q3._Wat_zijn_AI_ML_bibliotheken?_“>Q3. Wat zijn AI ML-bibliotheken?
A. AI/ML-bibliotheken zijn een raamwerk dat bestaat uit een reeks routines en vooraf gedefinieerde functies die zijn geschreven in veelgebruikte programmeertalen. Deze bibliotheken bieden end-to-end software- en applicatieontwikkelingstechnologieën met kunstmatige intelligentie en machine learning voor commercieel gebruik.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/03/machine-learning-libraries-in-2023/

