Introductie
Op het gebied van computer vision bestaan er verschillende technieken voor detectie van live objecten, waaronder Faster R-CNN, SSD en YOLO. Elke techniek heeft zijn beperkingen en voordelen. Hoewel Faster R-CNN misschien uitblinkt in nauwkeurigheid, presteert het mogelijk minder goed in realtime scenario's, wat leidt tot een verschuiving naar de YOLO-algoritme.
Objectdetectie is van fundamenteel belang in computervisie, waardoor machines objecten binnen een frame of scherm kunnen identificeren en lokaliseren. In de loop der jaren zijn er verschillende algoritmen voor objectdetectie ontwikkeld, waarbij YOLO als een van de meest succesvolle naar voren kwam. Onlangs is YOLOv8 geïntroduceerd, waardoor de mogelijkheden van het algoritme verder zijn verbeterd.
In deze uitgebreide gids onderzoeken we drie prominente algoritmen voor objectdetectie: snellere R-CNN, SSD (Single Shot MultiBox Detector) en YOLOv8. We bespreken de praktische aspecten van het implementeren van deze algoritmen, waaronder het opzetten van een virtuele omgeving en het ontwikkelen van een Streamlit-applicatie.
Leerdoel
- Begrijp Faster R-CNN, SSD en YOLO en analyseer de verschillen daartussen.
- Praktische ervaring opdoen met het implementeren van live objectdetectiesystemen met behulp van OpenCV, Supervision en YOLOv8.
- Het beeldsegmentatiemodel begrijpen met behulp van de Roboflow-annotatie.
- Creëer een Streamlit-applicatie voor een eenvoudige gebruikersinterface.
Laten we eens kijken hoe u beeldsegmentatie kunt uitvoeren met YOLOv8!
Inhoudsopgave
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Snellere R-CNN
Faster R-CNN (Faster Region-based Convolutional Neural Network) is een op deep learning gebaseerd algoritme voor objectdetectie. Het wordt geëvalueerd met behulp van de R-CNN- en Fast R-CNN-frameworks en kan worden beschouwd als een uitbreiding van Fast R-CNN.
Dit algoritme introduceert het Region Proposal Network (RPN) om regiovoorstellen te genereren, ter vervanging van de selectieve zoekactie die in R-CNN wordt gebruikt. De RPN deelt convolutionele lagen met het detectienetwerk, waardoor efficiënte end-to-end training mogelijk is.
De gegenereerde regiovoorstellen worden vervolgens ingevoerd in een Fast R-CNN-netwerk voor verfijning van de selectiekaders en objectclassificatie.
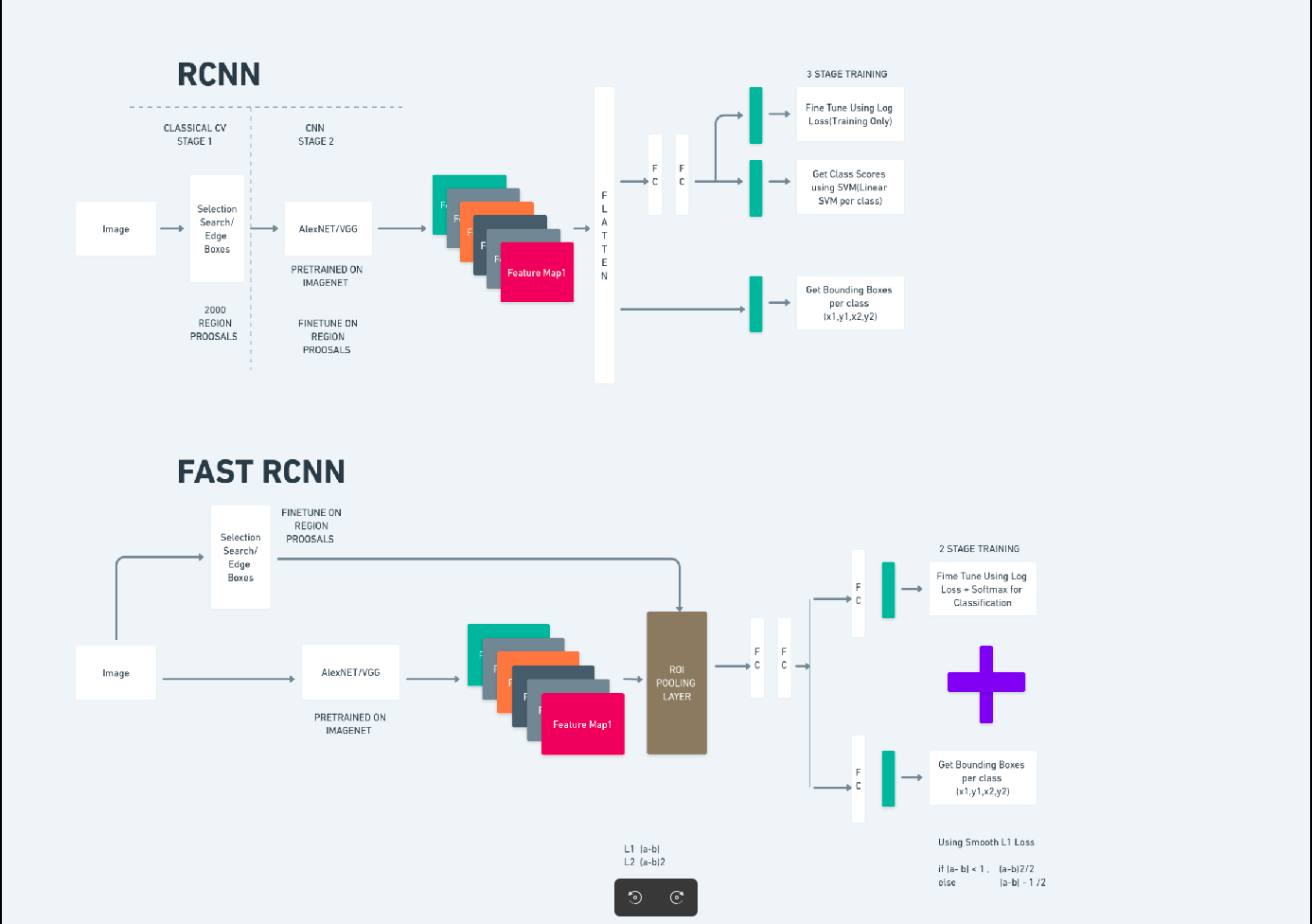
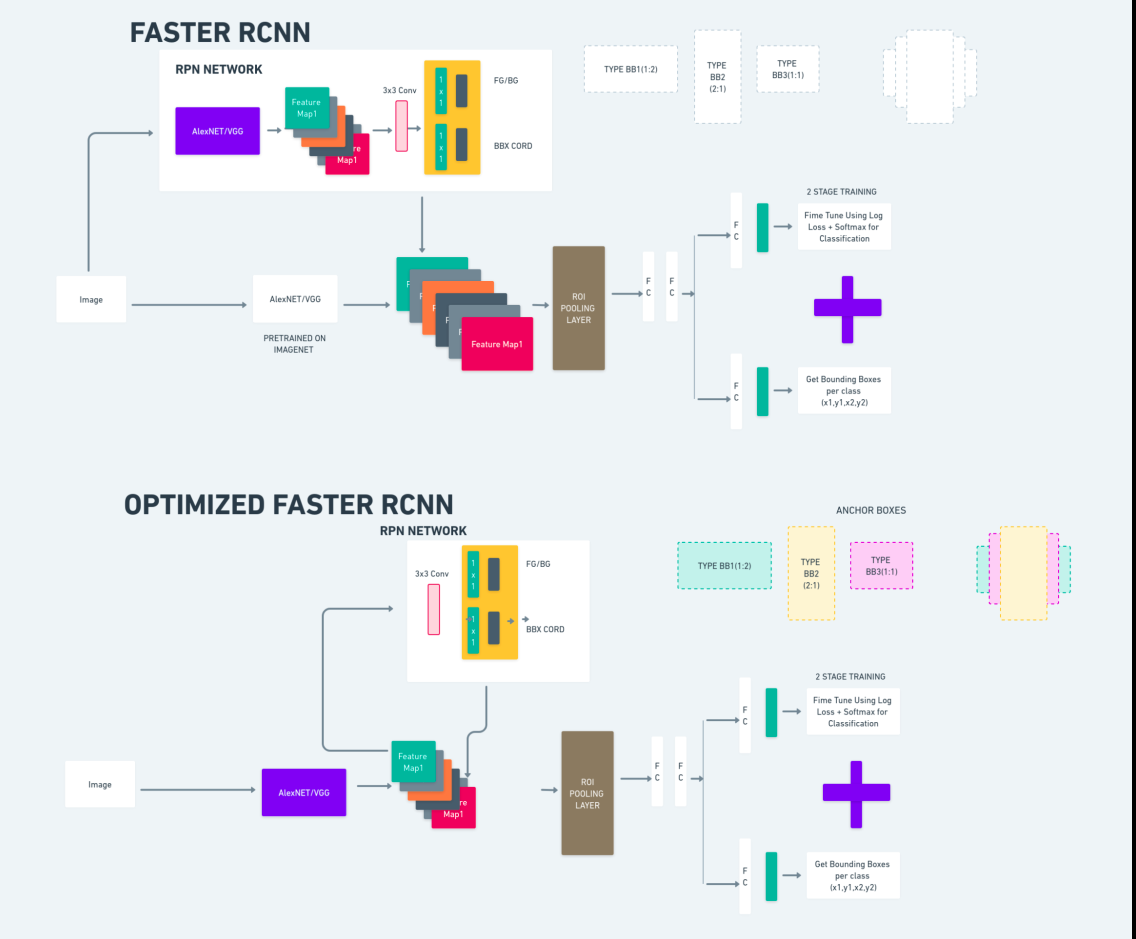
Het bovenstaande diagram illustreert de Faster R-CNN-familie uitgebreid en is gemakkelijk te begrijpen voor het evalueren van elk algoritme.
Single Shot MultiBox-detector (SSD)
De Single Shot MultiBox-detector (SSD) is populair bij objectdetectie en wordt voornamelijk gebruikt bij computervisietaken. Bij de vorige methode, Faster R-CNN, volgden we twee stappen: de eerste stap betrof het detectiegedeelte en de tweede betrof regressie. Bij SSD voeren we echter slechts één detectiestap uit. SSD werd in 2016 geïntroduceerd om tegemoet te komen aan de behoefte aan een snel en nauwkeurig objectdetectiemodel.

SSD heeft verschillende voordelen ten opzichte van eerdere objectdetectiemethoden zoals Faster R-CNN:
- Efficiëntie: SSD is een detector in één fase, wat betekent dat hij direct de grenskaders en klassescores voorspelt zonder dat er een afzonderlijke stap voor het genereren van voorstellen nodig is. Dit maakt het sneller vergeleken met tweetrapsdetectoren zoals Faster R-CNN.
- End-to-end training: SSD kan end-to-end worden getraind, waardoor zowel het basisnetwerk als de detectiekop gezamenlijk worden geoptimaliseerd, wat het trainingsproces vereenvoudigt.
- Multi-scale Feature Fusion: SSD werkt op feature maps op meerdere schalen, waardoor objecten van verschillende groottes effectiever kunnen worden gedetecteerd.
SSD biedt een goede balans tussen snelheid en nauwkeurigheid, waardoor het geschikt is voor realtime toepassingen waarbij zowel prestaties als efficiëntie van cruciaal belang zijn.
Je kijkt maar één keer (YOLOv8)
In 2015 werd You Only Look Once (YOLO) geïntroduceerd als een objectdetectie-algoritme in een onderzoekspaper van Joseph Redmon, Santosh Divvala, Ross Girshick en Ali Farhadi. YOLO is een single-shot-algoritme dat een object in één keer direct classificeert door slechts één neuraal netwerk de begrenzingsvakken en klassenkansen te laten voorspellen met behulp van een volledig beeld als invoer.
Laten we YOLOv8 nu begrijpen als een state-of-the-art vooruitgang in real-time objectdetectie met verbeterde nauwkeurigheid en snelheid. Met YOLOv8 kunt u vooraf getrainde modellen gebruiken, die al zijn getraind op een enorme dataset zoals COCO (Common Objects in Context). Beeldsegmentatie biedt informatie op pixelniveau over elk object, waardoor een meer gedetailleerde analyse en begrip van de beeldinhoud mogelijk wordt.
Hoewel beeldsegmentatie computationeel duur kan zijn, integreert YOLOv8 deze methode in zijn neurale netwerkarchitectuur, waardoor efficiënte en nauwkeurige objectsegmentatie mogelijk wordt.
Werkingsprincipe van YOLOv8
YOLOv8 werkt door het invoerbeeld eerst in rastercellen te verdelen. Met behulp van deze rastercellen voorspelt YOLOv8 de selectiekaders (bbox) met klassenwaarschijnlijkheden.
Daarna gebruikt YOLOv8 het NMS-algoritme om overlapping te verminderen. Als er bijvoorbeeld meerdere auto's in de afbeelding aanwezig zijn, wat resulteert in overlappende selectiekaders, helpt het NMS-algoritme deze overlap te verminderen.
Verschil tussen varianten van Yolo V8: YOLOv8 is beschikbaar in drie varianten: YOLOv8, YOLOv8-L en YOLOv8-X. Het belangrijkste verschil tussen de varianten is de omvang van het backbone-netwerk. YOLOv8 heeft het kleinste backbone-netwerk, terwijl YOLOv8-X het grootste backbone-netwerk heeft.
Verschil tussen snellere R-CNN, SSD en YOLO
| Aspect | Snellere R-CNN | SSD | YOLO |
|---|---|---|---|
| Architectuur | Tweetrapsdetector met RPN en Fast R-CNN | Eentrapsdetector | Eentrapsdetector |
| Regionale voorstellen | Ja | Nee | Nee |
| Detectiesnelheid | Langzamer vergeleken met SSD en YOLO | Sneller vergeleken met snellere R-CNN, langzamer dan YOLO | Zeer snel |
| Nauwkeurigheid | Over het algemeen hogere nauwkeurigheid | Evenwichtige nauwkeurigheid en snelheid | Behoorlijke nauwkeurigheid, vooral voor realtime toepassingen |
| Flexibiliteit | Flexibel, kan verschillende objectgroottes en beeldverhoudingen aan | Kan meerdere schalen van objecten aan | Kan moeite hebben met de nauwkeurige lokalisatie van kleine objecten |
| Uniforme detectie | Nee | Nee | Ja |
| Afweging tussen snelheid en nauwkeurigheid | Over het algemeen wordt snelheid opgeofferd voor nauwkeurigheid | Brengt snelheid en nauwkeurigheid in evenwicht | Geeft prioriteit aan snelheid met behoud van behoorlijke nauwkeurigheid |
Wat is segmentatie?
Zoals we weten betekent segmentatie dat we het grote beeld in kleinere groepen verdelen op basis van bepaalde kenmerken. Laten we beeldsegmentatie begrijpen, de computervisietechniek die wordt gebruikt om een afbeelding in verschillende segmenten of regio's te verdelen. Omdat de afbeeldingen zijn gemaakt van pixels en bij beeldsegmentatie worden pixels gegroepeerd op basis van de gelijkenis in kleur, intensiteit, textuur of andere visuele eigenschappen.
Als een afbeelding bijvoorbeeld bomen, auto's of mensen bevat, verdeelt de afbeeldingssegmentatie de afbeelding in verschillende klassen die betekenisvolle objecten of delen van de afbeelding vertegenwoordigen. Beeldsegmentatie wordt veel gebruikt op verschillende gebieden, zoals medische beeldvorming, analyse van satellietbeelden, objectherkenning in computervisie en meer.

In het segmentatiegedeelte creëren we in eerste instantie het eerste YOLOv8-segmentatiemodel met behulp van Robflow. Vervolgens importeren we het segmentatiemodel om de segmentatietaak uit te voeren. De vraag rijst: waarom creëren we het segmentatiemodel als de taak alleen met een detectiealgoritme kan worden voltooid?
Door segmentatie kunnen we het volledige lichaamsbeeld van een klas verkrijgen. Terwijl detectie-algoritmen zich richten op het detecteren van de aanwezigheid van objecten, zorgt segmentatie voor een nauwkeuriger begrip door de exacte grenzen van objecten af te bakenen. Dit leidt tot een nauwkeurigere lokalisatie en begrip van de objecten in het beeld.
Segmentatie brengt doorgaans echter een hogere tijdscomplexiteit met zich mee in vergelijking met detectiealgoritmen, omdat hiervoor extra stappen nodig zijn, zoals het scheiden van annotaties en het maken van het model. Ondanks dit nadeel kan de grotere precisie die door segmentatie wordt geboden, opwegen tegen de rekenkosten bij taken waarbij nauwkeurige objectafbakening cruciaal is.
Stapsgewijze livedetectie en beeldsegmentatie met YOLOv8
In dit concept onderzoeken we de stappen voor het creëren van een virtuele omgeving met behulp van conda, het activeren van de venv en het installeren van de vereistenpakketten met behulp van pip. eerst maken we het normale Python-script en daarna maken we de gestroomlijnde applicatie.
Stap 1: Creëer een virtuele omgeving met Conda
conda create -p ./venv python=3.8 -yStap 2: Activeer de virtuele omgeving
conda activate ./venv
Stap 3: Maak vereisten.txt aan
Open de terminal en plak het onderstaande script:
touch requirements.txtStap 4: Gebruik het Nano-commando en bewerk de vereisten.txt
Na het maken van de eisen.txt schrijft u de volgende opdracht voor het bewerken van eisen.txt
nano requirements.txtNadat u het bovenstaande script hebt uitgevoerd, kunt u deze gebruikersinterface zien.
Schrijf haar vereiste pakketten.
ultralytics==8.0.32
supervision==0.2.1
streamlitDruk vervolgens op “ctrl+o”(deze opdracht slaat het bewerkingsgedeelte op) en druk vervolgens op de "Enter"
Na het indrukken van de “Ctrl+x”. u kunt het bestand afsluiten. en naar het hoofdpad gaan.
Stap 5: Het installeren van de vereisten.txt
pip install -r requirements.txtStap 6: Maak het Python-script
Schrijf in de terminal het volgende script of we kunnen commando zeggen.
touch main.pyNadat u main.py hebt gemaakt, opent u de vs-code en gebruikt u de opdracht schrijven in terminal,
code Stap 7: Het Python-script schrijven
import cv2
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
cv2.imshow("yolov8", frame)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
Nadat je deze opdracht hebt uitgevoerd, kun je zien dat je camera open is en een deel van jou detecteert. zoals geslachts- en achtergronddelen.
Stap 7: Maak een gestroomlijnde app
import cv2
import streamlit as st
from ultralytics import YOLO
import supervision as sv
# Define the frame width and height for video capture
frame_width = 1280
frame_height = 720
def main():
# Set page title and header
st.title("Live Object Detection with YOLOv8")
# Button to start the camera
start_camera = st.button("Start Camera")
if start_camera:
# Initialize video capture from default camera
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, frame_width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_height)
# Load YOLOv8 model
model = YOLO("yolov8l.pt")
# Initialize box annotator for visualization
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
# Main loop for video processing
while True:
# Read frame from video capture
ret, frame = cap.read()
# Perform object detection using YOLOv8
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
# Prepare labels for detected objects
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
# Annotate frame with bounding boxes and labels
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
# Display annotated frame
st.image(frame, channels="BGR", use_column_width=True)
# Check for quit key
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# Release video capture
cap.release()
if __name__ == "__main__":
main()
In dit script maken we de gestroomlijnde applicatie en maken we de knop zodat na het indrukken van de knop de camera van uw apparaat open is en het deel in het frame detecteert.
Voer dit script uit met deze opdracht.
streamlit run app.py
# first create the app.py then paste the above code and run this script.Stel dat u na het uitvoeren van de bovenstaande opdracht een reikwijdtefout krijgt, zoals:
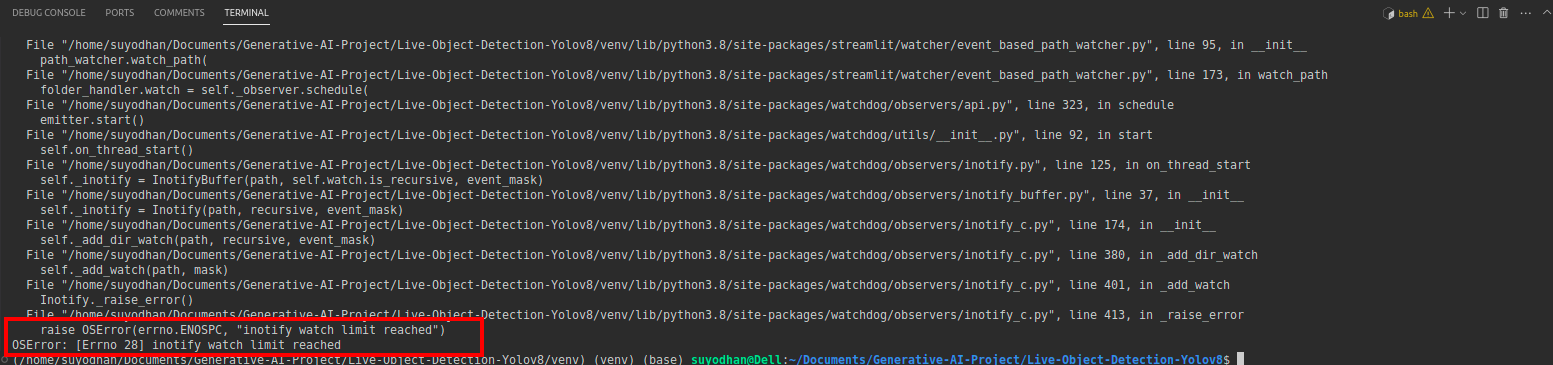
druk vervolgens op deze opdracht,
sudo sysctl fs.inotify.max_user_watches=524288Nadat je het commando hebt gebruikt waarmee je je wachtwoord wilt schrijven, omdat we het sudo-commando sudo is god gebruiken :)
Voer het script opnieuw uit. en je kunt de gestroomlijnde applicatie zien.
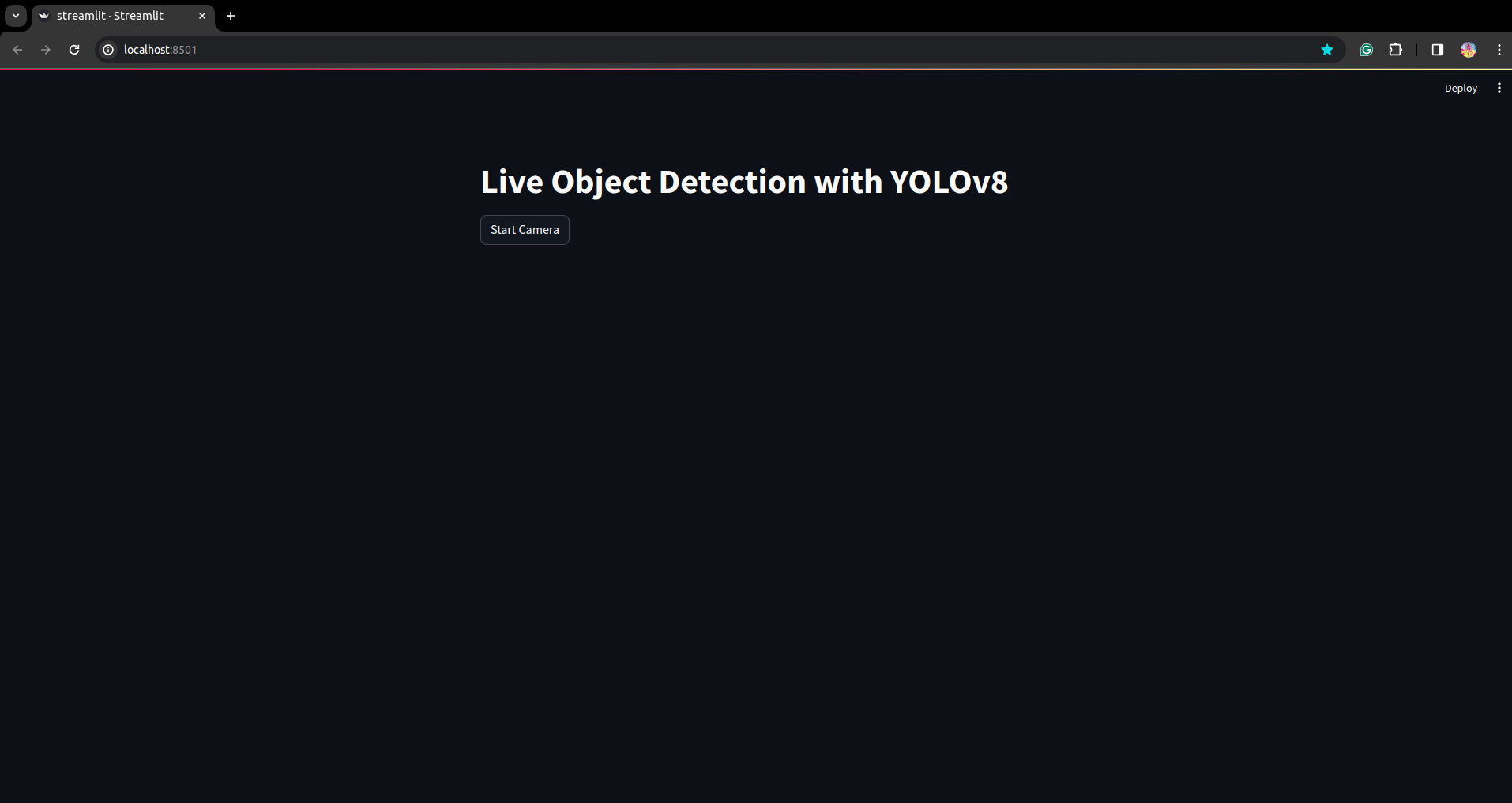
Hier kunnen we een succesvolle live detectie-applicatie maken. In het volgende deel zullen we het segmentatiegedeelte zien.
Stappen voor annotatie
Stap 1: Roboflow-installatie
Na het ondertekenen van de “Project aanmaken”. hier kunt u de project- en annotatiegroep maken.

Stap 2: Dataset downloaden
Hier beschouwen we het eenvoudige voorbeeld, maar u wilt het gebruiken voor uw probleemstelling, dus ik gebruik hier de duck-dataset.
Ga dit link en download de duck-dataset.

Pak de map uit. Daar kun je de drie mappen zien: trainen, testen en val.
Stap 3: Uploaden van de dataset op roboflow
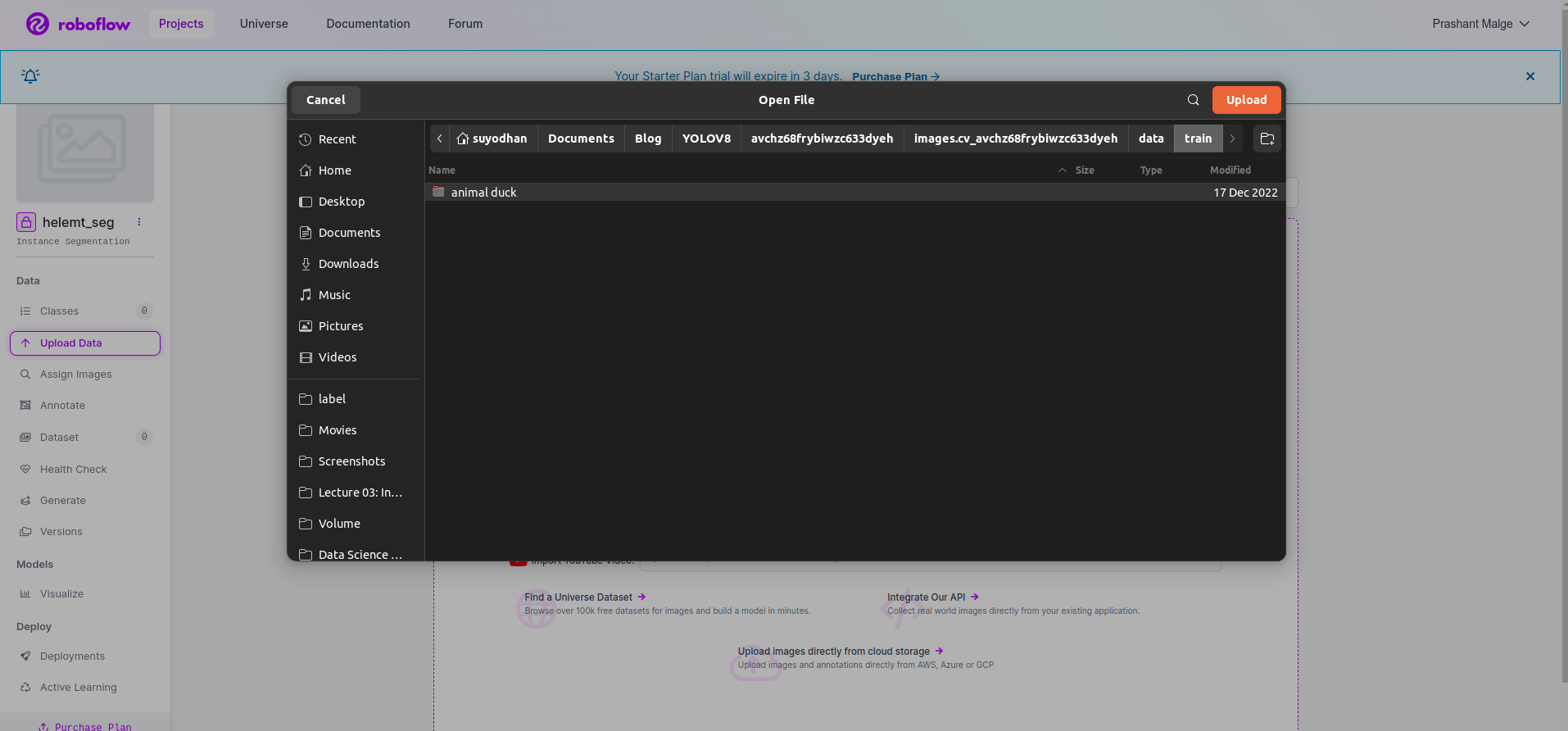
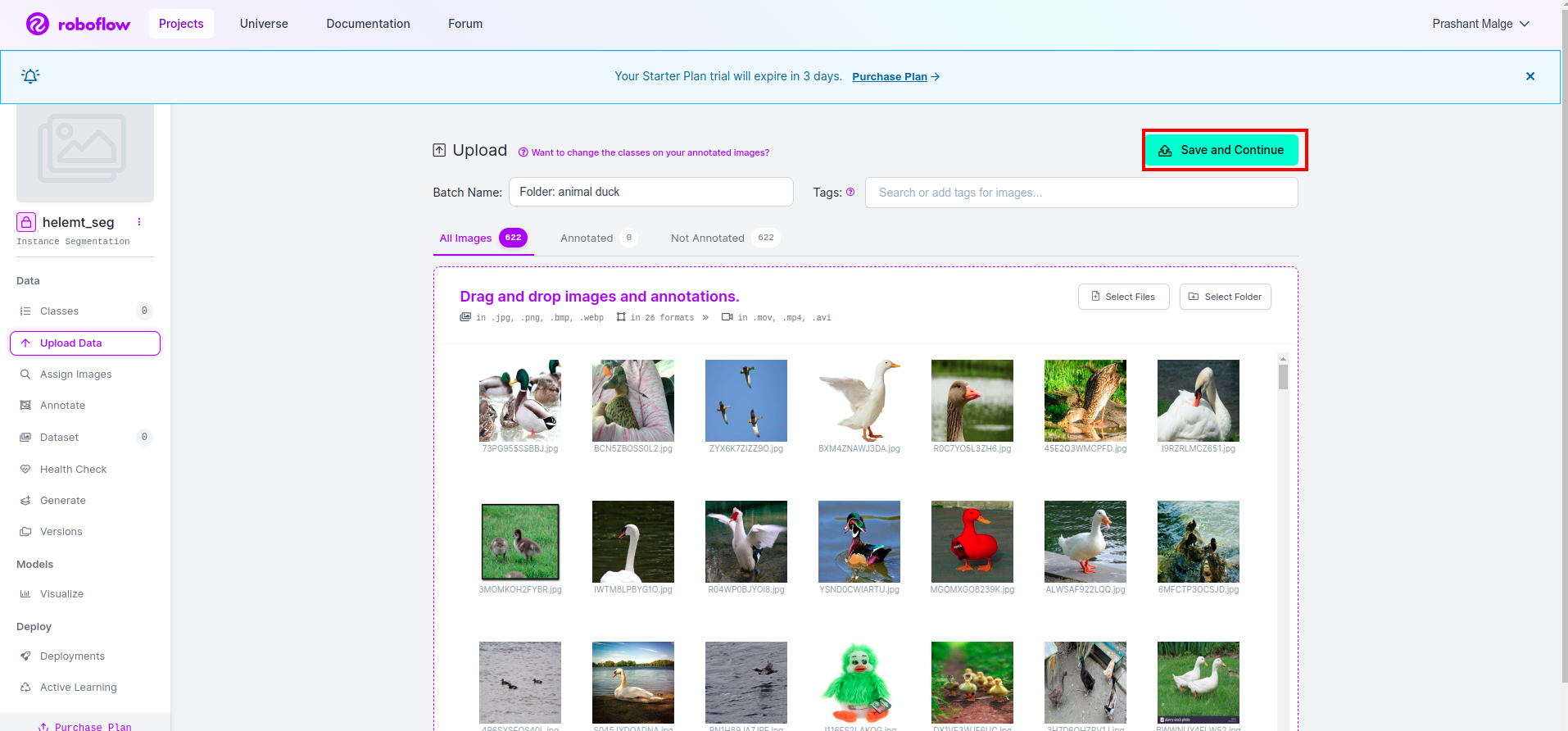
Nadat u het project in roboflow hebt gemaakt, kunt u deze gebruikersinterface hier zien. U kunt uw dataset uploaden, dus upload alleen afbeeldingen van treinonderdelen, selecteer de "selecteer map" optie.
Klik vervolgens op de "opslaan en doorgaan" optie zoals ik markeer in een rood rechthoekig vak
Stap 4: Voeg de klassenaam toe
Ga dan naar de klasse onderdeel aan de linkerkant van het rode vakje aanvinken. en schrijf de klassenaam als eend, nadat u op het groene vakje hebt geklikt.
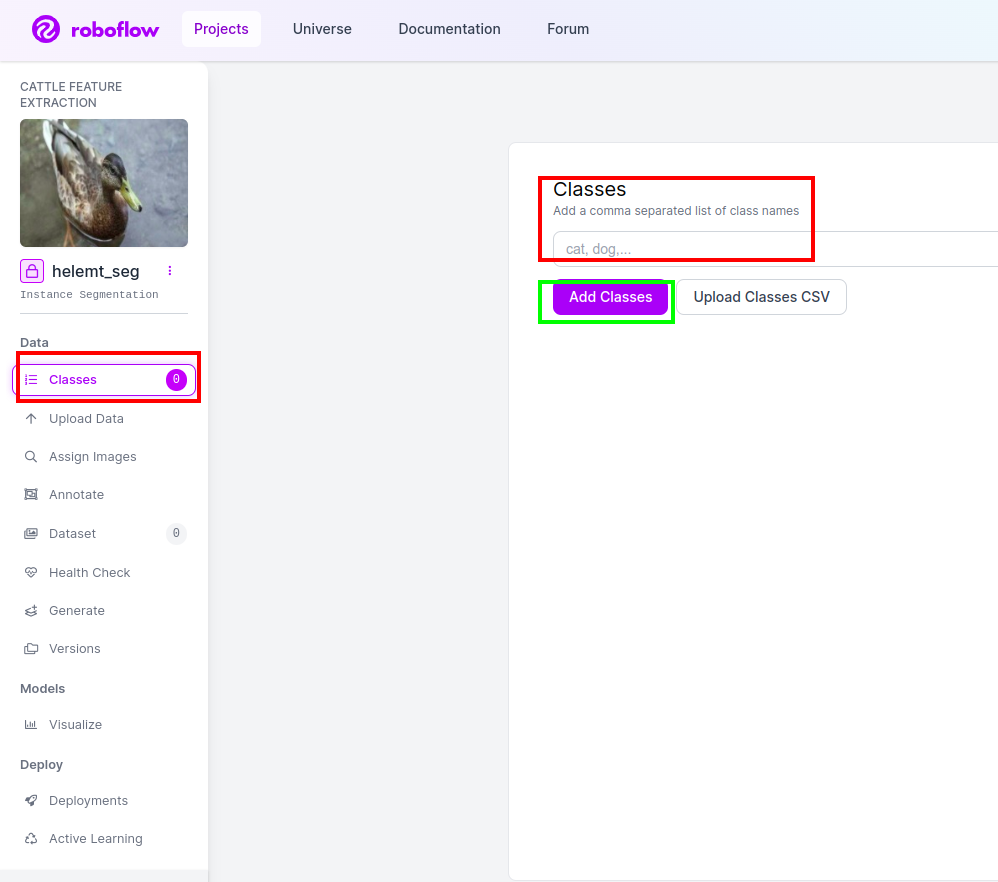
Nu is onze installatie voltooid en is het volgende deel, zoals het annotatiegedeelte, ook eenvoudig.
Stap 5: Start de annotatie gedeelte
Ga naar uw annotatie optie Ik heb het in het rode vak gemarkeerd en klik vervolgens op het annoatiegedeelte starten, zoals ik in het groene vak heb gemarkeerd.
Klik op de eerste afbeelding waarop u deze gebruikersinterface kunt zien. Nadat u dit heeft gezien, klikt u op de optie voor handmatige annotatie.
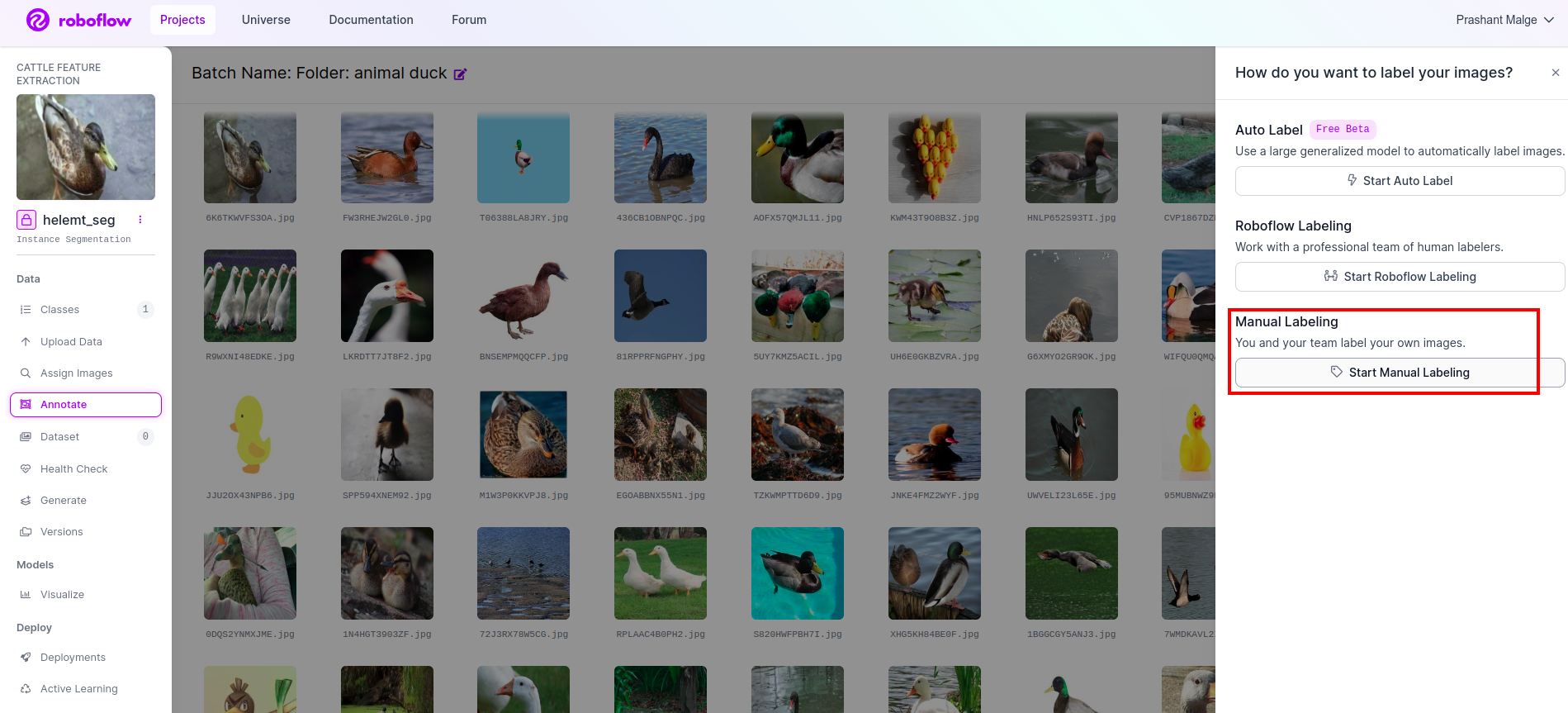
Voeg vervolgens uw e-mailadres of de naam van uw teamgenoot toe, zodat u de taak kunt toewijzen.
Klik op de eerste afbeelding waarop u deze gebruikersinterface kunt zien. Klik hier op het rode vakje zodat u het multipolynoommodel kunt selecteren.
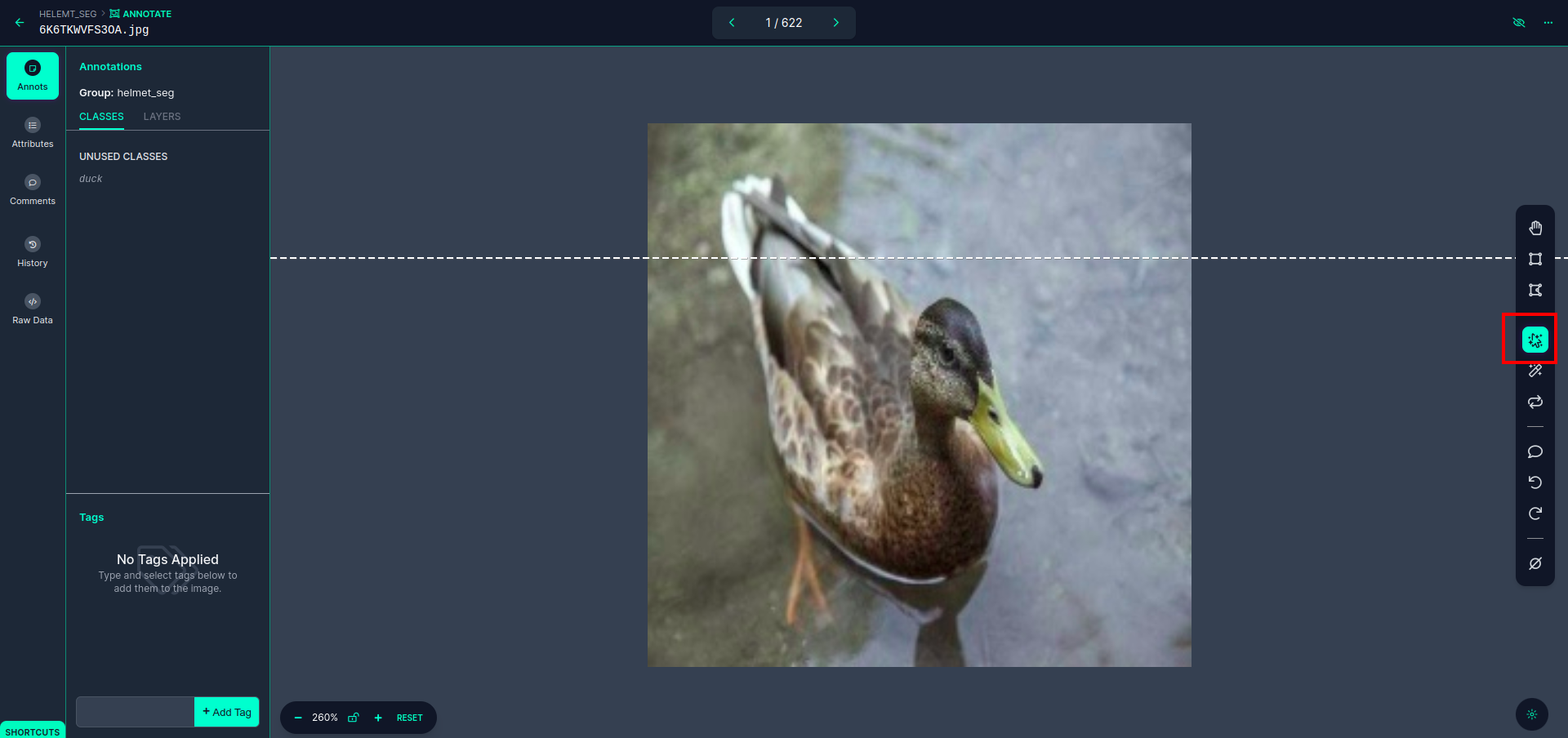
Nadat u op het rode vakje hebt geklikt, selecteert u het standaardmodel en klikt u op het duck-object. Hierdoor wordt de afbeelding automatisch gesegmenteerd. Klik vervolgens op het volgende deel en sla het op. Je ziet dan de linkerkant gemarkeerd in een rood vak, waar je de klasnaam kunt zien.
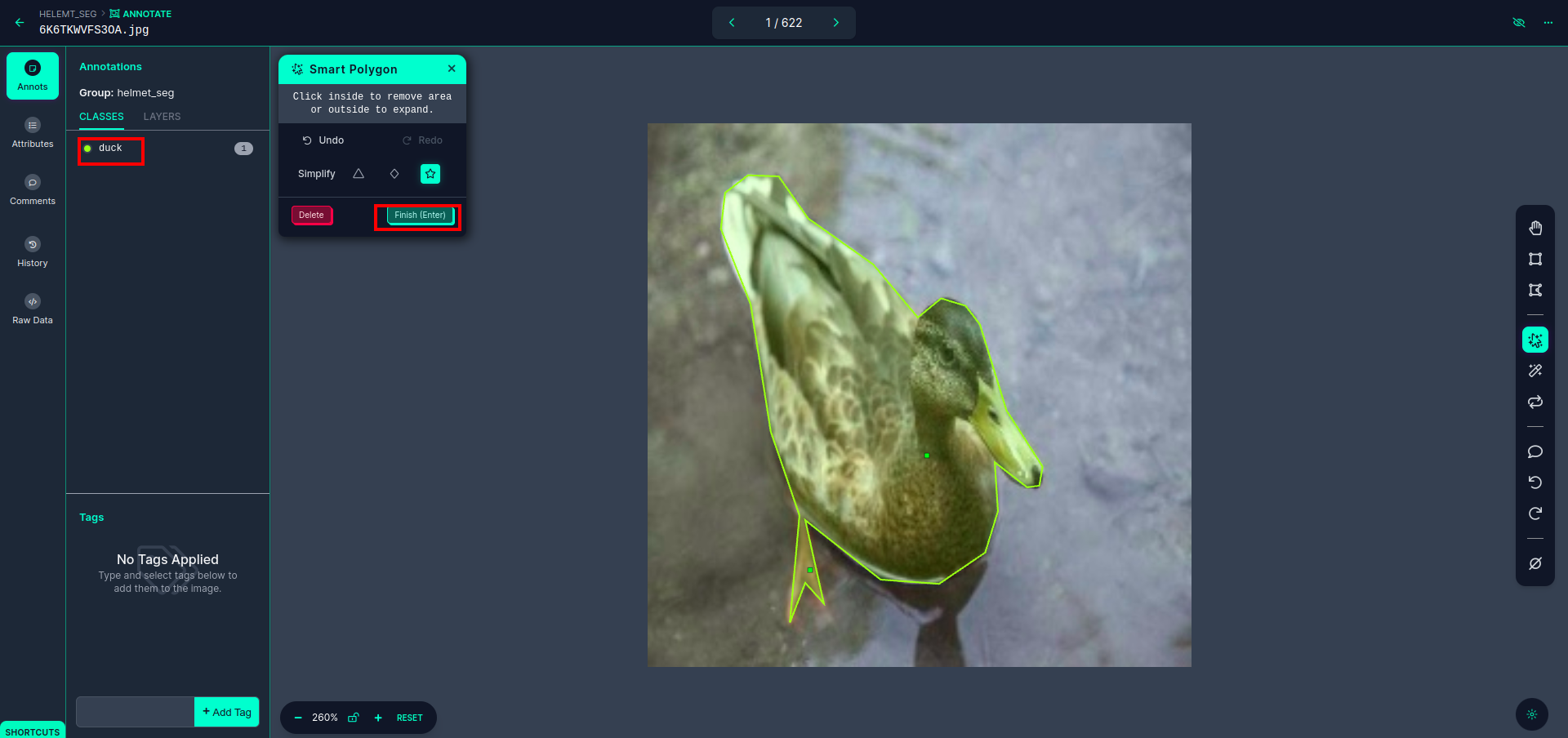
Klik op de opslaan&invoeren keuze. annoteer alle afbeeldingen.
Voeg de afbeeldingen toe voor het YOLOv8-formaat. Aan de rechterkant ziet u de optie om afbeeldingen toe te voegen in het annotatiegedeelte. Hier worden twee delen gemaakt: één voor geannoteerde afbeeldingen en één voor niet-geannoteerde afbeeldingen.
- Klik eerst op de linkerkant “annoteren" optie dan toevoegen de afbeeldingen naar de dataset.
- Klik vervolgens op de volgende “Afbeeldingen toevoegen'.
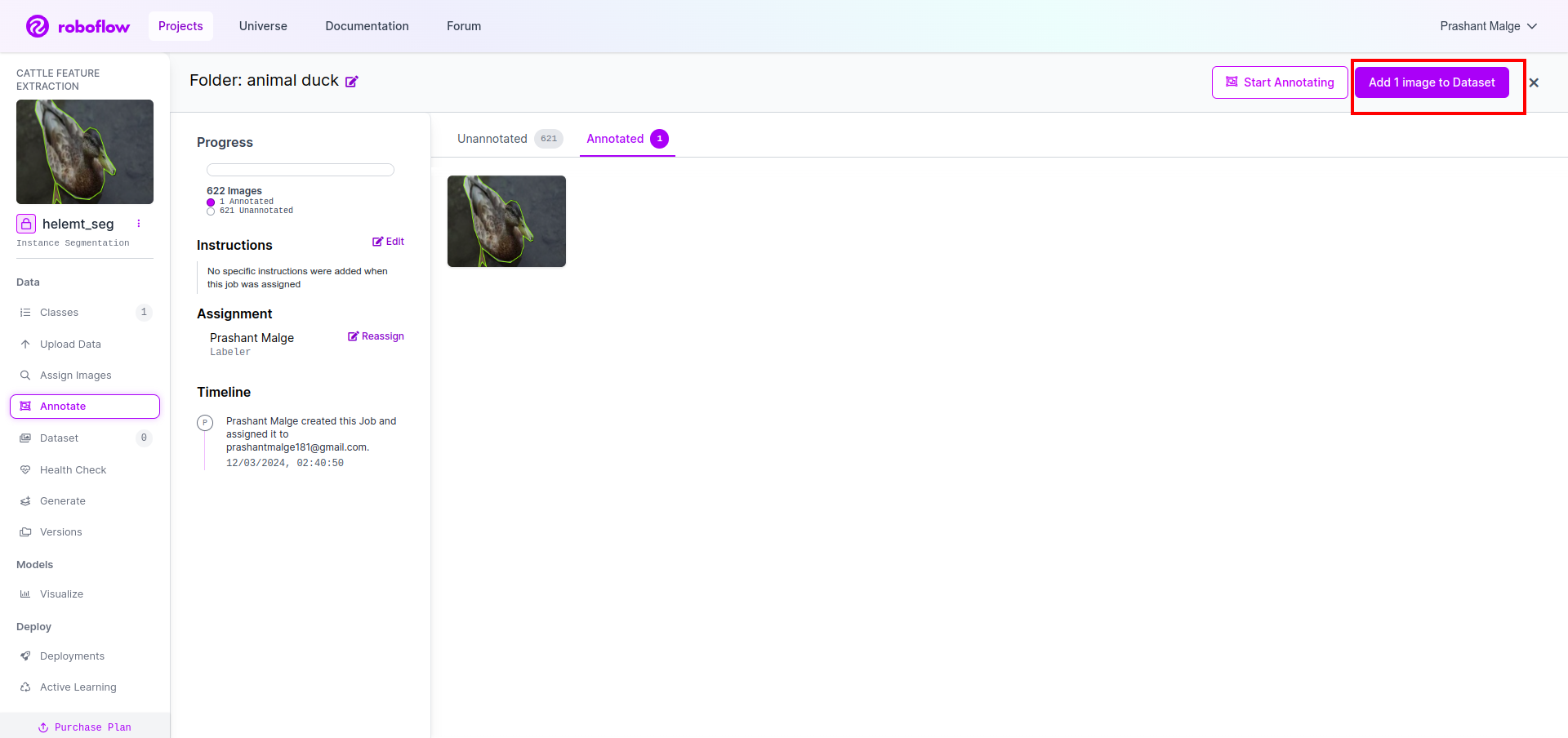
Nu maken we als laatste de dataset, dus klik op de optie "Genereren" aan de linkerkant, vink vervolgens de optie aan en druk op de optie conitune.
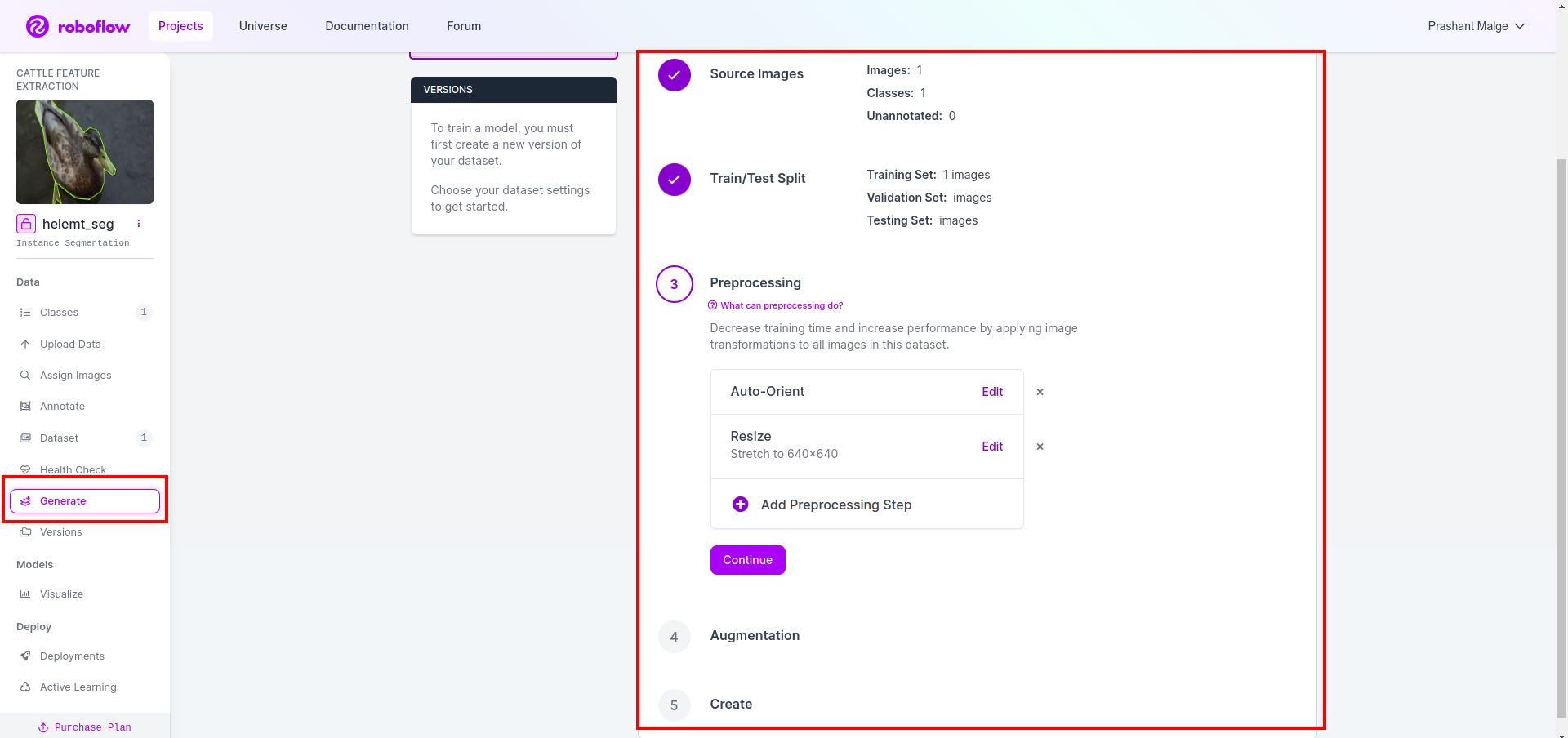
Vervolgens krijgt u de gebruikersinterface van de optie voor het splitsen van gegevenssets. Hier kunt u de train-, test- en val-mappen bekijken waarvan de afbeeldingen automatisch worden gesplitst. en klik op het bovenstaande rode vakje Optie Gegevensset exporteren en download het zip-bestand. de mapstructuur van het zip-bestand is als ...
root_file.zip
│
├── test
│ ├── Images
│ └── labels
│
├── train
│ ├── Images
│ └── labels
│
├── val
│ ├── Images
│ └── labels
│
├── data.yaml
└── Readme.roboflow.txt
Stap6: Schrijf het script voor het trainen van het beeldsegmentatiemodel
In dit deel maakt u eerst het Google Collab-bestand met Drive en uploadt u vervolgens uw dataset. en koppel de Google Drive met Google Collab.
1. Gebruik deze opdracht voor Google Drive koppelen
from google.colab import drive
drive.mount('/content/gdrive')2. Definieer de gegevensdirectory Gebruik de constante variabele.
DATA_DIR = '/content/drive/MyDrive/YoloV8/Data/'3. Het vereiste pakket installeren, Ultralytics installeren
!pip install ultralytics4. Importeren van de bibliotheken
import os
from ultralytics import YOLO5. Laad voorgetrainde YOLOv8 model (hier hebben we een ander model, bekijk ook de officiële documentatie, daar kunt u het verschillende model zien)
model = YOLO('yolov8n-seg.pt')
# load a pretrained model (recommended for training)
6. Train het model
model.train(data='/content/drive/MyDrive/YoloV8/Data/data.yaml', epochs=2, imgsz=640)
# Update the path & and join this line together Controleer uw schijf niet. De map met de modelnaam wordt gemaakt en het model wordt opgeslagen voor de voorspelling dat we dit model willen hebben.
7. Voorspel het model
#Update the path
model_path = '/content/drive/MyDrive/YoloV8/Model/train2/weights/last.pt'
#Update the path
image_path = '/content/drive/MyDrive/YoloV8/Data/val/1be566eccffe9561.png'
img = cv2.imread(image_path)
H, W, _ = img.shape
model = YOLO(model_path)
results = model(img)
for result in results:
for j, mask in enumerate(result.masks.data):
mask = mask.numpy() * 255
mask = cv2.resize(mask, (W, H))
cv2.imwrite('./output.png', mask)Hier kunt u zien dat de segmentatieafbeelding is opgeslagen.

Nu kunnen we eindelijk zowel live detectie- als beeldsegmentatiemodellen bouwen.
Conclusie
In deze blog verkennen we live objectdetectie en beeldsegmentatie met YOLOv8. Voor live detectie importeren we een vooraf getraind YOLOv8-model en gebruiken we de computer vision-bibliotheek, OpenCV, om de camera te openen en objecten te detecteren. Daarnaast creëren we een Streamlit-applicatie voor een aantrekkelijke gebruikersinterface.
Vervolgens verdiepen we ons in beeldsegmentatie met YOLOv8. We importeren een vooraf getraind model en voeren transfer learning uit op een aangepaste dataset. Hiervoor hebben we Roboflow onderzocht voor annotatie van datasets, wat een eenvoudig te gebruiken alternatief biedt voor tools zoals LabelAfb.
Ten slotte voorspellen we een afbeelding met daarin een eend. Hoewel het object in de afbeelding een vogel lijkt te zijn, specificeren we de klassenaam als “eend” voor demonstratiedoeleinden.
Key Takeaways
- Leren over objectdetectiemodellen zoals Faster R-CNN, SSD en de nieuwste YOLOv8.
- Inzicht in de annotatietool Roboflow en zijn rol bij het creëren van datasets voor YOLOv8-segmentatiemodellen.
- Verkennen van live objectdetectie met behulp van OpenCV (cv2) en Supervision, waardoor praktische vaardigheden worden verbeterd.
- Trainen en inzetten van een segmentatiemodel met behulp van YOLOv8, waardoor praktijkervaring wordt opgedaan.
Veelgestelde Vragen / FAQ
A. Objectdetectie omvat het identificeren en lokaliseren van meerdere objecten binnen een afbeelding, meestal door er kaders omheen te tekenen. Beeldsegmentatie daarentegen verdeelt een afbeelding in segmenten of gebieden op basis van pixelovereenkomst, waardoor een gedetailleerder inzicht in de objectgrenzen ontstaat.
A. YOLOv8 verbetert eerdere versies door verbeteringen in netwerkarchitectuur, trainingstechnieken en optimalisatie op te nemen. Het biedt mogelijk een betere nauwkeurigheid, snelheid en efficiëntie in vergelijking met YOLOv3.
A. YOLOv8 kan worden gebruikt voor real-time objectdetectie op ingebedde apparaten, afhankelijk van de hardwaremogelijkheden en modeloptimalisatie. Het kan echter optimalisaties vereisen, zoals het snoeien van modellen of kwantisering, om real-time prestaties te bereiken op apparaten met beperkte middelen.
A. Roboflow biedt intuïtieve annotatietools, functies voor datasetbeheer en ondersteuning voor verschillende annotatieformaten. Het stroomlijnt het annotatieproces, maakt samenwerking mogelijk en biedt versiebeheer, waardoor het eenvoudiger wordt om datasets voor computer vision-projecten te maken en te beheren.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2024/03/live-object-detection-and-image-segmentation-with-yolov8/

