Introductie
Aandachtsmodellen, ook wel bekend als aandacht mechanismen, zijn invoerverwerkingstechnieken die worden gebruikt in neurale netwerken. Ze stellen het netwerk in staat om zich afzonderlijk te concentreren op verschillende aspecten van complexe input totdat de volledige dataset is gecategoriseerd. Het doel is om complexe taken op te splitsen in kleinere aandachtsgebieden die opeenvolgend worden verwerkt. Deze benadering is vergelijkbaar met hoe de menselijke geest nieuwe problemen oplost door ze op te splitsen in eenvoudigere taken en ze stap voor stap op te lossen. Aandachtsmodellen kunnen zich beter aanpassen aan specifieke taken, hun prestaties optimaliseren en hun vermogen verbeteren om naar relevante informatie te kijken.

Het aandachtsmechanisme in NLP is een van de meest waardevolle ontwikkelingen op het gebied van deep learning in het afgelopen decennium. De Transformer-architectuur en natuurlijke taalverwerking (NLP) zoals Google's BERT hebben geleid tot een recente golf van vooruitgang.
leerdoelen
- Begrijp de behoefte aan aandachtsmechanismen bij diep leren, hoe ze werken en hoe ze de prestaties van modellen kunnen verbeteren.
- Maak kennis met de soorten aandachtsmechanismen en voorbeelden van hun gebruik.
- Verken uw toepassing en de voor- en nadelen van het gebruik van het aandachtsmechanisme.
- Doe praktijkervaring op door een voorbeeld van aandachtsimplementatie te volgen.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Wanneer gebruik je het Aandachtskader?
Het aandachtskader werd aanvankelijk gebruikt in op encoder-decoder gebaseerde neurale machinevertalingssystemen en computervisie om hun prestaties te verbeteren. Traditionele automatische vertaalsystemen vertrouwden op grote datasets en complexe functies om vertalingen te verwerken, terwijl aandachtsmechanismen het proces vereenvoudigden. In plaats van woord voor woord te vertalen, wijzen aandachtsmechanismen vectoren met een vaste lengte toe om de algemene betekenis en het sentiment van de invoer vast te leggen, wat resulteert in nauwkeurigere vertalingen. Het aandachtsraamwerk is vooral handig als het gaat om de beperkingen van het encoder-decoder-vertaalmodel. Het maakt nauwkeurige uitlijning en vertaling van ingevoerde zinnen en zinnen mogelijk.
In tegenstelling tot het coderen van de volledige invoerreeks in een enkele vector met vaste inhoud, genereert het aandachtsmechanisme een contextvector voor elke uitvoer, wat efficiëntere vertalingen mogelijk maakt. Het is belangrijk op te merken dat hoewel aandachtsmechanismen de nauwkeurigheid van vertalingen verbeteren, ze niet altijd taalkundige perfectie bereiken. Ze geven echter effectief de intentie en het algemene gevoel van de oorspronkelijke invoer weer. Samengevat, aandachtskaders zijn een waardevol hulpmiddel om de beperkingen van traditionele machinevertalingsmodellen te overwinnen en nauwkeurigere en contextbewuste vertalingen te realiseren.
Hoe werken aandachtsmodellen?
In grote lijnen maken aandachtsmodellen gebruik van een functie die een query en een reeks sleutel-waardeparen in kaart brengt om een uitvoer te genereren. Deze elementen, inclusief de query, sleutels, waarden en uiteindelijke uitvoer, worden allemaal weergegeven als vectoren. De uitvoer wordt berekend door een gewogen som van de waarden te nemen, waarbij de gewichten worden bepaald door een compatibiliteitsfunctie die de overeenkomst tussen de query en de bijbehorende sleutel evalueert.
In de praktijk stellen aandachtsmodellen neurale netwerken in staat om het visuele aandachtsmechanisme van mensen te benaderen. Vergelijkbaar met hoe mensen een nieuwe scène verwerken, focust het model intens op een specifiek punt in een afbeelding, waardoor een "hoge resolutie" begrip wordt verkregen, terwijl de omliggende gebieden met minder detail worden waargenomen, vergelijkbaar met "lage resolutie". Naarmate het netwerk de scène beter begrijpt, past het het brandpunt dienovereenkomstig aan.
Implementatie van het algemene aandachtsmechanisme met NumPy en SciPy
In deze sectie zullen we de implementatie van het algemene aandachtsmechanisme onderzoeken met behulp van de Python-bibliotheken NumPy en SciPy.
Om te beginnen definiëren we de woordinbeddingen voor een reeks van vier woorden. Omwille van de eenvoud zullen we de woordinbeddingen handmatig definiëren, hoewel ze in de praktijk zouden worden gegenereerd door een encoder.
import numpy as np # encoder representations of four different words
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1])Vervolgens genereren we de gewichtsmatrices die worden vermenigvuldigd met de woordinbeddingen om de vragen, sleutels en waarden te verkrijgen. Voor dit voorbeeld genereren we deze gewichtsmatrices willekeurig, maar in echte scenario's zouden ze tijdens de training worden geleerd.
np.random.seed(42) W_Q = np.random.randint(3, size=(3, 3))
W_K = np.random.randint(3, size=(3, 3))
W_V = np.random.randint(3, size=(3, 3))Vervolgens berekenen we de query-, sleutel- en waardevectoren voor elk woord door matrixvermenigvuldigingen uit te voeren tussen de woordinbeddingen en de overeenkomstige gewichtsmatrices.
query_1 = np.dot(word_1, W_Q)
key_1 = np.dot(word_1, W_K)
value_1 = np.dot(word_1, W_V) query_2 = np.dot(word_2, W_Q)
key_2 = np.dot(word_2, W_K)
value_2 = np.dot(word_2, W_V) query_3 = np.dot(word_3, W_Q)
key_3 = np.dot(word_3, W_K)
value_3 = np.dot(word_3, W_V) query_4 = np.dot(word_4, W_Q)
key_4 = np.dot(word_4, W_K)
value_4 = np.dot(word_4, W_V)Verderop scoren we de queryvector van het eerste woord tegen alle sleutelvectoren met behulp van een puntproductbewerking.
scores = np.array([np.dot(query_1,key_1),
np.dot(query_1,key_2),np.dot(query_1,key_3),np.dot(query_1,key_4)])Om de gewichten te genereren, passen we de softmax-bewerking toe op de scores.
weights = np.softmax(scores / np.sqrt(key_1.shape[0]))Ten slotte berekenen we de aandachtsoutput door de gewogen som van alle waardevectoren te nemen.
attention=(weights[0]*value_1)+(weights[1]*value_2)+(weights[2]*value_3)+(weights[3]*value_4) print(attention)Voor een snellere berekening kunnen deze berekeningen in matrixvorm worden uitgevoerd om de attentie-output voor alle vier de woorden tegelijkertijd te verkrijgen. Hier is een voorbeeld:
import numpy as np
from scipy.special import softmax # Representing the encoder representations of four different words
word_1 = np.array([1, 0, 0])
word_2 = np.array([0, 1, 0])
word_3 = np.array([1, 1, 0])
word_4 = np.array([0, 0, 1]) # word embeddings.
words = np.array([word_1, word_2, word_3, word_4]) # Generating the weight matrices.
np. random.seed(42)
W_Q = np. random.randint(3, size=(3, 3))
W_K = np. random.randint(3, size=(3, 3))
W_V = np. random.randint(3, size=(3, 3)) # Generating the queries, keys, and values.
Q = np.dot(words, W_Q)
K = np.dot(words, W_K)
V = np.dot(words, W_V) # Scoring vector query.
scores = np.dot(Q, K.T) # Computing the weights by applying a softmax operation.
weights = softmax(scores / np.sqrt(K.shape[1]), axis=1) # Computing the attention by calculating the weighted sum of the value vectors.
attention = np.dot(weights, V) print(attention)Soorten aandachtsmodellen
- Wereldwijde en lokale aandacht (local-m, local-p)
- Harde en zachte aandacht
- Zelfaandacht
Wereldwijd aandachtsmodel
Het globale aandachtsmodel houdt rekening met invoer van elke bronstatus (encoder) en decoderstatus voorafgaand aan de huidige status om de uitvoer te berekenen. Het houdt rekening met de relatie tussen de bron- en doelsequenties. Hieronder is een diagram dat het wereldwijde aandachtsmodel illustreert.
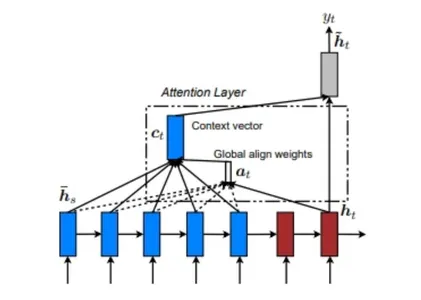
In het globale aandachtsmodel worden de afstemmingsgewichten of aandachtsgewichten (a ) worden berekend met behulp van elke encoderstap en de vorige stap van de decoder (h ). De contextvector (c ) wordt vervolgens berekend door de gewogen som van de encoderuitgangen te nemen met behulp van de uitlijningsgewichten. Deze referentievector wordt naar de RNN-cel gevoerd om de uitvoer van de decoder te bepalen.
Lokaal Aandachtsmodel
Het lokale aandachtsmodel verschilt van het globale aandachtsmodel doordat het alleen rekening houdt met een subset van posities van de bron (encoder) bij het berekenen van de uitlijningsgewichten (een ). Hieronder ziet u een diagram dat het lokale aandachtsmodel illustreert.
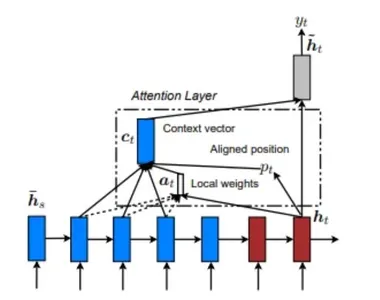
Het lokale aandachtsmodel kan worden begrepen aan de hand van het verstrekte diagram. Het gaat om het vinden van een enkelvoudig uitgelijnde positie (p ) en vervolgens een venster met woorden uit de bronlaag (encoder) gebruiken, samen met (h ), om uitlijningsgewichten en de contextvector te berekenen.
Er zijn twee soorten lokale aandacht: Monotone uitlijning en voorspellende uitlijning. Bij monotone uitlijning wordt de positie (p ) is gewoon ingesteld als "t", terwijl in voorspellende uitlijning de positie (p ) wordt voorspeld door een voorspellend model in plaats van het aan te nemen als "t".
Harde en zachte aandacht
Soft attention en het Global attention-model hebben overeenkomsten in hun functionaliteit. Er zijn echter duidelijke verschillen tussen harde aandacht en lokale aandachtsmodellen. Het primaire onderscheid ligt in de eigenschap differentieerbaarheid. Het lokale aandachtsmodel is op elk punt differentieerbaar, terwijl het bij harde aandacht ontbreekt aan differentiatie. Dit impliceert dat het lokale aandachtsmodel gradiëntgebaseerde optimalisatie door het hele model mogelijk maakt, terwijl harde aandacht een uitdaging vormt voor optimalisatie vanwege niet-differentieerbare operaties.
Zelfaandachtsmodel
Het zelfaandachtsmodel omvat het tot stand brengen van relaties tussen verschillende locaties in dezelfde invoervolgorde. In principe kan zelfaandacht elk van de eerder genoemde scorefuncties gebruiken, maar de doelreeks wordt vervangen door dezelfde invoerreeks.
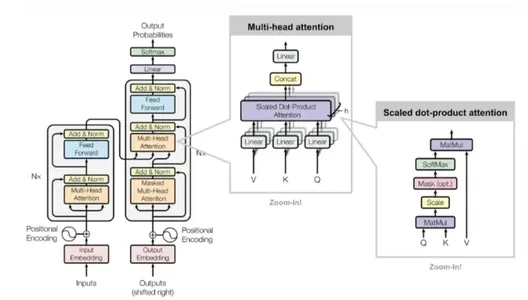
Transformator netwerk
Het transformatornetwerk is volledig gebouwd op basis van zelfaandachtsmechanismen, zonder gebruik te maken van terugkerende netwerkarchitectuur. De transformator maakt gebruik van multi-head zelf-aandachtsmodellen.
Voor- en nadelen van aandachtsmechanismen
Aandachtsmechanismen zijn een krachtig hulpmiddel om de prestaties van deep learning-modellen te verbeteren en hebben verschillende belangrijke voordelen. Enkele van de belangrijkste voordelen van het aandachtsmechanisme zijn:
- Verbeterde nauwkeurigheid: Aandachtsmechanismen dragen bij aan het verbeteren van de nauwkeurigheid van voorspellingen doordat het model zich kan concentreren op de meest relevante informatie.
- verhoogde efficiëntie: Door alleen de belangrijkste gegevens te verwerken, verhogen aandachtsmechanismen de efficiëntie van het model. Dit vermindert de benodigde rekenkracht en verbetert de schaalbaarheid van het model.
- Verbeterde interpreteerbaarheid: De aandachtsgewichten die door het model worden geleerd, bieden waardevolle inzichten in de meest kritieke aspecten van de gegevens. Dit helpt de interpreteerbaarheid van het model te verbeteren en helpt bij het begrijpen van het besluitvormingsproces.
Het aandachtsmechanisme heeft echter ook nadelen waarmee rekening moet worden gehouden. De grote nadelen zijn:
- Moeilijkheidsgraad training: Het trainen van aandachtsmechanismen kan een uitdaging zijn, vooral bij grote en complexe taken. Het leren van de aandachtsgewichten uit gegevens vereist vaak een aanzienlijke hoeveelheid gegevens en rekenkracht.
- Overfitting: Aandachtsmechanismen kunnen vatbaar zijn voor overfitting. Hoewel het model goed presteert op de trainingsgegevens, kan het moeite hebben om effectief te generaliseren naar nieuwe gegevens. Het gebruik van regularisatietechnieken kan dit probleem verminderen, maar het blijft een uitdaging voor grote en complexe taken.
- Blootstellingsbias: Aandachtsmechanismen kunnen last hebben van problemen met blootstellingsbias tijdens de training. Dit gebeurt wanneer het model is getraind om de uitvoerreeks stap voor stap te genereren, maar wordt geëvalueerd door de volledige reeks in één keer te produceren. Deze discrepantie kan resulteren in slechte prestaties op testgegevens, omdat het model moeite kan hebben om de volledige uitvoervolgorde nauwkeurig te reproduceren.
Het is belangrijk om zowel de voor- als nadelen van aandachtsmechanismen te erkennen om weloverwogen beslissingen te kunnen nemen over het gebruik ervan in deep learning-modellen.
Tips voor het gebruik van aandachtskaders
Overweeg bij het implementeren van een aandachtskader de volgende tips om de effectiviteit ervan te vergroten:
- Begrijp verschillende modellen: Maak uzelf vertrouwd met de verschillende aandachtskadermodellen die beschikbaar zijn. Elk model heeft unieke kenmerken en voordelen, dus als u ze evalueert, kunt u het meest geschikte raamwerk kiezen om nauwkeurige resultaten te behalen.
- Zorg voor consistente training: Consistente training van het neurale netwerk is cruciaal. Gebruik technieken zoals back-propagation en Reinforcement Learning om de effectiviteit en nauwkeurigheid van het aandachtskader te verbeteren. Dit maakt het mogelijk om potentiële fouten in het model te identificeren en helpt bij het verfijnen en verbeteren van de prestaties.
- Aandachtsmechanismen toepassen op vertaalprojecten: Ze zijn bijzonder geschikt voor taalvertalingen. Door aandachtsmechanismen in vertaaltaken op te nemen, kunt u de nauwkeurigheid van de vertalingen verbeteren. Het aandachtsmechanisme kent de juiste gewichten toe aan verschillende woorden, legt hun relevantie vast en verbetert de algehele vertaalkwaliteit.
Toepassing van aandachtsmechanismen
Enkele van de belangrijkste toepassingen van het aandachtsmechanisme zijn:
- Pas aandachtsmechanismen toe bij NLP-taken (natural language processing), waaronder machinevertaling, tekstsamenvatting en het beantwoorden van vragen. Deze mechanismen spelen een cruciale rol bij het helpen van modellen om de betekenis van woorden in een bepaalde tekst te begrijpen en om de meest relevante informatie te benadrukken.
- Computervisietaken zoals beeldclassificatie en objectherkenning profiteren ook van aandachtsmechanismen. Door aandacht te gebruiken, kunnen modellen delen van een afbeelding identificeren en hun analyse richten op specifieke objecten.
- Spraakherkenningstaken omvatten het transcriberen van opgenomen geluiden en het herkennen van spraakopdrachten. Aandachtsmechanismen blijken waardevol bij taken door modellen in staat te stellen zich te concentreren op segmenten van het audiosignaal en gesproken woorden nauwkeurig te herkennen.
- Aandachtsmechanismen zijn ook nuttig bij muziekproductietaken, zoals het genereren van melodieën en akkoordprogressies. Door aandacht te gebruiken, kunnen modellen essentiële muzikale elementen benadrukken en coherente en expressieve composities genereren.
Conclusie
Aandachtsmechanismen worden op grote schaal gebruikt in verschillende domeinen, waaronder computervisie. Het merendeel van het onderzoek en de ontwikkeling op het gebied van aandachtsmechanismen is echter geconcentreerd rond Neural Machine Translation (NMT). Conventionele geautomatiseerde vertaalsystemen zijn sterk afhankelijk van uitgebreide gelabelde datasets met complexe functies die de statistische eigenschappen van elk woord in kaart brengen.
Aandachtsmechanismen daarentegen bieden een eenvoudigere aanpak voor NMT. Bij deze benadering coderen we de betekenis van een zin in een vector met een vaste lengte en gebruiken we deze om een vertaling te genereren. In plaats van woord voor woord te vertalen, richt het aandachtsmechanisme zich op het vastleggen van het algemene sentiment of de informatie op hoog niveau van een zin. Door deze leergestuurde aanpak toe te passen, bereiken NMT-systemen niet alleen aanzienlijke nauwkeurigheidsverbeteringen, maar profiteren ze ook van eenvoudigere constructie en snellere trainingsprocessen.
Key Takeaways
- Het aandachtsmechanisme is een neurale netwerklaag die integreert in deep learning-modellen.
- Het stelt het model in staat zich te concentreren op specifieke delen van de input door gewichten toe te wijzen op basis van hun relevantie voor de taak.
- Aandachtsmechanismen zijn zeer effectief gebleken bij verschillende taken, waaronder machinevertaling, beeldonderschriften en spraakherkenning.
- Ze zijn vooral voordelig bij lange invoerreeksen, omdat ze het model in staat stellen zich selectief te concentreren op de meest relevante onderdelen.
- Aandachtsmechanismen kunnen de interpreteerbaarheid van het model verbeteren door de delen van de input waar het model aandacht aan besteedt visueel weer te geven.
Veelgestelde Vragen / FAQ
A. Het aandachtsmechanisme is een laag die wordt toegevoegd aan deep learning-modellen die gewicht toekent aan verschillende delen van de gegevens, waardoor het model de aandacht kan richten op specifieke delen.
A. Wereldwijde aandacht houdt rekening met alle beschikbare gegevens, terwijl lokale aandacht zich richt op een specifieke subset van de totale gegevens.
A. Bij machinevertaling past het aandachtsmechanisme zich tijdens het vertaalproces selectief aan en richt het zich op relevante delen van de bronzin, waarbij meer gewicht wordt toegekend aan belangrijke woorden en zinsdelen.
A. De transformator is een neurale netwerkarchitectuur die sterk leunt op aandachtsmechanismen. Het gebruikt zelfaandacht om afhankelijkheden tussen woorden in invoerreeksen vast te leggen en kan afhankelijkheden op lange afstand effectiever modelleren dan traditionele terugkerende neurale netwerken.
A. Een voorbeeld is het "show, attend, and tell"-model dat wordt gebruikt bij afbeeldingsbeschrijvingstaken. Het maakt gebruik van een aandachtsmechanisme om dynamisch te focussen op verschillende delen van het beeld en tegelijkertijd relevante beschrijvende bijschriften te genereren.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/06/learn-attention-models-from-scratch/

