In essentie, LangChain is een innovatief raamwerk dat op maat is gemaakt voor het maken van applicaties die gebruik maken van de mogelijkheden van taalmodellen. Het is een toolkit die is ontworpen voor ontwikkelaars om applicaties te maken die contextbewust zijn en in staat zijn tot geavanceerde redeneringen.
Dit betekent dat LangChain-applicaties de context kunnen begrijpen, zoals promptinstructies of inhoudelijke reacties, en taalmodellen kunnen gebruiken voor complexe redeneringstaken, zoals beslissen hoe te reageren of welke acties moeten worden ondernomen. LangChain vertegenwoordigt een uniforme aanpak voor het ontwikkelen van intelligente applicaties, waardoor de reis van concept naar uitvoering wordt vereenvoudigd met zijn diverse componenten.
LangChain begrijpen
LangChain is veel meer dan alleen een raamwerk; het is een volwaardig ecosysteem dat uit verschillende integrale onderdelen bestaat.
- Ten eerste zijn er de LangChain-bibliotheken, beschikbaar in zowel Python als JavaScript. Deze bibliotheken vormen de ruggengraat van LangChain en bieden interfaces en integraties voor verschillende componenten. Ze bieden een basisruntime voor het combineren van deze componenten tot samenhangende ketens en agenten, samen met kant-en-klare implementaties voor onmiddellijk gebruik.
- Vervolgens hebben we LangChain-sjablonen. Dit is een verzameling inzetbare referentiearchitecturen die op maat zijn gemaakt voor een breed scala aan taken. Of je nu een chatbot of een complexe analytische tool bouwt, deze sjablonen bieden een solide startpunt.
- LangServe treedt op als een veelzijdige bibliotheek voor het inzetten van LangChain-ketens als REST API's. Deze tool is essentieel om uw LangChain-projecten om te zetten in toegankelijke en schaalbare webservices.
- Ten slotte fungeert LangSmith als ontwikkelaarsplatform. Het is ontworpen voor het debuggen, testen, evalueren en monitoren van ketens die op elk LLM-framework zijn gebouwd. De naadloze integratie met LangChain maakt het een onmisbaar hulpmiddel voor ontwikkelaars die hun applicaties willen verfijnen en perfectioneren.
Samen zorgen deze componenten ervoor dat u met gemak applicaties kunt ontwikkelen, produceren en implementeren. Met LangChain begint u met het schrijven van uw applicaties met behulp van de bibliotheken, waarbij u ter begeleiding naar sjablonen verwijst. LangSmith helpt u vervolgens bij het inspecteren, testen en monitoren van uw ketens, zodat uw applicaties voortdurend worden verbeterd en gereed zijn voor implementatie. Ten slotte kunt u met LangServe eenvoudig elke keten in een API transformeren, waardoor de implementatie een fluitje van een cent wordt.
In de volgende secties gaan we dieper in op het opzetten van LangChain en beginnen we aan uw reis bij het creëren van intelligente, door taalmodellen aangedreven applicaties.
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
Installatie en configuratie
Ben je klaar om in de wereld van LangChain te duiken? Het instellen is eenvoudig en deze handleiding leidt u stap voor stap door het proces.
De eerste stap in uw LangChain-reis is het installeren ervan. Je kunt dit eenvoudig doen met pip of conda. Voer de volgende opdracht uit in uw terminal:
pip install langchain
Voor degenen die de voorkeur geven aan de nieuwste functies en vertrouwd zijn met wat meer avontuur, kunt u LangChain rechtstreeks vanaf de bron installeren. Kloon de repository en navigeer naar het langchain/libs/langchain map. Voer vervolgens uit:
pip install -e .
Voor experimentele functies kunt u overwegen om te installeren langchain-experimental. Het is een pakket dat de allernieuwste code bevat en bedoeld is voor onderzoeks- en experimentele doeleinden. Installeer het met behulp van:
pip install langchain-experimental
LangChain CLI is een handig hulpmiddel voor het werken met LangChain-sjablonen en LangServe-projecten. Om de LangChain CLI te installeren, gebruikt u:
pip install langchain-cli
LangServe is essentieel voor het inzetten van uw LangChain-ketens als REST API. Het wordt naast de LangChain CLI geïnstalleerd.
LangChain vereist vaak integraties met modelproviders, datastores, API's, enz. Voor dit voorbeeld gebruiken we de model-API's van OpenAI. Installeer het OpenAI Python-pakket met behulp van:
pip install openai
Om toegang te krijgen tot de API, stelt u uw OpenAI API-sleutel in als een omgevingsvariabele:
export OPENAI_API_KEY="your_api_key"
U kunt de sleutel ook rechtstreeks in uw Python-omgeving doorgeven:
import os
os.environ['OPENAI_API_KEY'] = 'your_api_key'
LangChain maakt het mogelijk om via modules taalmodeltoepassingen te creëren. Deze modules kunnen op zichzelf staan of worden samengesteld voor complexe gebruiksscenario's. Deze modules zijn –
- Model-I/O: Vergemakkelijkt de interactie met verschillende taalmodellen, waarbij de input en output efficiënt worden verwerkt.
- Ophalen: Maakt toegang tot en interactie met applicatiespecifieke gegevens mogelijk, cruciaal voor dynamisch gegevensgebruik.
- Ontmoet het team: Geef applicaties de mogelijkheid om geschikte tools te selecteren op basis van richtlijnen op hoog niveau, waardoor de besluitvormingsmogelijkheden worden verbeterd.
- Ketens: Biedt vooraf gedefinieerde, herbruikbare composities die dienen als bouwstenen voor applicatieontwikkeling.
- Geheugen: Behoudt de applicatiestatus over meerdere ketenuitvoeringen, essentieel voor contextbewuste interacties.
Elke module richt zich op specifieke ontwikkelingsbehoeften, waardoor LangChain een uitgebreide toolkit is voor het creëren van geavanceerde taalmodeltoepassingen.
Samen met de bovenstaande componenten hebben we ook LangChain-expressietaal (LCEL), wat een declaratieve manier is om eenvoudig modules samen te stellen, en dit maakt het aan elkaar koppelen van componenten mogelijk met behulp van een universele Runnable-interface.
LCEL ziet er ongeveer zo uit:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import BaseOutputParser # Example chain
chain = ChatPromptTemplate() | ChatOpenAI() | CustomOutputParser()
Nu we de basis hebben behandeld, gaan we verder met:
- Graaf dieper in elke Langchain-module in detail.
- Leer hoe u de LangChain-expressietaal gebruikt.
- Ontdek veelvoorkomende gebruiksscenario's en implementeer deze.
- Implementeer een end-to-end-applicatie met LangServe.
- Bekijk LangSmith voor foutopsporing, testen en monitoring.
Laten we beginnen!
Module I: Model-I/O
In LangChain draait het kernelement van elke applicatie om het taalmodel. Deze module biedt de essentiële bouwstenen voor een effectieve interface met elk taalmodel, waardoor een naadloze integratie en communicatie wordt gegarandeerd.
Belangrijkste componenten van Model I/O
- LLM's en chatmodellen (door elkaar gebruikt):
- LLM's:
- Definitie: Modellen voor pure tekstaanvulling.
- Input / Output: Neem een tekststring als invoer en retourneer een tekststring als uitvoer.
- Chatmodellen
- LLM's:
- Definitie: Modellen die een taalmodel als basis gebruiken, maar verschillen in invoer- en uitvoerformaten.
- Input / Output: Accepteer een lijst met chatberichten als invoer en stuur een chatbericht terug.
- aanwijzingen: Modelinvoer sjabloneren, dynamisch selecteren en beheren. Maakt het mogelijk om flexibele en contextspecifieke aanwijzingen te creëren die de antwoorden van het taalmodel begeleiden.
- Uitvoerparsers: informatie uit modeluitvoer extraheren en formatteren. Handig voor het omzetten van de onbewerkte uitvoer van taalmodellen naar gestructureerde gegevens of specifieke formaten die nodig zijn voor de toepassing.
LLM's
De integratie van LangChain met Large Language Models (LLM's) zoals OpenAI, Cohere en Hugging Face is een fundamenteel aspect van de functionaliteit ervan. LangChain host zelf geen LLM's, maar biedt een uniforme interface voor interactie met verschillende LLM's.
Deze sectie biedt een overzicht van het gebruik van de OpenAI LLM-wrapper in LangChain, ook van toepassing op andere LLM-typen. We hebben dit al geïnstalleerd in het gedeelte 'Aan de slag'. Laten we de LLM initialiseren.
from langchain.llms import OpenAI
llm = OpenAI()
- LLM's implementeren de Uitvoerbare interface, de basisbouwsteen van de LangChain-expressietaal (LCEL). Dit betekent dat ze ondersteunen
invoke,ainvoke,stream,astream,batch,abatch,astream_lognoemt. - LLM's accepteren strings als invoer, of objecten die kunnen worden gedwongen om aanwijzingen te geven, inclusief
List[BaseMessage]enPromptValue. (hierover later meer)
Laten we eens kijken naar enkele voorbeelden.
response = llm.invoke("List the seven wonders of the world.")
print(response)

U kunt ook de streammethode aanroepen om het tekstantwoord te streamen.
for chunk in llm.stream("Where were the 2012 Olympics held?"): print(chunk, end="", flush=True)

Chatmodellen
De integratie van LangChain met chatmodellen, een gespecialiseerde variant van taalmodellen, is essentieel voor het creëren van interactieve chattoepassingen. Hoewel ze intern taalmodellen gebruiken, bieden chatmodellen een aparte interface waarin chatberichten als input en output centraal staan. Deze sectie biedt een gedetailleerd overzicht van het gebruik van het chatmodel van OpenAI in LangChain.
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
Chatmodellen in LangChain werken met verschillende berichttypen, zoals AIMessage, HumanMessage, SystemMessage, FunctionMessage en ChatMessage (met een willekeurige rolparameter). Over het algemeen, HumanMessage, AIMessage en SystemMessage zijn de meest gebruikte.
Chatmodellen accepteren voornamelijk List[BaseMessage] als ingangen. Tekenreeksen kunnen worden geconverteerd naar HumanMessage en PromptValue wordt ook ondersteund.
from langchain.schema.messages import HumanMessage, SystemMessage
messages = [ SystemMessage(content="You are Micheal Jordan."), HumanMessage(content="Which shoe manufacturer are you associated with?"),
]
response = chat.invoke(messages)
print(response.content)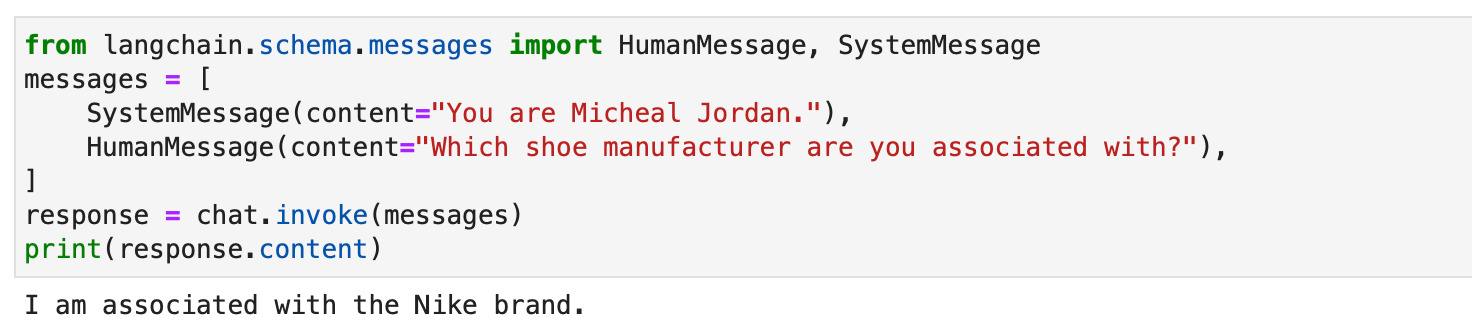
aanwijzingen
Aanwijzingen zijn essentieel bij het begeleiden van taalmodellen om relevante en coherente resultaten te genereren. Ze kunnen variëren van eenvoudige instructies tot complexe, enkele voorbeelden. In LangChain kan het afhandelen van aanwijzingen een zeer gestroomlijnd proces zijn, dankzij verschillende speciale klassen en functies.
LangChains PromptTemplate class is een veelzijdig hulpmiddel voor het maken van stringprompts. Het maakt gebruik van Python str.format syntaxis, waardoor dynamische promptgeneratie mogelijk is. U kunt een sjabloon met tijdelijke aanduidingen definiëren en deze indien nodig met specifieke waarden vullen.
from langchain.prompts import PromptTemplate # Simple prompt with placeholders
prompt_template = PromptTemplate.from_template( "Tell me a {adjective} joke about {content}."
) # Filling placeholders to create a prompt
filled_prompt = prompt_template.format(adjective="funny", content="robots")
print(filled_prompt)Voor chatmodellen zijn aanwijzingen meer gestructureerd, waarbij berichten met specifieke rollen betrokken zijn. LangChain-aanbiedingen ChatPromptTemplate Voor dit doeleinde.
from langchain.prompts import ChatPromptTemplate # Defining a chat prompt with various roles
chat_template = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful AI bot. Your name is {name}."), ("human", "Hello, how are you doing?"), ("ai", "I'm doing well, thanks!"), ("human", "{user_input}"), ]
) # Formatting the chat prompt
formatted_messages = chat_template.format_messages(name="Bob", user_input="What is your name?")
for message in formatted_messages: print(message)
Deze aanpak maakt het mogelijk interactieve, boeiende chatbots met dynamische reacties te creëren.
Te gebruiken zowel PromptTemplate en ChatPromptTemplate naadloos te integreren met de LangChain Expression Language (LCEL), waardoor ze deel kunnen uitmaken van grotere, complexe workflows. We zullen hier later meer over bespreken.
Aangepaste promptsjablonen zijn soms essentieel voor taken die unieke opmaak of specifieke instructies vereisen. Het maken van een aangepaste aanwijzingssjabloon omvat het definiëren van invoervariabelen en een aangepaste opmaakmethode. Dankzij deze flexibiliteit kan LangChain tegemoetkomen aan een breed scala aan toepassingsspecifieke vereisten. Lees hier meer.
LangChain ondersteunt ook enkele vragen, waardoor het model van voorbeelden kan leren. Deze functie is essentieel voor taken die contextueel begrip of specifieke patronen vereisen. Few-shot-promptsjablonen kunnen worden opgebouwd op basis van een reeks voorbeelden of door gebruik te maken van een voorbeeldkiezerobject. Lees hier meer.
Uitvoerparsers
Uitvoerparsers spelen een cruciale rol in Langchain, waardoor gebruikers de door taalmodellen gegenereerde antwoorden kunnen structureren. In deze sectie zullen we het concept van uitvoerparsers verkennen en codevoorbeelden geven met behulp van Langchain's PydanticOutputParser, SimpleJsonOutputParser, CommaSeparatedListOutputParser, DatetimeOutputParser en XMLOutputParser.
PydanticOutputParser
Langchain biedt de PydanticOutputParser voor het parseren van antwoorden in Pydantic-datastructuren. Hieronder vindt u een stapsgewijs voorbeeld van hoe u het kunt gebruiken:
from typing import List
from langchain.llms import OpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
from langchain.pydantic_v1 import BaseModel, Field, validator # Initialize the language model
model = OpenAI(model_name="text-davinci-003", temperature=0.0) # Define your desired data structure using Pydantic
class Joke(BaseModel): setup: str = Field(description="question to set up a joke") punchline: str = Field(description="answer to resolve the joke") @validator("setup") def question_ends_with_question_mark(cls, field): if field[-1] != "?": raise ValueError("Badly formed question!") return field # Set up a PydanticOutputParser
parser = PydanticOutputParser(pydantic_object=Joke) # Create a prompt with format instructions
prompt = PromptTemplate( template="Answer the user query.n{format_instructions}n{query}n", input_variables=["query"], partial_variables={"format_instructions": parser.get_format_instructions()},
) # Define a query to prompt the language model
query = "Tell me a joke." # Combine prompt, model, and parser to get structured output
prompt_and_model = prompt | model
output = prompt_and_model.invoke({"query": query}) # Parse the output using the parser
parsed_result = parser.invoke(output) # The result is a structured object
print(parsed_result)
De output zal worden:

SimpleJsonOutputParser
De SimpleJsonOutputParser van Langchain wordt gebruikt wanneer u JSON-achtige uitvoer wilt parseren. Hier is een voorbeeld:
from langchain.output_parsers.json import SimpleJsonOutputParser # Create a JSON prompt
json_prompt = PromptTemplate.from_template( "Return a JSON object with `birthdate` and `birthplace` key that answers the following question: {question}"
) # Initialize the JSON parser
json_parser = SimpleJsonOutputParser() # Create a chain with the prompt, model, and parser
json_chain = json_prompt | model | json_parser # Stream through the results
result_list = list(json_chain.stream({"question": "When and where was Elon Musk born?"})) # The result is a list of JSON-like dictionaries
print(result_list)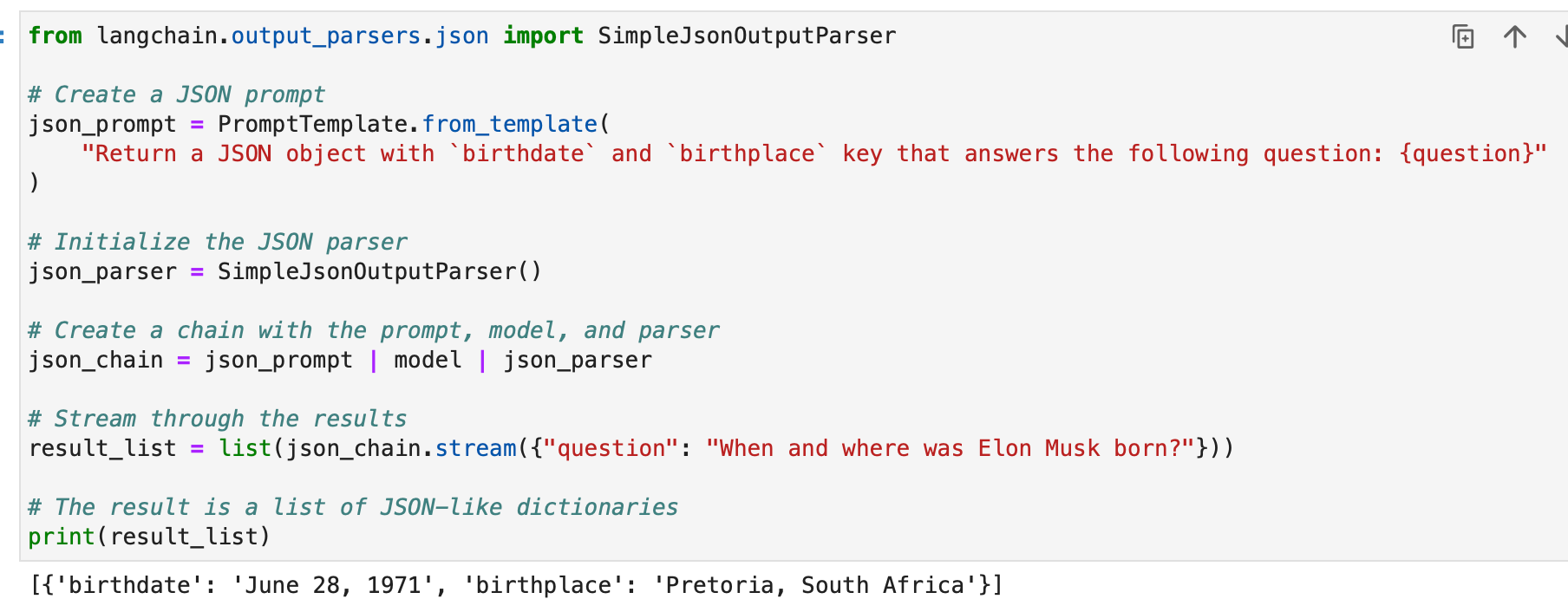
CommaSeparatedListOutputParser
De CommaSeparatedListOutputParser is handig als u door komma's gescheiden lijsten uit modelreacties wilt extraheren. Hier is een voorbeeld:
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI # Initialize the parser
output_parser = CommaSeparatedListOutputParser() # Create format instructions
format_instructions = output_parser.get_format_instructions() # Create a prompt to request a list
prompt = PromptTemplate( template="List five {subject}.n{format_instructions}", input_variables=["subject"], partial_variables={"format_instructions": format_instructions}
) # Define a query to prompt the model
query = "English Premier League Teams" # Generate the output
output = model(prompt.format(subject=query)) # Parse the output using the parser
parsed_result = output_parser.parse(output) # The result is a list of items
print(parsed_result)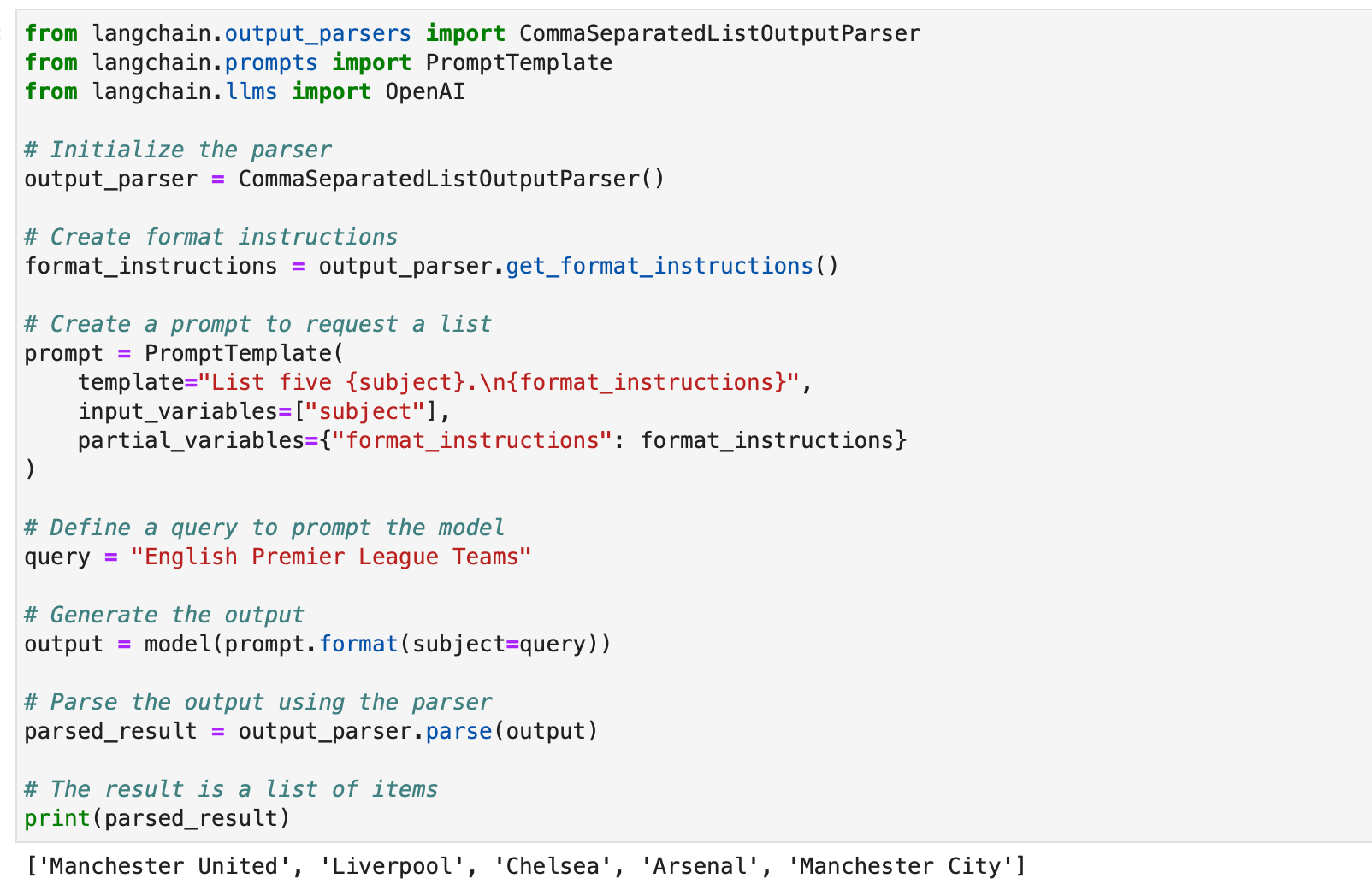
DatetimeOutputParser
De DatetimeOutputParser van Langchain is ontworpen om datetime-informatie te parseren. Hier ziet u hoe u het kunt gebruiken:
from langchain.prompts import PromptTemplate
from langchain.output_parsers import DatetimeOutputParser
from langchain.chains import LLMChain
from langchain.llms import OpenAI # Initialize the DatetimeOutputParser
output_parser = DatetimeOutputParser() # Create a prompt with format instructions
template = """
Answer the user's question:
{question}
{format_instructions} """ prompt = PromptTemplate.from_template( template, partial_variables={"format_instructions": output_parser.get_format_instructions()},
) # Create a chain with the prompt and language model
chain = LLMChain(prompt=prompt, llm=OpenAI()) # Define a query to prompt the model
query = "when did Neil Armstrong land on the moon in terms of GMT?" # Run the chain
output = chain.run(query) # Parse the output using the datetime parser
parsed_result = output_parser.parse(output) # The result is a datetime object
print(parsed_result)
Deze voorbeelden laten zien hoe de uitvoerparsers van Langchain kunnen worden gebruikt om verschillende soorten modelreacties te structureren, waardoor ze geschikt worden voor verschillende toepassingen en formaten. Uitvoerparsers zijn een waardevol hulpmiddel voor het verbeteren van de bruikbaarheid en interpreteerbaarheid van taalmodeluitvoer in Langchain.
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
Module II: Ophalen
Ophalen in LangChain speelt een cruciale rol in applicaties die gebruikersspecifieke gegevens vereisen, die niet zijn opgenomen in de trainingsset van het model. Dit proces, bekend als Retrieval Augmented Generation (RAG), omvat het ophalen van externe gegevens en het integreren ervan in het generatieproces van het taalmodel. LangChain biedt een uitgebreide reeks tools en functionaliteiten om dit proces te vergemakkelijken, geschikt voor zowel eenvoudige als complexe toepassingen.
LangChain bereikt het ophalen via een reeks componenten die we één voor één zullen bespreken.
Documentladers
Documentladers in LangChain maken het extraheren van gegevens uit verschillende bronnen mogelijk. Met meer dan 100 beschikbare laders ondersteunen ze een reeks documenttypen, apps en bronnen (privé s3-buckets, openbare websites, databases).
U kunt een documentlader kiezen op basis van uw vereisten hier.
Al deze laders nemen gegevens op in Document klassen. We zullen later leren hoe u gegevens kunt gebruiken die zijn opgenomen in documentklassen.
Tekstbestandslader: Laad een eenvoudig .txt opslaan in een document.
from langchain.document_loaders import TextLoader loader = TextLoader("./sample.txt")
document = loader.load()
CSV-lader: Laad een CSV-bestand in een document.
from langchain.document_loaders.csv_loader import CSVLoader loader = CSVLoader(file_path='./example_data/sample.csv')
documents = loader.load()
We kunnen ervoor kiezen om de parsering aan te passen door veldnamen op te geven:
loader = CSVLoader(file_path='./example_data/mlb_teams_2012.csv', csv_args={ 'delimiter': ',', 'quotechar': '"', 'fieldnames': ['MLB Team', 'Payroll in millions', 'Wins']
})
documents = loader.load()
PDF-laders: PDF-laders in LangChain bieden verschillende methoden voor het parseren en extraheren van inhoud uit PDF-bestanden. Elke lader voldoet aan verschillende vereisten en gebruikt verschillende onderliggende bibliotheken. Hieronder vindt u gedetailleerde voorbeelden voor elke lader.
PyPDFLoader wordt gebruikt voor eenvoudige PDF-parsering.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
MathPixLoader is ideaal voor het extraheren van wiskundige inhoud en diagrammen.
from langchain.document_loaders import MathpixPDFLoader loader = MathpixPDFLoader("example_data/math-content.pdf")
data = loader.load()
PyMuPDFLoader is snel en bevat gedetailleerde extractie van metagegevens.
from langchain.document_loaders import PyMuPDFLoader loader = PyMuPDFLoader("example_data/layout-parser-paper.pdf")
data = loader.load() # Optionally pass additional arguments for PyMuPDF's get_text() call
data = loader.load(option="text")
PDFMiner Loader wordt gebruikt voor meer gedetailleerde controle over tekstextractie.
from langchain.document_loaders import PDFMinerLoader loader = PDFMinerLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
AmazonTextractPDFParser maakt gebruik van AWS Textract voor OCR en andere geavanceerde PDF-parseerfuncties.
from langchain.document_loaders import AmazonTextractPDFLoader # Requires AWS account and configuration
loader = AmazonTextractPDFLoader("example_data/complex-layout.pdf")
documents = loader.load()
PDFMinerPDFasHTMLLoader genereert HTML uit PDF voor semantische parsering.
from langchain.document_loaders import PDFMinerPDFasHTMLLoader loader = PDFMinerPDFasHTMLLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
PDFPlumberLoader biedt gedetailleerde metadata en ondersteunt één document per pagina.
from langchain.document_loaders import PDFPlumberLoader loader = PDFPlumberLoader("example_data/layout-parser-paper.pdf")
data = loader.load()
Geïntegreerde laders: LangChain biedt een breed scala aan aangepaste laders om gegevens rechtstreeks uit uw apps (zoals Slack, Sigma, Notion, Confluence, Google Drive en nog veel meer) en databases te laden en deze in LLM-applicaties te gebruiken.
De volledige lijst is hier.
Hieronder staan een paar voorbeelden om dit te illustreren –
Voorbeeld I – Slack
Slack, een veelgebruikt instant messaging-platform, kan worden geïntegreerd in LLM-workflows en -applicaties.
- Ga naar uw Slack Workspace Management-pagina.
- Navigeer naar
{your_slack_domain}.slack.com/services/export. - Selecteer het gewenste datumbereik en start de export.
- Slack informeert via e-mail en DM zodra de export klaar is.
- De export resulteert in een
.zipbestand in uw map Downloads of het door u aangegeven downloadpad. - Wijs het pad van het gedownloade bestand toe
.zipbestand naarLOCAL_ZIPFILE. - Gebruik de
SlackDirectoryLoadervan hetlangchain.document_loaderspakket.
from langchain.document_loaders import SlackDirectoryLoader SLACK_WORKSPACE_URL = "https://xxx.slack.com" # Replace with your Slack URL
LOCAL_ZIPFILE = "" # Path to the Slack zip file loader = SlackDirectoryLoader(LOCAL_ZIPFILE, SLACK_WORKSPACE_URL)
docs = loader.load()
print(docs)
Voorbeeld II – Figma
Figma, een populaire tool voor interfaceontwerp, biedt een REST API voor data-integratie.
- Verkrijg de Figma-bestandssleutel uit het URL-formaat:
https://www.figma.com/file/{filekey}/sampleFilename. - Knooppunt-ID's zijn te vinden in de URL-parameter
?node-id={node_id}. - Genereer een toegangstoken volgens de instructies op de Figma-helpcentrum.
- De
FigmaFileLoaderklas vanlangchain.document_loaders.figmawordt gebruikt om Figma-gegevens te laden. - Verschillende LangChain-modules zoals
CharacterTextSplitter,ChatOpenAIenz., worden gebruikt voor de verwerking.
import os
from langchain.document_loaders.figma import FigmaFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.chat_models import ChatOpenAI
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import ConversationChain, LLMChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate figma_loader = FigmaFileLoader( os.environ.get("ACCESS_TOKEN"), os.environ.get("NODE_IDS"), os.environ.get("FILE_KEY"),
) index = VectorstoreIndexCreator().from_loaders([figma_loader])
figma_doc_retriever = index.vectorstore.as_retriever()
- De
generate_codefunctie gebruikt de Figma-gegevens om HTML/CSS-code te maken. - Het maakt gebruik van een sjabloongesprek met een op GPT gebaseerd model.
def generate_code(human_input): # Template for system and human prompts system_prompt_template = "Your coding instructions..." human_prompt_template = "Code the {text}. Ensure it's mobile responsive" # Creating prompt templates system_message_prompt = SystemMessagePromptTemplate.from_template(system_prompt_template) human_message_prompt = HumanMessagePromptTemplate.from_template(human_prompt_template) # Setting up the AI model gpt_4 = ChatOpenAI(temperature=0.02, model_name="gpt-4") # Retrieving relevant documents relevant_nodes = figma_doc_retriever.get_relevant_documents(human_input) # Generating and formatting the prompt conversation = [system_message_prompt, human_message_prompt] chat_prompt = ChatPromptTemplate.from_messages(conversation) response = gpt_4(chat_prompt.format_prompt(context=relevant_nodes, text=human_input).to_messages()) return response # Example usage
response = generate_code("page top header")
print(response.content)
- De
generate_codefunctie retourneert, indien uitgevoerd, HTML/CSS-code op basis van de Figma-ontwerpinvoer.
Laten we nu onze kennis gebruiken om een paar documentensets te maken.
We laden eerst een pdf, het jaarlijkse duurzaamheidsrapport van BCG.

Wij gebruiken hiervoor de PyPDFLoader.
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("bcg-2022-annual-sustainability-report-apr-2023.pdf")
pdfpages = loader.load_and_split()
We zullen nu gegevens van Airtable opnemen. We hebben een Airtable met informatie over verschillende OCR- en data-extractiemodellen –
Laten we hiervoor de AirtableLoader gebruiken, te vinden in de lijst met geïntegreerde laders.
from langchain.document_loaders import AirtableLoader api_key = "XXXXX"
base_id = "XXXXX"
table_id = "XXXXX" loader = AirtableLoader(api_key, table_id, base_id)
airtabledocs = loader.load()
Laten we nu verder gaan en leren hoe u deze documentklassen kunt gebruiken.
Documenttransformatoren
Documenttransformatoren in LangChain zijn essentiële hulpmiddelen die zijn ontworpen om documenten te manipuleren, die we in onze vorige subsectie hebben gemaakt.
Ze worden gebruikt voor taken zoals het opsplitsen van lange documenten in kleinere stukken, het combineren en filteren, wat cruciaal is voor het aanpassen van documenten aan het contextvenster van een model of voor het voldoen aan specifieke applicatiebehoeften.
Eén zo'n tool is de RecursiveCharacterTextSplitter, een veelzijdige tekstsplitter die een tekenlijst gebruikt voor het splitsen. Het staat parameters toe zoals chunkgrootte, overlap en startindex. Hier is een voorbeeld van hoe het in Python wordt gebruikt:
from langchain.text_splitter import RecursiveCharacterTextSplitter state_of_the_union = "Your long text here..." text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=20, length_function=len, add_start_index=True,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
Een ander hulpmiddel is de CharacterTextSplitter, die tekst splitst op basis van een opgegeven teken en besturingselementen bevat voor de blokgrootte en overlap:
from langchain.text_splitter import CharacterTextSplitter text_splitter = CharacterTextSplitter( separator="nn", chunk_size=1000, chunk_overlap=200, length_function=len, is_separator_regex=False,
) texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
De HTMLHeaderTextSplitter is ontworpen om HTML-inhoud te splitsen op basis van header-tags, waarbij de semantische structuur behouden blijft:
from langchain.text_splitter import HTMLHeaderTextSplitter html_string = "Your HTML content here..."
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")] html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text(html_string)
print(html_header_splits[0])
Een complexere manipulatie kan worden bereikt door HTMLHeaderTextSplitter te combineren met een andere splitter, zoals de Pipelined Splitter:
from langchain.text_splitter import HTMLHeaderTextSplitter, RecursiveCharacterTextSplitter url = "https://example.com"
headers_to_split_on = [("h1", "Header 1"), ("h2", "Header 2")]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url) chunk_size = 500
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size)
splits = text_splitter.split_documents(html_header_splits)
print(splits[0])
LangChain biedt ook specifieke splitters voor verschillende programmeertalen, zoals de Python Code Splitter en de JavaScript Code Splitter:
from langchain.text_splitter import RecursiveCharacterTextSplitter, Language python_code = """
def hello_world(): print("Hello, World!")
hello_world() """ python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, chunk_size=50
)
python_docs = python_splitter.create_documents([python_code])
print(python_docs[0]) js_code = """
function helloWorld() { console.log("Hello, World!");
}
helloWorld(); """ js_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.JS, chunk_size=60
)
js_docs = js_splitter.create_documents([js_code])
print(js_docs[0])
Voor het splitsen van tekst op basis van het aantal tokens, wat handig is voor taalmodellen met tokenlimieten, wordt de TokenTextSplitter gebruikt:
from langchain.text_splitter import TokenTextSplitter text_splitter = TokenTextSplitter(chunk_size=10)
texts = text_splitter.split_text(state_of_the_union)
print(texts[0])
Ten slotte herschikt de LongContextReorder documenten opnieuw om prestatieverlies in modellen als gevolg van lange contexten te voorkomen:
from langchain.document_transformers import LongContextReorder reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(docs)
print(reordered_docs[0])
Deze tools demonstreren verschillende manieren om documenten in LangChain te transformeren, van eenvoudige tekstsplitsing tot complexe herschikking en taalspecifieke splitsing. Voor meer diepgaande en specifieke gebruiksscenario's moet de sectie LangChain-documentatie en Integraties worden geraadpleegd.
In onze voorbeelden hebben de laders al gefragmenteerde documenten voor ons gemaakt, en dit deel is al afgehandeld.
Modellen voor het insluiten van tekst
Tekstinsluitingsmodellen in LangChain bieden een gestandaardiseerde interface voor verschillende aanbieders van insluitingsmodellen, zoals OpenAI, Cohere en Hugging Face. Deze modellen transformeren tekst in vectorrepresentaties, waardoor bewerkingen zoals semantisch zoeken door tekstovereenkomsten in de vectorruimte mogelijk worden.
Om aan de slag te gaan met modellen voor het insluiten van tekst, moet u doorgaans specifieke pakketten installeren en API-sleutels instellen. Voor OpenAI hebben we dit al gedaan
In LangChain, de embed_documents methode wordt gebruikt om meerdere teksten in te sluiten, waardoor een lijst met vectorrepresentaties ontstaat. Bijvoorbeeld:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a list of texts
embeddings = embeddings_model.embed_documents( ["Hi there!", "Oh, hello!", "What's your name?", "My friends call me World", "Hello World!"]
)
print("Number of documents embedded:", len(embeddings))
print("Dimension of each embedding:", len(embeddings[0]))
Voor het insluiten van een enkele tekst, zoals een zoekopdracht, wordt de embed_query methode wordt gebruikt. Dit is handig als u een query wilt vergelijken met een reeks documentinsluitingen. Bijvoorbeeld:
from langchain.embeddings import OpenAIEmbeddings # Initialize the model
embeddings_model = OpenAIEmbeddings() # Embed a single query
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
print("First five dimensions of the embedded query:", embedded_query[:5])
Het begrijpen van deze inbedding is cruciaal. Elk stukje tekst wordt omgezet in een vector, waarvan de afmeting afhangt van het gebruikte model. OpenAI-modellen produceren bijvoorbeeld doorgaans 1536-dimensionale vectoren. Deze inbedding wordt vervolgens gebruikt om relevante informatie op te halen.
De inbeddingsfunctionaliteit van LangChain is niet beperkt tot OpenAI, maar is ontworpen om met verschillende providers te werken. De opzet en het gebruik kunnen enigszins verschillen afhankelijk van de provider, maar het kernconcept van het inbedden van teksten in vectorruimte blijft hetzelfde. Voor gedetailleerd gebruik, inclusief geavanceerde configuraties en integraties met verschillende aanbieders van inbeddingsmodellen, is de LangChain-documentatie in de sectie Integraties een waardevolle hulpbron.
Vectorwinkels
Vectorwinkels in LangChain ondersteunen het efficiënt opslaan en zoeken van tekstinsluitingen. LangChain kan worden geïntegreerd met meer dan 50 vectorwinkels en biedt een gestandaardiseerde interface voor gebruiksgemak.
Voorbeeld: Insluitingen opslaan en zoeken
Na het insluiten van teksten kunnen we ze opslaan in een vectorwinkel zoals Chroma en zoek naar gelijkenissen:
from langchain.vectorstores import Chroma db = Chroma.from_texts(embedded_texts)
similar_texts = db.similarity_search("search query")
Laten we als alternatief de FAISS-vectoropslag gebruiken om indexen voor onze documenten te maken.
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS pdfstore = FAISS.from_documents(pdfpages, embedding=OpenAIEmbeddings()) airtablestore = FAISS.from_documents(airtabledocs, embedding=OpenAIEmbeddings())

retriever
Retrievers in LangChain zijn interfaces die documenten retourneren als reactie op een ongestructureerde vraag. Ze zijn algemener dan vectorwinkels en richten zich eerder op ophalen dan op opslag. Hoewel vectoropslag kan worden gebruikt als de ruggengraat van een retriever, zijn er ook andere soorten retrievers.
Om een Chroma retriever in te stellen, installeert u deze eerst met behulp van pip install chromadb. Vervolgens laadt, splitst, sluit u documenten in en haalt u ze op met behulp van een reeks Python-opdrachten. Hier is een codevoorbeeld voor het instellen van een Chroma-retriever:
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma full_text = open("state_of_the_union.txt", "r").read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_text(full_text) embeddings = OpenAIEmbeddings()
db = Chroma.from_texts(texts, embeddings)
retriever = db.as_retriever() retrieved_docs = retriever.invoke("What did the president say about Ketanji Brown Jackson?")
print(retrieved_docs[0].page_content)
De MultiQueryRetriever automatiseert het afstemmen van prompts door meerdere query's te genereren voor een gebruikersinvoerquery en de resultaten te combineren. Hier is een voorbeeld van het eenvoudige gebruik ervan:
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever question = "What are the approaches to Task Decomposition?"
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm( retriever=db.as_retriever(), llm=llm
) unique_docs = retriever_from_llm.get_relevant_documents(query=question)
print("Number of unique documents:", len(unique_docs))
Contextuele compressie in LangChain comprimeert opgehaalde documenten met behulp van de context van de zoekopdracht, zodat alleen relevante informatie wordt geretourneerd. Hierbij gaat het om inhoudsreductie en het wegfilteren van minder relevante documenten. In het volgende codevoorbeeld ziet u hoe u Contextual Compression Retriever gebruikt:
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever) compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
print(compressed_docs[0].page_content)
De EnsembleRetriever combineert verschillende ophaalalgoritmen om betere prestaties te bereiken. Een voorbeeld van het combineren van BM25 en FAISS Retrievers wordt weergegeven in de volgende code:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS bm25_retriever = BM25Retriever.from_texts(doc_list).set_k(2)
faiss_vectorstore = FAISS.from_texts(doc_list, OpenAIEmbeddings())
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2}) ensemble_retriever = EnsembleRetriever( retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
) docs = ensemble_retriever.get_relevant_documents("apples")
print(docs[0].page_content)
MultiVector Retriever in LangChain maakt het bevragen van documenten met meerdere vectoren per document mogelijk, wat handig is voor het vastleggen van verschillende semantische aspecten binnen een document. Methoden voor het maken van meerdere vectoren zijn onder meer het opsplitsen in kleinere stukken, het samenvatten of het genereren van hypothetische vragen. Voor het opsplitsen van documenten in kleinere stukken kan de volgende Python-code worden gebruikt:
python
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.storage import InMemoryStore
from langchain.document_loaders from TextLoader
import uuid loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=10000)
docs = text_splitter.split_documents(docs) vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
id_key = "doc_id"
retriever = MultiVectorRetriever(vectorstore=vectorstore, docstore=store, id_key=id_key) doc_ids = [str(uuid.uuid4()) for _ in docs]
child_text_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
sub_docs = [sub_doc for doc in docs for sub_doc in child_text_splitter.split_documents([doc])]
for sub_doc in sub_docs: sub_doc.metadata[id_key] = doc_ids[sub_docs.index(sub_doc)] retriever.vectorstore.add_documents(sub_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Een andere methode is het genereren van samenvattingen voor een betere vindbaarheid dankzij een meer gerichte weergave van de inhoud. Hier is een voorbeeld van het genereren van samenvattingen:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.document import Document chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Summarize the following document:nn{doc}") | ChatOpenAI(max_retries=0) | StrOutputParser()
summaries = chain.batch(docs, {"max_concurrency": 5}) summary_docs = [Document(page_content=s, metadata={id_key: doc_ids[i]}) for i, s in enumerate(summaries)]
retriever.vectorstore.add_documents(summary_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
Het genereren van hypothetische vragen die relevant zijn voor elk document met behulp van LLM is een andere benadering. Dit kan gedaan worden met de volgende code:
functions = [{"name": "hypothetical_questions", "parameters": {"questions": {"type": "array", "items": {"type": "string"}}}}]
from langchain.output_parsers.openai_functions import JsonKeyOutputFunctionsParser chain = (lambda x: x.page_content) | ChatPromptTemplate.from_template("Generate 3 hypothetical questions:nn{doc}") | ChatOpenAI(max_retries=0).bind(functions=functions, function_call={"name": "hypothetical_questions"}) | JsonKeyOutputFunctionsParser(key_name="questions")
hypothetical_questions = chain.batch(docs, {"max_concurrency": 5}) question_docs = [Document(page_content=q, metadata={id_key: doc_ids[i]}) for i, questions in enumerate(hypothetical_questions) for q in questions]
retriever.vectorstore.add_documents(question_docs)
retriever.docstore.mset(list(zip(doc_ids, docs)))
De Parent Document Retriever is een andere retriever die een balans vindt tussen inbeddingsnauwkeurigheid en contextbehoud door kleine stukjes op te slaan en de grotere ouderdocumenten op te halen. De uitvoering ervan is als volgt:
from langchain.retrievers import ParentDocumentRetriever loaders = [TextLoader("file1.txt"), TextLoader("file2.txt")]
docs = [doc for loader in loaders for doc in loader.load()] child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(collection_name="full_documents", embedding_function=OpenAIEmbeddings())
store = InMemoryStore()
retriever = ParentDocumentRetriever(vectorstore=vectorstore, docstore=store, child_splitter=child_splitter) retriever.add_documents(docs, ids=None) retrieved_docs = retriever.get_relevant_documents("query")
Een zelfvragende retriever construeert gestructureerde zoekopdrachten op basis van natuurlijke taalinvoer en past deze toe op de onderliggende VectorStore. De implementatie ervan wordt weergegeven in de volgende code:
from langchain.chat_models from ChatOpenAI
from langchain.chains.query_constructor.base from AttributeInfo
from langchain.retrievers.self_query.base from SelfQueryRetriever metadata_field_info = [AttributeInfo(name="genre", description="...", type="string"), ...]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0) retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info) retrieved_docs = retriever.invoke("query")
De WebResearchRetriever voert webonderzoek uit op basis van een bepaalde zoekopdracht –
from langchain.retrievers.web_research import WebResearchRetriever # Initialize components
llm = ChatOpenAI(temperature=0)
search = GoogleSearchAPIWrapper()
vectorstore = Chroma(embedding_function=OpenAIEmbeddings()) # Instantiate WebResearchRetriever
web_research_retriever = WebResearchRetriever.from_llm(vectorstore=vectorstore, llm=llm, search=search) # Retrieve documents
docs = web_research_retriever.get_relevant_documents("query")
Voor onze voorbeelden kunnen we ook de standaard retriever gebruiken die al als volgt is geïmplementeerd als onderdeel van ons vectoropslagobject:

We kunnen nu de retrievers bevragen. De uitvoer van onze query bestaat uit documentobjecten die relevant zijn voor de query. Deze zullen uiteindelijk worden gebruikt om in verdere secties relevante reacties te creëren.


Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
Module III: Agenten
LangChain introduceert een krachtig concept genaamd “Agents” dat het idee van ketens naar een geheel nieuw niveau tilt. Agenten maken gebruik van taalmodellen om op dynamische wijze de reeks acties te bepalen die moeten worden uitgevoerd, waardoor ze ongelooflijk veelzijdig en adaptief zijn. In tegenstelling tot traditionele ketens, waar acties hardgecodeerd zijn in code, gebruiken agenten taalmodellen als redeneermachines om te beslissen welke acties ze moeten ondernemen en in welke volgorde.
De agent is de kerncomponent die verantwoordelijk is voor de besluitvorming. Het maakt gebruik van de kracht van een taalmodel en een prompt om de volgende stappen te bepalen om een specifiek doel te bereiken. De invoer voor een agent omvat doorgaans:
- Tools: Beschrijvingen van beschikbare tools (hierover later meer).
- Gebruikers invoer: Het doel of de vraag op hoog niveau van de gebruiker.
- Tussenstappen: Een geschiedenis van (actie, gereedschapsuitvoer) paren die zijn uitgevoerd om de huidige gebruikersinvoer te bereiken.
De output van een agent kan de volgende zijn actie actie ondernemen (Agentacties) of de finale antwoord om naar de gebruiker te sturen (AgentFinish). Een actie specificeert a tools en invoer voor dat gereedschap.
Tools
Tools zijn interfaces die een agent kan gebruiken om met de wereld te communiceren. Ze stellen agenten in staat verschillende taken uit te voeren, zoals zoeken op internet, shell-opdrachten uitvoeren of toegang krijgen tot externe API's. In LangChain zijn tools essentieel om de mogelijkheden van agenten uit te breiden en hen in staat te stellen diverse taken uit te voeren.
Om tools in LangChain te gebruiken, kunt u ze laden met behulp van het volgende fragment:
from langchain.agents import load_tools tool_names = [...]
tools = load_tools(tool_names)
Voor sommige tools is mogelijk een basistaalmodel (LLM) nodig om te initialiseren. In dergelijke gevallen kunt u ook een LLM behalen:
from langchain.agents import load_tools tool_names = [...]
llm = ...
tools = load_tools(tool_names, llm=llm)
Met deze configuratie hebt u toegang tot een verscheidenheid aan tools en kunt u deze integreren in de workflows van uw agent. De volledige lijst met tools met gebruiksdocumentatie is hier.
Laten we eens kijken naar enkele voorbeelden van Tools.
DuckDuckGo
Met de DuckDuckGo-tool kunt u zoekopdrachten op internet uitvoeren met behulp van de zoekmachine. Hier ziet u hoe u het kunt gebruiken:
from langchain.tools import DuckDuckGoSearchRun
search = DuckDuckGoSearchRun()
search.run("manchester united vs luton town match summary")

GegevensForSeo
Met de DataForSeo toolkit kunt u zoekresultaten van zoekmachines verkrijgen met behulp van de DataForSeo API. Om deze toolkit te gebruiken, moet u uw API-gegevens instellen. Zo configureert u de inloggegevens:
import os os.environ["DATAFORSEO_LOGIN"] = "<your_api_access_username>"
os.environ["DATAFORSEO_PASSWORD"] = "<your_api_access_password>"
Zodra uw inloggegevens zijn ingesteld, kunt u een DataForSeoAPIWrapper hulpmiddel om toegang te krijgen tot de API:
from langchain.utilities.dataforseo_api_search import DataForSeoAPIWrapper wrapper = DataForSeoAPIWrapper() result = wrapper.run("Weather in Los Angeles")
De DataForSeoAPIWrapper tool haalt zoekresultaten van zoekmachines op uit verschillende bronnen.
U kunt het type resultaten en velden aanpassen dat in het JSON-antwoord wordt geretourneerd. U kunt bijvoorbeeld de resultaattypen en velden opgeven en een maximumaantal instellen voor het aantal topresultaten dat moet worden geretourneerd:
json_wrapper = DataForSeoAPIWrapper( json_result_types=["organic", "knowledge_graph", "answer_box"], json_result_fields=["type", "title", "description", "text"], top_count=3,
) json_result = json_wrapper.results("Bill Gates")
In dit voorbeeld wordt het JSON-antwoord aangepast door resultaattypen en velden op te geven en het aantal resultaten te beperken.
U kunt ook de locatie en taal voor uw zoekresultaten opgeven door aanvullende parameters door te geven aan de API-wrapper:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en"},
) customized_result = customized_wrapper.results("coffee near me")
Door locatie- en taalparameters op te geven, kunt u uw zoekresultaten afstemmen op specifieke regio's en talen.
U heeft de flexibiliteit om de zoekmachine te kiezen die u wilt gebruiken. Geef eenvoudig de gewenste zoekmachine op:
customized_wrapper = DataForSeoAPIWrapper( top_count=10, json_result_types=["organic", "local_pack"], json_result_fields=["title", "description", "type"], params={"location_name": "Germany", "language_code": "en", "se_name": "bing"},
) customized_result = customized_wrapper.results("coffee near me")
In dit voorbeeld is de zoekopdracht aangepast om Bing als zoekmachine te gebruiken.
Met de API-wrapper kunt u ook het type zoekopdracht opgeven dat u wilt uitvoeren. U kunt bijvoorbeeld een kaartzoekopdracht uitvoeren:
maps_search = DataForSeoAPIWrapper( top_count=10, json_result_fields=["title", "value", "address", "rating", "type"], params={ "location_coordinate": "52.512,13.36,12z", "language_code": "en", "se_type": "maps", },
) maps_search_result = maps_search.results("coffee near me")
Hiermee wordt de zoekopdracht aangepast om kaartgerelateerde informatie op te halen.
Shell (bash)
De Shell-toolkit biedt agenten toegang tot de shell-omgeving, waardoor ze shell-opdrachten kunnen uitvoeren. Deze functie is krachtig, maar moet met voorzichtigheid worden gebruikt, vooral in sandbox-omgevingen. Zo kunt u de Shell-tool gebruiken:
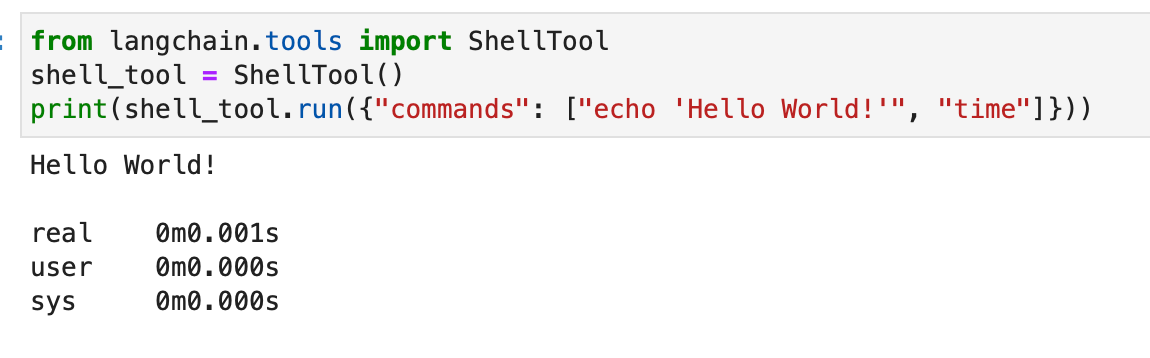
from langchain.tools import ShellTool shell_tool = ShellTool() result = shell_tool.run({"commands": ["echo 'Hello World!'", "time"]})
In dit voorbeeld voert de Shell-tool twee shell-opdrachten uit: in echo 'Hallo wereld!' en weergave van de huidige tijd.
U kunt de Shell-tool aan een agent ter beschikking stellen om complexere taken uit te voeren. Hier is een voorbeeld van een agent die links van een webpagina ophaalt met behulp van de Shell-tool:
from langchain.agents import AgentType, initialize_agent
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0.1) shell_tool.description = shell_tool.description + f"args {shell_tool.args}".replace( "{", "{{"
).replace("}", "}}")
self_ask_with_search = initialize_agent( [shell_tool], llm, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
self_ask_with_search.run( "Download the langchain.com webpage and grep for all urls. Return only a sorted list of them. Be sure to use double quotes."
)
In dit scenario gebruikt de agent de Shell-tool om een reeks opdrachten uit te voeren om URL's van een webpagina op te halen, te filteren en te sorteren.
De gegeven voorbeelden demonstreren enkele van de tools die beschikbaar zijn in LangChain. Deze tools breiden uiteindelijk de mogelijkheden van agenten uit (verkend in de volgende subsectie) en stellen hen in staat verschillende taken efficiënt uit te voeren. Afhankelijk van uw vereisten kunt u de tools en toolkits kiezen die het beste aansluiten bij de behoeften van uw project en deze integreren in de workflows van uw agent.
Terug naar Agenten
Laten we nu verder gaan met agenten.
De AgentExecutor is de runtimeomgeving voor een agent. Het is verantwoordelijk voor het oproepen van de agent, het uitvoeren van de acties die het selecteert, het doorgeven van de actie-uitvoer aan de agent en het herhalen van het proces totdat de agent klaar is. In pseudocode zou de AgentExecutor er ongeveer zo uit kunnen zien:
next_action = agent.get_action(...)
while next_action != AgentFinish: observation = run(next_action) next_action = agent.get_action(..., next_action, observation)
return next_action
De AgentExecutor kan verschillende complexiteiten aan, zoals het omgaan met gevallen waarin de agent een niet-bestaand hulpmiddel selecteert, het afhandelen van gereedschapsfouten, het beheren van door de agent geproduceerde uitvoer en het bieden van logboekregistratie en observatie op alle niveaus.
Hoewel de klasse AgentExecutor de primaire agentruntime in LangChain is, worden er andere, meer experimentele runtimes ondersteund, waaronder:
- Plan-en-uitvoeragent
- Baby-AGI
- Automatische GPT
Laten we, om een beter inzicht te krijgen in het agentframework, een basisagent helemaal opnieuw bouwen en vervolgens verdergaan met het verkennen van vooraf gebouwde agenten.
Voordat we ingaan op het bouwen van de agent, is het essentieel om enkele belangrijke terminologie en schema's opnieuw te bekijken:
- Agentactie: Dit is een gegevensklasse die de actie vertegenwoordigt die een agent moet ondernemen. Het bestaat uit een
tooleigenschap (de naam van het hulpmiddel dat moet worden aangeroepen) en atool_inputeigenschap (de invoer voor dat hulpmiddel). - AgentFinish: Deze gegevensklasse geeft aan dat de agent zijn taak heeft voltooid en een antwoord naar de gebruiker moet retourneren. Het bevat doorgaans een woordenboek met geretourneerde waarden, vaak met een sleutel 'uitvoer' die de antwoordtekst bevat.
- Tussenstappen: Dit zijn de records van eerdere agentacties en bijbehorende outputs. Ze zijn cruciaal voor het doorgeven van context aan toekomstige iteraties van de agent.
In ons voorbeeld gebruiken we OpenAI Function Calling om onze agent te maken. Deze aanpak is betrouwbaar voor het maken van agenten. We beginnen met het maken van een eenvoudig hulpmiddel dat de lengte van een woord berekent. Deze tool is handig omdat taalmodellen soms fouten kunnen maken als gevolg van tokenisatie bij het tellen van woordlengtes.
Laten we eerst het taalmodel laden dat we gaan gebruiken om de agent te besturen:
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
Laten we het model testen met een woordlengteberekening:
llm.invoke("how many letters in the word educa?")
Het antwoord moet het aantal letters van het woord ‘educa’ aangeven.
Vervolgens definiëren we een eenvoudige Python-functie om de lengte van een woord te berekenen:
from langchain.agents import tool @tool
def get_word_length(word: str) -> int: """Returns the length of a word.""" return len(word)
We hebben een tool gemaakt met de naam get_word_length dat een woord als invoer neemt en de lengte ervan retourneert.
Laten we nu de prompt voor de agent maken. De prompt instrueert de agent over het redeneren en formatteren van de uitvoer. In ons geval gebruiken we OpenAI Function Calling, waarvoor minimale instructies nodig zijn. We definiëren de prompt met tijdelijke aanduidingen voor gebruikersinvoer en het kladblok van de agent:
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Hoe weet de agent nu welke tools hij kan gebruiken? We vertrouwen op OpenAI-functieaanroepende taalmodellen, waarvoor functies afzonderlijk moeten worden doorgegeven. Om onze tools aan de agent te leveren, formatteren we ze als OpenAI-functieaanroepen:
from langchain.tools.render import format_tool_to_openai_function llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools])
Nu kunnen we de agent maken door invoertoewijzingen te definiëren en de componenten te verbinden:
Dit is LCEL-taal. We zullen dit later in detail bespreken.
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai _function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
We hebben onze agent gemaakt, die gebruikersinvoer begrijpt, beschikbare tools gebruikt en de uitvoer formatteert. Laten we er nu mee omgaan:
agent.invoke({"input": "how many letters in the word educa?", "intermediate_steps": []})
De agent moet reageren met een AgentAction, waarmee de volgende actie wordt aangegeven.
We hebben de agent gemaakt, maar nu moeten we er een runtime voor schrijven. De eenvoudigste runtime is een runtime waarbij de agent continu wordt opgeroepen, acties wordt uitgevoerd en wordt herhaald totdat de agent klaar is. Hier is een voorbeeld:
from langchain.schema.agent import AgentFinish user_input = "how many letters in the word educa?"
intermediate_steps = [] while True: output = agent.invoke( { "input": user_input, "intermediate_steps": intermediate_steps, } ) if isinstance(output, AgentFinish): final_result = output.return_values["output"] break else: print(f"TOOL NAME: {output.tool}") print(f"TOOL INPUT: {output.tool_input}") tool = {"get_word_length": get_word_length}[output.tool] observation = tool.run(output.tool_input) intermediate_steps.append((output, observation)) print(final_result)
In deze lus bellen we herhaaldelijk de agent, voeren we acties uit en werken we de tussenstappen bij totdat de agent klaar is. We verzorgen ook gereedschapsinteracties binnen de lus.

Om dit proces te vereenvoudigen, biedt LangChain de klasse AgentExecutor, die de uitvoering van agenten omvat en foutafhandeling, vroegtijdig stoppen, traceren en andere verbeteringen biedt. Laten we AgentExecutor gebruiken om met de agent te communiceren:
from langchain.agents import AgentExecutor agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "how many letters in the word educa?"})
AgentExecutor vereenvoudigt het uitvoeringsproces en biedt een handige manier om met de agent te communiceren.
Het geheugen wordt later ook in detail besproken.
De agent die we tot nu toe hebben gemaakt, is staatloos, wat betekent dat hij eerdere interacties niet onthoudt. Om vervolgvragen en gesprekken mogelijk te maken, moeten we geheugen aan de agent toevoegen. Dit omvat twee stappen:
- Voeg een geheugenvariabele toe aan de prompt om de chatgeschiedenis op te slaan.
- Houd de chatgeschiedenis bij tijdens interacties.
Laten we beginnen met het toevoegen van een tijdelijke aanduiding voor geheugen in de prompt:
from langchain.prompts import MessagesPlaceholder MEMORY_KEY = "chat_history"
prompt = ChatPromptTemplate.from_messages( [ ( "system", "You are a very powerful assistant but not great at calculating word lengths.", ), MessagesPlaceholder(variable_name=MEMORY_KEY), ("user", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad"), ]
)
Maak nu een lijst om de chatgeschiedenis bij te houden:
from langchain.schema.messages import HumanMessage, AIMessage chat_history = []
Bij het maken van de agent nemen we ook het geheugen op:
agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), "chat_history": lambda x: x["chat_history"], } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
)
Zorg er nu voor dat u bij het uitvoeren van de agent de chatgeschiedenis bijwerkt:
input1 = "how many letters in the word educa?"
result = agent_executor.invoke({"input": input1, "chat_history": chat_history})
chat_history.extend([ HumanMessage(content=input1), AIMessage(content=result["output"]),
])
agent_executor.invoke({"input": "is that a real word?", "chat_history": chat_history})
Hierdoor kan de agent een gespreksgeschiedenis bijhouden en vervolgvragen beantwoorden op basis van eerdere interacties.
Gefeliciteerd! U heeft met succes uw eerste end-to-end-agent in LangChain gemaakt en uitgevoerd. Om dieper in te gaan op de mogelijkheden van LangChain, kunt u het volgende verkennen:
- Verschillende agenttypen worden ondersteund.
- Vooraf gebouwde agenten
- Hoe te werken met tools en toolintegraties.
Agenttypen
LangChain biedt verschillende soorten agenten, elk geschikt voor specifieke gebruiksscenario's. Hier zijn enkele van de beschikbare agenten:
- Zero-shot ReAct: Deze agent gebruikt het ReAct-framework om tools uitsluitend op basis van hun beschrijvingen te kiezen. Het vereist beschrijvingen voor elk hulpmiddel en is zeer veelzijdig.
- Gestructureerde input ReAct: Deze agent verwerkt tools met meerdere invoer en is geschikt voor complexe taken zoals het navigeren door een webbrowser. Het gebruikt een argumentschema van tools voor gestructureerde invoer.
- OpenAI-functies: Deze agent is speciaal ontworpen voor modellen die zijn afgestemd op het aanroepen van functies en is compatibel met modellen als gpt-3.5-turbo-0613 en gpt-4-0613. We hebben dit gebruikt om onze eerste agent hierboven te maken.
- Gesprek: Deze agent is ontworpen voor gesprekssituaties en gebruikt ReAct voor toolselectie en gebruikt geheugen om eerdere interacties te onthouden.
- Zelf vragen met zoeken: Deze agent vertrouwt op één enkele tool, ‘Intermediate Answer’, die feitelijke antwoorden op vragen opzoekt. Het is gelijk aan de originele zelfvraag met zoekpapier.
- ReAct-documentopslag: Deze agent communiceert met een documentopslag met behulp van het ReAct-framework. Het vereist de tools "Zoeken" en "Opzoeken" en is vergelijkbaar met het Wikipedia-voorbeeld van het originele ReAct-artikel.
Ontdek deze agenttypen om degene te vinden die het beste bij uw behoeften past in LangChain. Met deze agenten kunt u een reeks tools aan hen koppelen om acties af te handelen en reacties te genereren. Meer informatie op hoe u hier uw eigen agent met tools kunt bouwen.
Vooraf gebouwde agenten
Laten we onze verkenning van agenten voortzetten, waarbij we ons concentreren op vooraf gebouwde agenten die beschikbaar zijn in LangChain.
Gmail
LangChain biedt een Gmail-toolkit waarmee u uw LangChain-e-mail kunt verbinden met de Gmail API. Om aan de slag te gaan, moet u uw inloggegevens instellen. Deze worden uitgelegd in de Gmail API-documentatie. Zodra u de credentials.json bestand, kunt u doorgaan met het gebruik van de Gmail API. Bovendien moet u enkele vereiste bibliotheken installeren met behulp van de volgende opdrachten:
pip install --upgrade google-api-python-client > /dev/null
pip install --upgrade google-auth-oauthlib > /dev/null
pip install --upgrade google-auth-httplib2 > /dev/null
pip install beautifulsoup4 > /dev/null # Optional for parsing HTML messages
U kunt de Gmail-toolkit als volgt maken:
from langchain.agents.agent_toolkits import GmailToolkit toolkit = GmailToolkit()
U kunt de authenticatie ook aanpassen aan uw behoeften. Achter de schermen wordt een googleapi-bron gemaakt met behulp van de volgende methoden:
from langchain.tools.gmail.utils import build_resource_service, get_gmail_credentials credentials = get_gmail_credentials( token_file="token.json", scopes=["https://mail.google.com/"], client_secrets_file="credentials.json",
)
api_resource = build_resource_service(credentials=credentials)
toolkit = GmailToolkit(api_resource=api_resource)
De toolkit biedt verschillende tools die binnen een agent kunnen worden gebruikt, waaronder:
GmailCreateDraft: maak een concept-e-mail met gespecificeerde berichtvelden.GmailSendMessage: e-mailberichten verzenden.GmailSearch: zoeken naar e-mailberichten of discussielijnen.GmailGetMessage: een e-mail ophalen op bericht-ID.GmailGetThread: zoeken naar e-mailberichten.
Om deze tools binnen een agent te gebruiken, kunt u de agent als volgt initialiseren:
from langchain.llms import OpenAI
from langchain.agents import initialize_agent, AgentType llm = OpenAI(temperature=0)
agent = initialize_agent( tools=toolkit.get_tools(), llm=llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
)
Hier zijn een paar voorbeelden van hoe deze tools kunnen worden gebruikt:
- Maak een Gmail-concept om te bewerken:
agent.run( "Create a gmail draft for me to edit of a letter from the perspective of a sentient parrot " "who is looking to collaborate on some research with her estranged friend, a cat. " "Under no circumstances may you send the message, however."
)
- Zoek naar de nieuwste e-mail in uw concepten:
agent.run("Could you search in my drafts for the latest email?")
Deze voorbeelden demonstreren de mogelijkheden van de Gmail-toolkit van LangChain binnen een agent, waardoor u programmatisch met Gmail kunt communiceren.
SQL Database-agent
Deze sectie biedt een overzicht van een agent die is ontworpen voor interactie met SQL-databases, met name de Chinook-database. Deze agent kan algemene vragen over een database beantwoorden en fouten herstellen. Houd er rekening mee dat het nog steeds in actieve ontwikkeling is en dat niet alle antwoorden correct kunnen zijn. Wees voorzichtig als u het op gevoelige gegevens uitvoert, omdat het DML-instructies op uw database kan uitvoeren.
Om deze agent te gebruiken, kunt u deze als volgt initialiseren:
from langchain.agents import create_sql_agent
from langchain.agents.agent_toolkits import SQLDatabaseToolkit
from langchain.sql_database import SQLDatabase
from langchain.llms.openai import OpenAI
from langchain.agents import AgentExecutor
from langchain.agents.agent_types import AgentType
from langchain.chat_models import ChatOpenAI db = SQLDatabase.from_uri("sqlite:///../../../../../notebooks/Chinook.db")
toolkit = SQLDatabaseToolkit(db=db, llm=OpenAI(temperature=0)) agent_executor = create_sql_agent( llm=OpenAI(temperature=0), toolkit=toolkit, verbose=True, agent_type=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
)
Deze agent kan worden geïnitialiseerd met behulp van de ZERO_SHOT_REACT_DESCRIPTION soort agent. Het is ontworpen om vragen te beantwoorden en beschrijvingen te geven. Als alternatief kunt u de agent initialiseren met behulp van de OPENAI_FUNCTIONS agenttype met het GPT-3.5-turbomodel van OpenAI, dat we in onze eerdere client gebruikten.
Disclaimer
- De queryketen kan query's voor invoegen/bijwerken/verwijderen genereren. Wees voorzichtig en gebruik indien nodig een aangepaste prompt of maak een SQL-gebruiker aan zonder schrijfrechten.
- Houd er rekening mee dat het uitvoeren van bepaalde query's, zoals 'voer de grootst mogelijke query uit', uw SQL-database kan overbelasten, vooral als deze miljoenen rijen bevat.
- Datawarehouse-georiënteerde databases ondersteunen vaak quota's op gebruikersniveau om het gebruik van bronnen te beperken.
U kunt de agent vragen een tabel te beschrijven, zoals de tabel “playlisttrack”. Hier is een voorbeeld van hoe u dit moet doen:
agent_executor.run("Describe the playlisttrack table")
De agent geeft informatie over het schema van de tabel en voorbeeldrijen.
Als u per ongeluk vraagt naar een tabel die niet bestaat, kan de agent de tabel herstellen en informatie verstrekken over de tabel die het dichtst bij de tabel past. Bijvoorbeeld:
agent_executor.run("Describe the playlistsong table")
De agent zal de dichtstbijzijnde bijpassende tafel vinden en hierover informatie verstrekken.
U kunt de agent ook vragen om query's uit te voeren op de database. Bijvoorbeeld:
agent_executor.run("List the total sales per country. Which country's customers spent the most?")
De agent voert de zoekopdracht uit en geeft het resultaat, bijvoorbeeld het land met de hoogste totale omzet.
Om het totale aantal nummers in elke afspeellijst te krijgen, kunt u de volgende query gebruiken:
agent_executor.run("Show the total number of tracks in each playlist. The Playlist name should be included in the result.")
De agent retourneert de namen van de afspeellijsten samen met het bijbehorende totale aantal nummers.
In gevallen waarin de agent fouten tegenkomt, kan deze herstellen en nauwkeurige antwoorden geven. Bijvoorbeeld:
agent_executor.run("Who are the top 3 best selling artists?")
Zelfs nadat er een eerste fout is opgetreden, zal de agent het aanpassen en het juiste antwoord geven, wat in dit geval de top 3 van best verkochte artiesten is.
Panda's DataFrame-agent
In deze sectie wordt een agent geïntroduceerd die is ontworpen om te communiceren met Pandas DataFrames voor het beantwoorden van vragen. Houd er rekening mee dat deze agent de Python-agent onder de motorkap gebruikt om Python-code uit te voeren die is gegenereerd door een taalmodel (LLM). Wees voorzichtig bij het gebruik van deze agent om mogelijke schade door kwaadaardige Python-code die door de LLM wordt gegenereerd, te voorkomen.
U kunt de Pandas DataFrame-agent als volgt initialiseren:
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType from langchain.llms import OpenAI
import pandas as pd df = pd.read_csv("titanic.csv") # Using ZERO_SHOT_REACT_DESCRIPTION agent type
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), df, verbose=True) # Alternatively, using OPENAI_FUNCTIONS agent type
# agent = create_pandas_dataframe_agent(
# ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
# df,
# verbose=True,
# agent_type=AgentType.OPENAI_FUNCTIONS,
# )
U kunt de agent vragen het aantal rijen in het DataFrame te tellen:
agent.run("how many rows are there?")
De agent voert de code uit df.shape[0] en geef het antwoord, zoals "Er zijn 891 rijen in het dataframe."
U kunt de agent ook vragen rijen te filteren op basis van specifieke criteria, zoals het vinden van het aantal mensen met meer dan drie broers en zussen:
agent.run("how many people have more than 3 siblings")
De agent voert de code uit df[df['SibSp'] > 3].shape[0] en geef het antwoord, zoals '30 mensen hebben meer dan drie broers en zussen.'
Als u de wortel van de gemiddelde leeftijd wilt berekenen, kunt u de agent vragen:
agent.run("whats the square root of the average age?")
De agent berekent de gemiddelde leeftijd met behulp van df['Age'].mean() en bereken vervolgens de vierkantswortel met behulp van math.sqrt(). Het zal het antwoord opleveren, zoals: “De vierkantswortel van de gemiddelde leeftijd is 5.449689683556195.”
Laten we een kopie van het DataFrame maken en de ontbrekende leeftijdswaarden worden gevuld met de gemiddelde leeftijd:
df1 = df.copy()
df1["Age"] = df1["Age"].fillna(df1["Age"].mean())
Vervolgens kunt u de agent initialiseren met beide DataFrames en deze een vraag stellen:
agent = create_pandas_dataframe_agent(OpenAI(temperature=0), [df, df1], verbose=True)
agent.run("how many rows in the age column are different?")
De agent vergelijkt de leeftijdskolommen in beide DataFrames en geeft het antwoord, bijvoorbeeld "177 rijen in de leeftijdskolom zijn verschillend."
Jira-toolkit
In deze sectie wordt uitgelegd hoe u de Jira-toolkit gebruikt, waarmee agenten kunnen communiceren met een Jira-instantie. Met deze toolkit kunt u verschillende acties uitvoeren, zoals het zoeken naar problemen en het aanmaken van problemen. Het maakt gebruik van de Atlassian-Python-API-bibliotheek. Als u deze toolkit wilt gebruiken, moet u omgevingsvariabelen instellen voor uw Jira-instantie, waaronder JIRA_API_TOKEN, JIRA_USERNAME en JIRA_INSTANCE_URL. Bovendien moet u mogelijk uw OpenAI API-sleutel instellen als omgevingsvariabele.
Installeer om te beginnen de atlassian-python-api-bibliotheek en stel de vereiste omgevingsvariabelen in:
%pip install atlassian-python-api import os
from langchain.agents import AgentType
from langchain.agents import initialize_agent
from langchain.agents.agent_toolkits.jira.toolkit import JiraToolkit
from langchain.llms import OpenAI
from langchain.utilities.jira import JiraAPIWrapper os.environ["JIRA_API_TOKEN"] = "abc"
os.environ["JIRA_USERNAME"] = "123"
os.environ["JIRA_INSTANCE_URL"] = "https://jira.atlassian.com"
os.environ["OPENAI_API_KEY"] = "xyz" llm = OpenAI(temperature=0)
jira = JiraAPIWrapper()
toolkit = JiraToolkit.from_jira_api_wrapper(jira)
agent = initialize_agent( toolkit.get_tools(), llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True
)
U kunt de agent opdracht geven om in een specifiek project een nieuw probleem aan te maken met een samenvatting en beschrijving:
agent.run("make a new issue in project PW to remind me to make more fried rice")
De agent zal de nodige acties uitvoeren om het probleem aan te maken en een reactie te geven, zoals “Er is een nieuw probleem aangemaakt in project PW met de samenvatting ‘Maak meer gebakken rijst’ en de beschrijving ‘Herinnering om meer gebakken rijst te maken’.”
Hierdoor kunt u met uw Jira-instantie communiceren met behulp van instructies in natuurlijke taal en de Jira-toolkit.
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
Module IV: Kettingen
LangChain is een tool die is ontworpen voor het gebruik van grote taalmodellen (LLM's) in complexe toepassingen. Het biedt raamwerken voor het creëren van ketens van componenten, inclusief LLM's en andere soorten componenten. Twee primaire raamwerken
- De LangChain-expressietaal (LCEL)
- Legacy Chain-interface
De LangChain Expression Language (LCEL) is een syntaxis die een intuïtieve samenstelling van ketens mogelijk maakt. Het ondersteunt geavanceerde functies zoals streaming, asynchrone oproepen, batching, parallellisatie, nieuwe pogingen, fallbacks en tracering. U kunt bijvoorbeeld een prompt-, model- en uitvoerparser samenstellen in LCEL, zoals weergegeven in de volgende code:
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser model = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = ChatPromptTemplate.from_messages([ ("system", "You're a very knowledgeable historian who provides accurate and eloquent answers to historical questions."), ("human", "{question}")
])
runnable = prompt | model | StrOutputParser() for chunk in runnable.stream({"question": "What are the seven wonders of the world"}): print(chunk, end="", flush=True)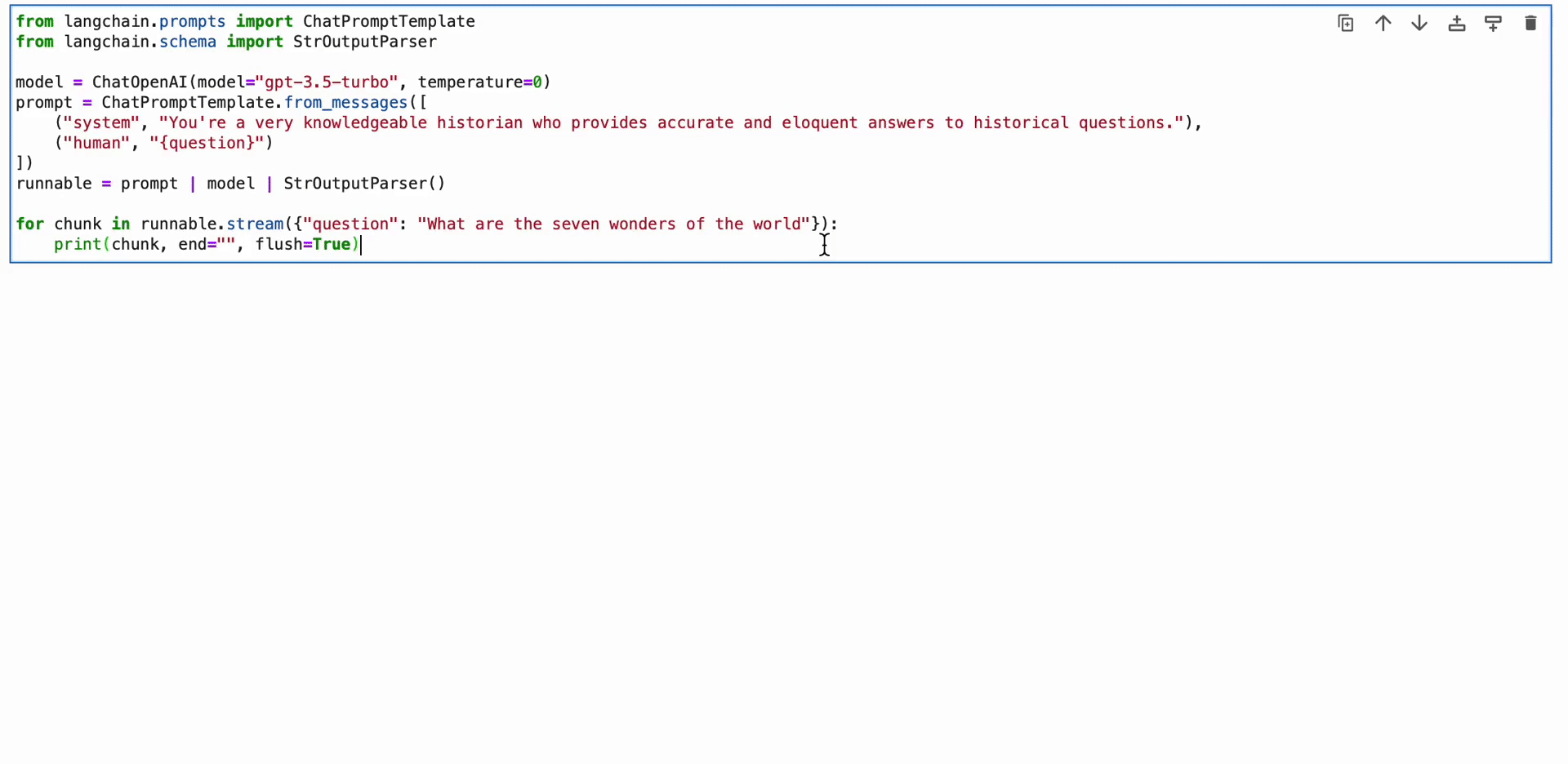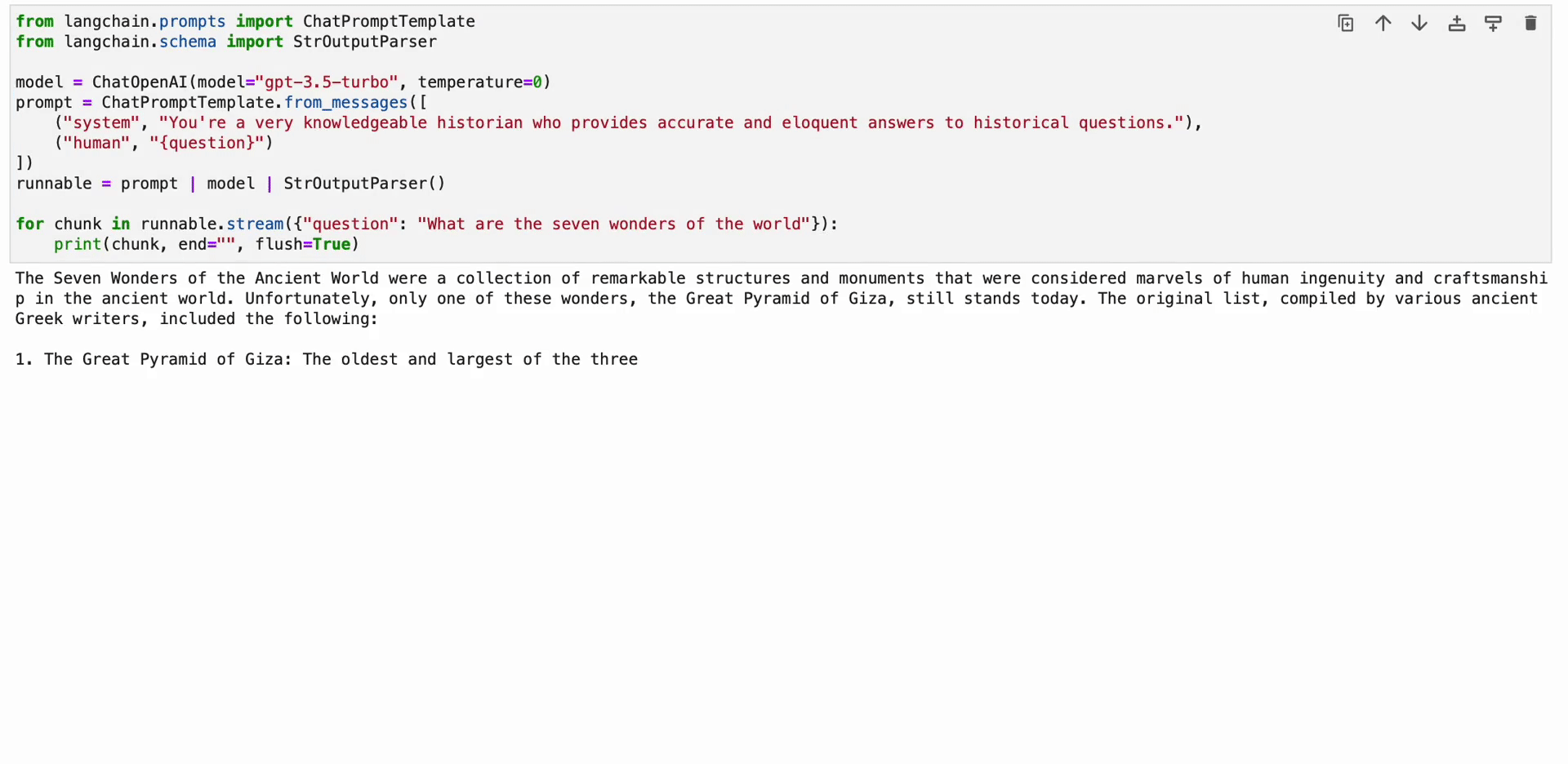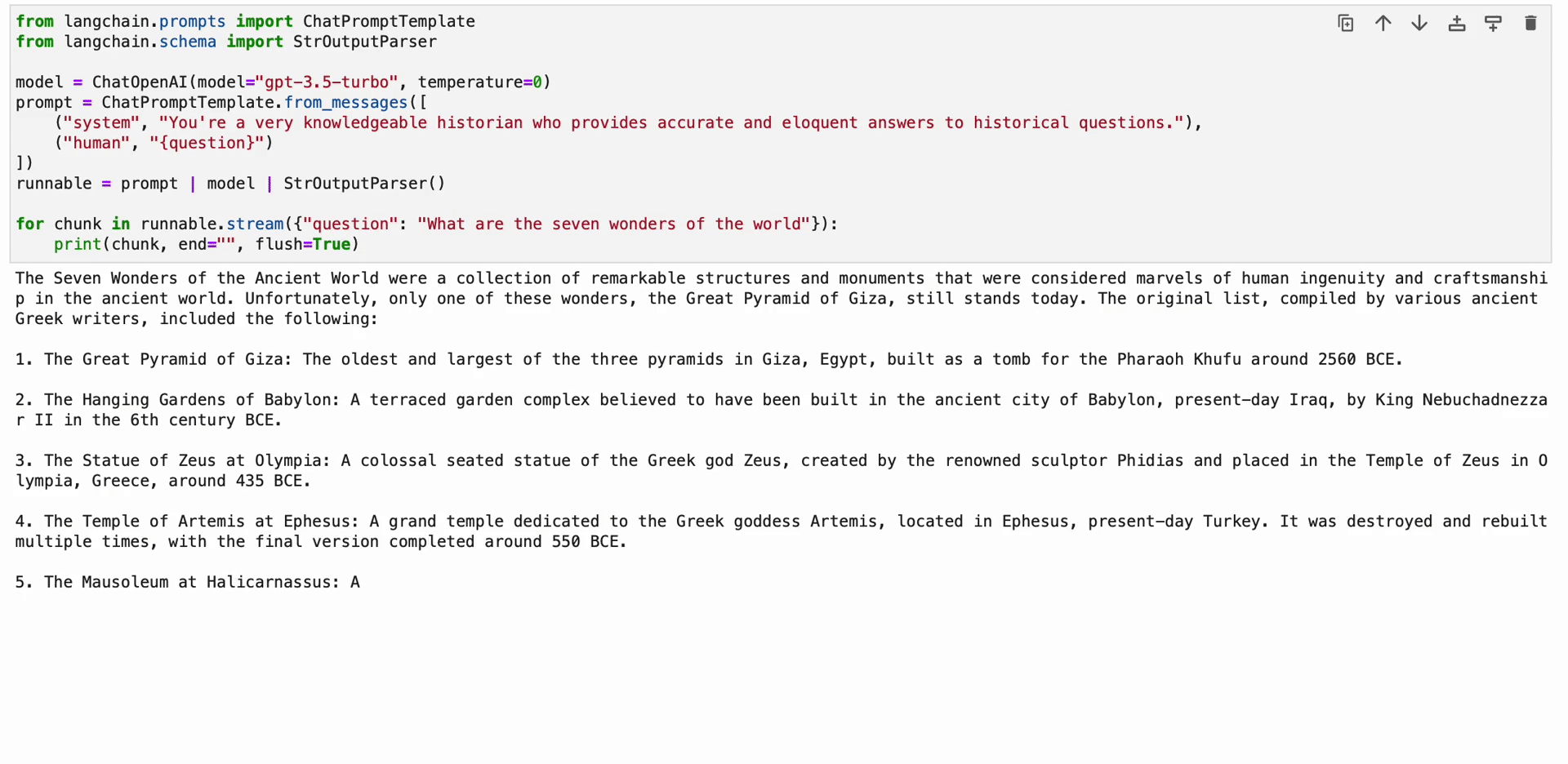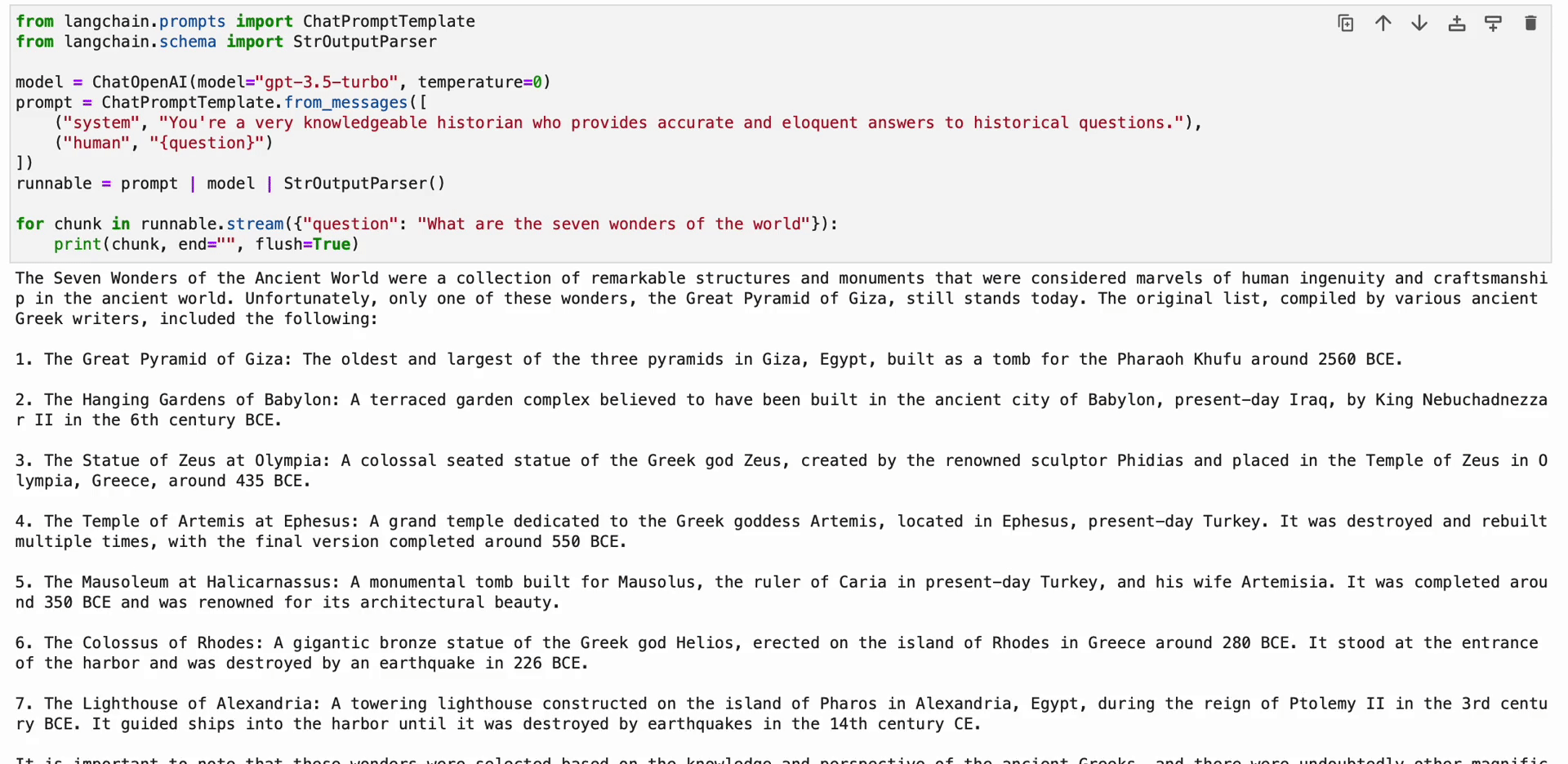
Als alternatief is de LLMChain een optie vergelijkbaar met LCEL voor het samenstellen van componenten. Het LLMChain-voorbeeld is als volgt:
from langchain.chains import LLMChain chain = LLMChain(llm=model, prompt=prompt, output_parser=StrOutputParser())
chain.run(question="What are the seven wonders of the world")
Ketens in LangChain kunnen ook stateful zijn door een Memory-object op te nemen. Dit zorgt voor gegevenspersistentie tussen gesprekken, zoals weergegeven in dit voorbeeld:
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory conversation = ConversationChain(llm=chat, memory=ConversationBufferMemory())
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
conversation.run("And the next 4?")
LangChain ondersteunt ook integratie met de API's voor het aanroepen van functies van OpenAI, wat handig is voor het verkrijgen van gestructureerde uitvoer en het uitvoeren van functies binnen een keten. Om gestructureerde uitvoer te verkrijgen, kunt u deze specificeren met behulp van Pydantic-klassen of JsonSchema, zoals hieronder geïllustreerd:
from langchain.pydantic_v1 import BaseModel, Field
from langchain.chains.openai_functions import create_structured_output_runnable
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") fav_food: Optional[str] = Field(None, description="The person's favorite food") llm = ChatOpenAI(model="gpt-4", temperature=0)
prompt = ChatPromptTemplate.from_messages([ # Prompt messages here
]) runnable = create_structured_output_runnable(Person, llm, prompt)
runnable.invoke({"input": "Sally is 13"})
Voor gestructureerde uitvoer is er ook een verouderde aanpak met LLMChain beschikbaar:
from langchain.chains.openai_functions import create_structured_output_chain class Person(BaseModel): name: str = Field(..., description="The person's name") age: int = Field(..., description="The person's age") chain = create_structured_output_chain(Person, llm, prompt, verbose=True)
chain.run("Sally is 13")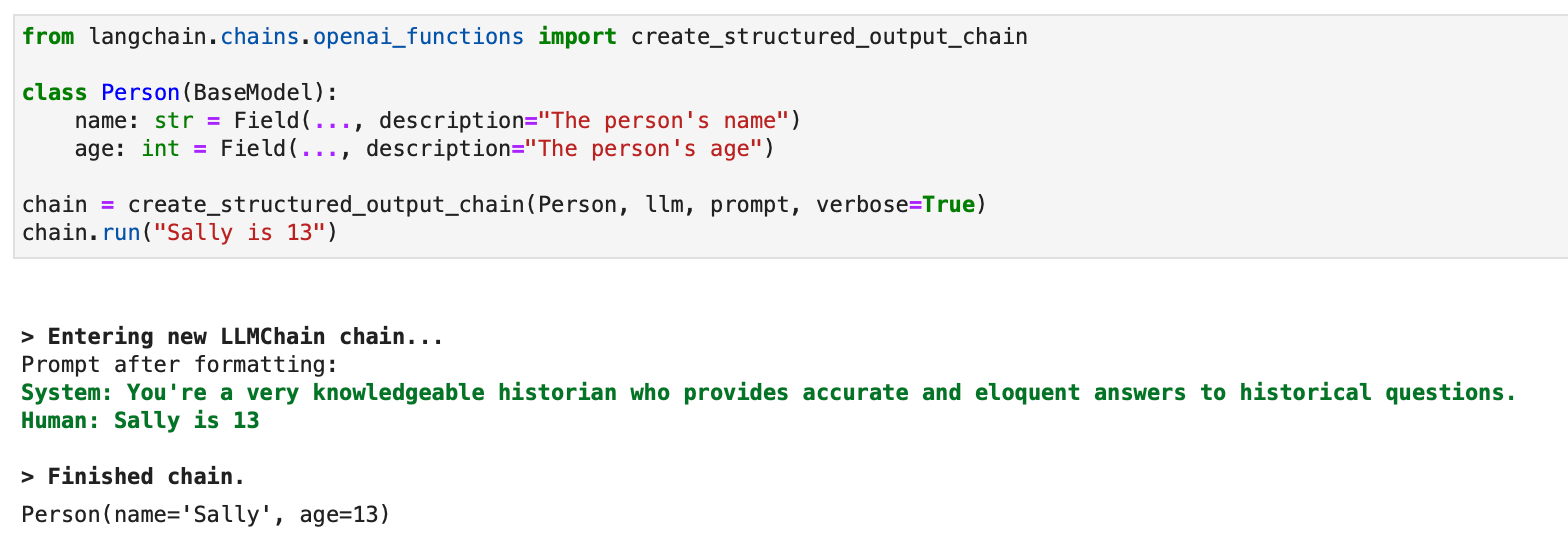
LangChain maakt gebruik van OpenAI-functies om verschillende specifieke ketens voor verschillende doeleinden te creëren. Deze omvatten ketens voor extractie, tagging, OpenAPI en QA met citaten.
In de context van extractie is het proces vergelijkbaar met de gestructureerde outputketen, maar richt het zich op de extractie van informatie of entiteiten. Bij het taggen is het de bedoeling om een document te labelen met klassen zoals sentiment, taal, stijl, behandelde onderwerpen of politieke strekking.
Een voorbeeld van hoe tagging werkt in LangChain kan worden gedemonstreerd met een Python-code. Het proces begint met het installeren van de benodigde pakketten en het opzetten van de omgeving:
pip install langchain openai
# Set env var OPENAI_API_KEY or load from a .env file:
# import dotenv
# dotenv.load_dotenv() from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import create_tagging_chain, create_tagging_chain_pydantic
Het schema voor het taggen is gedefinieerd, waarbij de eigenschappen en hun verwachte typen worden gespecificeerd:
schema = { "properties": { "sentiment": {"type": "string"}, "aggressiveness": {"type": "integer"}, "language": {"type": "string"}, }
} llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_tagging_chain(schema, llm)
Voorbeelden van het uitvoeren van de taggingketen met verschillende invoer tonen het vermogen van het model om sentimenten, talen en agressiviteit te interpreteren:
inp = "Estoy increiblemente contento de haberte conocido! Creo que seremos muy buenos amigos!"
chain.run(inp)
# {'sentiment': 'positive', 'language': 'Spanish'} inp = "Estoy muy enojado con vos! Te voy a dar tu merecido!"
chain.run(inp)
# {'sentiment': 'enojado', 'aggressiveness': 1, 'language': 'es'}
Voor een nauwkeurigere controle kan het schema specifieker worden gedefinieerd, inclusief mogelijke waarden, beschrijvingen en vereiste eigenschappen. Een voorbeeld van deze verbeterde controle wordt hieronder weergegeven:
schema = { "properties": { # Schema definitions here }, "required": ["language", "sentiment", "aggressiveness"],
} chain = create_tagging_chain(schema, llm)
Pydantic-schema's kunnen ook worden gebruikt voor het definiëren van taggingcriteria, waardoor een Pythonische manier wordt geboden om vereiste eigenschappen en typen te specificeren:
from enum import Enum
from pydantic import BaseModel, Field class Tags(BaseModel): # Class fields here chain = create_tagging_chain_pydantic(Tags, llm)
Bovendien kan de metadata-tagger-documenttransformator van LangChain worden gebruikt om metadata uit LangChain-documenten te extraheren, die vergelijkbare functionaliteit biedt als de tagging-keten, maar wordt toegepast op een LangChain-document.
Het citeren van ophaalbronnen is een ander kenmerk van LangChain, waarbij gebruik wordt gemaakt van OpenAI-functies om citaten uit tekst te extraheren. Dit wordt gedemonstreerd in de volgende code:
from langchain.chains import create_citation_fuzzy_match_chain
from langchain.chat_models import ChatOpenAI llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
chain = create_citation_fuzzy_match_chain(llm)
# Further code for running the chain and displaying results
In LangChain omvat het koppelen van Large Language Model (LLM) -toepassingen doorgaans het combineren van een promptsjabloon met een LLM en optioneel een uitvoerparser. De aanbevolen manier om dit te doen is via de LangChain Expression Language (LCEL), hoewel de oudere LLMChain-aanpak ook wordt ondersteund.
Met behulp van LCEL implementeren de BasePromptTemplate, BaseLanguageModel en BaseOutputParser allemaal de Runnable-interface en kunnen ze eenvoudig in elkaar worden doorgesluisd. Hier is een voorbeeld dat dit aantoont:
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser prompt = PromptTemplate.from_template( "What is a good name for a company that makes {product}?"
)
runnable = prompt | ChatOpenAI() | StrOutputParser()
runnable.invoke({"product": "colorful socks"})
# Output: 'VibrantSocks'
Routing in LangChain maakt het mogelijk om niet-deterministische ketens te creëren waarbij de output van een vorige stap de volgende stap bepaalt. Dit helpt bij het structureren en behouden van consistentie in interacties met LLM's. Als u bijvoorbeeld twee sjablonen heeft die zijn geoptimaliseerd voor verschillende soorten vragen, kunt u de sjabloon kiezen op basis van gebruikersinvoer.
Hier ziet u hoe u dit kunt bereiken met behulp van LCEL met een RunnableBranch, die wordt geïnitialiseerd met een lijst met (voorwaarde, uitvoerbare) paren en een standaard uitvoerbare:
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableBranch
# Code for defining physics_prompt and math_prompt general_prompt = PromptTemplate.from_template( "You are a helpful assistant. Answer the question as accurately as you can.nn{input}"
)
prompt_branch = RunnableBranch( (lambda x: x["topic"] == "math", math_prompt), (lambda x: x["topic"] == "physics", physics_prompt), general_prompt,
) # More code for setting up the classifier and final chain
De uiteindelijke keten wordt vervolgens opgebouwd met behulp van verschillende componenten, zoals een onderwerpclassificator, een promptvertakking en een uitvoerparser, om de stroom te bepalen op basis van het onderwerp van de invoer:
from operator import itemgetter
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough final_chain = ( RunnablePassthrough.assign(topic=itemgetter("input") | classifier_chain) | prompt_branch | ChatOpenAI() | StrOutputParser()
) final_chain.invoke( { "input": "What is the first prime number greater than 40 such that one plus the prime number is divisible by 3?" }
)
# Output: Detailed answer to the math question
Deze aanpak illustreert de flexibiliteit en kracht van LangChain bij het afhandelen van complexe vragen en het op de juiste manier routeren ervan op basis van de invoer.
Op het gebied van taalmodellen is het gebruikelijk om een eerste oproep op te volgen met een reeks daaropvolgende oproepen, waarbij de uitvoer van de ene oproep wordt gebruikt als invoer voor de volgende. Deze sequentiële aanpak is vooral nuttig als u wilt voortbouwen op de informatie die tijdens eerdere interacties is gegenereerd. Hoewel de LangChain Expression Language (LCEL) de aanbevolen methode is voor het maken van deze reeksen, is de SequentialChain-methode nog steeds gedocumenteerd vanwege zijn achterwaartse compatibiliteit.
Laten we, om dit te illustreren, een scenario bekijken waarin we eerst een synopsis van het toneelstuk genereren en vervolgens een recensie op basis van die synopsis. Met behulp van Python langchain.prompts, we maken er twee PromptTemplate voorbeelden: één voor de synopsis en één voor de recensie. Hier is de code om deze sjablonen in te stellen:
from langchain.prompts import PromptTemplate synopsis_prompt = PromptTemplate.from_template( "You are a playwright. Given the title of play, it is your job to write a synopsis for that title.nnTitle: {title}nPlaywright: This is a synopsis for the above play:"
) review_prompt = PromptTemplate.from_template( "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
)
In de LCEL-aanpak koppelen we deze aanwijzingen aan elkaar ChatOpenAI en StrOutputParser om een reeks te creëren die eerst een synopsis en vervolgens een recensie genereert. Het codefragment is als volgt:
from langchain.chat_models import ChatOpenAI
from langchain.schema import StrOutputParser llm = ChatOpenAI()
chain = ( {"synopsis": synopsis_prompt | llm | StrOutputParser()} | review_prompt | llm | StrOutputParser()
)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Als we zowel de synopsis als de recensie nodig hebben, kunnen we deze gebruiken RunnablePassthrough om voor elk een aparte keten te maken en deze vervolgens te combineren:
from langchain.schema.runnable import RunnablePassthrough synopsis_chain = synopsis_prompt | llm | StrOutputParser()
review_chain = review_prompt | llm | StrOutputParser()
chain = {"synopsis": synopsis_chain} | RunnablePassthrough.assign(review=review_chain)
chain.invoke({"title": "Tragedy at sunset on the beach"})
Voor scenario's met complexere reeksen kan de SequentialChain methode speelt een rol. Hierdoor zijn meerdere in- en uitgangen mogelijk. Beschouw een geval waarin we een synopsis nodig hebben op basis van de titel en het tijdperk van een toneelstuk. Zo kunnen we het instellen:
from langchain.llms import OpenAI
from langchain.chains import LLMChain, SequentialChain
from langchain.prompts import PromptTemplate llm = OpenAI(temperature=0.7) synopsis_template = "You are a playwright. Given the title of play and the era it is set in, it is your job to write a synopsis for that title.nnTitle: {title}nEra: {era}nPlaywright: This is a synopsis for the above play:"
synopsis_prompt_template = PromptTemplate(input_variables=["title", "era"], template=synopsis_template)
synopsis_chain = LLMChain(llm=llm, prompt=synopsis_prompt_template, output_key="synopsis") review_template = "You are a play critic from the New York Times. Given the synopsis of play, it is your job to write a review for that play.nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:"
prompt_template = PromptTemplate(input_variables=["synopsis"], template=review_template)
review_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="review") overall_chain = SequentialChain( chains=[synopsis_chain, review_chain], input_variables=["era", "title"], output_variables=["synopsis", "review"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
In scenario’s waarin je de context gedurende een keten of voor een later deel van de keten wilt behouden, SimpleMemory kan worden gebruikt. Dit is met name handig voor het beheren van complexe invoer-/uitvoerrelaties. In een scenario waarin we bijvoorbeeld berichten op sociale media willen genereren op basis van de titel, het tijdperk, de synopsis en de recensie van een toneelstuk, SimpleMemory kan helpen bij het beheren van deze variabelen:
from langchain.memory import SimpleMemory
from langchain.chains import SequentialChain template = "You are a social media manager for a theater company. Given the title of play, the era it is set in, the date, time and location, the synopsis of the play, and the review of the play, it is your job to write a social media post for that play.nnHere is some context about the time and location of the play:nDate and Time: {time}nLocation: {location}nnPlay Synopsis:n{synopsis}nReview from a New York Times play critic of the above play:n{review}nnSocial Media Post:"
prompt_template = PromptTemplate(input_variables=["synopsis", "review", "time", "location"], template=template)
social_chain = LLMChain(llm=llm, prompt=prompt_template, output_key="social_post_text") overall_chain = SequentialChain( memory=SimpleMemory(memories={"time": "December 25th, 8pm PST", "location": "Theater in the Park"}), chains=[synopsis_chain, review_chain, social_chain], input_variables=["era", "title"], output_variables=["social_post_text"], verbose=True,
) overall_chain({"title": "Tragedy at sunset on the beach", "era": "Victorian England"})
Naast sequentiële ketens zijn er gespecialiseerde ketens voor het werken met documenten. Elk van deze ketens dient een ander doel, van het combineren van documenten tot het verfijnen van antwoorden op basis van iteratieve documentanalyse, tot het in kaart brengen en reduceren van documentinhoud voor samenvatting of herschikking op basis van gescoorde antwoorden. Deze kettingen kunnen met LCEL opnieuw worden gemaakt voor extra flexibiliteit en maatwerk.
-
StuffDocumentsChaincombineert een lijst met documenten in één enkele prompt die wordt doorgegeven aan een LLM. -
RefineDocumentsChainwerkt het antwoord iteratief bij voor elk document, geschikt voor taken waarbij documenten de contextcapaciteit van het model overschrijden. -
MapReduceDocumentsChainpast een keten toe op elk document afzonderlijk en combineert vervolgens de resultaten. -
MapRerankDocumentsChainscoort elk documentgebaseerd antwoord en selecteert het hoogst scorende antwoord.
Hier is een voorbeeld van hoe u een MapReduceDocumentsChain met behulp van LCEL:
from functools import partial
from langchain.chains.combine_documents import collapse_docs, split_list_of_docs
from langchain.schema import Document, StrOutputParser
from langchain.schema.prompt_template import format_document
from langchain.schema.runnable import RunnableParallel, RunnablePassthrough llm = ChatAnthropic()
document_prompt = PromptTemplate.from_template("{page_content}")
partial_format_document = partial(format_document, prompt=document_prompt) map_chain = ( {"context": partial_format_document} | PromptTemplate.from_template("Summarize this content:nn{context}") | llm | StrOutputParser()
) map_as_doc_chain = ( RunnableParallel({"doc": RunnablePassthrough(), "content": map_chain}) | (lambda x: Document(page_content=x["content"], metadata=x["doc"].metadata))
).with_config(run_name="Summarize (return doc)") def format_docs(docs): return "nn".join(partial_format_document(doc) for doc in docs) collapse_chain = ( {"context": format_docs} | PromptTemplate.from_template("Collapse this content:nn{context}") | llm | StrOutputParser()
) reduce_chain = ( {"context": format_docs} | PromptTemplate.from_template("Combine these summaries:nn{context}") | llm | StrOutputParser()
).with_config(run_name="Reduce") map_reduce = (map_as_doc_chain.map() | collapse | reduce_chain).with_config(run_name="Map reduce")
Deze configuratie maakt een gedetailleerde en uitgebreide analyse van de documentinhoud mogelijk, waarbij gebruik wordt gemaakt van de sterke punten van LCEL en het onderliggende taalmodel.
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
Module V: Geheugen
In LangChain is geheugen een fundamenteel aspect van gespreksinterfaces, waardoor systemen kunnen verwijzen naar eerdere interacties. Dit wordt bereikt door het opslaan en opvragen van informatie, met twee primaire acties: lezen en schrijven. Het geheugensysteem werkt tijdens een run twee keer samen met een keten, waardoor de gebruikersinvoer wordt uitgebreid en de in- en uitgangen worden opgeslagen voor toekomstig gebruik.
Geheugen inbouwen in een systeem
- Chatberichten opslaan: De LangChain-geheugenmodule integreert verschillende methoden om chatberichten op te slaan, variërend van in-memory lijsten tot databases. Dit zorgt ervoor dat alle chatinteracties worden vastgelegd voor toekomstig gebruik.
- Chatberichten opvragen: Naast het opslaan van chatberichten, gebruikt LangChain datastructuren en algoritmen om een bruikbaar beeld van deze berichten te creëren. Eenvoudige geheugensystemen kunnen recente berichten retourneren, terwijl meer geavanceerde systemen eerdere interacties kunnen samenvatten of zich kunnen concentreren op entiteiten die in de huidige interactie worden genoemd.
Om het gebruik van geheugen in LangChain te demonstreren, overweeg dan de ConversationBufferMemory class, een eenvoudige geheugenvorm die chatberichten in een buffer opslaat. Hier is een voorbeeld:
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("Hello!")
memory.chat_memory.add_ai_message("How can I assist you?")
Bij het integreren van geheugen in een keten is het van cruciaal belang om de variabelen te begrijpen die uit het geheugen worden geretourneerd en hoe ze in de keten worden gebruikt. Bijvoorbeeld de load_memory_variables De methode helpt de uit het geheugen gelezen variabelen af te stemmen op de verwachtingen van de keten.
End-to-end voorbeeld met LangChain
Overweeg het gebruik ConversationBufferMemory een LLMChain. De keten, gecombineerd met een passend promptsjabloon en het geheugen, zorgt voor een naadloze gesprekservaring. Hier is een vereenvoudigd voorbeeld:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory llm = OpenAI(temperature=0)
template = "Your conversation template here..."
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory(memory_key="chat_history")
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory) response = conversation({"question": "What's the weather like?"})
Dit voorbeeld illustreert hoe het geheugensysteem van LangChain integreert met zijn ketens om een samenhangende en contextueel bewuste gesprekservaring te bieden.
Geheugentypen in Langchain
Langchain biedt verschillende geheugentypen die kunnen worden gebruikt om de interacties met de AI-modellen te verbeteren. Elk geheugentype heeft zijn eigen parameters en retourtypen, waardoor ze geschikt zijn voor verschillende scenario's. Laten we enkele van de geheugentypen verkennen die beschikbaar zijn in Langchain, samen met codevoorbeelden.
1. Gespreksbuffergeheugen
Met dit geheugentype kunt u berichten uit gesprekken opslaan en extraheren. U kunt de geschiedenis extraheren als een tekenreeks of als een lijst met berichten.
from langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory()
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) # Extract history as a string
{'history': 'Human: hinAI: whats up'} # Extract history as a list of messages
{'history': [HumanMessage(content='hi', additional_kwargs={}), AIMessage(content='whats up', additional_kwargs={})]}
U kunt ook Conversatiebuffergeheugen in een keten gebruiken voor chatachtige interacties.
2. Gesprekbuffervenstergeheugen
Dit geheugentype houdt een lijst bij van recente interacties en gebruikt de laatste K-interacties, waardoor wordt voorkomen dat de buffer te groot wordt.
from langchain.memory import ConversationBufferWindowMemory memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
Net als Conversation Buffer Memory kunt u dit geheugentype ook in een keten gebruiken voor chatachtige interacties.
3. Geheugen van gespreksentiteit
Dit geheugentype onthoudt feiten over specifieke entiteiten in een gesprek en extraheert informatie met behulp van een LLM.
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationEntityMemory(llm=llm)
_input = {"input": "Deven & Sam are working on a hackathon project"}
memory.load_memory_variables(_input)
memory.save_context( _input, {"output": " That sounds like a great project! What kind of project are they working on?"}
)
memory.load_memory_variables({"input": 'who is Sam'}) {'history': 'Human: Deven & Sam are working on a hackathon projectnAI: That sounds like a great project! What kind of project are they working on?', 'entities': {'Sam': 'Sam is working on a hackathon project with Deven.'}}
4. Gesprek Kennisgrafiekgeheugen
Dit geheugentype gebruikt een kennisgrafiek om geheugen opnieuw te creëren. U kunt huidige entiteiten en kennistripletten uit berichten extraheren.
from langchain.memory import ConversationKGMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationKGMemory(llm=llm)
memory.save_context({"input": "say hi to sam"}, {"output": "who is sam"})
memory.save_context({"input": "sam is a friend"}, {"output": "okay"})
memory.load_memory_variables({"input": "who is sam"}) {'history': 'On Sam: Sam is friend.'}
U kunt dit geheugentype ook in een keten gebruiken voor het ophalen van kennis op basis van gesprekken.
5. Geheugen voor gesprekssamenvatting
Dit geheugentype creëert een samenvatting van het gesprek in de loop van de tijd, handig voor het condenseren van informatie uit langere gesprekken.
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.load_memory_variables({}) {'history': 'nThe human greets the AI, to which the AI responds.'}
6. Gesprekssamenvatting Buffergeheugen
Dit geheugentype combineert de gesprekssamenvatting en buffer, waardoor een evenwicht wordt gehandhaafd tussen recente interacties en een samenvatting. Het gebruikt de tokenlengte om te bepalen wanneer interacties moeten worden gewist.
from langchain.memory import ConversationSummaryBufferMemory
from langchain.llms import OpenAI llm = OpenAI()
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({}) {'history': 'System: nThe human says "hi", and the AI responds with "whats up".nHuman: not much younAI: not much'}
U kunt deze geheugentypen gebruiken om uw interacties met AI-modellen in Langchain te verbeteren. Elk geheugentype dient een specifiek doel en kan worden geselecteerd op basis van uw wensen.
7. Buffergeheugen voor gesprekstokens
ConversationTokenBufferMemory is een ander geheugentype dat een buffer van recente interacties in het geheugen bewaart. In tegenstelling tot de vorige geheugentypen die zich richten op het aantal interacties, gebruikt deze de tokenlengte om te bepalen wanneer interacties moeten worden gewist.
Geheugen gebruiken met LLM:
from langchain.memory import ConversationTokenBufferMemory
from langchain.llms import OpenAI llm = OpenAI() memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"}) memory.load_memory_variables({}) {'history': 'Human: not much younAI: not much'}
In dit voorbeeld is het geheugen ingesteld om interacties te beperken op basis van de tokenlengte in plaats van het aantal interacties.
Als u dit geheugentype gebruikt, kunt u de geschiedenis ook als een lijst met berichten ophalen.
memory = ConversationTokenBufferMemory( llm=llm, max_token_limit=10, return_messages=True
)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
Gebruik in een keten:
U kunt ConversationTokenBufferMemory in een keten gebruiken om de interactie met het AI-model te verbeteren.
from langchain.chains import ConversationChain conversation_with_summary = ConversationChain( llm=llm, # We set a very low max_token_limit for the purposes of testing. memory=ConversationTokenBufferMemory(llm=OpenAI(), max_token_limit=60), verbose=True,
)
conversation_with_summary.predict(input="Hi, what's up?")
In dit voorbeeld wordt ConversationTokenBufferMemory gebruikt in een ConversationChain om het gesprek te beheren en interacties te beperken op basis van de tokenlengte.
8. VectorStoreRetrievergeheugen
VectorStoreRetrieverMemory slaat herinneringen op in een vectorarchief en vraagt elke keer dat het wordt aangeroepen de belangrijkste documenten op. Dit geheugentype houdt niet expliciet de volgorde van interacties bij, maar gebruikt vectorherstel om relevante herinneringen op te halen.
from datetime import datetime
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.memory import VectorStoreRetrieverMemory
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate # Initialize your vector store (specifics depend on the chosen vector store)
import faiss
from langchain.docstore import InMemoryDocstore
from langchain.vectorstores import FAISS embedding_size = 1536 # Dimensions of the OpenAIEmbeddings
index = faiss.IndexFlatL2(embedding_size)
embedding_fn = OpenAIEmbeddings().embed_query
vectorstore = FAISS(embedding_fn, index, InMemoryDocstore({}), {}) # Create your VectorStoreRetrieverMemory
retriever = vectorstore.as_retriever(search_kwargs=dict(k=1))
memory = VectorStoreRetrieverMemory(retriever=retriever) # Save context and relevant information to the memory
memory.save_context({"input": "My favorite food is pizza"}, {"output": "that's good to know"})
memory.save_context({"input": "My favorite sport is soccer"}, {"output": "..."})
memory.save_context({"input": "I don't like the Celtics"}, {"output": "ok"}) # Retrieve relevant information from memory based on a query
print(memory.load_memory_variables({"prompt": "what sport should i watch?"})["history"])
In dit voorbeeld wordt VectorStoreRetrieverMemory gebruikt om relevante informatie uit een gesprek op te slaan en op te halen op basis van het ophalen van vectoren.
U kunt VectorStoreRetrieverMemory ook in een keten gebruiken voor het ophalen van kennis op basis van gesprekken, zoals u in de vorige voorbeelden kunt zien.
Deze verschillende geheugentypen in Langchain bieden verschillende manieren om informatie uit gesprekken te beheren en op te halen, waardoor de mogelijkheden van AI-modellen bij het begrijpen en reageren op gebruikersvragen en context worden vergroot. Elk geheugentype kan worden geselecteerd op basis van de specifieke vereisten van uw toepassing.
Nu zullen we leren hoe we geheugen kunnen gebruiken met een LLMChain. Met geheugen in een LLMChain kan het model eerdere interacties en context onthouden om meer samenhangende en contextbewuste reacties te bieden.
Als u geheugen in een LLMChain wilt instellen, moet u een geheugenklasse maken, zoals ConversationBufferMemory. Zo kun je het instellen:
from langchain.chains import LLMChain
from langchain.llms import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.prompts import PromptTemplate template = """You are a chatbot having a conversation with a human. {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history") llm = OpenAI()
llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) llm_chain.predict(human_input="Hi there my friend")
In dit voorbeeld wordt de ConversationBufferMemory gebruikt om de gespreksgeschiedenis op te slaan. De memory_key parameter specificeert de sleutel die wordt gebruikt om de gespreksgeschiedenis op te slaan.
Als u een chatmodel gebruikt in plaats van een voltooiingsmodel, kunt u uw aanwijzingen anders structureren om het geheugen beter te benutten. Hier is een voorbeeld van hoe u een op een chatmodel gebaseerde LLMChain met geheugen instelt:
from langchain.chat_models import ChatOpenAI
from langchain.schema import SystemMessage
from langchain.prompts import ( ChatPromptTemplate, HumanMessagePromptTemplate, MessagesPlaceholder,
) # Create a ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages( [ SystemMessage( content="You are a chatbot having a conversation with a human." ), # The persistent system prompt MessagesPlaceholder( variable_name="chat_history" ), # Where the memory will be stored. HumanMessagePromptTemplate.from_template( "{human_input}" ), # Where the human input will be injected ]
) memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True) llm = ChatOpenAI() chat_llm_chain = LLMChain( llm=llm, prompt=prompt, verbose=True, memory=memory,
) chat_llm_chain.predict(human_input="Hi there my friend")
In dit voorbeeld wordt de ChatPromptTemplate gebruikt om de prompt te structureren, en wordt de ConversationBufferMemory gebruikt om de gespreksgeschiedenis op te slaan en op te halen. Deze aanpak is vooral handig voor gesprekken in chatstijl waarbij context en geschiedenis een cruciale rol spelen.
Geheugen kan ook worden toegevoegd aan een keten met meerdere invoergegevens, zoals een vraag/antwoordketen. Hier is een voorbeeld van hoe u geheugen in een vraag-/antwoordketen kunt instellen:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.embeddings.cohere import CohereEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
from langchain.vectorstores import Chroma
from langchain.docstore.document import Document
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory # Split a long document into smaller chunks
with open("../../state_of_the_union.txt") as f: state_of_the_union = f.read()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union) # Create an ElasticVectorSearch instance to index and search the document chunks
embeddings = OpenAIEmbeddings()
docsearch = Chroma.from_texts( texts, embeddings, metadatas=[{"source": i} for i in range(len(texts))]
) # Perform a question about the document
query = "What did the president say about Justice Breyer"
docs = docsearch.similarity_search(query) # Set up a prompt for the question-answering chain with memory
template = """You are a chatbot having a conversation with a human. Given the following extracted parts of a long document and a question, create a final answer. {context} {chat_history}
Human: {human_input}
Chatbot:""" prompt = PromptTemplate( input_variables=["chat_history", "human_input", "context"], template=template
)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input")
chain = load_qa_chain( OpenAI(temperature=0), chain_type="stuff", memory=memory, prompt=prompt
) # Ask the question and retrieve the answer
query = "What did the president say about Justice Breyer"
result = chain({"input_documents": docs, "human_input": query}, return_only_outputs=True) print(result)
print(chain.memory.buffer)
In dit voorbeeld wordt een vraag beantwoord met behulp van een document dat in kleinere delen is opgesplitst. De ConversationBufferMemory wordt gebruikt om de gespreksgeschiedenis op te slaan en op te halen, waardoor het model contextbewuste antwoorden kan geven.
Door geheugen aan een agent toe te voegen, kan deze eerdere interacties onthouden en gebruiken om vragen te beantwoorden en contextbewuste antwoorden te geven. Zo kunt u geheugen in een agent instellen:
from langchain.agents import ZeroShotAgent, Tool, AgentExecutor
from langchain.memory import ConversationBufferMemory
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.utilities import GoogleSearchAPIWrapper # Create a tool for searching
search = GoogleSearchAPIWrapper()
tools = [ Tool( name="Search", func=search.run, description="useful for when you need to answer questions about current events", )
] # Create a prompt with memory
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!" {chat_history}
Question: {input}
{agent_scratchpad}""" prompt = ZeroShotAgent.create_prompt( tools, prefix=prefix, suffix=suffix, input_variables=["input", "chat_history", "agent_scratchpad"],
)
memory = ConversationBufferMemory(memory_key="chat_history") # Create an LLMChain with memory
llm_chain = LLMChain(llm=OpenAI(temperature=0), prompt=prompt)
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
agent_chain = AgentExecutor.from_agent_and_tools( agent=agent, tools=tools, verbose=True, memory=memory
) # Ask a question and retrieve the answer
response = agent_chain.run(input="How many people live in Canada?")
print(response) # Ask a follow-up question
response = agent_chain.run(input="What is their national anthem called?")
print(response)
In dit voorbeeld wordt geheugen aan een agent toegevoegd, waardoor deze de eerdere gespreksgeschiedenis kan onthouden en contextbewuste antwoorden kan geven. Hierdoor kan de agent vervolgvragen nauwkeurig beantwoorden op basis van de informatie die in het geheugen is opgeslagen.
LangChain-expressietaal
In de wereld van natuurlijke taalverwerking en machinaal leren kan het samenstellen van complexe ketens van bewerkingen een hele klus zijn. Gelukkig komt LangChain Expression Language (LCEL) te hulp en biedt een declaratieve en efficiënte manier om geavanceerde pijplijnen voor taalverwerking te bouwen en in te zetten. LCEL is ontworpen om het proces van het samenstellen van ketens te vereenvoudigen, waardoor het mogelijk wordt om gemakkelijk van prototyping naar productie te gaan. In deze blog onderzoeken we wat LCEL is en waarom je het zou willen gebruiken, samen met praktische codevoorbeelden om de mogelijkheden ervan te illustreren.
LCEL, of LangChain Expression Language, is een krachtig hulpmiddel voor het samenstellen van taalverwerkingsketens. Het is speciaal gebouwd om de overgang van prototyping naar productie naadloos te ondersteunen, zonder dat uitgebreide codewijzigingen nodig zijn. Of u nu een eenvoudige “prompt + LLM”-keten bouwt of een complexe pijplijn met honderden stappen, LCEL staat voor u klaar.
Hier zijn enkele redenen om LCEL te gebruiken in uw taalverwerkingsprojecten:
- Snelle tokenstreaming: LCEL levert tokens van een taalmodel in realtime aan een uitvoerparser, waardoor de responsiviteit en efficiëntie worden verbeterd.
- Veelzijdige API's: LCEL ondersteunt zowel synchrone als asynchrone API's voor prototyping en productiegebruik, waardoor meerdere verzoeken efficiënt worden afgehandeld.
- Automatische parallellisatie: LCEL optimaliseert waar mogelijk de parallelle uitvoering, waardoor de latentie in zowel synchronisatie- als asynchrone interfaces wordt verminderd.
- Betrouwbare configuraties: Configureer nieuwe pogingen en fallbacks voor verbeterde ketenbetrouwbaarheid op schaal, met ondersteuning voor streaming in ontwikkeling.
- Tussenresultaten streamen: Krijg toegang tot tussenresultaten tijdens de verwerking voor gebruikersupdates of foutopsporingsdoeleinden.
- Schema genereren: LCEL genereert Pydantic- en JSONSchema-schema's voor invoer- en uitvoervalidatie.
- Uitgebreide tracering: LangSmith traceert automatisch alle stappen in complexe ketens voor observatie en foutopsporing.
- Eenvoudige implementatie: Implementeer moeiteloos door LCEL gemaakte ketens met LangServe.
Laten we nu eens kijken naar praktische codevoorbeelden die de kracht van LCEL demonstreren. We onderzoeken algemene taken en scenario's waarin LCEL uitblinkt.
Prompt + LLM
De meest fundamentele samenstelling omvat het combineren van een prompt en een taalmodel om een keten te creëren die gebruikersinvoer opneemt, deze aan een prompt toevoegt, deze doorgeeft aan een model en de ruwe modeluitvoer retourneert. Hier is een voorbeeld:
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI prompt = ChatPromptTemplate.from_template("tell me a joke about {foo}")
model = ChatOpenAI()
chain = prompt | model result = chain.invoke({"foo": "bears"})
print(result)
In dit voorbeeld genereert de ketting een grap over beren.
U kunt stopreeksen aan uw keten koppelen om te bepalen hoe deze tekst verwerkt. Bijvoorbeeld:
chain = prompt | model.bind(stop=["n"])
result = chain.invoke({"foo": "bears"})
print(result)
Deze configuratie stopt het genereren van tekst wanneer een nieuwregelteken wordt aangetroffen.
LCEL ondersteunt het koppelen van functieoproepinformatie aan uw keten. Hier is een voorbeeld:
functions = [ { "name": "joke", "description": "A joke", "parameters": { "type": "object", "properties": { "setup": {"type": "string", "description": "The setup for the joke"}, "punchline": { "type": "string", "description": "The punchline for the joke", }, }, "required": ["setup", "punchline"], }, }
]
chain = prompt | model.bind(function_call={"name": "joke"}, functions=functions)
result = chain.invoke({"foo": "bears"}, config={})
print(result)
In dit voorbeeld worden functieaanroepgegevens toegevoegd om een grap te genereren.
Prompt + LLM + OutputParser
U kunt een uitvoerparser toevoegen om de uitvoer van het onbewerkte model om te zetten in een beter werkbaar formaat. Hier ziet u hoe u het kunt doen:
from langchain.schema.output_parser import StrOutputParser chain = prompt | model | StrOutputParser()
result = chain.invoke({"foo": "bears"})
print(result)
De uitvoer is nu in een string-indeling, wat handiger is voor downstream-taken.
Wanneer u een functie opgeeft die moet worden geretourneerd, kunt u deze rechtstreeks parseren met behulp van LCEL. Bijvoorbeeld:
from langchain.output_parsers.openai_functions import JsonOutputFunctionsParser chain = ( prompt | model.bind(function_call={"name": "joke"}, functions=functions) | JsonOutputFunctionsParser()
)
result = chain.invoke({"foo": "bears"})
print(result)
In dit voorbeeld wordt de uitvoer van de functie "grap" rechtstreeks ontleed.
Dit zijn slechts enkele voorbeelden van hoe LCEL complexe taalverwerkingstaken vereenvoudigt. Of u nu chatbots bouwt, inhoud genereert of complexe teksttransformaties uitvoert, LCEL kan uw workflow stroomlijnen en uw code beter onderhoudbaar maken.
RAG (ophaalbare generatie)
LCEL kan worden gebruikt om ophaal-verbeterde generatieketens te creëren, die ophaal- en taalgeneratiestappen combineren. Hier is een voorbeeld:
from operator import itemgetter from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.vectorstores import FAISS # Create a vector store and retriever
vectorstore = FAISS.from_texts( ["harrison worked at kensho"], embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever() # Define templates for prompts
template = """Answer the question based only on the following context:
{context} Question: {question} """
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() # Create a retrieval-augmented generation chain
chain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser()
) result = chain.invoke("where did harrison work?")
print(result)
In dit voorbeeld haalt de keten relevante informatie uit de context en genereert een antwoord op de vraag.
Conversationele ophaalketen
U kunt eenvoudig gespreksgeschiedenis aan uw ketens toevoegen. Hier is een voorbeeld van een conversatie-ophaalketen:
from langchain.schema.runnable import RunnableMap
from langchain.schema import format_document from langchain.prompts.prompt import PromptTemplate # Define templates for prompts
_template = """Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language. Chat History:
{chat_history}
Follow Up Input: {question}
Standalone question:"""
CONDENSE_QUESTION_PROMPT = PromptTemplate.from_template(_template) template = """Answer the question based only on the following context:
{context} Question: {question} """
ANSWER_PROMPT = ChatPromptTemplate.from_template(template) # Define input map and context
_inputs = RunnableMap( standalone_question=RunnablePassthrough.assign( chat_history=lambda x: _format_chat_history(x["chat_history"]) ) | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
)
_context = { "context": itemgetter("standalone_question") | retriever | _combine_documents, "question": lambda x: x["standalone_question"],
}
conversational_qa_chain = _inputs | _context | ANSWER_PROMPT | ChatOpenAI() result = conversational_qa_chain.invoke( { "question": "where did harrison work?", "chat_history": [], }
)
print(result)
In dit voorbeeld behandelt de keten een vervolgvraag binnen een gesprekscontext.
Met geheugen en terugkerende brondocumenten
LCEL ondersteunt ook geheugen en het retourneren van brondocumenten. Zo kunt u geheugen in een keten gebruiken:
from operator import itemgetter
from langchain.memory import ConversationBufferMemory # Create a memory instance
memory = ConversationBufferMemory( return_messages=True, output_key="answer", input_key="question"
) # Define steps for the chain
loaded_memory = RunnablePassthrough.assign( chat_history=RunnableLambda(memory.load_memory_variables) | itemgetter("history"),
) standalone_question = { "standalone_question": { "question": lambda x: x["question"], "chat_history": lambda x: _format_chat_history(x["chat_history"]), } | CONDENSE_QUESTION_PROMPT | ChatOpenAI(temperature=0) | StrOutputParser(),
} retrieved_documents = { "docs": itemgetter("standalone_question") | retriever, "question": lambda x: x["standalone_question"],
} final_inputs = { "context": lambda x: _combine_documents(x["docs"]), "question": itemgetter("question"),
} answer = { "answer": final_inputs | ANSWER_PROMPT | ChatOpenAI(), "docs": itemgetter("docs"),
} # Create the final chain by combining the steps
final_chain = loaded_memory | standalone_question | retrieved_documents | answer inputs = {"question": "where did harrison work?"}
result = final_chain.invoke(inputs)
print(result)
In dit voorbeeld wordt geheugen gebruikt voor het opslaan en ophalen van de gespreksgeschiedenis en brondocumenten.
Meerdere ketens
Je kunt meerdere ketens aan elkaar rijgen met Runnables. Hier is een voorbeeld:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser prompt1 = ChatPromptTemplate.from_template("what is the city {person} is from?")
prompt2 = ChatPromptTemplate.from_template( "what country is the city {city} in? respond in {language}"
) model = ChatOpenAI() chain1 = prompt1 | model | StrOutputParser() chain2 = ( {"city": chain1, "language": itemgetter("language")} | prompt2 | model | StrOutputParser()
) result = chain2.invoke({"person": "obama", "language": "spanish"})
print(result)
In dit voorbeeld worden twee ketens gecombineerd om informatie over een stad en haar land in een bepaalde taal te genereren.
Vertakkingen en samenvoegen
Met LCEL kunt u ketens splitsen en samenvoegen met behulp van RunnableMaps. Hier is een voorbeeld van vertakken en samenvoegen:
from operator import itemgetter from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import StrOutputParser planner = ( ChatPromptTemplate.from_template("Generate an argument about: {input}") | ChatOpenAI() | StrOutputParser() | {"base_response": RunnablePassthrough()}
) arguments_for = ( ChatPromptTemplate.from_template( "List the pros or positive aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
)
arguments_against = ( ChatPromptTemplate.from_template( "List the cons or negative aspects of {base_response}" ) | ChatOpenAI() | StrOutputParser()
) final_responder = ( ChatPromptTemplate.from_messages( [ ("ai", "{original_response}"), ("human", "Pros:n{results_1}nnCons:n{results_2}"), ("system", "Generate a final response given the critique"), ] ) | ChatOpenAI() | StrOutputParser()
) chain = ( planner | { "results_1": arguments_for, "results_2": arguments_against, "original_response": itemgetter("base_response"), } | final_responder
) result = chain.invoke({"input": "scrum"})
print(result)
In dit voorbeeld wordt een vertakkings- en samenvoegingsketen gebruikt om een argument te genereren en de voor- en nadelen ervan te evalueren voordat een definitief antwoord wordt gegenereerd.
Python-code schrijven met LCEL
Een van de krachtige toepassingen van LangChain Expression Language (LCEL) is het schrijven van Python-code om gebruikersproblemen op te lossen. Hieronder ziet u een voorbeeld van hoe u LCEL gebruikt om Python-code te schrijven:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain_experimental.utilities import PythonREPL template = """Write some python code to solve the user's problem. Return only python code in Markdown format, e.g.: ```python
....
```"""
prompt = ChatPromptTemplate.from_messages([("system", template), ("human", "{input}")]) model = ChatOpenAI() def _sanitize_output(text: str): _, after = text.split("```python") return after.split("```")[0] chain = prompt | model | StrOutputParser() | _sanitize_output | PythonREPL().run result = chain.invoke({"input": "what's 2 plus 2"})
print(result)
In dit voorbeeld geeft een gebruiker invoer en genereert LCEL Python-code om het probleem op te lossen. De code wordt vervolgens uitgevoerd met behulp van een Python REPL en de resulterende Python-code wordt geretourneerd in Markdown-indeling.
Houd er rekening mee dat het gebruik van een Python REPL willekeurige code kan uitvoeren, dus wees voorzichtig.
Geheugen toevoegen aan een keten
Geheugen is essentieel in veel conversationele AI-toepassingen. Zo voegt u geheugen toe aan een willekeurige keten:
from operator import itemgetter
from langchain.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain.schema.runnable import RunnablePassthrough, RunnableLambda
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder model = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages( [ ("system", "You are a helpful chatbot"), MessagesPlaceholder(variable_name="history"), ("human", "{input}"), ]
) memory = ConversationBufferMemory(return_messages=True) # Initialize memory
memory.load_memory_variables({}) chain = ( RunnablePassthrough.assign( history=RunnableLambda(memory.load_memory_variables) | itemgetter("history") ) | prompt | model
) inputs = {"input": "hi, I'm Bob"}
response = chain.invoke(inputs)
response # Save the conversation in memory
memory.save_context(inputs, {"output": response.content}) # Load memory to see the conversation history
memory.load_memory_variables({})
In dit voorbeeld wordt geheugen gebruikt om de gespreksgeschiedenis op te slaan en op te halen, waardoor de chatbot de context kan behouden en op de juiste manier kan reageren.
Externe tools gebruiken met Runnables
Met LCEL kunt u externe tools naadloos integreren met Runnables. Hier is een voorbeeld met de DuckDuckGo-zoekfunctie:
from langchain.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.tools import DuckDuckGoSearchRun search = DuckDuckGoSearchRun() template = """Turn the following user input into a search query for a search engine: {input}"""
prompt = ChatPromptTemplate.from_template(template) model = ChatOpenAI() chain = prompt | model | StrOutputParser() | search search_result = chain.invoke({"input": "I'd like to figure out what games are tonight"})
print(search_result)
In dit voorbeeld integreert LCEL de DuckDuckGo Search-tool in de keten, waardoor deze een zoekopdracht kan genereren op basis van gebruikersinvoer en zoekresultaten kan ophalen.
De flexibiliteit van LCEL maakt het gemakkelijk om verschillende externe tools en diensten in uw taalverwerkingspijplijnen op te nemen, waardoor hun mogelijkheden en functionaliteit worden verbeterd.
Moderatie toevoegen aan een LLM-applicatie
Om ervoor te zorgen dat uw LLM-applicatie voldoet aan het inhoudsbeleid en moderatiewaarborgen omvat, kunt u moderatiecontroles in uw keten integreren. U kunt als volgt moderatie toevoegen met LangChain:
from langchain.chains import OpenAIModerationChain
from langchain.llms import OpenAI
from langchain.prompts import ChatPromptTemplate moderate = OpenAIModerationChain() model = OpenAI()
prompt = ChatPromptTemplate.from_messages([("system", "repeat after me: {input}")]) chain = prompt | model # Original response without moderation
response_without_moderation = chain.invoke({"input": "you are stupid"})
print(response_without_moderation) moderated_chain = chain | moderate # Response after moderation
response_after_moderation = moderated_chain.invoke({"input": "you are stupid"})
print(response_after_moderation)
In dit voorbeeld is de OpenAIModerationChain wordt gebruikt om moderatie toe te voegen aan de reactie die door de LLM wordt gegenereerd. De moderatieketen controleert de reactie op inhoud die het inhoudsbeleid van OpenAI schendt. Als er overtredingen worden geconstateerd, wordt de reactie dienovereenkomstig gemarkeerd.
Routering op basis van semantische gelijkenis
Met LCEL kunt u aangepaste routeringslogica implementeren op basis van de semantische gelijkenis van gebruikersinvoer. Hier is een voorbeeld van hoe u de ketenlogica dynamisch kunt bepalen op basis van gebruikersinvoer:
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
from langchain.utils.math import cosine_similarity physics_template = """You are a very smart physics professor. You are great at answering questions about physics in a concise and easy to understand manner. When you don't know the answer to a question you admit that you don't know. Here is a question:
{query}""" math_template = """You are a very good mathematician. You are great at answering math questions. You are so good because you are able to break down hard problems into their component parts, answer the component parts, and then put them together to answer the broader question. Here is a question:
{query}""" embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates) def prompt_router(input): query_embedding = embeddings.embed_query(input["query"]) similarity = cosine_similarity([query_embedding], prompt_embeddings)[0] most_similar = prompt_templates[similarity.argmax()] print("Using MATH" if most_similar == math_template else "Using PHYSICS") return PromptTemplate.from_template(most_similar) chain = ( {"query": RunnablePassthrough()} | RunnableLambda(prompt_router) | ChatOpenAI() | StrOutputParser()
) print(chain.invoke({"query": "What's a black hole"}))
print(chain.invoke({"query": "What's a path integral"}))
In dit voorbeeld is de prompt_router functie berekent de cosinusovereenkomst tussen gebruikersinvoer en vooraf gedefinieerde promptsjablonen voor natuurkunde- en wiskundevragen. Op basis van de gelijkenisscore selecteert de keten dynamisch het meest relevante promptsjabloon, zodat de chatbot op de juiste manier reageert op de vraag van de gebruiker.
Agenten en Runnables gebruiken
Met LangChain kunt u agenten maken door Runnables, aanwijzingen, modellen en hulpmiddelen te combineren. Hier is een voorbeeld van het bouwen van een agent en het gebruik ervan:
from langchain.agents import XMLAgent, tool, AgentExecutor
from langchain.chat_models import ChatAnthropic model = ChatAnthropic(model="claude-2") @tool
def search(query: str) -> str: """Search things about current events.""" return "32 degrees" tool_list = [search] # Get prompt to use
prompt = XMLAgent.get_default_prompt() # Logic for going from intermediate steps to a string to pass into the model
def convert_intermediate_steps(intermediate_steps): log = "" for action, observation in intermediate_steps: log += ( f"<tool>{action.tool}</tool><tool_input>{action.tool_input}" f"</tool_input><observation>{observation}</observation>" ) return log # Logic for converting tools to a string to go in the prompt
def convert_tools(tools): return "n".join([f"{tool.name}: {tool.description}" for tool in tools]) agent = ( { "question": lambda x: x["question"], "intermediate_steps": lambda x: convert_intermediate_steps( x["intermediate_steps"] ), } | prompt.partial(tools=convert_tools(tool_list)) | model.bind(stop=["</tool_input>", "</final_answer>"]) | XMLAgent.get_default_output_parser()
) agent_executor = AgentExecutor(agent=agent, tools=tool_list, verbose=True) result = agent_executor.invoke({"question": "What's the weather in New York?"})
print(result)
In dit voorbeeld wordt een agent gemaakt door een model, tools, een aanwijzing en aangepaste logica voor tussenstappen en toolconversie te combineren. De agent wordt vervolgens uitgevoerd en geeft een antwoord op de vraag van de gebruiker.
Een SQL-database opvragen
U kunt LangChain gebruiken om query's uit te voeren op een SQL-database en SQL-query's te genereren op basis van gebruikersvragen. Hier is een voorbeeld:
from langchain.prompts import ChatPromptTemplate template = """Based on the table schema below, write a SQL query that would answer the user's question:
{schema} Question: {question}
SQL Query:"""
prompt = ChatPromptTemplate.from_template(template) from langchain.utilities import SQLDatabase # Initialize the database (you'll need the Chinook sample DB for this example)
db = SQLDatabase.from_uri("sqlite:///./Chinook.db") def get_schema(_): return db.get_table_info() def run_query(query): return db.run(query) from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnablePassthrough model = ChatOpenAI() sql_response = ( RunnablePassthrough.assign(schema=get_schema) | prompt | model.bind(stop=["nSQLResult:"]) | StrOutputParser()
) result = sql_response.invoke({"question": "How many employees are there?"})
print(result) template = """Based on the table schema below, question, SQL query, and SQL response, write a natural language response:
{schema} Question: {question}
SQL Query: {query}
SQL Response: {response}"""
prompt_response = ChatPromptTemplate.from_template(template) full_chain = ( RunnablePassthrough.assign(query=sql_response) | RunnablePassthrough.assign( schema=get_schema, response=lambda x: db.run(x["query"]), ) | prompt_response | model
) response = full_chain.invoke({"question": "How many employees are there?"})
print(response)
In dit voorbeeld wordt LangChain gebruikt om SQL-query's te genereren op basis van gebruikersvragen en antwoorden op te halen uit een SQL-database. De aanwijzingen en antwoorden zijn zo opgemaakt dat interacties in natuurlijke taal met de database mogelijk zijn.
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
LangServe & LangSmith
LangServe helpt ontwikkelaars bij het implementeren van LangChain-runnables en -ketens als een REST API. Deze bibliotheek is geïntegreerd met FastAPI en gebruikt pydantic voor gegevensvalidatie. Bovendien biedt het een client die kan worden gebruikt om runnables aan te roepen die op een server zijn geïmplementeerd, en er is een JavaScript-client beschikbaar in LangChainJS.
Voordelen
- Invoer- en uitvoerschema's worden automatisch afgeleid van uw LangChain-object en afgedwongen bij elke API-aanroep, met uitgebreide foutmeldingen.
- Er is een API-documentatiepagina met JSONSchema en Swagger beschikbaar.
- Efficiënte /invoke-, /batch- en /stream-eindpunten met ondersteuning voor veel gelijktijdige verzoeken op één server.
- /stream_log eindpunt voor het streamen van alle (of enkele) tussenstappen van uw keten/agent.
- Speeltuinpagina op /playground met streaming-uitvoer en tussenstappen.
- Ingebouwde (optionele) tracering naar LangSmith; voeg gewoon uw API-sleutel toe (zie instructies).
- Allemaal gebouwd met beproefde open-source Python-bibliotheken zoals FastAPI, Pydantic, uvloop en asyncio.
Beperkingen
- Client-callbacks worden nog niet ondersteund voor gebeurtenissen die afkomstig zijn van de server.
- OpenAPI-documenten worden niet gegenereerd bij gebruik van Pydantic V2. FastAPI biedt geen ondersteuning voor het combineren van pydantic v1- en v2-naamruimten. Zie het onderstaande gedeelte voor meer details.
Gebruik de LangChain CLI om snel een LangServe-project op te starten. Om de langchain CLI te gebruiken, zorg ervoor dat u een recente versie van langchain-cli geïnstalleerd heeft. Je kunt het installeren met pip install -U langchain-cli.
langchain app new ../path/to/directory
Zorg ervoor dat uw LangServe-instantie snel aan de slag gaat met LangChain-sjablonen. Zie de sjablonenindex of de map met voorbeelden voor meer voorbeelden.
Hier is een server die een OpenAI-chatmodel gebruikt, een Antropisch chatmodel en een keten die het Antropisch model gebruikt om een grap over een onderwerp te vertellen.
#!/usr/bin/env python
from fastapi import FastAPI
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic, ChatOpenAI
from langserve import add_routes app = FastAPI( title="LangChain Server", version="1.0", description="A simple api server using Langchain's Runnable interfaces",
) add_routes( app, ChatOpenAI(), path="/openai",
) add_routes( app, ChatAnthropic(), path="/anthropic",
) model = ChatAnthropic()
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
add_routes( app, prompt | model, path="/chain",
) if __name__ == "__main__": import uvicorn uvicorn.run(app, host="localhost", port=8000)
Nadat u de bovenstaande server heeft geïmplementeerd, kunt u de gegenereerde OpenAPI-documenten bekijken met behulp van:
curl localhost:8000/docs
Zorg ervoor dat u het achtervoegsel /docs toevoegt.
from langchain.schema import SystemMessage, HumanMessage
from langchain.prompts import ChatPromptTemplate
from langchain.schema.runnable import RunnableMap
from langserve import RemoteRunnable openai = RemoteRunnable("http://localhost:8000/openai/")
anthropic = RemoteRunnable("http://localhost:8000/anthropic/")
joke_chain = RemoteRunnable("http://localhost:8000/chain/") joke_chain.invoke({"topic": "parrots"}) # or async
await joke_chain.ainvoke({"topic": "parrots"}) prompt = [ SystemMessage(content='Act like either a cat or a parrot.'), HumanMessage(content='Hello!')
] # Supports astream
async for msg in anthropic.astream(prompt): print(msg, end="", flush=True) prompt = ChatPromptTemplate.from_messages( [("system", "Tell me a long story about {topic}")]
) # Can define custom chains
chain = prompt | RunnableMap({ "openai": openai, "anthropic": anthropic,
}) chain.batch([{ "topic": "parrots" }, { "topic": "cats" }])
In TypeScript (vereist LangChain.js versie 0.0.166 of hoger):
import { RemoteRunnable } from "langchain/runnables/remote"; const chain = new RemoteRunnable({ url: `http://localhost:8000/chain/invoke/`,
});
const result = await chain.invoke({ topic: "cats",
});
Python gebruikt verzoeken:
import requests
response = requests.post( "http://localhost:8000/chain/invoke/", json={'input': {'topic': 'cats'}}
)
response.json()
Je kunt ook krul gebruiken:
curl --location --request POST 'http://localhost:8000/chain/invoke/' --header 'Content-Type: application/json' --data-raw '{ "input": { "topic": "cats" } }'
De volgende code:
...
add_routes( app, runnable, path="/my_runnable",
)
voegt deze eindpunten toe aan de server:
- POST /my_runnable/invoke – roep de runnable aan op een enkele invoer
- POST /my_runnable/batch – roep het uitvoerbare bestand aan op een batch invoer
- POST /my_runnable/stream – roep een enkele invoer aan en stream de uitvoer
- POST /my_runnable/stream_log – roep een enkele invoer aan en stream de uitvoer, inclusief de uitvoer van tussenstappen terwijl deze wordt gegenereerd
- GET /my_runnable/input_schema – json-schema voor invoer naar het uitvoerbare bestand
- GET /my_runnable/output_schema – json-schema voor uitvoer van het uitvoerbare bestand
- GET /my_runnable/config_schema – json-schema voor configuratie van het uitvoerbare bestand
Je kunt een speeltuinpagina voor je runnable vinden op /my_runnable/playground. Dit biedt een eenvoudige gebruikersinterface waarmee u uw uitvoerbare bestand kunt configureren en aanroepen met streaminguitvoer en tussenstappen.
Voor zowel client als server:
pip install "langserve[all]"
of pip installeer “langserve[client]” voor clientcode, en pip installeer “langserve[server]” voor servercode.
Als u authenticatie aan uw server moet toevoegen, raadpleeg dan de beveiligingsdocumentatie en middleware-documentatie van FastAPI.
U kunt met de volgende opdracht implementeren in GCP Cloud Run:
gcloud run deploy [your-service-name] --source . --port 8001 --allow-unauthenticated --region us-central1 --set-env-vars=OPENAI_API_KEY=your_key
LangServe biedt ondersteuning voor Pydantic 2 met enkele beperkingen. OpenAPI-documenten worden niet gegenereerd voor invoke/batch/stream/stream_log bij gebruik van Pydantic V2. Fast API biedt geen ondersteuning voor het combineren van pydantic v1- en v2-naamruimten. LangChain gebruikt de v1-naamruimte in Pydantic v2. Lees de volgende richtlijnen om compatibiliteit met LangChain te garanderen. Afgezien van deze beperkingen verwachten we dat de API-eindpunten, de speeltuin en alle andere functies naar verwachting werken.
LLM-applicaties hebben vaak te maken met bestanden. Er zijn verschillende architecturen die kunnen worden gemaakt om bestandsverwerking te implementeren; op een hoog niveau:
- Het bestand kan via een speciaal eindpunt naar de server worden geüpload en via een afzonderlijk eindpunt worden verwerkt.
- Het bestand kan worden geüpload op basis van waarde (bestandsbytes) of referentie (bijvoorbeeld s3-URL naar bestandsinhoud).
- Het verwerkingseindpunt kan blokkerend of niet-blokkerend zijn.
- Als aanzienlijke verwerking vereist is, kan de verwerking worden overgebracht naar een speciale procespool.
U moet bepalen wat de juiste architectuur voor uw toepassing is. Om bestanden op waarde te uploaden naar een uitvoerbaar bestand, gebruikt u momenteel base64-codering voor het bestand (multipart/form-data wordt nog niet ondersteund).
Hier is een voorbeeld dat laat zien hoe je base64-codering gebruikt om een bestand naar een extern uitvoerbaar bestand te verzenden. Houd er rekening mee dat u altijd bestanden kunt uploaden via referentie (bijvoorbeeld de s3-URL) of ze kunt uploaden als meerdelige/formuliergegevens naar een speciaal eindpunt.
Invoer- en uitvoertypen zijn gedefinieerd voor alle uitvoerbare bestanden. U kunt ze openen via de eigenschappen input_schema en output_schema. LangServe gebruikt deze typen voor validatie en documentatie. Als u de standaard afgeleide typen wilt overschrijven, kunt u de methode with_types gebruiken.
Hier is een speelgoedvoorbeeld om het idee te illustreren:
from typing import Any
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda app = FastAPI() def func(x: Any) -> int: """Mistyped function that should accept an int but accepts anything.""" return x + 1 runnable = RunnableLambda(func).with_types( input_schema=int,
) add_routes(app, runnable)
Overerf van CustomUserType als u wilt dat de gegevens worden gedeserialiseerd naar een pydantisch model in plaats van de equivalente dict-representatie. Op dit moment werkt dit type alleen server-side en wordt het gebruikt om het gewenste decodeergedrag te specificeren. Als er van dit type wordt geërfd, zal de server het gedecodeerde type behouden als een pydantisch model in plaats van het in een dictaat om te zetten.
from fastapi import FastAPI
from langchain.schema.runnable import RunnableLambda
from langserve import add_routes
from langserve.schema import CustomUserType app = FastAPI() class Foo(CustomUserType): bar: int def func(foo: Foo) -> int: """Sample function that expects a Foo type which is a pydantic model""" assert isinstance(foo, Foo) return foo.bar add_routes(app, RunnableLambda(func), path="/foo")
Met de speeltuin kunt u vanuit de backend aangepaste widgets voor uw runnable definiëren. Een widget wordt op veldniveau gespecificeerd en verzonden als onderdeel van het JSON-schema van het invoertype. Een widget moet een sleutel bevatten met de naam type, waarbij de waarde een van een bekende lijst met widgets is. Andere widgetsleutels worden gekoppeld aan waarden die paden in een JSON-object beschrijven.
Algemeen schema:
type JsonPath = number | string | (number | string)[];
type NameSpacedPath = { title: string; path: JsonPath }; // Using title to mimic json schema, but can use namespace
type OneOfPath = { oneOf: JsonPath[] }; type Widget = { type: string // Some well-known type (e.g., base64file, chat, etc.) [key: string]: JsonPath | NameSpacedPath | OneOfPath;
};
Maakt het mogelijk om invoer voor het uploaden van bestanden in de UI-speeltuin te maken voor bestanden die worden geüpload als met base64 gecodeerde tekenreeksen. Hier is het volledige voorbeeld.
try: from pydantic.v1 import Field
except ImportError: from pydantic import Field from langserve import CustomUserType # ATTENTION: Inherit from CustomUserType instead of BaseModel otherwise
# the server will decode it into a dict instead of a pydantic model.
class FileProcessingRequest(CustomUserType): """Request including a base64 encoded file.""" # The extra field is used to specify a widget for the playground UI. file: str = Field(..., extra={"widget": {"type": "base64file"}}) num_chars: int = 100
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
Inleiding tot LangSmith
LangChain maakt het eenvoudig om LLM-applicaties en agenten te prototypen. Het kan echter bedrieglijk moeilijk zijn om LLM-applicaties in productie te brengen. U zult waarschijnlijk uw aanwijzingen, ketens en andere componenten zwaar moeten aanpassen en herhalen om een product van hoge kwaliteit te creëren.
Om dit proces te ondersteunen werd LangSmith geïntroduceerd, een uniform platform voor het debuggen, testen en monitoren van uw LLM-applicaties.
Wanneer zou dit van pas kunnen komen? U vindt dit wellicht handig als u snel fouten wilt opsporen in een nieuwe keten, agent of set tools, wilt visualiseren hoe componenten (ketens, llm's, retrievers, etc.) zich verhouden en worden gebruikt, verschillende aanwijzingen en LLM's voor een enkele component wilt evalueren, voer een bepaalde keten meerdere keren uit over een dataset om ervoor te zorgen dat deze consistent aan een kwaliteitsnorm voldoet, of leg gebruikssporen vast en gebruik LLM's of analysepijplijnen om inzichten te genereren.
Vereisten:
- Maak een LangSmith-account aan en maak een API-sleutel aan (zie linkerbenedenhoek).
- Maak uzelf vertrouwd met het platform door de documenten te bekijken.
Laten we beginnen!
Configureer eerst uw omgevingsvariabelen om LangChain te vertellen traceringen te loggen. Dit wordt gedaan door de omgevingsvariabele LANGCHAIN_TRACING_V2 in te stellen op true. U kunt LangChain vertellen op welk project moet worden ingelogd door de omgevingsvariabele LANGCHAIN_PROJECT in te stellen (als deze niet is ingesteld, worden uitvoeringen geregistreerd in het standaardproject). Hierdoor wordt het project automatisch voor u gemaakt als het nog niet bestaat. U moet ook de omgevingsvariabelen LANGCHAIN_ENDPOINT en LANGCHAIN_API_KEY instellen.
OPMERKING: u kunt ook een contextmanager in Python gebruiken om sporen te loggen met behulp van:
from langchain.callbacks.manager import tracing_v2_enabled with tracing_v2_enabled(project_name="My Project"): agent.run("How many people live in canada as of 2023?")
In dit voorbeeld gebruiken we echter omgevingsvariabelen.
%pip install openai tiktoken pandas duckduckgo-search --quiet import os
from uuid import uuid4 unique_id = uuid4().hex[0:8]
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = f"Tracing Walkthrough - {unique_id}"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = "<YOUR-API-KEY>" # Update to your API key # Used by the agent in this tutorial
os.environ["OPENAI_API_KEY"] = "<YOUR-OPENAI-API-KEY>"
Maak de LangSmith-client voor interactie met de API:
from langsmith import Client client = Client()
Maak een LangChain-component en log runs naar het platform. In dit voorbeeld maken we een agent in ReAct-stijl met toegang tot een algemene zoekfunctie (DuckDuckGo). De prompt van de agent kan hier in de Hub worden bekeken:
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents.format_scratchpad import format_to_openai_function_messages
from langchain.agents.output_parsers import OpenAIFunctionsAgentOutputParser
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchResults
from langchain.tools.render import format_tool_to_openai_function # Fetches the latest version of this prompt
prompt = hub.pull("wfh/langsmith-agent-prompt:latest") llm = ChatOpenAI( model="gpt-3.5-turbo-16k", temperature=0,
) tools = [ DuckDuckGoSearchResults( name="duck_duck_go" ), # General internet search using DuckDuckGo
] llm_with_tools = llm.bind(functions=[format_tool_to_openai_function(t) for t in tools]) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser()
) agent_executor = AgentExecutor( agent=runnable_agent, tools=tools, handle_parsing_errors=True
)
We voeren de agent gelijktijdig uit op meerdere ingangen om de latentie te verminderen. Uitvoeringen worden op de achtergrond bij LangSmith geregistreerd, zodat de latentie van de uitvoering niet wordt beïnvloed:
inputs = [ "What is LangChain?", "What's LangSmith?", "When was Llama-v2 released?", "What is the langsmith cookbook?", "When did langchain first announce the hub?",
] results = agent_executor.batch([{"input": x} for x in inputs], return_exceptions=True) results[:2]
Ervan uitgaande dat u uw omgeving met succes hebt ingesteld, zouden uw agenttraceringen moeten verschijnen in de sectie Projecten in de app. Gefeliciteerd!
Het lijkt er echter op dat de agent de tools niet effectief gebruikt. Laten we dit evalueren, zodat we een basislijn hebben.
Naast het loggen van runs, kunt u met LangSmith ook uw LLM-applicaties testen en evalueren.
In dit gedeelte ga je LangSmith gebruiken om een benchmarkdataset te maken en AI-ondersteunde evaluatoren op een agent uit te voeren. Dat doe je in een paar stappen:
- Maak een LangSmith-gegevensset:
Hieronder gebruiken we de LangSmith-client om een dataset te maken op basis van de invoervragen van bovenaf en een lijstlabels. U zult deze later gebruiken om de prestaties van een nieuwe agent te meten. Een dataset is een verzameling voorbeelden, die niets meer zijn dan invoer-uitvoerparen die u kunt gebruiken als testcases voor uw toepassing:
outputs = [ "LangChain is an open-source framework for building applications using large language models. It is also the name of the company building LangSmith.", "LangSmith is a unified platform for debugging, testing, and monitoring language model applications and agents powered by LangChain", "July 18, 2023", "The langsmith cookbook is a github repository containing detailed examples of how to use LangSmith to debug, evaluate, and monitor large language model-powered applications.", "September 5, 2023",
] dataset_name = f"agent-qa-{unique_id}" dataset = client.create_dataset( dataset_name, description="An example dataset of questions over the LangSmith documentation.",
) for query, answer in zip(inputs, outputs): client.create_example( inputs={"input": query}, outputs={"output": answer}, dataset_id=dataset.id )
- Initialiseer een nieuwe agent om te benchmarken:
Met LangSmith kunt u elke LLM, keten, agent of zelfs een aangepaste functie evalueren. Conversationele agenten zijn stateful (ze hebben geheugen); om ervoor te zorgen dat deze status niet wordt gedeeld tussen dataset-uitvoeringen, zullen we een chain_factory (
oftewel een constructor) functie die voor elke aanroep moet worden geïnitialiseerd:
# Since chains can be stateful (e.g. they can have memory), we provide
# a way to initialize a new chain for each row in the dataset. This is done
# by passing in a factory function that returns a new chain for each row.
def agent_factory(prompt): llm_with_tools = llm.bind( functions=[format_tool_to_openai_function(t) for t in tools] ) runnable_agent = ( { "input": lambda x: x["input"], "agent_scratchpad": lambda x: format_to_openai_function_messages( x["intermediate_steps"] ), } | prompt | llm_with_tools | OpenAIFunctionsAgentOutputParser() ) return AgentExecutor(agent=runnable_agent, tools=tools, handle_parsing_errors=True)
- Evaluatie configureren:
Het handmatig vergelijken van de resultaten van ketens in de gebruikersinterface is effectief, maar kan tijdrovend zijn. Het kan nuttig zijn om geautomatiseerde statistieken en AI-ondersteunde feedback te gebruiken om de prestaties van uw component te evalueren:
from langchain.evaluation import EvaluatorType
from langchain.smith import RunEvalConfig evaluation_config = RunEvalConfig( evaluators=[ EvaluatorType.QA, EvaluatorType.EMBEDDING_DISTANCE, RunEvalConfig.LabeledCriteria("helpfulness"), RunEvalConfig.LabeledScoreString( { "accuracy": """
Score 1: The answer is completely unrelated to the reference.
Score 3: The answer has minor relevance but does not align with the reference.
Score 5: The answer has moderate relevance but contains inaccuracies.
Score 7: The answer aligns with the reference but has minor errors or omissions.
Score 10: The answer is completely accurate and aligns perfectly with the reference.""" }, normalize_by=10, ), ], custom_evaluators=[],
)
- Voer de agent en evaluatoren uit:
Gebruik de functie run_on_dataset (of asynchrone arun_on_dataset) om uw model te evalueren. Dit zal:
- Haal voorbeeldrijen op uit de opgegeven gegevensset.
- Voer uw agent (of een aangepaste functie) uit voor elk voorbeeld.
- Pas beoordelaars toe op de resulterende runtraces en bijbehorende referentievoorbeelden om geautomatiseerde feedback te genereren.
De resultaten zijn zichtbaar in de LangSmith-app:
chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-5d466cbc-{unique_id}", tags=[ "testing-notebook", "prompt:5d466cbc", ],
)
Nu we onze testrunresultaten hebben, kunnen we wijzigingen aanbrengen in onze agent en deze benchmarken. Laten we dit opnieuw proberen met een andere prompt en de resultaten bekijken:
candidate_prompt = hub.pull("wfh/langsmith-agent-prompt:39f3bbd0") chain_results = run_on_dataset( dataset_name=dataset_name, llm_or_chain_factory=functools.partial(agent_factory, prompt=candidate_prompt), evaluation=evaluation_config, verbose=True, client=client, project_name=f"runnable-agent-test-39f3bbd0-{unique_id}", tags=[ "testing-notebook", "prompt:39f3bbd0", ],
)
Met LangSmith kunt u gegevens rechtstreeks in de webapp exporteren naar veelgebruikte formaten zoals CSV of JSONL. U kunt de client ook gebruiken om runs op te halen voor verdere analyse, om op te slaan in uw eigen database of om te delen met anderen. Laten we de runtraces van de evaluatierun ophalen:
runs = client.list_runs(project_name=chain_results["project_name"], execution_order=1) # After some time, these will be populated.
client.read_project(project_name=chain_results["project_name"]).feedback_stats
Dit was een korte handleiding om aan de slag te gaan, maar er zijn nog veel meer manieren waarop u LangSmith kunt gebruiken om uw ontwikkelaarsstroom te versnellen en betere resultaten te behalen.
Voor meer informatie over hoe u het maximale uit LangSmith kunt halen, raadpleegt u de LangSmith-documentatie.
Ga een level omhoog met nanonetten
Hoewel LangChain een waardevol hulpmiddel is voor het integreren van taalmodellen (LLM's) met uw applicaties, kan het beperkingen ondervinden als het gaat om zakelijke gebruiksscenario's. Laten we onderzoeken hoe Nanonets verder gaat dan LangChain om deze uitdagingen aan te pakken:
1. Uitgebreide dataconnectiviteit:
LangChain biedt connectoren, maar dekt mogelijk niet alle werkruimte-apps en gegevensformaten waar bedrijven op vertrouwen. Nanonets biedt dataconnectoren voor meer dan 100 veelgebruikte werkruimte-apps, waaronder Slack, Notion, Google Suite, Salesforce, Zendesk en nog veel meer. Het ondersteunt ook alle ongestructureerde gegevenstypen zoals PDF's, TXT's, afbeeldingen, audiobestanden en videobestanden, evenals gestructureerde gegevenstypen zoals CSV's, spreadsheets, MongoDB en SQL-databases.

2. Taakautomatisering voor Workspace-apps:
Hoewel het genereren van tekst/antwoorden uitstekend werkt, zijn de mogelijkheden van LangChain beperkt als het gaat om het gebruik van natuurlijke taal om taken uit te voeren in verschillende toepassingen. Nanonets biedt trigger-/actieagenten voor de meest populaire werkruimte-apps, waarmee u workflows kunt opzetten die naar gebeurtenissen luisteren en acties uitvoeren. U kunt bijvoorbeeld e-mailreacties, CRM-invoer, SQL-query's en meer automatiseren, allemaal via natuurlijke taalopdrachten.
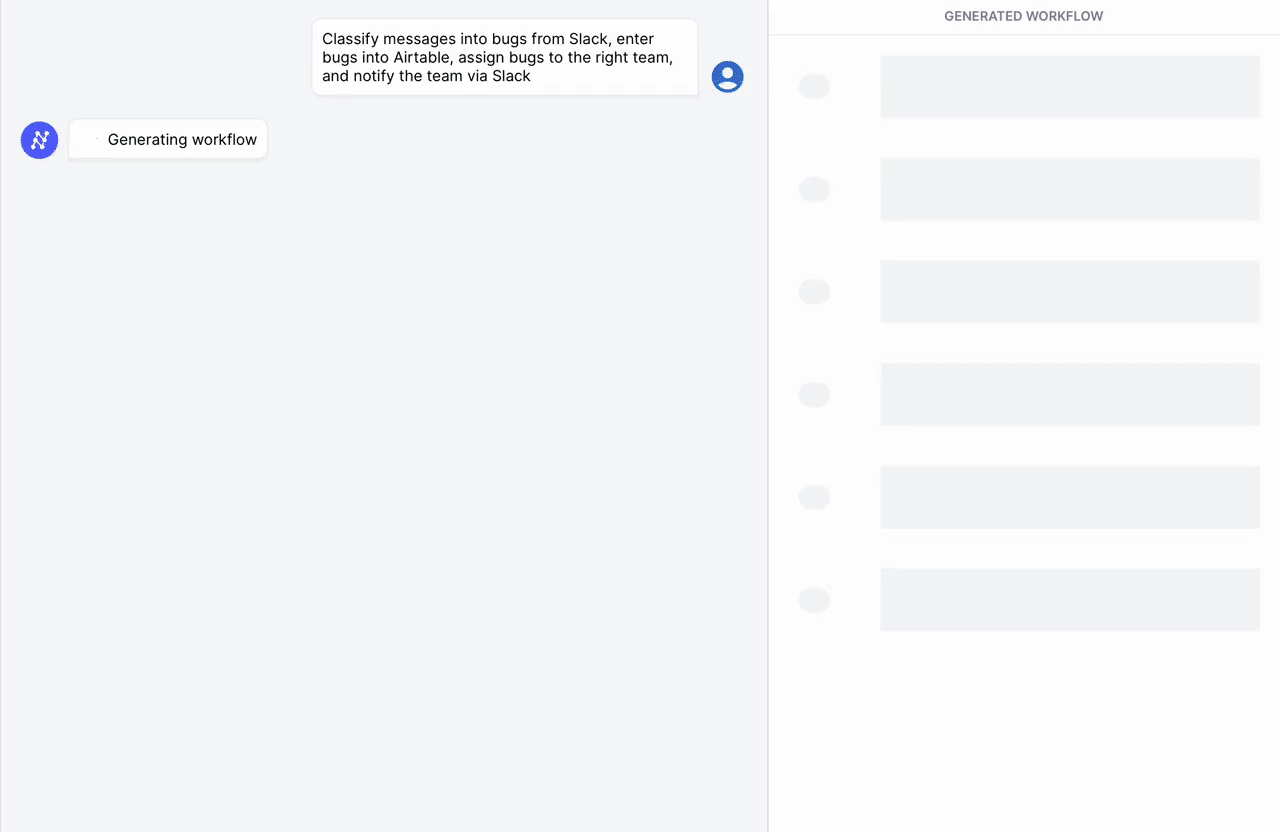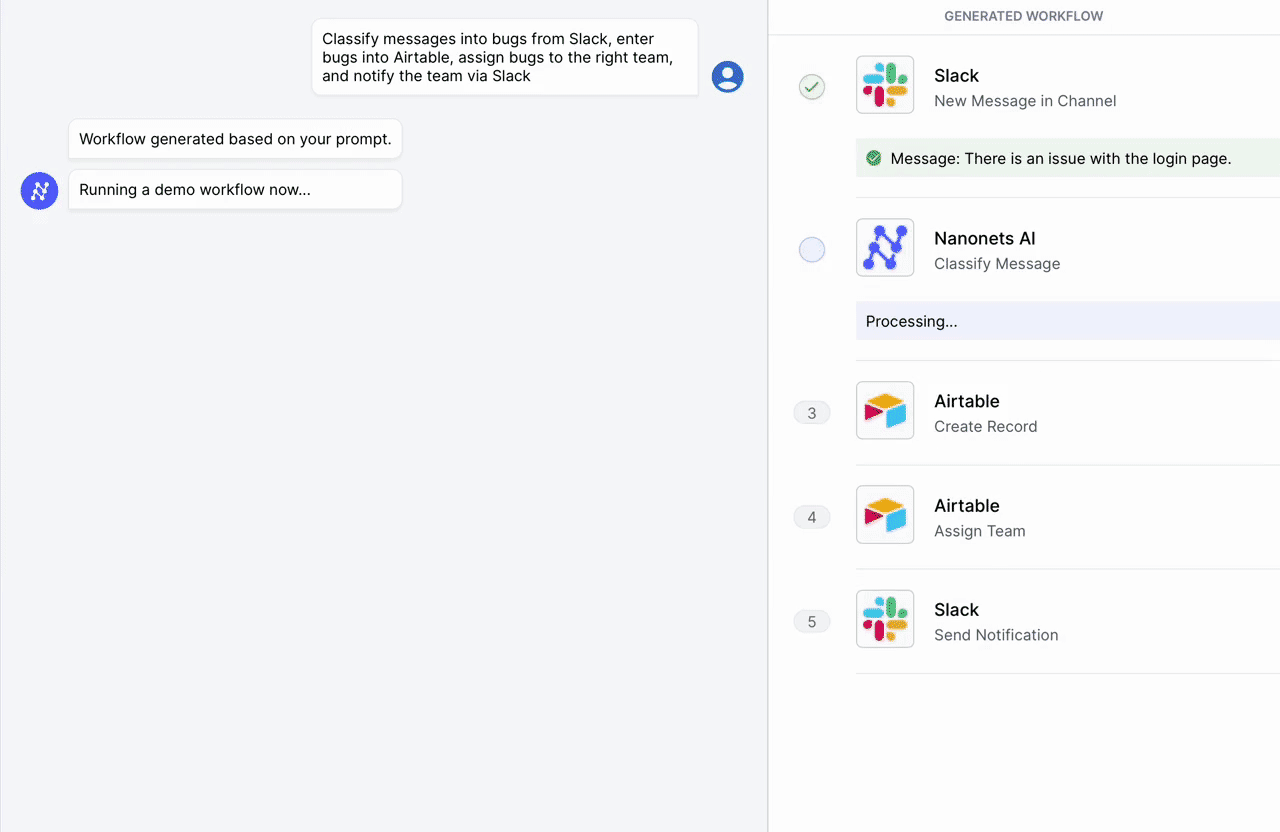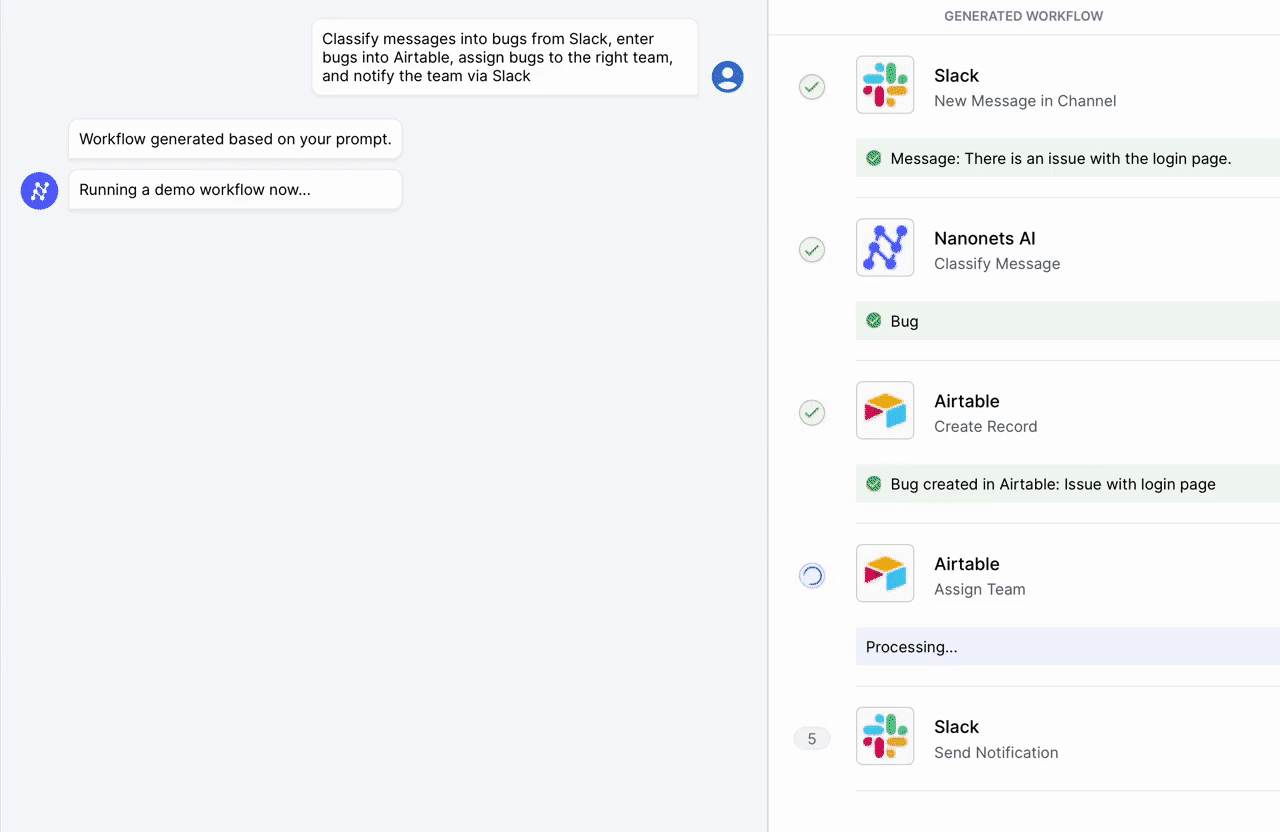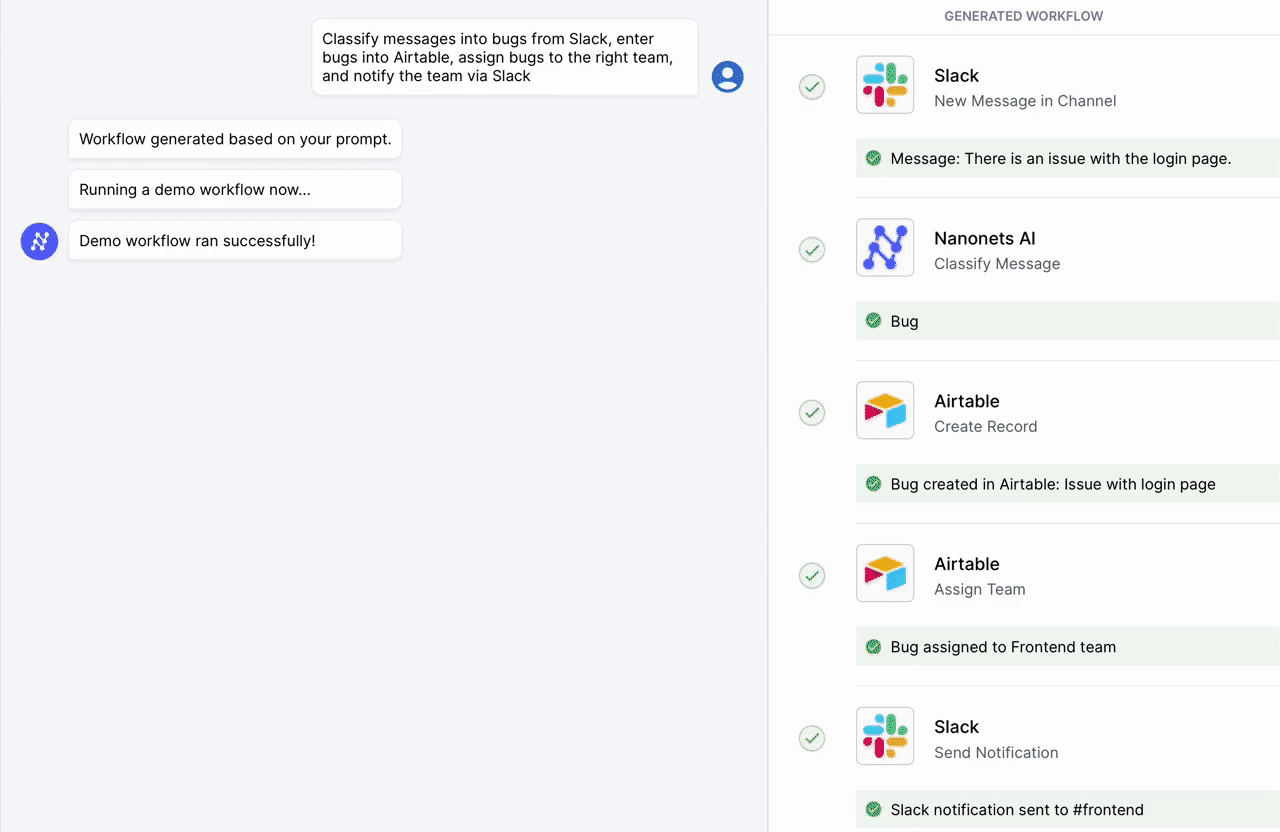
3. Realtime gegevenssynchronisatie:
LangChain haalt statische gegevens op met gegevensconnectoren, die mogelijk geen gelijke tred houden met gegevenswijzigingen in de brondatabase. Nanonets zorgt daarentegen voor realtime synchronisatie met databronnen, zodat u altijd met de nieuwste informatie werkt.

3. Vereenvoudigde configuratie:
Het configureren van de elementen van de LangChain-pijplijn, zoals retrievers en synthesizers, kan een complex en tijdrovend proces zijn. Nanonetten stroomlijnen dit door geoptimaliseerde gegevensopname en indexering voor elk gegevenstype te bieden, allemaal op de achtergrond afgehandeld door de AI-assistent. Dit vermindert de last van het afstemmen en maakt het eenvoudiger om het in te stellen en te gebruiken.
4. Uniforme oplossing:
In tegenstelling tot LangChain, waarvoor mogelijk voor elke taak unieke implementaties nodig zijn, fungeert Nanonets als een totaaloplossing voor het verbinden van uw gegevens met LLM's. Of u nu LLM-applicaties of AI-workflows moet creëren, Nanonets biedt een uniform platform voor uw uiteenlopende behoeften.
Nanonetten AI-workflows
Nanonets Workflows is een veilige, multifunctionele AI-assistent die de integratie van uw kennis en gegevens met LLM's vereenvoudigt en de creatie van no-code-applicaties en workflows vergemakkelijkt. Het biedt een eenvoudig te gebruiken gebruikersinterface, waardoor het toegankelijk is voor zowel individuen als organisaties.
Om aan de slag te gaan, kunt u een gesprek plannen met een van onze AI-experts, die u een gepersonaliseerde demo en proefversie van Nanonets Workflows kan bieden, afgestemd op uw specifieke gebruikssituatie.
Eenmaal ingesteld, kunt u natuurlijke taal gebruiken om complexe applicaties en workflows te ontwerpen en uit te voeren, mogelijk gemaakt door LLM's, en naadloos te integreren met uw apps en gegevens.

Geef uw teams een boost met Nanonets AI om apps te maken en uw gegevens te integreren met AI-gestuurde applicaties en workflows, zodat uw teams zich kunnen concentreren op wat er echt toe doet.
Automatiseer handmatige taken en workflows met onze AI-gestuurde workflowbuilder, ontworpen door Nanonets voor jou en je teams.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://nanonets.com/blog/langchain/

