Introductie
begreep het volledige stroom van het beslissingsboomalgoritme. Hierin begrijpen we waarom we moeten leren over het willekeurige bos. wanneer we al een beslissingsboomalgoritme hebben. Waarom hebben we Willekeurig bos nodig? Waar gaat het allemaal om?naar de beslisboom. Random Forest is ook een algoritme voor machinaal leren onder toezicht. Het wordt veel gebruikt bij classificatie en regressie. Maar de beslisboom heeft een overfittingprobleem.
Benieuwd wat overfitting is? Overfitting treedt op wanneer het model te complex is en te nauw aansluit bij de gegevens. Dit betekent dat het model geen nauwkeurige voorspellingen kan doen op ongeziene gegevens. De Random Forest-algoritme kan dit probleem oplossen door meerdere beslissingsbomen te maken en hun voorspellingen te combineren om tot nauwkeurigere voorspellingen te komen.
leerdoelen
- Inzicht in de basisprincipes van gecombineerd leren.
- Bekijk de basisprincipes van Random forest.
- Het belang begrijpen van elke betrokken stap bij het bouwen van het complete willekeurige bos.
- Praktische implementatie van het willekeurige bos met behulp van python.
- Begrijpen hoe het probleem van overfitting wordt opgelost.
- We zullen ook begrijpen hoe ze de robuustheid kunnen verbeteren.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
- Ensembletechnieken: wat ze zijn en hoe ze werken
- Het is mogelijk om te begrijpen hoe willekeurige forests werken door vier eenvoudige stappen te volgen?
-
Stap 1: Hoe wordt een complete trainingsgegevensset gebruikt om meerdere bomen te bouwen?
-
Stap 2: Meerdere beslisbomen kunnen worden gebouwd door de volgende stappen te volgen
-
Stap 3: Wat is het proces van het verwachten van het resultaat met behulp van multi-tree-modellen voor het voorspellen van de uitkomst?
-
Stap 4: Wanneer een model een resultaat afrondt voor regressie of classificatie, hoe noemen we deze stap dan?
-
Conclusie
Ensembletechnieken: wat zijn ze en hoe werken ze?
In een beslisboom hebben we maar één boom om de vraag te beantwoorden. Laten we zeggen dat we een telefoon willen kopen. De volgende beslisboom kan worden gebruikt om te beslissen of we een iPhone of een Android-telefoon moeten kopen.
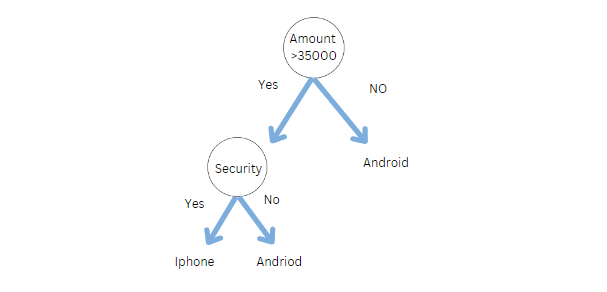
Doen we echter in het echte leven hetzelfde, vragen we gewoon aan één persoon om een telefoon te kopen? Zeker Nee. We vragen het aan meerdere mensen, zoals familie, vrienden, experts en verkopers.
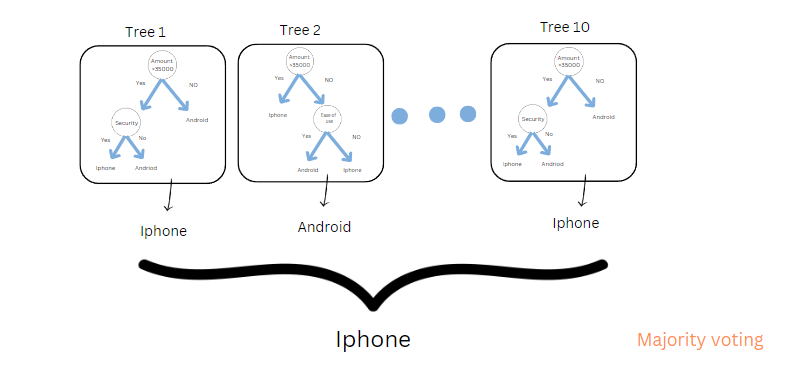
Stel dat elke boom is zoals elke persoon. Dus, als je het aan 10 mensen vraagt (8 mensen zeiden iPhone, en 2 mensen zeiden Android. In willekeurige bosclassificatie is de uiteindelijke output gebaseerd op stemmen bij meerderheid. We zullen een iPhone kopen.
Opmerking: wat als we een regressiemodel bouwen? We gebruiken gemiddelde of gemiddelde.
We noemen het proces van het kammen van de verschillende beslissingsboommodellen een willekeurig bos. Maar de vraag is, kunnen we meerdere modellen combineren, zoals logistiek, naïef Bayes en KNN, en zo ja, hoe noemen we het? We noemen het Bagging en Boosting. Het zijn twee ensemblemethoden die worden gebruikt bij machine learning om de prestaties van een enkel model te verbeteren door de voorspellingen van meerdere modellen te combineren.
bagging: bagging is een manier om meerdere modellen te combineren; het kan elk model zijn, zoals we hierboven hebben besproken, zoals knn, naïeve Bayes, logistiek, enz. Het resultaat zal echter hetzelfde zijn omdat de gegevensinvoer voor alle modellen hetzelfde zal zijn. Om dat aan te pakken, gebruiken we een bootstrap-aggregator.
- Als we bijvoorbeeld 10 modellen hebben, traint elk model op een andere subset van de trainingsgegevens.
- De uiteindelijke voorspelling is meestal het gemiddelde of de meerderheid van de voorspellingen van alle modellen.
Daarnaast vermindert Bagging ook de variantie vanwege de twee bovenstaande punten.
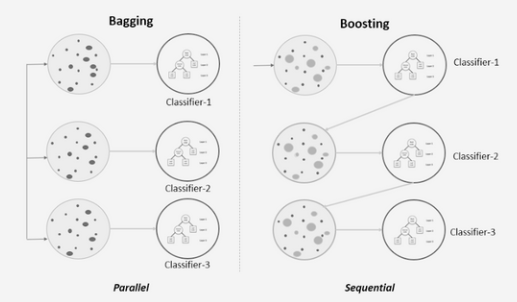
Het stimuleren van: Omgekeerd produceert BOOSTING sterke leerlingen door zwakke te combineren. Op bovenstaande afbeelding, kunt u zien dat het sequentiële training volgt.
Soorten Boosting-algoritmen
1. Aanpassen
2. Gradiëntversterking
3. XGboost
We zullen al deze onderwerpen behandelen in de komende artikelen
Stapsgewijze procedure om te begrijpen hoe Random Forest werkt
Ja, het is mogelijk om de werking van het willekeurige bos in 4 eenvoudige stappen te begrijpen. Maar daarvoor moeten we één vraag over Random Forest begrijpen.
Tot welk type ensembled learning random forest behoort?
Het hoort bij bagging, waarbij we meerdere beslissingsbomen bouwen, random forest genaamd.
Het begrijpen van willekeurige forests vereist een stapsgewijze aanpak. Hier is een stapsgewijze handleiding.

Stap 1: wordt de trainingsgegevensset gebruikt om meerdere bomen te bouwen?
Wanneer we een trainingsdataset hebben. Het model maakt een bootstrap-voorbeeld met de vervanging.
Wat is Bootstrap?
Meerdere subsets maken van de daadwerkelijke trainingsdataset.
Hoe creëren we meerdere subsets als we die hebben Rijen en kolommen in de trainingsdataset? en welke is met vervanging?
rijen:
Als we zeggen met devervanging(raadpleeg de afbeelding hieronder voor een beter begrip), in een subset kunnen we meerdere keren dezelfde rij hebben. zoals je erin kunt zien deelverzameling 2, de 2e rij wordt 2 keer herhaald, en in deelverzameling 3 De 1e rij wordt 2 keer herhaald.
columns:
1. Voor classificatie is het een vierkantswortel van het totale aantal kenmerken
Voorbeeld: laten we zeggen dat we in totaal 4 kenmerken hebben voor elke subset die we zullen hebben
De vierkantswortel van 4= 2. dat zijn 2 kenmerken voor elke boom.
2. Regressie: totaal aantal kenmerken en gedeeld door 3
Stap 2: Er kunnen meerdere beslissingsbomen worden gebouwd door de volgende stappen te volgen
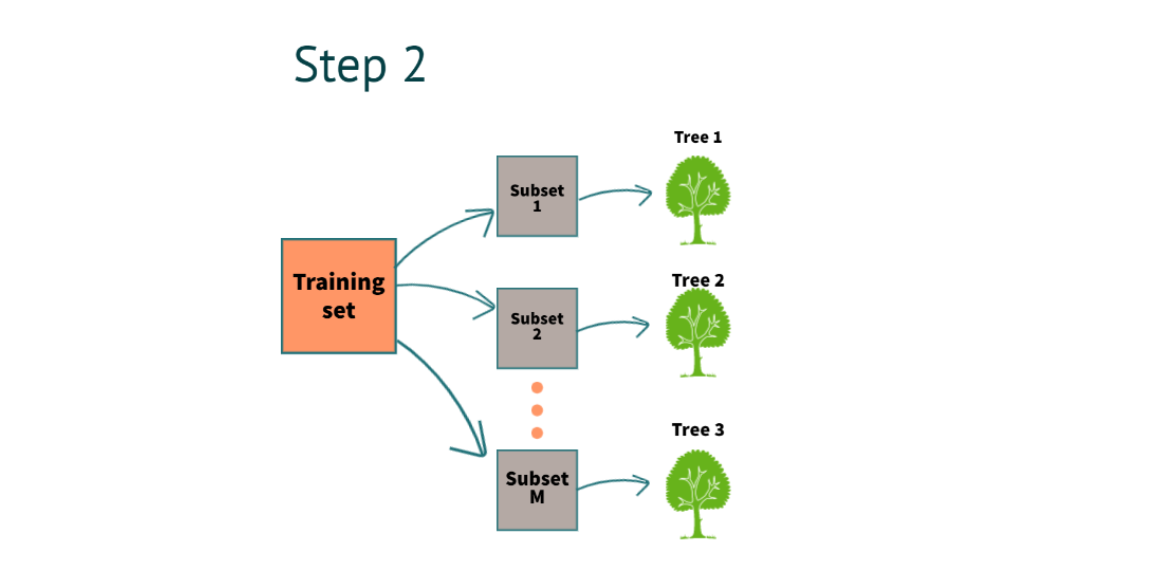
Na het voltooien van stap 1, bouwen we een beslisboom voor elke subset. In het bovenstaande voorbeeld hebben we 3 beslisbomen.
Hoe konden we de beslisbomen bouwen van
Om een beslisboom te bouwen, moeten we twee methoden gebruiken.
1. Gini
2. Entropie en informatiewinst
Voor een gedetailleerd begrip van wiskunde kunt u verwijzen naar mijn Beslisboom artikel in Analytics Vidhya.
Stap 3: Multi-tree-modellen gebruiken om de uitkomst te voorspellen, wat is het proces van het voorspellen van het resultaat?
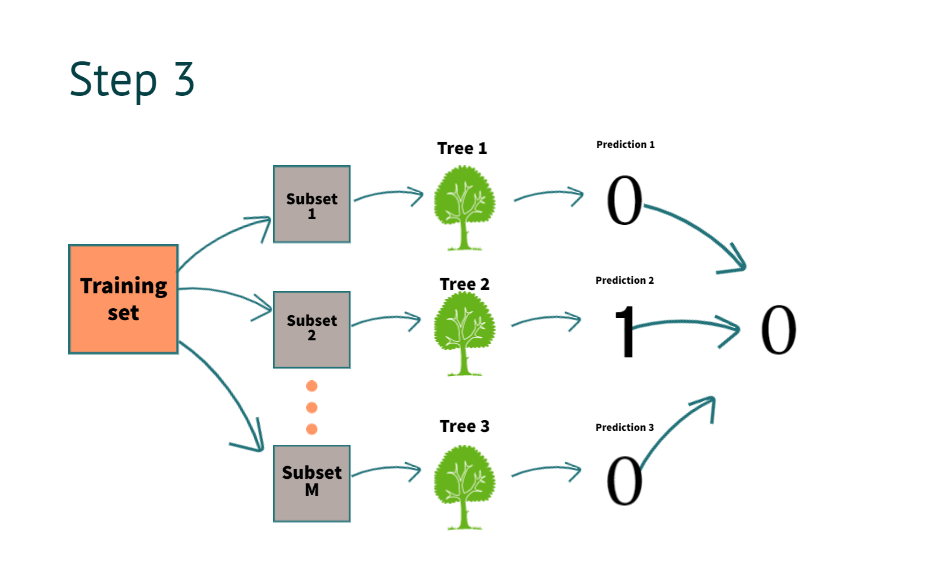
Nu de beslisboom is gebouwd, is het tijd om de resultaten te krijgen. stel dat we nieuwe informatie hebben voor voorspelling
| salaris | eigendom | lening goedkeuring |
| 10k | Nee | ? |
Het model voorspelt het als "0". Door alle bovenstaande beslisboomvoorspellingen te combineren, zoals u kunt zien in de afbeelding
Wat bedoelen we met het combineren van de voorspelling van alle bomen?
Om het te begrijpen, gaan we naar stap vier.
Stap 4: Wanneer een model een resultaat voor regressie of classificatie beëindigt, hoe heet dat dan?

In stap 4 kunnen we het proces van het combineren van de voorspellingen van meerdere bomen die we aggregatie noemen, duidelijk begrijpen
- Voor classificatie gebruiken we stemming bij meerderheid
- Voor regressie gebruiken we middeling
hiermee begrijpen we wat een bootstrap-aggregatie precies inhoudt.
Nu moeten we begrijpen hoe het voordelen heeft.
Het verkleint de variantie. Dit helpt bij het bouwen van robuuste modellen, die zelfs goed werken op ongeziene gegevens.
Python-implementatie
# De benodigde bibliotheken importeren panda's importeren als pd import numpy als np uit sklearn.datasets import load_iris data = load_iris()
laad de iris-dataset uit de sklearn-bibliotheek
# Zet de irisgegevens om in een Pandas-dataframe met functienamen als kolomnamen df = pd.DataFrame(data.data, columns=data.feature_names)
# Voeg een nieuwe kolom 'target' toe aan het dataframe met doelnamen en doelcodes df['target'] = pd.Categorical.from_codes(data.target, data.target_names) # Print de eerste 5 rijen van het dataframe print(df. hoofd())
We printen de eerste 5 rijen na het converteren van de gegevens naar een dataframe.
# Splits de gegevens X en y X = df.drop('target',axis=1) y = df['target']
# Importeer train_test_split-functie van sklearn van sklearn.model_selection importeer train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, willekeurige_status=0)
# Importeer de RandomForestClassifier van sklearn van sklearn.ensemble importeer RandomForestClassifier
classifier_rf = RandomForestClassifier(random_state=42, n_jobs=-1, n_estimators=20)
We gebruiken een willekeurige bosclassificatie met Hyper-parameter
- Random_state (het helpt om dezelfde resultaten te genereren elke keer dat we het model uitvoeren)
- n_jobs (het gebruikt alle processors)
- n_schatters( we gebruiken 20 beslissingsbomen in het willekeurige bos. Als we willen, kunnen we het afstemmen.
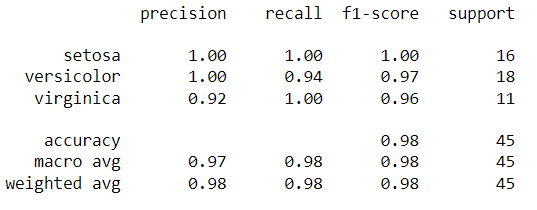
# Pas de trainingsgegevens aan classifier_rf.fit(X_train, y_train) # Voorspel op testgegevens y_pred = classifier_rf.predict(X_test) van sklearn.metrics import , y_pred))
We hebben de voorspellingen opgeslagen in de variabele y_pred. We kunnen de werkelijke vs. voorspelde vergelijken met behulp van het onderstaande rapport.
Conclusie
In dit artikel hebben we gekeken naar het meest populaire algoritme. Om samen te vatten, we hebben in detail over Random Forest geleerd. Laten we eens kijken naar de belangrijkste afhaalrestaurants.
Sleutelfaciliteiten:
- Willekeurig bos geeft ons een betere nauwkeurigheid dan de enkele beslissingsboom omdat de informatie aan meerdere bomen wordt doorgegeven.
- In realtime krijgen we geen gebalanceerde datasets en daarom zullen de meeste machine learning-modellen gericht zijn op één specifieke klasse. Toch kan Random forest een onevenwichtige dataset aan door de data te randomiseren.
- We gebruiken meerdere beslisbomen om de ontbrekende informatie te middelen. Met Random forest kunnen we dus ook de ontbrekende waarden aan.
- Ten slotte helpt het om in realtime robuuste modellen te bouwen door de variantie te verminderen.
Heb je genoten van mijn artikel? Geef hieronder een reactie.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/02/how-does-random-forest-work/

