Dit bericht is geschreven in samenwerking met Hernan Figueroa, Sr. Manager Data Science bij Marubeni Power International.
Marubeni Power International Inc (MPII) bezit en investeert in energiebedrijfsplatforms in Amerika. Een belangrijke verticaal voor MPII is activabeheer voor hernieuwbare energie en activa voor energieopslag, die van cruciaal belang zijn om de koolstofintensiteit van onze energie-infrastructuur te verminderen. Werken met hernieuwbare energiebronnen vereist voorspellende en responsieve digitale oplossingen, omdat de opwekking van hernieuwbare energie en de omstandigheden op de elektriciteitsmarkt voortdurend veranderen. MPII gebruikt een machine learning (ML) bodoptimalisatie-engine om stroomopwaartse besluitvormingsprocessen op het gebied van vermogensbeheer en handel te informeren. Deze oplossing helpt marktanalisten bij het ontwerpen en uitvoeren van datagestuurde biedstrategieën die zijn geoptimaliseerd voor de winstgevendheid van power assets.
In dit bericht leer je hoe Marubeni marktbeslissingen optimaliseert door gebruik te maken van de brede set AWS-analyses en ML-services, om een robuuste en kosteneffectieve Power Bid Optimization-oplossing te bouwen.
Overzicht oplossingen
Elektriciteitsmarkten maken het mogelijk om stroom en energie te verhandelen om vraag en aanbod in het elektriciteitsnet in evenwicht te brengen en om te voldoen aan verschillende behoeften aan betrouwbaarheid van het elektriciteitsnet. Marktdeelnemers, zoals MPII-activa-exploitanten, bieden voortdurend stroom en energiehoeveelheden op deze elektriciteitsmarkten om winst te behalen uit hun stroomactiva. Een marktdeelnemer kan tegelijkertijd biedingen op verschillende markten indienen om de winstgevendheid van een asset te vergroten, maar hij moet rekening houden met vermogenslimieten en reactiesnelheden van activa, evenals andere operationele beperkingen van activa en de interoperabiliteit van die markten.
MPII's engine-oplossing voor bodoptimalisatie maakt gebruik van ML-modellen om optimale biedingen te genereren voor deelname aan verschillende markten. De meest voorkomende biedingen zijn day-ahead energiebiedingen, die 1 dag voor de daadwerkelijke handelsdag dienen te worden ingediend, en real-time energiebiedingen, die 75 minuten voor het handelsuur dienen te worden ingediend. De oplossing orkestreert het dynamische bieden en de werking van een power asset en vereist het gebruik van optimalisatie- en voorspellende mogelijkheden die beschikbaar zijn in de ML-modellen.
De Power Bid Optimization-oplossing bevat meerdere componenten die specifieke rollen spelen. Laten we de betrokken componenten en hun respectieve zakelijke functie eens bekijken.
Gegevensverzameling en opname
De gegevensverzamelings- en opnamelaag maakt verbinding met alle stroomopwaartse gegevensbronnen en laadt de gegevens in het datameer. Bieden op de elektriciteitsmarkt vereist ten minste vier soorten invoer:
- Prognoses elektriciteitsvraag
- Weersverwachtingen
- Geschiedenis van de marktprijs
- Prognoses voor stroomprijzen
Deze gegevensbronnen zijn uitsluitend toegankelijk via API's. Daarom moeten de opnamecomponenten authenticatie, data sourcing in pull-modus, data preprocessing en data opslag kunnen beheren. Omdat de gegevens elk uur worden opgehaald, is er ook een mechanisme vereist om opnametaken te orkestreren en te plannen.
Data voorbereiding
Zoals bij de meeste ML-use-cases, speelt gegevensvoorbereiding een cruciale rol. Gegevens komen uit verschillende bronnen in een aantal formaten. Voordat het klaar is om te worden gebruikt voor ML-modeltraining, moet het een aantal van de volgende stappen doorlopen:
- Consolideer datasets per uur op basis van aankomsttijd. Een complete dataset moet alle bronnen bevatten.
- Verbeter de kwaliteit van de gegevens door technieken zoals standaardisatie, normalisatie of interpolatie te gebruiken.
Aan het einde van dit proces worden de samengestelde gegevens geënsceneerd en beschikbaar gemaakt voor verder gebruik.
Model training en implementatie
De volgende stap bestaat uit het trainen en implementeren van een model dat in staat is om optimale marktbiedingen voor het kopen en verkopen van energie te voorspellen. Om het risico op ondermaatse prestaties te minimaliseren, gebruikte Marubeni de ensemble-modelleringstechniek. Ensemble-modellering bestaat uit het combineren van meerdere ML-modellen om de voorspellingsprestaties te verbeteren. Marubeni combineert de output van externe en interne voorspellingsmodellen met een gewogen gemiddelde om te profiteren van de kracht van alle modellen. Marubeni's interne modellen zijn gebaseerd op Long Short-Term Memory (LSTM)-architecturen, die goed gedocumenteerd zijn en eenvoudig te implementeren en aan te passen in TensorFlow. Amazon Sage Maker ondersteunt TensorFlow-implementaties en vele andere ML-omgevingen. Het externe model is eigendom van het bedrijf en de beschrijving ervan kan niet in dit bericht worden opgenomen.
In de use case van Marubeni voeren de biedmodellen numerieke optimalisatie uit om de opbrengst te maximaliseren met behulp van een aangepaste versie van de objectieve functies die in de publicatie worden gebruikt. Kansen voor energieopslag in CAISO.
SageMaker stelt Marubeni in staat om ML en numerieke optimalisatie-algoritmen in één omgeving uit te voeren. Dit is van cruciaal belang, omdat tijdens de training van het interne model de uitvoer van de numerieke optimalisatie wordt gebruikt als onderdeel van de voorspellingsverliesfunctie. Raadpleeg voor meer informatie over het aanpakken van gebruiksscenario's voor numerieke optimalisatie Oplossen van numerieke optimalisatieproblemen zoals planning, routing en toewijzing met Amazon SageMaker Processing.
Vervolgens implementeren we die modellen via inferentie-eindpunten. Omdat periodiek nieuwe gegevens worden opgenomen, moeten de modellen opnieuw worden getraind omdat ze na verloop van tijd oud worden. Het architectuurgedeelte verderop in dit bericht geeft meer details over de levenscyclus van de modellen.
Vermogensbodgegevens genereren
Op uurbasis voorspelt de oplossing de optimale hoeveelheden en prijzen waartegen stroom op de markt moet worden aangeboden - ook wel genoemd biedingen. Hoeveelheden worden gemeten in MW en prijzen worden gemeten in $/MW. Biedingen worden gegenereerd voor meerdere combinaties van voorspelde en waargenomen marktomstandigheden. De volgende tabel toont een voorbeeld van de finale biedcurve uitvoer voor bedrijfsuur 17 op een illustratief handelsknooppunt nabij Marubeni's kantoor in Los Angeles.
| Datum | uur | Markt | Locatie | MW | Prijs |
| 11/7/2022 | 17 | RT Energie | LCIENEGA_6_N001 | 0 | $0 |
| 11/7/2022 | 17 | RT Energie | LCIENEGA_6_N001 | 1.65 | $80.79 |
| 11/7/2022 | 17 | RT Energie | LCIENEGA_6_N001 | 5.15 | $105.34 |
| 11/7/2022 | 17 | RT Energie | LCIENEGA_6_N001 | 8 | $230.15 |
Dit voorbeeld geeft onze bereidheid weer om 1.65 MW vermogen te bieden als de stroomprijs minimaal $ 80.79 is, 5.15 MW als de stroomprijs minimaal $ 105.34 is en 8 MW als de stroomprijs minimaal $ 230.15 is.
Onafhankelijke systeembeheerders (ISO's) houden toezicht op de elektriciteitsmarkten in de VS en zijn verantwoordelijk voor het toekennen en afwijzen van biedingen om de betrouwbaarheid van het elektriciteitsnet op de meest economische manier te handhaven. California Independent System Operator (CAISO) beheert elektriciteitsmarkten in Californië en publiceert elk uur voorafgaand aan het volgende biedvenster marktresultaten. Door de huidige marktomstandigheden te vergelijken met hun equivalent op de curve, kunnen analisten optimale inkomsten afleiden. De Power Bid Optimization-oplossing werkt toekomstige biedingen bij met behulp van nieuwe inkomende marktinformatie en nieuwe voorspellende outputs van modellen
AWS-architectuuroverzicht
De oplossingsarchitectuur die in de volgende afbeelding wordt geïllustreerd, implementeert alle eerder gepresenteerde lagen. Het maakt gebruik van de volgende AWS-services als onderdeel van de oplossing:
- Amazon eenvoudige opslagservice (Amazon S3) om de volgende gegevens op te slaan:
- Prijs-, weer- en belastingsvoorspellingsgegevens uit verschillende bronnen.
- Geconsolideerde en uitgebreide gegevens die klaar zijn om te worden gebruikt voor modeltraining.
- Uitvoerbodcurves worden elk uur vernieuwd.
- Amazon Sage Maker om modellen te trainen, testen en implementeren om geoptimaliseerde biedingen uit te voeren via inferentie-eindpunten.
- AWS Stap Functies om zowel de data- als de ML-pijplijnen te orkestreren. We gebruiken twee toestandsmachines:
- Eén statusmachine om gegevensverzameling te orkestreren en ervoor te zorgen dat alle bronnen zijn opgenomen.
- Eén statusmachine om de ML-pijplijn te orkestreren, evenals de workflow voor het genereren van geoptimaliseerde biedingen.
- AWS Lambda om opname-, voorverwerkings- en naverwerkingsfunctionaliteit te implementeren:
- Drie functies om invoergegevensfeeds op te nemen, met één functie per bron.
- Eén functie om de gegevens te consolideren en voor te bereiden voor training.
- Eén functie die de prijsprognose genereert door het eindpunt van het model aan te roepen dat is geïmplementeerd in SageMaker.
- Amazone Athene om ontwikkelaars en bedrijfsanalisten SQL-toegang te bieden tot de gegenereerde gegevens voor analyse en probleemoplossing.
- Amazon EventBridge om de gegevensopname en ML-pijplijn volgens een schema en als reactie op gebeurtenissen te activeren.
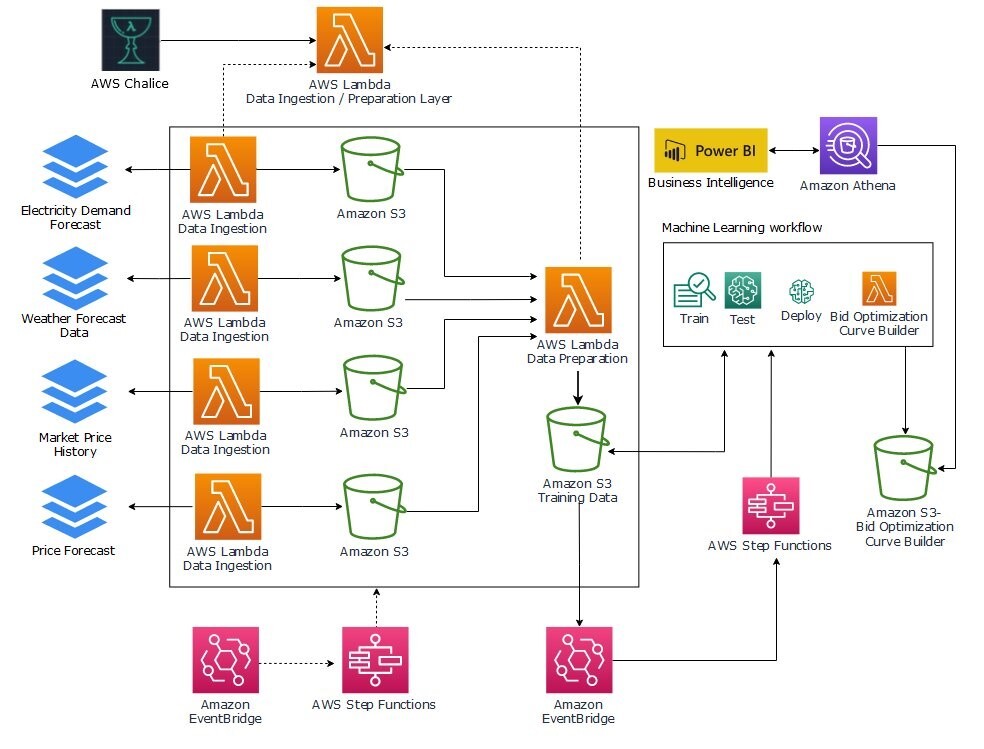
In de volgende secties gaan we dieper in op de workflow.
Gegevensverzameling en voorbereiding
Elk uur wordt de statusmachine Step Functions voor gegevensvoorbereiding aangeroepen. Het roept elk van de Lambda-functies voor gegevensopname parallel aan en wacht tot alle vier zijn voltooid. De functies voor gegevensverzameling roepen hun respectievelijke bron-API aan en halen gegevens op voor het afgelopen uur. Elke functie slaat vervolgens de ontvangen gegevens op in hun respectieve S3-bucket.
Deze functies delen een gemeenschappelijke implementatiebasislijn die bouwstenen biedt voor standaardgegevensmanipulatie zoals normalisatie of indexering. Om dit te bereiken, gebruiken we Lambda-lagen en AWS-kelk, zoals beschreven in AWS Lambda-lagen gebruiken met AWS Chalice. Dit zorgt ervoor dat alle ontwikkelaars dezelfde basisbibliotheken gebruiken om nieuwe logica voor gegevensvoorbereiding te bouwen en de implementatie te versnellen.
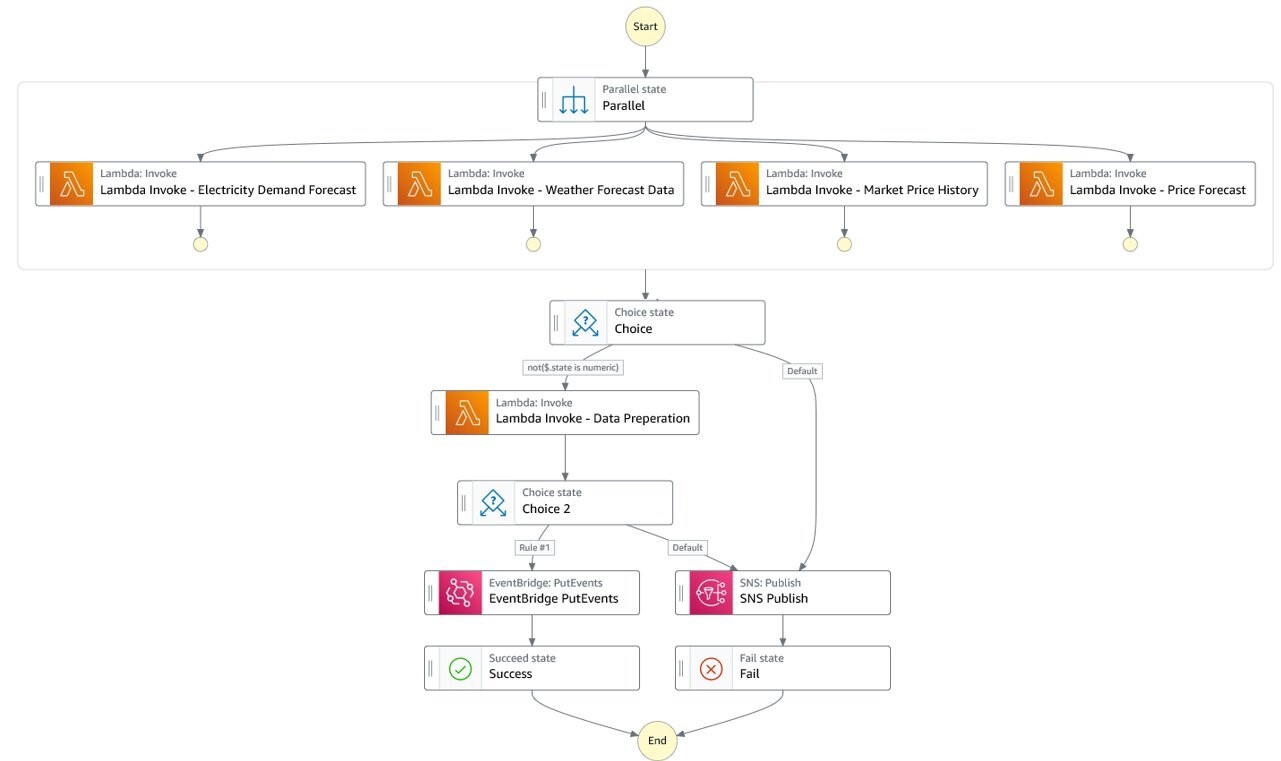
Nadat alle vier de bronnen zijn opgenomen en opgeslagen, activeert de toestandsmachine de Lambda-functie voor gegevensvoorbereiding. Stroomprijs-, weer- en belastingsvoorspellingsgegevens worden ontvangen in JSON en door tekens gescheiden bestanden. Elk recordgedeelte van elk bestand heeft een tijdstempel dat wordt gebruikt om datafeeds te consolideren tot één dataset die een tijdsbestek van 1 uur bestrijkt.
Deze constructie biedt een volledig gebeurtenisgestuurde workflow. De voorbereiding van trainingsgegevens wordt gestart zodra alle verwachte gegevens zijn opgenomen.
ML-pijplijn
Na datavoorbereiding worden de nieuwe datasets opgeslagen in Amazon S3. Een EventBridge-regel activeert de ML-pijplijn via een Step Functions-statusmachine. De toestandsmachine stuurt twee processen aan:
- Controleer of het model voor het genereren van de biedcurve actueel is
- Herscholing van modellen automatisch activeren wanneer de prestaties afnemen of modellen ouder zijn dan een bepaald aantal dagen
Als de leeftijd van het momenteel geïmplementeerde model ouder is dan de laatste dataset met een bepaalde drempel, bijvoorbeeld 7 dagen, start de Step Functions-statusmachine de SageMaker-pijplijn die een nieuw inferentie-eindpunt traint, test en implementeert. Als de modellen nog up-to-date zijn, slaat de workflow de ML-pijplijn over en gaat door naar de stap voor het genereren van biedingen. Ongeacht de status van het model wordt er een nieuwe biedcurve gegenereerd bij levering van een nieuwe dataset per uur. Het volgende diagram illustreert deze workflow. Standaard is de StartPipelineExecution actie is asynchroon. We kunnen de toestandsmachine laten wachten op het einde van de pijplijn alvorens de stap voor het genereren van biedingen aan te roepen door de 'Wachten op terugbellen' keuze.


Om de kosten en time-to-market te verminderen bij het bouwen van een proefoplossing, gebruikte Marubeni Amazon SageMaker Serverloze inferentie. Dit zorgt ervoor dat de onderliggende infrastructuur die wordt gebruikt voor training en implementatie alleen kosten met zich meebrengt wanneer dat nodig is. Dit maakt ook het proces van het bouwen van de pijplijn eenvoudiger omdat ontwikkelaars de infrastructuur niet langer hoeven te beheren. Dit is een geweldige optie voor workloads met periodes van inactiviteit tussen verkeersspurts. Naarmate de oplossing volwassener wordt en overgaat naar productie, zal Marubeni hun ontwerp herzien en een configuratie aannemen die geschikter is voor voorspelbaar en stabiel gebruik.
Biedingen genereren en gegevens opvragen
De Lambda-functie voor het genereren van biedingen roept periodiek het inferentie-eindpunt aan om uurlijkse voorspellingen te genereren en slaat de uitvoer op in Amazon S3.
Ontwikkelaars en bedrijfsanalisten kunnen de gegevens vervolgens verkennen met behulp van Athena en Microsoft Power BI voor visualisatie. De gegevens kunnen ook via API beschikbaar worden gesteld aan downstream bedrijfsapplicaties. In de pilootfase raadplegen operators visueel de biedcurve om hun stroomtransactieactiviteiten op markten te ondersteunen. Marubeni overweegt echter om dit proces in de toekomst te automatiseren en deze oplossing biedt daarvoor de nodige basis.
Conclusie
Dankzij deze oplossing kon Marubeni hun pijplijnen voor gegevensverwerking en opname volledig automatiseren en de implementatietijd van hun voorspellende en optimalisatiemodellen terugbrengen van uren naar minuten. Biedcurves worden nu automatisch gegenereerd en up-to-date gehouden naarmate de marktomstandigheden veranderen. Ze realiseerden ook een kostenreductie van 80% bij het overstappen van een ingericht inferentie-eindpunt naar een serverloos eindpunt.
De prognoseoplossing van MPII is een van de recente initiatieven voor digitale transformatie die Marubeni Corporation in de energiesector lanceert. MPII is van plan aanvullende digitale oplossingen te bouwen ter ondersteuning van nieuwe krachtige bedrijfsplatforms. MPII kan vertrouwen op AWS-services om hun digitale transformatiestrategie te ondersteunen in veel gebruiksscenario's.
"We kunnen ons concentreren op het beheer van de waardeketen voor nieuwe bedrijfsplatforms, wetende dat AWS de onderliggende digitale infrastructuur van onze oplossingen beheert."
– Hernan Figueroa, Sr. Manager Data Science bij Marubeni Power International.
Voor meer informatie over hoe AWS energieorganisaties helpt bij hun digitale transformatie en duurzaamheidsinitiatieven, zie AWS-energie.
![]() Marubeni Power International is een dochteronderneming van Marubeni Corporation. Marubeni Corporation is een groot Japans handels- en investeringsconglomeraat. De missie van Marubeni Power International is het ontwikkelen van nieuwe zakelijke platforms, het beoordelen van nieuwe energietrends en -technologieën en het beheren van Marubeni's energieportfolio in Amerika. Als je meer wilt weten over Marubeni Power, kijk dan eens https://www.marubeni-power.com/.
Marubeni Power International is een dochteronderneming van Marubeni Corporation. Marubeni Corporation is een groot Japans handels- en investeringsconglomeraat. De missie van Marubeni Power International is het ontwikkelen van nieuwe zakelijke platforms, het beoordelen van nieuwe energietrends en -technologieën en het beheren van Marubeni's energieportfolio in Amerika. Als je meer wilt weten over Marubeni Power, kijk dan eens https://www.marubeni-power.com/.
Over de auteurs
 Hernan Figueroa leidt de initiatieven voor digitale transformatie bij Marubeni Power International. Zijn team past datawetenschap en digitale technologieën toe om de groeistrategieën van Marubeni Power te ondersteunen. Voordat hij bij Marubeni kwam, was Hernan een datawetenschapper aan Columbia University. Hij heeft een Ph.D. in Elektrotechniek en een BS in Computer Engineering.
Hernan Figueroa leidt de initiatieven voor digitale transformatie bij Marubeni Power International. Zijn team past datawetenschap en digitale technologieën toe om de groeistrategieën van Marubeni Power te ondersteunen. Voordat hij bij Marubeni kwam, was Hernan een datawetenschapper aan Columbia University. Hij heeft een Ph.D. in Elektrotechniek en een BS in Computer Engineering.
 Lino Brescia is een Principal Account Executive gevestigd in NYC. Hij heeft meer dan 25 jaar technologische ervaring en kwam in 2018 bij AWS. Hij beheert wereldwijde zakelijke klanten die hun bedrijf transformeren met AWS-cloudservices en grootschalige migraties uitvoeren.
Lino Brescia is een Principal Account Executive gevestigd in NYC. Hij heeft meer dan 25 jaar technologische ervaring en kwam in 2018 bij AWS. Hij beheert wereldwijde zakelijke klanten die hun bedrijf transformeren met AWS-cloudservices en grootschalige migraties uitvoeren.
 Narcisse Zekpa is een Sr. Solutions Architect gevestigd in Boston. Hij helpt klanten in het noordoosten van de VS hun bedrijfstransformatie te versnellen door middel van innovatieve en schaalbare oplossingen op de AWS Cloud. Als Narcisse niet aan het bouwen is, brengt hij graag tijd door met zijn gezin, reizen, koken, basketballen en hardlopen.
Narcisse Zekpa is een Sr. Solutions Architect gevestigd in Boston. Hij helpt klanten in het noordoosten van de VS hun bedrijfstransformatie te versnellen door middel van innovatieve en schaalbare oplossingen op de AWS Cloud. Als Narcisse niet aan het bouwen is, brengt hij graag tijd door met zijn gezin, reizen, koken, basketballen en hardlopen.
 Pedrom Jahangiri is een Enterprise Solution Architect bij AWS, met een doctoraat in elektrotechniek. Hij heeft meer dan 10 jaar ervaring in de energie- en IT-industrie. Pedram heeft jarenlange praktijkervaring in alle aspecten van Advanced Analytics voor het bouwen van kwantitatieve en grootschalige oplossingen voor ondernemingen door gebruik te maken van cloudtechnologieën.
Pedrom Jahangiri is een Enterprise Solution Architect bij AWS, met een doctoraat in elektrotechniek. Hij heeft meer dan 10 jaar ervaring in de energie- en IT-industrie. Pedram heeft jarenlange praktijkervaring in alle aspecten van Advanced Analytics voor het bouwen van kwantitatieve en grootschalige oplossingen voor ondernemingen door gebruik te maken van cloudtechnologieën.
 Sara Childers is een accountmanager gevestigd in Washington DC. Ze is een voormalige wetenschapsdocent die cloudenthousiasteling is geworden en zich richt op het ondersteunen van klanten tijdens hun cloudreis. Sarah werkt graag samen met een gemotiveerd team dat gediversifieerde ideeën aanmoedigt om klanten zo goed mogelijk uit te rusten met de meest innovatieve en uitgebreide oplossingen.
Sara Childers is een accountmanager gevestigd in Washington DC. Ze is een voormalige wetenschapsdocent die cloudenthousiasteling is geworden en zich richt op het ondersteunen van klanten tijdens hun cloudreis. Sarah werkt graag samen met een gemotiveerd team dat gediversifieerde ideeën aanmoedigt om klanten zo goed mogelijk uit te rusten met de meest innovatieve en uitgebreide oplossingen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/how-marubeni-is-optimizing-market-decisions-using-aws-machine-learning-and-analytics/

