In dit bericht bespreken we hoe United Airlines, in samenwerking met de Amazon Machine Learning Solutions-lab, bouw een actief leerraamwerk op AWS om de verwerking van passagiersdocumenten te automatiseren.
“Om onze passagiers de beste vliegervaring te bieden en ons interne bedrijfsproces zo efficiënt mogelijk te maken, hebben we in AWS een geautomatiseerde op machine learning gebaseerde documentverwerkingspijplijn ontwikkeld. Om deze toepassingen aan te drijven, evenals die welke andere datamodaliteiten zoals computer vision gebruiken, hebben we een robuuste en efficiënte workflow nodig om snel gegevens te annoteren, modellen te trainen en evalueren, en snel te itereren. In de loop van een paar maanden werkte United samen met Amazon Machine Learning Solutions Labs om een herbruikbare, case-agnostische actieve leerworkflow te ontwerpen en ontwikkelen met behulp van AWS CDK. Deze workflow zal de basis vormen voor onze ongestructureerde, op data gebaseerde machine learning-applicaties, omdat het ons in staat zal stellen de menselijke etiketteringsinspanningen te minimaliseren, snel sterke modelprestaties te leveren en ons aan te passen aan datadrift.”
– Jon Nelson, Senior Manager Data Science en Machine Learning bij United Airlines.
probleem
Het Digital Technology-team van United bestaat uit wereldwijd diverse individuen die samenwerken met de allernieuwste technologie om de bedrijfsresultaten te verbeteren en de klanttevredenheid hoog te houden. Ze wilden profiteren van machine learning (ML)-technieken zoals computer vision (CV) en natuurlijke taalverwerking (NLP) om de documentverwerkingspijplijnen te automatiseren. Als onderdeel van deze strategie ontwikkelden ze een intern paspoortanalysemodel om de identiteit van passagiers te verifiëren. Het proces is afhankelijk van handmatige annotaties om ML-modellen te trainen, wat erg kostbaar is.
United wilde een flexibel, veerkrachtig en kostenefficiënt ML-framework creëren voor het automatiseren van de verificatie van paspoortinformatie, het valideren van de identiteit van passagiers en het detecteren van mogelijke frauduleuze documenten. Ze schakelden het ML Solutions Lab in om dit doel te helpen bereiken, waardoor United diensten van wereldklasse kan blijven leveren in het licht van de toekomstige passagiersgroei.
Overzicht oplossingen
Ons gezamenlijke team ontwierp en ontwikkelde een raamwerk voor actief leren, mogelijk gemaakt door de AWS Cloud-ontwikkelingskit (AWS CDK), dat programmatisch alle noodzakelijke AWS-services configureert en levert. Het raamwerk gebruikt Amazon Sage Maker om ongelabelde gegevens te verwerken, maakt zachte labels, start handmatige labeltaken met Amazon SageMaker Grondwaarheiden traint een willekeurig ML-model met de resulterende dataset. We gebruikten Amazon T-extract om de extractie van informatie uit specifieke documentvelden, zoals naam en paspoortnummer, te automatiseren. Op een hoog niveau kan de aanpak worden beschreven met het volgende diagram.
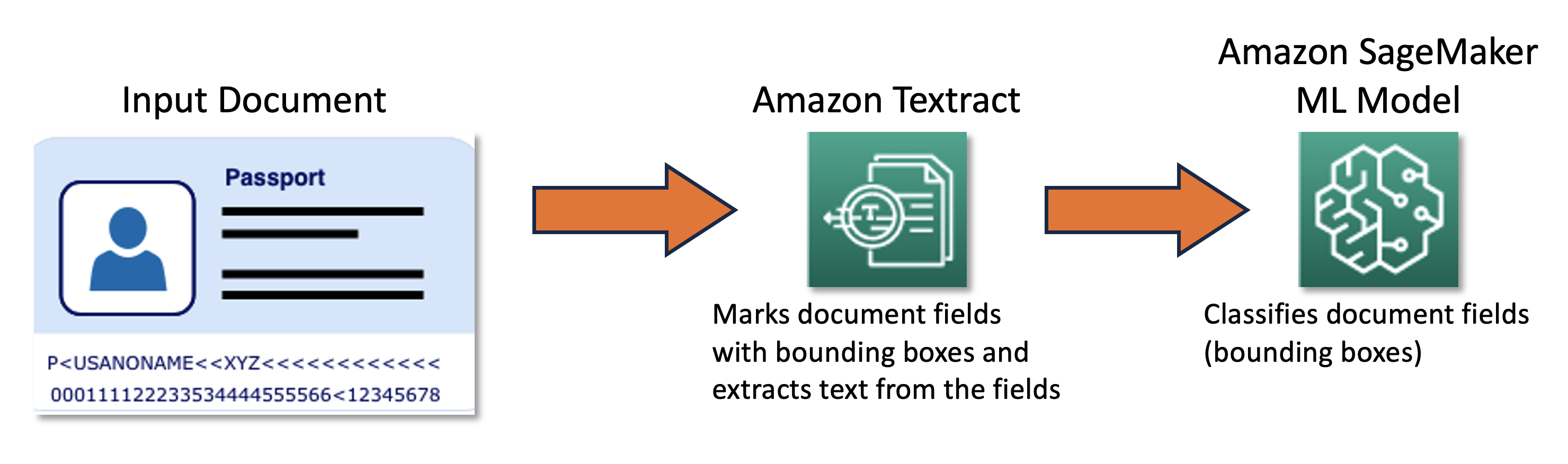
Data
De primaire dataset voor dit probleem bestaat uit tienduizenden paspoortafbeeldingen op de hoofdpagina waaruit persoonlijke informatie (naam, geboortedatum, paspoortnummer, enzovoort) moet worden gehaald. Het afbeeldingsformaat, de lay-out en de structuur variëren afhankelijk van het land dat het document uitgeeft. We normaliseren deze afbeeldingen tot een reeks uniforme miniaturen, die de functionele input vormen voor de actieve leerpijplijn (automatische labeling en gevolgtrekking).
De tweede dataset bevat JSON-lijngeformatteerde manifestbestanden die onbewerkte paspoortafbeeldingen, miniatuurafbeeldingen en labelinformatie bevatten, zoals zachte labels en omsluitende kaderposities. Manifestbestanden dienen als een metadataset waarin resultaten van verschillende AWS-services in een uniform formaat worden opgeslagen, en ontkoppelen de actieve leerpijplijn van downstream-services die door United worden gebruikt. Het volgende diagram illustreert deze architectuur.
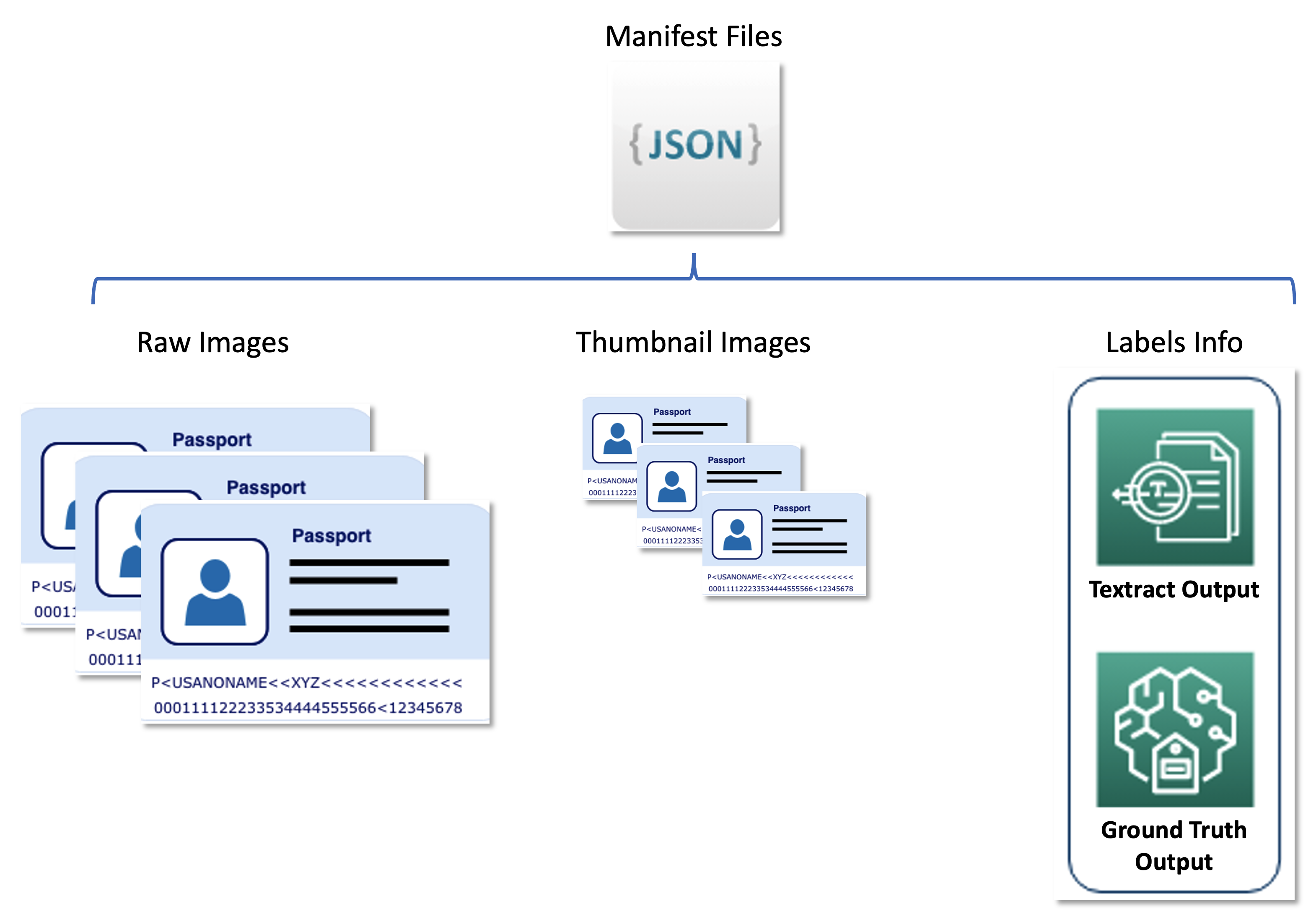
De volgende code is een voorbeeld van een manifestbestand:
Componenten van de oplossing
De oplossing omvat twee hoofdcomponenten:
- Een ML-framework, dat verantwoordelijk is voor het trainen van het model
- Een pijplijn voor automatisch labelen, die verantwoordelijk is voor het op een kostenefficiënte manier verbeteren van de nauwkeurigheid van getrainde modellen
Het ML-framework is verantwoordelijk voor het trainen van het ML-model en het implementeren ervan als een SageMaker-eindpunt. De pijplijn voor automatisch labelen is gericht op het automatiseren van SageMaker Ground Truth-taken en het bemonsteren van afbeeldingen voor het labelen van die taken.
De twee componenten zijn van elkaar losgekoppeld en werken alleen samen via de reeks gelabelde afbeeldingen die worden geproduceerd door de automatische labelingspijplijn. Dat wil zeggen dat de labelpijplijn labels maakt die later door het ML-framework worden gebruikt om het ML-model te trainen.
ML-framework
Het ML Solutions Lab-team heeft het ML-framework gebouwd met behulp van de Hugging Face-implementatie van het ultramoderne LayoutLMV2-model (LayoutLMv2: multimodale vooropleiding voor visueel rijk documentbegrip, Yang Xu, et al.). De training was gebaseerd op Amazon Textract-uitvoer, die als preprocessor diende en selectiekaders rond interessante tekst produceerde. Het raamwerk maakt gebruik van gedistribueerde training en draait op een aangepaste Docker-container op basis van de door SageMaker vooraf gebouwde Hugging Face-image met extra afhankelijkheden (afhankelijkheden die ontbreken in de vooraf gebouwde SageMaker Docker-image maar vereist zijn voor Hugging Face LayoutLMv2).
Het ML-model is getraind om documentvelden in de volgende 11 klassen te classificeren:
De trainingspijplijn kan worden samengevat in het volgende diagram.
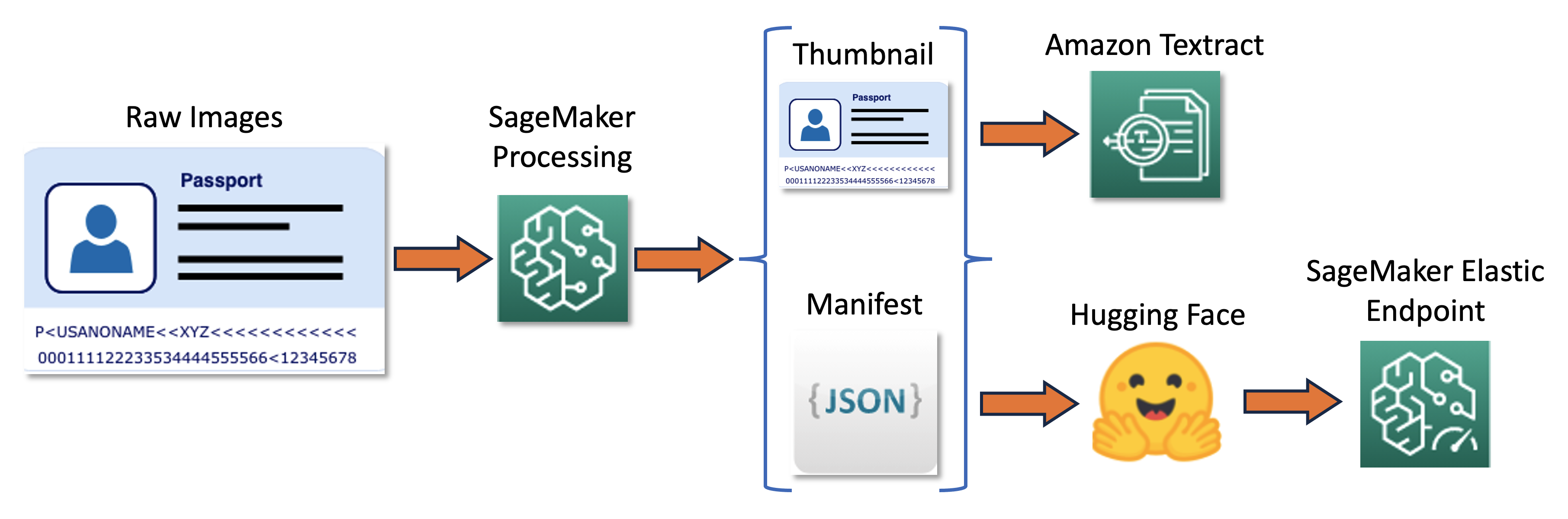
Eerst passen we het formaat van een reeks onbewerkte afbeeldingen aan en normaliseren we deze tot miniaturen. Tegelijkertijd wordt er een JSON-lijnmanifestbestand met één regel per afbeelding gemaakt met informatie over onbewerkte afbeeldingen en miniatuurafbeeldingen uit de batch. Vervolgens gebruiken we Amazon Textract om tekstkaders in de miniatuurafbeeldingen te extraheren. Alle door Amazon Textract geproduceerde informatie wordt vastgelegd in hetzelfde manifestbestand. Ten slotte gebruiken we de miniatuurafbeeldingen en manifestgegevens om een model te trainen, dat later wordt ingezet als een SageMaker-eindpunt.
Pijplijn voor automatisch labelen
We hebben een automatische labelingspijplijn ontwikkeld die is ontworpen om de volgende functies uit te voeren:
- Voer periodieke batch-inferentie uit op een niet-gelabelde dataset.
- Filter resultaten op basis van een specifieke onzekerheidssteekproefstrategie.
- Activeer een SageMaker Ground Truth-taak om de bemonsterde afbeeldingen te labelen met behulp van menselijke arbeidskrachten.
- Voeg nieuw gelabelde afbeeldingen toe aan de trainingsgegevensset voor daaropvolgende modelverfijning.
De onzekerheidssteekproefstrategie vermindert het aantal afbeeldingen dat naar de menselijke labeltaak wordt gestuurd door afbeeldingen te selecteren die waarschijnlijk het meest zouden bijdragen aan het verbeteren van de modelnauwkeurigheid. Omdat het labelen van mensen een dure taak is, is een dergelijke bemonstering een belangrijke kostenbesparende techniek. We ondersteunen vier bemonsteringsstrategieën, die kunnen worden geselecteerd als een parameter die is opgeslagen in Parameter opslaan, een vermogen van AWS-systeembeheerder:
- Minste vertrouwen
- Margevertrouwen
- Verhouding van vertrouwen
- Entropy
De volledige workflow voor automatisch labelen is geïmplementeerd met AWS Stap Functies, dat de verwerkingstaak orkestreert (het elastische eindpunt voor batch-inferentie genoemd), onzekerheidssteekproeven en SageMaker Ground Truth. Het volgende diagram illustreert de workflow voor stapfuncties.
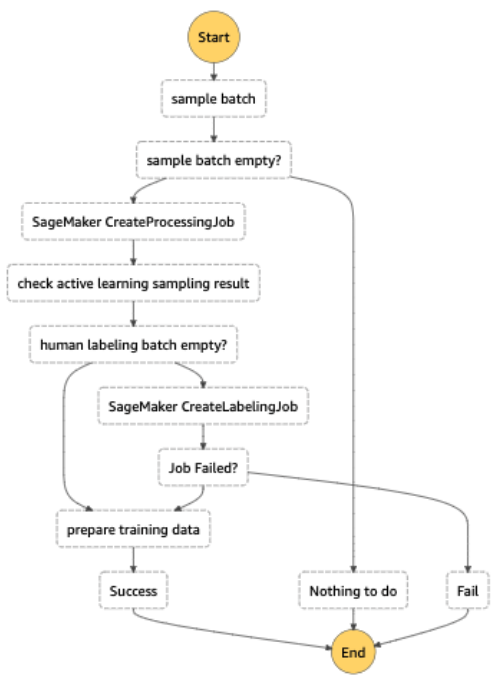
Kost efficiëntie
De belangrijkste factor die de etiketteringskosten beïnvloedt, is handmatige annotatie. Voordat het United-team deze oplossing in gebruik nam, moest het een op regels gebaseerde aanpak gebruiken, waarvoor dure handmatige gegevensannotatie en parsing-OCR-technieken van derden nodig waren. Met onze oplossing heeft United de werklast voor het handmatig labelen verminderd door alleen afbeeldingen handmatig te labelen die tot de grootste modelverbeteringen zouden leiden. Omdat het raamwerk modelonafhankelijk is, kan het in andere vergelijkbare scenario's worden gebruikt, waardoor de waarde ervan wordt uitgebreid tot een veel bredere reeks documenten.
We hebben een kostenanalyse uitgevoerd op basis van de volgende aannames:
- Elke batch bevat 1,000 afbeeldingen
- De training wordt uitgevoerd met behulp van een mlg4dn.16xlarge-instantie
- De gevolgtrekking wordt uitgevoerd op een mlg4dn.xlarge-instantie
- Er wordt na elke batch een training gegeven met 10% geannoteerde labels
- Elke trainingsronde resulteert in de volgende nauwkeurigheidsverbeteringen:
- 50% na de eerste batch
- 25% na de tweede batch
- 10% na de derde batch
Uit onze analyse blijkt dat de opleidingskosten constant en hoog blijven zonder actief leren. Het integreren van actief leren resulteert in exponentieel dalende kosten bij elke nieuwe batch gegevens.
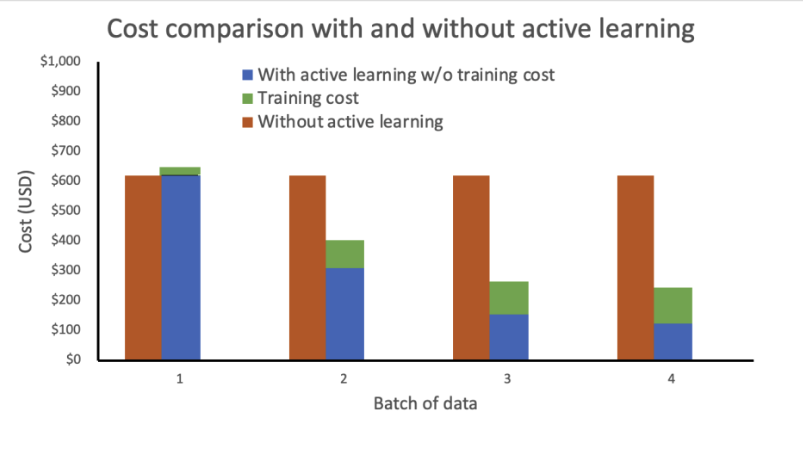
We hebben de kosten verder verlaagd door het inferentie-eindpunt te implementeren als een elastisch eindpunt door een beleid voor automatisch schalen toe te voegen. De eindpuntbronnen kunnen omhoog of omlaag worden geschaald tussen nul en een geconfigureerd maximaal aantal exemplaren.
Architectuur van de uiteindelijke oplossing
Onze focus was om het United-team te helpen aan hun functionele eisen te voldoen en tegelijkertijd een schaalbare en flexibele cloudapplicatie te bouwen. Het ML Solutions Lab-team ontwikkelde de complete productieklare oplossing met behulp van AWS CDK, waardoor het beheer en de levering van alle cloudbronnen en -diensten werd geautomatiseerd. De uiteindelijke cloudapplicatie werd als één geheel ingezet AWS CloudFormatie stapel met vier geneste stapels, die elk een enkele functionele component vertegenwoordigden.
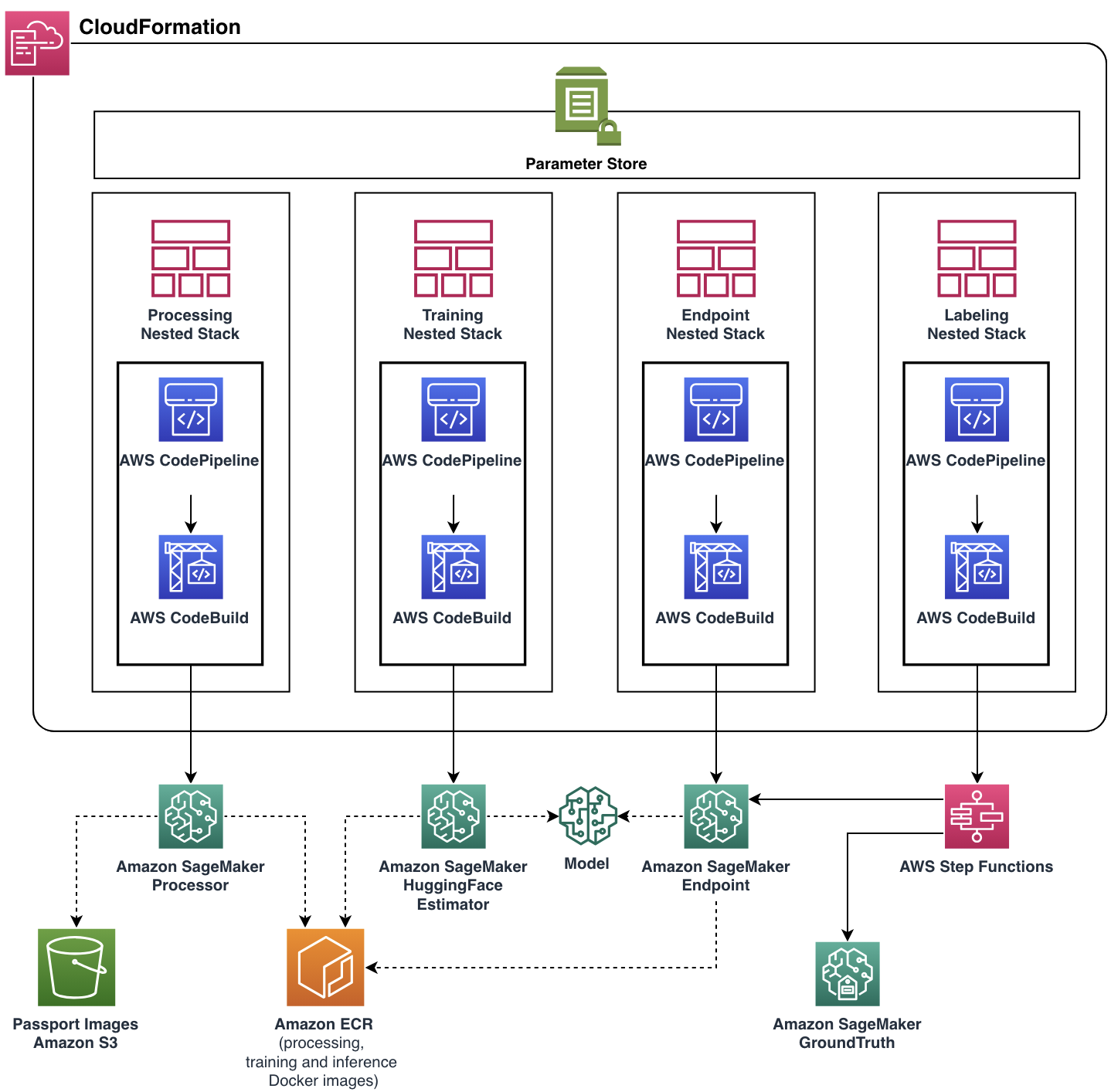
Bijna elke pijplijnfunctie, inclusief Docker-images, beleid voor automatisch schalen van eindpunten en meer, werd geparametriseerd via Parameter Store. Met een dergelijke flexibiliteit zou dezelfde pijplijninstantie kunnen worden uitgevoerd met een breed scala aan instellingen, waardoor de mogelijkheid om te experimenteren wordt toegevoegd.
Conclusie
In dit bericht bespraken we hoe United Airlines, in samenwerking met het ML Solutions Lab, een actief leerframework op AWS bouwde om de verwerking van passagiersdocumenten te automatiseren. De oplossing had grote impact op twee belangrijke aspecten van de automatiseringsdoelen van United:
- herbruikbaarheid – Dankzij het modulaire ontwerp en de modelonafhankelijke implementatie kan United Airlines deze oplossing hergebruiken voor vrijwel elk ander auto-labeling ML-gebruiksscenario
- Terugkerende kostenreductie – Door handmatige en automatische etiketteringsprocessen op een intelligente manier te combineren, kan het United-team de gemiddelde etiketteringskosten verlagen en dure etiketteringsdiensten van derden vervangen
Als u geïnteresseerd bent in het implementeren van een soortgelijke oplossing of meer wilt weten over het ML Solutions Lab, neem dan contact op met uw accountmanager of bezoek ons op Amazon Machine Learning Solutions-lab.
Over de auteurs
 Xin Gu is de Lead Data Scientist – Machine Learning bij de Advanced Analytics and Innovation-divisie van United Airlines. Ze heeft een belangrijke bijdrage geleverd aan het ontwerpen van door machine learning ondersteunde automatisering van documentbegrip en speelde een sleutelrol bij het uitbreiden van actieve leerworkflows voor gegevensannotatie voor verschillende taken en modellen. Haar expertise ligt in het verhogen van de effectiviteit en efficiëntie van AI, waardoor opmerkelijke vooruitgang wordt geboekt op het gebied van intelligente technologische vooruitgang bij United Airlines.
Xin Gu is de Lead Data Scientist – Machine Learning bij de Advanced Analytics and Innovation-divisie van United Airlines. Ze heeft een belangrijke bijdrage geleverd aan het ontwerpen van door machine learning ondersteunde automatisering van documentbegrip en speelde een sleutelrol bij het uitbreiden van actieve leerworkflows voor gegevensannotatie voor verschillende taken en modellen. Haar expertise ligt in het verhogen van de effectiviteit en efficiëntie van AI, waardoor opmerkelijke vooruitgang wordt geboekt op het gebied van intelligente technologische vooruitgang bij United Airlines.
 Jon Nelson is de Senior Manager Data Science en Machine Learning bij United Airlines.
Jon Nelson is de Senior Manager Data Science en Machine Learning bij United Airlines.
 Alex Gorjajnov is Machine Learning Engineer bij Amazon AWS. Hij bouwt architectuur en implementeert kerncomponenten van de pijplijn voor actief leren en automatisch labelen, mogelijk gemaakt door AWS CDK. Alex is een expert in MLOps, cloud computing-architectuur, statistische data-analyse en grootschalige dataverwerking.
Alex Gorjajnov is Machine Learning Engineer bij Amazon AWS. Hij bouwt architectuur en implementeert kerncomponenten van de pijplijn voor actief leren en automatisch labelen, mogelijk gemaakt door AWS CDK. Alex is een expert in MLOps, cloud computing-architectuur, statistische data-analyse en grootschalige dataverwerking.
 Vishal Das is een toegepast wetenschapper bij het Amazon ML Solutions Lab. Vóór MLSL was Vishal een oplossingsarchitect, energie, AWS. Hij promoveerde in de geofysica met een PhD minor in statistiek aan Stanford University. Hij zet zich in om met klanten samen te werken en hen te helpen groots te denken en bedrijfsresultaten te behalen. Hij is een expert in machine learning en de toepassing ervan bij het oplossen van bedrijfsproblemen.
Vishal Das is een toegepast wetenschapper bij het Amazon ML Solutions Lab. Vóór MLSL was Vishal een oplossingsarchitect, energie, AWS. Hij promoveerde in de geofysica met een PhD minor in statistiek aan Stanford University. Hij zet zich in om met klanten samen te werken en hen te helpen groots te denken en bedrijfsresultaten te behalen. Hij is een expert in machine learning en de toepassing ervan bij het oplossen van bedrijfsproblemen.
 Tianyi Mao is een Applied Scientist bij AWS, gevestigd in de omgeving van Chicago. Hij heeft meer dan 5 jaar ervaring in het bouwen van machine learning- en deep learning-oplossingen en richt zich op computervisie en versterkend leren met menselijke feedback. Hij werkt graag samen met klanten om hun uitdagingen te begrijpen en deze op te lossen door innovatieve oplossingen te creëren met behulp van AWS-services.
Tianyi Mao is een Applied Scientist bij AWS, gevestigd in de omgeving van Chicago. Hij heeft meer dan 5 jaar ervaring in het bouwen van machine learning- en deep learning-oplossingen en richt zich op computervisie en versterkend leren met menselijke feedback. Hij werkt graag samen met klanten om hun uitdagingen te begrijpen en deze op te lossen door innovatieve oplossingen te creëren met behulp van AWS-services.
 Yunzhi Shi is een Applied Scientist bij het Amazon ML Solutions Lab, waar hij samenwerkt met klanten in verschillende branches om hen te helpen bij het bedenken, ontwikkelen en implementeren van AI/ML-oplossingen die zijn gebouwd op AWS Cloud-services om hun zakelijke uitdagingen op te lossen. Hij heeft gewerkt met klanten in de automobielsector, geospatiale sector, transport en productie. Yunzhi behaalde zijn Ph.D. in Geofysica aan de Universiteit van Texas in Austin.
Yunzhi Shi is een Applied Scientist bij het Amazon ML Solutions Lab, waar hij samenwerkt met klanten in verschillende branches om hen te helpen bij het bedenken, ontwikkelen en implementeren van AI/ML-oplossingen die zijn gebouwd op AWS Cloud-services om hun zakelijke uitdagingen op te lossen. Hij heeft gewerkt met klanten in de automobielsector, geospatiale sector, transport en productie. Yunzhi behaalde zijn Ph.D. in Geofysica aan de Universiteit van Texas in Austin.
 Diego Socolinski is Senior Applied Science Manager bij het AWS Generative AI Innovation Center, waar hij leiding geeft aan het leveringsteam voor de regio's Oost-VS en Latijns-Amerika. Hij heeft meer dan twintig jaar ervaring in machinaal leren en computer vision, en heeft een doctoraat in wiskunde van de Johns Hopkins University.
Diego Socolinski is Senior Applied Science Manager bij het AWS Generative AI Innovation Center, waar hij leiding geeft aan het leveringsteam voor de regio's Oost-VS en Latijns-Amerika. Hij heeft meer dan twintig jaar ervaring in machinaal leren en computer vision, en heeft een doctoraat in wiskunde van de Johns Hopkins University.
 Xin Chen is momenteel hoofd van People Science Solutions Lab bij Amazon People eXperience Technology (PXT, ook bekend als HR) Central Science. Hij leidt een team van toegepaste wetenschappers om wetenschappelijke oplossingen van productiekwaliteit te bouwen om proactief mechanismen en procesverbeteringen te identificeren en te lanceren. Voorheen was hij hoofd van Central US, Greater China Region, LATAM en Automotive Vertical in AWS Machine Learning Solutions Lab. Hij hielp AWS-klanten bij het identificeren en bouwen van machine learning-oplossingen om de hoogste return-on-investment-mogelijkheden van hun organisatie te benutten. Xin is adjunct-faculteit aan de Northwestern University en het Illinois Institute of Technology. Hij behaalde zijn doctoraat in computerwetenschappen en techniek aan de Universiteit van Notre Dame.
Xin Chen is momenteel hoofd van People Science Solutions Lab bij Amazon People eXperience Technology (PXT, ook bekend als HR) Central Science. Hij leidt een team van toegepaste wetenschappers om wetenschappelijke oplossingen van productiekwaliteit te bouwen om proactief mechanismen en procesverbeteringen te identificeren en te lanceren. Voorheen was hij hoofd van Central US, Greater China Region, LATAM en Automotive Vertical in AWS Machine Learning Solutions Lab. Hij hielp AWS-klanten bij het identificeren en bouwen van machine learning-oplossingen om de hoogste return-on-investment-mogelijkheden van hun organisatie te benutten. Xin is adjunct-faculteit aan de Northwestern University en het Illinois Institute of Technology. Hij behaalde zijn doctoraat in computerwetenschappen en techniek aan de Universiteit van Notre Dame.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/how-united-airlines-built-a-cost-efficient-optical-character-recognition-active-learning-pipeline/

