Dit bericht is geschreven in samenwerking met Ankur Goyal en Karthikeyan Chokappa van de Cloud & Digital-activiteiten van PwC Australia.
Kunstmatige intelligentie (AI) en machinaal leren (ML) worden een integraal onderdeel van systemen en processen, waardoor beslissingen in realtime mogelijk worden gemaakt, waardoor zowel de top- als de bedrijfsresultaten binnen organisaties worden verbeterd. Het op grote schaal in productie brengen van een ML-model is echter een uitdaging en vereist een reeks best practices. Veel bedrijven beschikken al over datawetenschappers en ML-ingenieurs die state-of-the-art modellen kunnen bouwen, maar het in productie nemen van modellen en het onderhouden van de modellen op schaal blijft een uitdaging. Handmatige workflows beperken de ML-levenscyclusactiviteiten, waardoor het ontwikkelingsproces wordt vertraagd, de kosten stijgen en de kwaliteit van het eindproduct in gevaar komt.
Machine learning operations (MLOps) passen DevOps-principes toe op ML-systemen. Net zoals DevOps ontwikkeling en operaties voor software-engineering combineert, combineert MLOps ML-engineering en IT-operaties. Met de snelle groei van ML-systemen en in de context van ML-engineering biedt MLOps mogelijkheden die nodig zijn om de unieke complexiteit van de praktische toepassing van ML-systemen aan te kunnen. Over het algemeen vereisen ML-gebruiksscenario's een direct beschikbare geïntegreerde oplossing om het proces dat een ML-model van ontwikkeling naar productie-implementatie op schaal brengt, te industrialiseren en te stroomlijnen met behulp van MLOps.
Om deze klantuitdagingen aan te pakken, heeft PwC Australia Machine Learning Ops Accelerator ontwikkeld als een reeks gestandaardiseerde proces- en technologiemogelijkheden om de operationalisering van AI/ML-modellen te verbeteren die cross-functionele samenwerking tussen teams tijdens ML-levenscyclusoperaties mogelijk maken. PwC Machine Learning Ops Accelerator, gebouwd bovenop de native AWS-services, levert een passende oplossing die eenvoudig kan worden geïntegreerd in de ML-gebruiksscenario's voor klanten in alle sectoren. In dit artikel concentreren we ons op het bouwen en implementeren van een ML-use case die verschillende levenscycluscomponenten van een ML-model integreert, waardoor continue integratie (CI), continue levering (CD), continue training (CT) en continue monitoring (CM) mogelijk wordt.
Overzicht oplossingen
In MLOps omvat een succesvolle reis van data naar ML-modellen naar aanbevelingen en voorspellingen in bedrijfssystemen en -processen verschillende cruciale stappen. Het houdt in dat je het resultaat van een experiment of prototype neemt en er een productiesysteem van maakt met standaardcontroles, kwaliteit en feedbackloops. Het is veel meer dan alleen automatisering. Het gaat om het verbeteren van organisatiepraktijken en het leveren van resultaten die herhaalbaar en reproduceerbaar zijn op schaal.
Slechts een klein deel van een praktijkvoorbeeld van ML bestaat uit het model zelf. De verschillende componenten die nodig zijn om een geïntegreerde geavanceerde ML-capaciteit op te bouwen en deze continu op schaal te exploiteren, worden weergegeven in figuur 1. Zoals geïllustreerd in het volgende diagram, omvat PwC MLOps Accelerator zeven belangrijke geïntegreerde mogelijkheden en iteratieve stappen die CI, CD, CT en CM van een ML-use-case. De oplossing maakt gebruik van de native AWS-functies van Amazon Sage Maker, en bouwt hieromheen een flexibel en uitbreidbaar raamwerk.
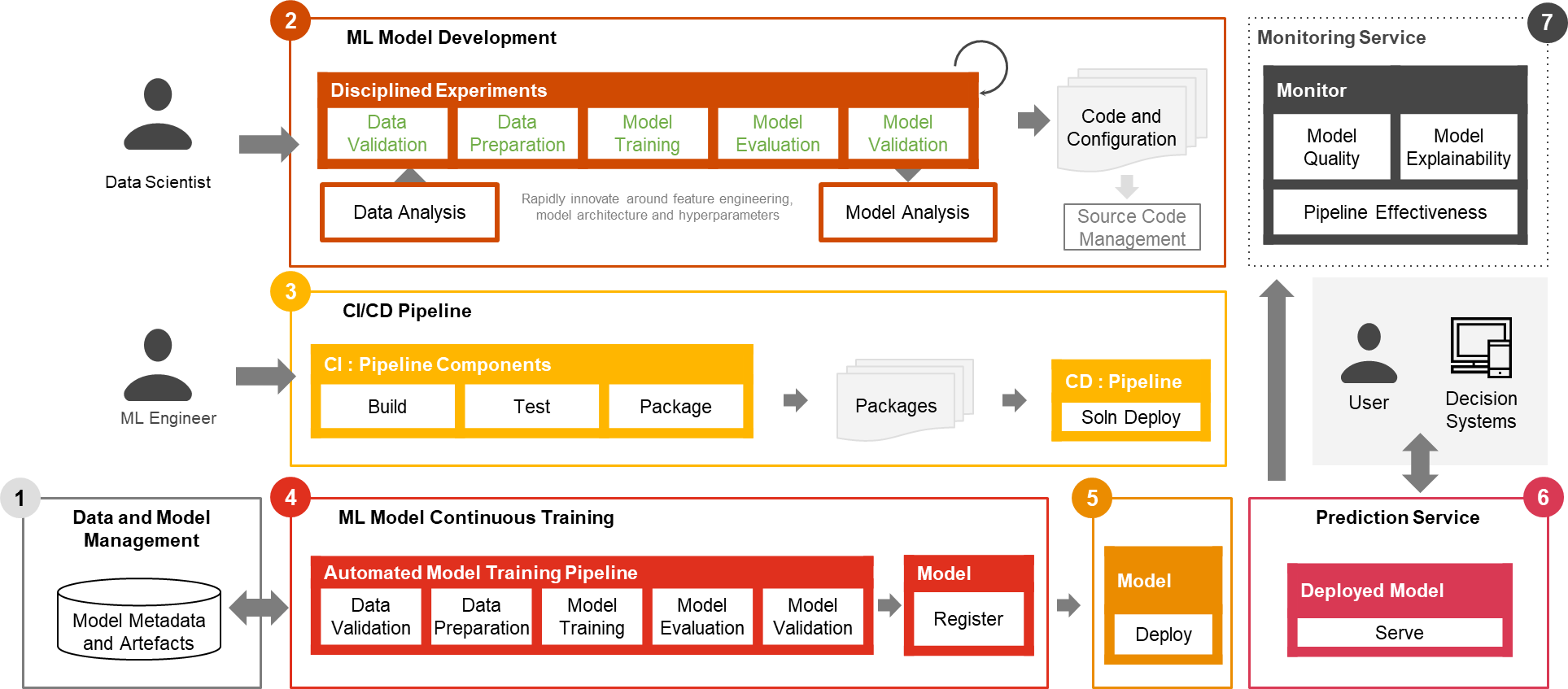
Figuur 1 – Mogelijkheden van PwC Machine Learning Ops Accelerator
In een echt ondernemingsscenario kunnen er aanvullende teststappen en -stadia bestaan om een rigoureuze validatie en implementatie van modellen in verschillende omgevingen te garanderen.
- Gegevens- en modelbeheer bieden een centrale mogelijkheid die ML-artefacten gedurende hun hele levenscyclus regelt. Het maakt controleerbaarheid, traceerbaarheid en compliance mogelijk. Het bevordert ook de deelbaarheid, herbruikbaarheid en vindbaarheid van ML-middelen.
- Ontwikkeling van ML-modellen stelt verschillende persona's in staat een robuuste en reproduceerbare pijplijn voor modeltraining te ontwikkelen, die een reeks stappen omvat, van gegevensvalidatie en -transformatie tot modeltraining en -evaluatie.
- Continue integratie/levering vergemakkelijkt het geautomatiseerd bouwen, testen en verpakken van de modeltrainingspijplijn en het implementeren ervan in de doeluitvoeringsomgeving. Integraties met CI/CD-workflows en dataversiebeheer bevorderen best practices van MLOps, zoals governance en monitoring voor iteratieve ontwikkeling en dataversiebeheer.
- Continue training in het ML-model mogelijkheid voert de trainingspijplijn uit op basis van herscholingstriggers; dat wil zeggen, naarmate nieuwe gegevens beschikbaar komen of de prestatie van het model onder een vooraf ingestelde drempel daalt. Het registreert het getrainde model als het in aanmerking komt als een succesvolle modelkandidaat en slaat de trainingsartefacten en bijbehorende metagegevens op.
- Modelimplementatie biedt toegang tot het geregistreerde getrainde model om te beoordelen en goed te keuren voor productievrijgave en maakt het verpakken, testen en implementeren van modellen in de voorspellingsserviceomgeving voor productie mogelijk.
- Voorspellingsservice -mogelijkheid start het geïmplementeerde model om voorspellingen te doen via online-, batch- of streamingpatronen. Serving runtime legt ook modelservinglogboeken vast voor continue monitoring en verbeteringen.
- Continue bewaking bewaakt het model op voorspellende effectiviteit om modelverval en service-effectiviteit te detecteren (latentie, pijplijn door en uitvoeringsfouten)
PwC Machine Learning Ops Accelerator-architectuur
De oplossing is gebouwd bovenop AWS-native services met behulp van Amazon SageMaker en serverloze technologie om de prestaties en schaalbaarheid hoog te houden en de bedrijfskosten laag.
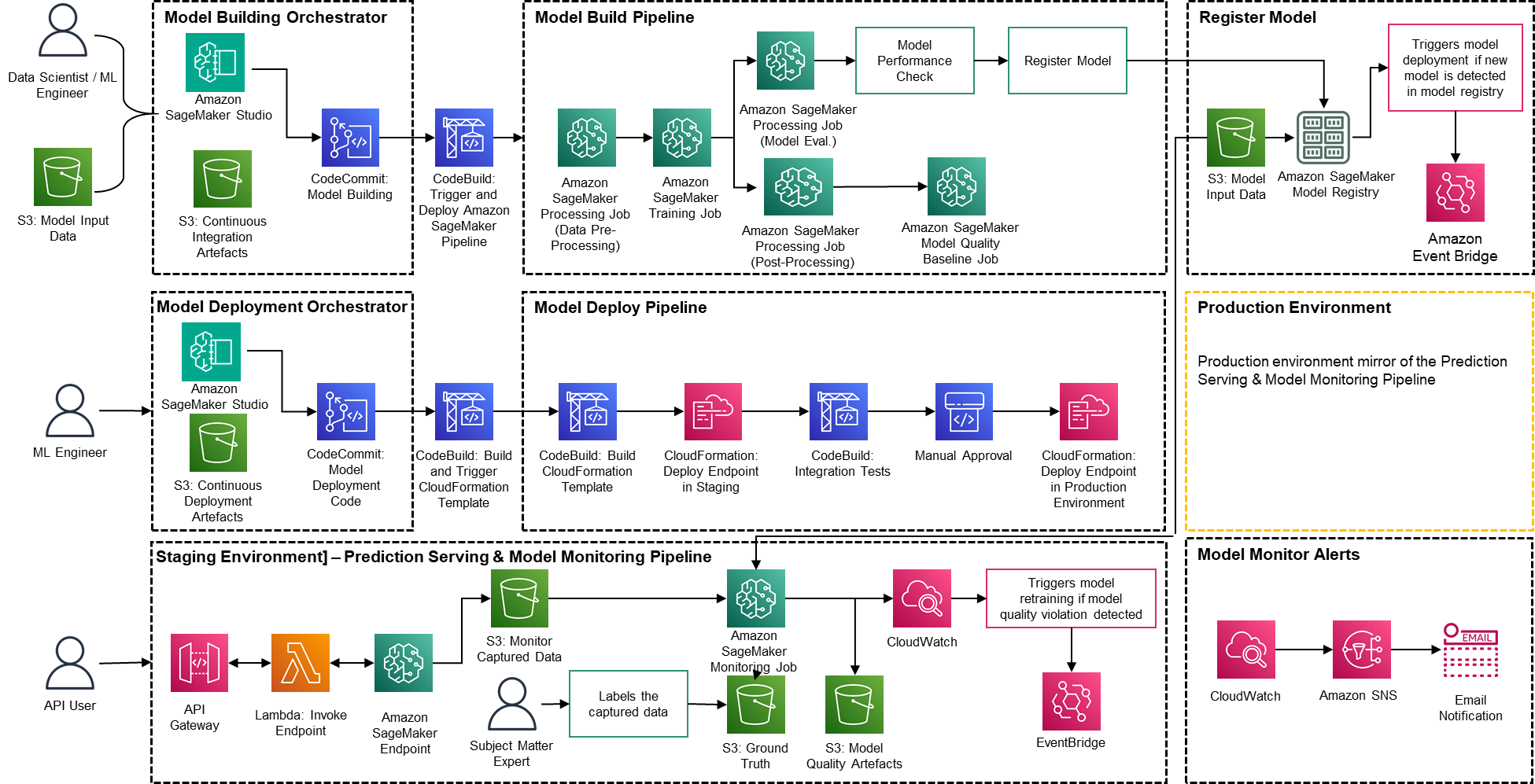
Figuur 2 – PwC Machine Learning Ops Accelerator-architectuur
- PwC Machine Learning Ops Accelerator biedt een persoonsgestuurd toegangsrecht voor build-out, gebruik en bewerkingen waarmee ML-ingenieurs en datawetenschappers de implementatie van pipelines (training en service) kunnen automatiseren en snel kunnen reageren op veranderingen in de modelkwaliteit. Amazon SageMaker-rolmanager wordt gebruikt om op rollen gebaseerde ML-activiteit te implementeren, en Amazon S3 wordt gebruikt om invoergegevens en artefacten op te slaan.
- Solution maakt gebruik van bestaande modelcreatiemiddelen van de klant en bouwt hieromheen een flexibel en uitbreidbaar raamwerk met behulp van native AWS-services. Er zijn integraties gebouwd tussen Amazon S3, Git en AWS CodeCommit die versiebeheer van datasets mogelijk maken met minimaal toekomstig beheer.
- AWS CloudFormation-sjabloon wordt gegenereerd met behulp van AWS Cloud Development Kit (AWS CDK). AWS CDK biedt de mogelijkheid om wijzigingen voor de volledige oplossing te beheren. De geautomatiseerde pijplijn omvat stappen voor kant-en-klare modelopslag en metrische tracking.
- PwC MLOps Accelerator is modulair ontworpen en wordt geleverd als infrastructuur-as-code (IaC) om automatische implementaties mogelijk te maken. Het implementatieproces maakt gebruik van AWS Codecommit, AWS CodeBuild, AWS CodePipelineen AWS CloudFormation-sjabloon. Volledige end-to-end oplossing voor het operationeel maken van een ML-model is beschikbaar als inzetbare code.
- Via een reeks IaC-sjablonen worden drie afzonderlijke componenten geïmplementeerd: modelbouw, modelimplementatie en modelmonitoring en voorspellingsservice, met behulp van Amazon SageMaker-pijpleidingen
- De modelbouwpijplijn automatiseert het modeltraining- en evaluatieproces en maakt goedkeuring en registratie van het getrainde model mogelijk.
- De pijplijn voor modelimplementatie voorziet in de noodzakelijke infrastructuur om het ML-model in te zetten voor batch- en realtime-inferentie.
- Modelmonitoring en voorspellingsservicepijplijn implementeert de infrastructuur die nodig is om voorspellingen te doen en de modelprestaties te monitoren.
- PwC MLOps Accelerator is ontworpen om agnostisch te zijn voor ML-modellen, ML-frameworks en runtime-omgevingen. De oplossing maakt het vertrouwde gebruik van programmeertalen zoals Python en R, ontwikkelingstools zoals Jupyter Notebook en ML-frameworks mogelijk via een configuratiebestand. Deze flexibiliteit maakt het voor datawetenschappers eenvoudig om modellen voortdurend te verfijnen en in te zetten in de taal en omgeving van hun voorkeur.
- De oplossing heeft ingebouwde integraties om vooraf gebouwde of aangepaste tools te gebruiken om de labeltaken toe te wijzen Amazon SageMaker Grondwaarheid voor trainingsdatasets om continue training en monitoring te bieden.
- End-to-end ML-pijplijn is ontworpen met behulp van de native functies van SageMaker (Amazon SageMaker Studio , Amazon SageMaker Modelbouwpijpleidingen, Amazon SageMaker-experimenten en Amazon SageMaker-eindpunten).
- De oplossing maakt gebruik van de ingebouwde mogelijkheden van Amazon SageMaker voor modelversiebeheer, het volgen van modelafstammingen, het delen van modellen en serverloze inferentie met Amazon SageMaker-modelregister.
- Zodra het model in productie is, bewaakt de oplossing continu de kwaliteit van ML-modellen in realtime. Amazon SageMaker-modelmonitor wordt gebruikt om modellen in productie continu te monitoren. Amazon CloudWatch Logs wordt gebruikt om logbestanden te verzamelen die de modelstatus monitoren, en meldingen worden verzonden via Amazon SNS wanneer de kwaliteit van het model bepaalde drempels bereikt. Native loggers zoals (boto3) worden gebruikt om de uitvoeringsstatus vast te leggen om het oplossen van problemen te versnellen.
Oplossingsoverzicht
In de volgende walkthrough worden de standaardstappen besproken voor het maken van het MLOps-proces voor een model met behulp van PwC MLOps Accelerator. Deze walkthrough beschrijft een gebruiksscenario van een MLOps-ingenieur die de pijplijn wil implementeren voor een recent ontwikkeld ML-model met behulp van een eenvoudig definitie-/configuratiebestand dat intuïtief is.
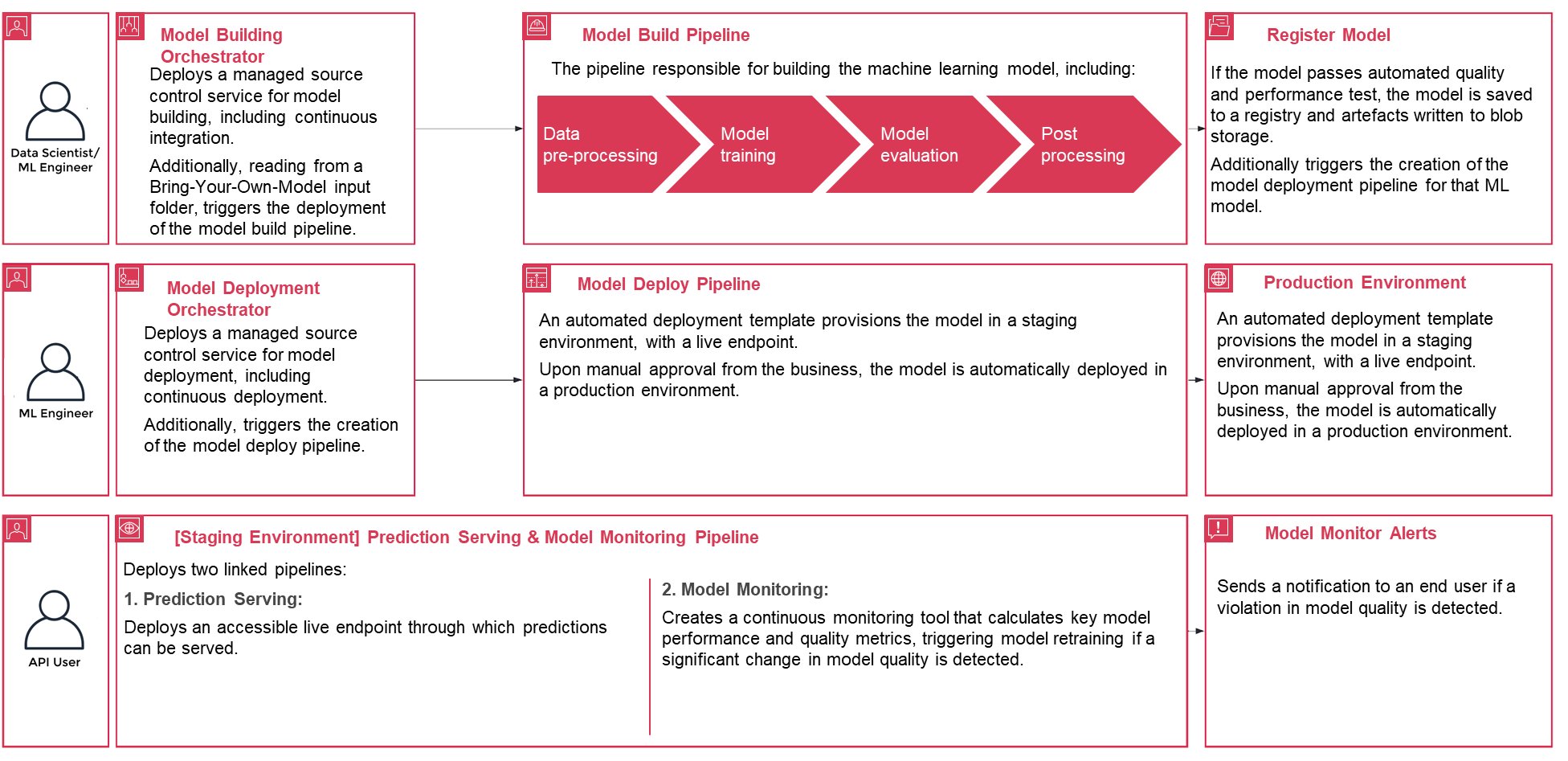
Figuur 3 – Levenscyclus van PwC Machine Learning Ops Accelerator-proces
- Schrijf u in om aan de slag te gaan PwC MLOps Accelerator om toegang te krijgen tot oplossingsartefacten. De gehele oplossing wordt aangestuurd vanuit één configuratie-YAML-bestand (
config.yaml) per model. Alle details die nodig zijn om de oplossing uit te voeren, bevinden zich in dat configuratiebestand en worden samen met het model opgeslagen in een Git-repository. Het configuratiebestand zal dienen als invoer voor het automatiseren van workflowstappen door belangrijke parameters en instellingen buiten de code te externaliseren. - De ML-ingenieur moet worden ingevuld
config.yamlbestand en activeer de MLOps-pijplijn. Klanten kunnen een AWS-account, de repository, het model, de gebruikte gegevens, de naam van de pijplijn, het trainingsframework, het aantal instanties dat voor training moet worden gebruikt, het inferentieframework en eventuele voor- en naverwerkingsstappen en diverse andere configureren. configuraties om de modelkwaliteit, bias en verklaarbaarheid te controleren.

Figuur 4 – Machine Learning Ops Accelerator-configuratie YAML
- Er wordt een eenvoudig YAML-bestand gebruikt om de vereisten voor training, implementatie, monitoring en runtime van elk model te configureren. Zodra de
config.yamlop de juiste manier is geconfigureerd en naast het model is opgeslagen in zijn eigen Git-repository, wordt de modelbouworkestrator aangeroepen. Het kan ook lezen van een Bring-Your-Own-Model dat kan worden geconfigureerd via YAML om de implementatie van de modelbouwpijplijn te activeren. - Alles na dit punt wordt door de oplossing geautomatiseerd en vereist geen tussenkomst van de ML-ingenieur of datawetenschapper. De pijplijn die verantwoordelijk is voor het bouwen van het ML-model omvat gegevensvoorverwerking, modeltraining, modelevaluatie en ost-verwerking. Als het model de geautomatiseerde kwaliteits- en prestatietests doorstaat, wordt het model opgeslagen in een register en worden artefacten naar Amazon S3-opslag geschreven volgens de definities in de YAML-bestanden. Dit activeert het maken van de modelimplementatiepijplijn voor dat ML-model.
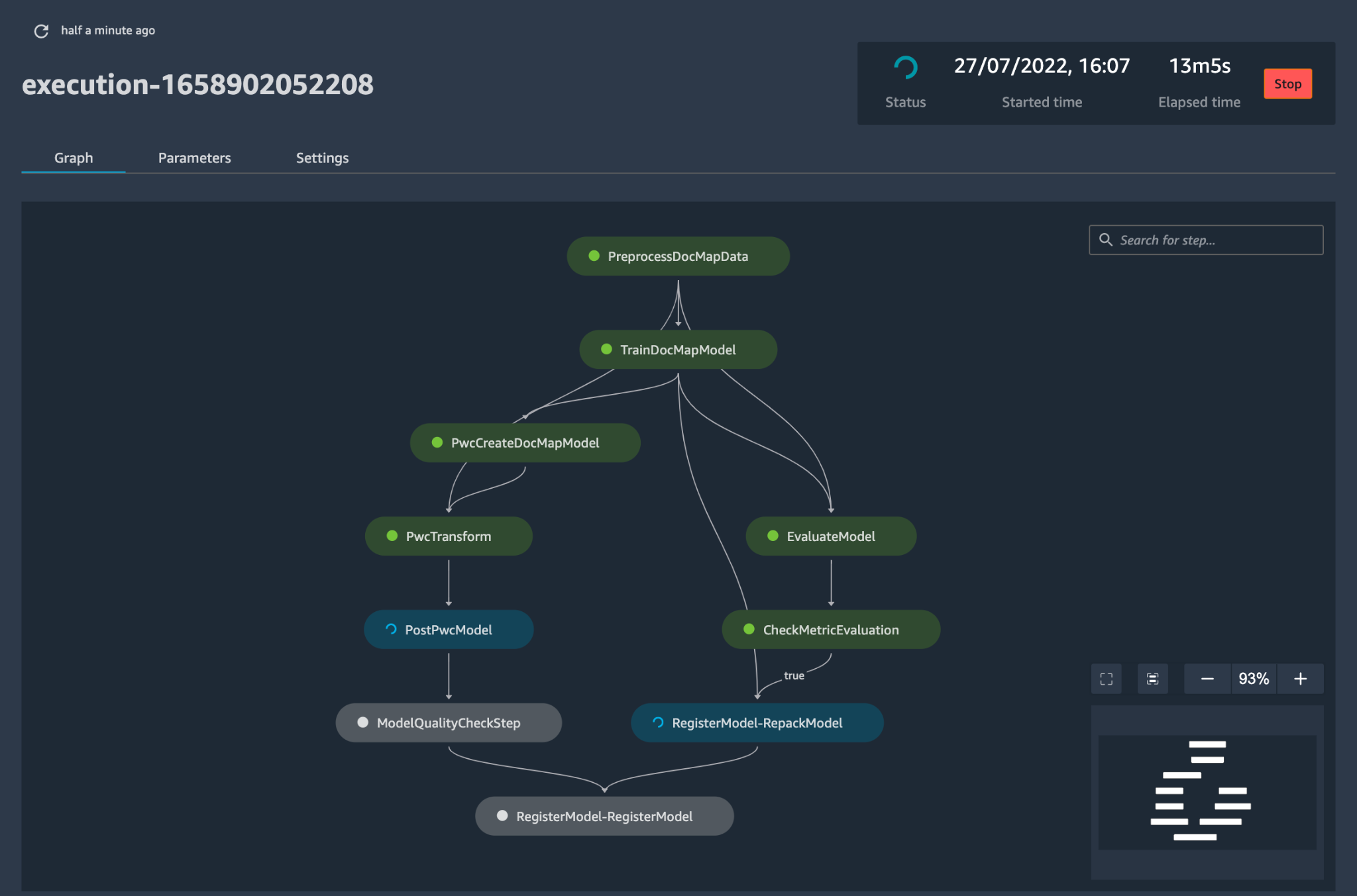
Figuur 5 – Voorbeeld van een workflow voor de implementatie van een model
- Vervolgens richt een geautomatiseerde implementatiesjabloon het model in een faseringsomgeving met een live eindpunt. Na goedkeuring wordt het model automatisch in de productieomgeving geïmplementeerd.
- De oplossing maakt gebruik van twee gekoppelde pijpleidingen. Voorspellingen serveren implementeert een toegankelijk live-eindpunt waarmee voorspellingen kunnen worden gedaan. Modelmonitoring creëert een tool voor continue monitoring die de belangrijkste prestatie- en kwaliteitsstatistieken van het model berekent, waardoor modelherscholing wordt geactiveerd als er een significante verandering in de modelkwaliteit wordt gedetecteerd.
- Nu u de creatie en de initiële implementatie hebt doorlopen, kan de MLOps-engineer foutwaarschuwingen configureren, zodat u wordt gewaarschuwd voor problemen, bijvoorbeeld wanneer een pijplijn er niet in slaagt zijn beoogde werk te doen.
- MLOps gaat niet langer over het verpakken, testen en implementeren van cloudservicecomponenten, vergelijkbaar met een traditionele CI/CD-implementatie; het is een systeem dat automatisch een andere dienst zou moeten inzetten. De modeltrainingspijplijn implementeert bijvoorbeeld automatisch de modelimplementatiepijplijn om de voorspellingsservice in te schakelen, die op zijn beurt de modelbewakingsservice mogelijk maakt.
Conclusie
Samenvattend is MLOps van cruciaal belang voor elke organisatie die ML-modellen op grote schaal in productiesystemen wil implementeren. PwC heeft een accelerator ontwikkeld om het bouwen, implementeren en onderhouden van ML-modellen te automatiseren door DevOps-tools te integreren in het modelontwikkelingsproces.
In dit bericht hebben we onderzocht hoe de PwC-oplossing wordt aangedreven door native ML-services van AWS en helpt om MLOps-praktijken over te nemen, zodat bedrijven hun AI-traject kunnen versnellen en meer waarde uit hun ML-modellen kunnen halen. We hebben de stappen doorlopen die een gebruiker zou moeten nemen om toegang te krijgen tot de PwC Machine Learning Ops Accelerator, de pipelines te laten draaien en een ML-use case te implementeren die verschillende levenscycluscomponenten van een ML-model integreert.
Om op grote schaal aan de slag te gaan met uw MLOps-traject op AWS Cloud en uw ML-productieworkloads uit te voeren, schrijft u zich in voor PwC Machine Learning-operaties.
Over de auteurs
 Kiran Kumar Ballari is een Principal Solutions Architect bij Amazon Web Services (AWS). Hij is een evangelist die klanten graag helpt nieuwe technologieën te benutten en herhaalbare industriële oplossingen te bouwen om hun problemen op te lossen. Hij heeft vooral een passie voor software engineering, generatieve AI en het helpen van bedrijven met AI/ML-productontwikkeling.
Kiran Kumar Ballari is een Principal Solutions Architect bij Amazon Web Services (AWS). Hij is een evangelist die klanten graag helpt nieuwe technologieën te benutten en herhaalbare industriële oplossingen te bouwen om hun problemen op te lossen. Hij heeft vooral een passie voor software engineering, generatieve AI en het helpen van bedrijven met AI/ML-productontwikkeling.
 Ankur Goyal is directeur van de Cloud en Digital-praktijk van PwC Australia, gericht op Data, Analytics & AI. Ankur heeft uitgebreide ervaring in het ondersteunen van organisaties uit de publieke en private sector bij het aansturen van technologische transformaties en het ontwerpen van innovatieve oplossingen door gebruik te maken van datamiddelen en -technologieën.
Ankur Goyal is directeur van de Cloud en Digital-praktijk van PwC Australia, gericht op Data, Analytics & AI. Ankur heeft uitgebreide ervaring in het ondersteunen van organisaties uit de publieke en private sector bij het aansturen van technologische transformaties en het ontwerpen van innovatieve oplossingen door gebruik te maken van datamiddelen en -technologieën.
 Karthikeyan Chokappa (KC) is manager in de cloud- en digitale praktijk van PwC Australië, gericht op data, analyse en AI. KC heeft een passie voor het ontwerpen, ontwikkelen en implementeren van end-to-end analyseoplossingen die gegevens transformeren in waardevolle beslissingsmiddelen om de prestaties en het gebruik te verbeteren en de totale eigendomskosten voor verbonden en intelligente dingen te verlagen.
Karthikeyan Chokappa (KC) is manager in de cloud- en digitale praktijk van PwC Australië, gericht op data, analyse en AI. KC heeft een passie voor het ontwerpen, ontwikkelen en implementeren van end-to-end analyseoplossingen die gegevens transformeren in waardevolle beslissingsmiddelen om de prestaties en het gebruik te verbeteren en de totale eigendomskosten voor verbonden en intelligente dingen te verlagen.
 Rama Lankalapalli is een Sr. Partner Solutions Architect bij AWS en werkt samen met PwC om de migraties en moderniseringen van hun klanten naar AWS te versnellen. Hij werkt in verschillende sectoren om de adoptie van AWS Cloud te versnellen. Zijn expertise ligt in het ontwerpen van efficiënte en schaalbare cloudoplossingen, het stimuleren van innovatie en modernisering van klantapplicaties door gebruik te maken van AWS-services en het opzetten van een veerkrachtige cloudfundament.
Rama Lankalapalli is een Sr. Partner Solutions Architect bij AWS en werkt samen met PwC om de migraties en moderniseringen van hun klanten naar AWS te versnellen. Hij werkt in verschillende sectoren om de adoptie van AWS Cloud te versnellen. Zijn expertise ligt in het ontwerpen van efficiënte en schaalbare cloudoplossingen, het stimuleren van innovatie en modernisering van klantapplicaties door gebruik te maken van AWS-services en het opzetten van een veerkrachtige cloudfundament.
 Jeejee Unwalla is een Senior Solutions Architect bij AWS die het leuk vindt om klanten te begeleiden bij het oplossen van uitdagingen en strategisch denken. Hij heeft een passie voor technologie en data en het mogelijk maken van innovatie.
Jeejee Unwalla is een Senior Solutions Architect bij AWS die het leuk vindt om klanten te begeleiden bij het oplossen van uitdagingen en strategisch denken. Hij heeft een passie voor technologie en data en het mogelijk maken van innovatie.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/driving-advanced-analytics-outcomes-at-scale-using-amazon-sagemaker-powered-pwcs-machine-learning-ops-accelerator/

