We leven in een tijdperk waarin het machine learning-model op zijn hoogtepunt is. Vergeleken met decennia geleden zouden de meeste mensen nog nooit van ChatGPT of kunstmatige intelligentie hebben gehoord. Dat zijn echter de onderwerpen waar mensen over blijven praten. Waarom? Omdat de gegeven waarden zo belangrijk zijn in vergelijking met de inspanning.
De doorbraak van AI in de afgelopen jaren kan aan veel dingen worden toegeschreven, maar een daarvan is het grote taalmodel (LLM). Veel mensen die tekstgeneratie-AI gebruiken, worden mogelijk gemaakt door het LLM-model; ChatGPT gebruikt bijvoorbeeld hun GPT-model. Omdat LLM een belangrijk onderwerp is, moeten we erover leren.
Dit artikel bespreekt grote taalmodellen in 3 moeilijkheidsgraden, maar we zullen slechts enkele aspecten van LLM's bespreken. We zouden alleen van mening verschillen op een manier die elke lezer in staat stelt te begrijpen wat LLM is. Laten we, met dat in gedachten, erop ingaan.
Op het eerste niveau gaan we ervan uit dat de lezer niets weet over LLM en misschien wel iets weet over het gebied van data science/machine learning. Dus ik zou AI en Machine Learning kort introduceren voordat ik naar de LLM's zou gaan.
Artificial Intelligence is de wetenschap van het ontwikkelen van intelligente computerprogramma's. Het is de bedoeling dat het programma intelligente taken uitvoert die mensen zouden kunnen doen, maar er zijn geen beperkingen aan de menselijke biologische behoeften. machine learning is een veld in kunstmatige intelligentie dat zich richt op gegevensgeneralisatiestudies met statistische algoritmen. In zekere zin probeert Machine Learning kunstmatige intelligentie te bereiken via datastudie, zodat het programma zonder instructie intelligentietaken kan uitvoeren.
Historisch gezien wordt het veld dat de informatica en de taalkunde kruist het Natuurlijke genoemd Taalverwerking veld. Het vakgebied betreft voornamelijk alle activiteiten van machinale verwerking van menselijke tekst, zoals tekstdocumenten. Voorheen was dit vakgebied alleen beperkt tot het op regels gebaseerde systeem, maar dit werd nog uitgebreider met de introductie van geavanceerde semi-gecontroleerde en niet-gecontroleerde algoritmen waarmee het model zonder enige richting kan leren. Een van de geavanceerde modellen om dit te doen is het Taalmodel.
De taal model is een probabilistisch NLP-model om veel menselijke taken uit te voeren, zoals vertaling, grammaticacorrectie en tekstgeneratie. De oude vorm van het taalmodel maakt gebruik van puur statistische benaderingen zoals de n-gram-methode, waarbij de aanname is dat de waarschijnlijkheid van het volgende woord alleen afhangt van de gegevens met een vaste grootte van het voorgaande woord.
Echter, de introductie van Neural Network heeft de vorige aanpak onttroond. Een kunstmatig neuraal netwerk, of NN, is een computerprogramma dat de neuronenstructuur van het menselijk brein nabootst. De Neural Network-aanpak is goed te gebruiken omdat deze complexe patroonherkenning uit de tekstgegevens kan verwerken en sequentiële gegevens zoals tekst kan verwerken. Daarom is het huidige Taalmodel meestal gebaseerd op NN.
Grote taalmodellen, of LLM's, zijn machine learning-modellen die leren van een groot aantal gegevensdocumenten om algemene taalgeneratie uit te voeren. Ze zijn nog steeds een taalmodel, maar door het enorme aantal parameters dat het NN leert, worden ze als groot beschouwd. In termen van leken zou het model kunnen uitvoeren hoe mensen schrijven door de volgende woorden uit de gegeven invoerwoorden heel goed te voorspellen.
Voorbeelden van LLM-taken zijn onder meer taalvertaling, machine-chatbot, het beantwoorden van vragen en nog veel meer. Uit elke reeks gegevensinvoer kan het model relaties tussen de woorden identificeren en uitvoer genereren die geschikt is voor de instructie.
Bijna alle generatieve AI-producten die iets bieden met behulp van tekstgeneratie worden mogelijk gemaakt door de LLM's. Grote producten zoals ChatGPT, Google's Bard en nog veel meer gebruiken LLM's als basis voor hun product.
De lezer heeft kennis van datawetenschap, maar moet op dit niveau meer leren over de LLM. Op zijn minst kan de lezer de termen begrijpen die in het gegevensveld worden gebruikt. Op dit niveau zouden we dieper in de basisarchitectuur duiken.
Zoals eerder uitgelegd, is LLM een neuraal netwerkmodel dat is getraind op enorme hoeveelheden tekstgegevens. Om dit concept verder te begrijpen, zou het nuttig zijn om te begrijpen hoe neurale netwerken en deep learning werken.
In het vorige niveau hebben we uitgelegd dat een neuraal neuron een model is dat de neurale structuur van het menselijk brein nabootst. Het belangrijkste element van het neurale netwerk zijn de neuronen, vaak knooppunten genoemd. Om het concept beter uit te leggen, zie de typische neurale netwerkarchitectuur in de onderstaande afbeelding.
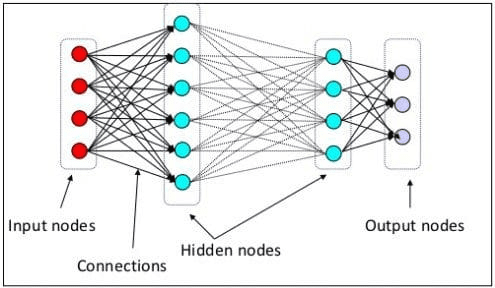
Neurale netwerkarchitectuur (bron afbeelding: KDnuggets)
Zoals we in de afbeelding hierboven kunnen zien, bestaat het neurale netwerk uit drie lagen:
- Invoerlaag waar het de informatie ontvangt en overdraagt naar de andere knooppunten in de volgende laag.
- Verborgen knooppuntlagen waar alle berekeningen plaatsvinden.
- Uitgangsknooppuntlaag waar de rekenuitvoer zich bevindt.
Het wordt deep learning genoemd als we ons neurale netwerkmodel trainen met twee of meer verborgen lagen. Het wordt diep genoemd omdat het veel tussenlagen gebruikt. Het voordeel van deep learning-modellen is dat ze automatisch functies leren en extraheren uit de gegevens waartoe traditionele machine learning-modellen niet in staat zijn.
In het Large Language Model is deep learning belangrijk omdat het model is gebouwd op diepe neurale netwerkarchitecturen. Dus waarom wordt het LLM genoemd? Dit komt doordat miljarden lagen zijn getraind op enorme hoeveelheden tekstgegevens. De lagen zouden modelparameters produceren die het model helpen complexe taalpatronen te leren, waaronder grammatica, schrijfstijl en nog veel meer.
Het vereenvoudigde proces van de modeltraining wordt weergegeven in de onderstaande afbeelding.
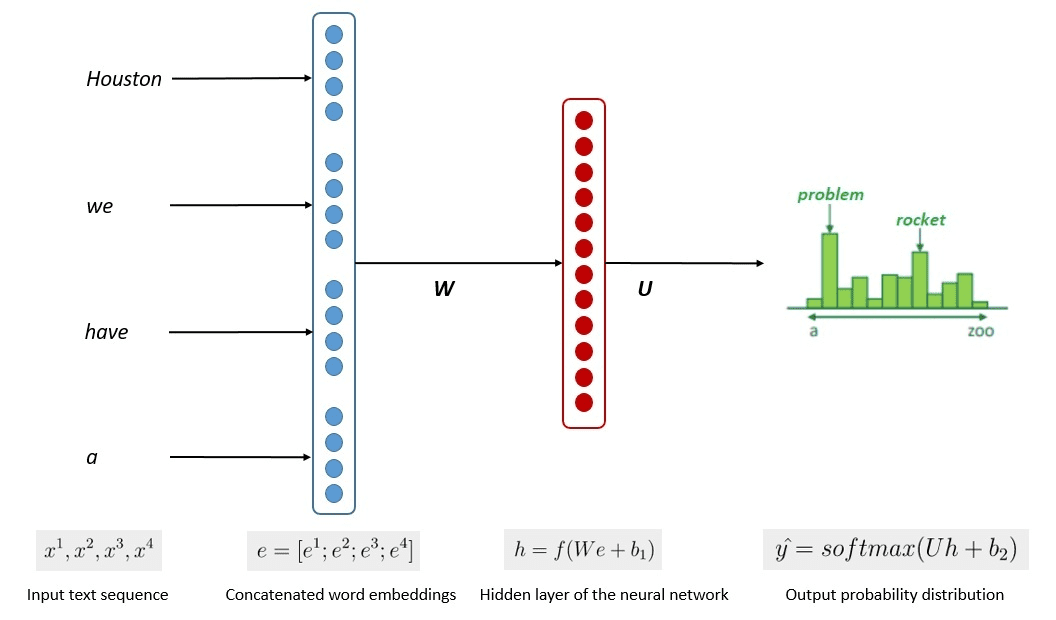
Afbeelding door Kumar Chandrakant (bron: Baeldung.com)
Uit het proces bleek dat de modellen relevante tekst konden genereren op basis van de waarschijnlijkheid van elk woord of elke zin in de invoergegevens. In de LLM's wordt gebruik gemaakt van de geavanceerde aanpak zelfstandig leren en semi-begeleid leren om het vermogen voor algemene doeleinden te bereiken.
Zelfgestuurd leren is een techniek waarbij we geen labels hebben, maar waarbij de trainingsgegevens zelf de trainingsfeedback leveren. Het wordt gebruikt in het LLM-trainingsproces, omdat de gegevens meestal geen labels hebben. In LLM zou je de omringende context kunnen gebruiken als aanwijzing om de volgende woorden te voorspellen. Semi-gesuperviseerd leren combineert daarentegen de concepten voor begeleid en onbewaakt leren met een kleine hoeveelheid gelabelde gegevens om nieuwe labels te genereren voor een grote hoeveelheid ongelabelde gegevens. Semi-gecontroleerd leren wordt meestal gebruikt voor LLM's met specifieke context- of domeinbehoeften.
Op het derde niveau zouden we de LLM dieper bespreken, vooral door de LLM-structuur aan te pakken en hoe deze mensachtige generatiecapaciteiten zou kunnen bereiken.
We hebben besproken dat LLM gebaseerd is op het neurale netwerkmodel met Deep Learning-technieken. De LLM is doorgaans gebouwd op basis van transformator gebaseerd architectuur van de afgelopen jaren. De transformator is gebaseerd op het multi-head aandachtsmechanisme geïntroduceerd door Vaswani et al. (2017) en is in veel LLM's gebruikt.
Transformers is een modelarchitectuur die de sequentiële taken probeert op te lossen die eerder voorkomen in de RNN's en LSTM's. De oude manier van het Taalmodel was om RNN en LSTM te gebruiken om gegevens sequentieel te verwerken, waarbij het model elke woorduitvoer zou gebruiken en deze terug zou herhalen, zodat het model het niet zou vergeten. Ze hebben echter problemen met gegevens over lange reeksen zodra transformatoren zijn geïntroduceerd.
Voordat we dieper ingaan op de Transformers, wil ik het concept van de encoder-decoder introduceren dat eerder in RNN's werd gebruikt. Dankzij de encoder-decoderstructuur kunnen de invoer- en uitvoertekst niet dezelfde lengte hebben. Het voorbeeldgebruik is een taalvertaling, die vaak een andere reeksgrootte heeft.
De structuur kan in tweeën worden verdeeld. Het eerste deel heet Encoder, een onderdeel dat gegevensreeksen ontvangt en op basis daarvan een nieuwe representatie creëert. De representatie zou worden gebruikt in het tweede deel van het model, namelijk de decoder.
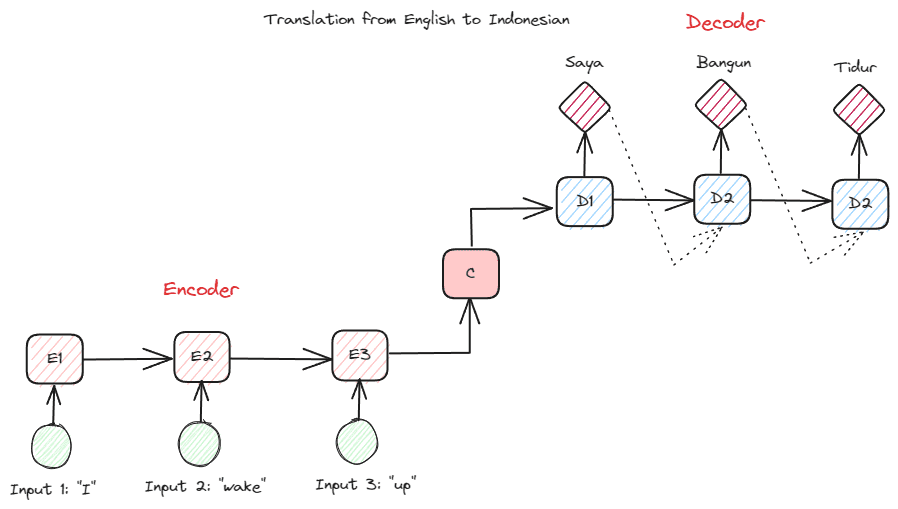
Afbeelding door auteur
Het probleem met RNN is dat het model mogelijk hulp nodig heeft bij het onthouden van langere reeksen, zelfs met de bovenstaande encoder-decoder-structuur. Dit is waar het aandachtsmechanisme zou kunnen helpen het probleem op te lossen, een laag die lange-invoerproblemen zou kunnen oplossen. Het aandachtsmechanisme wordt in het artikel geïntroduceerd door Bahdanau c.s.. (2014) om de RNN's van het encoder-decoder-type op te lossen door zich te concentreren op een belangrijk deel van de modelinvoer terwijl de uitvoervoorspelling wordt gedaan.
De structuur van de transformator is geïnspireerd op het encoder-decoder-type en gebouwd met aandachtsmechanismetechnieken, zodat de gegevens niet in opeenvolgende volgorde hoeven te worden verwerkt. Het algemene transformatormodel is gestructureerd zoals in de onderstaande afbeelding.

Transformers-architectuur (Vaswani et al. (2017))
In de bovenstaande structuur coderen de transformatoren de datavectorreeks in de woordinbedding, terwijl ze de decodering gebruiken om gegevens naar de oorspronkelijke vorm te transformeren. De codering kan met het aandachtsmechanisme een bepaald belang toekennen aan de invoer.
We hebben wat gesproken over transformatoren die de datavector coderen, maar wat is een datavector? Laten we het bespreken. In het machine learning-model kunnen we de ruwe natuurlijke taalgegevens niet in het model invoeren, dus moeten we ze omzetten in numerieke vormen. Het transformatieproces wordt woordinbedding genoemd, waarbij elk invoerwoord wordt verwerkt via het woordinbeddingsmodel om de datavector te verkrijgen. We kunnen veel initiële woordinsluitingen gebruiken, zoals Woord2vec or Handschoen, maar veel gevorderde gebruikers proberen ze te verfijnen met behulp van hun woordenschat. In basisvorm kan het woord inbeddingsproces in de onderstaande afbeelding worden weergegeven.
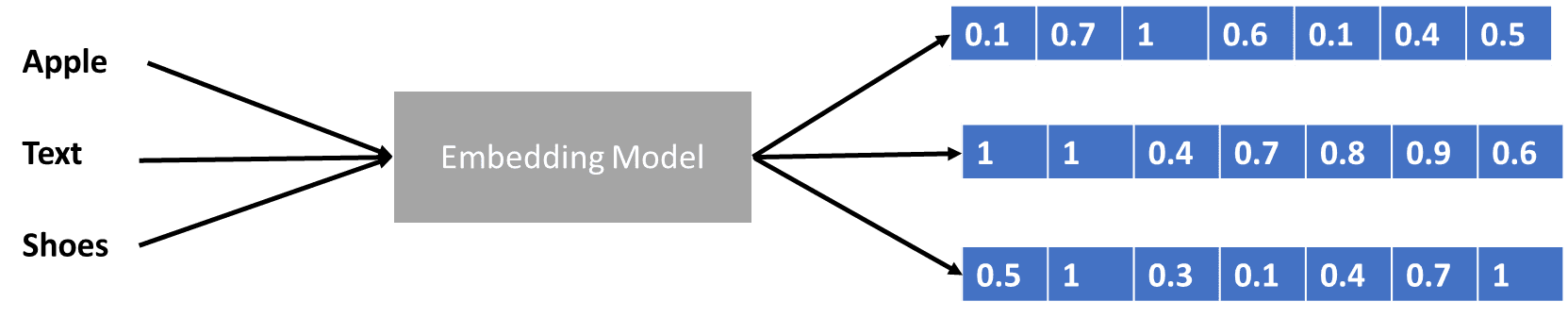
Afbeelding door auteur
De transformatoren zouden de invoer kunnen accepteren en een relevantere context kunnen bieden door de woorden in numerieke vormen te presenteren, zoals de gegevensvector hierboven. In de LLM's zijn woordinsluitingen meestal contextafhankelijk, en worden ze doorgaans verfijnd op basis van de gebruiksscenario's en de beoogde output.
We bespraken het Grote Taalmodel in drie moeilijkheidsgraden, van beginner tot gevorderd. Van het algemene gebruik van LLM tot hoe het is gestructureerd, u kunt een uitleg vinden waarin het concept gedetailleerder wordt uitgelegd.
Cornellius Yudha Wijaya is een data science assistent-manager en dataschrijver. Terwijl hij fulltime bij Allianz Indonesia werkt, deelt hij graag Python- en Data-tips via sociale media en schrijvende media.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/large-language-models-explained-in-3-levels-of-difficulty?utm_source=rss&utm_medium=rss&utm_campaign=large-language-models-explained-in-3-levels-of-difficulty

