In het recente verleden vereiste het gebruik van machine learning (ML) om voorspellingen te doen, vooral voor gegevens in de vorm van tekst en afbeeldingen, uitgebreide ML-kennis voor het creëren en afstemmen van deep learning-modellen. Tegenwoordig is ML toegankelijker geworden voor elke gebruiker die ML-modellen wil gebruiken om bedrijfswaarde te genereren. Met Amazon SageMaker-canvas, kunt u voorspellingen maken voor een aantal verschillende gegevenstypen die verder gaan dan alleen gegevens in tabelvorm of tijdreeksgegevens, zonder ook maar één regel code te schrijven. Deze mogelijkheden omvatten vooraf getrainde modellen voor afbeeldings-, tekst- en documentgegevenstypen.
In dit bericht bespreken we hoe u vooraf getrainde modellen kunt gebruiken om voorspellingen op te halen voor ondersteunde gegevenstypen die verder gaan dan tabelgegevens.
Tekstgegevens
SageMaker Canvas biedt een visuele omgeving zonder code voor het bouwen, trainen en implementeren van ML-modellen. Voor taken op het gebied van natuurlijke taalverwerking (NLP) kan SageMaker Canvas naadloos worden geïntegreerd met Amazon begrijpt het zodat u belangrijke NLP-mogelijkheden kunt uitvoeren, zoals taaldetectie, entiteitsherkenning, sentimentanalyse, onderwerpmodellering en meer. De integratie elimineert de noodzaak van codering of data-engineering om de robuuste NLP-modellen van Amazon Comprehend te gebruiken. U hoeft alleen maar uw tekstgegevens op te geven en te kiezen uit vier veelgebruikte mogelijkheden: sentimentanalyse, taaldetectie, extractie van entiteiten en detectie van persoonlijke informatie. Voor elk scenario kunt u de gebruikersinterface gebruiken om batchvoorspellingen te testen en gegevens te selecteren die zijn opgeslagen in Amazon eenvoudige opslagservice (Amazone S3).
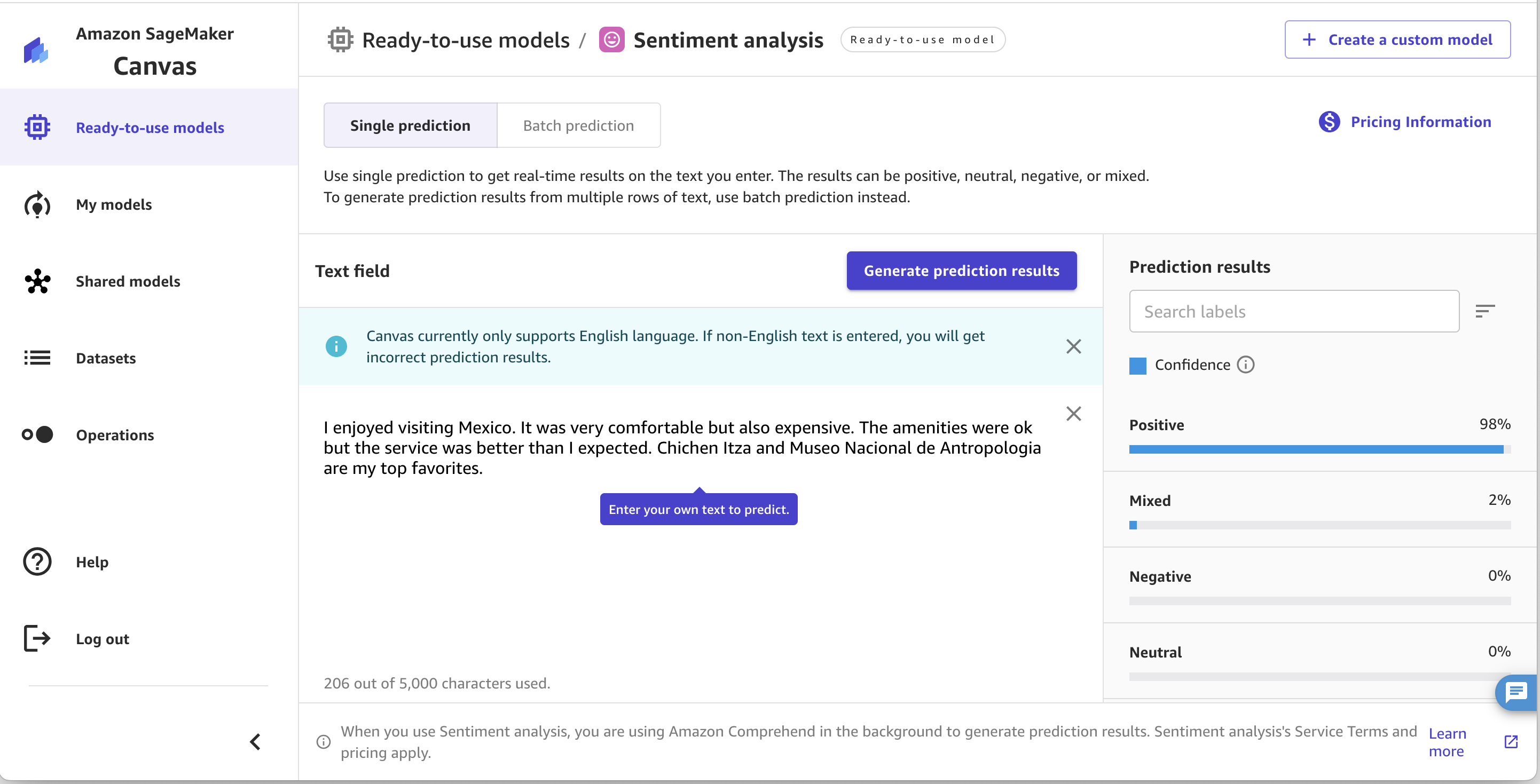
Sentiment analyse
Met sentimentanalyse kunt u met SageMaker Canvas het sentiment van uw invoertekst analyseren. Het kan bepalen of het algehele sentiment positief, negatief, gemengd of neutraal is, zoals weergegeven in de volgende schermafbeelding. Dit is handig in situaties zoals het analyseren van productrecensies. Bijvoorbeeld de tekst "Ik hou van dit product, het is geweldig!" zou door SageMaker Canvas worden geclassificeerd als een product met een positief sentiment, terwijl “Dit product is vreselijk, ik heb er spijt van dat ik het heb gekocht” als een negatief sentiment zou worden bestempeld.
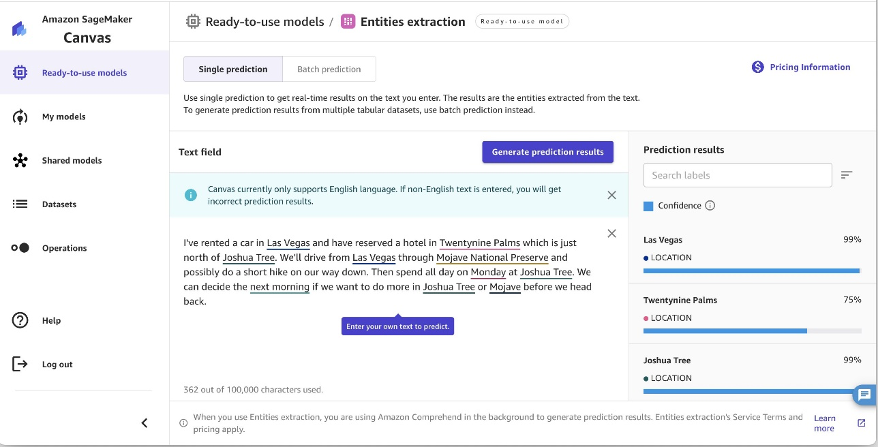
Extractie van entiteiten
SageMaker Canvas kan tekst analyseren en automatisch de daarin genoemde entiteiten detecteren. Wanneer een document voor analyse naar SageMaker Canvas wordt verzonden, worden personen, organisaties, locaties, datums, hoeveelheden en andere entiteiten in de tekst geïdentificeerd. Met deze mogelijkheid om entiteiten te extraheren, kunt u snel inzicht krijgen in de belangrijkste mensen, plaatsen en details die in documenten worden besproken. Raadpleeg voor een lijst met ondersteunde entiteiten Entiteiten.
Taaldetectie
SageMaker Canvas kan ook de dominante teksttaal bepalen met behulp van Amazon Comprehend. Het analyseert tekst om de hoofdtaal te identificeren en geeft betrouwbaarheidsscores voor de gedetecteerde dominante taal, maar geeft geen procentuele uitsplitsingen aan voor meertalige documenten. Voor de beste resultaten met lange documenten in meerdere talen splitst u de tekst in kleinere stukken en voegt u de resultaten samen om de taalpercentages te schatten. Het werkt het beste met minimaal 20 tekens tekst.

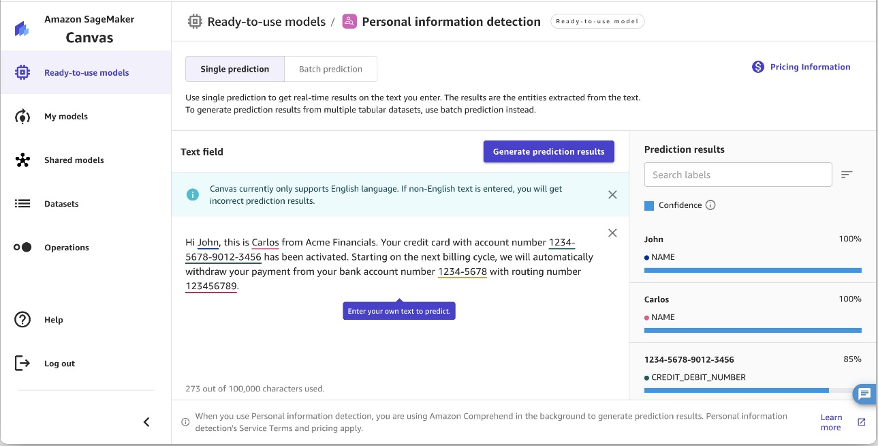
Detectie van persoonlijke informatie
U kunt gevoelige gegevens ook beschermen met behulp van de detectie van persoonlijke informatie met SageMaker Canvas. Het kan tekstdocumenten analyseren om automatisch persoonlijk identificeerbare informatie (PII)-entiteiten te detecteren, zodat u gevoelige gegevens zoals namen, adressen, geboortedata, telefoonnummers, e-mailadressen en meer kunt lokaliseren. Het analyseert documenten tot 100 KB en geeft een betrouwbaarheidsscore voor elke gedetecteerde entiteit, zodat u de meest gevoelige informatie kunt bekijken en selectief kunt redigeren. Voor een lijst met gedetecteerde entiteiten raadpleegt u PII-entiteiten detecteren.
beeldgegevens
SageMaker Canvas biedt een visuele interface zonder code waarmee u eenvoudig computervisiemogelijkheden kunt gebruiken door te integreren met Amazon Rekognition voor beeldanalyse. U kunt bijvoorbeeld een dataset met afbeeldingen uploaden, Amazon Rekognition gebruiken om objecten en scènes te detecteren en tekstdetectie uitvoeren om een breed scala aan gebruiksscenario's aan te pakken. De visuele interface en Amazon Rekognition-integratie maken het voor niet-ontwikkelaars mogelijk om geavanceerde computer vision-technieken te gebruiken.
Objectdetectie in afbeeldingen
SageMaker Canvas gebruikt Amazon Rekognition om labels (objecten) in een afbeelding te detecteren. U kunt de afbeelding uploaden vanuit de gebruikersinterface van SageMaker Canvas of de Batchvoorspelling tabblad om afbeeldingen te selecteren die zijn opgeslagen in een S3-bucket. Zoals in het volgende voorbeeld wordt getoond, kan het objecten uit de afbeelding extraheren, zoals een klokkentoren, bus, gebouwen en meer. U kunt de interface gebruiken om door de voorspellingsresultaten te zoeken en deze te sorteren.

Tekstdetectie in afbeeldingen
Het extraheren van tekst uit afbeeldingen is een veel voorkomende toepassing. Nu kunt u deze taak eenvoudig uitvoeren op SageMaker Canvas, zonder code. De tekst wordt geëxtraheerd als regelitems, zoals weergegeven in de volgende schermafbeelding. Korte zinnen in de afbeelding worden samen geclassificeerd en geïdentificeerd als een zin.
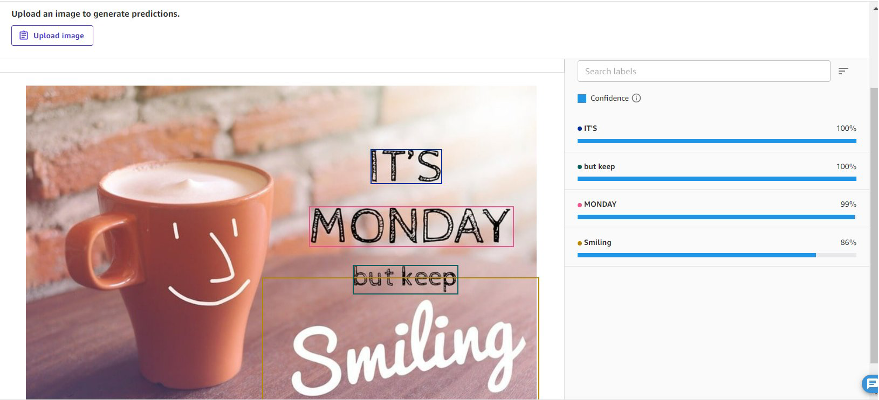
U kunt batchvoorspellingen uitvoeren door een reeks afbeeldingen te uploaden, alle afbeeldingen in één batchtaak te extraheren en de resultaten als CSV-bestand te downloaden. Deze oplossing is handig als u tekst in afbeeldingen wilt extraheren en detecteren.
Documentgegevens
SageMaker Canvas biedt een verscheidenheid aan kant-en-klare oplossingen die aan uw dagelijkse behoeften op het gebied van documentbegrip voldoen. Deze oplossingen worden mogelijk gemaakt door Amazon T-extract. Als u alle beschikbare opties voor documenten wilt bekijken, kiest u voor Kant-en-klare modellen in het navigatievenster en filter op Documenten, zoals weergegeven in de volgende schermafbeelding.
Document analyse
Documentanalyse analyseert documenten en formulieren op relaties tussen gedetecteerde tekst. De bewerkingen retourneren vier categorieën documentextractie: onbewerkte tekst, formulieren, tabellen en handtekeningen. Het vermogen van de oplossing om de documentstructuur te begrijpen, geeft u extra flexibiliteit in het type gegevens dat u uit de documenten wilt halen. De volgende schermafbeelding is een voorbeeld van hoe tabeldetectie eruit ziet.

Deze oplossing kan de lay-outs van complexe documenten begrijpen, wat handig is als u specifieke informatie uit uw documenten wilt extraheren.
Analyse van identiteitsdocumenten
Deze oplossing is ontworpen om documenten zoals persoonlijke identiteitskaarten, rijbewijzen of andere soortgelijke vormen van identificatie te analyseren. Informatie zoals middelste naam, provincie en geboorteplaats, samen met de individuele betrouwbaarheidsscore over de nauwkeurigheid, wordt voor elk identiteitsdocument geretourneerd, zoals weergegeven in de volgende schermafbeelding.

Er is een optie om batchvoorspellingen uit te voeren, waarbij u sets identificatiedocumenten in bulk kunt uploaden en deze als batchtaak kunt verwerken. Dit biedt een snelle en naadloze manier om identificatiedocumentgegevens om te zetten in sleutel-waardeparen die kunnen worden gebruikt voor stroomafwaartse processen zoals gegevensanalyse.
Kostenanalyse
Onkostenanalyse is ontworpen om onkostendocumenten zoals facturen en bonnen te analyseren. De volgende schermafbeelding is een voorbeeld van hoe de geëxtraheerde informatie eruit ziet.
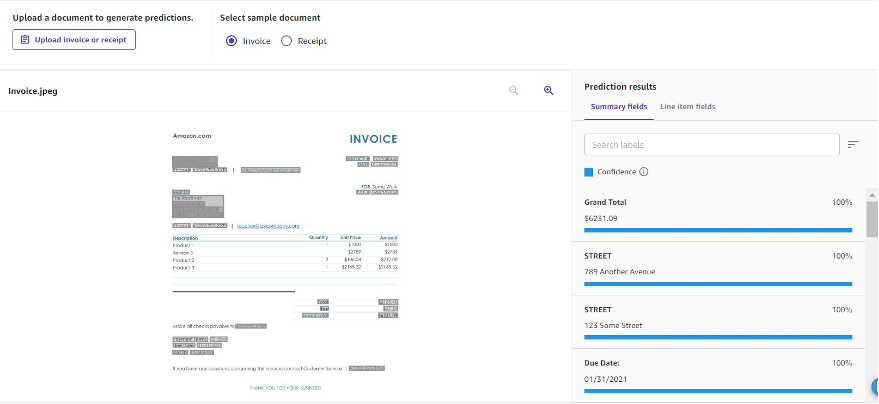
De resultaten worden geretourneerd als overzichtsvelden en regelitemvelden. Samenvattingsvelden zijn sleutel-waardeparen die uit het document worden geëxtraheerd en bevatten sleutels zoals Algemeen totaal, Einddatum en belasting. Regelitemvelden verwijzen naar gegevens die als tabel in het document zijn gestructureerd. Dit is handig om informatie uit het document te extraheren terwijl de lay-out behouden blijft.
Documentquery's
Documentquery's zijn bedoeld om u vragen over uw documenten te laten stellen. Dit is een geweldige oplossing als u documenten met meerdere pagina's heeft en zeer specifieke antwoorden uit uw documenten wilt halen. Hieronder ziet u een voorbeeld van de soorten vragen die u kunt stellen en hoe de daaruit verkregen antwoorden eruitzien.
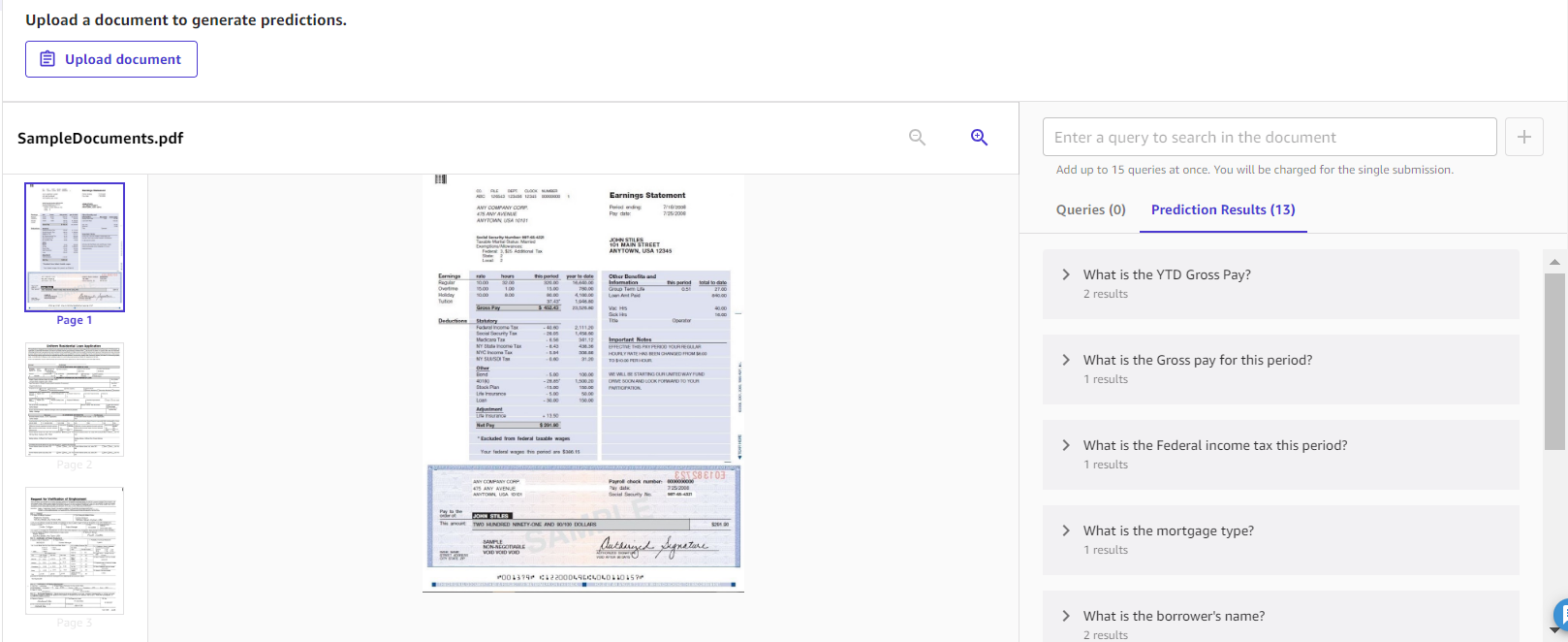
De oplossing biedt een eenvoudige interface waarmee u met uw documenten kunt communiceren. Dit is handig als u specifieke details in grote documenten wilt weergeven.
Conclusie
SageMaker Canvas biedt een codeloze omgeving om ML gemakkelijk te gebruiken voor verschillende gegevenstypen, zoals tekst, afbeeldingen en documenten. De visuele interface en integratie met AWS-services zoals Amazon Comprehend, Amazon Rekognition en Amazon Textract elimineert de behoefte aan codering en data-engineering. U kunt tekst analyseren op sentiment, entiteiten, talen en PII. Voor afbeeldingen maakt object- en tekstdetectie gebruiksscenario's voor computervisie mogelijk. Ten slotte kan documentanalyse tekst extraheren terwijl de lay-out ervan behouden blijft voor verdere processen. De kant-en-klare oplossingen in SageMaker Canvas maken het voor u mogelijk om geavanceerde ML-technieken te gebruiken om inzichten te genereren uit zowel gestructureerde als ongestructureerde data. Als je geïnteresseerd bent in het gebruik van tools zonder code met kant-en-klare ML-modellen, probeer dan vandaag nog SageMaker Canvas. Voor meer informatie, zie Aan de slag met het gebruik van Amazon SageMaker Canvas.
Over de auteurs
 Julia Ang is een oplossingsarchitect gevestigd in Singapore. Ze heeft met klanten op verschillende gebieden gewerkt, van de gezondheidszorg en de publieke sector tot digitale bedrijven, om oplossingen te implementeren die aansluiten bij hun zakelijke behoeften. Ze ondersteunt ook klanten in Zuidoost-Azië en daarbuiten bij het gebruik van AI en ML in hun bedrijf. Buiten haar werk leert ze graag over de wereld door te reizen en zich bezig te houden met creatieve bezigheden.
Julia Ang is een oplossingsarchitect gevestigd in Singapore. Ze heeft met klanten op verschillende gebieden gewerkt, van de gezondheidszorg en de publieke sector tot digitale bedrijven, om oplossingen te implementeren die aansluiten bij hun zakelijke behoeften. Ze ondersteunt ook klanten in Zuidoost-Azië en daarbuiten bij het gebruik van AI en ML in hun bedrijf. Buiten haar werk leert ze graag over de wereld door te reizen en zich bezig te houden met creatieve bezigheden.
 Loke Jun Kai is een Specialist Solutions Architect voor AI/ML, gevestigd in Singapore. Hij werkt samen met klanten in de ASEAN om machine learning-oplossingen op schaal in AWS te ontwerpen. Jun Kai is een voorstander van Low-Code No-Code machine learning-tools. In zijn vrije tijd is hij graag in de natuur.
Loke Jun Kai is een Specialist Solutions Architect voor AI/ML, gevestigd in Singapore. Hij werkt samen met klanten in de ASEAN om machine learning-oplossingen op schaal in AWS te ontwerpen. Jun Kai is een voorstander van Low-Code No-Code machine learning-tools. In zijn vrije tijd is hij graag in de natuur.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/use-machine-learning-without-writing-a-single-line-of-code-with-amazon-sagemaker-canvas/

