Grote taalmodellen (LLM's) kunnen worden gebruikt om complexe documenten te analyseren en samenvattingen en antwoorden op vragen te geven. De post Domeinaanpassing Verfijning van Foundation-modellen in Amazon SageMaker JumpStart op financiële gegevens beschrijft hoe u een LLM kunt verfijnen met uw eigen dataset. Als u eenmaal een solide LLM hebt, wilt u die LLM aan zakelijke gebruikers laten zien om nieuwe documenten te verwerken, die honderden pagina's lang kunnen zijn. In dit bericht laten we zien hoe je een real-time gebruikersinterface kunt bouwen om zakelijke gebruikers een PDF-document van willekeurige lengte te laten verwerken. Zodra het bestand is verwerkt, kunt u het document samenvatten of vragen stellen over de inhoud. De voorbeeldoplossing beschreven in dit bericht is beschikbaar op GitHub.
Werken met financiële documenten
Jaarrekeningen zoals kwartaalcijfers en jaarverslagen aan aandeelhouders zijn vaak tientallen of honderden pagina's lang. Deze documenten bevatten veel standaardtaal, zoals disclaimers en juridisch taalgebruik. Als u de belangrijkste gegevenspunten uit een van deze documenten wilt halen, heeft u zowel tijd als enige vertrouwdheid met de standaardtaal nodig, zodat u de interessante feiten kunt identificeren. En natuurlijk kun je een LLM geen vragen stellen over een document dat het nog nooit heeft gezien.
LLM's die worden gebruikt voor samenvatting hebben een limiet op het aantal tokens (tekens) dat in het model wordt ingevoerd, en op enkele uitzonderingen na zijn dit doorgaans niet meer dan een paar duizend tokens. Dat verhindert normaal gesproken de mogelijkheid om langere documenten samen te vatten.
Onze oplossing behandelt documenten die de maximale tokenreekslengte van een LLM overschrijden, en stelt dat document beschikbaar aan de LLM voor het beantwoorden van vragen.
Overzicht oplossingen
Ons ontwerp heeft drie belangrijke onderdelen:
- Het heeft een interactieve webapplicatie voor zakelijke gebruikers om PDF's te uploaden en te verwerken
- Het gebruikt de langchain-bibliotheek om een grote PDF op te splitsen in beter beheersbare stukken
- Het maakt gebruik van de retrieval augmented generation-techniek om gebruikers vragen te laten stellen over nieuwe gegevens die de LLM nog niet eerder heeft gezien
Zoals te zien is in het volgende diagram, gebruiken we een front-end geïmplementeerd met React JavaScript gehost in een Amazon eenvoudige opslagservice (Amazon S3) emmer voorop Amazon CloudFront. Met de front-end-applicatie kunnen gebruikers PDF-documenten uploaden naar Amazon S3. Nadat het uploaden is voltooid, kunt u een tekstextractietaak activeren, mogelijk gemaakt door Amazon T-extract. Als onderdeel van de nabewerking, een AWS Lambda functie voegt speciale markeringen in de tekst in die paginagrenzen aangeven. Als die klus is geklaard, kun je een API aanroepen die de tekst samenvat of vragen hierover beantwoordt.

Omdat sommige van deze stappen enige tijd in beslag kunnen nemen, gebruikt de architectuur een ontkoppelde asynchrone benadering. De aanroep om een document samen te vatten roept bijvoorbeeld een Lambda-functie op die een bericht naar een Amazon Simple Queue-service (Amazon SQS) wachtrij. Een andere Lambda-functie pikt dat bericht op en start een Amazon Elastic Container-service (Amazone-ECS) AWS Fargate taak. De Fargate-taak roept de Amazon Sage Maker gevolgtrekking eindpunt. We gebruiken hier een Fargate-taak omdat het samenvatten van een zeer lange PDF meer tijd en geheugen kan kosten dan een Lambda-functie beschikbaar heeft. Wanneer de samenvatting klaar is, kan de front-end applicatie de resultaten ophalen van een Amazon DynamoDB tafel.
Voor samenvatting gebruiken we het Summarize-model van AI21, een van de basismodellen die beschikbaar zijn via Amazon SageMaker JumpStart. Hoewel dit model documenten van maximaal 10,000 woorden (ongeveer 40 pagina's) verwerkt, gebruiken we de tekstsplitter van Langchain om ervoor te zorgen dat elke samenvattingsoproep naar de LLM niet langer is dan 10,000 woorden. Voor het genereren van tekst gebruiken we het Medium-model van Cohere en gebruiken we GPT-J voor inbedding, beide via JumpStart.
Samenvattende verwerking
Bij het verwerken van grotere documenten moeten we definiëren hoe het document in kleinere stukken moet worden gesplitst. Wanneer we de resultaten van de tekstextractie terugkrijgen van Amazon Textract, voegen we markeringen in voor grotere stukken tekst (een configureerbaar aantal pagina's), afzonderlijke pagina's en regeleinden. Langchain zal splitsen op basis van die markeringen en kleinere documenten samenstellen die onder de tokenlimiet vallen. Zie de volgende code:
De LLM in de samenvattingsketen is een dun omhulsel rond ons SageMaker-eindpunt:
Vraag beantwoorden
Bij de retrieval augmented generation-methode splitsen we het document eerst op in kleinere segmenten. We maken inbeddingen voor elk segment en slaan deze op in de open-source Chroma-vectordatabase via de interface van langchain. We slaan de database op in een Amazon elastisch bestandssysteem (Amazon EFS) bestandssysteem voor later gebruik. Zie de volgende code:
Als de inbeddingen klaar zijn, kan de gebruiker een vraag stellen. We zoeken in de vectordatabase naar de tekstblokken die het meest overeenkomen met de vraag:
We nemen het meest overeenkomende stuk en gebruiken het als context voor het tekstgeneratiemodel om de vraag te beantwoorden:
User experience
Hoewel LLM's geavanceerde datawetenschap vertegenwoordigen, hebben de meeste use cases voor LLM's uiteindelijk betrekking op interactie met niet-technische gebruikers. Onze voorbeeldwebapplicatie behandelt een interactieve use case waarbij zakelijke gebruikers een nieuw PDF-document kunnen uploaden en verwerken.
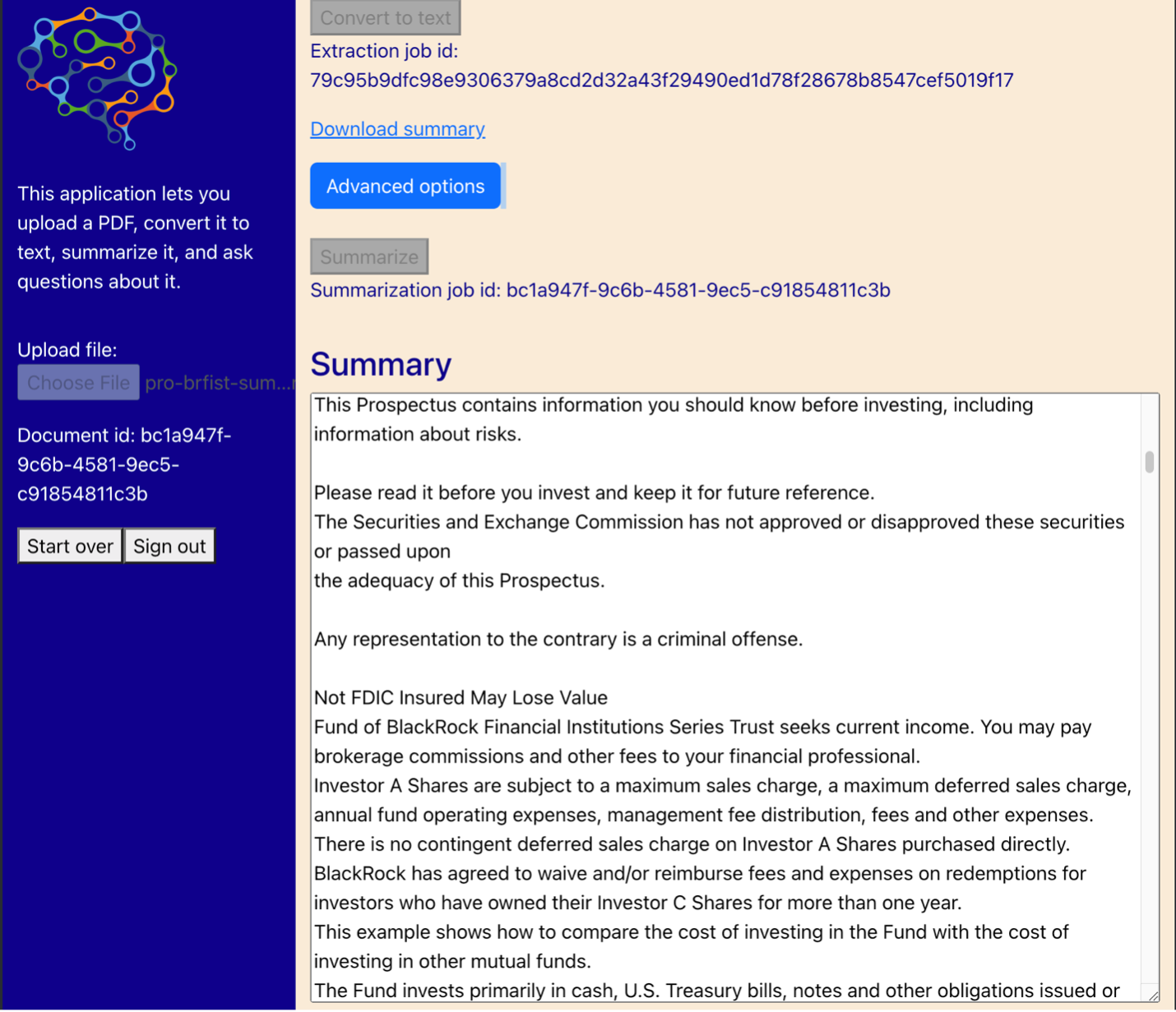
Het volgende diagram toont de gebruikersinterface. Een gebruiker begint met het uploaden van een PDF. Nadat het document is opgeslagen in Amazon S3, kan de gebruiker de tekstextractietaak starten. Wanneer dat is voltooid, kan de gebruiker de samenvattingstaak aanroepen of vragen stellen. De gebruikersinterface geeft een aantal geavanceerde opties weer, zoals de grootte van de stukken en de overlapping van stukken, wat handig zou zijn voor geavanceerde gebruikers die de applicatie testen op nieuwe documenten.
Volgende stappen
LLM's bieden belangrijke nieuwe mogelijkheden voor het ophalen van informatie. Zakelijke gebruikers hebben gemakkelijke toegang tot die mogelijkheden nodig. Er zijn twee richtingen voor toekomstig werk om te overwegen:
- Profiteer van de krachtige LLM's die al beschikbaar zijn in Jumpstart-basismodellen. Met slechts een paar regels code kon onze voorbeeldtoepassing geavanceerde LLM's van AI21 en Cohere inzetten en gebruiken voor het samenvatten en genereren van tekst.
- Maak deze mogelijkheden toegankelijk voor niet-technische gebruikers. Een vereiste voor het verwerken van PDF-documenten is het extraheren van tekst uit het document, en het uitvoeren van samenvattingstaken kan enkele minuten duren. Dat vraagt om een eenvoudige gebruikersinterface met asynchrone backend-verwerkingsmogelijkheden, die eenvoudig te ontwerpen is met behulp van cloud-native services zoals Lambda en Fargate.
We merken ook op dat een PDF-document semi-gestructureerde informatie is. Belangrijke aanwijzingen zoals sectiekoppen zijn programmatisch moeilijk te identificeren, omdat ze afhankelijk zijn van lettergroottes en andere visuele indicatoren. Door de onderliggende structuur van informatie te identificeren, kan de LLM de gegevens nauwkeuriger verwerken, in ieder geval tot het moment dat LLM's invoer van onbegrensde lengte aankunnen.
Conclusie
In dit bericht hebben we laten zien hoe u een interactieve webtoepassing kunt bouwen waarmee zakelijke gebruikers PDF-documenten kunnen uploaden en verwerken voor samenvatting en het beantwoorden van vragen. We hebben gezien hoe u kunt profiteren van Jumpstart-basismodellen om toegang te krijgen tot geavanceerde LLM's, en hoe u technieken voor het splitsen van tekst en het ophalen van augmented generation kunt gebruiken om langere documenten te verwerken en deze beschikbaar te maken als informatie voor de LLM.
Op dit moment is er geen reden om deze krachtige mogelijkheden niet beschikbaar te maken voor uw gebruikers. We raden u aan om te beginnen met het gebruik van de Jumpstart-basismodellen <p></p>
Over de auteur
 Randy DeFauw is Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE van de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft verschillende functies bekleed in de technologiesector, variërend van software-engineering tot productbeheer. In betrad de Big Data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten in de ML-ruimte en heeft op tal van conferenties gepresenteerd, waaronder Strata en GlueCon.
Randy DeFauw is Senior Principal Solutions Architect bij AWS. Hij heeft een MSEE van de Universiteit van Michigan, waar hij werkte aan computervisie voor autonome voertuigen. Hij heeft ook een MBA van de Colorado State University. Randy heeft verschillende functies bekleed in de technologiesector, variërend van software-engineering tot productbeheer. In betrad de Big Data-ruimte in 2013 en blijft dat gebied verkennen. Hij werkt actief aan projecten in de ML-ruimte en heeft op tal van conferenties gepresenteerd, waaronder Strata en GlueCon.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/use-a-generative-ai-foundation-model-for-summarization-and-question-answering-using-your-own-data/

