Grote taalmodellen (LLM's) worden over het algemeen getraind op grote openbaar beschikbare datasets die domein-agnostisch zijn. Bijvoorbeeld, Meta's lama modellen worden getraind op datasets zoals CommonCrawl, C4, Wikipedia, en ArXiv. Deze datasets omvatten een breed scala aan onderwerpen en domeinen. Hoewel de resulterende modellen verbazingwekkend goede resultaten opleveren voor algemene taken, zoals het genereren van tekst en het herkennen van entiteiten, zijn er aanwijzingen dat modellen die zijn getraind met domeinspecifieke datasets de LLM-prestaties verder kunnen verbeteren. Bijvoorbeeld de trainingsgegevens die worden gebruikt voor Bloomberg GPT bestaat voor 51% uit domeinspecifieke documenten, waaronder financieel nieuws, dossiers en ander financieel materiaal. De resulterende LLM presteert beter dan LLM's die zijn getraind op niet-domeinspecifieke datasets wanneer ze worden getest op financiële specifieke taken. De auteurs van Bloomberg GPT concludeerden dat hun model beter presteert dan alle andere geteste modellen voor vier van de vijf financiële taken. Het model presteerde zelfs nog beter toen het werd getest voor de interne financiële taken van Bloomberg, met een ruime marge – maar liefst 60 punten beter (van de 100). Hoewel u meer kunt leren over de uitgebreide evaluatieresultaten in de papier, het volgende monster gevangen uit de Bloomberg GPT paper kan u een glimp geven van de voordelen van het trainen van LLM's met behulp van financiële domeinspecifieke gegevens. Zoals uit het voorbeeld blijkt, leverde het BloombergGPT-model correcte antwoorden op, terwijl andere niet-domeinspecifieke modellen het moeilijk hadden:
Dit bericht biedt een gids voor het trainen van LLM's specifiek voor het financiële domein. Wij behandelen de volgende belangrijke gebieden:
- Gegevensverzameling en voorbereiding – Begeleiding bij het verzamelen en beheren van relevante financiële gegevens voor effectieve modeltraining
- Voortdurende voortraining versus fijnafstemming – Wanneer u elke techniek moet gebruiken om de prestaties van uw LLM te optimaliseren
- Efficiënte voortdurende vooropleiding – Strategieën om het voortdurende pre-trainingsproces te stroomlijnen, waardoor tijd en middelen worden bespaard
Deze post brengt de expertise samen van het toegepaste wetenschappelijke onderzoeksteam binnen Amazon Finance Technology en het AWS Worldwide Specialist-team voor de mondiale financiële sector. Een deel van de inhoud is gebaseerd op het papier Efficiënte, voortdurende vooropleiding voor het bouwen van domeinspecifieke grote taalmodellen.
Het verzamelen en voorbereiden van financiële gegevens
Voor voortdurende voortraining van domeinen is een grootschalige, hoogwaardige, domeinspecifieke dataset nodig. Hieronder volgen de belangrijkste stappen voor het beheer van domeingegevenssets:
- Identificeer gegevensbronnen – Potentiële gegevensbronnen voor domeincorpus zijn onder meer open web, Wikipedia, boeken, sociale media en interne documenten.
- Domeingegevensfilters – Omdat het uiteindelijke doel het beheren van het domeincorpus is, moet u mogelijk extra stappen uitvoeren om voorbeelden eruit te filteren die niet relevant zijn voor het doeldomein. Dit vermindert het nutteloze corpus voor voortdurende voortraining en verlaagt de trainingskosten.
- Voorverwerking – U kunt een reeks voorverwerkingsstappen overwegen om de gegevenskwaliteit en de trainingsefficiëntie te verbeteren. Bepaalde gegevensbronnen kunnen bijvoorbeeld een behoorlijk aantal luidruchtige tokens bevatten; deduplicatie wordt beschouwd als een nuttige stap om de gegevenskwaliteit te verbeteren en de trainingskosten te verlagen.
Om financiële LLM's te ontwikkelen, kunt u twee belangrijke gegevensbronnen gebruiken: News CommonCrawl en SEC-registraties. Een SEC-aanvraag is een financieel overzicht of ander formeel document dat wordt ingediend bij de Amerikaanse Securities and Exchange Commission (SEC). Beursgenoteerde bedrijven zijn verplicht om regelmatig verschillende documenten in te dienen. Hierdoor ontstaat door de jaren heen een groot aantal documenten. Nieuws CommonCrawl is een dataset die in 2016 door CommonCrawl is vrijgegeven. Het bevat nieuwsartikelen van nieuwssites over de hele wereld.
Nieuws CommonCrawl is beschikbaar op Amazon eenvoudige opslagservice (Amazon S3) in de commoncrawl emmer bij crawl-data/CC-NEWS/. U kunt de lijsten met bestanden ophalen met behulp van de AWS-opdrachtregelinterface (AWS CLI) en het volgende commando:
In Efficiënte, voortdurende vooropleiding voor het bouwen van domeinspecifieke grote taalmodellengebruiken de auteurs een op URL's en trefwoorden gebaseerde aanpak om financiële nieuwsartikelen van generiek nieuws te filteren. Concreet houden de auteurs een lijst bij van belangrijke financiële nieuwskanalen en een reeks trefwoorden die verband houden met financieel nieuws. We identificeren een artikel als financieel nieuws als het afkomstig is van financiële nieuwsmedia of als er trefwoorden in de URL voorkomen. Met deze eenvoudige maar effectieve aanpak kunt u financieel nieuws niet alleen van financiële nieuwskanalen identificeren, maar ook van financiële delen van generieke nieuwskanalen.
SEC-documenten zijn online beschikbaar via de EDGAR-database (Electronic Data Gathering, Analysis, and Retrieval) van de SEC, die open toegang tot gegevens biedt. U kunt de dossiers rechtstreeks uit EDGAR schrapen of API's gebruiken Amazon Sage Maker met een paar regels code, voor elke tijdsperiode en voor een groot aantal tickers (dwz de door de SEC toegewezen identificatiecode). Raadpleeg voor meer informatie Ophalen van SEC-archieven.
De volgende tabel vat de belangrijkste details van beide gegevensbronnen samen.
| . | Nieuws CommonCrawl | SEC-archivering |
| Dekking | 2016-2022 | 1993-2022 |
| Maat | 25.8 miljard woorden | 5.1 miljard woorden |
De auteurs doorlopen een paar extra voorbewerkingsstappen voordat de gegevens in een trainingsalgoritme worden ingevoerd. Ten eerste zien we dat SEC-documenten ruis bevatten als gevolg van het verwijderen van tabellen en figuren. Daarom verwijderen de auteurs korte zinnen die worden beschouwd als tabel- of figuurlabels. Ten tweede passen we een plaatsgevoelig hash-algoritme toe om de nieuwe artikelen en documenten te ontdubbelen. Voor SEC-deponeringen ontdubbelen we op sectieniveau in plaats van op documentniveau. Ten slotte voegen we documenten samen tot een lange reeks, tokeniseren we deze en delen we de tokenisatie op in stukken met een maximale invoerlengte die wordt ondersteund door het te trainen model. Dit verbetert de doorvoer van voortdurende voortraining en verlaagt de trainingskosten.
Voortdurende voortraining versus fijnafstemming
De meeste beschikbare LLM's zijn bedoeld voor algemene doeleinden en missen domeinspecifieke vaardigheden. Domein-LLM's hebben aanzienlijke prestaties laten zien op medisch, financieel of wetenschappelijk gebied. Om een LLM domeinspecifieke kennis te laten verwerven, zijn er vier methoden: helemaal opnieuw trainen, voortdurende voortraining, het afstemmen van instructies op domeintaken en Retrieval Augmented Generation (RAG).
In traditionele modellen wordt meestal gebruik gemaakt van fine-tuning om taakspecifieke modellen voor een domein te creëren. Dit betekent dat u meerdere modellen moet onderhouden voor meerdere taken, zoals het extraheren van entiteiten, intentieclassificatie, sentimentanalyse of het beantwoorden van vragen. Met de komst van LLM's is de noodzaak om afzonderlijke modellen te onderhouden overbodig geworden door het gebruik van technieken zoals in-context leren of prompting. Dit bespaart de moeite die nodig is om een stapel modellen bij te houden voor gerelateerde, maar verschillende taken.
Intuïtief kunt u LLM's helemaal opnieuw trainen met domeinspecifieke gegevens. Hoewel het meeste werk om domein-LLM's te creëren zich heeft geconcentreerd op het vanaf het begin opleiden, is het onbetaalbaar. Het GPT-4-model kost bijvoorbeeld meer dan $ 100 miljoen trainen. Deze modellen zijn getraind op een mix van open domeindata en domeindata. Doorlopende voortraining kan modellen helpen domeinspecifieke kennis te verwerven zonder de kosten van een helemaal nieuwe voortraining, omdat u een bestaande LLM met een open domein vooraf traint op alleen de domeingegevens.
Met het afstemmen van instructies op een taak kunt u het model niet domeinkennis laten verwerven, omdat de LLM alleen domeininformatie verkrijgt die is opgenomen in de gegevensset voor het afstemmen van instructies. Tenzij een zeer grote dataset voor het afstemmen van instructies wordt gebruikt, is het niet voldoende om domeinkennis te verwerven. Het verkrijgen van instructiedatasets van hoge kwaliteit is meestal een uitdaging en is de reden om in de eerste plaats LLM's te gebruiken. Ook kan het afstemmen van instructies op één taak de prestaties op andere taken beïnvloeden (zoals te zien in dit papier). Het afstemmen van de instructies is echter kosteneffectiever dan elk van de alternatieven voorafgaand aan de training.
De volgende afbeelding vergelijkt de traditionele taakspecifieke verfijning. versus in-context leerparadigma met LLM's.
 RAG is de meest effectieve manier om een LLM te begeleiden bij het genereren van reacties die op een domein zijn gebaseerd. Hoewel het een model kan begeleiden bij het genereren van antwoorden door feiten uit het domein als aanvullende informatie aan te bieden, verwerft het de domeinspecifieke taal niet omdat de LLM nog steeds vertrouwt op niet-domeintaalstijlen om de antwoorden te genereren.
RAG is de meest effectieve manier om een LLM te begeleiden bij het genereren van reacties die op een domein zijn gebaseerd. Hoewel het een model kan begeleiden bij het genereren van antwoorden door feiten uit het domein als aanvullende informatie aan te bieden, verwerft het de domeinspecifieke taal niet omdat de LLM nog steeds vertrouwt op niet-domeintaalstijlen om de antwoorden te genereren.
Voortdurende vooropleiding is qua kosten een middenweg tussen vooropleiding en verfijning van de instructies, terwijl het een sterk alternatief is voor het opdoen van domeinspecifieke kennis en stijl. Het kan een algemeen model verschaffen waarop verdere fijnafstemming van instructies op beperkte instructiegegevens kan worden uitgevoerd. Voortdurende vooropleiding kan een kosteneffectieve strategie zijn voor gespecialiseerde domeinen waar de set downstream-taken groot of onbekend is en de gelabelde instructie-afstemmingsgegevens beperkt zijn. In andere scenario's kan het afstemmen van instructies of RAG geschikter zijn.
Voor meer informatie over fijnafstemming, RAG en modeltraining raadpleegt u Verfijn een funderingsmodel, Ophalen van Augmented Generation (RAG) en Train een model met Amazon SageMakerrespectievelijk. Voor deze functie richten we ons op een efficiënte, voortdurende vooropleiding.
Methodologie van efficiënte voortdurende vooropleiding
Voortdurende vooropleiding bestaat uit de volgende methodologie:
- Domein-Adaptieve Continue Pre-training (DACP) - In de krant Efficiënte, voortdurende vooropleiding voor het bouwen van domeinspecifieke grote taalmodellen, trainen de auteurs voortdurend de Pythia-taalmodelsuite op het financiële corpus om deze aan te passen aan het financiële domein. Het doel is om financiële LLM's te creëren door gegevens uit het hele financiële domein in een open source-model in te voeren. Omdat het trainingscorpus alle samengestelde datasets in het domein bevat, moet het resulterende model financiële specifieke kennis verwerven, waardoor het een veelzijdig model wordt voor verschillende financiële taken. Dit resulteert in FinPythia-modellen.
- Taakadaptieve continue pre-training (TACP) – De auteurs trainen de modellen vooraf verder op gelabelde en ongelabelde taakgegevens om ze aan te passen aan specifieke taken. In bepaalde omstandigheden kunnen ontwikkelaars de voorkeur geven aan modellen die betere prestaties leveren voor een groep taken binnen het domein, dan aan een domein-generiek model. TACP is ontworpen als voortdurende pre-training met als doel de prestaties bij gerichte taken te verbeteren, zonder vereisten voor gelabelde gegevens. Concreet trainen de auteurs de open source-modellen voortdurend vooraf op de taaktokens (zonder labels). De belangrijkste beperking van TACP ligt in het construeren van taakspecifieke LLM's in plaats van basis-LLM's, vanwege het uitsluitende gebruik van niet-gelabelde taakgegevens voor training. Hoewel DACP een veel groter corpus gebruikt, is het onbetaalbaar. Om deze beperkingen in evenwicht te brengen, stellen de auteurs twee benaderingen voor die tot doel hebben domeinspecifieke basis-LLM's op te bouwen en tegelijkertijd superieure prestaties op doeltaken te behouden:
- Efficiënte taak-vergelijkbare DACP (ETS-DACP) – De auteurs stellen voor om een subset van het financiële corpus te selecteren die sterk lijkt op de taakgegevens, waarbij gebruik wordt gemaakt van het inbedden van gelijkenis. Deze subset wordt gebruikt voor voortdurende voortraining om deze efficiënter te maken. Concreet trainen de auteurs de open source LLM voortdurend voor op een klein corpus dat uit het financiële corpus wordt gehaald en dat dicht bij de doeltaken in de distributie ligt. Dit kan de taakprestaties helpen verbeteren, omdat we het model overnemen voor de distributie van taaktokens, ondanks dat gelabelde gegevens niet vereist zijn.
- Efficiënte taak-agnostische DACP (ETA-DACP) – De auteurs stellen voor om metrieken als perplexiteit en tokentype-entropie te gebruiken, waarvoor geen taakgegevens nodig zijn om steekproeven uit het financiële corpus te selecteren voor een efficiënte, voortdurende voortraining. Deze aanpak is ontworpen om met scenario's om te gaan waarin taakgegevens niet beschikbaar zijn of waarbij meer veelzijdige domeinmodellen voor het bredere domein de voorkeur hebben. De auteurs hanteren twee dimensies bij het selecteren van gegevensmonsters die belangrijk zijn voor het verkrijgen van domeininformatie uit een subset van pre-training domeingegevens: nieuwheid en diversiteit. Nieuwigheid, gemeten aan de hand van de verbijstering vastgelegd door het doelmodel, verwijst naar de informatie die voorheen niet door de LLM werd gezien. Gegevens met een hoge mate van nieuwheid duiden op nieuwe kennis voor de LLM, en dergelijke gegevens worden als moeilijker te leren beschouwd. Hiermee worden generieke LLM's bijgewerkt met intensieve domeinkennis tijdens voortdurende pre-training. Diversiteit daarentegen omvat de diversiteit van distributies van tokentypen in het domeincorpus, wat is gedocumenteerd als een nuttig kenmerk in het onderzoek naar het leren van curricula op het gebied van taalmodellering.
De volgende afbeelding vergelijkt een voorbeeld van ETS-DACP (links) met ETA-DACP (rechts).

We gebruiken twee steekproefschema's om actief gegevenspunten uit het samengestelde financiële corpus te selecteren: harde steekproeven en zachte steekproeven. Het eerste wordt gedaan door eerst het financiële corpus te rangschikken op basis van overeenkomstige statistieken en vervolgens de top-k-steekproeven te selecteren, waarbij k vooraf wordt bepaald op basis van het trainingsbudget. Voor dit laatste kennen de auteurs steekproefgewichten toe aan elk datapunt op basis van de metrische waarden, en bemonsteren ze vervolgens willekeurig k datapunten om aan het trainingsbudget te voldoen.
Resultaat en analyse
De auteurs evalueren de resulterende financiële LLM's voor een reeks financiële taken om de effectiviteit van voortdurende vooropleiding te onderzoeken:
- Financiële taalbank – Een sentimentclassificatietaak over financieel nieuws.
- FiQA SA – Een aspectgebaseerde taak voor sentimentclassificatie op basis van financieel nieuws en krantenkoppen.
- Opschrift – Een binaire classificatietaak die bepaalt of een kop over een financiële entiteit bepaalde informatie bevat.
- NER – Een taak voor het extraheren van financiële entiteiten op basis van het kredietrisicobeoordelingsgedeelte van SEC-rapporten. Woorden in deze taak zijn geannoteerd met PER, LOC, ORG en MISC.
Omdat financiële LLM's op instructie zijn afgestemd, evalueren de auteurs modellen in een 5-shot-setting voor elke taak omwille van de robuustheid. Gemiddeld presteert de FinPythia 6.9B beter dan de Pythia 6.9B met 10% over vier taken, wat de effectiviteit aantoont van domeinspecifieke voortdurende voortraining. Voor het 1B-model is de verbetering minder diepgaand, maar de prestaties verbeteren gemiddeld nog steeds met 2%.
De volgende afbeelding illustreert het prestatieverschil voor en na DACP op beide modellen.

De volgende afbeelding toont twee kwalitatieve voorbeelden gegenereerd door Pythia 6.9B en FinPythia 6.9B. Voor twee financiële vragen over een beleggersmanager en een financiële term begrijpt Pythia 6.9B de term niet en herkent de naam niet, terwijl FinPythia 6.9B gedetailleerde antwoorden correct genereert. De kwalitatieve voorbeelden laten zien dat voortdurende vooropleiding de LLM's in staat stelt om tijdens het proces domeinkennis op te doen.

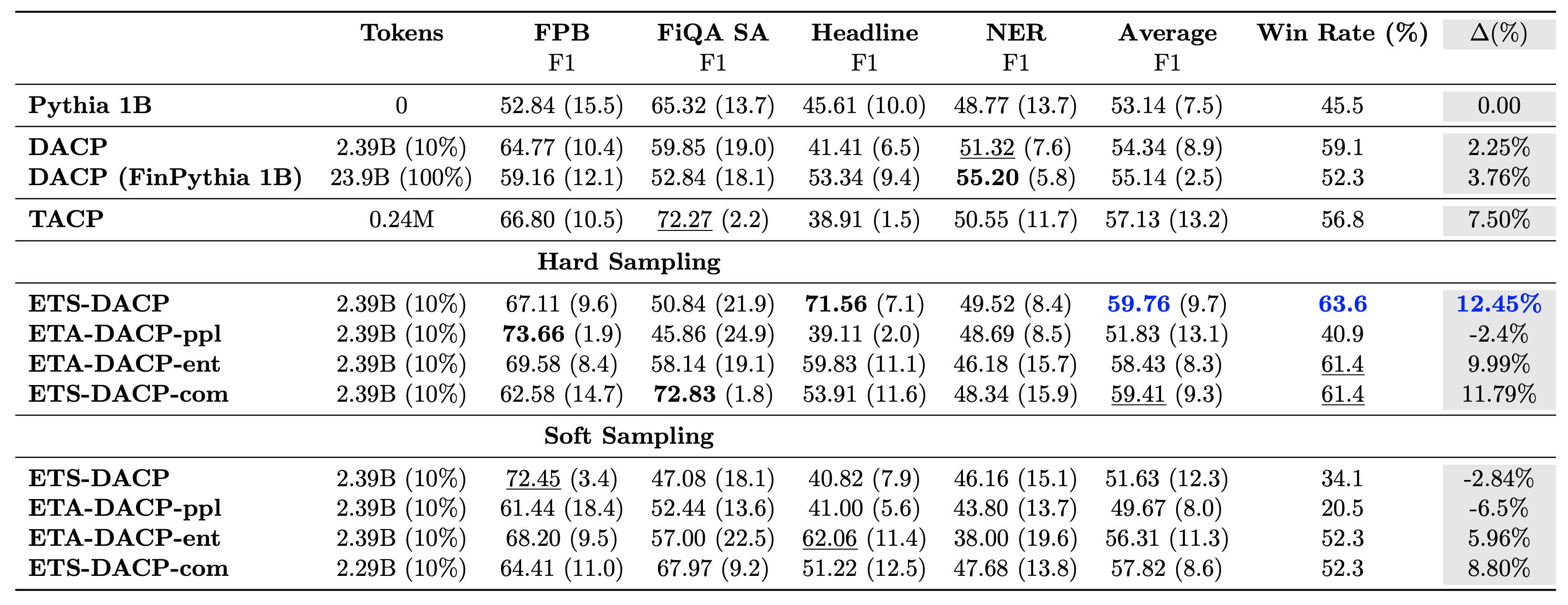
De volgende tabel vergelijkt verschillende efficiënte, voortdurende pre-trainingsbenaderingen. ETA-DACP-ppl is ETA-DACP gebaseerd op verwarring (nieuwigheid), en ETA-DACP-ent is gebaseerd op entropie (diversiteit). ETS-DACP-com is vergelijkbaar met DACP met gegevensselectie door het middelen van alle drie de statistieken. Hieronder volgen enkele conclusies uit de resultaten:
- Methoden voor gegevensselectie zijn efficiënt – Ze overtreffen de standaard continue voortraining met slechts 10% van de trainingsgegevens. Efficiënte, voortdurende voortraining inclusief Task-Similar DACP (ETS-DACP), Task-Agnostic DACP gebaseerd op entropie (ESA-DACP-ent) en Task-Similar DACP gebaseerd op alle drie de statistieken (ETS-DACP-com) presteert beter dan standaard DACP gemiddeld ondanks het feit dat zij slechts op 10% van het financiële corpus zijn opgeleid.
- Taakbewuste dataselectie werkt het beste in lijn met onderzoek naar kleine taalmodellen – ETS-DACP registreert de beste gemiddelde prestatie van alle methoden en registreert, op basis van alle drie de meetgegevens, de op een na beste taakprestatie. Dit suggereert dat het gebruik van ongelabelde taakgegevens nog steeds een effectieve aanpak is om de taakprestaties te verbeteren in het geval van LLM's.
- Taakonafhankelijke dataselectie komt op de tweede plaats – ESA-DACP-ent volgt de prestaties van de taakbewuste benadering van gegevensselectie, wat impliceert dat we de taakprestaties nog steeds kunnen verbeteren door actief monsters van hoge kwaliteit te selecteren die niet aan specifieke taken zijn gebonden. Dit maakt de weg vrij om financiële LLM's voor het hele domein op te bouwen en tegelijkertijd superieure taakprestaties te bereiken.
Een cruciale vraag met betrekking tot voortdurende voortraining is of dit een negatieve invloed heeft op de prestaties bij niet-domeintaken. De auteurs evalueren ook het voortdurend vooraf getrainde model op vier veelgebruikte generieke taken: ARC, MMLU, TruthQA en HellaSwag, die het vermogen van het beantwoorden van vragen, redeneren en voltooien meten. De auteurs zijn van mening dat voortdurende voortraining geen negatieve invloed heeft op de prestaties buiten het domein. Voor meer details, zie Efficiënte, voortdurende vooropleiding voor het bouwen van domeinspecifieke grote taalmodellen.
Conclusie
Dit bericht bood inzicht in het verzamelen van gegevens en voortdurende pre-trainingsstrategieën voor het trainen van LLM's voor het financiële domein. U kunt beginnen met het trainen van uw eigen LLM's voor financiële taken met behulp van Amazon SageMaker-training or Amazonebodem <p></p>
Over de auteurs
 Yong Xie is een toegepast wetenschapper in Amazon FinTech. Hij richt zich op het ontwikkelen van grote taalmodellen en generatieve AI-toepassingen voor de financiële wereld.
Yong Xie is een toegepast wetenschapper in Amazon FinTech. Hij richt zich op het ontwikkelen van grote taalmodellen en generatieve AI-toepassingen voor de financiële wereld.
 Karan Aggarwal is een Senior Applied Scientist bij Amazon FinTech met een focus op generatieve AI voor financiële use-cases. Karan heeft uitgebreide ervaring met tijdreeksanalyse en NLP, met bijzondere interesse in het leren van beperkte gelabelde gegevens
Karan Aggarwal is een Senior Applied Scientist bij Amazon FinTech met een focus op generatieve AI voor financiële use-cases. Karan heeft uitgebreide ervaring met tijdreeksanalyse en NLP, met bijzondere interesse in het leren van beperkte gelabelde gegevens
 Aitzaz Ahmad is Applied Science Manager bij Amazon, waar hij leiding geeft aan een team van wetenschappers die verschillende toepassingen van Machine Learning en Generatieve AI in de financiële wereld bouwen. Zijn onderzoeksinteresses liggen bij NLP, Generatieve AI en LLM Agents. Hij promoveerde in elektrotechniek aan de Texas A&M University.
Aitzaz Ahmad is Applied Science Manager bij Amazon, waar hij leiding geeft aan een team van wetenschappers die verschillende toepassingen van Machine Learning en Generatieve AI in de financiële wereld bouwen. Zijn onderzoeksinteresses liggen bij NLP, Generatieve AI en LLM Agents. Hij promoveerde in elektrotechniek aan de Texas A&M University.
 Qingwei Li is Machine Learning-specialist bij Amazon Web Services. Hij behaalde zijn Ph.D. in Operations Research nadat hij de onderzoeksbeurs van zijn adviseur had verspeeld en er niet in was geslaagd de beloofde Nobelprijs uit te reiken. Momenteel helpt hij klanten in de financiële dienstverlening bij het bouwen van machine learning-oplossingen op AWS.
Qingwei Li is Machine Learning-specialist bij Amazon Web Services. Hij behaalde zijn Ph.D. in Operations Research nadat hij de onderzoeksbeurs van zijn adviseur had verspeeld en er niet in was geslaagd de beloofde Nobelprijs uit te reiken. Momenteel helpt hij klanten in de financiële dienstverlening bij het bouwen van machine learning-oplossingen op AWS.
 Ragvender Arni leidt het Customer Acceleration Team (CAT) binnen AWS Industries. De CAT is een wereldwijd, multifunctioneel team van klantgerichte cloudarchitecten, software-ingenieurs, datawetenschappers en AI/ML-experts en -ontwerpers dat innovatie stimuleert via geavanceerde prototyping, en operationele uitmuntendheid in de cloud stimuleert via gespecialiseerde technische expertise.
Ragvender Arni leidt het Customer Acceleration Team (CAT) binnen AWS Industries. De CAT is een wereldwijd, multifunctioneel team van klantgerichte cloudarchitecten, software-ingenieurs, datawetenschappers en AI/ML-experts en -ontwerpers dat innovatie stimuleert via geavanceerde prototyping, en operationele uitmuntendheid in de cloud stimuleert via gespecialiseerde technische expertise.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

