Introductie
Vectordatabases zijn dé plek geworden voor het opslaan en indexeren van de representaties van ongestructureerde en gestructureerde gegevens. Deze representaties zijn de vectorinbeddingen die worden gegenereerd door de inbeddingsmodellen. De vectorwinkels zijn een integraal onderdeel geworden van het ontwikkelen van apps met Deep Learning Models, vooral de Large Language Models. In het steeds evoluerende landschap van Vector Stores is Qdrant zo'n vectordatabase die onlangs is geïntroduceerd en boordevol functies zit. Laten we erin duiken en er meer over leren.
leerdoelen
- Vertrouwd raken met de Qdrant-terminologieën om deze beter te begrijpen
- Duiken in Qdrant Cloud en clusters creëren
- Leren om inbedding van onze documenten te maken en deze op te slaan in Qdrant Collections
- Onderzoeken hoe de bevraging werkt in Qdrant
- Lekker sleutelen aan de Filtering in Qdrant om te kijken hoe het werkt
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Wat zijn insluitingen?
Vectorinsluitingen zijn een manier om gegevens in numerieke vorm uit te drukken, dat wil zeggen als getallen in een n-dimensionale ruimte, of als een numerieke vector, ongeacht het type gegevens: tekst, foto's, audio, video's, enzovoort. Insluitingen stellen ons in staat om gerelateerde gegevens op deze manier te groeperen. Bepaalde inputs kunnen met behulp van bepaalde modellen in vectoren worden omgezet. Een bekend inbeddingsmodel van Google dat woorden vertaalt in vectoren (vectoren zijn punten met n dimensies) heet Word2Vec. Elk van de grote taalmodellen heeft een inbeddingsmodel dat een inbedding voor de LLM.
Waar worden insluitingen voor gebruikt?
Een voordeel van het vertalen van woorden naar vectoren is dat ze vergelijking mogelijk maken. Wanneer twee woorden als numerieke invoer of vectorinbedding worden gegeven, kan een computer ze vergelijken, ook al kan hij ze niet rechtstreeks vergelijken. Het is mogelijk om woorden met vergelijkbare inbedding te groeperen. Omdat ze aan elkaar gerelateerd zijn, verschijnen de termen Koning, Koningin, Prins en Prinses in een cluster.
In die zin helpen inbedding ons woorden te vinden die verband houden met een bepaalde term. Dit kan worden gebruikt in zinnen, waarbij we een zin invoeren en de aangeleverde gegevens gerelateerde zinnen retourneren. Dit dient als basis voor talloze gebruiksscenario's, waaronder chatbots, zinsgelijkenis, detectie van afwijkingen en semantisch zoeken. De Chatbots die wij ontwikkelen om vragen te beantwoorden op basis van een PDF of document dat wij aanleveren, maken gebruik van deze inbeddingsgedachte. Deze methode wordt door alle generatieve grote taalmodellen gebruikt om inhoud te verkrijgen die op vergelijkbare wijze verband houdt met de zoekopdrachten die aan hen worden geleverd.
Wat zijn vectordatabases?
Zoals besproken, zijn inbeddingen meestal weergaven van elk soort gegevens, de ongestructureerde in het numerieke formaat in een n-dimensionale ruimte. Waar slaan we ze nu op? Traditionele RDMS (Relational Database Management Systems) kunnen niet worden gebruikt om deze vectorinbeddingen op te slaan. Dit is waar de Vector Store / Vector Dabases in het spel komen. Vectordatabases zijn ontworpen om vectorinbeddingen op een efficiënte manier op te slaan en op te halen. Er zijn veel vectorwinkels die verschillen door de inbeddingsmodellen die ze ondersteunen en het soort zoekalgoritme dat ze gebruiken om vergelijkbare vectoren te vinden.
Wat is Qdrant?
Qdrant is de nieuwe Vector Likenity Search Engine en een Vector DB, die een productieklare service biedt, gebouwd in Rust, de taal die bekend staat om zijn veiligheid. Qdrant wordt geleverd met een gebruiksvriendelijke API die is ontworpen voor het opslaan, zoeken en beheren van hoogdimensionale punten (punten zijn niets anders dan vectorinsluitingen), verrijkt met metagegevens die payloads worden genoemd. Deze payloads worden waardevolle stukjes informatie, waardoor de zoekprecisie wordt verbeterd en gebruikers inzichtelijke gegevens krijgen. Als u bekend bent met andere vectordatabases zoals Chroma, is Payload vergelijkbaar met de metadata: het bevat informatie over de vectoren.
Omdat het in Rust is geschreven, is Qdrant een snelle en betrouwbare Vectore Store, zelfs onder zware belasting. Wat Qdrant onderscheidt van de andere databases is het aantal client-API’s dat het biedt. Momenteel ondersteunt Qdrant Python, TypeSciprt/JavaScript, Rust en Go. Het komt met. Qdrant gebruikt HSNW (Hierarchical Navigable Small World Graph) voor vectorindexering en wordt geleverd met veel afstandsstatistieken zoals Cosinus, Dot en Euclidisch. Het wordt standaard geleverd met een aanbevelings-API.
Ken de Qdrant-terminologie
Om een vlotte start met Qdrant te krijgen, is het een goede gewoonte om vertrouwd te raken met de terminologie/de belangrijkste componenten die worden gebruikt in de Qdrant Vector Database.
Collecties
Verzamelingen worden sets van punten genoemd, waarbij elk punt een vector en een optionele ID en payload bevat. Vectoren in dezelfde verzameling moeten dezelfde dimensionaliteit delen en worden geëvalueerd met een enkele gekozen metriek.
Afstandsstatistieken
Essentieel voor het meten van hoe dicht de vectoren bij elkaar zijn, afstandsmetrieken worden geselecteerd tijdens het maken van een verzameling. Qdrant biedt de volgende afstandsmetrieken: punt, cosinus en euclidisch.
Punten
De fundamentele entiteit binnen Qdrant, punten, bestaat uit een vectorinbedding, een optionele ID en een bijbehorende payload, waarbij
id: Een unieke identificatie voor elke vectorinbedding
vector: Een hoogdimensionale weergave van gegevens, die zowel gestructureerde als ongestructureerde formaten kunnen zijn, zoals afbeeldingen, tekst, documenten, pdf's, video's, audio, enz.
laadvermogen: Een optioneel JSON-object dat gegevens bevat die aan een vector zijn gekoppeld. Dit kan worden beschouwd als vergelijkbaar met metadata en we kunnen hiermee werken om het zoekproces te filteren
Opbergen
Qdrant biedt twee opslagmogelijkheden:
- Opslag in het geheugen: slaat alle vectoren op in het RAM-geheugen, waardoor de snelheid wordt geoptimaliseerd door de schijftoegang tot persistentietaken te minimaliseren.
- Memmap-opslag: Creëert een virtuele adresruimte die is gekoppeld aan een bestand op schijf, waarbij snelheid en persistentievereisten in evenwicht worden gebracht.
Dit zijn de belangrijkste concepten waarvan we op de hoogte moeten zijn, zodat we snel aan de slag kunnen met Qdrant
Qdrant Cloud – Ons eerste cluster creëren
Qdrant biedt een schaalbare cloudservice voor het opslaan en beheren van vectoren. Het biedt zelfs een gratis cluster van 1 GB voor altijd zonder creditcardgegevens. In deze sectie doorlopen we het proces van het aanmaken van een account bij Qdrant Cloud en het creëren van ons eerste cluster.
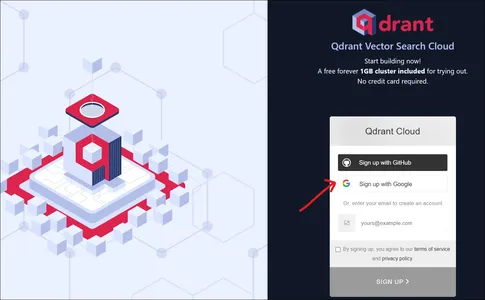
Als we naar de Qdrant-website gaan, zien we een landingspagina zoals hierboven. We kunnen ons aanmelden bij Qdrant met een Google-account of met een GitHub-account.
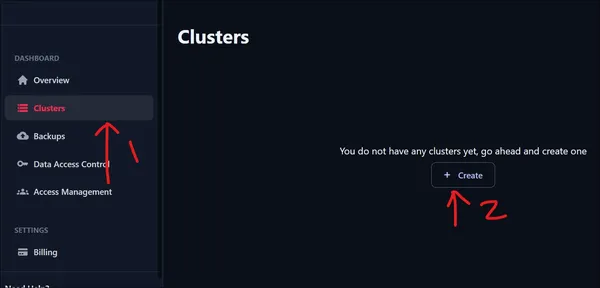
Nadat we zijn ingelogd, krijgen we de hierboven weergegeven gebruikersinterface te zien. Om een cluster te maken, gaat u naar het linkerdeelvenster en klikt u op de optie Clusters onder het Dashboard. Omdat we ons zojuist hebben aangemeld, hebben we nul clusters. Klik op Cluster maken om een nieuw cluster te maken.
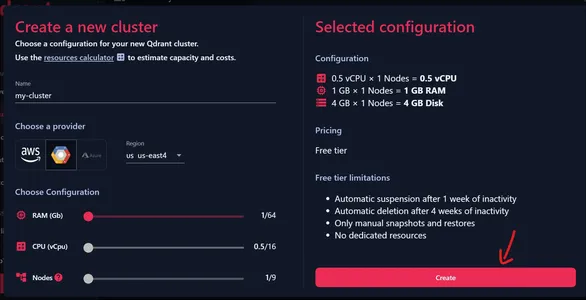
Nu kunnen we een naam voor ons cluster opgeven. Zorg ervoor dat alle configuraties op de startpositie staan, want dit geeft ons een gratis cluster. We kunnen een van de hierboven weergegeven providers kiezen en een van de bijbehorende regio's kiezen.
Controleer de huidige configuratie
We kunnen aan de linkerkant de huidige configuratie zien, dat wil zeggen 0.5 vCPU, 1 GB RAM en 4 GB schijfopslag. Klik op Maken om ons cluster te maken.
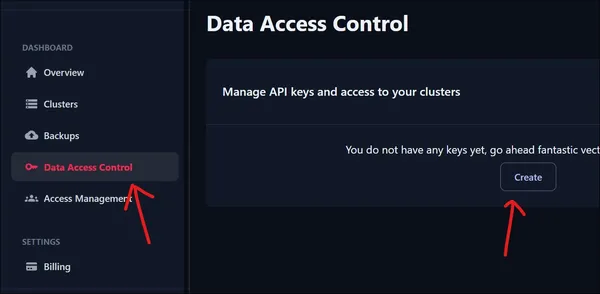
Om toegang te krijgen tot ons nieuw gecreëerde cluster hebben we een API-sleutel nodig. Om een nieuwe API-sleutel te maken, gaat u naar Gegevenstoegangsbeheer onder het Dashboard. Klik op de knop Maken om een nieuwe API-sleutel te maken.

Zoals hierboven weergegeven, krijgen we een vervolgkeuzemenu te zien waarin we selecteren voor welk cluster we de API moeten maken. Omdat we maar één cluster hebben, selecteren we die en klikken op de knop OK.
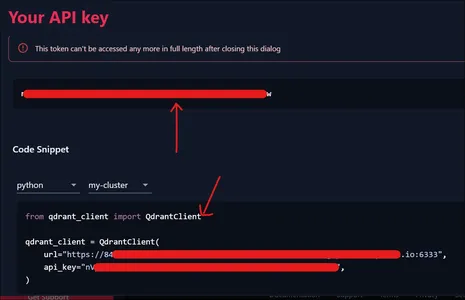
Vervolgens krijgt u het hierboven weergegeven API-token te zien. Ook als we het onderstaande deel van de afbeelding zien, krijgen we zelfs het codefragment om onze Cluster te verbinden, die we in de volgende sectie zullen gebruiken.
Qdrant – Hands-on
In deze sectie gaan we werken met de Qdrant Vector Database. Eerst beginnen we met het importeren van de benodigde bibliotheken.
!pip install sentence-transformers
!pip install qdrant_clientOp de eerste regel wordt de Python-bibliotheek met zinstransformatoren geïnstalleerd. De zinstransformatorbibliotheek wordt gebruikt voor het genereren van insluitingen van zinnen, tekst en afbeeldingen. We kunnen deze bibliotheek gebruiken om verschillende inbeddingsmodellen te importeren om inbedding te creëren. Met de volgende instructie wordt de qdrant-client voor Python geïnstalleerd. Laten we beginnen met het maken van onze client.
from qdrant_client import QdrantClient
client = QdrantClient(
url="YOUR CLUSTER URL",
api_key="YOUR API KEY",
)
QdrantClient
In het bovenstaande instantiëren we de klant door het importeren van de QdrantClient class en geef de Cluster-URL en de API Key die we een tijdje geleden hebben gemaakt. Vervolgens zullen we ons inbeddingsmodel introduceren.
# bringing in our embedding model
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')In de bovenstaande code hebben we de ZinTransformator klasse en instantieerde een model. Het inbeddingsmodel dat we hebben gebruikt is het all-mpnet-base-v2. Dit is een zeer populair vectorinbeddingsmodel voor algemene doeleinden. Dit model neemt tekst op en voert a uit 768 dimensionaal vector. Laten we onze gegevens definiëren.
# data
documents = [
"""Elephants, the largest land mammals, exhibit remarkable intelligence and
social bonds, relying on their powerful trunks for communication and various
tasks like lifting objects and gathering food.""",
""" Penguins, flightless birds adapted to life in the water, showcase strong
social structures and exceptional parenting skills. Their sleek bodies
enable efficient swimming, and they endure
harsh Antarctic conditions in tightly-knit colonies. """,
"""Cars, versatile modes of transportation, come in various shapes and
sizes, from compact city cars to powerful sports vehicles, offering a
range of features for different preferences and needs.""",
"""Motorbikes, nimble two-wheeled machines, provide a thrilling and
liberating riding experience, appealing to enthusiasts who appreciate
speed, agility, and the open road.""",
"""Tigers, majestic big cats, are solitary hunters with distinctive
striped fur. Their powerful build and stealthy movements make them
formidable predators, but their populations are threatened
due to habitat loss and poaching."""
]
In het bovenstaande hebben we een variabele genaamd documenten en deze bevat een lijst van 5 strings (laten we ze allemaal als één enkel document beschouwen). Elke reeks gegevens is gerelateerd aan een bepaald onderwerp. Sommige gegevens hebben betrekking op elementen en sommige gegevens hebben betrekking op auto's. Laten we insluitingen voor de gegevens maken.
# embedding the data
embeddings = model.encode(documents)
print(embeddings.shape)We maken gebruik van de coderen() functie van het modelobject om onze gegevens te coderen. Om te coderen, geven we de documentenlijst rechtstreeks door aan de coderen() functie en sla de resulterende vectorinbedding op in de inbeddingsvariabele. We printen zelfs de vorm van de inbeddingen, die hier worden afgedrukt (5, 768). Dit komt omdat we 5 datapunten hebben, dat wil zeggen 5 documenten, en voor elk document wordt een vectorinbedding van 768 dimensies gemaakt.
Creëer uw collectie
Nu gaan we onze collectie creëren.
from qdrant_client.http.models import VectorParams, Distance
client.create_collection(
collection_name = "my-collection",
vectors_config = VectorParams(size=768,distance=Distance.COSINE)
)
- Om een collectie te maken, werken we met de create_collection() functie van het clientobject en met de “Collectienaam“, geven we onze collectienaam door, dat wil zeggen “mijn-collectie”
- VectorParams: Deze klasse van qdrant is voor vectorconfiguratie, zoals wat de vectorinbeddingsgrootte is, wat de afstandsmetriek is, en dergelijke
- Afstand: Deze klasse van qdrant is om te definiëren welke afstandsmetriek moet worden gebruikt voor het opvragen van vectoren
- Nu naar de vector_config variabele geven we onze configuratie door, dat is de grootte van vectorinbedding, dwz 786, en de afstandsmetriek die we willen gebruiken, namelijk COSINUS
Voeg vectorinsluitingen toe
We hebben nu met succes onze collectie gecreëerd. Nu zullen we onze vectorinsluitingen aan deze collectie toevoegen.
from qdrant_client.http.models import Batch
client.upsert (
collection_name = "my-collection",
points = Batch(
ids = [1,2,3,4,5],
payloads= [
{"category":"animals"},
{"category":"animals"},
{"category":"automobiles"},
{"category":"automobiles"},
{"category":"animals"}
],
vectors = embeddings.tolist()
)
)
- Om gegevens aan qdrant toe te voegen noemen we de opsteken() methode en geef de collectienaam en punten door. Zoals we hierboven hebben geleerd, is a punt bestaat uit vectoren, een optionele index en payloads. De Partij Met Class from qdrant kunnen we gegevens in batches toevoegen in plaats van ze één voor één toe te voegen.
- ids: We geven onze documenten een identiteitsbewijs. Momenteel geven we een bereik van waarden van 1 tot 5 omdat we 5 documenten op onze lijst hebben.
- ladingen: Zoals we eerder hebben gezien, de laadvermogen bevat informatie over de vectoren, zoals metadata. We bieden het aan in sleutel-waardeparen. Voor elk document hebben we een laadvermogen hier wijzen we de categorie-informatie toe voor elk document.
- vectoren: Dit zijn de vectorinsluitingen van de documenten. We converteren het naar een lijst vanuit een numpy-array en voeren deze in.
Dus na het uitvoeren van deze code worden de vectorinsluitingen toegevoegd aan de collectie. Om te controleren of ze zijn toegevoegd, kunnen we het clouddashboard bezoeken dat de Qdrant Cloud biedt. Daarvoor doen wij het volgende:
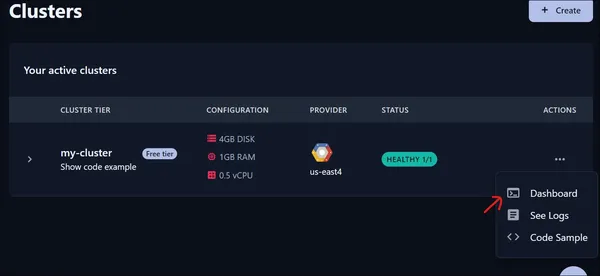
We klikken op het dashboard en er wordt een nieuwe pagina geopend.
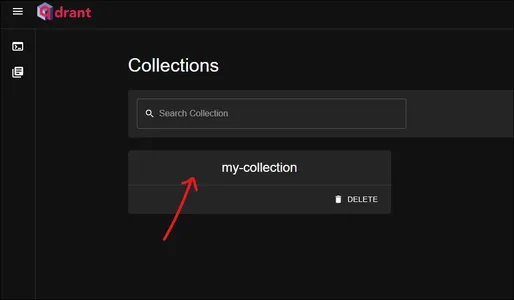
Dit is het qdrant-dashboard. Bekijk onze “mijn collectie”collectie hier. Klik erop om te zien wat erin zit.

In de Qdrant-cloud zien we dat onze punten (vectoren + payload + ID's) inderdaad worden toegevoegd aan onze verzameling binnen onze cluster. In het vervolggedeelte zullen we leren hoe we deze vectoren kunnen bevragen.
De Qdrant Vector-database opvragen
In deze sectie zullen we de vectordatabase doorzoeken en zelfs proberen enkele filters toe te voegen om een gefilterd resultaat te krijgen. Om onze qdrant-vectordatabase te doorzoeken, moeten we eerst een queryvector maken, wat we kunnen doen door:
query = model.encode(['Animals live in the forest'])Query-insluiting
Het volgende zal onze creëren vraag inbedden. Met behulp hiervan zullen we onze vectorwinkel doorzoeken om de meest relevante vectorinbedding te verkrijgen.
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 4
)
Zoekopdracht
Voor het opvragen gebruiken we de zoeken() methode van het clientobject en geef het volgende door:
- Collectienaam: De naam van onze collectie
- vraag_vector: De zoekvector waarop we het vectorarchief willen doorzoeken
- begrenzing: Hoeveel zoekresultaten willen we hebben zoeken() functie om ook te beperken
Het uitvoeren van de code levert de volgende uitvoer op:
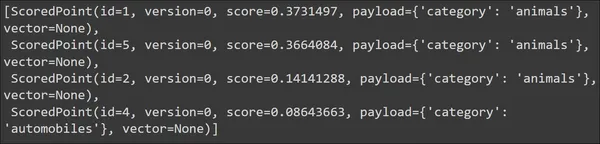
We zien dat voor onze zoekopdracht de best gevonden documenten van de categorie dieren zijn. We kunnen dus zeggen dat de zoektocht effectief is. Laten we het nu proberen met een andere zoekopdracht, zodat deze andere resultaten oplevert. De vectoren worden standaard niet weergegeven/opgehaald en daarom ingesteld op Geen.
query = model.encode(['Vehicles are polluting the world'])
client.search(
collection_name = "my-collection",
query_vector = query[0],
limit = 3
)

Zoekopdracht gerelateerd aan voertuigen
Deze keer hebben we een gegeven vraag gerelateerd aan voertuigen de vectordatabase kon met succes de documenten van de relevante Categorie (auto) bovenaan ophalen. Wat als we nu wat willen filteren? Dit kunnen wij doen door:
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
query = model.encode(['Animals live in the forest'])
custom_filter = Filter(
must = [
FieldCondition(
key = "category",
match = MatchValue(
value="animals"
),
)
]
)
- Ten eerste maken we onze query embedding/vector
- Hier importeren we de FILTER, Veldvoorwaarde en Matchwaarde lessen uit de qdrant-bibliotheek.
- FILTER: Gebruik deze klasse om een Filter-object te maken
- FiledConditie: Deze klasse is bedoeld voor het maken van filters, zoals waarop we onze zoekopdracht willen filteren
- Matchwaarde: Deze klasse is bedoeld om aan te geven welke waarde voor een bepaalde sleutel we door de qdrant vector db willen laten filteren
Dus in de bovenstaande code zeggen we eigenlijk dat we een FILTER dat controleert de Veldvoorwaarde dat de sleutel “categorie" in de payload wedstrijden(Matchwaarde) de waarde "dieren”. Dit ziet er een beetje groot uit voor een eenvoudig filter, maar deze aanpak zal onze code meer gestructureerd maken als we te maken hebben met a payload bevat veel informatie en we willen op meerdere sleutels filteren. Laten we nu het filter gebruiken in onze zoekopdracht.
client.search(
collection_name = "my-collection",
query_vector = query[0],
query_filter = custom_filter,
limit = 4
)
Query_filter
Deze keer geven we hier zelfs een query_filter variabele die de Aangepast filter die wij hebben gedefinieerd. Houd er rekening mee dat we een limiet van 4 hebben aangehouden om de top 4 overeenkomende documenten op te halen. De vraag heeft betrekking op dieren. Het uitvoeren van de code resulteert in de volgende uitvoer:

In de uitvoer hebben we alleen de top 3 dichtstbijzijnde documenten ontvangen, ook al hebben we 5 documenten. Dit komt omdat we ons filter zo hebben ingesteld dat alleen de diercategorieën worden gekozen en er slechts 3 documenten met die categorie zijn. Op deze manier kunnen we de vectorinsluitingen opslaan in de qdrant-wolk, vectorzoekopdrachten uitvoeren op deze inbeddingsvectoren, de dichtstbijzijnde vectoren ophalen en zelfs filters toepassen om de uitvoer te filteren:
Toepassingen
De volgende toepassingen kunnen Qdrant Vector Database gebruiken:
- Aanbevelingssystemen: Qdrant kan aanbevelingsmotoren aandrijven door efficiënt hoog-dimensionale vectoren te matchen, waardoor het geschikt is voor gepersonaliseerde inhoudsaanbevelingen op platforms zoals streamingdiensten, e-commerce of sociale media.
- Ophalen van afbeeldingen en multimedia: Door gebruik te maken van de mogelijkheden van Qdrant om vectoren te verwerken die afbeeldingen en multimedia-inhoud vertegenwoordigen, kunnen applicaties effectieve zoek- en ophaalfunctionaliteiten implementeren voor beelddatabases of multimedia-archieven.
- Toepassingen voor natuurlijke taalverwerking (NLP): De ondersteuning van Qdrant voor vectorinbedding maakt het waardevol voor NLP-taken, zoals semantisch zoeken, het matchen van documentovereenkomsten en inhoudsaanbevelingen in toepassingen die omgaan met grote hoeveelheden tekstuele datasets.
- Onregelmatigheidsdetectie: Qdrant's hoogdimensionale vectorzoekopdracht kan worden gebruikt in anomaliedetectiesystemen. Door vectoren die normaal gedrag vertegenwoordigen te vergelijken met binnenkomende gegevens, kunnen afwijkingen worden geïdentificeerd op terreinen als netwerkbeveiliging of industriële monitoring.
- Product zoeken en matchen: Op e-commerceplatforms kan Qdrant de zoekmogelijkheden voor producten verbeteren door vectoren te matchen die productkenmerken vertegenwoordigen, waardoor nauwkeurige en efficiënte productaanbevelingen mogelijk worden gemaakt op basis van gebruikersvoorkeuren.
- Op inhoud gebaseerd filteren in sociale netwerken: De vectorzoekopdracht van Qdrant kan worden toegepast in sociale netwerken voor op inhoud gebaseerde filtering. Gebruikers kunnen relevante inhoud krijgen op basis van de gelijkenis van vectorrepresentaties, waardoor de gebruikersbetrokkenheid wordt verbeterd.
Conclusie
Naarmate de vraag naar een efficiënte weergave van gegevens groeit, onderscheidt Qdrant zich als een open source-zoekmachine voor vectorgelijkenis boordevol functies, geschreven in de robuuste en op veiligheid gerichte taal Rust. Qdrant bevat alle populaire afstandsstatistieken en biedt een robuuste manier om onze vectorzoekopdracht te filteren. Met zijn rijke functies, cloud-native architectuur en robuuste terminologie opent Qdrant deuren naar een nieuw tijdperk in zoektechnologie voor vectorgelijkenis. Ook al is het nieuw op dit gebied, het biedt clientbibliotheken voor veel programmeertalen en biedt een cloud die efficiënt meegroeit met de omvang.
Key Takeaways
Enkele van de belangrijkste afhaalrestaurants zijn:
- Qdrant is vervaardigd in Rust en garandeert zowel snelheid als betrouwbaarheid, zelfs onder zware belasting, waardoor het de beste keuze is voor krachtige vectorwinkels.
- Wat Qdrant onderscheidt is de ondersteuning voor client-API's, gericht op ontwikkelaars in Python, TypeScript/JavaScript, Rust en Go.
- Qdrant maakt gebruik van het HSNW-algoritme en geeft verschillende afstandsstatistieken, waaronder Dot, Cosine en Euclidische, waardoor ontwikkelaars de statistiek kunnen kiezen die aansluit bij hun specifieke gebruiksscenario's.
- Qdrant gaat naadloos over naar de cloud met een schaalbare cloudservice, die een free-tier optie voor verkenning biedt. De cloud-native architectuur zorgt voor optimale prestaties, ongeacht het datavolume.
Veelgestelde Vragen / FAQ
A: Qdrant is een vectorgelijkeniszoekmachine en vectorwinkel geschreven in Rust. Het valt op door zijn snelheid, betrouwbaarheid en rijke clientondersteuning en biedt API's voor Python, TypeScript/JavaScript, Rust en Go.
A: Qdrant gebruikt het HSNW-algoritme en geeft verschillende afstandsmetrieken zoals Dot, Cosinus en Euclidisch. Ontwikkelaars kunnen bij het maken van collecties de statistiek kiezen die aansluit bij hun specifieke gebruiksscenario's.
A: Belangrijke componenten zijn onder meer verzamelingen, afstandsstatistieken, punten (vectoren, optionele ID's en payloads) en opslagopties (in het geheugen en Memmap).
A: Ja, Qdrant integreert naadloos met clouddiensten en biedt zo een schaalbare cloudoplossing. De cloud-native architectuur zorgt voor optimale prestaties, waardoor deze kan worden aangepast aan variërende datavolumes en computerbehoeften.
A: Qdrant maakt filteren op payload-informatie mogelijk. Gebruikers kunnen filters definiëren met behulp van de Qdrant-bibliotheek, door voorwaarden op te geven op basis van payload-sleutels en -waarden om de zoekresultaten te verfijnen.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/11/a-deep-dive-into-qdrant-the-rust-based-vector-database/

