Recente ontwikkelingen in de ontwikkeling van LLM's hebben het gebruik ervan voor diverse NLP-taken gepopulariseerd die voorheen werden aangepakt met behulp van oudere machine learning-methoden. Grote taalmodellen zijn in staat een verscheidenheid aan taalproblemen op te lossen, zoals classificatie, samenvatten, het ophalen van informatie, het maken van inhoud, het beantwoorden van vragen en het onderhouden van een gesprek – allemaal met behulp van slechts één enkel model. Maar hoe weten we dat ze goed werk leveren bij al deze verschillende taken?
De opkomst van LLM's heeft een onopgelost probleem aan het licht gebracht: we hebben geen betrouwbare standaard om ze te evalueren. Wat de evaluatie moeilijker maakt, is dat ze voor zeer uiteenlopende taken worden gebruikt en dat het ons ontbreekt aan een duidelijke definitie van wat een goed antwoord is voor elke gebruikssituatie.
Dit artikel bespreekt de huidige benaderingen voor het evalueren van LLM's en introduceert een nieuw LLM-leaderboard dat gebruik maakt van menselijke evaluatie en een verbetering is van bestaande evaluatietechnieken.
De eerste en gebruikelijke initiële vorm van evaluatie is om het model op verschillende samengestelde datasets uit te voeren en de prestaties ervan te onderzoeken. HuggingFace heeft een LLM-klassement openen waar open-access grote modellen worden geëvalueerd met behulp van vier bekende datasets (AI2 Redeneer-uitdaging , HellaSwag , MMLU , waarheidsgetrouwe QA). Dit komt overeen met automatische evaluatie en controleert het vermogen van het model om de feiten voor bepaalde specifieke vragen te achterhalen.
Dit is een voorbeeld van een vraag uit de MMLU gegevensset.
Onderwerp: universiteitsgeneeskunde
Vraag: Een verwachte bijwerking van creatinesuppletie is.
- A) spierzwakte
- B) winst in lichaamsmassa
- C) spierkrampen
- D) verlies van elektrolyten
Antwoord: (B)
Het scoren van het model op het beantwoorden van dit soort vragen is een belangrijke maatstaf en dient goed voor het controleren van feiten, maar het test niet het generatieve vermogen van het model. Dit is waarschijnlijk het grootste nadeel van deze evaluatiemethode, omdat het genereren van vrije tekst een van de belangrijkste kenmerken van LLM's is.
Er lijkt een consensus te bestaan binnen de gemeenschap dat we, om het model goed te kunnen evalueren, menselijke evaluatie nodig hebben. Dit wordt doorgaans gedaan door de antwoorden van verschillende modellen te vergelijken.
Vergelijking van twee promptvoltooiingen in het LMSYS-project – screenshot door de auteur
Annotators beslissen welk antwoord beter is, zoals te zien is in het bovenstaande voorbeeld, en kwantificeren soms het verschil in kwaliteit van de snelle voltooiingen. LMSYS Org heeft een leaderboard dat dit soort menselijke evaluatie gebruikt en 17 verschillende modellen vergelijkt, en rapporteert Elo-beoordeling voor elk model.
Omdat menselijke evaluatie moeilijk op te schalen kan zijn, zijn er pogingen ondernomen om het evaluatieproces op te schalen en te versnellen en dit resulteerde in een interessant project genaamd AlpacaEval. Hier wordt elk model vergeleken met een basislijn (text-davinci-003 geleverd door GPT-4) en wordt menselijke evaluatie vervangen door GPT-4-oordeel. Dit is inderdaad snel en schaalbaar, maar kunnen we erop vertrouwen dat het model hier de score uitvoert? We moeten ons bewust zijn van modelvooroordelen. Het project heeft feitelijk aangetoond dat GPT-4 de voorkeur kan geven aan langere antwoorden.
LLM-evaluatiemethoden blijven zich ontwikkelen terwijl de AI-gemeenschap zoekt naar gemakkelijke, eerlijke en schaalbare benaderingen. De nieuwste ontwikkeling komt van het team van Toloka met een nieuwe leaderboard om de huidige evaluatienormen verder te bevorderen.
De nieuwe leaderboard vergelijkt modelreacties met echte gebruikersprompts die zijn gecategoriseerd op basis van nuttige NLP-taken, zoals beschreven in dit InstructGPT-papier. Het toont ook het algemene winstpercentage van elk model in alle categorieën.
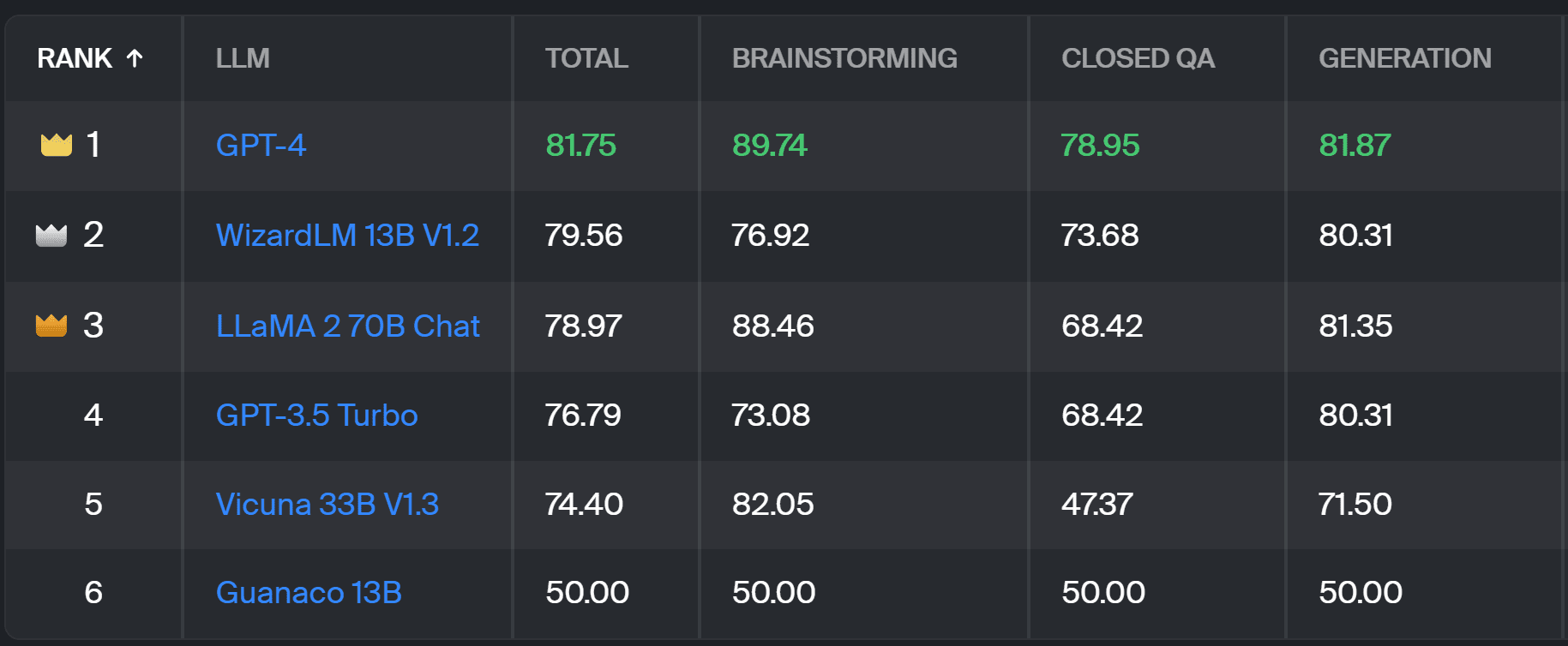
Toloka-klassement – screenshot door de auteur
De evaluatie die voor dit project wordt gebruikt, is vergelijkbaar met die in AlpacaEval. De scores op het scorebord vertegenwoordigen het winstpercentage van het betreffende model in vergelijking met de Guanaco 13B model, dat hier als basisvergelijking dient. De keuze voor Guanaco 13B is een verbetering van de AlpacaEval-methode, die het binnenkort verouderde tekst-davinci-003-model als basis gebruikt.
De daadwerkelijke evaluatie wordt gedaan door menselijke deskundige annotators op basis van een reeks echte aanwijzingen. Voor elke prompt krijgen annotators twee aanvullingen en wordt gevraagd welke hun voorkeur heeft. U kunt details over de methodologie vinden hier.
Dit type menselijke evaluatie is nuttiger dan welke andere automatische evaluatiemethode dan ook en zou een verbetering moeten zijn ten opzichte van de menselijke evaluatie die voor de evaluatie wordt gebruikt LMSYS-klassement. Het nadeel van de LMSYS-methode is dat iedereen met de link kunnen deelnemen aan de evaluatie, wat serieuze vragen oproept over de kwaliteit van de op deze manier verzamelde gegevens. Een besloten groep deskundige annotators heeft een beter potentieel voor betrouwbare resultaten, en Toloka past aanvullende kwaliteitscontroletechnieken toe om de gegevenskwaliteit te garanderen.
In dit artikel hebben we een veelbelovende nieuwe oplossing geïntroduceerd voor het evalueren van LLM's: het Toloka Leaderboard. De aanpak is innovatief, combineert de sterke punten van bestaande methoden, voegt taakspecifieke granulariteit toe en maakt gebruik van betrouwbare menselijke annotatietechnieken om de modellen te vergelijken.
Verken het bord en deel uw mening en suggesties voor verbeteringen met ons.
Magdalena Konkiewicz is Data Evangelist bij Toloka, een wereldwijd bedrijf dat snelle en schaalbare AI-ontwikkeling ondersteunt. Ze heeft een masterdiploma in kunstmatige intelligentie behaald aan de Universiteit van Edinburgh en heeft gewerkt als NLP-ingenieur, ontwikkelaar en datawetenschapper voor bedrijven in Europa en Amerika. Ze is ook betrokken geweest bij het lesgeven en begeleiden van datawetenschappers en draagt regelmatig bij aan publicaties over datawetenschap en machine learning.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.kdnuggets.com/a-better-way-to-evaluate-llms?utm_source=rss&utm_medium=rss&utm_campaign=a-better-way-to-evaluate-llms

