Introductie
Taalmodellen gebaseerd op grootschalige pre-training LLM's hebben een revolutie teweeggebracht op het gebied van natuurlijke taalverwerking. Dit stelt machines in staat om mensachtige tekst met opmerkelijke nauwkeurigheid te begrijpen en te genereren. Om de mogelijkheden van LLM's echt te waarderen, is het essentieel om diep in hun innerlijke werking te duiken en de fijne kneepjes van hun architectuur te begrijpen. Door de mysteries achter de taalmodelarchitectuur van LLM's te ontrafelen, kunnen we waardevolle inzichten verkrijgen in hoe deze modellen taal verwerken en genereren, wat de weg vrijmaakt voor taalbegrip, tekstgeneratie en vooruitgang in informatie-extractie.
In deze blog duiken we diep in de innerlijke werking van LLM's en ontdekken we de magie die hen in staat stelt taal te begrijpen en te genereren op een manier die de mogelijkheden van mens-machine-interactie voor altijd heeft veranderd.
leerdoelen
- Begrijp de fundamentele componenten van LLM's, inclusief transformatoren en mechanismen voor zelfaandacht.
- Verken de gelaagde architectuur van LLM's, bestaande uit encoders en decoders.
- Krijg inzicht in de pre-trainings- en finetuning-fasen van LLM-training.
- Ontdek recente ontwikkelingen in LLM-architecturen, zoals GPT-3, T5 en BERT.
- Krijg een uitgebreid begrip van aandachtsmechanismen en hun betekenis in LLM's.
Dit artikel is gepubliceerd als onderdeel van de Data Science Blogathon.
Meer informatie: Wat zijn grote taalmodellen (LLM's)?
Inhoudsopgave
De fundamenten van LLM's: transformatoren en mechanismen voor zelfaandacht
Stap in de basis van LLM's, waar transformatoren en mechanismen voor zelfaandacht de bouwstenen vormen waarmee deze modellen taal met uitzonderlijke bekwaamheid kunnen begrijpen en genereren.
transformers
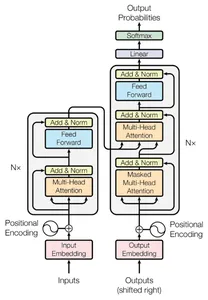
transformers voor het eerst geïntroduceerd in het document "Attention is All You Need" door Vaswani et al. in 2017, een revolutie op het gebied van natuurlijke taalverwerking. Deze robuuste architecturen elimineren de noodzaak van terugkerende neurale netwerken (RNN's) en in plaats daarvan vertrouwen op mechanismen voor zelfaandacht om relaties tussen woorden in een invoerreeks vast te leggen.
Transformers stellen LLM's in staat om tekst parallel te verwerken, waardoor een efficiënter en effectiever taalbegrip mogelijk wordt. Door gelijktijdig aandacht te besteden aan alle woorden in een invoerreeks, vangen transformatoren langeafstandsafhankelijkheden en contextuele relaties op die een uitdaging kunnen zijn voor traditionele modellen. Deze parallelle verwerking stelt LLM's in staat om ingewikkelde patronen en afhankelijkheden uit tekst te extraheren, wat leidt tot een beter begrip van taalsemantiek.
Zelf Aandacht
Als we dieper graven, komen we het concept van zelfaandacht tegen, dat de kern vormt van op transformator gebaseerde architecturen. Door zelfaandacht kunnen LLM's zich concentreren op verschillende delen van de invoerreeks bij het verwerken van elk woord.
Tijdens zelfaandacht kennen LLM's aandachtsgewichten toe aan verschillende woorden op basis van hun relevantie voor het huidige woord dat wordt verwerkt. Deze dynamiek aandachtsmechanisme stelt LLM's in staat om cruciale contextuele informatie bij te wonen en irrelevante of luidruchtige invoeronderdelen te negeren.
Door selectief aandacht te besteden aan relevante woorden, kunnen LLM's effectief afhankelijkheden vastleggen en zinvolle informatie extraheren, waardoor hun taalbegrip wordt verbeterd.
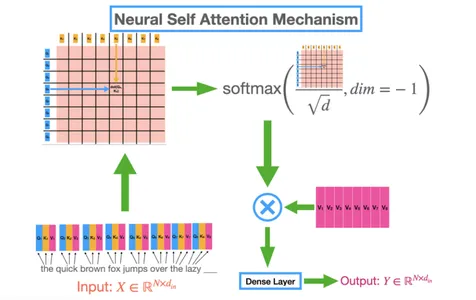
Het zelfaandachtsmechanisme stelt transformatoren in staat om het belang van elk woord in de context van de gehele invoerreeks te overwegen. Bijgevolg kunnen afhankelijkheden tussen woorden efficiënt worden vastgelegd, ongeacht de afstand. Dit vermogen is waardevol voor het begrijpen van genuanceerde betekenissen, het behouden van samenhang en het genereren van contextueel relevante antwoorden.
Lagen, encoders en decoders
Binnen de architectuur van LLM's is een complex tapijt geweven met meerdere lagen encoders en decoders, die elk een cruciale rol spelen in het taalbegrip en het generatieproces. Deze lagen vormen een hiërarchische structuur die LLMs in staat stelt om de nuances en fijne kneepjes van taal geleidelijk vast te leggen.
encoder
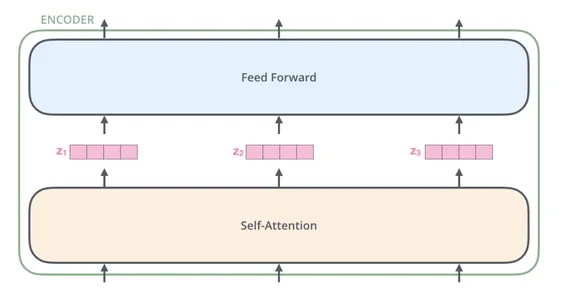
De kern van dit tapijt zijn de encoderlagen. Encoders analyseren en verwerken de invoertekst en extraheren betekenisvolle representaties die de essentie van de taal vastleggen. Deze representaties coderen cruciale informatie over de semantiek, syntaxis en context van de input. Door de invoertekst op meerdere lagen te analyseren, leggen encoders zowel lokale als globale afhankelijkheden vast, waardoor LLM's de fijne kneepjes van taal kunnen begrijpen.
Decoder
Terwijl de gecodeerde informatie door de lagen stroomt, bereikt deze de decodercomponenten. Decoders genereren coherente en contextueel relevante antwoorden op basis van de gecodeerde representaties. De decoders gebruiken de gecodeerde gegevens om het volgende woord te voorspellen of een reeks termen te creëren die een betekenisvol antwoord vormen. LLM's verfijnen en verbeteren hun reactiegeneratie met elke decoderlaag, waarbij de context en informatie uit de invoertekst wordt opgenomen.

Door de hiërarchische structuur van LLM's kunnen ze de nuances van taal laag voor laag begrijpen. Op elke laag verfijnen encoders en decoders het begrip en de generatie van tekst, waardoor steeds complexere relaties en context worden vastgelegd. De lagere lagen leggen kenmerken op een lager niveau vast, zoals semantiek op woordniveau, terwijl hogere lagen meer abstracte en contextuele informatie vastleggen. Deze hiërarchische benadering stelt LLM's in staat om coherente, contextueel geschikte en semantisch rijke antwoorden te genereren.
De gelaagde architectuur van LLM's maakt niet alleen het extraheren van betekenis en context uit invoertekst mogelijk, maar maakt het ook mogelijk reacties te genereren die verder gaan dan alleen woordassociaties. Door het samenspel tussen encoders en decoders in meerdere lagen kunnen LLM's de fijnmazige details van taal vastleggen, inclusief syntactische structuren, semantische relaties en zelfs nuances van toon en stijl.
Aandacht in de kern, contextueel begrip mogelijk maken
Taalmodellen hebben enorm geprofiteerd van aandachtsmechanismen, waardoor de manier waarop we taalbegrip benaderen, is veranderd. Laten we eens kijken naar de transformerende rol van aandachtsmechanismen in taalmodellen en hun bijdrage aan contextueel bewustzijn.
De kracht van aandacht
Aandachtsmechanismen in taalmodellen zorgen voor een dynamisch en contextbewust begrip van taal. Traditionele taalmodellen, zoals n-gram-modellen, behandelen woorden als geïsoleerde eenheden zonder rekening te houden met hun relaties binnen een zin of document.
Aandachtsmechanismen daarentegen stellen LM's in staat verschillende gewichten toe te kennen aan verschillende woorden, waardoor hun relevantie binnen de gegeven context wordt vastgelegd. Door zich te concentreren op essentiële termen en irrelevante termen te negeren, helpen aandachtsmechanismen taalmodellen om de onderliggende betekenis van een tekst nauwkeuriger te begrijpen.
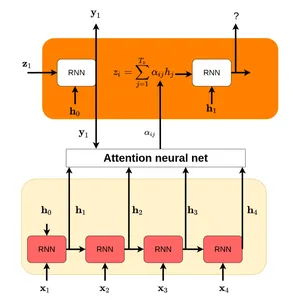
Gewogen relevantie
Een van de cruciale voordelen van aandachtsmechanismen is hun vermogen om verschillende gewichten toe te kennen aan verschillende woorden in een zin. Bij het verwerken van een opmerking berekent het taalmodel de relevantie ervan voor andere woorden in de context door rekening te houden met hun semantische en syntactische relaties.
Bijvoorbeeld, in de zin "De kat zat op de mat", zou het taalmodel dat aandachtsmechanismen gebruikt, hogere gewichten toekennen aan "kat" en "mat" omdat ze relevanter zijn voor de actie van het zitten. Deze gewogen relevantie stelt het taalmodel in staat prioriteit te geven aan de meest opvallende informatie terwijl irrelevante details worden genegeerd, wat resulteert in een beter begrip van de context.
Modellering van afhankelijkheden op lange afstand
Taal omvat vaak afhankelijkheden die zich uitstrekken over meerdere woorden of zelfs zinnen. Aandachtsmechanismen blinken uit in het vastleggen van deze langeafstandsafhankelijkheden, waardoor LM's het taalweefsel naadloos kunnen verbinden. Door aandacht te besteden aan verschillende delen van de invoerreeks, kunnen taalmodellen leren betekenisvolle verbanden te leggen tussen woorden die ver uit elkaar staan in een zin.
Deze mogelijkheid is waardevol bij taken zoals machinevertaling, waar het behouden van de samenhang en het begrijpen van de context over langere afstanden cruciaal is.
Pre-training en finetuning: de kracht van data ontketenen
Taalmodellen beschikken over een uniek trainingsproces dat hen in staat stelt om taal met vaardigheid te begrijpen en te genereren. Dit proces bestaat uit twee hoofdfasen: pre-training en finetuning. We zullen de geheimen achter deze stadia verkennen en ontrafelen hoe LLM's de kracht van data ontketenen om taalmeesters te worden.
Vooraf getrainde transformatoren gebruiken
import torch
from transformers import TransformerModel, AdamW # Load the pretrained Transformer model
pretrained_model_name = 'bert-base-uncased'
pretrained_model = TransformerModel.from_pretrained(pretrained_model_name) # Example input
input_ids = torch.tensor([[1, 2, 3, 4, 5]]) # Get the output from the pretrained model
outputs = pretrained_model(input_ids) # Access the last hidden states or pooled output
last_hidden_states = outputs.last_hidden_state
pooled_output = outputs.pooler_output
Scherpstellen
Zodra LLM's een algemeen begrip van taal hebben verworven door middel van vooropleiding, gaan ze de fase van verfijning in, waar ze worden toegesneden op specifieke taken of domeinen. Finetuning omvat het blootstellen van LLM's aan gelabelde gegevens die specifiek zijn voor de gewenste taak, zoals sentimentanalyse of het beantwoorden van vragen. Met deze gelabelde gegevens kunnen LLM's hun vooraf opgeleide kennis aanpassen aan de specifieke nuances en vereisten van de taak.
Tijdens de finetuning verfijnen LLM's hun taalbegrip en generatiemogelijkheden, waarbij ze zich specialiseren in domeinspecifieke taalpatronen en contextuele nuances. Door te trainen op gelabelde gegevens krijgen LLM's een beter begrip van de complexiteit van de specifieke taak, waardoor ze nauwkeurigere en contextueel relevante antwoorden kunnen geven.
Fijnafstelling van de transformator
import torch
from transformers import TransformerModel, AdamW # Load the pretrained Transformer model
pretrained_model_name = 'bert-base-uncased'
pretrained_model = TransformerModel.from_pretrained(pretrained_model_name) # Modify the pretrained model for a specific downstream task
pretrained_model.config.num_labels = 2 # Number of labels for the task # Example input
input_ids = torch.tensor([[1, 2, 3, 4, 5]])
labels = torch.tensor([1]) # Define the fine-tuning optimizer and loss function
optimizer = AdamW(pretrained_model.parameters(), lr=1e-5)
loss_fn = torch.nn.CrossEntropyLoss() # Fine-tuning loop
for epoch in range(num_epochs): # Forward pass outputs = pretrained_model(input_ids) logits = outputs.logits # Compute loss loss = loss_fn(logits.view(-1, 2), labels.view(-1)) # Backward pass and optimization optimizer.zero_grad() loss.backward() optimizer.step() # Print the loss for monitoring print(f"Epoch {epoch+1}/{num_epochs} - Loss: {loss.item():.4f}")
Het mooie van dit tweetraps trainingsproces ligt in het vermogen om de kracht van data te benutten. Pre-training op grote hoeveelheden niet-gelabelde tekstgegevens geeft LLM's een algemeen begrip van taal, terwijl het verfijnen van gelabelde gegevens hun kennis voor specifieke taken verfijnt. Deze combinatie stelt LLM's in staat om een brede kennisbasis te bezitten en tegelijkertijd uit te blinken in bepaalde domeinen, wat opmerkelijk taalbegrip en generatievermogen biedt.
Vooruitgang in moderne architectuur buiten LLM's
De recente vorderingen in taalmodelarchitecturen die verder gaan dan traditionele LLM, tonen de opmerkelijke mogelijkheden van modellen zoals GPT-3, T5 en BERT. We zullen onderzoeken hoe deze modellen de grenzen van taalbegrip en -generatie hebben verlegd, waardoor nieuwe mogelijkheden in verschillende domeinen zijn ontstaan.
GPT-3
GPT-3, generatieve vooraf getrainde transformator, is naar voren gekomen als een baanbrekende taalmodelarchitectuur, die een revolutie teweegbrengt in het begrijpen en genereren van natuurlijke taal. De architectuur van GPT-3 is gebaseerd op het Transformer-model en bevat veel parameters om uitzonderlijke prestaties te bereiken.
De architectuur van GPT-3
GPT-3 bestaat uit een stapel Transformer-encoderlagen. Elke laag bestaat uit multi-head zelfaandachtsmechanismen en feed-forward neurale netwerken. Het aandachtsmechanisme stelt het model in staat om afhankelijkheden en relaties tussen woorden vast te leggen, terwijl de feed-forward-netwerken de gecodeerde representaties verwerken en transformeren. De belangrijkste innovatie van GPT-3 ligt in zijn enorme omvang, met maar liefst 175 miljard parameters, waardoor het enorme taalkennis kan vastleggen.

Code Implementatie
U kunt de OpenAI API gebruiken om te communiceren met het GPT-3-model van openAI. Hier is een illustratie van het gebruik van GPT-3 om tekst te genereren.
import openai # Set up your OpenAI API credentials
openai.api_key = 'YOUR_API_KEY' # Define the prompt for text generation
prompt = "" # Make a request to GPT-3 for text generation
response = openai.Completion.create( engine="text-davinci-003", prompt=prompt, max_tokens=100, temperature=0.6
) # Retrieve the generated text from the API response
generated_text = response.choices[0].text # Print the generated text
print(generated_text)
T5
Text-to-Text Transfer Transformer, of T5, vertegenwoordigt een baanbrekende vooruitgang in taalmodelarchitecturen. Het vereist een uniforme benadering van verschillende natuurlijke taalverwerkingstaken door ze te kaderen als tekst-naar-tekst-transformaties. Deze benadering stelt een enkel model in staat om meerdere taken uit te voeren, waaronder tekstclassificatie, samenvatting en het beantwoorden van vragen.
Door de taakspecifieke architecturen te verenigen in één enkel model, bereikt T5 indrukwekkende prestaties en efficiëntie, waardoor het modelontwikkelings- en implementatieproces wordt gestroomlijnd.
De architectuur van T5
T5 is gebouwd op de Transformer-architectuur, bestaande uit een encoder-decoderstructuur. In tegenstelling tot traditionele modellen die zijn afgestemd op specifieke taken, wordt T5 getraind met behulp van een multi-task-doelstelling waarbij een diverse reeks functies wordt gegoten als tekst-naar-tekst-transformaties. Tijdens de training leert het model om een tekstinvoer toe te wijzen aan een tekstuitvoer, waardoor het zeer flexibel is en in staat is om een breed scala aan NLP-taken uit te voeren, waaronder tekstclassificatie, samenvatting, vertaling en meer.

Code Implementatie
De transformatorbibliotheek, die een eenvoudige interface biedt voor interactie met verschillende transformatormodellen, waaronder T5, kan het T5-model in Python gebruiken. Hier is een illustratie van het gebruik van T5 om tekst-naar-tekst-taken uit te voeren.
from transformers import T5Tokenizer, T5ForConditionalGeneration tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small") input_ids = tokenizer("translate English to German: The house is wonderful.", return_tensors="pt").input_ids # Generate the translation using T5 outputs = model.generate(input_ids) # Print the generated text
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
BERT
BERT, bidirectionele encoderrepresentaties van transformatoren, introduceerde een revolutionaire verschuiving in taalbegrip. Door gebruik te maken van bidirectionele training, vangt BERT de context van zowel de linker- als de rechtercontext, waardoor een beter begrip van taalsemantiek mogelijk wordt.
BERT heeft de prestaties aanzienlijk verbeterd in taken zoals herkenning van benoemde entiteiten, sentimentanalyse en natuurlijke taalinferentie. Het vermogen om de nuances van taal te begrijpen met een fijnmazig contextueel begrip heeft het tot een hoeksteen gemaakt in de moderne verwerking van natuurlijke taal.
De architectuur van BERT
BERT bestaat uit een stapel transformatorencoderlagen. Het maakt gebruik van bidirectionele training, waardoor het model context van zowel de linker- als de rechtercontext kan vastleggen. Deze bidirectionele benadering biedt een dieper begrip van taalsemantiek. Het stelt BERT ook in staat om uit te blinken in taken zoals herkenning van benoemde entiteiten, sentimentanalyse, het beantwoorden van vragen en meer. BERT bevat ook unieke tokens, waaronder [CLS] voor classificatie en [SEP] om zinnen te scheiden of grenzen te documenteren
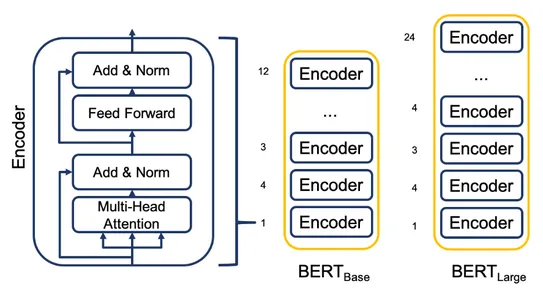
Code Implementatie
De bibliotheek met transformatoren biedt een eenvoudige interface voor interactie met verschillende transformatormodellen. Het bevat ook BERT en kan worden gebruikt in Python. Hier is een illustratie van het gebruik van BERT om taalbegrip uit te voeren.
from transformers import BertTokenizer, BertForSequenceClassification # Load the BERT model and tokenizer
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased') # Define the input text
input_text = "Hello, my dog is cute" # Tokenize the input text and convert into Pytorch tensor
input_ids = tokenizer.encode(input_text, add_special_tokens=True)
input_tensors = torch.tensor([input_ids]) # Make the model prediction
outputs = model(input_tensors) # Print the predicted label
print("Predicted label:", torch.argmax(outputs[0]).item())
Conclusie
De innerlijke werking van LLM's onthult een geavanceerde architectuur. Hierdoor kunnen deze modellen taal begrijpen en genereren met een ongeëvenaarde nauwkeurigheid en veelzijdigheid.
Elk onderdeel is cruciaal bij het begrijpen en genereren van taal, van transformatoren en mechanismen voor zelfaandacht tot gelaagde encoders en decoders. Terwijl we de geheimen achter de architectuur van LLM's ontrafelen, krijgen we een diepere waardering voor hun capaciteiten en potentieel voor het transformeren van verschillende industrieën.
Key Takeaways:
- LLM's, aangedreven door transformatoren en mechanismen voor zelfaandacht, hebben een revolutie teweeggebracht in de verwerking van natuurlijke taal. Dit stelt machines in staat om mensachtige tekst met opmerkelijke nauwkeurigheid te begrijpen en te genereren.
- De gelaagde architectuur van LLM's omvat encoders en decoders. Dit maakt het mogelijk om betekenis en context uit de invoertekst te halen, wat leidt tot het genereren van coherente en contextueel relevante antwoorden.
- Pre-training en finetuning zijn cruciale fasen in het trainingsproces van LLM's. Pre-training stelt modellen in staat om algemeen taalbegrip te verwerven uit niet-gelabelde tekstgegevens, terwijl de fijnafstemming de modellen afstemt op specifieke taken met behulp van gelabelde gegevens, waardoor hun kennis en specialisatie worden verfijnd.
Veelgestelde Vragen / FAQ
A. LLM's, of taalmodellen gebaseerd op grootschalige pre-training, zijn geavanceerde modellen die zijn getraind op grote hoeveelheden tekstgegevens. Dankzij hun geavanceerde architectuur en trainingsproces verschillen ze van traditionele taalmodellen in hun vermogen om tekst met opmerkelijke nauwkeurigheid te begrijpen en te genereren.
A. Transformers vormen de kern van de LLM-architectuur en maken parallelle verwerking en vastlegging van complexe relaties in taal mogelijk. Ze brachten een revolutie teweeg op het gebied van natuurlijke taalverwerking door het vermogen van de modellen om tekst te begrijpen en te genereren te verbeteren.
A. Mechanismen voor zelfaandacht stellen LLM's in staat verschillende gewichten toe te kennen aan verschillende woorden, waardoor hun relevantie binnen de context wordt vastgelegd. Ze stellen de modellen in staat zich te concentreren op relevante informatie en de contextuele relaties tussen woorden te begrijpen.
A. Pre-training stelt LLM's bloot aan enorme hoeveelheden niet-gelabelde tekstgegevens, waardoor ze algemeen taalbegrip kunnen verwerven. Finetuning stemt de modellen af op specifieke taken met behulp van gelabelde gegevens, waardoor hun kennis en specialisatie worden verfijnd. Dit trainingsproces in twee fasen verbetert hun prestaties in verschillende domeinen.
A. De interne werking van LLM's heeft een revolutie teweeggebracht in verschillende industrieën, waaronder begrip van natuurlijke taal, sentimentanalyse, taalvertaling en meer. Ze hebben nieuwe mogelijkheden geopend voor mens-machine-interactie, geautomatiseerde contentgeneratie en verbeterde systemen voor het ophalen van informatie. De inzichten die zijn verkregen door het begrijpen van de LLM-architectuur blijven de vooruitgang in de verwerking van natuurlijke taal stimuleren.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. Automotive / EV's, carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- BlockOffsets. Eigendom voor milieucompensatie moderniseren. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/07/inner-workings-of-llms/

