Vergelijkbare kolommen zoeken in a data lake heeft belangrijke toepassingen bij het opschonen en annoteren van gegevens, het matchen van schema's, het ontdekken van gegevens en het analyseren van meerdere gegevensbronnen. Het onvermogen om nauwkeurig gegevens uit ongelijksoortige bronnen te vinden en te analyseren, vormt een potentiële efficiëntiemoordenaar voor iedereen, van datawetenschappers, medische onderzoekers, academici tot financiële en overheidsanalisten.
Conventionele oplossingen omvatten zoeken op lexicale trefwoorden of het matchen van reguliere expressies, die vatbaar zijn voor problemen met de gegevenskwaliteit, zoals ontbrekende kolomnamen of verschillende conventies voor kolomnaamgeving in diverse datasets (bijvoorbeeld zip_code, zcode, postalcode).
In dit bericht demonstreren we een oplossing voor het zoeken naar vergelijkbare kolommen op basis van kolomnaam, kolominhoud of beide. De oplossing gebruikt geschatte algoritmen voor de naaste buren beschikbaar in Amazon OpenSearch-service om te zoeken naar semantisch vergelijkbare kolommen. Om het zoeken te vergemakkelijken, maken we representaties van kenmerken (inbeddingen) voor individuele kolommen in het datameer met behulp van vooraf getrainde Transformer-modellen uit de zin-transformatoren bibliotheek in Amazon Sage Maker. Ten slotte bouwen we een interactief Gestroomlijnd webapplicatie draait AWS Fargate.
We omvatten een code-tutorial zodat u de middelen kunt inzetten om de oplossing uit te voeren op voorbeeldgegevens of uw eigen gegevens.
Overzicht oplossingen
Het volgende architectuurdiagram illustreert de werkstroom in twee fasen voor het vinden van semantisch vergelijkbare kolommen. De eerste etappe loopt een AWS Stap Functies workflow die insluitingen maakt van kolommen in tabelvorm en de zoekindex van OpenSearch Service opbouwt. De tweede fase, of de online inferentiefase, voert een Streamlit-toepassing uit via Fargate. De webtoepassing verzamelt ingevoerde zoekopdrachten en haalt uit de OpenSearch Service-index de kolommen bij benadering die het meest op de k lijken.
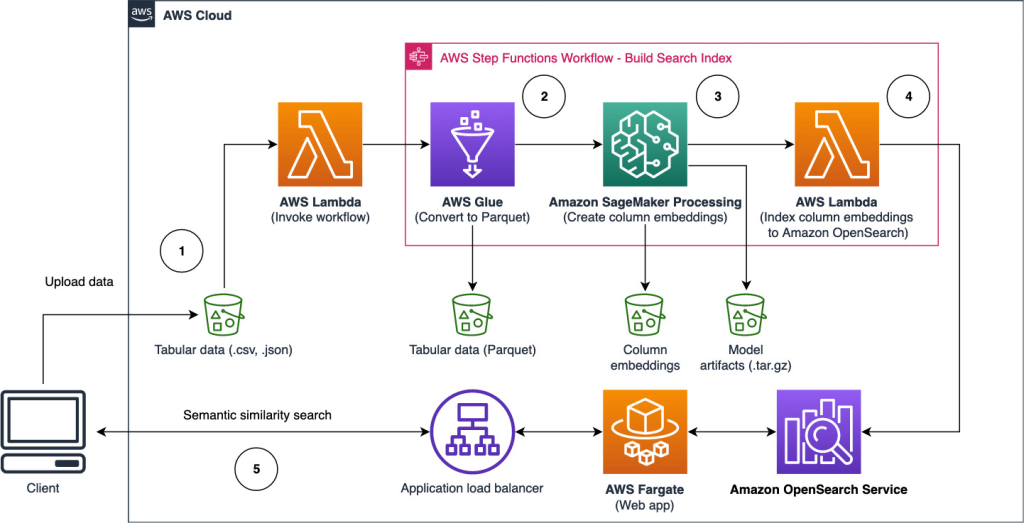
Figuur 1. Oplossingsarchitectuur
De geautomatiseerde workflow verloopt in de volgende stappen:
- De gebruiker uploadt datasets in tabelvorm naar een Amazon eenvoudige opslagservice (Amazon S3) bucket, die een AWS Lambda functie die de stapfuncties-workflow initieert.
- De workflow begint met een AWS lijm taak die de CSV-bestanden converteert naar Apache Parket data formaat.
- Een SageMaker Processing-taak maakt insluitingen voor elke kolom met behulp van vooraf getrainde modellen of aangepaste modellen voor het insluiten van kolommen. De SageMaker Processing-taak slaat de inbedding van kolommen op voor elke tabel in Amazon S3.
- Een Lambda-functie creëert het OpenSearch Service-domein en -cluster om de in de vorige stap geproduceerde kolominsluitingen te indexeren.
- Ten slotte wordt er een interactieve Streamlit-webtoepassing geïmplementeerd met Fargate. De webtoepassing biedt een interface voor de gebruiker om zoekopdrachten in te voeren om in het OpenSearch Service-domein naar vergelijkbare kolommen te zoeken.
U kunt de codehandleiding downloaden van GitHub om deze oplossing uit te proberen op voorbeeldgegevens of uw eigen gegevens. Instructies voor het implementeren van de vereiste bronnen voor deze zelfstudie zijn beschikbaar op GitHub.
Vereisten
Om deze oplossing te implementeren, hebt u het volgende nodig:
- An AWS-account.
- Basiskennis van AWS-services zoals de AWS Cloud-ontwikkelingskit (AWS CDK), Lambda, OpenSearch Service en SageMaker-verwerking.
- Een dataset in tabelvorm om de zoekindex te maken. U kunt uw eigen gegevens in tabelvorm meenemen of de voorbeelddatasets downloaden op GitHub.
Bouw een zoekindex
De eerste fase bouwt de kolomzoekmachine-index op. De volgende afbeelding illustreert de Step Functions-workflow die deze fase uitvoert.
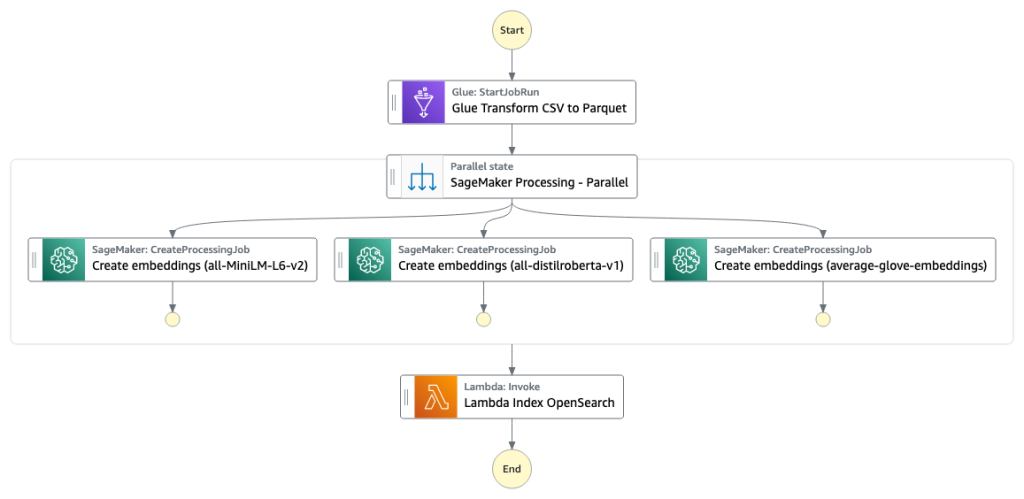
Figuur 2 - Stapfuncties workflow - meerdere inbeddingsmodellen
datasets
In dit bericht bouwen we een zoekindex met meer dan 400 kolommen uit meer dan 25 datasets in tabelvorm. De datasets zijn afkomstig uit de volgende openbare bronnen:
Voor de volledige lijst van de tabellen die in de index zijn opgenomen, zie de codehandleiding op GitHub.
U kunt uw eigen dataset in tabelvorm meenemen om de voorbeeldgegevens aan te vullen of uw eigen zoekindex maken. We voegen twee Lambda-functies toe die de Step Functions-workflow initiëren om de zoekindex op te bouwen voor respectievelijk individuele CSV-bestanden of een batch CSV-bestanden.
Transformeer CSV naar parket
Ruwe CSV-bestanden worden met AWS Glue geconverteerd naar het gegevensformaat Parquet. Parquet is een kolomgeoriënteerd bestandsformaat dat de voorkeur heeft in big data-analyse en dat efficiënte compressie en codering biedt. In onze experimenten bood de Parquet-gegevensindeling een aanzienlijke vermindering van de opslaggrootte in vergelijking met onbewerkte CSV-bestanden. We hebben Parquet ook gebruikt als algemeen dataformaat om andere dataformaten te converteren (bijvoorbeeld JSON en NDJSON) omdat het geavanceerde geneste datastructuren ondersteunt.
Maak tabellaire kolominsluitingen
Om inbeddingen te extraheren voor individuele tabelkolommen in de voorbeeldgegevenssets in tabelvorm in dit bericht, gebruiken we de volgende vooraf getrainde modellen uit de sentence-transformers bibliotheek. Zie voor meer modellen Voorgetrainde modellen.
De SageMaker-verwerkingstaak wordt uitgevoerd create_embeddings.py(code) voor een enkel model. Voor het extraheren van inbeddingen uit meerdere modellen voert de workflow parallelle SageMaker Processing-taken uit, zoals weergegeven in de Step Functions-workflow. We gebruiken het model om twee sets inbeddingen te maken:
- kolomnaam_insluitingen – Inbedding van kolomnamen (headers)
- column_content_embeddings – Gemiddelde inbedding van alle rijen in de kolom
Zie voor meer informatie over het proces voor het insluiten van kolommen de zelfstudie over code GitHub.
Een alternatief voor de SageMaker-verwerkingsstap is het maken van een SageMaker-batchtransformatie om kolominsluitingen op grote datasets te krijgen. Hiervoor moet het model worden geïmplementeerd op een SageMaker-eindpunt. Voor meer informatie, zie Batchtransformatie gebruiken.
Inbeddingen indexeren met OpenSearch Service
In de laatste stap van deze fase voegt een Lambda-functie de inbedding van kolommen toe aan een OpenSearch-service bij benadering k-Nearest-Neighbor (kNN) zoekindex. Elk model krijgt zijn eigen zoekindex toegewezen. Voor meer informatie over de geschatte kNN-zoekindexparameters, zie k-NN.
Online gevolgtrekking en semantisch zoeken met een web-app
De tweede fase van de workflow loopt a Gestroomlijnd webtoepassing waar u invoer kunt leveren en kunt zoeken naar semantisch vergelijkbare kolommen die zijn geïndexeerd in OpenSearch Service. De applicatielaag gebruikt een Toepassing Load Balancer, Fargate en Lambda. De applicatie-infrastructuur wordt automatisch ingezet als onderdeel van de oplossing.
Met de toepassing kunt u invoer geven en zoeken naar semantisch vergelijkbare kolomnamen, kolominhoud of beide. Bovendien kunt u het inbeddingsmodel en het aantal dichtstbijzijnde buren selecteren om terug te keren uit de zoekopdracht. De toepassing ontvangt invoer, sluit de invoer in met het opgegeven model en gebruikt kNN zoeken in OpenSearch Service om geïndexeerde kolominsluitingen te doorzoeken en de kolommen te vinden die het meest lijken op de gegeven invoer. De weergegeven zoekresultaten omvatten de tabelnamen, kolomnamen en overeenkomstenscores voor de geïdentificeerde kolommen, evenals de locaties van de gegevens in Amazon S3 voor verder onderzoek.
De volgende afbeelding toont een voorbeeld van de webapplicatie. In dit voorbeeld hebben we gezocht naar kolommen in ons datameer die vergelijkbare Column Names (type lading) Om district (laadvermogen). De gebruikte applicatie all-MiniLM-L6-v2 de inbeddingsmodel en keerde terug 10 (k) dichtstbijzijnde buren uit onze OpenSearch Service-index.
De toepassing is teruggekeerd transit_district, city, borough en location als de vier meest vergelijkbare kolommen op basis van de gegevens die zijn geïndexeerd in OpenSearch Service. Dit voorbeeld demonstreert het vermogen van de zoekbenadering om semantisch vergelijkbare kolommen in datasets te identificeren.

Afbeelding 3: gebruikersinterface van de webtoepassing
Opruimen
Voer de volgende opdracht uit om de bronnen te verwijderen die door de AWS CDK in deze zelfstudie zijn gemaakt:
cdk destroy --allConclusie
In dit bericht hebben we een end-to-end workflow gepresenteerd voor het bouwen van een semantische zoekmachine voor tabelkolommen.
Ga vandaag nog aan de slag met uw eigen gegevens met onze codehandleiding beschikbaar op GitHub. Als u hulp wilt bij het versnellen van uw gebruik van ML in uw producten en processen, neem dan contact op met de Amazon Machine Learning Solutions-lab.
Over de auteurs
![]() Kachi Odoemene is Applied Scientist bij AWS AI. Hij bouwt AI/ML-oplossingen om zakelijke problemen voor AWS-klanten op te lossen.
Kachi Odoemene is Applied Scientist bij AWS AI. Hij bouwt AI/ML-oplossingen om zakelijke problemen voor AWS-klanten op te lossen.
![]() Taylor McNally is een Deep Learning Architect bij Amazon Machine Learning Solutions Lab. Hij helpt klanten uit verschillende branches bij het bouwen van oplossingen die gebruikmaken van AI/ML op AWS. Hij geniet van een goede kop koffie, het buitenleven en tijd met zijn gezin en energieke hond.
Taylor McNally is een Deep Learning Architect bij Amazon Machine Learning Solutions Lab. Hij helpt klanten uit verschillende branches bij het bouwen van oplossingen die gebruikmaken van AI/ML op AWS. Hij geniet van een goede kop koffie, het buitenleven en tijd met zijn gezin en energieke hond.
![]() Austin Welch is een datawetenschapper in het Amazon ML Solutions Lab. Hij ontwikkelt op maat gemaakte deep learning-modellen om AWS-klanten in de publieke sector te helpen hun AI- en cloudadoptie te versnellen. In zijn vrije tijd houdt hij van lezen, reizen en jiu-jitsu.
Austin Welch is een datawetenschapper in het Amazon ML Solutions Lab. Hij ontwikkelt op maat gemaakte deep learning-modellen om AWS-klanten in de publieke sector te helpen hun AI- en cloudadoptie te versnellen. In zijn vrije tijd houdt hij van lezen, reizen en jiu-jitsu.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/

