Duik in diep leren (D2L.ai) is een open-source leerboek dat diep leren voor iedereen toegankelijk maakt. Het bevat interactieve Jupyter-notebooks met op zichzelf staande code in PyTorch, JAX, TensorFlow en MXNet, evenals praktijkvoorbeelden, expositiecijfers en wiskunde. Tot nu toe is D2L overgenomen door meer dan 400 universiteiten over de hele wereld, zoals de University of Cambridge, Stanford University, het Massachusetts Institute of Technology, Carnegie Mellon University en Tsinghua University. Dit werk is ook beschikbaar in het Chinees, Japans, Koreaans, Portugees, Turks en Vietnamees, met plannen om Spaans en andere talen te lanceren.
Het is een uitdagende onderneming om een online boek te hebben dat continu up-to-date wordt gehouden, is geschreven door meerdere auteurs en beschikbaar is in meerdere talen. In dit bericht presenteren we een oplossing die D2L.ai gebruikte om deze uitdaging aan te pakken door de Actieve functie voor aangepaste vertalingen (ACT). of Amazon Vertalen en het bouwen van een meertalige automatische vertaalpijplijn.
We demonstreren het gebruik van de AWS-beheerconsole en Amazon Translate openbare API om automatische automatische batchvertaling te leveren en de vertalingen tussen twee talenparen te analyseren: Engels en Chinees, en Engels en Spaans. We raden ook best practices aan bij het gebruik van Amazon Translate in deze automatische vertaalpijplijn om de vertaalkwaliteit en efficiëntie te garanderen.
Overzicht oplossingen
We hebben automatische vertaalpijplijnen voor meerdere talen gebouwd met behulp van de ACT-functie in Amazon Translate. Met ACT kunt u vertaaluitvoer on-the-fly aanpassen door op maat gemaakte vertaalvoorbeelden te bieden in de vorm van parallelle gegevens. Parallelle data bestaat uit een verzameling tekstuele voorbeelden in een brontaal en de gewenste vertalingen in een of meer doeltalen. Tijdens de vertaling selecteert ACT automatisch de meest relevante segmenten uit de parallelle gegevens en werkt het vertaalmodel on-the-fly bij op basis van die segmentparen. Dit resulteert in vertalingen die beter aansluiten bij de stijl en inhoud van de parallelle data.
De architectuur bevat meerdere subpijplijnen; elke subpijplijn verwerkt één taalvertaling, zoals Engels naar Chinees, Engels naar Spaans, enzovoort. Meerdere vertaal-subpijplijnen kunnen parallel worden verwerkt. In elke subpijplijn bouwen we eerst de parallelle gegevens in Amazon Translate met behulp van de hoogwaardige dataset van vertaalde vertaalvoorbeelden uit de door mensen vertaalde D2L-boeken. Vervolgens genereren we de aangepaste machinevertalingsoutput on-the-fly tijdens runtime, wat een betere kwaliteit en nauwkeurigheid oplevert.
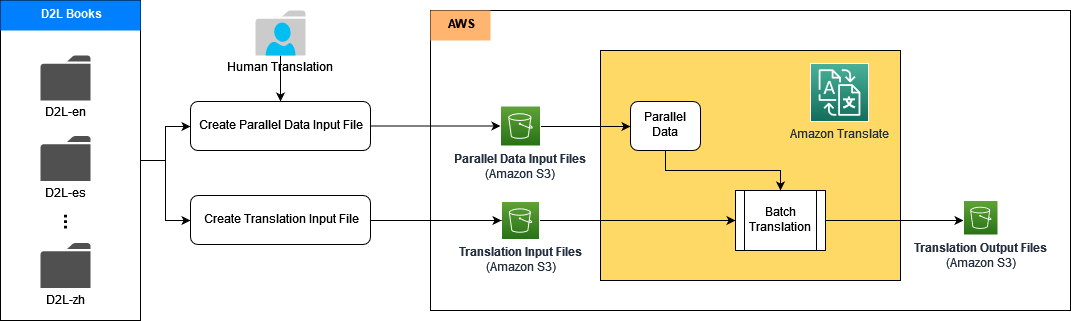
In de volgende secties laten we zien hoe u elke vertaalpijplijn bouwt met behulp van Amazon Translate met ACT, samen met Amazon Sage Maker en Amazon eenvoudige opslagservice (Amazone S3).
Eerst hebben we de brondocumenten, referentiedocumenten en parallelle datatrainingsset in een S3-bucket geplaatst. Vervolgens bouwen we Jupyter-notebooks in SageMaker om het vertaalproces uit te voeren met openbare API's van Amazon Translate.
Voorwaarden
Om de stappen in dit bericht te volgen, moet je ervoor zorgen dat je een AWS-account hebt met het volgende:
- Toegang tot AWS Identiteits- en toegangsbeheer (IAM) voor rol- en beleidsconfiguratie
- Toegang tot Amazon Translate, SageMaker en Amazon S3
- Een S3-bucket om de brondocumenten, referentiedocumenten, parallelle datadataset en output van vertaling op te slaan
Creëer een IAM-rol en beleid voor Amazon Translate met ACT
Onze IAM-rol moet een aangepast vertrouwensbeleid voor Amazon Translate bevatten:
Deze rol moet ook een machtigingenbeleid hebben dat Amazon Translate leestoegang verleent tot de invoermap en submappen in Amazon S3 die de brondocumenten bevatten, en lees-/schrijftoegang tot de uitvoer S3-bucket en -map die de vertaalde documenten bevat:
Om Jupyter-notebooks in SageMaker uit te voeren voor de vertaaltaken, moeten we een inline machtigingsbeleid toekennen aan de uitvoeringsrol van SageMaker. Deze rol geeft de Amazon Translate-servicerol door aan SageMaker waarmee de SageMaker-notebooks toegang hebben tot de bron en vertaalde documenten in de aangewezen S3-buckets:
Bereid voorbeelden van parallelle gegevenstraining voor
De parallelle gegevens in ACT moeten worden getraind door een invoerbestand dat bestaat uit een lijst met tekstuele voorbeeldparen, bijvoorbeeld een paar brontaal (Engels) en doeltaal (Chinees). Het invoerbestand kan de indeling TMX, CSV of TSV hebben. De volgende schermafbeelding toont een voorbeeld van een CSV-invoerbestand. De eerste kolom bevat de gegevens in de brontaal (in het Engels) en de tweede kolom bevat de gegevens in de doeltaal (in het Chinees). Het volgende voorbeeld is geëxtraheerd uit het D2L-en-boek en het D2L-zh-boek.

Voer aangepaste parallelle datatraining uit in Amazon Translate
Eerst hebben we de S3-bucket en -mappen ingesteld zoals weergegeven in de volgende schermafbeelding. De source_data map bevat de brondocumenten vóór de vertaling; de gegenereerde documenten na de batchvertaling worden in de uitvoermap geplaatst. De ParallelData map bevat het parallelle gegevensinvoerbestand dat in de vorige stap is voorbereid.
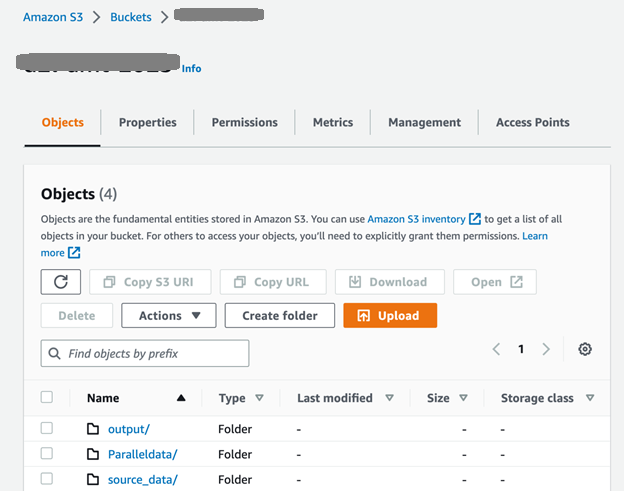
Na het uploaden van de invoerbestanden naar het source_data map, kunnen we de CreateParallelData-API om een parallelle gegevensaanmaaktaak uit te voeren in Amazon Translate:
Om bestaande parallelle data bij te werken met nieuwe trainingsdatasets, kunnen we de UpdateParallelData-API:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data( Name=pd_name, # pd_name is the parallel data name Description=pd_description, # pd_description is the parallel data description ParallelDataConfig={ 'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step 'Format': 'CSV' },
)
print(pd_name, ": ", response_t['Status'], " updated.")
We kunnen de voortgang van de trainingstaak controleren op de Amazon Translate-console. Wanneer de taak is voltooid, wordt de parallelle gegevensstatus weergegeven als Actief en is klaar voor gebruik.
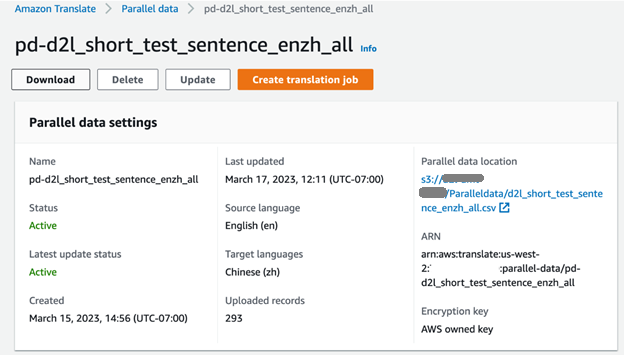
Voer gesynchroniseerde batchvertaling uit met behulp van parallelle gegevens
De batchvertaling kan worden uitgevoerd in een proces waarbij meerdere brondocumenten automatisch worden vertaald naar documenten in doeltalen. Het proces omvat het uploaden van de brondocumenten naar de invoermap van de S3-bucket en vervolgens het toepassen van de StartTextTranslationJob-API van Amazon Translate om een asynchrone vertaaltaak te starten:
We selecteerden vijf brondocumenten in het Engels uit het D2L-boek (D2L-en) voor de bulkvertaling. Op de Amazon Translate-console kunnen we de voortgang van de vertaaltaak volgen. Wanneer de taakstatus verandert in Voltooid, kunnen we de vertaalde documenten in het Chinees (D2L-zh) vinden in de uitvoermap van de S3-bucket.
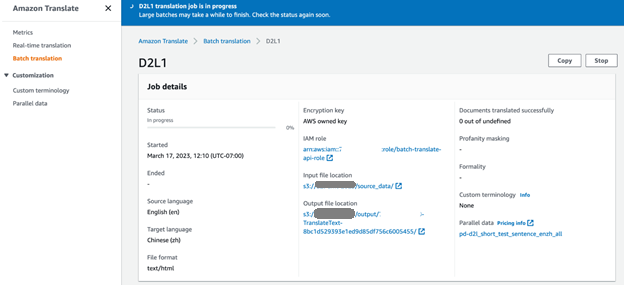
Evalueer de vertaalkwaliteit
Om de effectiviteit van de ACT-functie in Amazon Translate aan te tonen, hebben we ook de traditionele methode van Amazon Translate real-time vertaling zonder parallelle gegevens toegepast om dezelfde documenten te verwerken, en vergeleken we de output met de batchvertaaloutput met ACT. We gebruikten de BLEU-score (BiLingual Evaluation Understudy) om de vertaalkwaliteit tussen de twee methoden te benchmarken. De enige manier om de kwaliteit van de uitvoer van machinevertalingen nauwkeurig te meten, is door een deskundige te laten beoordelen en de kwaliteit te beoordelen. BLEU geeft echter een schatting van de relatieve kwaliteitsverbetering tussen twee outputs. Een BLEU-score is meestal een getal tussen 0 en 1; het berekent de gelijkenis van de machinevertaling met de menselijke referentievertaling. De hogere score staat voor een betere kwaliteit in begrip van natuurlijke taal (NLU).
We hebben een reeks documenten getest in vier pijplijnen: Engels naar Chinees (en naar zh), Chinees naar Engels (zh naar en), Engels naar Spaans (en naar es) en Spaans naar Engels (es naar en). De volgende figuur laat zien dat de vertaling met ACT een hogere gemiddelde BLEU-score opleverde in alle vertaalpijplijnen.
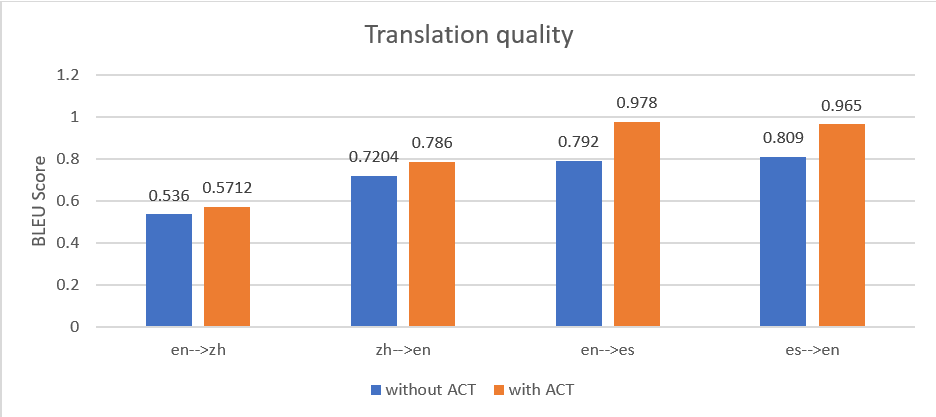
We hebben ook vastgesteld dat hoe gedetailleerder de parallelle gegevensparen zijn, hoe beter de vertaalprestaties zijn. We gebruiken bijvoorbeeld het volgende parallelle gegevensinvoerbestand met paragrafenparen, dat 10 ingangen bevat.

Voor dezelfde inhoud gebruiken we het volgende parallelle gegevensinvoerbestand met zinsparen en 16 ingangen.

We hebben beide parallelle gegevensinvoerbestanden gebruikt om twee parallelle gegevensentiteiten in Amazon Translate te construeren en hebben vervolgens twee batchvertaaltaken gemaakt met hetzelfde brondocument. De volgende afbeelding vergelijkt de uitvoervertalingen. Het laat zien dat de uitvoer met behulp van parallelle gegevens met paren van zinnen beter presteerde dan die met parallelle gegevens met paren van alinea's, voor zowel Engels-Chinees vertaling als Chinees-Engels vertaling.
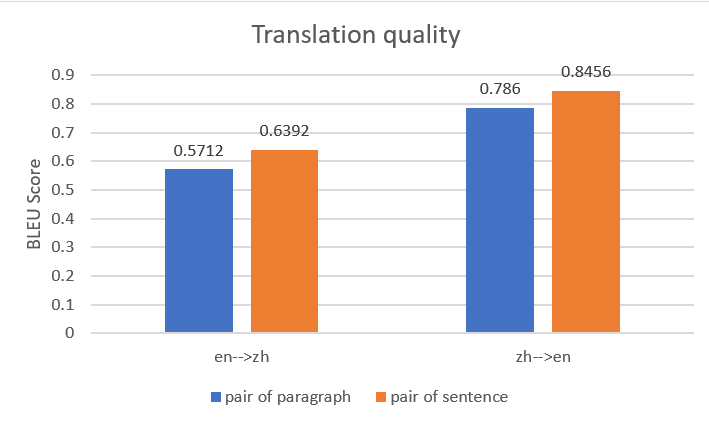
Als u meer wilt weten over deze benchmarkanalyses, raadpleeg dan Automatische machinevertaling en synchronisatie voor "Dive into Deep Learning".
Opruimen
Om terugkerende kosten in de toekomst te voorkomen, raden we u aan de bronnen die u hebt gemaakt op te schonen:
- Selecteer op de Amazon Translate-console de parallelle gegevens die u hebt gemaakt en kies Verwijder. Als alternatief kunt u de DeleteParallelData-API of de AWS-opdrachtregelinterface (AWS-CLI) delete-parallelle-data opdracht om de parallelle gegevens te verwijderen.
- Verwijder de S3-bucket gebruikt om de bron- en referentiedocumenten, vertaalde documenten en parallelle gegevensinvoerbestanden te hosten.
- Verwijder de IAM-rol en het beleid. Raadpleeg voor instructies Rollen of instantieprofielen verwijderen en IAM-beleid verwijderen.
Conclusie
Met deze oplossing willen we de werklast van menselijke vertalers met 80% verminderen, terwijl de vertaalkwaliteit behouden blijft en meerdere talen worden ondersteund. U kunt deze oplossing gebruiken om uw vertaalkwaliteit en efficiëntie te verbeteren. We werken aan het verder verbeteren van de oplossingsarchitectuur en de vertaalkwaliteit voor andere talen.
Uw feedback is altijd welkom; laat uw mening en vragen achter in het opmerkingengedeelte.
Over de auteurs
 Yunfei Bai is Senior Solutions Architect bij AWS. Met een achtergrond in AI/ML, datawetenschap en analyse helpt Yunfei klanten om AWS-services te gebruiken om zakelijke resultaten te behalen. Hij ontwerpt AI/ML- en data-analyseoplossingen die complexe technische uitdagingen overwinnen en strategische doelstellingen aansturen. Yunfei is gepromoveerd in elektronische en elektrotechniek. Naast zijn werk houdt Yunfei van lezen en muziek.
Yunfei Bai is Senior Solutions Architect bij AWS. Met een achtergrond in AI/ML, datawetenschap en analyse helpt Yunfei klanten om AWS-services te gebruiken om zakelijke resultaten te behalen. Hij ontwerpt AI/ML- en data-analyseoplossingen die complexe technische uitdagingen overwinnen en strategische doelstellingen aansturen. Yunfei is gepromoveerd in elektronische en elektrotechniek. Naast zijn werk houdt Yunfei van lezen en muziek.
 Rachel Hu is een toegepaste wetenschapper aan de AWS Machine Learning University (MLU). Ze heeft een aantal cursusontwerpen geleid, waaronder ML Operations (MLOps) en Accelerator Computer Vision. Rachel is een AWS senior spreker en heeft gesproken op topconferenties, waaronder AWS re:Invent, NVIDIA GTC, KDD en MLOps Summit. Voordat ze bij AWS kwam, werkte Rachel als machine learning-ingenieur en bouwde ze modellen voor natuurlijke taalverwerking. Buiten haar werk houdt ze van yoga, ultieme frisbee, lezen en reizen.
Rachel Hu is een toegepaste wetenschapper aan de AWS Machine Learning University (MLU). Ze heeft een aantal cursusontwerpen geleid, waaronder ML Operations (MLOps) en Accelerator Computer Vision. Rachel is een AWS senior spreker en heeft gesproken op topconferenties, waaronder AWS re:Invent, NVIDIA GTC, KDD en MLOps Summit. Voordat ze bij AWS kwam, werkte Rachel als machine learning-ingenieur en bouwde ze modellen voor natuurlijke taalverwerking. Buiten haar werk houdt ze van yoga, ultieme frisbee, lezen en reizen.
 Watson Srivathsan is de Principal Product Manager voor Amazon Translate, de natuurlijke taalverwerkingsservice van AWS. In het weekend zul je hem het buitenleven in de Pacific Northwest ontdekken.
Watson Srivathsan is de Principal Product Manager voor Amazon Translate, de natuurlijke taalverwerkingsservice van AWS. In het weekend zul je hem het buitenleven in de Pacific Northwest ontdekken.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/build-a-multilingual-automatic-translation-pipeline-with-amazon-translate-active-custom-translation/

