De opkomst van contextueel en semantisch zoeken heeft ervoor gezorgd dat e-commerce- en detailhandelsbedrijven eenvoudig naar hun consumenten kunnen zoeken. Zoekmachines en aanbevelingssystemen die worden aangedreven door generatieve AI kunnen de zoekervaring naar producten exponentieel verbeteren door zoekopdrachten in natuurlijke taal te begrijpen en nauwkeurigere resultaten te retourneren. Dit verbetert de algehele gebruikerservaring en helpt klanten precies te vinden wat ze zoeken.
Amazon OpenSearch-service ondersteunt nu de cosinus gelijkenis metriek voor k-NN-indexen. Cosinusovereenkomst meet de cosinus van de hoek tussen twee vectoren, waarbij een kleinere cosinushoek een grotere overeenkomst tussen de vectoren aangeeft. Met cosinusovereenkomst kunt u de oriëntatie tussen twee vectoren meten, waardoor het een goede keuze is voor sommige specifieke semantische zoektoepassingen.
In dit bericht laten we zien hoe u een contextuele tekst- en afbeeldingenzoekmachine kunt bouwen voor productaanbevelingen met behulp van de Amazon Titan Multimodal Embeddings-model, beschikbaar in Amazonebodemmet Amazon OpenSearch Serverloos.
Een multimodaal inbeddingsmodel is ontworpen om gezamenlijke representaties van verschillende modaliteiten zoals tekst, afbeeldingen en audio te leren. Door te trainen op grootschalige datasets met afbeeldingen en de bijbehorende bijschriften, leert een multimodaal inbeddingsmodel afbeeldingen en teksten in een gedeelde latente ruimte inbedden. Het volgende is een overzicht op hoog niveau van hoe het conceptueel werkt:
- Aparte encoders – Deze modellen hebben afzonderlijke encoders voor elke modaliteit: een tekstencoder voor tekst (bijvoorbeeld BERT of RoBERTa), afbeeldingsencoder voor afbeeldingen (bijvoorbeeld CNN voor afbeeldingen) en audio-encoders voor audio (bijvoorbeeld modellen als Wav2Vec) . Elke encoder genereert inbedding die semantische kenmerken van hun respectievelijke modaliteiten vastlegt
- Modaliteitsfusie – De inbedding van de unimodale encoders wordt gecombineerd met behulp van extra neurale netwerklagen. Het doel is om interacties en correlaties tussen de modaliteiten te leren. Veel voorkomende fusiebenaderingen zijn onder meer aaneenschakeling, elementgewijze bewerkingen, pooling en aandachtsmechanismen.
- Gedeelde representatieruimte – De fusielagen helpen de individuele modaliteiten in een gedeelde representatieruimte te projecteren. Door te trainen op multimodale datasets leert het model een gemeenschappelijke inbeddingsruimte waar inbedding van elke modaliteit die dezelfde onderliggende semantische inhoud vertegenwoordigt dichter bij elkaar ligt.
- Stroomafwaartse taken – De gezamenlijke multimodale inbedding die wordt gegenereerd, kan vervolgens worden gebruikt voor verschillende downstream-taken, zoals multimodaal ophalen, classificatie of vertaling. Het model maakt gebruik van correlaties tussen modaliteiten om de prestaties bij deze taken te verbeteren in vergelijking met individuele modale inbedding. Het belangrijkste voordeel is het vermogen om interacties en semantiek tussen modaliteiten zoals tekst, afbeeldingen en audio te begrijpen door middel van gezamenlijke modellering.
Overzicht oplossingen
De oplossing biedt een implementatie voor het bouwen van een door een groot taalmodel (LLM) aangedreven prototype van een zoekmachine om producten op te halen en aan te bevelen op basis van tekst- of afbeeldingsquery's. We beschrijven de stappen om een Multimodale inbedding van Amazon Titan model om afbeeldingen en tekst te coderen in insluitingen, insluitingen op te nemen in een OpenSearch Service-index en de index te doorzoeken met behulp van de OpenSearch Service functionaliteit van k-dichtstbijzijnde buren (k-NN)..
Deze oplossing bevat de volgende componenten:
- Amazon Titan Multimodal Embeddings-model – Dit basismodel (FM) genereert inbedding van de productafbeeldingen die in dit bericht worden gebruikt. Met Amazon Titan Multimodal Embeddings kunt u insluitingen voor uw inhoud genereren en deze opslaan in een vectordatabase. Wanneer een eindgebruiker een combinatie van tekst en afbeeldingen als zoekopdracht indient, genereert het model insluitingen voor de zoekopdracht en koppelt deze aan de opgeslagen insluitingen om relevante zoek- en aanbevelingsresultaten aan eindgebruikers te bieden. U kunt het model verder aanpassen om het begrip van uw unieke inhoud te vergroten en betekenisvollere resultaten te bieden door beeld-tekstparen te gebruiken voor verfijning. Het model genereert standaard vectoren (inbedding) van 1,024 dimensies en is toegankelijk via Amazon Bedrock. U kunt ook kleinere afmetingen genereren om de snelheid en prestaties te optimaliseren
- Amazon OpenSearch Serverloos – Het is een on-demand serverloze configuratie voor OpenSearch Service. We gebruiken Amazon OpenSearch Serverless als een vectordatabase voor het opslaan van insluitingen die zijn gegenereerd door het Amazon Titan Multimodal Embeddings-model. Een index die is gemaakt in de Amazon OpenSearch Serverless-collectie dient als vectoropslag voor onze Retrieval Augmented Generation (RAG)-oplossing.
- Amazon SageMaker Studio – Het is een geïntegreerde ontwikkelomgeving (IDE) voor machine learning (ML). ML-professionals kunnen alle ML-ontwikkelingsstappen uitvoeren, van het voorbereiden van uw gegevens tot het bouwen, trainen en implementeren van ML-modellen.
Het oplossingsontwerp bestaat uit twee delen: gegevensindexering en contextueel zoeken. Tijdens het indexeren van gegevens verwerkt u de productafbeeldingen om insluitingen voor deze afbeeldingen te genereren en vult u vervolgens de vectorgegevensopslag. Deze stappen worden voltooid voorafgaand aan de stappen voor gebruikersinteractie.
In de contextuele zoekfase wordt een zoekopdracht (tekst of afbeelding) van de gebruiker omgezet in inbedding en wordt er een gelijkeniszoekopdracht uitgevoerd in de vectordatabase om vergelijkbare productafbeeldingen te vinden op basis van gelijkeniszoekopdracht. Vervolgens geeft u de beste vergelijkbare resultaten weer. Alle code voor dit bericht is beschikbaar in de GitHub repo.
Het volgende diagram illustreert de oplossingsarchitectuur.
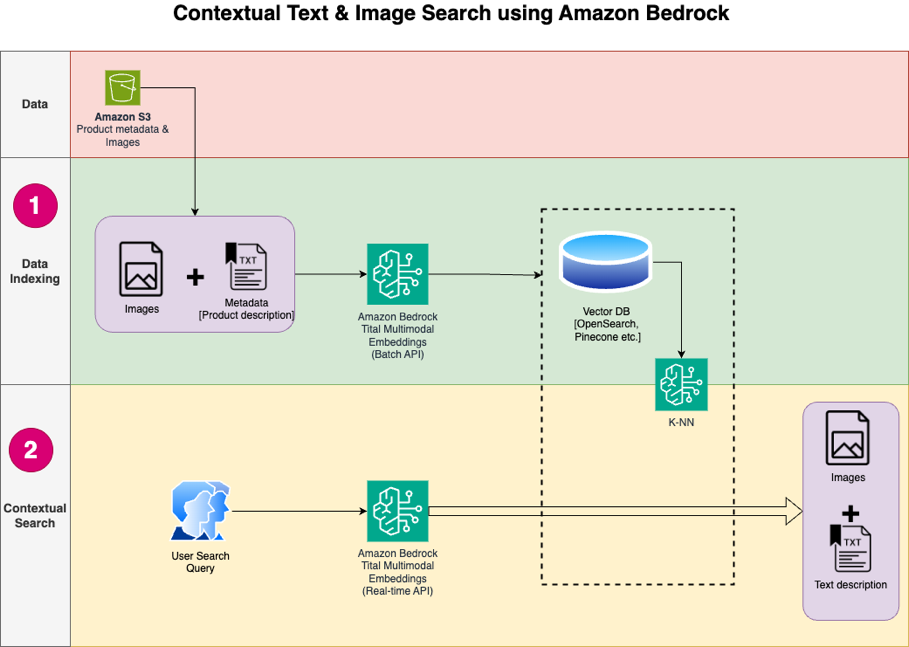
Hieronder volgen de stappen voor de oplossingsworkflow:
- Download de productbeschrijvingstekst en afbeeldingen van het publiek Amazon eenvoudige opslagservice (Amazon S3) emmer.
- Controleer de dataset en bereid deze voor.
- Genereer insluitingen voor de productafbeeldingen met behulp van het Amazon Titan Multimodal Embeddings-model (amazon.titan-embed-image-v1). Als u een groot aantal afbeeldingen en beschrijvingen heeft, kunt u optioneel de Batch-inferentie voor Amazon Bedrock.
- Bewaar insluitingen in de Amazon OpenSearch Serverloos als zoekmachine.
- Haal ten slotte de gebruikersquery op in natuurlijke taal, converteer deze naar insluitingen met behulp van het Amazon Titan Multimodal Embeddings-model en voer een k-NN-zoekopdracht uit om de relevante zoekresultaten te krijgen.
We gebruiken SageMaker Studio (niet weergegeven in het diagram) als de IDE om de oplossing te ontwikkelen.
Deze stappen worden in de volgende paragrafen gedetailleerd besproken. We nemen ook schermafbeeldingen en details van de uitvoer op.
Voorwaarden
Om de oplossing in dit bericht te implementeren, zou je over het volgende moeten beschikken:
- An AWS-account en bekendheid met FM's, Amazon Bedrock, Amazon Sage Makeren OpenSearch-service.
- Het Amazon Titan Multimodal Embeddings-model ingeschakeld in Amazon Bedrock. U kunt bevestigen dat deze is ingeschakeld op de Toegang tot modellen pagina van de Amazon Bedrock-console. Als Amazon Titan Multimodal Embeddings is ingeschakeld, wordt de toegangsstatus weergegeven als Toegang verleend, zoals weergegeven in de volgende schermafbeelding.

Als het model niet beschikbaar is, schakelt u de toegang tot het model in door te kiezen Beheer modeltoegang, selecteren Multimodale inbedding van Amazon Titan G1en kiezen Modeltoegang aanvragen. Het model is onmiddellijk klaar voor gebruik.

Stel de oplossing in
Wanneer de vereiste stappen zijn voltooid, bent u klaar om de oplossing in te stellen:
- Open in uw AWS-account de SageMaker-console en kies studio in het navigatievenster.
- Kies uw domein en gebruikersprofiel en kies vervolgens Studio openen.
Uw domein- en gebruikersprofielnaam kunnen verschillen.

- Kies Systeemterminal voor Hulpprogramma's en bestanden.
- Voer de volgende opdracht uit om het GitHub repo naar de SageMaker Studio-instantie:
- Navigeer naar de
multimodal/Titan/titan-multimodal-embeddings/amazon-bedrock-multimodal-oss-searchengine-e2emap. - Open de
titan_mm_embed_search_blog.ipynbnotebook.
Voer de oplossing uit
Open het bestand titan_mm_embed_search_blog.ipynb en gebruik de Data Science Python 3-kernel. Op de lopen menu, kies Voer alle cellen uit om de code in dit notitieblok uit te voeren.
Dit notebook voert de volgende stappen uit:
- Installeer de pakketten en bibliotheken die nodig zijn voor deze oplossing.
- Laad het openbaar beschikbare bestand Amazon Berkeley Objects-gegevensset en metadata in een panda-dataframe.
De dataset is een verzameling van 147,702 productvermeldingen met meertalige metadata en 398,212 unieke catalogusafbeeldingen. Voor dit bericht gebruik je alleen de itemafbeeldingen en itemnamen in Amerikaans Engels. Je gebruikt ongeveer 1,600 producten.

- Genereer insluitingen voor de itemafbeeldingen met behulp van het Amazon Titan Multimodal Embeddings-model met behulp van de
get_titan_multomodal_embedding()functie. Omwille van de abstractie hebben we alle belangrijke functies die in dit notebook worden gebruikt, gedefinieerd in deutils.pybestand.

Vervolgens maakt en configureert u een Amazon OpenSearch Serverless vectorwinkel (verzameling en index).
- Voordat u de nieuwe vectorzoekcollectie en -index maakt, moet u eerst drie bijbehorende OpenSearch Service-beleidsregels maken: het versleutelingsbeveiligingsbeleid, het netwerkbeveiligingsbeleid en het gegevenstoegangsbeleid.

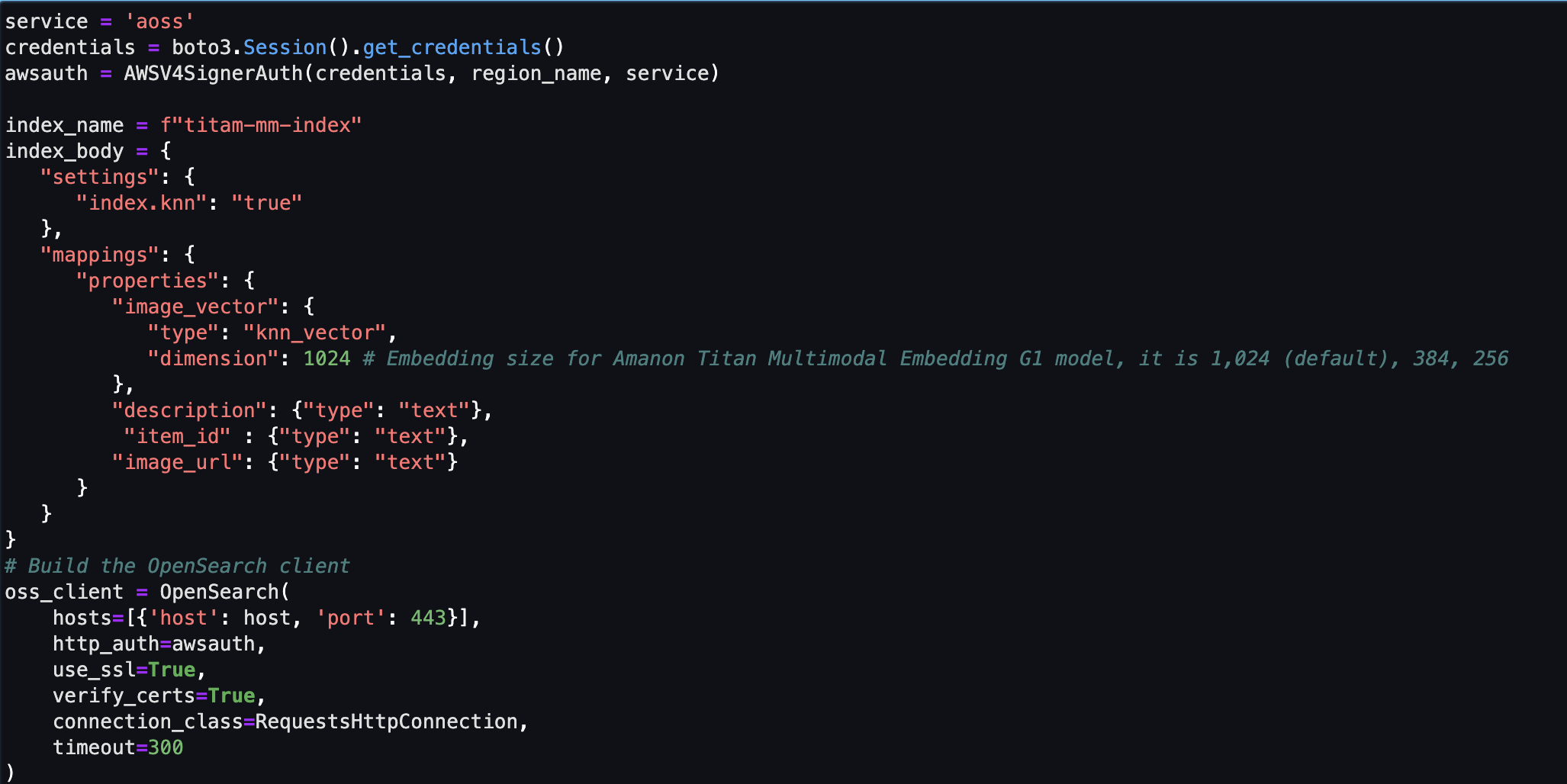
- Neem ten slotte de afbeelding op die is ingebed in de vectorindex.
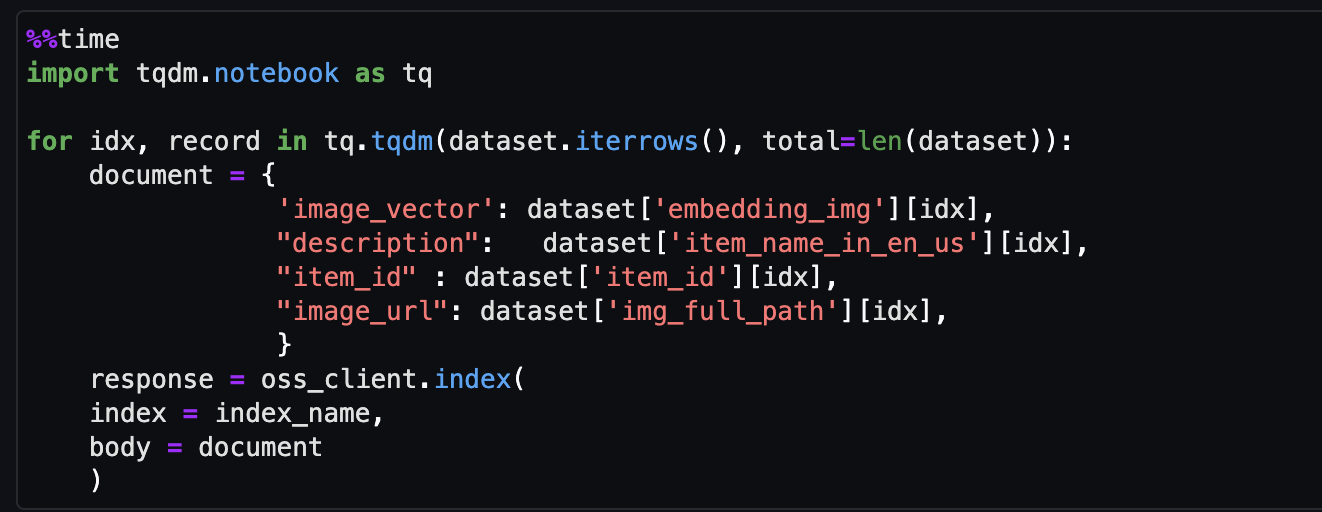
Nu kunt u realtime multimodaal zoeken.
Voer een contextuele zoekopdracht uit
In deze sectie tonen we de resultaten van contextueel zoeken op basis van een tekst- of beeldquery.
Laten we eerst een afbeeldingszoekopdracht uitvoeren op basis van tekstinvoer. In het volgende voorbeeld gebruiken we de tekstinvoer ‘drinkglas’ en sturen deze naar de zoekmachine om soortgelijke artikelen te vinden.
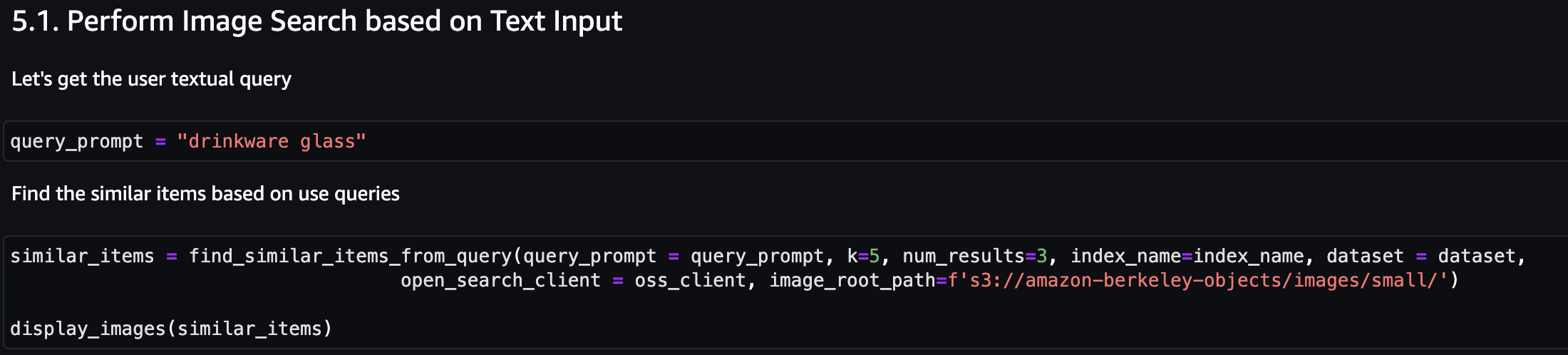
De volgende schermafbeelding toont de resultaten.

Laten we nu naar de resultaten kijken op basis van een eenvoudige afbeelding. De invoerafbeelding wordt omgezet in vectorinbedding en op basis van het zoeken naar overeenkomsten retourneert het model het resultaat.
U kunt elke afbeelding gebruiken, maar voor het volgende voorbeeld gebruiken we een willekeurige afbeelding uit de dataset op basis van item-ID (bijvoorbeeld item_id = “B07JCDQWM6”) en stuur deze afbeelding vervolgens naar de zoekmachine om vergelijkbare items te vinden.

De volgende schermafbeelding toont de resultaten.

Opruimen
Om te voorkomen dat er in de toekomst kosten in rekening worden gebracht, verwijdert u de bronnen die in deze oplossing worden gebruikt. U kunt dit doen door het opruimgedeelte van het notitieblok uit te voeren.

Conclusie
Dit bericht presenteerde een walkthrough voor het gebruik van het Amazon Titan Multimodal Embeddings-model in Amazon Bedrock om krachtige contextuele zoekapplicaties te bouwen. We hebben in het bijzonder een voorbeeld gedemonstreerd van een zoekapplicatie voor productlijsten. We hebben gezien hoe het embeddingsmodel efficiënte en nauwkeurige ontdekking van informatie uit afbeeldingen en tekstuele gegevens mogelijk maakt, waardoor de gebruikerservaring wordt verbeterd tijdens het zoeken naar de relevante items.
Amazon Titan Multimodal Embeddings helpt u nauwkeurigere en contextueel relevante multimodale zoek-, aanbevelings- en personalisatie-ervaringen voor eindgebruikers mogelijk te maken. Een stockfotografiebedrijf met honderden miljoenen afbeeldingen kan het model bijvoorbeeld gebruiken om de zoekfunctionaliteit te versterken, zodat gebruikers naar afbeeldingen kunnen zoeken met behulp van een zin, afbeelding of een combinatie van afbeelding en tekst.
Het Amazon Titan Multimodal Embeddings-model in Amazon Bedrock is nu beschikbaar in de AWS-regio's VS-Oost (N. Virginia) en VS-West (Oregon). Raadpleeg voor meer informatie Amazon Titan Image Generator, Multimodal Embeddings en Tekstmodellen zijn nu beschikbaar in Amazon Bedrock Amazon Titan-productpaginaEn Amazon Bedrock-gebruikershandleiding. Ga naar om aan de slag te gaan met Amazon Titan Multimodal Embeddings in Amazon Bedrock Amazon Bedrock-console.
Begin met bouwen met het Amazon Titan Multimodal Embeddings-model Amazonebodem <p></p>
Over de auteurs
 Sandeep Singh is een Senior Genative AI Data Scientist bij Amazon Web Services en helpt bedrijven te innoveren met generatieve AI. Hij is gespecialiseerd in generatieve AI, kunstmatige intelligentie, machinaal leren en systeemontwerp. Hij heeft een passie voor het ontwikkelen van state-of-the-art AI/ML-aangedreven oplossingen om complexe zakelijke problemen voor diverse industrieën op te lossen, waarbij de efficiëntie en schaalbaarheid worden geoptimaliseerd.
Sandeep Singh is een Senior Genative AI Data Scientist bij Amazon Web Services en helpt bedrijven te innoveren met generatieve AI. Hij is gespecialiseerd in generatieve AI, kunstmatige intelligentie, machinaal leren en systeemontwerp. Hij heeft een passie voor het ontwikkelen van state-of-the-art AI/ML-aangedreven oplossingen om complexe zakelijke problemen voor diverse industrieën op te lossen, waarbij de efficiëntie en schaalbaarheid worden geoptimaliseerd.
 Mani Khanuja is een Tech Lead – Generative AI Specialists, auteur van het boek Applied Machine Learning and High Performance Computing on AWS, en lid van de Raad van Bestuur van Women in Manufacturing Education Foundation Board. Ze leidt machine learning-projecten in verschillende domeinen, zoals computer vision, natuurlijke taalverwerking en generatieve AI. Ze spreekt op interne en externe conferenties zoals AWS re:Invent, Women in Manufacturing West, YouTube-webinars en GHC 23. In haar vrije tijd maakt ze graag lange runs langs het strand.
Mani Khanuja is een Tech Lead – Generative AI Specialists, auteur van het boek Applied Machine Learning and High Performance Computing on AWS, en lid van de Raad van Bestuur van Women in Manufacturing Education Foundation Board. Ze leidt machine learning-projecten in verschillende domeinen, zoals computer vision, natuurlijke taalverwerking en generatieve AI. Ze spreekt op interne en externe conferenties zoals AWS re:Invent, Women in Manufacturing West, YouTube-webinars en GHC 23. In haar vrije tijd maakt ze graag lange runs langs het strand.
 Rupinder Grewal is een Senior AI/ML Specialist Solutions Architect bij AWS. Momenteel richt hij zich op het serveren van modellen en MLOps op Amazon SageMaker. Voorafgaand aan deze rol werkte hij als Machine Learning Engineer bij het bouwen en hosten van modellen. Buiten zijn werk speelt hij graag tennis en fietst hij op bergpaden.
Rupinder Grewal is een Senior AI/ML Specialist Solutions Architect bij AWS. Momenteel richt hij zich op het serveren van modellen en MLOps op Amazon SageMaker. Voorafgaand aan deze rol werkte hij als Machine Learning Engineer bij het bouwen en hosten van modellen. Buiten zijn werk speelt hij graag tennis en fietst hij op bergpaden.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/build-a-contextual-text-and-image-search-engine-for-product-recommendations-using-amazon-bedrock-and-amazon-opensearch-serverless/

