
Afbeelding door auteur
Sparse data verwijst naar datasets met veel functies met nulwaarden. Het kan op verschillende gebieden problemen veroorzaken, vooral bij machine learning.
Er kunnen schaarse gegevens optreden als gevolg van ongepaste feature engineering-methoden. Bijvoorbeeld door een one-hot-codering te gebruiken die een groot aantal dummy-variabelen creëert.
Schaarsheid kan worden berekend door de verhouding van nullen in een dataset tot het totale aantal elementen te nemen. Het aanpakken van schaarste heeft invloed op de nauwkeurigheid van uw machine learning-model.
We moeten ook schaarsheid onderscheiden van ontbrekende gegevens. Ontbrekende gegevens betekenen simpelweg dat sommige waarden niet beschikbaar zijn. In schaarse gegevens zijn alle waarden aanwezig, maar de meeste zijn nul.
Ook veroorzaakt schaarsheid unieke uitdagingen voor machine learning. Om precies te zijn, het veroorzaakt overfitting, verlies van goede gegevens, geheugenproblemen en tijdsproblemen.
In dit artikel worden deze veelvoorkomende problemen met schaarse gegevens onderzocht. Vervolgens behandelen we de technieken die worden gebruikt om dit probleem aan te pakken.
Ten slotte zullen we verschillende machine learning-modellen toepassen op de schaarse data en uitleggen waarom deze modellen geschikt zijn voor schaarse data.
In het hele artikel zal ik voornamelijk de scikit-learn-bibliotheek gebruiken, en als je de code en argumenten wilt wijzigen, zal ik ook de officiële documentatielinks geven.
Laten we nu beginnen met de veelvoorkomende problemen met schaarse gegevens.
Schaarse gegevens kunnen unieke uitdagingen vormen voor gegevensanalyse. We hebben al vermeld dat enkele van de meest voorkomende problemen zijn: overfitting, verlies van goede gegevens, geheugenproblemen en tijdsproblemen.
Laten we ze nu eens in detail bekijken.

Afbeelding door auteur
overfitting
Overfitting treedt op wanneer een model te complex wordt en ruis in de gegevens begint vast te leggen in plaats van de onderliggende patronen.
In schaarse gegevens kan er een groot aantal kenmerken zijn, maar slechts een paar daarvan zijn echt relevant voor de analyse. Dit kan het moeilijk maken om te bepalen welke functies belangrijk zijn en welke niet.
Als gevolg hiervan kan een model te veel aanpassen aan ruis in de gegevens en slecht presteren op nieuwe gegevens.
Als u nieuw bent met machine learning of meer wilt weten, kunt u dat doen in de scikit-learn documentatie over overfitting.
Goede gegevens verliezen
Een van de grootste problemen met schaarse gegevens is dat het kan leiden tot het verlies van potentieel bruikbare informatie.
Wanneer we zeer beperkte gegevens hebben, wordt het moeilijker om betekenisvolle patronen of relaties in die gegevens te identificeren. Dit komt omdat de ruis en willekeur die inherent zijn aan elke gegevensset, essentiële kenmerken gemakkelijker kunnen verdoezelen wanneer de gegevens schaars zijn.
Bovendien, omdat de hoeveelheid beschikbare gegevens beperkt is, is de kans groter dat we enkele van de echt waardevolle patronen of relaties in de gegevens zullen missen. Dit is met name het geval in gevallen waarin de gegevens schaars zijn vanwege een gebrek aan steekproeven, in plaats van simpelweg te ontbreken. In dergelijke gevallen zijn we ons misschien niet eens bewust van de ontbrekende gegevenspunten en realiseren we ons dus misschien niet dat we waardevolle informatie verliezen.
Daarom kan belangrijke informatie verloren gaan als er te veel functies worden verwijderd of als de gegevens te veel worden gecomprimeerd, wat resulteert in een minder nauwkeurig model.
Geheugen probleem
Door de grote omvang van de dataset kunnen er geheugenproblemen ontstaan. Schaarse gegevens resulteren vaak in veel functies en het opslaan van deze gegevens kan rekenkundig duur zijn. Dit kan de hoeveelheid gegevens beperken die tegelijk kan worden verwerkt of kan aanzienlijke computerbronnen vereisen.
Here u kunt verschillende strategieën zien om uw gegevens te schalen door scikit-learn te gebruiken.
Tijd probleem
Het tijdsprobleem kan ook optreden door de grote omvang van de dataset. Sparse gegevens kunnen langere verwerkingstijden vereisen, vooral wanneer het gaat om een groot aantal functies. Dit kan de snelheid waarmee gegevens kunnen worden verwerkt beperken, wat problematisch kan zijn in tijdgevoelige toepassingen.

Afbeelding door auteur
Schaarse gegevens vormen een uitdaging bij gegevensanalyse vanwege het lage voorkomen van niet-nulwaarden. Er zijn echter verschillende methoden beschikbaar om dit probleem te verminderen.
Een gebruikelijke benadering is het verwijderen van de functie die schaarste in de dataset veroorzaakt.
Een andere optie is om Principal Component Analysis (PCA) te gebruiken om de dimensionaliteit van de dataset te verminderen terwijl belangrijke informatie behouden blijft.
Functie-hashing is een andere techniek die kan worden gebruikt, waarbij kenmerken worden toegewezen aan een vector met een vaste lengte.
T-Distributed Stochastic Neighbor Embedding (t-SNE) is een andere handige methode die kan worden gebruikt om hoogdimensionale datasets te visualiseren.
Naast deze technieken is het cruciaal om een geschikt machine learning-model te selecteren dat schaarse gegevens kan verwerken, zoals SVM of logistische regressie.
Door deze strategieën te implementeren, kan men de uitdagingen die gepaard gaan met schaarse gegevens in gegevensanalyse effectief aanpakken.
Laten we nu beginnen met de tactieken die worden gebruikt om schaarse gegevens te verminderen, daarna gaan we dieper in op de modellen.
Verwijder het!
Bij het werken met schaarse gegevens is een benadering het verwijderen van objecten die meestal nulwaarden bevatten. Dit kan worden gedaan door een drempel in te stellen voor het percentage niet-nulwaarden in elke functie. Elk kenmerk dat onder deze drempel valt, kan uit de dataset worden verwijderd.
Deze aanpak kan helpen de dimensionaliteit van de dataset te verminderen en de prestaties van bepaalde machine learning-algoritmen te verbeteren.
Code Voorbeeld
In dit voorbeeld stellen we de dimensies van de dataset in, evenals het sparsity-niveau, dat bepaalt hoeveel waarden in de dataset nul zullen zijn.
Vervolgens genereren we willekeurige gegevens met het opgegeven sparsity-niveau om te controleren of onze methode werkt of niet. Bij deze stap berekenen we de sparsity om daarna te vergelijken.
Vervolgens stelt de code het aantal te verwijderen nullen in en verwijdert willekeurig een specifiek aantal nullen uit de dataset. Vervolgens herberekenen we de schaarsheid van de gewijzigde dataset om te controleren of onze methode werkt of niet.
Ten slotte berekenen we de schaarsheid opnieuw om de veranderingen te zien.
Hier is de code.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Set the number of zeros to remove
num_zeros_to_remove = 50000 # Remove a specific number of zeros randomly from the dataset
zero_indices = np.argwhere(data == 0)
zeros_to_remove = np.random.choice( zero_indices.shape[0], num_zeros_to_remove, replace=False
)
data[ zero_indices[zeros_to_remove, 0], zero_indices[zeros_to_remove, 1]
] = np.nan # Calculate the sparsity of the modified dataset num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print( "Sparsity after removing {} zeros:".format(num_zeros_to_remove), sparsity
)
Hier is de uitvoer.

PCA
PCA is een populaire techniek voor dimensionaliteitsreductie. Het identificeert de belangrijkste componenten van de gegevens, de richtingen waarin de gegevens het meest variëren.
Deze hoofdcomponenten kunnen vervolgens worden gebruikt om de gegevens in een lager-dimensionale ruimte weer te geven.
In de context van schaarse gegevens kan PCA worden gebruikt om de belangrijkste kenmerken te identificeren die de meeste variatie in de gegevens bevatten.
Door alleen deze kenmerken te selecteren, kunnen we de dimensionaliteit van de dataset verminderen terwijl de meeste belangrijke informatie behouden blijft.
U kunt PCA implementeren door gebruik te maken van de sci-kit leerbibliotheek, zoals we hierna zullen doen in het codevoorbeeld. Here is de officiële documentatie als u er meer over wilt weten.
Code Voorbeeld
Om PCA toe te passen op schaarse gegevens, kunnen we de scikit-learn-bibliotheek in Python gebruiken.
De bibliotheek biedt een PCA-klasse die we kunnen gebruiken om een PCA-model aan te passen aan de gegevens en het om te zetten in een lager-dimensionale ruimte.
In het eerste gedeelte van de volgende code maken we een gegevensset zoals we in het vorige gedeelte hebben gedaan, met een bepaalde dimensie en schaarsheid.
In het tweede deel passen we PCA toe om de dimensie van de dataset terug te brengen tot 10. Daarna zullen we de schaarsheid opnieuw berekenen.
Hier is de code.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply PCA to the dataset
pca = PCA(n_components=10)
data_pca = pca.fit_transform(data)
# Calculate the sparsity of the reduced dataset
num_zeros = (data_pca == 0).sum()
total_elements = data_pca.shape[0] * data_pca.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after PCA: {sparsity:.4f}")
Hier is de uitvoer.

Functie hashen
Een andere methode om met schaarse gegevens te werken, wordt feature-hashing genoemd. Deze benadering converteert elk kenmerk naar een reeks waarden met een vaste lengte met behulp van een hashing-functie.
De hashing-functie wijst elk invoerkenmerk toe aan een reeks indices in de array met vaste lengte. De waarden worden bij elkaar opgeteld als meerdere invoerfuncties aan dezelfde index worden toegewezen. Feature-hashing kan handig zijn voor grote datasets waarbij het opslaan van een groot feature-woordenboek niet haalbaar is.
We zullen dit samen behandelen in de volgende sectie, maar als je er dieper op wilt ingaan, hier je kunt de officiële documentatie van de functiehash bekijken in de scikit-learn-bibliotheek.
Code Voorbeeld
Hier gebruiken we opnieuw dezelfde methode bij het maken van datasets.
Vervolgens passen we feature-hashing toe op de dataset met behulp van de FeatureHasher-klasse van scikit-learn.
We specificeren het aantal uitvoerfuncties met de n_functies parameter en het invoertype als een woordenboek met de invoer_type parameter.
Vervolgens transformeren we de invoergegevens in gehashte arrays met behulp van de transformatiemethode van het FeatureHasher-object.
Ten slotte berekenen we de schaarsheid van de resulterende dataset.
Hier is de code.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply feature hashing to the dataset
hasher = FeatureHasher(n_features=10, input_type="dict")
data_dict = [ dict(("feature" + str(i), val) for i, val in enumerate(row)) for row in data
]
data_hashed = hasher.transform(data_dict).toarray() # Calculate the sparsity of the reduced dataset
num_zeros = (data_hashed == 0).sum()
total_elements = data_hashed.shape[0] * data_hashed.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after feature hashing: {sparsity:.4f}")
Hier is de uitvoer.
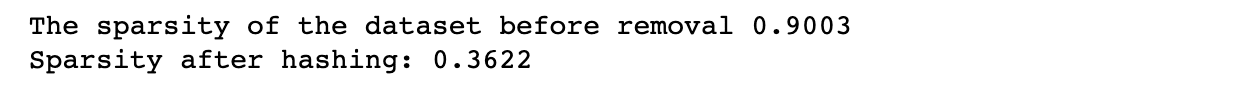
t-SNE Inbedding
t-SNE (t-Distributed Stochastic Neighbor Embedding) is een niet-lineaire dimensionaliteitsreductietechniek die wordt gebruikt om hoogdimensionale gegevens te visualiseren. Het vermindert de dimensionaliteit van de gegevens met behoud van de globale structuur en is een populair hulpmiddel geworden bij machine learning voor het visualiseren en clusteren van hoogdimensionale gegevens.
t-SNE is met name handig voor het werken met schaarse gegevens, omdat het de dimensionaliteit van de gegevens effectief kan verminderen terwijl de structuur behouden blijft. Het t-SNE-algoritme werkt door paarsgewijze afstanden tussen gegevenspunten in hoog- en laagdimensionale ruimtes te berekenen. Het minimaliseert vervolgens het verschil tussen deze afstanden in hoog- en laagdimensionale ruimte.
Om t-SNE te gebruiken met schaarse gegevens, moeten de gegevens eerst worden omgezet in een dichte matrix. Dit kan met behulp van verschillende technieken, zoals PCA of feature-hashing. Zodra de gegevens zijn geconverteerd, kan t-SNE hoog-x zijn om een laag-dimensionale inbedding van de gegevens te verkrijgen.
Ook als je nieuwsgierig bent naar t-SNE, hier is de officiële documentatie van de scikit-leer om meer te zien.
Code Voorbeeld
De volgende code stelt eerst de dimensies van de dataset en het sparsity-niveau in, genereert willekeurige gegevens met het opgegeven sparsity-niveau en berekent de sparsity van de dataset voordat t-SNE wordt toegepast, zoals we deden in de vorige voorbeelden.
Het past vervolgens t-SNE toe op de dataset met 3 componenten en berekent de schaarsheid van de resulterende t-SNE-inbedding. Ten slotte drukt het de schaarsheid van de t-SNE-inbedding af.
Hier is de code.
import numpy as np # Set the dimensions of the dataset
num_rows = 1000
num_cols = 100 # Set the sparsity level of the dataset
sparsity = 0.9 # Generate random data with the specified sparsity level
data = np.random.random((num_rows, num_cols))
data[data sparsity] = 0 # Calculate the sparsity of the dataset
num_zeros = (data == 0).sum()
total_elements = data.shape[0] * data.shape[1]
sparsity = num_zeros / total_elements print(f"The sparsity of the dataset before removal {sparsity:.4f}") # Apply t-SNE to the dataset
tsne = TSNE(n_components=3)
data_tsne = tsne.fit_transform(data) # Calculate the sparsity of the t-SNE embedding
num_zeros = (data_tsne == 0).sum()
total_elements = data_tsne.shape[0] * data_tsne.shape[1]
sparsity = num_zeros / total_elements print(f"Sparsity after t-SNE: {sparsity:.4f}")
Hier is de uitvoer.

Nu we de uitdagingen van het werken met schaarse data hebben aangepakt, kunnen we machine learning-modellen verkennen die speciaal zijn ontworpen om goed te presteren met schaarse data.
Deze modellen kunnen omgaan met de unieke kenmerken van schaarse gegevens, zoals een groot aantal kenmerken met veel nullen en beperkte informatie, waardoor het een uitdaging kan zijn om nauwkeurige voorspellingen te doen met traditionele modellen.
Door modellen te gebruiken die expliciet zijn ontworpen voor schaarse gegevens, kunnen we ervoor zorgen dat onze voorspellingen nauwkeuriger en betrouwbaarder zijn.
Laten we het nu hebben over de modellen die goed zijn voor schaarse gegevens.
SVC (ondersteunde vectorclassificator)
SVC (Support Vector Classifier) met de lineaire kernel kan goed presteren met schaarse gegevens omdat het een subset van trainingspunten, ook wel ondersteuningsvectoren genoemd, gebruikt om voorspellingen te doen. Dit betekent dat het efficiënt om kan gaan met hoog-dimensionale, schaarse gegevens.
U kunt Support Vector ook gebruiken voor regressie.
Ik legde de Steun Vector Machine hier als u meer wilt weten over het Support Vector-algoritme, zowel classificatie als regressie.
Logistische regressie
Dit kan ook goed werken met schaarse gegevens, omdat logistische regressie een regularisatieterm gebruikt om de modelcomplexiteit te beheersen, wat kan helpen voorkomen dat er te veel wordt toegepast op schaarse datasets.
Als u meer wilt weten over logistische regressie en ook over andere classificatie-algoritmen, vindt u hier de Overzicht van machine learning-algoritmen: classificatie.
KNeighboursClassifier
Dit algoritme kan goed werken met schaarse gegevens, omdat het afstanden tussen gegevenspunten berekent en hoog-dimensionale gegevens kan verwerken.
Je kunt KNN en andere zien machine learning-algoritmen hier die je moet weten voor data science.
MLP-classificatie
De MLPClassifier kan goed presteren met schaarse gegevens wanneer de invoergegevens zijn gestandaardiseerd, omdat het gradiëntafdaling gebruikt voor optimalisatie.
Here je kunt de implementatie van MLP Classifier zien, samen met een heleboel andere algoritmen, met behulp van ChatGPT.
DecisionTreeClassifier
Het kan goed werken met schaarse gegevens wanneer het aantal functies klein is. Als je niets weet over beslisbomen, heb ik het uitgelegd beslisbomen en willekeurige bossen hier, wat ons uiteindelijke model zal zijn voor het analyseren van de modellen voor schaarse gegevens.
RandomForestClassifier
De RandomForestClassifier kan goed werken met schaarse gegevens wanneer het aantal functies klein is.

Afbeelding door auteur
Nu zal ik u laten zien hoe deze modellen presteren op de gegenereerde gegevens. Maar ik zal een ander algoritme toevoegen om te zien of deze algoritmen beter zullen presteren dan dit algoritme (wat doorgaans niet goed is voor schaarse gegevens) of niet.
Code Voorbeeld
In deze sectie testen we meerdere machine learning-modellen op een schaarse dataset, een dataset met veel lege waarden of nulwaarden.
We zullen de schaarsheid van de dataset berekenen en de modellen evalueren met behulp van de F1-score.
Vervolgens maken we een dataframe met de F1-scores voor elk model om hun prestaties te vergelijken. We filteren ook alle waarschuwingen uit die tijdens het evaluatieproces kunnen verschijnen.
import numpy as np
from scipy.sparse import random
import numpy as np
from scipy.sparse import random
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression, Lasso
from sklearn.cluster import KMeans
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.exceptions import ConvergenceWarning
import warnings # Generate a sparse dataset
X = random(1000, 20, density=0.1, format="csr", random_state=42)
y = np.random.randint(2, size=1000) # Calculate the sparsity of the dataset
sparsity = 1.0 - X.nnz / float(X.shape[0] * X.shape[1])
print("Sparsity:", sparsity) X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
) # Train and evaluate multiple classifiers
classifiers = [ SVC(kernel="linear"), LogisticRegression(), KMeans( n_clusters=2, init="k-means++", max_iter=100, random_state=42, algorithm="full", ), KNeighborsClassifier(n_neighbors=5), MLPClassifier( hidden_layer_sizes=(100, 50), max_iter=1000, alpha=0.01, solver="sgd", verbose=0, random_state=21, tol=0.000000001, ), DecisionTreeClassifier(), RandomForestClassifier(),
] # Create an empty DataFrame with column names
df = pd.DataFrame(columns=["Classifier", "F1 Score"]) # Filter out the specific warning
warnings.filterwarnings( "ignore", category=ConvergenceWarning
) # Filter warning that mlp classifier will possibly print out. for clf in classifiers: clf.fit(X_train, y_train) y_pred = clf.predict(X_test) f1 = f1_score(y_test, y_pred) df = pd.concat( [ df, pd.DataFrame( {"Classifier": [type(clf).__name__], "F1 Score": [f1]} ), ], ignore_index=True, )
df = df.sort_values(by="F1 Score", ascending=True)
df
Hier is de uitvoer.
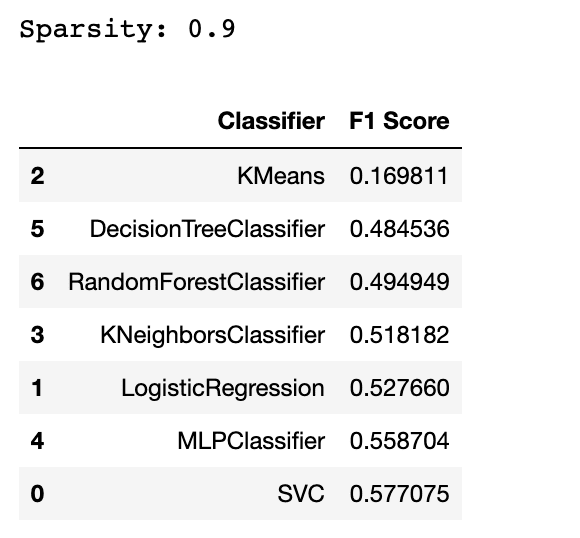
U zou nu een algoritme kunnen vangen dat niet goed geschikt is voor de schaarse gegevens. Ja, het antwoord is de KMeans. Maar waarom?
KMeans is doorgaans niet goed geschikt voor schaarse gegevens omdat het is gebaseerd op afstandsmetingen, wat problematisch kan zijn met hoog-dimensionale, schaarse gegevens.
Er zijn ook enkele algoritmen die we niet eens kunnen proberen. Als u bijvoorbeeld de GaussianNB-classificatie in deze lijst probeert op te nemen, krijgt u een foutmelding. Het suggereert dat de GaussianNB-classificatie dichte gegevens verwacht in plaats van schaarse gegevens. Dit komt omdat de GaussianNB-classificatie ervan uitgaat dat de invoergegevens de Gaussiaanse verdeling volgen en niet geschikt is voor schaarse gegevens.
Concluderend kan het werken met schaarse gegevens een uitdaging zijn vanwege verschillende problemen zoals overfitting, verlies van goede gegevens, geheugen en tijdsproblemen.
Er zijn echter verschillende methoden beschikbaar om met schaarse functies te werken, waaronder het verwijderen van functies, het gebruik van PCA en het hashen van functies.
Bovendien zijn bepaalde machine learning-modellen zoals SVM, Logistic Regression, Lasso, Decision Tree, Random Forest, MLP en k-naaste buren zeer geschikt voor het verwerken van schaarse gegevens.
Deze modellen zijn ontworpen om efficiënt om te gaan met hoogdimensionale en schaarse gegevens, waardoor ze de beste keuze zijn voor problemen met schaarse gegevens. Het gebruik van deze methoden en modellen kan de nauwkeurigheid van uw model verbeteren en tijd en middelen besparen.
Nate Rosidi is een datawetenschapper en in productstrategie. Hij is ook een adjunct-professor onderwijsanalyse en is de oprichter van StrataScratch, een platform dat datawetenschappers helpt bij het voorbereiden van hun interviews met echte interviewvragen van topbedrijven. Maak contact met hem op Twitter: StrataScratch or LinkedIn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/04/best-machine-learning-model-sparse-data.html?utm_source=rss&utm_medium=rss&utm_campaign=best-machine-learning-model-for-sparse-data

