Bij het inzetten van een groot taalmodel (LLM) zijn beoefenaars van machine learning (ML) doorgaans geïnteresseerd in twee metingen van de prestaties van het model: latentie, gedefinieerd door de tijd die nodig is om een enkel token te genereren, en doorvoer, gedefinieerd door het aantal gegenereerde tokens. per seconde. Hoewel een enkel verzoek aan het geïmplementeerde eindpunt een doorvoer zou vertonen die ongeveer gelijk is aan het omgekeerde van de modellatentie, is dit niet noodzakelijkerwijs het geval wanneer meerdere gelijktijdige verzoeken tegelijkertijd naar het eindpunt worden verzonden. Als gevolg van modelservingtechnieken, zoals continue batchverwerking van gelijktijdige verzoeken aan de clientzijde, hebben latentie en doorvoer een complexe relatie die aanzienlijk varieert op basis van de modelarchitectuur, serviceconfiguraties, hardware van het instancetype, het aantal gelijktijdige verzoeken en variaties in invoerpayloads, zoals als aantal invoertokens en uitvoertokens.
Dit bericht onderzoekt deze relaties via een uitgebreide benchmarking van LLM's die beschikbaar zijn in Amazon SageMaker JumpStart, inclusief Llama 2-, Falcon- en Mistral-varianten. Met SageMaker JumpStart kunnen ML-beoefenaars kiezen uit een brede selectie openbaar beschikbare basismodellen die ze kunnen inzetten op specifieke Amazon Sage Maker instances binnen een netwerkgeïsoleerde omgeving. We bieden theoretische principes over hoe specificaties van versnellers de LLM-benchmarking beïnvloeden. We laten ook de impact zien van het implementeren van meerdere instanties achter één enkel eindpunt. Ten slotte bieden we praktische aanbevelingen voor het afstemmen van het SageMaker JumpStart-implementatieproces op uw vereisten op het gebied van latentie, doorvoer, kosten en beperkingen op beschikbare exemplaartypen. Alle benchmarkresultaten en aanbevelingen zijn gebaseerd op een veelzijdige notitieboekje die u kunt aanpassen aan uw gebruikssituatie.
Eindpuntbenchmarking geïmplementeerd
De volgende afbeelding toont de waarden met de laagste latenties (links) en de hoogste doorvoer (rechts) voor implementatieconfiguraties voor verschillende modeltypen en exemplaartypen. Belangrijk is dat elk van deze modelimplementaties standaardconfiguraties gebruikt zoals geleverd door SageMaker JumpStart, gegeven de gewenste model-ID en het gewenste exemplaartype voor implementatie.
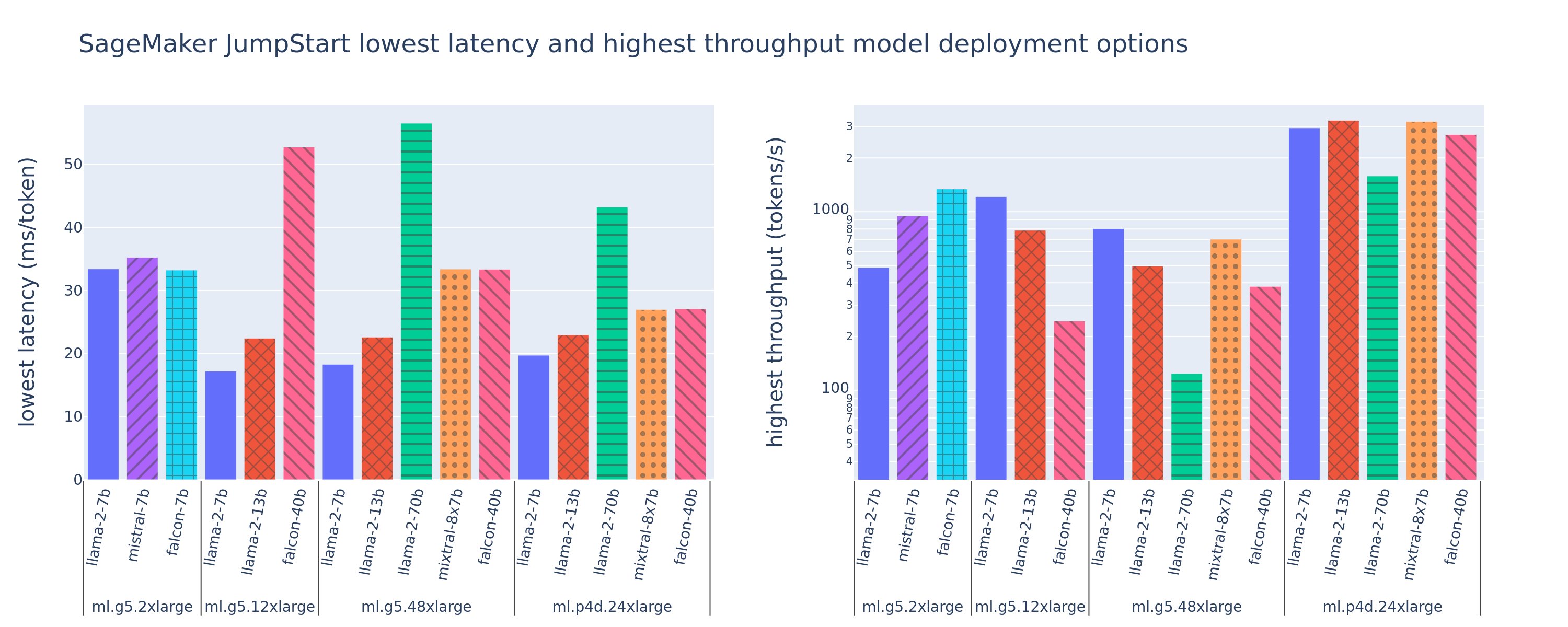
Deze latentie- en doorvoerwaarden komen overeen met payloads met 256 invoertokens en 256 uitvoertokens. De configuratie met de laagste latentie beperkt het model voor één gelijktijdige aanvraag, en de configuratie met de hoogste doorvoer maximaliseert het mogelijke aantal gelijktijdige aanvragen. Zoals we in onze benchmarking kunnen zien, verhoogt het verhogen van gelijktijdige verzoeken monotoon de doorvoer, terwijl de verbetering voor grote gelijktijdige verzoeken afneemt. Bovendien worden modellen volledig geshard op het ondersteunde exemplaar. Omdat de ml.g5.48xlarge-instantie bijvoorbeeld 8 GPU's heeft, worden alle SageMaker JumpStart-modellen die deze instantie gebruiken, geshard met behulp van tensor-parallellisme op alle acht beschikbare versnellers.
Uit deze figuur kunnen we enkele conclusies trekken. Ten eerste worden niet alle modellen op alle instances ondersteund; sommige kleinere modellen, zoals Falcon 7B, ondersteunen geen model-sharding, terwijl grotere modellen hogere rekenresourcevereisten vereisen. Ten tweede verbeteren de prestaties doorgaans naarmate de sharding toeneemt, maar dit hoeft niet noodzakelijkerwijs te verbeteren voor kleine modellen. Dit komt omdat kleine modellen zoals 7B en 13B een aanzienlijke communicatieoverhead met zich meebrengen wanneer ze over te veel versnellers worden verdeeld. We bespreken dit later uitvoeriger. Ten slotte hebben ml.p4d.24xlarge-instanties doorgaans een aanzienlijk betere doorvoer dankzij verbeteringen in de geheugenbandbreedte van A100 ten opzichte van A10G GPU's. Zoals we later bespreken, hangt de beslissing om een bepaald exemplaartype te gebruiken af van uw implementatievereisten, inclusief latentie, doorvoer en kostenbeperkingen.
Hoe kunt u deze configuratiewaarden met de laagste latentie en de hoogste doorvoer verkrijgen? Laten we beginnen met het uitzetten van de latentie versus de doorvoer voor een Llama 2 7B-eindpunt op een ml.g5.12xlarge-instantie voor een payload met 256 invoertokens en 256 uitvoertokens, zoals te zien in de volgende curve. Er bestaat een soortgelijke curve voor elk geïmplementeerd LLM-eindpunt.

Naarmate de gelijktijdigheid toeneemt, nemen de doorvoer en de latentie ook monotoon toe. Daarom treedt het laagste latentiepunt op bij een gelijktijdige aanvraagwaarde van 1, en kunt u op kosteneffectieve wijze de systeemdoorvoer verhogen door de gelijktijdige aanvragen te vergroten. Er bestaat een duidelijke 'knie' in deze curve, waarbij het duidelijk is dat de doorvoerwinst die gepaard gaat met extra gelijktijdigheid niet opweegt tegen de daarmee samenhangende toename in latentie. De exacte locatie van deze knie is gevalspecifiek; sommige beoefenaars definiëren de knie op het punt waar een vooraf gespecificeerde latentievereiste wordt overschreden (bijvoorbeeld 100 ms/token), terwijl anderen belastingtestbenchmarks en wachtrijtheoriemethoden zoals de halve latentieregel kunnen gebruiken, en anderen kunnen gebruik maken van theoretische versnellerspecificaties.
We merken ook op dat het maximale aantal gelijktijdige verzoeken beperkt is. In de voorgaande afbeelding eindigt de lijntracering met 192 gelijktijdige verzoeken. De bron van deze beperking is de time-outlimiet voor SageMaker-aanroepen, waarbij SageMaker-eindpunten na 60 seconden een time-out voor een aanroepreactie geven. Deze instelling is accountspecifiek en kan niet worden geconfigureerd voor een individueel eindpunt. Voor LLM's kan het genereren van een groot aantal uitvoertokens seconden of zelfs minuten duren. Daarom kunnen grote invoer- of uitvoerladingen ervoor zorgen dat de aanroepaanvragen mislukken. Als het aantal gelijktijdige verzoeken bovendien erg groot is, zullen veel verzoeken lange wachtrijtijden ervaren, waardoor deze time-outlimiet van 60 seconden wordt opgedreven. Voor het doel van dit onderzoek gebruiken we de time-outlimiet om de maximaal mogelijke doorvoer voor een modelimplementatie te definiëren. Belangrijk is dat, hoewel een SageMaker-eindpunt een groot aantal gelijktijdige verzoeken kan afhandelen zonder een time-out voor de aanroepreactie te observeren, u wellicht het maximale aantal gelijktijdige verzoeken wilt definiëren met betrekking tot de knie in de latentie-doorvoercurve. Dit is waarschijnlijk het punt waarop u horizontaal schalen gaat overwegen, waarbij één eindpunt meerdere exemplaren van modelreplica's voorziet en de binnenkomende aanvragen over de replica's verdeelt, om meer gelijktijdige aanvragen te ondersteunen.
Als we nog een stap verder gaan, bevat de volgende tabel benchmarkingresultaten voor verschillende configuraties voor het Llama 2 7B-model, inclusief een verschillend aantal invoer- en uitvoertokens, instantietypen en het aantal gelijktijdige verzoeken. Merk op dat de voorgaande figuur slechts één rij van deze tabel weergeeft.
| . | Doorvoer (tokens/sec) | Latentie (ms/token) | ||||||||||||||||||
| Gelijktijdige verzoeken | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Aantal totale tokens: 512, Aantal uitvoertokens: 256 | ||||||||||||||||||||
| ml.g5.2xgroot | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xgroot | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xgroot | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xgroot | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Aantal totale tokens: 4096, Aantal uitvoertokens: 256 | ||||||||||||||||||||
| ml.g5.2xgroot | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xgroot | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xgroot | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xgroot | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
We zien enkele aanvullende patronen in deze gegevens. Wanneer de contextgrootte wordt vergroot, neemt de latentie toe en neemt de doorvoer af. Op ml.g5.2xlarge met een gelijktijdigheid van 1 is de doorvoer bijvoorbeeld 30 tokens/sec wanneer het totale aantal tokens 512 is, versus 20 tokens/sec als het totale aantal tokens 4,096 is. Dit komt omdat het meer tijd kost om de grotere invoer te verwerken. We kunnen ook zien dat het vergroten van de GPU-mogelijkheden en sharding invloed heeft op de maximale doorvoer en de maximaal ondersteunde gelijktijdige verzoeken. De tabel laat zien dat Llama 2 7B met name verschillende maximale doorvoerwaarden heeft voor verschillende instantietypen, en deze maximale doorvoerwaarden komen voor bij verschillende waarden van gelijktijdige verzoeken. Deze kenmerken zouden een ML-beoefenaar ertoe aanzetten de kosten van de ene instantie boven de andere te rechtvaardigen. Gegeven een lage latentievereiste kan de arts bijvoorbeeld een ml.g5.12xlarge-instantie (4 A10G GPU's) selecteren in plaats van een ml.g5.2xlarge-instantie (1 A10G GPU). Als er een hoge doorvoervereiste wordt gegeven, zou het gebruik van een ml.p4d.24xlarge-instantie (8 A100 GPU's) met volledige sharding alleen gerechtvaardigd zijn bij hoge gelijktijdigheid. Houd er echter rekening mee dat het vaak nuttig is om in plaats daarvan meerdere inferentiecomponenten van een 7B-model op één enkele ml.p4d.24xlarge-instantie te laden; dergelijke ondersteuning voor meerdere modellen wordt later in dit bericht besproken.
De voorgaande waarnemingen zijn gedaan voor het Llama 2 7B-model. Soortgelijke patronen blijven echter ook gelden voor andere modellen. Een belangrijk uitgangspunt is dat de prestatiecijfers voor latentie en doorvoer afhankelijk zijn van de payload, het instancetype en het aantal gelijktijdige verzoeken. U zult dus de ideale configuratie voor uw specifieke toepassing moeten vinden. Om de voorgaande cijfers voor uw gebruiksscenario te genereren, kunt u de link uitvoeren notitieboekje, waar u deze belastingtestanalyse kunt configureren voor uw model, exemplaartype en payload.
Begrijpen van de specificaties van de versneller
Het selecteren van geschikte hardware voor LLM-inferentie is sterk afhankelijk van specifieke gebruiksscenario's, gebruikerservaringsdoelen en de gekozen LLM. In dit gedeelte wordt geprobeerd inzicht te krijgen in de knie in de latentie-doorvoercurve met betrekking tot principes op hoog niveau gebaseerd op versnellerspecificaties. Deze principes alleen zijn niet voldoende om een beslissing te nemen: echte benchmarks zijn noodzakelijk. De voorwaarde apparaat wordt hier gebruikt om alle ML-hardwareversnellers te omvatten. We beweren dat de knie in de latentie-doorvoercurve wordt bepaald door een van twee factoren:
- De versneller heeft het geheugen uitgeput om KV-matrices in de cache op te slaan, dus daaropvolgende verzoeken worden in de wachtrij geplaatst
- De accelerator heeft nog steeds reservegeheugen voor de KV-cache, maar gebruikt een batchgrootte die groot genoeg is zodat de verwerkingstijd wordt bepaald door de latentie van rekenbewerkingen in plaats van door geheugenbandbreedte
Meestal geven we er de voorkeur aan beperkt te worden door de tweede factor, omdat dit impliceert dat de hulpbronnen van de versneller verzadigd zijn. Kortom, u maximaliseert de middelen waarvoor u heeft betaald. Laten we deze bewering eens nader onderzoeken.
KV-caching en apparaatgeheugen
Standaard transformator-aandachtsmechanismen berekenen de aandacht voor elk nieuw token ten opzichte van alle voorgaande tokens. De meeste moderne ML-servers cachen attentiesleutels en waarden in het apparaatgeheugen (DRAM) om herberekening bij elke stap te voorkomen. Dit heet dit KV-cache, en het groeit met de batchgrootte en reekslengte. Het definieert hoeveel gebruikersverzoeken parallel kunnen worden afgehandeld en bepaalt de knie in de latentie-doorvoercurve als er nog niet aan het rekengebonden regime in het eerder genoemde tweede scenario wordt voldaan, gegeven de beschikbare DRAM. De volgende formule is een ruwe benadering voor de maximale KV-cachegrootte.

In deze formule is B de batchgrootte en N het aantal versnellers. Het Llama 2 7B-model in FP16 (2 bytes/parameter) geserveerd op een A10G GPU (24 GB DRAM) verbruikt bijvoorbeeld ongeveer 14 GB, waardoor er 10 GB overblijft voor de KV-cache. Door de volledige contextlengte van het model (N = 4096) en de resterende parameters (n_layers=32, n_kv_attention_heads=32 en d_attention_head=128) in te voeren, laat deze expressie zien dat we beperkt zijn tot het parallel bedienen van een batchgrootte van vier gebruikers vanwege DRAM-beperkingen . Als u de overeenkomstige benchmarks in de vorige tabel bekijkt, is dit een goede benadering voor de waargenomen knie in deze latentie-doorvoercurve. Methoden zoals gegroepeerde vraagaandacht (GQA) kan de KV-cachegrootte verkleinen, in het geval van GQA vermindert het met dezelfde factor het aantal KV-heads.
Rekenkundige intensiteit en bandbreedte van het apparaatgeheugen
De groei van de rekenkracht van ML-versnellers heeft hun geheugenbandbreedte overtroffen, wat betekent dat ze veel meer berekeningen kunnen uitvoeren op elke byte aan gegevens in de hoeveelheid tijd die nodig is om toegang te krijgen tot die byte.
De rekenkundige intensiteit, of de verhouding tussen rekenbewerkingen en geheugentoegang, want een bewerking bepaalt of deze wordt beperkt door geheugenbandbreedte of rekencapaciteit op de geselecteerde hardware. Een A10G GPU (g5-instantietypefamilie) met 70 TFLOPS FP16 en een bandbreedte van 600 GB/sec kan bijvoorbeeld ongeveer 116 ops/byte berekenen. Een A100 GPU (p4d-instantietypefamilie) kan ongeveer 208 bewerkingen/byte berekenen. Als de rekenkundige intensiteit voor een transformatormodel onder die waarde ligt, is deze geheugengebonden; als het hoger is, is het computergebonden. Het aandachtsmechanisme voor Llama 2 7B vereist 62 ops/byte voor batchgrootte 1 (zie voor uitleg Een gids voor LLM-gevolgtrekking en prestaties), wat betekent dat het geheugengebonden is. Wanneer het aandachtsmechanisme geheugengebonden is, blijven dure FLOPS ongebruikt.
Er zijn twee manieren om de versneller beter te benutten en de rekenintensiteit te verhogen: de vereiste geheugentoegang voor de bewerking verminderen (dit is wat FlashAandacht richt zich op) of vergroot de batchgrootte. Het is echter mogelijk dat we onze batchgrootte niet voldoende kunnen vergroten om een rekengebonden regime te bereiken als onze DRAM te klein is om de overeenkomstige KV-cache te bevatten. Een ruwe benadering van de kritische batchgrootte B* die rekengebonden en geheugengebonden regimes scheidt voor standaard GPT-decoder-inferentie wordt beschreven door de volgende uitdrukking, waarbij A_mb de geheugenbandbreedte van de accelerator is, A_f de accelerator FLOPS is en N het getal is van versnellers. Deze kritische batchgrootte kan worden afgeleid door te bepalen waar de geheugentoegangstijd gelijk is aan de rekentijd. Verwijzen naar deze blog post om vergelijking 2 en de aannames ervan in meer detail te begrijpen.
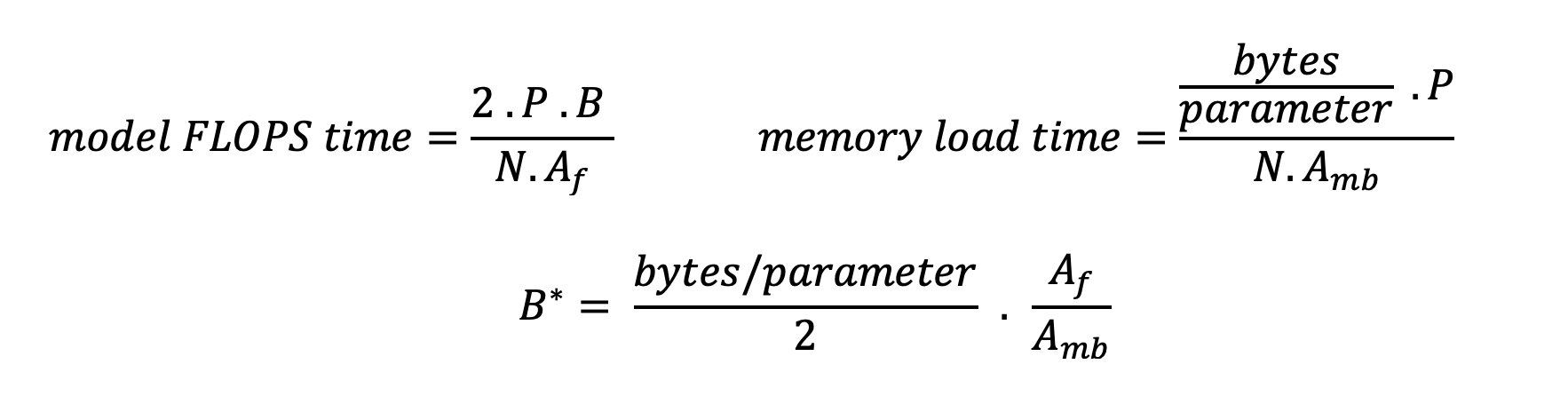
Dit is dezelfde ops/byte-verhouding die we eerder hebben berekend voor de A10G, dus de kritische batchgrootte op deze GPU is 116. Een manier om deze theoretische, kritische batchgrootte te benaderen is door de model-sharding te vergroten en de cache over meer N-accelerators te verdelen. Dit vergroot effectief de KV-cachecapaciteit en de geheugengebonden batchgrootte.
Een ander voordeel van model sharding is het splitsen van modelparameters en het laden van gegevens over N-accelerators. Dit type sharding is een type modelparallellisme dat ook wel wordt genoemd tensor parallellisme. Naïef is er N maal de geheugenbandbreedte en de rekenkracht in totaal. Ervan uitgaande dat er geen enkele overhead is (communicatie, software, enzovoort), zou dit de decoderingslatentie per token met N verminderen als we geheugengebonden zijn, omdat de tokendecoderingslatentie in dit regime gebonden is aan de tijd die nodig is om het model te laden gewichten en cache. In het echte leven resulteert het verhogen van de mate van sharding echter in een betere communicatie tussen apparaten om tussentijdse activeringen op elke modellaag te delen. Deze communicatiesnelheid wordt beperkt door de bandbreedte van de apparaatverbinding. Het is moeilijk om de impact ervan precies in te schatten (voor details, zie Model parallellisme), maar dit kan uiteindelijk geen voordelen meer opleveren of de prestaties verslechteren. Dit geldt vooral voor kleinere modellen, omdat kleinere gegevensoverdrachten tot lagere overdrachtssnelheden leiden.
Om ML-accelerators te vergelijken op basis van hun specificaties, raden we het volgende aan. Bereken eerst de geschatte kritische batchgrootte voor elk versnellertype volgens de tweede vergelijking en de KV-cachegrootte voor de kritische batchgrootte volgens de eerste vergelijking. Vervolgens kunt u de beschikbare DRAM op de versneller gebruiken om het minimale aantal versnellers te berekenen dat nodig is om aan de KV-cache en modelparameters te voldoen. Als u tussen meerdere versnellers kiest, geef dan prioriteit aan versnellers in volgorde van de laagste kosten per GB/sec geheugenbandbreedte. Benchmark ten slotte deze configuraties en verifieer wat de beste kosten/token zijn voor uw bovengrens van de gewenste latentie.
Selecteer een eindpuntimplementatieconfiguratie
Veel LLM's die door SageMaker JumpStart worden gedistribueerd, gebruiken de tekstgeneratie-inferentie (TGI) SageMaker-container voor het serveren van modellen. In de volgende tabel wordt besproken hoe u verschillende modelweergaveparameters kunt aanpassen om de modelweergave te beïnvloeden, wat van invloed is op de latentie-doorvoercurve, of om het eindpunt te beschermen tegen verzoeken die het eindpunt zouden overbelasten. Dit zijn de primaire parameters die u kunt gebruiken om uw eindpuntimplementatie voor uw gebruiksscenario te configureren. Tenzij anders aangegeven, gebruiken wij standaard payloadparameters voor het genereren van tekst en TGI-omgevingsvariabelen.
| Omgevingsvariabele | Omschrijving | SageMaker JumpStart-standaardwaarde |
| Model serveerconfiguraties | . | . |
MAX_BATCH_PREFILL_TOKENS |
Beperkt het aantal tokens in de voorvulbewerking. Met deze bewerking wordt de KV-cache gegenereerd voor een nieuwe invoerpromptreeks. Het is geheugenintensief en computergebonden, dus deze waarde beperkt het aantal tokens dat is toegestaan in een enkele prefill-bewerking. De decoderingsstappen voor andere query's worden onderbroken terwijl het vooraf invullen plaatsvindt. | 4096 (TGI-standaard) of modelspecifieke maximaal ondersteunde contextlengte (SageMaker JumpStart meegeleverd), afhankelijk van welke groter is. |
MAX_BATCH_TOTAL_TOKENS |
Bepaalt het maximale aantal tokens dat in een batch moet worden opgenomen tijdens het decoderen, of een enkele voorwaartse doorgang door het model. Idealiter is dit zo ingesteld dat het gebruik van alle beschikbare hardware wordt gemaximaliseerd. | Niet gespecificeerd (TGI-standaard). TGI zal deze waarde instellen met betrekking tot het resterende CUDA-geheugen tijdens het opwarmen van het model. |
SM_NUM_GPUS |
Het aantal scherven dat moet worden gebruikt. Dat wil zeggen het aantal GPU's dat wordt gebruikt om het model uit te voeren met behulp van tensor-parallellisme. | Instantie-afhankelijk (SageMaker JumpStart meegeleverd). Voor elke ondersteunde instantie voor een bepaald model biedt SageMaker JumpStart de beste instelling voor tensorparallellisme. |
| Configuraties om uw eindpunt te bewaken (stel deze in voor uw gebruiksscenario) | . | . |
MAX_TOTAL_TOKENS |
Dit beperkt het geheugenbudget van een enkel clientverzoek door het aantal tokens in de invoerreeks plus het aantal tokens in de uitvoerreeks te beperken (de max_new_tokens laadvermogenparameter). |
Modelspecifieke maximaal ondersteunde contextlengte. Bijvoorbeeld 4096 voor Lama 2. |
MAX_INPUT_LENGTH |
Identificeert het maximaal toegestane aantal tokens in de invoerreeks voor één clientverzoek. Dingen waarmee u rekening moet houden bij het verhogen van deze waarde zijn onder meer: langere invoerreeksen vereisen meer geheugen, wat de continue batchverwerking beïnvloedt, en veel modellen hebben een ondersteunde contextlengte die niet mag worden overschreden. | Modelspecifieke maximaal ondersteunde contextlengte. Bijvoorbeeld 4095 voor Lama 2. |
MAX_CONCURRENT_REQUESTS |
Het maximale aantal gelijktijdige aanvragen dat is toegestaan door het geïmplementeerde eindpunt. Nieuwe aanvragen die deze limiet overschrijden, zullen onmiddellijk een fout over het overbelasten van het model veroorzaken om een slechte latentie voor de huidige verwerkingsaanvragen te voorkomen. | 128 (TGI-standaard). Met deze instelling kunt u een hoge doorvoer verkrijgen voor verschillende gebruiksscenario's, maar u moet deze indien nodig vastzetten om time-outfouten bij SageMaker-aanroepen te beperken. |
De TGI-server maakt gebruik van continue batching, waarbij gelijktijdige aanvragen dynamisch worden samengevoegd om een enkele modelinferentie-voorwaartse doorgang te delen. Er zijn twee soorten voorwaartse passen: vooraf invullen en decoderen. Elke nieuwe aanvraag moet een enkele voorwaartse doorgang uitvoeren om de KV-cache voor de invoerreekstokens te vullen. Nadat de KV-cache is gevuld, voert een decodeervoorwaartse pass een enkele next-token-voorspelling uit voor alle batchverzoeken, die iteratief wordt herhaald om de uitvoerreeks te produceren. Wanneer er nieuwe verzoeken naar de server worden verzonden, moet de volgende decodeerstap wachten zodat de prefill-stap voor de nieuwe verzoeken kan worden uitgevoerd. Dit moet gebeuren voordat deze nieuwe verzoeken worden opgenomen in daaropvolgende continu batchgewijze decodeerstappen. Vanwege hardwarebeperkingen omvat de continue batchverwerking die wordt gebruikt voor het decoderen mogelijk niet alle verzoeken. Op dit punt komen verzoeken in een verwerkingswachtrij terecht en begint de inferentielatentie aanzienlijk toe te nemen met slechts een kleine doorvoerwinst.
Het is mogelijk om LLM-latentiebenchmarkanalyses te scheiden in latentie vooraf invullen, latentie decoderen en wachtrijlatentie. De tijd die elk van deze componenten verbruikt, is fundamenteel verschillend van aard: prefill is een eenmalige berekening, het decoderen vindt één keer plaats voor elk token in de uitvoerreeks, en wachtrijen omvatten serverbatchprocessen. Wanneer meerdere gelijktijdige verzoeken worden verwerkt, wordt het moeilijk om de latenties van elk van deze componenten te ontwarren, omdat de latentie die door een bepaald clientverzoek wordt ervaren zowel wachtrijlatenties omvat die worden veroorzaakt door de noodzaak om nieuwe gelijktijdige verzoeken vooraf in te vullen, als wachtrijlatenties die worden veroorzaakt door de opname van het verzoek in batch-decoderingsprocessen. Om deze reden richt dit bericht zich op end-to-end verwerkingslatentie. De knie in de latentie-doorvoercurve treedt op op het punt van verzadiging waar wachtrijlatenties aanzienlijk beginnen toe te nemen. Dit fenomeen doet zich voor bij elke modelinferentieserver en wordt aangestuurd door acceleratorspecificaties.
Algemene vereisten tijdens de implementatie zijn onder meer het voldoen aan een minimaal vereiste doorvoer, maximaal toegestane latentie, maximale kosten per uur en maximale kosten om 1 miljoen tokens te genereren. U moet deze vereisten afhankelijk stellen van payloads die verzoeken van eindgebruikers vertegenwoordigen. Een ontwerp dat aan deze vereisten voldoet, moet met veel factoren rekening houden, waaronder de specifieke modelarchitectuur, de grootte van het model, instancetypen en het aantal instances (horizontale schaling). In de volgende secties concentreren we ons op het implementeren van eindpunten om de latentie te minimaliseren, de doorvoer te maximaliseren en de kosten te minimaliseren. Deze analyse houdt rekening met 512 tokens in totaal en 256 uitvoertokens.
Minimaliseer latentie
Latentie is een belangrijke vereiste in veel real-time gebruiksscenario's. In de volgende tabel bekijken we de minimale latentie voor elk model en elk exemplaartype. U kunt een minimale latentie bereiken door in te stellen MAX_CONCURRENT_REQUESTS = 1.
| Minimale latentie (ms/token) | |||||
| Model ID | ml.g5.2xgroot | ml.g5.12xgroot | ml.g5.48xgroot | ml.p4d.24xgroot | ml.p4de.24xgroot |
| Lama 2 7B | 33 | 17 | 18 | 20 | - |
| Lama 2 7B Chat | 33 | 17 | 18 | 20 | - |
| Lama 2 13B | - | 22 | 23 | 23 | - |
| Lama 2 13B Chat | - | 23 | 23 | 23 | - |
| Lama 2 70B | - | - | 57 | 43 | - |
| Lama 2 70B Chat | - | - | 57 | 45 | - |
| Mistral 7B | 35 | - | - | - | - |
| Mistral 7B Instrueer | 35 | - | - | - | - |
| Mixtraal 8x7B | - | - | 33 | 27 | - |
| Valk 7B | 33 | - | - | - | - |
| Falcon 7B Instrueer | 33 | - | - | - | - |
| Valk 40B | - | 53 | 33 | 27 | - |
| Falcon 40B Instrueer | - | 53 | 33 | 28 | - |
| Valk 180B | - | - | - | - | 42 |
| Falcon 180B Chat | - | - | - | - | 42 |
Om een minimale latentie voor een model te bereiken, kunt u de volgende code gebruiken terwijl u uw gewenste model-ID en exemplaartype vervangt:
Houd er rekening mee dat de latentiegetallen veranderen afhankelijk van het aantal invoer- en uitvoertokens. Het implementatieproces blijft echter hetzelfde, behalve de omgevingsvariabelen MAX_INPUT_TOKENS en MAX_TOTAL_TOKENS. Hier worden deze omgevingsvariabelen ingesteld om de latentievereisten van het eindpunt te helpen garanderen, omdat grotere invoerreeksen de latentievereiste kunnen schenden. Merk op dat SageMaker JumpStart al de andere optimale omgevingsvariabelen biedt bij het selecteren van het exemplaartype; Als u bijvoorbeeld ml.g5.12xlarge gebruikt, wordt dit ingesteld SM_NUM_GPUS tot 4 in de modelomgeving.
Maximaliseer de doorvoer
In deze sectie maximaliseren we het aantal gegenereerde tokens per seconde. Dit wordt doorgaans bereikt bij het maximale aantal geldige gelijktijdige aanvragen voor het model en het exemplaartype. In de volgende tabel rapporteren we de doorvoer die is bereikt bij de grootste gelijktijdige verzoekwaarde die is bereikt voordat er voor een verzoek een time-out voor SageMaker-aanroep optreedt.
| Maximale doorvoer (tokens/sec), gelijktijdige verzoeken | |||||
| Model ID | ml.g5.2xgroot | ml.g5.12xgroot | ml.g5.48xgroot | ml.p4d.24xgroot | ml.p4de.24xgroot |
| Lama 2 7B | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Lama 2 7B Chat | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Lama 2 13B | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Lama 2 13B Chat | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Lama 2 70B | - | - | 124 (16) | 1585 (256) | - |
| Lama 2 70B Chat | - | - | 114 (16) | 1546 (256) | - |
| Mistral 7B | 947 (64) | - | - | - | - |
| Mistral 7B Instrueer | 986 (128) | - | - | - | - |
| Mixtraal 8x7B | - | - | 701 (128) | 3196 (512) | - |
| Valk 7B | 1340 (128) | - | - | - | - |
| Falcon 7B Instrueer | 1313 (128) | - | - | - | - |
| Valk 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Falcon 40B Instrueer | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Valk 180B | - | - | - | - | 1100 (128) |
| Falcon 180B Chat | - | - | - | - | 1081 (128) |
Om maximale doorvoer voor een model te bereiken, kunt u de volgende code gebruiken:
Houd er rekening mee dat het maximale aantal gelijktijdige aanvragen afhankelijk is van het modeltype, het exemplaartype, het maximale aantal invoertokens en het maximale aantal uitvoertokens. Daarom moet u deze parameters instellen voordat u instelt MAX_CONCURRENT_REQUESTS.
Houd er ook rekening mee dat een gebruiker die geïnteresseerd is in het minimaliseren van de latentie vaak op gespannen voet staat met een gebruiker die geïnteresseerd is in het maximaliseren van de doorvoer. De eerste is geïnteresseerd in realtime reacties, terwijl de laatste geïnteresseerd is in batchverwerking, zodat de wachtrij van het eindpunt altijd verzadigd is, waardoor de downtime van de verwerking wordt geminimaliseerd. Gebruikers die de doorvoer willen maximaliseren, afhankelijk van de latentievereisten, zijn vaak geïnteresseerd in het opereren op de knie in de latentie-doorvoercurve.
Minimaliseer de kosten
De eerste optie om de kosten te minimaliseren is het minimaliseren van de kosten per uur. Hiermee kunt u een geselecteerd model op de SageMaker-instantie implementeren tegen de laagste kosten per uur. Voor realtime prijzen van SageMaker-instanties raadpleegt u Prijzen van Amazon SageMaker. Over het algemeen is het standaardinstantietype voor SageMaker JumpStart LLM's de goedkoopste implementatieoptie.
De tweede optie om de kosten te minimaliseren omvat het minimaliseren van de kosten voor het genereren van 1 miljoen tokens. Dit is een eenvoudige transformatie van de tabel die we eerder hebben besproken om de doorvoer te maximaliseren, waarbij je eerst de tijd kunt berekenen die nodig is in uren om 1 miljoen tokens te genereren (1e6 / doorvoer / 3600). U kunt deze tijd vervolgens vermenigvuldigen om 1 miljoen tokens te genereren met de prijs per uur van de opgegeven SageMaker-instantie.
Houd er rekening mee dat instanties met de laagste kosten per uur niet hetzelfde zijn als instanties met de laagste kosten om 1 miljoen tokens te genereren. Als de aanroepverzoeken bijvoorbeeld sporadisch zijn, kan een instantie met de laagste kosten per uur optimaal zijn, terwijl in de beperkingsscenario's de laagste kosten voor het genereren van een miljoen tokens geschikter kunnen zijn.
Tensor parallel versus multi-model afweging
In alle voorgaande analyses hebben we overwogen om één modelreplica te implementeren met een tensor parallelle graad die gelijk is aan het aantal GPU's op het implementatie-instantietype. Dit is het standaardgedrag van SageMaker JumpStart. Zoals eerder opgemerkt kan het sharden van een model de latentie en doorvoer van het model echter slechts tot een bepaalde limiet verbeteren, waarboven de communicatievereisten tussen apparaten de rekentijd domineren. Dit houdt in dat het vaak voordelig is om meerdere modellen met een lagere parallelle tensorgraad op één exemplaar te implementeren in plaats van één enkel model met een hogere parallelle tensorgraad.
Hier implementeren we Llama 2 7B- en 13B-eindpunten op ml.p4d.24xlarge-instanties met tensor parallelle (TP) graden van 1, 2, 4 en 8. Voor duidelijkheid in het modelgedrag laadt elk van deze eindpunten slechts één model.
| . | Doorvoer (tokens/sec) | Latentie (ms/token) | ||||||||||||||||||
| Gelijktijdige verzoeken | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| TP-graad | Lama 2 13B | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Lama 2 7B | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Onze eerdere analyses lieten al aanzienlijke doorvoervoordelen zien op ml.p4d.24xlarge-instances, wat zich vaak vertaalt in betere prestaties in termen van kosten voor het genereren van 1 miljoen tokens ten opzichte van de g5-instancefamilie onder hoge gelijktijdige verzoekbelastingomstandigheden. Deze analyse laat duidelijk zien dat u de afweging tussen model-sharding en modelreplicatie binnen één exemplaar moet overwegen; dat wil zeggen dat een volledig geshard model doorgaans niet het beste gebruik is van ml.p4d.24xlarge rekenbronnen voor 7B- en 13B-modelfamilies. Voor de 7B-modelfamilie verkrijgt u zelfs de beste doorvoer voor een enkele modelreplica met een tensor-parallelle graad van 4 in plaats van 8.
Vanaf hier kunt u extrapoleren dat de hoogste doorvoerconfiguratie voor het 7B-model een tensor parallelle graad van 1 met acht modelreplica's omvat, en dat de hoogste doorvoerconfiguratie voor het 13B-model waarschijnlijk een tensor parallelle graad van 2 met vier modelreplica's is. Voor meer informatie over hoe u dit kunt bereiken, raadpleegt u Verlaag de implementatiekosten van modellen met gemiddeld 50% met behulp van de nieuwste functies van Amazon SageMaker, die het gebruik van op inferentiecomponenten gebaseerde eindpunten demonstreert. Vanwege taakverdelingstechnieken, serverroutering en het delen van CPU-bronnen bereikt u mogelijk niet volledig een doorvoerverbetering die exact gelijk is aan het aantal replica's maal de doorvoer voor één replica.
Horizontaal schalen
Zoals eerder opgemerkt heeft elke eindpuntimplementatie een beperking op het aantal gelijktijdige verzoeken, afhankelijk van het aantal invoer- en uitvoertokens en het exemplaartype. Als dit niet voldoet aan uw vereisten voor doorvoer of gelijktijdige aanvragen, kunt u opschalen om meer dan één exemplaar achter het geïmplementeerde eindpunt te gebruiken. SageMaker voert automatisch taakverdeling uit van queries tussen instances. Met de volgende code wordt bijvoorbeeld een eindpunt geïmplementeerd dat door drie instanties wordt ondersteund:
De volgende tabel toont de doorvoerwinst als een factor van het aantal exemplaren voor het Llama 2 7B-model.
| . | . | Doorvoer (tokens/sec) | Latentie (ms/token) | ||||||||||||||
| . | Gelijktijdige verzoeken | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Aantal exemplaren | Instantietype | Aantal totale tokens: 512, Aantal uitvoertokens: 256 | |||||||||||||||
| 1 | ml.g5.2xgroot | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xgroot | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xgroot | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Met name de knie in de latentie-doorvoercurve verschuift naar rechts omdat hogere aantallen instanties grotere aantallen gelijktijdige verzoeken binnen het eindpunt met meerdere instanties kunnen verwerken. Voor deze tabel geldt de waarde voor gelijktijdige aanvragen voor het gehele eindpunt, niet voor het aantal gelijktijdige aanvragen dat elke afzonderlijke instantie ontvangt.
U kunt ook automatisch schalen gebruiken, een functie om uw werklasten te monitoren en de capaciteit dynamisch aan te passen om stabiele en voorspelbare prestaties te behouden tegen de mogelijke laagste kosten. Dit valt buiten het bestek van dit bericht. Voor meer informatie over automatisch schalen raadpleegt u Inferentie-eindpunten voor automatisch schalen configureren in Amazon SageMaker.
Roep het eindpunt aan met gelijktijdige aanvragen
Stel dat u een grote batch query's hebt die u wilt gebruiken om antwoorden te genereren op basis van een geïmplementeerd model onder omstandigheden met hoge doorvoer. In het volgende codeblok stellen we bijvoorbeeld een lijst samen van 1,000 payloads, waarbij voor elke payload de generatie van 100 tokens wordt aangevraagd. In totaal vragen we om het genereren van 100,000 tokens.
Wanneer u een groot aantal verzoeken naar de SageMaker runtime API verzendt, kunt u last krijgen van beperkingsfouten. Om dit te verhelpen, kunt u een aangepaste SageMaker runtime-client maken die het aantal nieuwe pogingen verhoogt. U kunt het resulterende SageMaker-sessieobject doorgeven aan de JumpStartModel bouwer of sagemaker.predictor.retrieve_default als u een nieuwe voorspeller aan een reeds geïmplementeerd eindpunt wilt koppelen. In de volgende code gebruiken we dit sessieobject bij het implementeren van een Llama 2-model met standaard SageMaker JumpStart-configuraties:
Dit geïmplementeerde eindpunt heeft MAX_CONCURRENT_REQUESTS = 128 standaard. In het volgende blok gebruiken we de gelijktijdige futures-bibliotheek om het eindpunt aan te roepen voor alle payloads met 128 werkthreads. Het eindpunt verwerkt maximaal 128 gelijktijdige verzoeken, en telkens wanneer een verzoek een antwoord retourneert, stuurt de uitvoerder onmiddellijk een nieuw verzoek naar het eindpunt.
Dit resulteert in het genereren van in totaal 100,000 tokens met een doorvoer van 1255 tokens/sec op één ml.g5.2xlarge-instantie. Het verwerken hiervan duurt ongeveer 80 seconden.
Merk op dat deze doorvoerwaarde aanzienlijk verschilt van de maximale doorvoer voor Llama 2 7B op ml.g5.2xlarge in de vorige tabellen van dit bericht (486 tokens/sec bij 64 gelijktijdige verzoeken). Dit komt omdat de invoerpayload 8 tokens gebruikt in plaats van 256, het aantal uitvoertokens 100 is in plaats van 256, en het kleinere aantal tokens 128 gelijktijdige verzoeken mogelijk maakt. Dit is een laatste herinnering dat alle latentie- en doorvoercijfers afhankelijk zijn van de payload! Het wijzigen van het aantal payload-tokens heeft invloed op batchprocessen tijdens het aanbieden van modellen, wat op zijn beurt invloed heeft op de opkomende prefill-, decoderings- en wachtrijtijden voor uw toepassing.
Conclusie
In dit bericht presenteerden we benchmarking van SageMaker JumpStart LLM's, waaronder Llama 2, Mistral en Falcon. We hebben ook een handleiding gepresenteerd voor het optimaliseren van de latentie, doorvoer en kosten voor de configuratie van uw eindpuntimplementatie. U kunt aan de slag door het uitvoeren van de bijbehorende notitieboekje om uw gebruiksscenario te benchmarken.
Over de auteurs
 Dr Kyle Ulrich is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
Dr Kyle Ulrich is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Zijn onderzoeksinteresses omvatten schaalbare machine learning-algoritmen, computervisie, tijdreeksen, Bayesiaanse niet-parametrische gegevens en Gaussiaanse processen. Zijn PhD is van Duke University en hij heeft artikelen gepubliceerd in NeurIPS, Cell en Neuron.
 Dr. Vivek Madan is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign en was een postdoctoraal onderzoeker bij Georgia Tech. Hij is een actief onderzoeker op het gebied van machine learning en algoritmeontwerp en heeft artikelen gepubliceerd op EMNLP-, ICLR-, COLT-, FOCS- en SODA-conferenties.
Dr. Vivek Madan is een Applied Scientist bij het Amazon SageMaker JumpStart-team. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign en was een postdoctoraal onderzoeker bij Georgia Tech. Hij is een actief onderzoeker op het gebied van machine learning en algoritmeontwerp en heeft artikelen gepubliceerd op EMNLP-, ICLR-, COLT-, FOCS- en SODA-conferenties.
 Dr Ashish Khetan is een Senior Applied Scientist bij Amazon SageMaker JumpStart en helpt bij het ontwikkelen van machine learning-algoritmen. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
Dr Ashish Khetan is een Senior Applied Scientist bij Amazon SageMaker JumpStart en helpt bij het ontwikkelen van machine learning-algoritmen. Hij promoveerde aan de Universiteit van Illinois in Urbana-Champaign. Hij is een actief onderzoeker op het gebied van machine learning en statistische inferentie, en heeft veel artikelen gepubliceerd op NeurIPS-, ICML-, ICLR-, JMLR-, ACL- en EMNLP-conferenties.
 Joao Moura is een Senior AI/ML Specialist Solutions Architect bij AWS. João helpt AWS-klanten – van kleine startups tot grote ondernemingen – grote modellen efficiënt op te leiden en in te zetten, en breder ML-platforms op AWS te bouwen.
Joao Moura is een Senior AI/ML Specialist Solutions Architect bij AWS. João helpt AWS-klanten – van kleine startups tot grote ondernemingen – grote modellen efficiënt op te leiden en in te zetten, en breder ML-platforms op AWS te bouwen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

