Met het gebruik van cloud computing, big data en machine learning (ML) tools zoals Amazone Athene or Amazon Sage Maker zijn voor iedereen beschikbaar en bruikbaar geworden zonder veel moeite bij het maken en onderhouden. Industriële bedrijven kijken steeds vaker naar data-analyse en datagestuurde besluitvorming om de hulpbronnenefficiëntie in hun hele portfolio te vergroten, van de bedrijfsvoering tot het uitvoeren van voorspellend onderhoud of planning.
Als gevolg van de snelheid waarmee de IT verandert, worden klanten in traditionele sectoren geconfronteerd met een dilemma op het gebied van vaardigheden. Aan de ene kant hebben analisten en domeinexperts een zeer diepgaande kennis van de gegevens in kwestie en de interpretatie ervan, maar missen ze vaak de kennis van datawetenschapstools en programmeertalen op hoog niveau, zoals Python. Aan de andere kant missen datawetenschapsexperts vaak de ervaring om de inhoud van machinegegevens te interpreteren en te filteren op wat relevant is. Dit dilemma belemmert het creëren van efficiënte modellen die data gebruiken om bedrijfsrelevante inzichten te genereren.
Amazon SageMaker-canvas pakt dit dilemma aan door domeinexperts een interface zonder code te bieden waarmee ze krachtige analyse- en ML-modellen kunnen creëren, zoals prognoses, classificatie- of regressiemodellen. U kunt deze modellen ook na creatie implementeren en delen met ML- en MLOps-specialisten.
In dit bericht laten we u zien hoe u SageMaker Canvas gebruikt om de juiste functies in uw gegevens te beheren en te selecteren, en vervolgens een voorspellingsmodel te trainen voor anomaliedetectie, met behulp van de no-code-functionaliteit van SageMaker Canvas voor modelafstemming.
Anomaliedetectie voor de maakindustrie
Op het moment van schrijven richt SageMaker Canvas zich op typische zakelijke gebruiksscenario’s, zoals prognoses, regressie en classificatie. Voor dit artikel laten we zien hoe deze mogelijkheden ook kunnen helpen bij het detecteren van complexe abnormale datapunten. Deze use case is bijvoorbeeld relevant om storingen of ongebruikelijke werkingen van industriële machines op te sporen.
Anomaliedetectie is belangrijk in het industriële domein, omdat machines (van treinen tot turbines) normaal gesproken zeer betrouwbaar zijn, met perioden tussen storingen van jaren. De meeste gegevens van deze machines, zoals temperatuursensormetingen of statusberichten, beschrijven de normale werking en hebben een beperkte waarde voor de besluitvorming. Ingenieurs zoeken naar abnormale gegevens bij het onderzoeken van de hoofdoorzaken van een storing of als waarschuwingsindicatoren voor toekomstige storingen, en prestatiemanagers onderzoeken abnormale gegevens om mogelijke verbeteringen te identificeren. Daarom is de typische eerste stap op weg naar datagestuurde besluitvorming afhankelijk van het vinden van relevante (abnormale) gegevens.
In dit bericht gebruiken we SageMaker Canvas om de juiste functies in gegevens samen te stellen en te selecteren, en vervolgens een voorspellingsmodel te trainen voor detectie van afwijkingen, met behulp van de no-code-functionaliteit van SageMaker Canvas voor het afstemmen van modellen. Vervolgens implementeren we het model als een SageMaker-eindpunt.
Overzicht oplossingen
Voor ons gebruiksscenario voor anomaliedetectie trainen we een voorspellingsmodel om een karakteristiek kenmerk voor de normale werking van een machine te voorspellen, zoals de motortemperatuur die in een auto wordt aangegeven, op basis van beïnvloedende kenmerken, zoals de snelheid en het recente koppel dat in de auto wordt toegepast. . Voor anomaliedetectie op een nieuwe steekproef van metingen vergelijken we de modelvoorspellingen voor het karakteristieke kenmerk met de verstrekte waarnemingen.
Voor het voorbeeld van de automotor verkrijgt een domeinexpert metingen van de normale motortemperatuur, het recente motorkoppel, de omgevingstemperatuur en andere potentiële beïnvloedende factoren. Hiermee kunt u een model trainen om de temperatuur op basis van de andere functies te voorspellen. Vervolgens kunnen we het model gebruiken om op regelmatige basis de motortemperatuur te voorspellen. Wanneer de voorspelde temperatuur voor die gegevens vergelijkbaar is met de waargenomen temperatuur in die gegevens, werkt de motor normaal; een discrepantie wijst op een anomalie, zoals een storing in het koelsysteem of een defect in de motor.
Het volgende diagram illustreert de oplossingsarchitectuur.
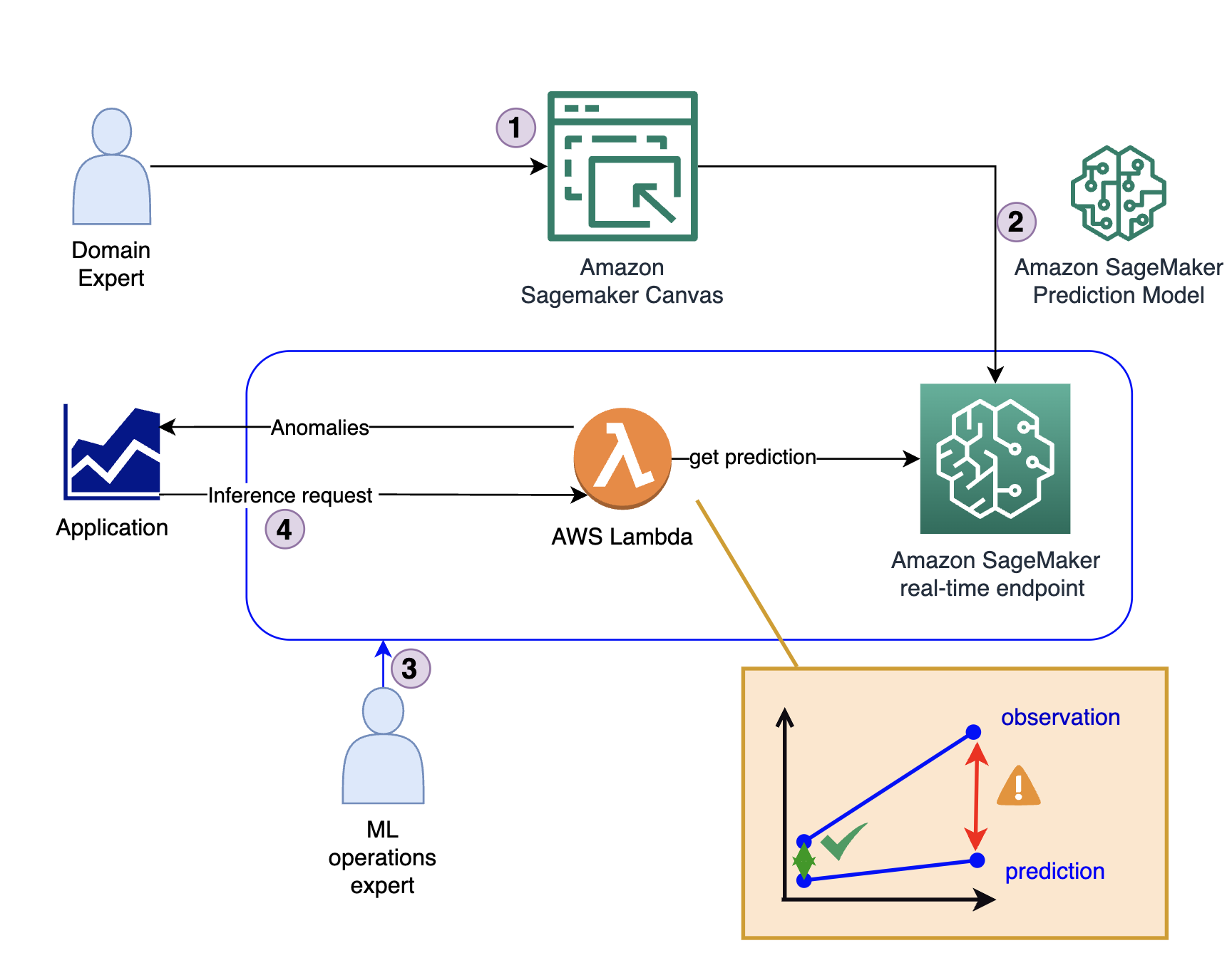
De oplossing bestaat uit vier belangrijke stappen:
- De domeinexpert creëert het initiële model, inclusief data-analyse en functiebeheer met behulp van SageMaker Canvas.
- De domeinexpert deelt het model via de Amazon SageMaker-modelregister of implementeert het rechtstreeks als een realtime eindpunt.
- Een MLOps-expert creëert de inferentie-infrastructuur en code en vertaalt de modeluitvoer van een voorspelling naar een anomalie-indicator. Deze code wordt doorgaans uitgevoerd in een AWS Lambda functie.
- Wanneer een toepassing een anomaliedetectie vereist, roept deze de Lambda-functie aan, die het model gebruikt voor gevolgtrekking en het antwoord levert (ongeacht of het een anomalie is of niet).
Voorwaarden
Om dit bericht te volgen, moet je aan de volgende vereisten voldoen:
Maak het model met SageMaker
Het proces voor het maken van modellen volgt de standaardstappen voor het maken van een regressiemodel in SageMaker Canvas. Voor meer informatie, zie Aan de slag met het gebruik van Amazon SageMaker Canvas.
Eerst laadt de domeinexpert relevante data in SageMaker Canvas, zoals een tijdreeks van metingen. Voor dit bericht gebruiken we een CSV-bestand met de (synthetisch gegenereerde) metingen van een elektromotor. Voor details, zie Gegevens importeren in Canvas. De gebruikte voorbeeldgegevens kunnen worden gedownload als CSV.
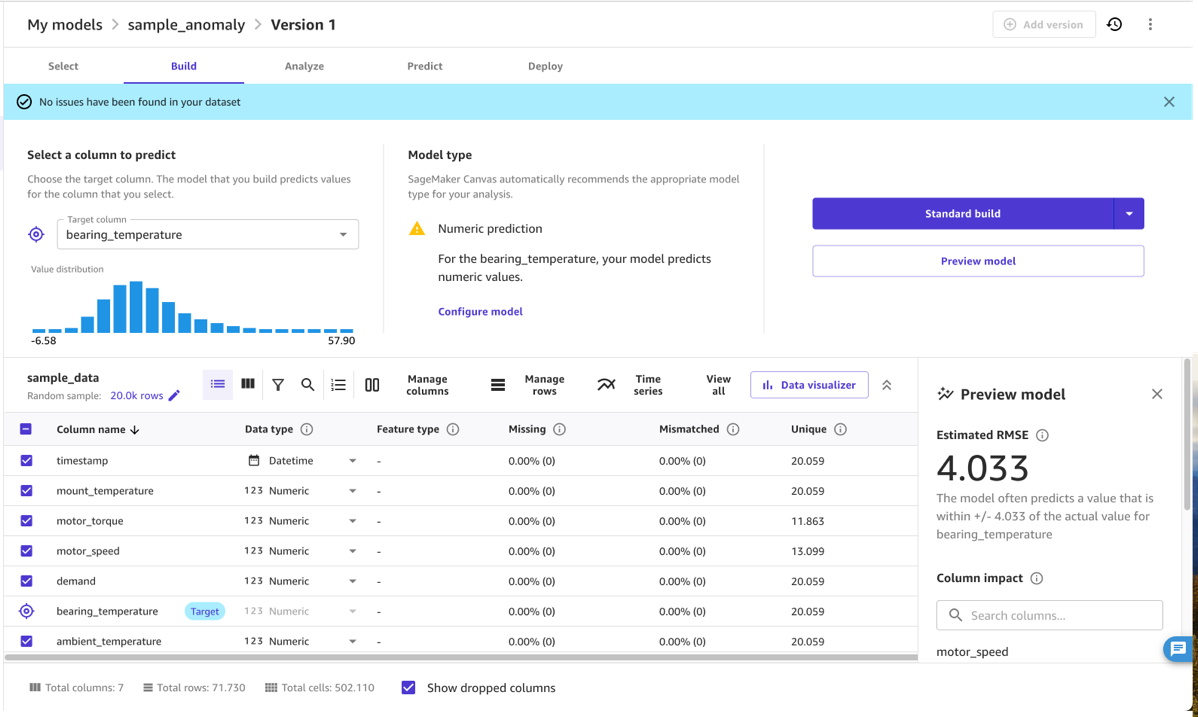
Beheer de gegevens met SageMaker Canvas
Nadat de gegevens zijn geladen, kan de domeinexpert SageMaker Canvas gebruiken om de gegevens te beheren die in het uiteindelijke model worden gebruikt. Hiervoor selecteert de expert die kolommen die karakteristieke metingen bevatten voor het betreffende probleem. Nauwkeuriger gezegd selecteert de expert kolommen die aan elkaar gerelateerd zijn, bijvoorbeeld door een fysieke relatie zoals een druk-temperatuurcurve, en waarbij een verandering in die relatie een relevante anomalie is voor hun gebruiksscenario. Het anomaliedetectiemodel leert de normale relatie tussen de geselecteerde kolommen en geeft aan wanneer de gegevens hier niet aan voldoen, zoals een abnormaal hoge motortemperatuur gegeven de huidige belasting van de motor.
In de praktijk moet de domeinexpert een set geschikte invoerkolommen en een doelkolom selecteren. De invoer is doorgaans de verzameling grootheden (numeriek of categorisch) die het gedrag van een machine bepalen, van vraaginstellingen tot belasting, snelheid en omgevingstemperatuur. De uitvoer is doorgaans een numerieke grootheid die de prestatie van de werking van de machine aangeeft, zoals een temperatuurmeting die de energiedissipatie meet of een andere prestatiemaatstaf die verandert wanneer de machine onder suboptimale omstandigheden draait.
Laten we een paar voorbeelden bekijken om het concept te illustreren van welke hoeveelheden we moeten selecteren voor invoer en uitvoer:
- Voor roterende apparatuur, zoals het model dat we in dit bericht bouwen, zijn typische invoergegevens de rotatiesnelheid, het koppel (stroom en geschiedenis) en de omgevingstemperatuur, en de doelen zijn de resulterende lager- of motortemperaturen die goede operationele omstandigheden van de rotaties aangeven
- Voor een windturbine zijn typische inputgegevens de huidige en recente geschiedenis van de windsnelheid en rotorbladinstellingen, en de beoogde hoeveelheid is het geproduceerde vermogen of de rotatiesnelheid.
- Voor een chemisch proces zijn typische inputs het percentage verschillende ingrediënten en de omgevingstemperatuur, en doelen zijn de geproduceerde warmte of de viscositeit van het eindproduct
- Voor het verplaatsen van apparatuur zoals schuifdeuren zijn typische invoergegevens de stroomtoevoer naar de motoren, en de doelwaarde is de snelheid of voltooiingstijd van de beweging
- Voor een HVAC-systeem zijn typische invoergegevens het bereikte temperatuurverschil en de belastingsinstellingen, en de doelhoeveelheid het gemeten energieverbruik
Uiteindelijk zullen de juiste inputs en doelen voor een bepaalde apparatuur afhangen van de use case en het afwijkende gedrag dat moet worden gedetecteerd, en deze zijn het best bekend bij een domeinexpert die bekend is met de fijne kneepjes van de specifieke dataset.
In de meeste gevallen betekent het selecteren van geschikte invoer- en doelhoeveelheden dat u alleen de juiste kolommen selecteert en de doelkolom markeert (in dit voorbeeld bearing_temperature). Een domeinexpert kan echter ook de no-code-functies van SageMaker Canvas gebruiken om kolommen te transformeren en de gegevens te verfijnen of samen te voegen. U kunt bijvoorbeeld specifieke datums of tijdstempels uit de gegevens halen of filteren die niet relevant zijn. SageMaker Canvas ondersteunt dit proces en toont statistieken over de geselecteerde hoeveelheden, zodat u kunt begrijpen of een hoeveelheid uitschieters en spreiding heeft die de resultaten van het model kunnen beïnvloeden.
Train, stem af en evalueer het model
Nadat de domeinexpert geschikte kolommen in de dataset heeft geselecteerd, kunnen ze het model trainen om de relatie tussen de inputs en outputs te leren. Preciezer gezegd: het model leert de doelwaarde te voorspellen die uit de inputs is geselecteerd.
Normaal gesproken kunt u het SageMaker Canvas gebruiken Modelvoorbeeld keuze. Dit geeft een snelle indicatie van de te verwachten modelkwaliteit en stelt u in staat het effect te onderzoeken dat verschillende invoergegevens hebben op de uitvoermetriek. In de volgende schermafbeelding wordt het model bijvoorbeeld het meest beïnvloed door de motor_speed en ambient_temperature meetgegevens bij het voorspellen bearing_temperature. Dat is verstandig, omdat deze temperaturen nauw met elkaar samenhangen. Tegelijkertijd zullen extra wrijving of andere vormen van energieverlies hier waarschijnlijk invloed op hebben.
Voor de modelkwaliteit is de RMSE van het model een indicator hoe goed het model in staat was het normale gedrag in de trainingsgegevens te leren en de relaties tussen de input- en outputmetingen te reproduceren. In het volgende model zou het model bijvoorbeeld het juiste moeten kunnen voorspellen motor_bearing temperatuur binnen 3.67 graden Celsius, dus we kunnen een afwijking van de werkelijke temperatuur ten opzichte van een modelvoorspelling die groter is dan bijvoorbeeld 7.4 graden als een anomalie beschouwen. De werkelijke drempelwaarde die u zou gebruiken, hangt echter af van de gevoeligheid die vereist is in het implementatiescenario.
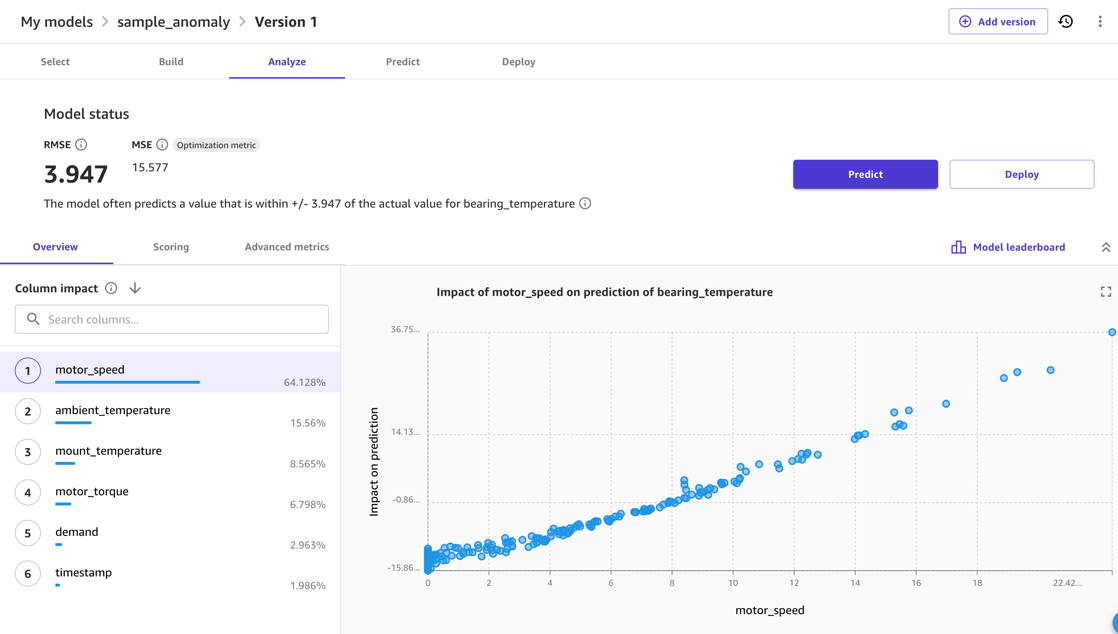
Ten slotte kunt u, nadat de modelevaluatie en -afstemming is voltooid, beginnen met de volledige modeltraining waarmee het model wordt gemaakt dat voor gevolgtrekkingen kan worden gebruikt.
Implementeer het model
Hoewel SageMaker Canvas een model voor gevolgtrekking kan gebruiken, vereist een productieve implementatie voor detectie van afwijkingen dat u het model buiten SageMaker Canvas implementeert. Om precies te zijn: we moeten het model als eindpunt inzetten.
In dit bericht en voor de eenvoud implementeren we het model rechtstreeks als eindpunt vanuit SageMaker Canvas. Voor instructies, zie Implementeer uw modellen op een eindpunt. Zorg ervoor dat u de implementatienaam noteert en rekening houdt met de prijzen van het exemplaartype waarnaar u implementeert (voor dit bericht gebruiken we ml.m5.large). SageMaker Canvas creëert vervolgens een modeleindpunt dat kan worden aangeroepen om voorspellingen te verkrijgen.
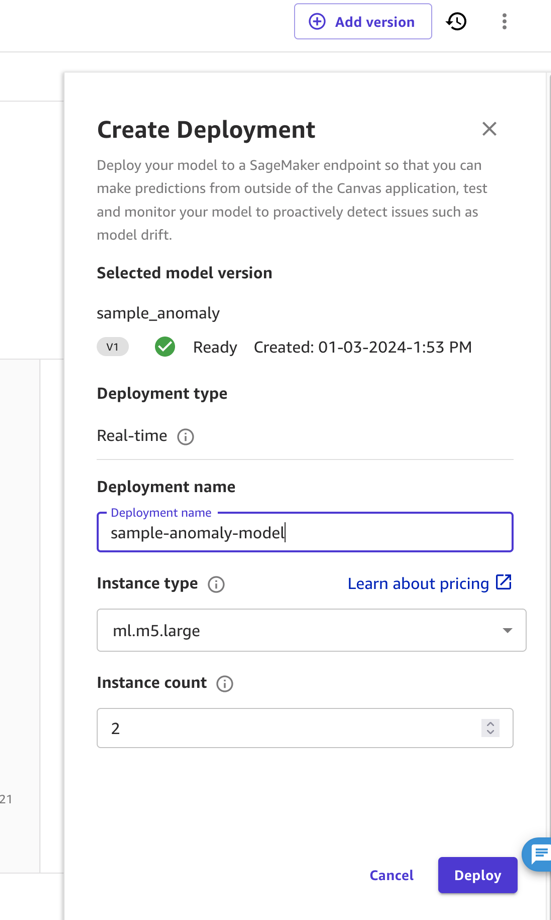
In industriële omgevingen moet een model grondig worden getest voordat het kan worden ingezet. Hiervoor zal de domeinexpert het niet implementeren, maar in plaats daarvan het model delen met het SageMaker Model Registry. Hier kan een MLOps-operationsexpert het overnemen. Normaal gesproken test die expert het modeleindpunt, evalueert de omvang van de computerapparatuur die nodig is voor de doeltoepassing en bepaalt de meest kostenefficiënte implementatie, zoals implementatie voor serverloze inferentie of batch-inferentie. Deze stappen zijn normaal gesproken geautomatiseerd (bijvoorbeeld met behulp van Amazon Sagemaker-pijpleidingen of de Amazon-SDK).

Gebruik het model voor detectie van afwijkingen
In de vorige stap hebben we een modelimplementatie gemaakt in SageMaker Canvas, genaamd canvas-sample-anomaly-model. We kunnen het gebruiken om voorspellingen te verkrijgen van a bearing_temperature waarde op basis van de andere kolommen in de gegevensset. Nu willen we dit eindpunt gebruiken om afwijkingen te detecteren.
Om afwijkende gegevens te identificeren, gebruikt ons model het eindpunt van het voorspellingsmodel om de verwachte waarde van de doelstatistiek te verkrijgen en vervolgens de voorspelde waarde te vergelijken met de werkelijke waarde in de gegevens. De voorspelde waarde geeft de verwachte waarde aan voor onze doelstatistiek op basis van de trainingsgegevens. Het verschil tussen deze waarde is daarom een maatstaf voor de afwijking van de feitelijk waargenomen gegevens. We kunnen de volgende code gebruiken:
De voorgaande code voert de volgende acties uit:
- De invoergegevens worden gefilterd naar de juiste kenmerken (functie “
input_transformer"). - Het SageMaker-modeleindpunt wordt aangeroepen met de gefilterde gegevens (functie “
do_inference“), waar we de invoer- en uitvoeropmaak verwerken volgens de voorbeeldcode die wordt verstrekt bij het openen van de detailpagina van onze implementatie in SageMaker Canvas. - Het resultaat van de aanroep wordt samengevoegd met de originele invoergegevens en het verschil wordt opgeslagen in de foutkolom (functie “
output_transform").
Vind afwijkingen en evalueer afwijkende gebeurtenissen
In een typische opstelling wordt de code om afwijkingen te verkrijgen uitgevoerd in een Lambda-functie. De Lambda-functie kan worden opgeroepen vanuit een applicatie of Amazon API-gateway. De hoofdfunctie retourneert een anomaliescore voor elke rij met invoergegevens, in dit geval een tijdreeks van een anomaliescore.
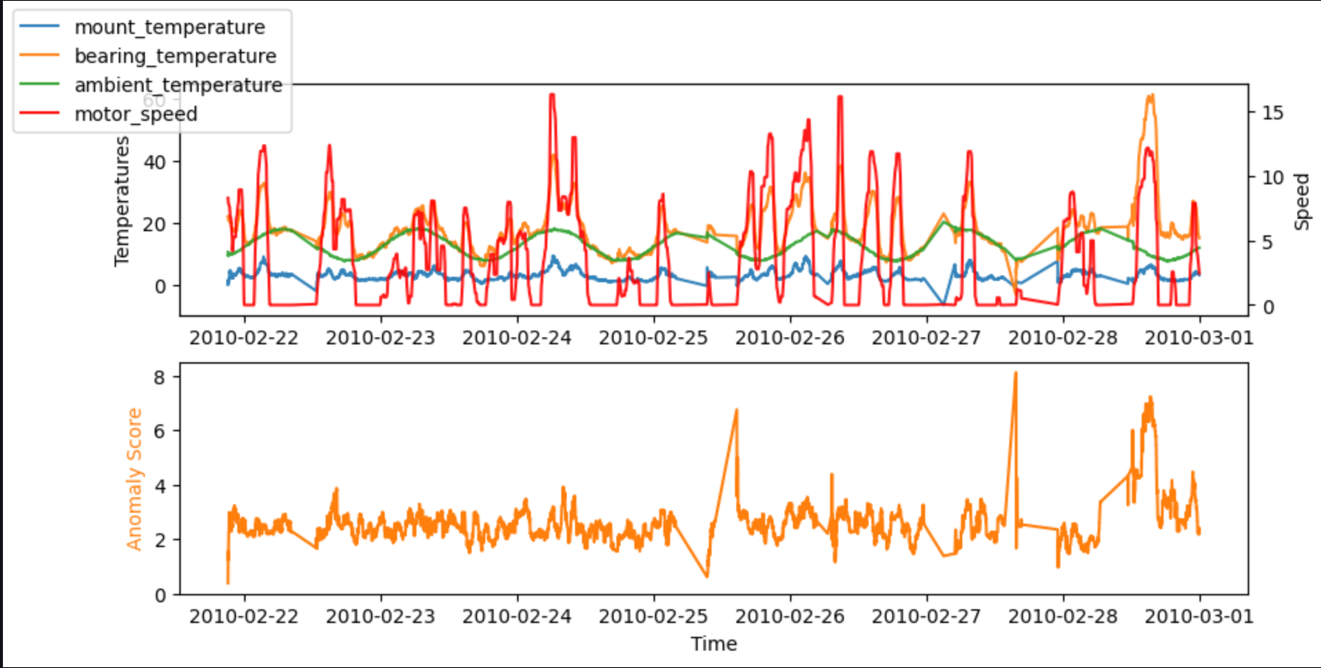
Voor testen kunnen we de code ook uitvoeren in een SageMaker-notebook. De volgende grafieken tonen de invoer en uitvoer van ons model bij gebruik van de voorbeeldgegevens. Pieken in de afwijking tussen voorspelde en werkelijke waarden (afwijkingsscore, weergegeven in de onderste grafiek) duiden op afwijkingen. In de grafiek kunnen we bijvoorbeeld drie verschillende pieken zien waarbij de anomaliescore (verschil tussen verwachte en werkelijke temperatuur) de 7 graden Celsius overschrijdt: de eerste na een lange inactiviteit, de tweede bij een steile daling van bearing_temperature, en de laatste waar bearing_temperature is hoog vergeleken met motor_speed.
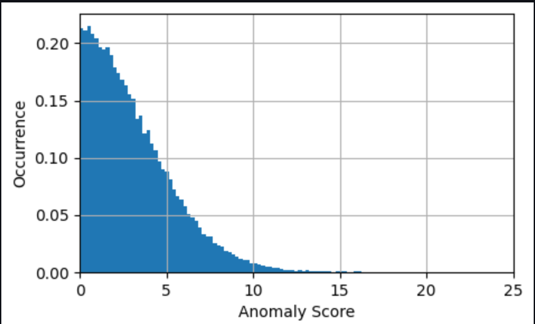
In veel gevallen is het al voldoende om de tijdreeksen van de anomaliescore te kennen; u kunt een drempel instellen voor wanneer u moet waarschuwen voor een significante afwijking, op basis van de noodzaak van modelgevoeligheid. De huidige score geeft vervolgens aan dat een machine een abnormale toestand heeft die moet worden onderzocht. Voor ons model wordt de absolute waarde van de anomaliescore bijvoorbeeld verdeeld zoals weergegeven in de volgende grafiek. Dit bevestigt dat de meeste afwijkingenscores onder de (2xRMS=)8 graden liggen die tijdens de training voor het model als typische fout zijn aangetroffen. De grafiek kan u helpen handmatig een drempelwaarde te kiezen, zodat het juiste percentage van de geëvalueerde monsters als afwijkingen wordt gemarkeerd.
Als de gewenste output uit gebeurtenissen met afwijkingen bestaat, moeten de door het model geleverde afwijkingenscores worden verfijnd om relevant te zijn voor zakelijk gebruik. Hiervoor zal de ML-expert doorgaans nabewerking toevoegen om ruis of grote pieken op de anomaliescore te verwijderen, zoals het toevoegen van een voortschrijdend gemiddelde. Bovendien zal de expert de anomaliescore doorgaans evalueren op basis van een logica die vergelijkbaar is met het verhogen van een Amazon Cloud Watch alarm, zoals het monitoren van de overschrijding van een drempelwaarde gedurende een bepaalde duur. Voor meer informatie over het instellen van alarmen, zie Amazon CloudWatch-alarmen gebruiken. Door deze evaluaties uit te voeren in de Lambda-functie kunt u waarschuwingen verzenden, bijvoorbeeld door een waarschuwing te publiceren naar een Amazon eenvoudige meldingsservice (Amazon SNS) onderwerp.
Opruimen
Nadat u klaar bent met het gebruik van deze oplossing, moet u opruimen om onnodige kosten te voorkomen:
- Zoek in SageMaker Canvas de implementatie van uw modeleindpunt en verwijder deze.
- Meld u af bij SageMaker Canvas om te voorkomen dat er kosten in rekening worden gebracht als het programma stilstaat.
Samengevat
In dit bericht hebben we laten zien hoe een domeinexpert invoergegevens kan evalueren en een ML-model kan maken met SageMaker Canvas zonder code te hoeven schrijven. Vervolgens lieten we zien hoe we dit model konden gebruiken om realtime anomaliedetectie uit te voeren met behulp van SageMaker en Lambda via een eenvoudige workflow. Deze combinatie stelt domeinexperts in staat hun kennis te gebruiken om krachtige ML-modellen te creëren zonder aanvullende training in datawetenschap, en stelt MLOps-experts in staat deze modellen te gebruiken en ze flexibel en efficiënt beschikbaar te maken voor gevolgtrekking.
Er is een gratis laag van 2 maanden beschikbaar voor SageMaker Canvas, waarna u alleen betaalt voor wat u gebruikt. Begin vandaag nog met experimenteren en voeg ML toe om het meeste uit uw gegevens te halen.
Over de auteur
 Helge Aufderheide is een liefhebber van het bruikbaar maken van data in de echte wereld met een sterke focus op automatisering, analyse en machinaal leren in industriële toepassingen, zoals productie en mobiliteit.
Helge Aufderheide is een liefhebber van het bruikbaar maken van data in de echte wereld met een sterke focus op automatisering, analyse en machinaal leren in industriële toepassingen, zoals productie en mobiliteit.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/detect-anomalies-in-manufacturing-data-using-amazon-sagemaker-canvas/

