Introductie
Het labelen van de afbeelding, of het annoteren van de foto, in het grote geheel van computer vision was een uitdaging. Onze verkenning duikt in het teamwerk van LabelImg en Detectron, een krachtig duo dat nauwkeurige annotatie combineert met efficiënte modelbouw. LabelImg, dat gemakkelijk te gebruiken en nauwkeurig is, leidt tot zorgvuldige annotatie en legt een solide basis voor duidelijke objectdetectie.
Terwijl we LabelImg verkennen en beter worden in het tekenen van selectiekaders, stappen we naadloos over op Detectron. Dit robuuste raamwerk organiseert onze gemarkeerde gegevens, waardoor het nuttig is bij het trainen van geavanceerde modellen. LabelImg en Detectron maken objectdetectie samen gemakkelijk voor iedereen, of u nu een beginner of een expert bent. Kom langs, waar elke gemarkeerde afbeelding ons helpt de volledige kracht van visuele informatie te ontsluiten.
leerdoelen
- Aan de slag met LabelImg.
- Omgevingsinstellingen en LabelImg-installatie.
- LabelImg en de functionaliteit ervan begrijpen.
- VOC- of Pascal-gegevens converteren naar COCO-formaat voor objectdetectie.
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
Flowchart

Uw omgeving instellen
1. Creëer een virtuele omgeving:
conda create -p ./venv python=3.8 -yMet deze opdracht wordt een virtuele omgeving met de naam “venv” gemaakt met behulp van Python versie 3.8.
2. Activeer de virtuele omgeving:
conda activate venvActiveer de virtuele omgeving om de installatie van LabelImg te isoleren.
LabelImg installeren en gebruiken
1. Installeer LabelImg:
pip install labelImgInstalleer LabelImg binnen de geactiveerde virtuele omgeving.
2. Start LabelImg:
labelImg
Probleemoplossing: als u fouten tegenkomt bij het uitvoeren van het script
Als u fouten tegenkomt tijdens het uitvoeren van het script, heb ik voor uw gemak een zip-archief gemaakt met de virtuele omgeving (venv).
1. Download het zip-archief:
- Download het venv.zip-archief van de Link
2. Maak een LabelImg-map:
- Maak een nieuwe map met de naam LabelImg op uw lokale computer.
3. Pak de venv-map uit:
- Pak de inhoud van het venv.zip-archief uit in de map LabelImg.
4. Activeer de virtuele omgeving:
- Open uw opdrachtprompt of terminal.
- Navigeer naar de LabelImg-map.
- Voer de volgende opdracht uit om de virtuele omgeving te activeren:
conda activate ./venvDit proces zorgt ervoor dat u over een vooraf geconfigureerde virtuele omgeving beschikt die klaar is voor gebruik met LabelImg. Het meegeleverde zip-archief omvat de noodzakelijke afhankelijkheden, waardoor een soepelere ervaring mogelijk is zonder dat u zich zorgen hoeft te maken over een mogelijke installatie.
Ga nu verder met de eerdere stappen voor het installeren en gebruiken van LabelImg binnen deze geactiveerde virtuele omgeving.
Annotatieworkflow met LabelImg
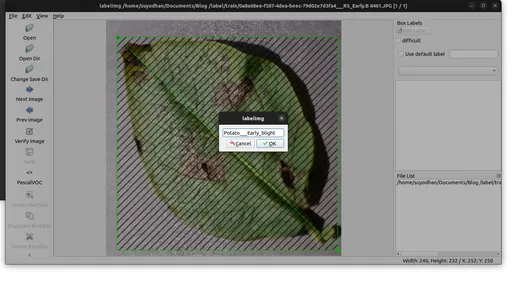
1. Annoteer afbeeldingen in PascalVOC-indeling:
- Bouw en start LabelImg.
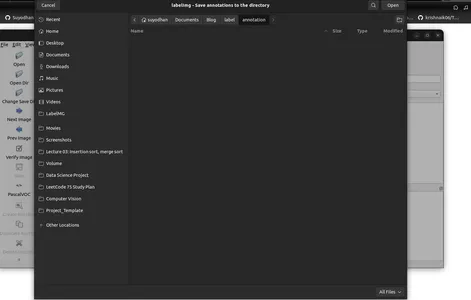
- Klik op 'Standaard opgeslagen annotatiemap wijzigen' in Menu/Bestand.
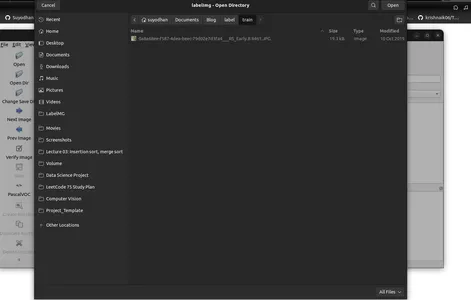
- Klik op 'Open Dir' om de afbeeldingsmap te selecteren.
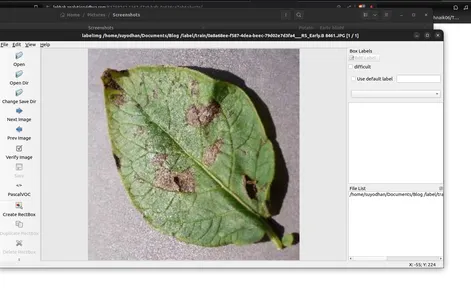
- Gebruik 'Create RectBox' om objecten in de afbeelding te annoteren.
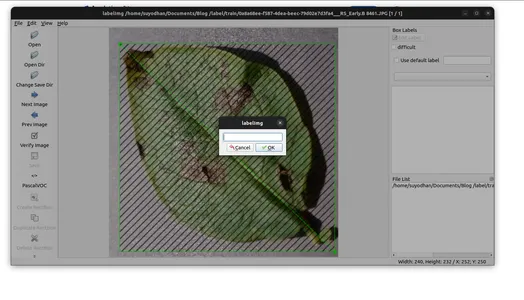
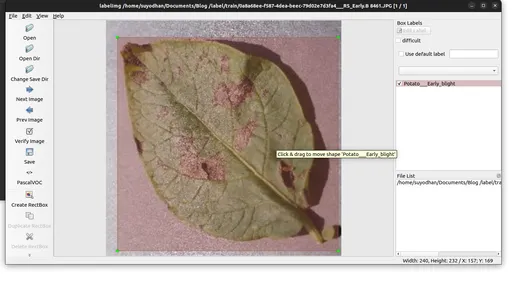
- Sla de annotaties op in de opgegeven map.
binnen de .xml
<annotation>
<folder>train</folder>
<filename>0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</filename>
<path>/home/suyodhan/Documents/Blog /label
/train/0a8a68ee-f587-4dea-beec-79d02e7d3fa4___RS_Early.B 8461.JPG</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>256</width>
<height>256</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>Potato___Early_blight</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>12</xmin>
<ymin>18</ymin>
<xmax>252</xmax>
<ymax>250</ymax>
</bndbox>
</object>
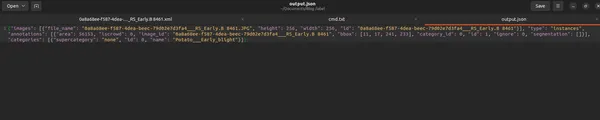
</annotation>Deze XML-structuur volgt het Pascal VOC-annotatieformaat, dat vaak wordt gebruikt voor datasets voor objectdetectie. Dit formaat biedt een gestandaardiseerde weergave van geannoteerde gegevens voor het trainen van computer vision-modellen. Als u extra afbeeldingen met annotaties heeft, kunt u vergelijkbare XML-bestanden blijven genereren voor elk geannoteerd object in de respectievelijke afbeeldingen.
Pascal VOC-annotaties converteren naar COCO-formaat: een Python-script
Objectdetectiemodellen vereisen vaak annotaties in specifieke formaten om effectief te kunnen trainen en evalueren. Hoewel Pascal VOC een veelgebruikt formaat is, geven specifieke raamwerken zoals Detectron de voorkeur aan COCO-annotaties. Om deze kloof te overbruggen, introduceren we een veelzijdige Python script, voc2coco.py, ontworpen om Pascal VOC-annotaties naadloos naar het COCO-formaat te converteren.
#!/usr/bin/python
# pip install lxml
import sys
import os
import json
import xml.etree.ElementTree as ET
import glob
START_BOUNDING_BOX_ID = 1
PRE_DEFINE_CATEGORIES = None
# If necessary, pre-define category and its id
# PRE_DEFINE_CATEGORIES = {"aeroplane": 1, "bicycle": 2, "bird": 3, "boat": 4,
# "bottle":5, "bus": 6, "car": 7, "cat": 8, "chair": 9,
# "cow": 10, "diningtable": 11, "dog": 12, "horse": 13,
# "motorbike": 14, "person": 15, "pottedplant": 16,
# "sheep": 17, "sofa": 18, "train": 19, "tvmonitor": 20}
def get(root, name):
vars = root.findall(name)
return vars
def get_and_check(root, name, length):
vars = root.findall(name)
if len(vars) == 0:
raise ValueError("Can not find %s in %s." % (name, root.tag))
if length > 0 and len(vars) != length:
raise ValueError(
"The size of %s is supposed to be %d, but is %d."
% (name, length, len(vars))
)
if length == 1:
vars = vars[0]
return vars
def get_filename_as_int(filename):
try:
filename = filename.replace("", "/")
filename = os.path.splitext(os.path.basename(filename))[0]
return str(filename)
except:
raise ValueError("Filename %s is supposed to be an integer." % (filename))
def get_categories(xml_files):
"""Generate category name to id mapping from a list of xml files.
Arguments:
xml_files {list} -- A list of xml file paths.
Returns:
dict -- category name to id mapping.
"""
classes_names = []
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall("object"):
classes_names.append(member[0].text)
classes_names = list(set(classes_names))
classes_names.sort()
return {name: i for i, name in enumerate(classes_names)}
def convert(xml_files, json_file):
json_dict = {"images": [], "type": "instances", "annotations": [], "categories": []}
if PRE_DEFINE_CATEGORIES is not None:
categories = PRE_DEFINE_CATEGORIES
else:
categories = get_categories(xml_files)
bnd_id = START_BOUNDING_BOX_ID
for xml_file in xml_files:
tree = ET.parse(xml_file)
root = tree.getroot()
path = get(root, "path")
if len(path) == 1:
filename = os.path.basename(path[0].text)
elif len(path) == 0:
filename = get_and_check(root, "filename", 1).text
else:
raise ValueError("%d paths found in %s" % (len(path), xml_file))
## The filename must be a number
image_id = get_filename_as_int(filename)
size = get_and_check(root, "size", 1)
width = int(get_and_check(size, "width", 1).text)
height = int(get_and_check(size, "height", 1).text)
image = {
"file_name": filename,
"height": height,
"width": width,
"id": image_id,
}
json_dict["images"].append(image)
## Currently we do not support segmentation.
# segmented = get_and_check(root, 'segmented', 1).text
# assert segmented == '0'
for obj in get(root, "object"):
category = get_and_check(obj, "name", 1).text
if category not in categories:
new_id = len(categories)
categories[category] = new_id
category_id = categories[category]
bndbox = get_and_check(obj, "bndbox", 1)
xmin = int(get_and_check(bndbox, "xmin", 1).text) - 1
ymin = int(get_and_check(bndbox, "ymin", 1).text) - 1
xmax = int(get_and_check(bndbox, "xmax", 1).text)
ymax = int(get_and_check(bndbox, "ymax", 1).text)
assert xmax > xmin
assert ymax > ymin
o_width = abs(xmax - xmin)
o_height = abs(ymax - ymin)
ann = {
"area": o_width * o_height,
"iscrowd": 0,
"image_id": image_id,
"bbox": [xmin, ymin, o_width, o_height],
"category_id": category_id,
"id": bnd_id,
"ignore": 0,
"segmentation": [],
}
json_dict["annotations"].append(ann)
bnd_id = bnd_id + 1
for cate, cid in categories.items():
cat = {"supercategory": "none", "id": cid, "name": cate}
json_dict["categories"].append(cat)
#os.makedirs(os.path.dirname(json_file), exist_ok=True)
json_fp = open(json_file, "w")
json_str = json.dumps(json_dict)
json_fp.write(json_str)
json_fp.close()
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser(
description="Convert Pascal VOC annotation to COCO format."
)
parser.add_argument("xml_dir", help="Directory path to xml files.", type=str)
parser.add_argument("json_file", help="Output COCO format json file.", type=str)
args = parser.parse_args()
xml_files = glob.glob(os.path.join(args.xml_dir, "*.xml"))
# If you want to do train/test split, you can pass a subset of xml files to convert function.
print("Number of xml files: {}".format(len(xml_files)))
convert(xml_files, args.json_file)
print("Success: {}".format(args.json_file))Scriptoverzicht
Het voc2coco.py-script vereenvoudigt het conversieproces door gebruik te maken van de lxml-bibliotheek. Laten we, voordat we in het gebruik duiken, de belangrijkste componenten ervan verkennen:
1. Afhankelijkheden:
- Zorg ervoor dat de lxml-bibliotheek is geïnstalleerd met behulp van pip install lxml.
2. Configuratie:
- Definieer eventueel categorieën vooraf met behulp van de PRE_DEFINE_CATEGORIES variabele. Verwijder de opmerkingen en pas deze sectie aan op basis van uw dataset.
3. FunctionioGet
- get, get_and_check, get_filename_as_int: Helperfuncties voor XML-parsering.
- get_categories: Genereert een categorienaam naar ID-toewijzing uit een lijst met XML-bestanden.
- converteren: De hoofdconversiefunctie verwerkt XML-bestanden en genereert JSON in COCO-formaat.
Hoe te gebruiken
Het uitvoeren van het script is eenvoudig, voer het uit vanaf de opdrachtregel, geef het pad naar uw Pascal VOC XML-bestanden op en specificeer het gewenste uitvoerpad voor het JSON-bestand in COCO-formaat. Hier is een voorbeeld:
python voc2coco.py /path/to/xml/files /path/to/output/output.jsonOutput:
Het script voert een goed gestructureerd JSON-bestand in COCO-indeling uit met essentiële informatie over afbeeldingen, annotaties en categorieën.
Conclusie
Ter afsluiting van onze reis door objectdetectie met LabelImg en Detectron is het van cruciaal belang om de verscheidenheid aan annotatiehulpmiddelen voor liefhebbers en professionals te herkennen. LabelImg biedt als open source-edelsteen veelzijdigheid en toegankelijkheid, waardoor het een eerste keuze is.
Naast gratis tools komen betaalde oplossingen zoals VGG Image Annotator (VIA), RectLabel en Labelbox tussenbeide voor complexe taken en grote projecten. Deze platforms bieden geavanceerde functies en schaalbaarheid, zij het met een financiële investering, waardoor efficiëntie wordt gegarandeerd bij inspanningen waarbij veel op het spel staat.
Onze verkenning legt de nadruk op het kiezen van de juiste annotatietool op basis van projectspecificaties, budget en verfijningsniveau. Of u nu vasthoudt aan de openheid van LabelImg of investeert in betaalde tools, de sleutel is afstemming op de schaal en doelstellingen van uw project. In het evoluerende veld van computer vision blijven annotatiehulpmiddelen zich diversifiëren, waardoor ze opties bieden voor projecten van elke omvang en complexiteit.
Key Takeaways
- De intuïtieve interface en geavanceerde functies van LabelImg maken het tot een veelzijdige open-source tool voor nauwkeurige beeldannotatie, ideaal voor degenen die zich bezighouden met objectdetectie.
- Betaalde tools zoals VIA, RectLabel en Labelbox zijn geschikt voor complexe annotatietaken en grootschalige projecten en bieden geavanceerde functies en schaalbaarheid.
- De cruciale conclusie is het kiezen van de juiste annotatietool op basis van projectbehoeften, budget en gewenste verfijning, waardoor efficiëntie en succes bij objectdetectie-inspanningen wordt gegarandeerd.
Hulpbronnen voor verder leren:
1. LabelImg-documentatie:
- Verken de officiële documentatie voor LabelImg om diepgaande inzichten te krijgen in de kenmerken en functionaliteiten ervan.
- LabelImg-documentatie
2. Detectron Framework-documentatie:
- Duik in de documentatie van Detectron, het krachtige raamwerk voor objectdetectie, om de mogelijkheden en het gebruik ervan te begrijpen.
- Detectron-documentatie
3. VGG Image Annotator (VIA)-gids:
- Als u geïnteresseerd bent in het verkennen van VIA, de VGG Image Annotator, raadpleeg dan de uitgebreide handleiding voor gedetailleerde instructies.
- VIA-gebruikershandleiding
4.RectLabel-documentatie:
- Lees meer over RectLabel, een betaalde annotatietool, door de officiële documentatie te raadplegen voor richtlijnen over gebruik en functies.
- RectLabel-documentatie
5.Labelbox-leercentrum:
- Ontdek educatieve bronnen en tutorials in het Labelbox Learning Center om uw begrip van dit annotatieplatform te vergroten.
- Labelbox-leercentrum
Veelgestelde Vragen / FAQ
A: LabelImg is een open-source hulpmiddel voor het annoteren van afbeeldingen voor objectdetectietaken. De gebruiksvriendelijke interface en veelzijdigheid onderscheiden het. In tegenstelling tot sommige tools maakt LabelImg nauwkeurige annotatie van het selectiekader mogelijk, waardoor het een voorkeurskeuze is voor mensen die nog niet bekend zijn met objectdetectie.
A: Ja, verschillende betaalde annotatietools, zoals VGG Image Annotator (VIA), RectLabel en Labelbox, bieden geavanceerde functies en schaalbaarheid. Hoewel gratis tools zoals LabelImg uitstekend geschikt zijn voor basistaken, zijn betaalde oplossingen op maat gemaakt voor complexere projecten, waardoor ze samenwerkingsfuncties en verbeterde efficiëntie bieden.
A: Het converteren van annotaties naar het Pascal VOC-formaat is cruciaal voor compatibiliteit met frameworks zoals Detectron. Het zorgt voor consistente klassenlabeling en naadloze integratie in de trainingspijplijn, waardoor het creëren van nauwkeurige objectdetectiemodellen wordt vergemakkelijkt.
A: Detectron is een robuust raamwerk voor objectdetectie dat het modeltrainingsproces stroomlijnt. Het speelt een cruciale rol bij het verwerken van geannoteerde gegevens, het voorbereiden ervan op training en het optimaliseren van de algehele efficiëntie van objectdetectiemodellen.
A: Hoewel betaalde annotatietools vaak worden geassocieerd met taken op ondernemingsniveau, kunnen ze ook kleinschalige projecten ten goede komen. De beslissing hangt af van de specifieke vereisten, budgetbeperkingen en het gewenste niveau van verfijning voor annotatietaken.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/11/detectron-integration-with-labelimg/

