In de wereld van machine learning (ML) is de kwaliteit van de dataset van groot belang voor de voorspelbaarheid van modellen. Hoewel meer data meestal beter is, kunnen grote datasets met een groot aantal kenmerken soms leiden tot niet-optimale modelprestaties vanwege de vloek van dimensionaliteit. Analisten kunnen een aanzienlijke hoeveelheid tijd besteden aan het transformeren van gegevens om de modelprestaties te verbeteren. Bovendien zijn grote datasets duurder en duurt het langer om te trainen. Als tijd een beperking is, kunnen de prestaties van het model daardoor beperkt zijn.
Dimensiereductietechnieken kunnen helpen de omvang van uw gegevens te verkleinen terwijl de informatie behouden blijft, wat resulteert in snellere trainingstijden, lagere kosten en potentieel beter presterende modellen.
Amazon SageMaker-gegevens Wrangler is een speciaal gebouwde tool voor gegevensaggregatie en -voorbereiding voor ML. Data Wrangler vereenvoudigt het proces van gegevensvoorbereiding en functie-engineering zoals gegevensselectie, opschoning, verkenning en visualisatie vanuit een enkele visuele interface. Data Wrangler heeft meer dan 300 vooraf geconfigureerde datatransformaties die effectief kunnen worden gebruikt bij het transformeren van de data. Bovendien kunt u aangepaste transformatie schrijven in PySpark, SQL en panda's.
Vandaag zijn we verheugd om een nieuwe transformatietechniek toe te voegen die veel wordt gebruikt in de ML-wereld aan de lijst met vooraf gebouwde Data Wrangler-transformaties: dimensionaliteitsreductie met behulp van Principal Component Analysis. Met deze nieuwe functie kunt u met slechts een paar klikken op de Data Wrangler-console het grote aantal dimensies in uw datasets terugbrengen tot een dimensie die kan worden gebruikt met populaire ML-algoritmen. Dit kan met minimale inspanning aanzienlijke verbeteringen in de prestaties van uw model opleveren.
In dit bericht geven we een overzicht van deze nieuwe functie en laten we zien hoe u deze kunt gebruiken in uw datatransformatie. We zullen laten zien hoe je dimensionaliteitsreductie kunt gebruiken op grote schaarse datasets.
Overzicht van hoofdcomponentenanalyse
Principal Component Analysis (PCA) is een methode waarmee de dimensionaliteit van kenmerken kan worden getransformeerd in een dataset met veel numerieke kenmerken in een met minder kenmerken terwijl toch zoveel mogelijk informatie uit de originele dataset behouden blijft. Dit wordt gedaan door een nieuwe set functies te vinden, genaamd componenten, dit zijn composieten van de originele kenmerken die niet met elkaar gecorreleerd zijn. Meerdere features in een dataset hebben vaak minder impact op het eindresultaat en kunnen de verwerkingstijd van ML-modellen verlengen. Het kan voor mensen moeilijk worden om dergelijke hoogdimensionale problemen te begrijpen en op te lossen. Dimensionaliteitsreductietechnieken zoals PCA kunnen dit voor ons helpen oplossen.
Overzicht oplossingen
In dit bericht laten we zien hoe je de dimensionaliteitsreductietransformatie in Data Wrangler kunt gebruiken op de MNIST dataset om het aantal kenmerken met 85% te verminderen en toch een vergelijkbare of betere nauwkeurigheid te bereiken dan de originele dataset. De MNIST-dataset (Modified National Institute of Standards and Technology), de de facto "hallo wereld"-dataset in computervisie, is een dataset van handgeschreven afbeeldingen. Elke rij van de gegevensset komt overeen met een enkele afbeelding van 28 x 28 pixels, voor een totaal van 784 pixels. Elke pixel wordt vertegenwoordigd door een enkele functie in de dataset met een pixelwaarde variërend van 0-255.
Voor meer informatie over de nieuwe functie voor dimensionaliteitsreductie, zie Dimensionaliteit binnen een dataset verminderen.
Voorwaarden
Dit bericht gaat ervan uit dat je een Amazon SageMaker Studio domein opgezet. Raadpleeg voor meer informatie over het instellen Aan boord van Amazon SageMaker Domain met behulp van Snelle installatie.
Open daarna Studio om aan de slag te gaan met de nieuwe mogelijkheden van Data Wrangler upgraden naar de nieuwste versie En kies de Dien in menu, New en Stroom, of kies Nieuwe datastroom vanuit het Studio-opstartprogramma.
Voer een Quick Model-analyse uit
De dataset die we in dit bericht gebruiken, bevat 60,000 trainingsvoorbeelden en labels. Elke rij bestaat uit 785 waarden: de eerste waarde is het label (een getal van 0–9) en de overige 784 waarden zijn de pixelwaarden (een getal van 0–255). Eerst voeren we een Quick Model-analyse uit op de onbewerkte gegevens om prestatiestatistieken te verkrijgen en deze te vergelijken met de modelstatistieken post-PCA-transformaties voor evaluatie. Voer de volgende stappen uit:
- Download de MNIST dataset trainingsdataset.
- Pak de gegevens uit het .zip-bestand en upload ze naar een Amazon eenvoudige opslagservice (Amazon S3) emmer.
- Kies in Studio New en Data Wrangler-stroom om een nieuwe Data Wrangler-stroom te maken.
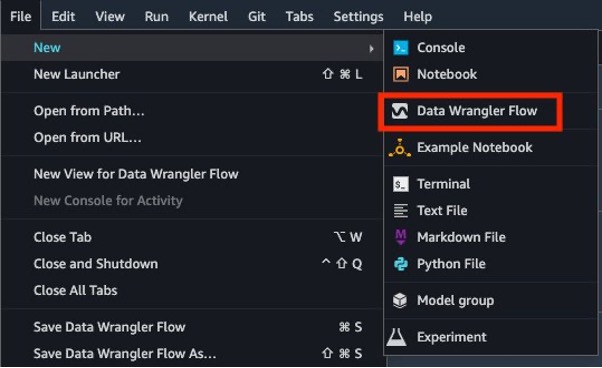
- Kies Datums importeren om de gegevens van Amazon S3 te laden.

- Kies Amazon S3 als uw gegevensbron.
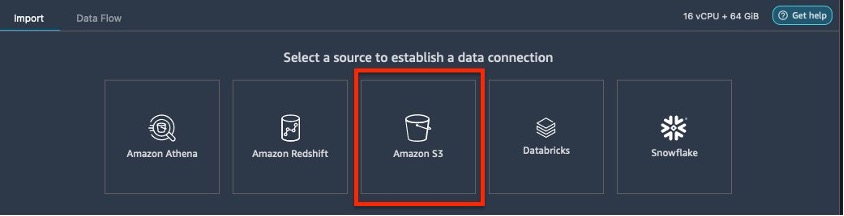
- Selecteer de dataset die is geüpload naar uw S3-bucket.
- Laat de standaardinstellingen staan en kies import.
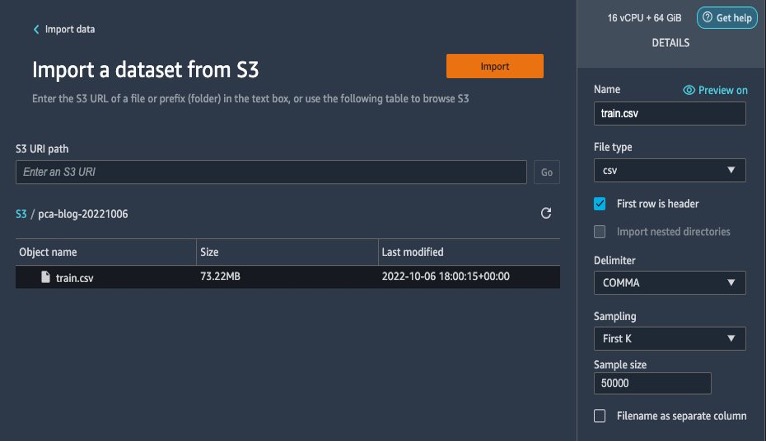
Nadat de gegevens zijn geïmporteerd, valideert Data Wrangler automatisch de datasets en detecteert het de gegevenstypen voor alle kolommen op basis van de steekproeven. Omdat alle kolommen lang zijn in de MNIST-dataset, laten we deze stap zoals hij is en gaan we terug naar de gegevensstroom.
- Kies Informatiestroom Op de top van de Datatypen pagina om terug te keren naar de hoofdgegevensstroom.
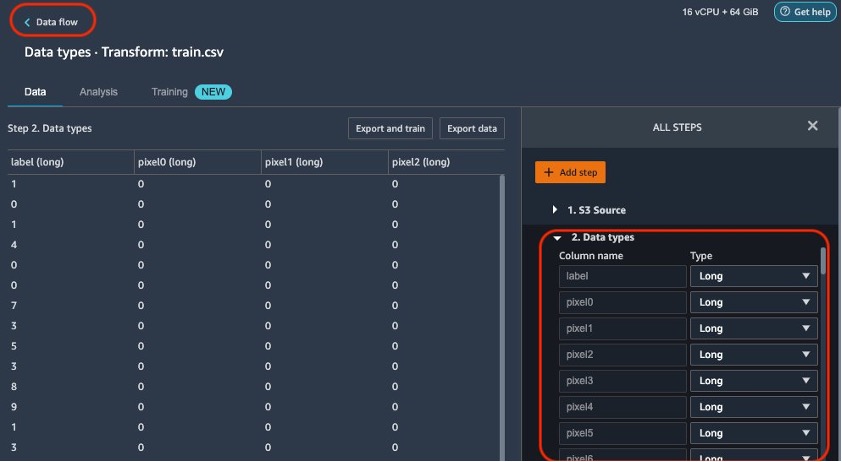
De stroomeditor toont nu twee blokken die laten zien dat de gegevens zijn geïmporteerd uit een bron en dat de gegevenstypen zijn herkend. U kunt indien nodig ook de gegevenstypen bewerken.
Nadat we hebben bevestigd dat de gegevenskwaliteit acceptabel is, gaan we terug naar de gegevensstroom en gebruiken we Data Wrangler's Data Quality and Insights Report. Dit rapport voert een analyse uit op de geïmporteerde gegevensset en biedt informatie over ontbrekende waarden, uitschieters, doellekkage, onevenwichtige gegevens en een Quick Model-analyse. Verwijzen naar Krijg inzicht in gegevens en gegevenskwaliteit voor meer informatie.
Voor deze analyse richten we ons alleen op het Quick Model-gedeelte van het Data Quality-rapport.
- Kies het plusteken naast Datatypen, kies dan Analyse toevoegen.

- Voor Type analyseKiezen Rapport over gegevenskwaliteit en inzichten.
- Voor Doelkolom, kies label.
- Voor Type probleemselecteer Classificatie (deze stap is optioneel).
- Kies creëren.
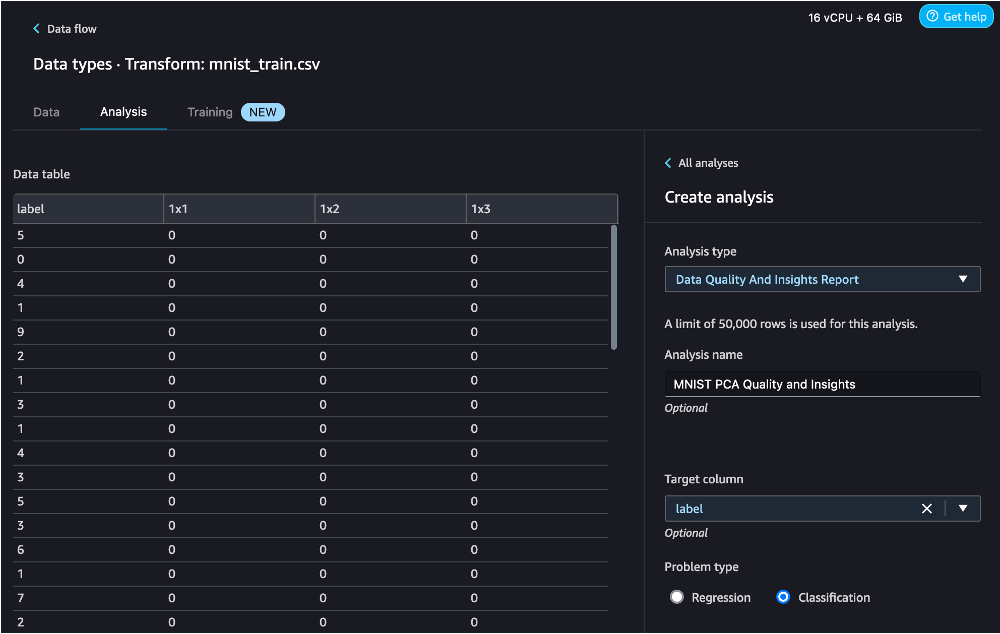
Voor dit bericht gebruiken we het Data Quality and Insights Report om te laten zien hoe de modelprestaties grotendeels behouden blijven met behulp van PCA. We raden u aan een op deep learning gebaseerde aanpak te gebruiken voor betere prestaties.
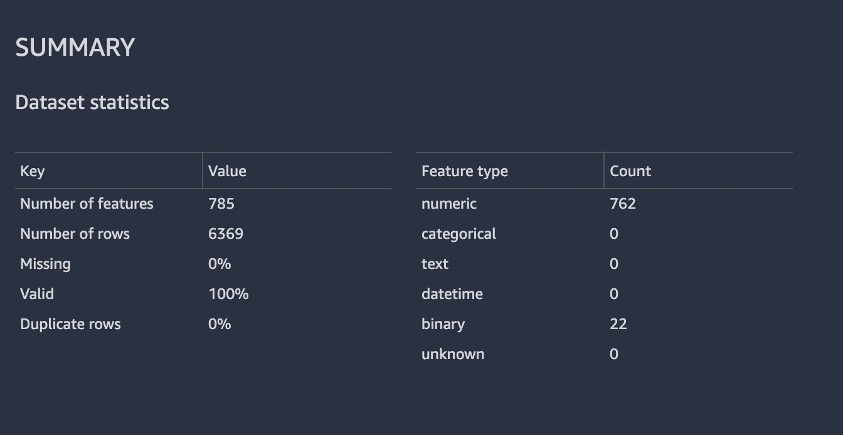
De volgende schermafbeelding toont een samenvatting van de dataset uit het rapport. Gelukkig hebben we geen ontbrekende waarden. De tijd die nodig is om het rapport te genereren, is afhankelijk van de grootte van de gegevensset, het aantal functies en de instantiegrootte die door Data Wrangler wordt gebruikt.
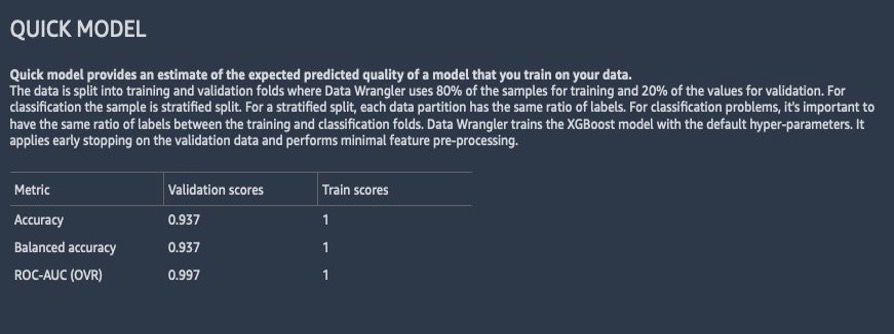
De volgende schermafbeelding laat zien hoe het model presteerde op de onbewerkte dataset. Hier zien we dat het model een nauwkeurigheid heeft van 93.7% met behulp van 784 functies.
Gebruik de Data Wrangler-transformatie voor dimensionaliteitsreductie
Laten we nu de Data Wrangler-transformatie voor dimensionaliteitsreductie gebruiken om het aantal objecten in deze dataset te verminderen.
- Kies op de gegevensstroompagina het plusteken naast Datatypen, kies dan Voeg transformatie toe.

- Kies Stap toevoegen.
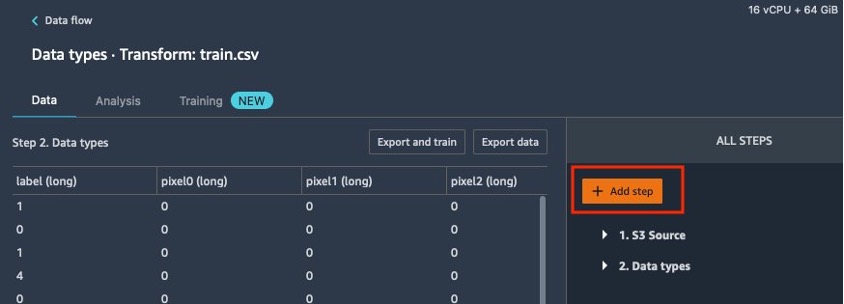
- Kies Dimensionaliteitsvermindering.
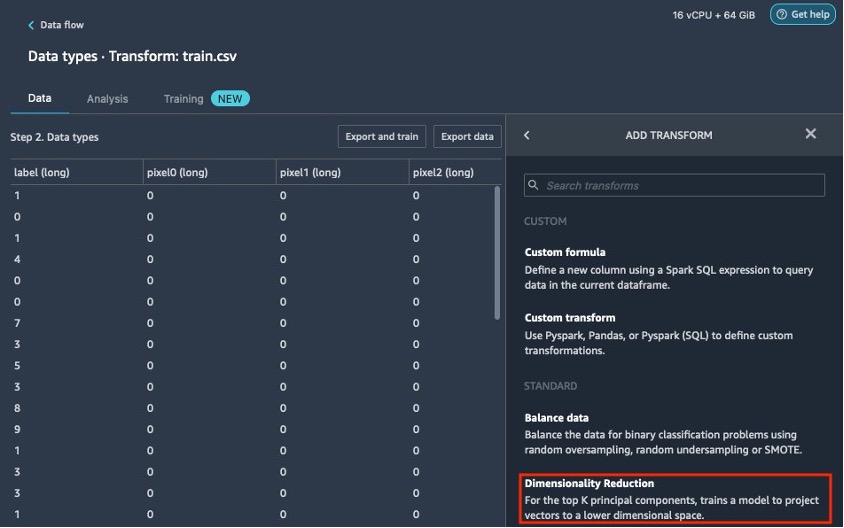
Als u de optie voor dimensionaliteitsreductie niet ziet, moet u Data Wrangler bijwerken. Raadpleeg voor instructies Gegevens Wrangler bijwerken.
- Configureer de belangrijkste variabelen die in PCA gaan:
- Voor Transformeren, kiest u de dimensionaliteitsreductietechniek die u wilt gebruiken. Voor deze post kiezen we Analyse van de belangrijkste componenten.
- Voor Invoerkolommen, kiest u de kolommen die u wilt opnemen in de PCA-analyse. Voor dit voorbeeld kiezen we alle functies behalve het doelkolomlabel (u kunt ook de Selecteer alle functie om alle functies te selecteren en de selectie van niet benodigde functies ongedaan te maken). Deze kolommen moeten van het numerieke gegevenstype zijn.
- Voor Aantal hoofdcomponenten, geeft u het aantal doeldimensies op.
- Voor Variantie drempel percentage, specificeer het variatiepercentage in de gegevens dat u wilt verklaren aan de hand van de hoofdcomponenten. De standaardwaarde is 95; voor deze post gebruiken we 80.
- kies Centreren om de gegevens te centreren met het gemiddelde vóór het schalen.
- kies Scale om de gegevens te schalen met de standaarddeviatie van de eenheid.
PCA legt meer nadruk op variabelen met een hoge variantie. Daarom krijgen we inconsistente resultaten als de dimensies niet worden geschaald. De waarde voor één variabele kan bijvoorbeeld in het bereik van 50–100 liggen en een andere variabele is 5–10. In dit geval zal PCA meer gewicht toekennen aan de eerste variabele. Dergelijke problemen kunnen worden opgelost door de dataset te schalen voordat PCA wordt toegepast. - Voor Output Format, specificeer of u componenten wilt uitvoeren in afzonderlijke kolommen of vectoren. Voor deze post kiezen we columns.
- Voor Uitvoerkolom, voer een voorvoegsel in voor kolomnamen die door PCA zijn gegenereerd. Voor deze post voeren we PCA80_ in.
- Kies Voorbeschouwing om een voorbeeld van de gegevens te bekijken en kies vervolgens bijwerken.

Na toepassing van PCA wordt het aantal kolommen teruggebracht van 784 naar 115. Dit is een vermindering van 85% van het aantal functies.
We kunnen nu de getransformeerde dataset gebruiken en een ander Data Quality and Insights Report genereren, zoals weergegeven in de volgende schermafbeelding, om de modelprestaties te observeren.

We kunnen in de tweede analyse zien dat de modelprestaties zijn verbeterd en dat de nauwkeurigheid is toegenomen tot 91.8% in vergelijking met het eerste Quick Model-rapport. PCA verminderde het aantal kenmerken in onze dataset met 85%, terwijl de modelnauwkeurigheid op een vergelijkbaar niveau bleef.
Op basis van de Quick Model-analyse uit het rapport zijn de modelprestaties 91.8%. Met PCA hebben we de kolommen met 85% verkleind, terwijl de modelnauwkeurigheid toch op een vergelijkbaar niveau bleef. Voor betere resultaten kunt u deep learning-modellen proberen, die mogelijk nog betere prestaties bieden.
We vonden de volgende vergelijking in trainingstijdgebruik Amazon SageMaker-stuurautomaat met en zonder PCA-dimensionaliteitsreductie:
- Met PCA maatreductie - 25 minuten
- Zonder PCA dimensionale reductie - 45 minuten
PCA operationaliseren
Aangezien gegevens in de loop van de tijd veranderen, is het vaak wenselijk om onze parameters opnieuw te trainen voor nieuwe ongeziene gegevens. Data Wrangler biedt deze mogelijkheid door het gebruik van aanpassingsparameters. Voor meer informatie over het aanpassen van getrainde parameters, zie Pas getrainde parameters aan op grote datasets met Amazon SageMaker Data Wrangler.
Eerder pasten we PCA toe op een steekproef van de MNIST-dataset met 50,000 voorbeeldrijen. Bijgevolg bevat ons stroombestand een model dat is getraind op dit voorbeeld en wordt gebruikt voor alle gemaakte taken, tenzij we specificeren dat we die parameters opnieuw willen leren.
Voer de volgende stappen uit om uw modelparameters opnieuw aan te passen aan de MNIST-trainingsgegevensset:
- Maak een bestemming voor ons stroombestand in Amazon S3, zodat we een Data Wrangler-verwerkingstaak kunnen maken.
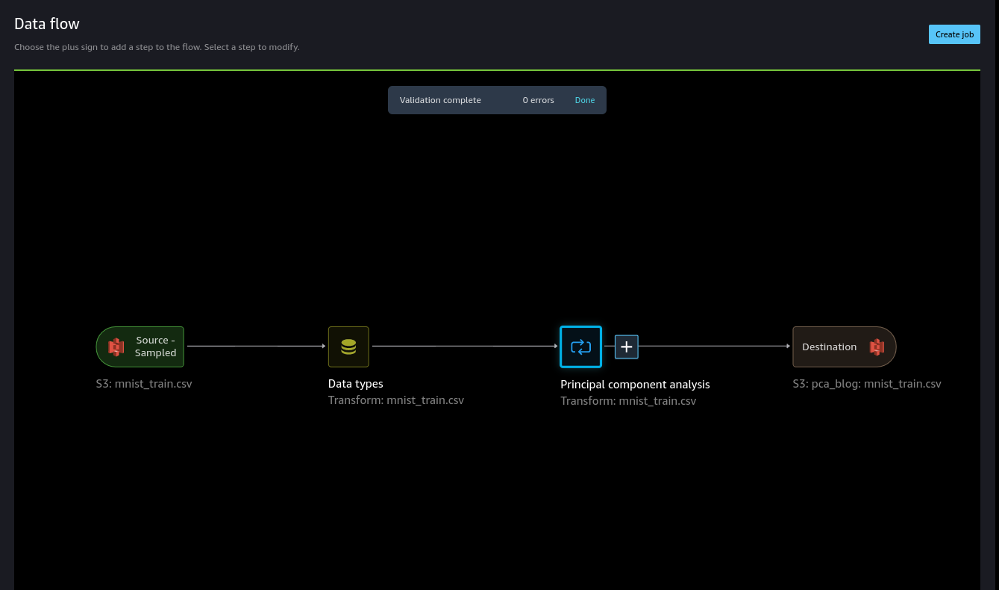
- Maak een vacature aan en selecteer herstel om nieuwe trainingsparameters te leren.
De Getrainde parameters sectie laat zien dat er 784 parameters zijn. Dat is één parameter voor elke kolom omdat we de labelkolom hebben uitgesloten in onze PCA-reductie.
Merk op dat als we niet selecteren herstel in deze stap worden de getrainde parameters gebruikt die tijdens de interactieve modus zijn geleerd.
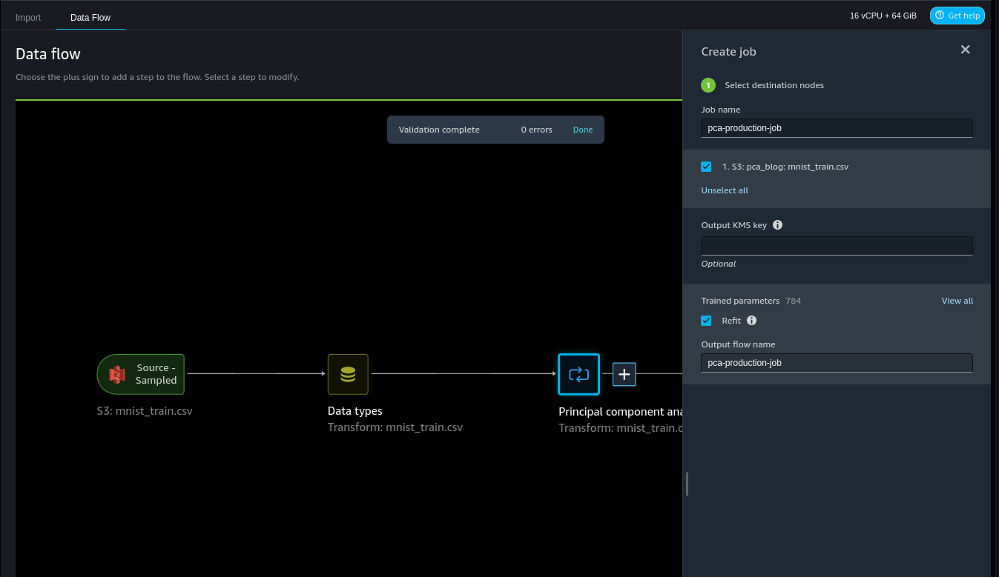
- Maak de baan.
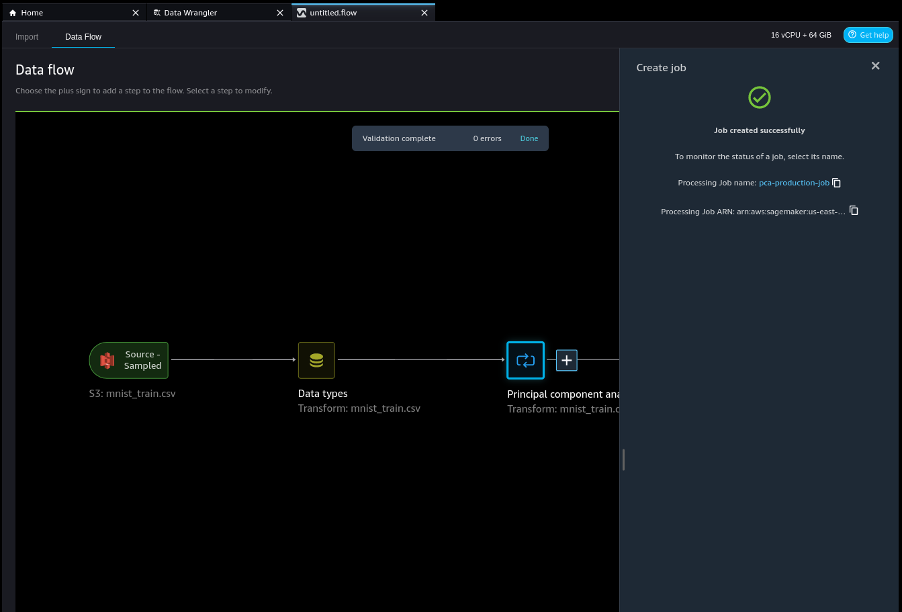
- Kies de verwerkingstaakkoppeling om de taak te volgen en zoek de locatie van het resulterende stroombestand op Amazon S3.
Dit stroombestand bevat het model dat is geleerd op de volledige MNIST-treindataset.
- Laad dit bestand in Data Wrangler.
Opruimen
Verwijder de datasets en artefacten in Amazon S3 om de omgeving op te schonen zodat u geen extra kosten hoeft te maken. Verwijder bovendien het gegevensstroombestand in Studio en sluit de instantie waarop het draait af. Verwijzen naar Sluit Data Wrangler af voor meer informatie.
Conclusie
Dimensionaliteitsreductie is een geweldige techniek om de ongewenste variabelen uit een model te verwijderen. Het kan worden gebruikt om de modelcomplexiteit en ruis in de gegevens te verminderen, waardoor het veelvoorkomende probleem van overfitting in machine learning- en deep learning-modellen wordt verminderd. In deze blog hebben we aangetoond dat we door het verminderen van het aantal functies nog steeds een vergelijkbare of hogere nauwkeurigheid voor onze modellen konden bereiken.
Raadpleeg voor meer informatie over het gebruik van PCA Principal Component Analysis (PCA)-algoritme. Voor meer informatie over de dimensionaliteitsreductietransformatie, zie Dimensionaliteit binnen een dataset verminderen.
Over de auteurs
 Adeleke Koker is een Global Solutions Architect bij AWS. Hij werkt samen met klanten over de hele wereld om begeleiding en technische assistentie te bieden bij het op grote schaal implementeren van productieworkloads op AWS. In zijn vrije tijd houdt hij van leren, lezen, gamen en kijken naar sportevenementen.
Adeleke Koker is een Global Solutions Architect bij AWS. Hij werkt samen met klanten over de hele wereld om begeleiding en technische assistentie te bieden bij het op grote schaal implementeren van productieworkloads op AWS. In zijn vrije tijd houdt hij van leren, lezen, gamen en kijken naar sportevenementen.
 Abigail is een Software Development Engineer bij Amazon SageMaker. Ze is gepassioneerd door het helpen van klanten bij het voorbereiden van hun gegevens in DataWrangler en het bouwen van gedistribueerde machine learning-systemen. In haar vrije tijd houdt Abigail van reizen, wandelen, skiën en bakken.
Abigail is een Software Development Engineer bij Amazon SageMaker. Ze is gepassioneerd door het helpen van klanten bij het voorbereiden van hun gegevens in DataWrangler en het bouwen van gedistribueerde machine learning-systemen. In haar vrije tijd houdt Abigail van reizen, wandelen, skiën en bakken.
 Vishaal Kapoor is een Senior Applied Scientist bij AWS AI. Hij is gepassioneerd om klanten te helpen hun gegevens in Data Wrangler te begrijpen. In zijn vrije tijd mountainbiket, snowboardt hij en brengt hij tijd door met zijn gezin.
Vishaal Kapoor is een Senior Applied Scientist bij AWS AI. Hij is gepassioneerd om klanten te helpen hun gegevens in Data Wrangler te begrijpen. In zijn vrije tijd mountainbiket, snowboardt hij en brengt hij tijd door met zijn gezin.
 Raviteja Yelamanchili is een Enterprise Solutions Architect bij Amazon Web Services, gevestigd in New York. Hij werkt samen met grote financiële dienstverleners aan het ontwerpen en implementeren van zeer veilige, schaalbare, betrouwbare en kosteneffectieve applicaties in de cloud. Hij brengt meer dan 11 jaar ervaring met risicobeheer, technologieadvies, data-analyse en machine learning met zich mee. Als hij geen klanten helpt, houdt hij van reizen en PS5 spelen.
Raviteja Yelamanchili is een Enterprise Solutions Architect bij Amazon Web Services, gevestigd in New York. Hij werkt samen met grote financiële dienstverleners aan het ontwerpen en implementeren van zeer veilige, schaalbare, betrouwbare en kosteneffectieve applicaties in de cloud. Hij brengt meer dan 11 jaar ervaring met risicobeheer, technologieadvies, data-analyse en machine learning met zich mee. Als hij geen klanten helpt, houdt hij van reizen en PS5 spelen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/amazon-sagemaker-data-wrangler-for-dimensionality-reduction/

